

Chainbaseの核心解説:1500万ドルを調達、最大のフルチェーンデータネットワークがCryptoとAIを相互に発展させる
TechFlow厳選深潮セレクト
Chainbaseの核心解説:1500万ドルを調達、最大のフルチェーンデータネットワークがCryptoとAIを相互に発展させる
Chainbaseは、すべてのブロックチェーンデータを統一されたエコシステムに統合し、AGI時代における最大級の信頼できる、安定した、透明性のあるデータソースとなることを目指しています。
執筆:TechFlow

現在の暗号資産市場は、整理期へと徐々に入りつつある。物語が静まり返り、既存プロジェクトたちも目立った成果を出せない中で、新たなアルファ機会はどこにあるのか?
外に目を向ければ、AGI時代の波がすでに到来している。内を見つめれば、AIは依然として今年通年の暗号叙事を貫くテーマであり、注目と流動性を集める磁石でもある。
ただし、今やAI分野においては、「構造的」な機会をより細かく探る必要がある:
AIの三つの基本要素である「計算力」「アルゴリズム」「データ」に着目すると、前者二つにはRender Network、IO、Bittensorといったトッププロジェクトがすでに登場しており、類似プロジェクトも集中しレッドオーシャン化している。一方、データ系プロジェクトはDePINの方向に多く進んでいる。
それに対してWeb3ネイティブなオンチェーンデータを有効活用する領域こそが、まだアルファを掘り起こせる宝庫なのである。
そして、一次市場の感度の高い資金は、すでに足で投票を始めている。
最近、重量級の資金調達が再び発表された。データ分野のプロジェクトChainbaseは、Matrix Partnersをリード投資家とした1500万ドルのシリーズA調達を発表。その他、あるインターネット企業の戦略的出資に加え、Hash Global、Folius Ventures、JSquare、DFG、MaskNetwork、Bodl Ventures、Bonfire Union Venturesなど著名な機関も参加した。

資金の流れは、ある意味で物語への予測とプロジェクトへの期待を示している。では、なぜChainbaseはこれほどまでに資金から支持されるのか?
TLDR : 最大の全チェーンデータネットワーク、オープンなデータスタック技術
ここに、要点だけをまとめたキーポイントを紹介する。Chainbaseを素早く理解するためのものだ。
-
より高次元の製品:オンチェーンデータといえば、普通はスマートマネー分析、ダッシュボード構築、データクエリなどが連想される。しかしChainbaseはこれらを包含する、さらに高次元のインフラ(Infra)製品である。これらのアプリケーションはすべて同製品上で実現できるが、Infraが果たせる役割はそれ以上に広い。
-
最大規模の全チェーンデータネットワーク:この高次元性の原点は、「全チェーンデータネットワーク」という最大の特徴にある。広大かつ断片化された暗号世界におけるあらゆるチェーン上のデータ、さらにはオフチェーンデータまでも統合・加工し、価値が眠るデータの金山と化す。
-
堅実なプロジェクト背景/チーム/サポート:Chainbaseは15,000人以上の開発者と8,000以上のプロジェクトを抱え、5,000億回以上の全チェーンデータ呼び出しを処理している。チームメンバーは一流テック企業のデータ関連分野出身であり、前述の出資機関に加え、Eigenlayer(経済的安全性提供)、Cosmos(コンセンサス安全性提供)といったトップレベルのパートナーもアーキテクチャ上での支援を行っている。
-
自己完結的なデータネットワーク実現ロジック:一般的な「まずブロックチェーンありき、その後にユースケースが登場」という公的チェーンの展開とは異なり、Chainbaseは最初から技術開発者と一般ユーザーをターゲットに、高品質なデータを提供。エコシステムとユースケースが成熟した後に自前のデータネットワークを構築するという順序を採っている。
-
Crypto NativeなAI大規模言語モデル:業界の多くのプロジェクトがGPTをラッピングしているのに対し、Chainbaseは独自開発のTheia AIモデルを保有。オンチェーン由来の高品質データで学習させ、マルチモーダル対応も可能で、Web3 × AIの基盤となる可能性を秘めている。

すべてのオンチェーン・オフチェーンデータが貢献され、本来の価値を発揮し、すべての人がデータ+AIを通じて自分に適した使い方を見つけられるとき――
Web3はようやく自身のオンチェーンデータインフラを持つことになる。この市場の想像力は膨大であり、アルファの気配が漂い始める。
DeFiにとってのオラクルのように、AIにとってのデータとは何か。全チェーンデータが「知能の舞」を踊り始めるとき、暗号の舞台に新たな一幕は上演されるだろうか。
早めの入場券を手に入れ、我々と一緒に「事前見学会」へ行こう。Chainbaseという最大の全チェーンデータネットワークのプロダクトメカニズム、適用シーン、AI能力、経済モデルを先取り解説する。
オンチェーンデータ:未だ効率的に利用されていない「暗黙知」
Chainbaseを理解し、そのビジネスロジックを把握するには、まずデータの価値を理解する必要がある。
実は2017年、『エコノミスト』の表紙記事で「データは石油に取って代わり、新時代において世界で最も価値ある資源となった」と指摘されていた。そして2024年、AGI(汎用人工知能)の台頭とともに、この「最も価値ある資源」であるデータは、AIによってますます効率的に採掘・利用されている。
OpenAIは45TBの生データから570GBを抽出してGPT-3を訓練した。大量かつ迅速、リアルタイム、体系的なデータ処理が行われており、GPT-4に至ってはその質と量がさらに拡大している。AIの優れたパフォーマンスを支える土台となっている。
一方で、暗号世界のオンチェーンデータは、まだ十分に効率的に利用されていない。
現在のWeb3におけるデータは、あたかもさまざまな隅に放置されているようなものだ。多くの暗号プロジェクトが行っているのは、その横たわるデータを「立たせる」こと――例えば従来のデータベース方式でインデックスを作成しオンチェーンデータを検索したり、Text to SQLにより問い合わせ要求をSQLコードに変換して結果を表示したりすることに過ぎない。
あなたが使うオンチェーンデータは、知能的に分析されておらず、リアルタイムのフィードバックもできず、暗号世界のすべてのチェーンすべての場所を網羅的に走査して、GPTのように知識や知恵を体系的に出力することはできない。

我々はオンチェーンデータを使って客観的・機械的に「何であるか」を答えることはできるが、「どうすればいいか」という知的な問いへの答えはまだ得られていない。言い換えれば、オンチェーンデータは表面上見えているように見えるが、実際には眠れる「暗黙知(ダークナレッジ)」なのである。
不十分な知能性、主体性、創造性、そして非中央集権性。
多くの暗号プロジェクトがデータを利用する際、コミュニティの主体性は十分に発揮されていない。
暗号愛好者のなかには才能豊かな人々が多く存在する。彼らは自身のリサーチニーズに基づいてサンプルを作成し、「このようなシナリオではデータをこう使えばよい」と示すことができるはずだが、現時点ではこのような非中央集権的な「知識の共同構築」はまだ普遍的ではない。
また、オンチェーンデータの整理から加工、出力、利用に至る一連のプロセスにおいて、コミュニティが参加できる余地は非常に少なく、暗号エコシステム内のさまざまな参加者の積極性をいかに最大化し、より大きなデータネットワークを構築するかは、魅力的で実現すべき課題である。
したがって、我々はオンチェーンデータを効率的に利用するだけでなく、非中央集権的な方法でデータを利用する必要がある。
-
SQLクエリ、インデックス型、非リアルタイムな利用方法から「次元上昇」し、より知能的になること。
-
OpenAIのような中央集権的モデルから、より透明で信頼でき、オープンソースかつコミュニティ主導のものに変えること。
そして、まさにここでChainbaseが登場する。
万チェーン合一:全チェーンデータの登場
上記の背景を踏まえれば、Chainbaseの本質がより理解しやすくなる。
世界で最大の全チェーンデータネットワークを構築し、すべてのブロックチェーンデータを統一されたエコシステムに統合することで、AGI時代における最大の信頼できる、安定した、透明なデータソースとなることを目指している。
もっとわかりやすく言えば、どのチェーン上のどんなデータであっても、誰でもより知能的に利用できるようにするということだ。
もし「全チェーンデータネットワーク」という概念がまだピンとこなければ、まずは全チェーンデータを顕微鏡で覗いてみよう。
まず、「全」とはどれほど「全」なのか?
各チェーンはそれぞれ独自のアーキテクチャとデータを持っているが、Chainbaseはあたかも「万チェーン合一」のように機能し、BTC、ETHなどを含む数十の主要L1/L2チェーン、EVMおよび非EVMチェーンのすべてのデータを統一エコシステムに統合する。

次に、この全チェーンデータの中身とは何か?
答えは、「ブロックチェーンに関するすべて」だ。
これは抽象的すぎるかもしれないが、詳しく見てみると、以下の種類のデータが含まれる。
-
Rawデータ:ブロックチェーン上に最初に記録されたデータ。ブロック、コントラクト、トランザクションなど。
-
Decoded(復号化)データ:生データから情報を抽出し、人間が読み取り可能な形式に変換したもの。例:異なるDeFiプロトコルの取引状況など。
-
Abstracted(抽象化)データ:高度なデータで、重要な情報や指標を抽出し、ビジネス分析や意思決定に適した形にしたもの。トークン、価格、インスクリプション&ルーンなど、理解しやすく特定の分析が必要な部分を指定できる。
まるで料理をする(データ分析を行う)場合、素材が生(Raw)から半調理(Abstracted)まで、自由に使えるようなものだ。
特筆すべきは、Chainbaseデータネットワーク内のこれらの全チェーンデータがリアルタイムで提供されること(更新間隔3秒未満)。つまり、素材の生熟具合を選べるだけでなく、素材そのものが常に新鮮に保たれている。
これは現時点のほとんどの暗号データプロジェクトが実現できていない「データの鮮度」である。

では、この膨大な全チェーンデータはどこから来るのか?
オンチェーンデータに関しては、任意のチェーンのNODE operatorまたはRPC providerがChainbaseネットワークに接続し、Chainbaseアーキテクチャ内の公開データゲートウェイ(open data gateway)を通じて、上述のデータを提供できる。
これがChainbaseのデータ入口、すなわちData Accessibility Layerを形成する。その実現には一定程度の技術的理解が必要なため、後述のアーキテクチャ分析で詳しく説明するが、ここでは機能説明に留める。
最後に、この全チェーンデータは一体どれくらいの規模なのか?
Chainbase公式サイトの公開データによると、現在ネットワーク内にはPB単位のデータが保存されており、毎日1.1億~1.5億回の全チェーンデータ呼び出しを処理している。累計呼び出し回数はすでに5,000億回を超えた。
これらのデータ呼び出しの源は、すでに提携している15,000人以上の開発者と8,000以上の暗号プロジェクトである。

我々の目に見えない暗号世界の奥深くで、巨大な全チェーンデータネットワークがすでに形成されている。
データ量から見れば、「最大の全チェーンデータ」という称号はまさに相応しい。しかし、その背後にある「ネットワーク」という概念はどこに現れているのか?
全体の視点から見ると、前述のData Accessibility Layerがまず第一に挙げられ、すべてのチェーンからのデータを吸収し、入り口の役割を担う。
次に、全チェーンデータの処理はOpenAIやクラウドベンダーのような中央集権的処理ではなく、Chainbaseはトークン報酬を動機に、コミュニティ主導、複数参加者が役割分担しながらデータを加工する構造を構築している。
最後に、上述のオンチェーン・オフチェーンの生データが処理され、Chainbaseデータネットワーク上で可視化される。ネットワーク内の開発者は、この生データをもとに「手稿」を構築し、データの定義、抽出、変換、処理を行い、全チェーンデータから価値ある情報を分析に利用できる。

このように、全チェーンデータは裏方から表舞台へ、収集、処理、提示、利用という複数の段階を経て登場する。データ利用の「道」を提供するものであり、具体的な「術」には以下のようなものがある。
ウォレットが単一インターフェースで複数ブロックチェーン上の資産を管理・閲覧できるようにし、ユーザビリティを向上させる。
セキュリティ分野:攻撃の追跡、セキュリティ警告の提供、深いセキュリティ分析を行い、ブロックチェーンネットワークを保護する。
ソーシャル分野:異なるブロックチェーンのユーザーがシームレスにインタラクションしコンテンツを共有できるソーシャルプラットフォームを構築。
DeFi:DeFiプラットフォームが異なるブロックチェーン間での貸借をサポートし、流動性と柔軟性を高める。
これらはあくまで一例にすぎない。インフラ製品として、Chainbaseの利点はこれらすべてのアプリケーションを実現できるだけでなく、それ以上の可能性を秘めている。
4層+ダブルコンセンサスアーキテクチャ:整然とした舞台の基盤
全チェーンデータが舞台上で舞うことができるのは、必ずその背後に支える土台があるからだ。
Chainbaseの4層+ダブルコンセンサスアーキテクチャデータネットワークは、実際には舞台の4本の柱の役割を果たしている。各層が独自の機能を持ち、全チェーンデータの利用のために協働し、すべての裏方作業が整然と進行するよう保証している。
全チェーンネットワークについて述べる際に、前項ですでにこのアーキテクチャに触れられているが、ここではより詳細な視点で分析しよう。
Chainbaseのすべての業務はデータを中心に展開されているため、データの入力、処理、出力というプロセスを切り口に、下から上へと4層アーキテクチャが何を行っているかを見ていくことにする。

-
データ取得層:全チェーンデータの入り口。データがどのようにネットワークに入るかを解決する。
-
コンセンサス層:データ処理中にデータ状態が変化した場合、非中央集権ネットワークが何らかの方法でその変化に合意する必要がある。これは多くの暗号プロジェクトが慣れ親しむ「コンセンサスの王道」である。
-
実行層:データ処理業務が発生する以上、安全かつ効率的に実行されることを保証する仕組みが必要である。
-
協処理層:データ出力の場所と通俗に理解できる。データの出力方法、誰が使うのか、どのような用途かという問題にかかわる。ここでいう「協処理」とは、コミュニティが共同で協力して高品質なデータを生成し、さまざまなシーンに応用することを意味する。
以上のロジックから、データがどうやって入り、どう加工され、どう利用されるかという点で、Chainbaseの4層アーキテクチャはそれぞれの役割を果たしていることが容易に理解できる。
次に、この4層を一つずつ分解し、各層の運営モデルと存在意義を確認していこう。
-
データ取得層:全チェーンデータのロールアップ、オフチェーンデータの安全な統合
この層はChainbaseのデータ入口である。
オンチェーンデータに関しては、任意のチェーンのNODE operatorまたはRPC providerがChainbaseネットワークに接続し、Chainbaseアーキテクチャの公開データゲートウェイ(open data gateway)を通じて、各チェーンのデータを提供できる。
オフチェーンデータ、たとえばSNSユーザー行動データなども、ZKなどの信頼できる方法により、公開データゲートウェイを経由してデータ取得層に入り、ロールアップ方式でChainbaseネットワークに接続される。プライバシーを守りながらデータを取得できる。
本質的には、これは非中央集権的なデータレイクに近く、データを蓄積する役割を果たす。同時に、ZKPによりアップロードされたデータが正しいこと、かつプライバシーが保護されていることが保証される。また、複数ノードによるデータ保存と検証(SCP)の方式により、データの信頼性と組織の非中央集権性が確保される。
-
コンセンサス層:Cosmosが提供するCometBFTコンセンサスメカニズムにより、ステータス同期を保証
どの暗号製品も直面する古典的な問題がある。「完全に公開され、信頼が限定された環境下で、ある事象の状態変化に対してどう一致を得るか?」
Chainbaseに具体化すると、それはデータ処理状態の変化である。
状態変化に対して合意を得るには、必然的にブロックチェーンの存在とコンセンサスアルゴリズムの使用が欠かせない。ChainbaseはCosmosのCometBFTコンセンサスアルゴリズムを採用している。ここでは技術的な詳細は省く。
知っておくべきは、これは改良されたビザンチンフォールトトレランス(BFT)アルゴリズムであり、ネットワークノードの最大3分の1が故障または悪意を持っていても合意に達できる。一部のノードが悪意を持っていても、合意が成立する。
この許容閾値は効率性と柔軟性を兼ね備えており、データ処理という比較的大規模な負荷条件下で効率的に合意を得るシナリオに適している。
-
実行層:EigenLayer + チェーン上データベース。性能を保証しつつ、追加の経済的安全性を導入
Chainbaseネットワーク内でデータ呼び出しが発生すると、実行層がその役割を果たす。
データ操作にはすべて「場所」、すなわちデータベースが必要である。Chainbaseは自社開発のChainbase DBチェーン上データベースを使用しており、データとタスクの並列処理を支え、高い同時接続呼び出し需要にも対応できるよう設計されている。これにより、ネットワーク全体のパフォーマンスとスループットが保証される。
しかし、データが実行可能であることは、それが十分に安全に実行されることを意味しない。
そのため、Chainbaseの解決策は、EigenLayerから経済的安全性を得ることである。
EigenLayerの継承特性を利用し、Chainbaseは独自のアクティブ検証サービス(AVS)を構築した。この方法により、Chainbaseはイーサリアムのステーキング参加者から継承される強力な経済的安全性を得ることができ、自社のデータ処理サービスの安全性を確保できる。
-
協処理層:コミュニティ共創、複数参加者が役割分担し、データ価値を最大化して出力
この層は私たちの直感に最も近い。データがどのように価値を発揮するために利用されているかが見える。
暗号世界では、異なるアプリケーションシナリオが大量かつ多様なデータを生み出す。これらの孤立し多様なデータから価値を抽出することが、協処理層が解決すべき課題である。
Chainbaseのこの層の設計思想は、多数の開発者が協力し、知識を蓄積することで集団的知恵を生み出すことにある。
この協力は、具体的な機能としては以下の通り。
-
知識貢献:ユーザーはデータ処理や専門タスクモデルに関する専門知識を協処理層に貢献できる。この協働環境は集団的知恵を活用してネットワークの機能を強化する。
-
知識の資産化:協処理層は知識の貢献を資産に変換し、その分配、流通、取引を管理することで、貢献者の知識と努力に報いる。
-
CBTトークンエコシステム:ネットワーク報酬構造に不可欠な一部であり、支払い、決済、ステーキング、ガバナンスを促進する。詳細は後述。
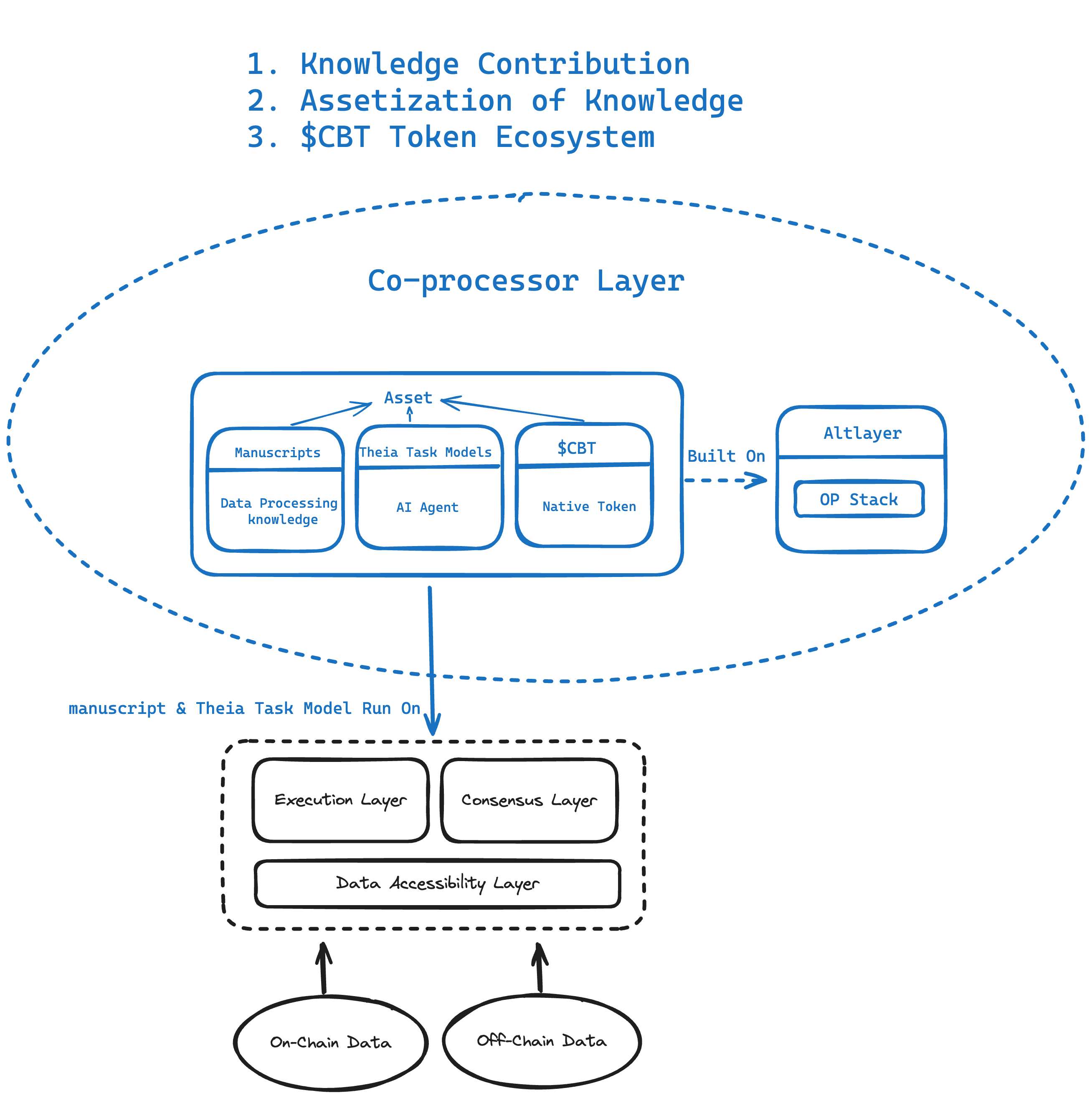
分かりやすく言えば、例えば「オンチェーン釣り詐欺を分析するレシピ」が必要な場合、開発者たちはそのニーズに必要なデータを抽出し、テンプレートとしてパッケージ化して皆で使えるようにする。
最後に、Chainbaseネットワークには一般ユーザーの参加空間もある。
通常の暗号愛好者はデータ分析の知識を持たないかもしれないが、自然言語でChainbaseネットワークと対話することで、暗号世界に関するさまざまな洞察や情報を得ることができる。
直感的には、これは一種の暗号版ChatGPTに見えるが、GPTの外側を張り替えて中身をそのまま使っているわけではない。むしろ、Chainbaseは協処理層において、一般ユーザー向けに大きな切り札を用意している。
Theia:膨大な全チェーンデータで学習させた、暗号ネイティブなAI大規模言語モデル。
Chainbaseはデータ処理業務を進めながら、70億の汎用大規模言語モデルパラメータと2億のcryptoパラメータを使ってTheiaを訓練した。

注意すべきは、「暗号ネイティブ」とは、GPTが手の届かない暗号世界で、リアルタイムに感知できるエージェントを育て、暗号世界で時々刻々起きていることを理解することを意味する。
GPTのラッピングは使えるが、ネイティブな暗号の文脈を理解できず、リアルタイムで低遅延の暗号ネイティブコンテンツを得ることもできない。
現在のほとんどのオンチェーンデータのAI利用方法は、スキーマをAIに与えてSQL文を書かせオンチェーンデータを検索するもので、依然として非知能的なクエリ段階、データベースからデータを引き出す段階にとどまっており、本質的にインデックスモードのプラス版に過ぎない。
一方、Theiaの動作モードは本質的に知能的モードである。既存の膨大なオンチェーン・オフチェーンデータに基づき、より効率的に思考・分析・回答を行う。主体性、創造性、リアルタイム性を備え、現在のオンチェーンデータ製品とは次元が異なる。
こうして、暗号愛好者の体質に最適化された大規模言語モデルが登場した。
今後、情報の優位性はもはや暗号界の「科学者」たちの特権ではなくなる。TheiaはAIの知能をより広い範囲のグループに解放する。一般人でもAIモデルを通じて、もともと専門的でハードコアな全チェーンデータネットワークを使えるようになる。
暗号ネイティブの大規模言語モデルTheiaを外部リソース(RAG)に接続することで、ジェネレーティブAIが出力する回答の正確性を高める。
ユーザーは使いやすいQ&Aインターフェースと対話するだけで、より知能的な応答を得られる。これらの応答は、広範なオンチェーン・オフチェーンデータおよび時空間活動から暗号パターンを学習し、因果推論を行うことで生成される。
例えば、「最近人気のDeFiプロトコルは何ですか?」と気軽な質問をしても、「人気」とはどう定義するか、データでどう裏付けるか、人気プロトコルのランキングと提示方法などはすべてTheiaが代行し、最終的な総合結果を提示してくれる。
データサイエンティストはTheiaを使ってタスクモデルを構築し、「魚を与えるよりも釣り方を教える」ことができる。例えば:
-
セキュリティタスクモデル――セキュリティ分野専用。AIに暗号セキュリティ脆弱性の評価、リアルタイム脅威監視、コンプライアンス監査などをさせる。
-
取引タスクモデル――市場トレンド分析、戦略最適化、リスク管理など。
-
意見タスクモデル――SNS感情追跡、ホットトピックトレンド、イベント影響力分析など。
AI能力に関しては、「魚を与える」よりも「釣り方を教える」方がずっと重要だ。
現時点で公開されている情報によれば、Theiaは市場のすべての暗号AI製品ができることをすべて実行できる。その自信と実力の裏付けは、膨大なデータとモデルチューニングにある。これは特定のシーンに一本の魚を与えるのではなく、「釣り方を教える」アプローチに近い。
同時に、協処理層を通じて、「全チェーンデータが連携して演じ、暗号ネイティブモデルTheiaが知能の舞を踊る」様子が見える。暗号世界の情報、インテリジェンス、洞察を得る方法が根本的に覆され、革新されるかもしれない。AIは暗号をより良くする助けとなる。
-
アーキテクチャ内のダブルコンセンサス:効率と安全を両立、経済的権益も考慮
Chainbaseの4層アーキテクチャを理解すれば、その中の「ダブルチェーン」構造も非常に理解しやすくなる。
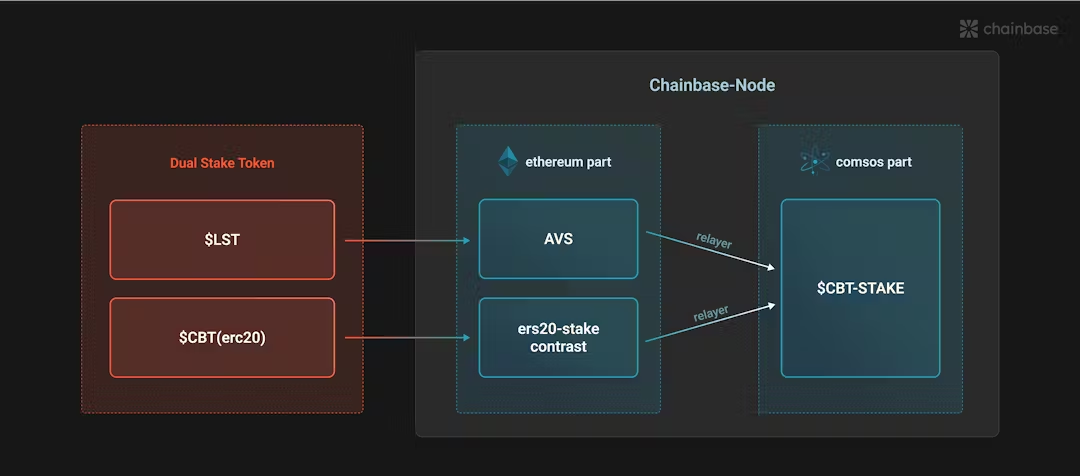
CosmosとEigenLayerの導入により、データ処理そのものとその状態変化の両方に、より強固な保証が与えられた。
EigenLayerは実行層で働き、AVSがタスクを担当し、イーサリアムの経済的安全性を継承する。Cosmosはコンセンサス層で働き、最適化されたBFTアルゴリズムによりデータ処理の状態変化に合意し、ある程度のフォールトトレランスを保証する。

さらに重要なのは、ダブルコンセンサスの導入により、経済的なダブルステーキングメカニズムが自然発生し、伝統的なPoSネットワークのデススパイラル問題を緩和することにある。
通常、あるプロジェクトの単一トークン価値が下落し始めた場合、そのプロジェクトがPoS方式を採用していれば、ネットワークの安全性も低下し、ステーキングに代表されるTVLも減少する。そして基本面の悪化がさらにトークン価格を押し下げ、悪循環となり、プロジェクトの安全性が不断に萎縮していく。
しかし、ダブルコンセンサス設計のもと、Chainbaseは自社のCBTトークンによるステーキングに加え、イーサリアムエコシステムの各種LSTトークンもステーキング可能。これによりネットワークの経済的安全性を高め、LST資産の価値を活性化し、外部の流動性をさらに取り込むことができる。
とはいえ、プロジェクトトークンCBTについて触れた以上、公式はまだ具体的なTGE時期やトークンエコノミクスを発表していないものの、トークンの機能と用途は明確であり、我々のリサーチに参考となる。
一言で言えば、CBTは経済的インセンティブを通じ、ネットワーク参加者が各自の役割を果たす鍵となる。
-
Chainbaseネットワーク運営ノード:データ処理タスクを円滑に遂行し、80%のデータクエリ料金(ユーザーがChainbaseネットワークを使ってデータを利用する際に支払う)+オペレータープール100%の報酬(Chainbaseプロジェクトが設立)を得る。
-
検証者:トランザクションを検証し、データの完全性を保ち、ネットワークの安定性を維持することで、100%のブロック報酬を得る。
-
開発者/データサイエンティスト:手稿を作成し、データセットが効果的に処理・クエリ可能になるようし、より良いデータ処理ロジックを提供することで、15%のデータクエリ料金報酬を得る。
-
委任者:トークンを検証者やオペレーターにステーキングし、報酬を共有。イーサリアムの委任ステーキングプロトコルにおける収益と同様。
総合的に見ると、Chainbaseのこの4層+ダブルコンセンサスアーキテクチャは、データネットワークの核心であり、データ処理プロセス全体を円滑かつ効率的に完了させると同時に、経済的効率性と安全性の両立を実現している。
巧妙かつ自己完結的、明確な設計が、全チェーンデータが舞台に立つための堅固な土台を築いている。特に協処理層が暗号ネイティブAIモデルを育てる取り組みは、データ利用の次元と広がりを一段と高めた。
データから知恵の提供へ:暗号とAIの相互成就
Chainbaseの製品を研究した後、筆者は同プロジェクトが「純粋なデータ提供者」から「AIを支援する全チェーンデータネットワーク」へと役割転換を図っていると感じた。
この役割の転換は、単なる空虚な物語の入れ替えではなく、暗号世界のデータ活用に関して、より一歩踏み込んだ決意を示している。
製品面から見ても、データ提供にとどまらず、データの知能的活用、知恵の形成に最適な条件を整えていることが明確にわかる。
知識管理分野では、以下のようなDIKWモデルが有名で、知識獲得の階層と方法を表している。これを踏まえ、暗号業界全体のデータと情報の活用について、より深い考察が可能になる。

このモデルから見ると、現在の大多数の暗号プロジェクトは、せいぜいデータと情報を提供しているにすぎず、知識や知恵の形成には程遠い。
主体性と創造性こそが、オンチェーンデータ活用の最終局面である。AGI時代のGPT-4はすでに知識と知恵を提供しているが、暗号世界のデータ活用は依然として道半ばである。
データ→情報→知識→知能へ。暗号データはAIをより良くし、逆にAIの能力が暗号ビジネスにさらに知恵と洞察を与え、効率と体験を向上させる。
暗号とAIは、本来相互に成就すべき関係にあるかもしれない。
Chainbase自体について、筆者はさらなる期待を寄せている。
現時点ですでに十分なデータ量があり、Theiaモデルも初歩的な段階を見せ始めている。公式Xではテストネット進捗が
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













