

1万字で解説する並列EVM:ブロックチェーンのパフォーマンスボトルネックをどう突破するか?
TechFlow厳選深潮セレクト
1万字で解説する並列EVM:ブロックチェーンのパフォーマンスボトルネックをどう突破するか?
並列EVMは、オンチェーン取引量が一定のレベルに達した後に登場した新しいナラティブである。
執筆:@leesper6
指導講師:@CryptoScott_ETH
TL;DR
-
並列EVMは、オンチェーン取引量の発展がある程度進んだ段階で現れた新たなナラティブ。並列EVMは主にモノリシックブロックチェーンとモジュラー型ブロックチェーンに分けられる。モノリシックブロックチェーンはさらにL1とL2に分類される。並列L1パブリックチェーンはEVM陣営と非EVM陣営の二大勢力に分かれている。現在、並列EVMナラティブは発展の初期段階にある。
-
並列EVMの技術的実装経路を分解すると、仮想マシン(VM)と並列実行メカニズムという二つの主要な側面が存在する。ブロックチェーンの文脈では、仮想マシンとは分散状態機械を仮想化するプロセス仮想マシンであり、契約の実行に用いられる。
-
並列実行とは、マルチコアプロセッサの利点を活かし、可能な限り同時に複数の取引を処理しながらも、最終的な状態が逐次実行時と一致することを保証する仕組みである。
-
並列実行メカニズムは、メッセージ渡し、共有メモリ、厳密な状態アクセスリストの3種類に大別される。共有メモリはさらにメモリロックモデルと楽観的並列化に分けられる。いずれの方式も技術的複雑性を高める。
-
並列EVMナラティブには業界成長の内的駆動要因がある一方、関係者はその潜在的な安全性問題にも高い関心を持つ必要がある。
-
並列EVM関連プロジェクトはそれぞれ異なる方法で並列実行のアイデアを提供しており、技術的共通点を持ちつつ独自の貢献もある。
1. 業界概要
1.1 歴史的経緯
性能は業界のさらなる発展におけるボトルネックとなっている。ブロックチェーンネットワークは個人や企業の取引に新しい、非中央集権的な信頼基盤を創出した。
ビットコインを代表とする第一世代のブロックチェーンネットワークは、分散型台帳として非中央集権的な電子マネー取引の新モデルを確立し、革命的に新たな時代を切り開いた。イーサリアムを代表とする第二世代のブロックチェーンネットワークは想像力を存分に発揮し、「分散型状態機械」によって非中央集権アプリケーション(dApp)を実現することを提唱した。
それ以来、ブロックチェーンネットワークはWeb3インフラからDeFi、NFT、ソーシャルネットワーク、GameFiなどの各種分野に至るまで、十数年にわたり急速に発展し、無数の技術革新やビジネスモデルのイノベーションを生み出してきた。業界の繁栄は、dAppエコシステム構築への新規ユーザー参加を継続的に促すことを求め、それが製品体験にさらに高い要求を突きつけることになる。
Web3は「前例のない」新製品形態であり、ユーザーの機能的要望に応えるだけでなく、安全性と性能のバランス(非機能的要件)も考慮しなければならない。誕生以来、性能問題を解決するためのさまざまなソリューションが提案されてきた。
これらのソリューションはおおむね二つに分けられる。一つはオンチェーン拡張案で、シャーディング(sharding)やDAG(有向非巡回グラフ)など。もう一つはオフチェーン拡張案で、Plasma、ライトニングネットワーク、サイドチェーン、Rollupsなどが含まれる。しかし、これらでもオンチェーン取引の急増に追いついていない。
特に2020年のDeFi Summerや2023年末のビットコインエコシステム内でのインスクリプション爆発以降、業界は「高性能・低手数料」という要求を満たす新たな性能向上策を切実に求めるようになり、こうした背景から並列ブロックチェーンが登場した。

1.2 市場規模
並列EVMナラティブは、並列ブロックチェーン領域において二強対立の競争構図が形成されたことを示している。イーサリアムは取引を逐次処理するため、各取引を順番に一つずつ実行しなければならず、リソース利用率が低い。これを並列処理に変更すれば、性能が飛躍的に向上する。
イーサリアムの競合チェーンであるSolana、Aptos、Suiはいずれも並列処理能力を備えており、エコシステムも良好に発展している。これらのトークン時価総額はそれぞれ450億ドル、33億ドル、19億ドルに達しており、これらは並列非EVM陣営を形成している。これに対し、イーサリアムエコシステムも黙っておらず、EVMを強化する動きが相次ぎ、並列EVM陣営を形成している。
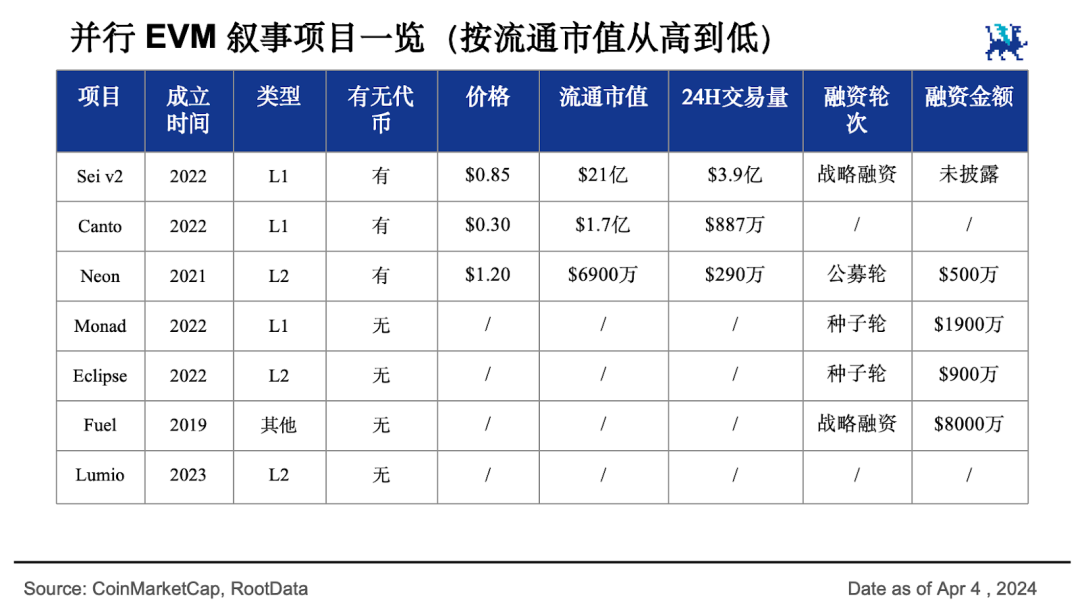
Seiはv2バージョンアップグレード提案で「初の並列EVMブロックチェーン」になると公言し、現在の時価総額は21億ドル。今後さらに大きな発展が期待される。現在マーケティング人気ナンバーワンの並列EVM新パブリックチェーンMonadは資本からの注目も高く、潜在力も侮れない。また、時価総額1.7億ドルで無料の公共インフラを備えたL1チェーンCantoも、自身の並列EVMアップグレード案を発表している。
他にも、まだ初期段階にある多数のL2プロジェクトが、複数のL1チェーンの能力を統合することでクロスエコシステムの性能向上を提供している。Neonが6900万ドルの時価総額を記録したものの、他のプロジェクトはまだ関連データが不足している。今後、より多くのL1およびL2プロジェクトが並列ブロックチェーン戦線に参入することが予想される。
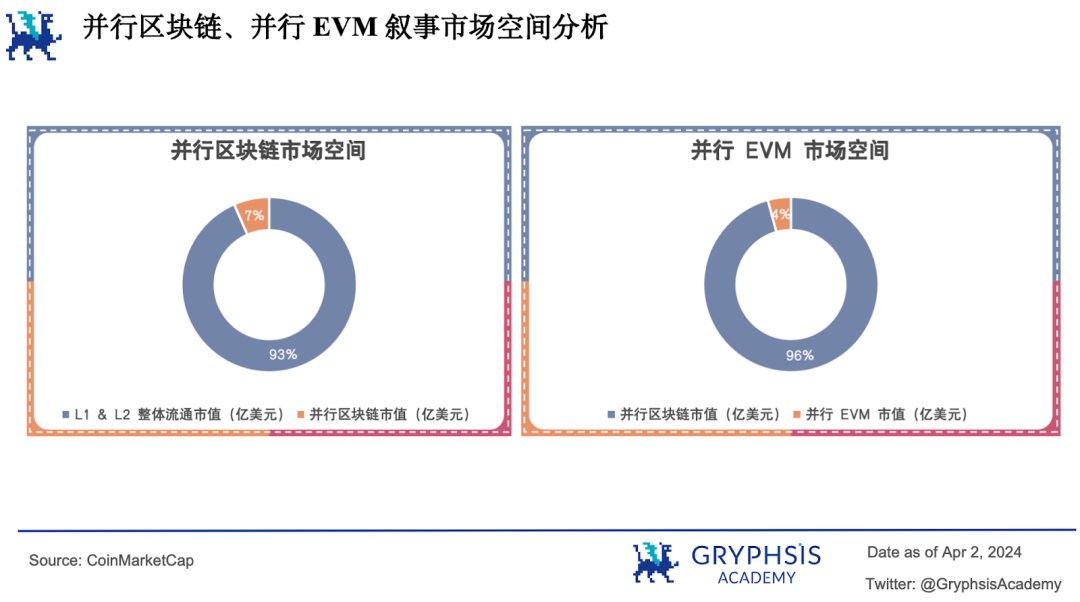
並列EVMナラティブ自体に大きな市場成長余地があるだけでなく、属する並列ブロックチェーンセクター全体にも大きな成長空間があり、市場見通しは明るい。
現在、L1とL2の合計時価総額は7521.23億ドル、並列ブロックチェーンは525.39億ドルで、全体の約7%を占める。そのうち並列EVM関連プロジェクトの時価総額は23.39億ドルで、並列ブロックチェーン全体のわずか4%である。
1.3 業界マップ
業界では一般的にブロックチェーンネットワークを4層構造に分類する:
-
レイヤー0(ネットワーク):ブロックチェーンの基盤ネットワーク。基本的なネットワーク通信プロトコルを処理
-
レイヤー1(インフラ):各種コンセンサスメカニズムに依存して取引を検証する非中央集権ネットワーク
-
レイヤー2(スケーリング):L1に依存する各種第2層プロトコル。L1の制限、特に拡張性の課題を解決することを目的とする
-
レイヤー3(アプリケーション):L2またはL1に依存し、各種dAppの構築に利用
並列EVMナラティブのプロジェクトは、主にモノリシックブロックチェーンとモジュラー型ブロックチェーンに分けられ、モノリシック型はさらにL1とL2に分類される。プロジェクト数や主要分野の発展状況から見ると、並列EVM L1チェーンのエコシステムはイーサリアムエコシステムに比べて依然として大きな発展余地がある。
DeFi分野は「高速・低手数料」を求めており、ゲーム分野は「リアルタイム強いインタラクション」を求めており、どちらも実行速度に一定の要求がある。並列EVMは必然的にこれらのプロジェクトに優れたユーザーエクスペリエンスをもたらし、業界発展を新たな段階へと押し上げることになる。
L1は並列実行能力を備えた新規パブリックチェーンであり、高性能インフラである。この派閥では、Sei v2、Monad、Cantoなどのプロジェクトが独自に並列EVMを設計し、イーサリアムエコシステムとの互換性を保ちながら高スループットの取引処理能力を提供している。
L2は他のL1チェーンの能力を統合し、クロスエコシステム協力によるスケーラビリティを提供する。これはロールアップの主流である。この派閥では、NeonはSolanaネットワーク上のEVMエミュレータであり、EclipseはSolana上で取引を実行し、EVM上で決済を行う。LumioもEclipseと似ているが、実行層をAptosに置き換えている。

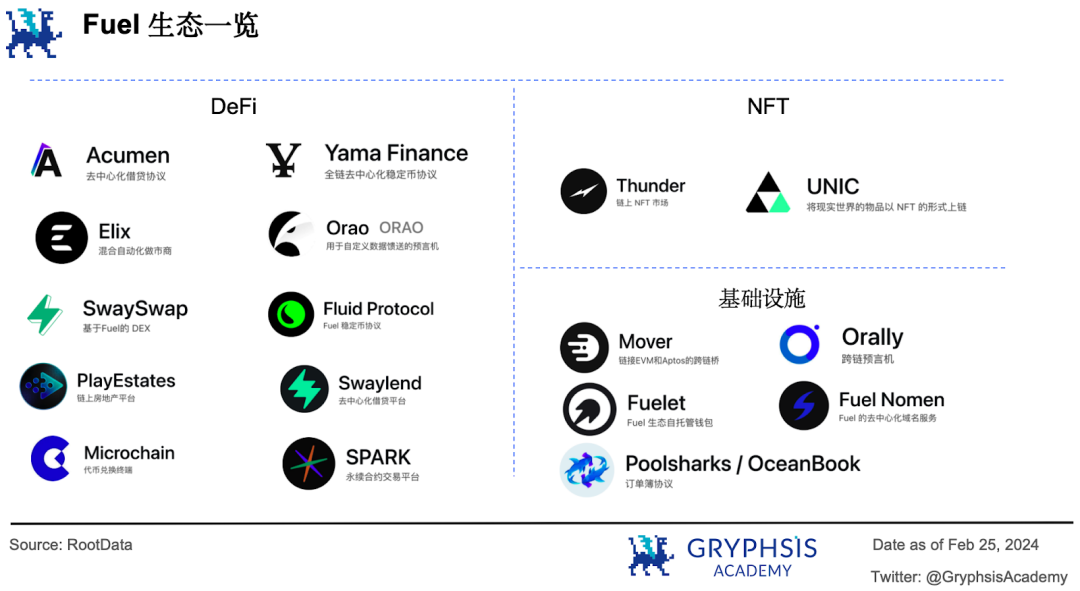
上記のモノリシック型ソリューションに加え、Fuelは独自のモジュラー型ブロックチェーン構想を提示している。同社は第2版で自分自身をイーサリアムロールアップOSと位置づけ、より柔軟で徹底的なモジュラー型実行能力を提供する。
Fuelは取引実行に特化し、他の部分を1つ以上の独立したレイヤーのブロックチェーンにアウトソースすることで、より柔軟な組み合わせを実現する。L2にもL1にも、あるいはサイドチェーンやステートチャネルにもなり得る。現在、Fuelエコシステムには17のプロジェクトがあり、主にDeFi、NFT、インフラの3分野に集中している。
ただし、Orallyのクロスチェーンオラクルのみが実際の運用に入っている。分散型貸借プラットフォームSwaylendと永続契約取引所SPARKはテストネットに上陸しており、他のプロジェクトは開発中である。
2. 技術的実装経路
非中央集権的な取引実行を実現するため、ブロックチェーンネットワークは以下の4つの責務を果たさなければならない:
-
実行:取引の実行と検証
-
データ可用性:新区間をブロックネットワークの全ノードに配布
-
コンセンサスメカニズム:ブロックを検証し、合意を得る
-
決済:取引の最終状態を決済し記録
並列EVMは主に実行層の性能最適化を目的とする。これはレイヤー1(L1)ソリューションとレイヤー2(L2)ソリューションの二種類に分けられる。L1のソリューションは取引の並列実行メカニズムを導入し、仮想マシン内でできるだけ並列に取引を実行させる。L2のソリューションは本質的に既に並列化されたL1仮想マシンを利用して、「オフチェーン実行+オンチェーン決済」というある種の形態を実現する。
したがって、並列EVMの技術原理を理解するには、まず「仮想マシン(virtual machine)」とは何かを理解し、次に「並列実行(parallel execution)」とは何かを理解する必要がある。
2.1 仮想マシン
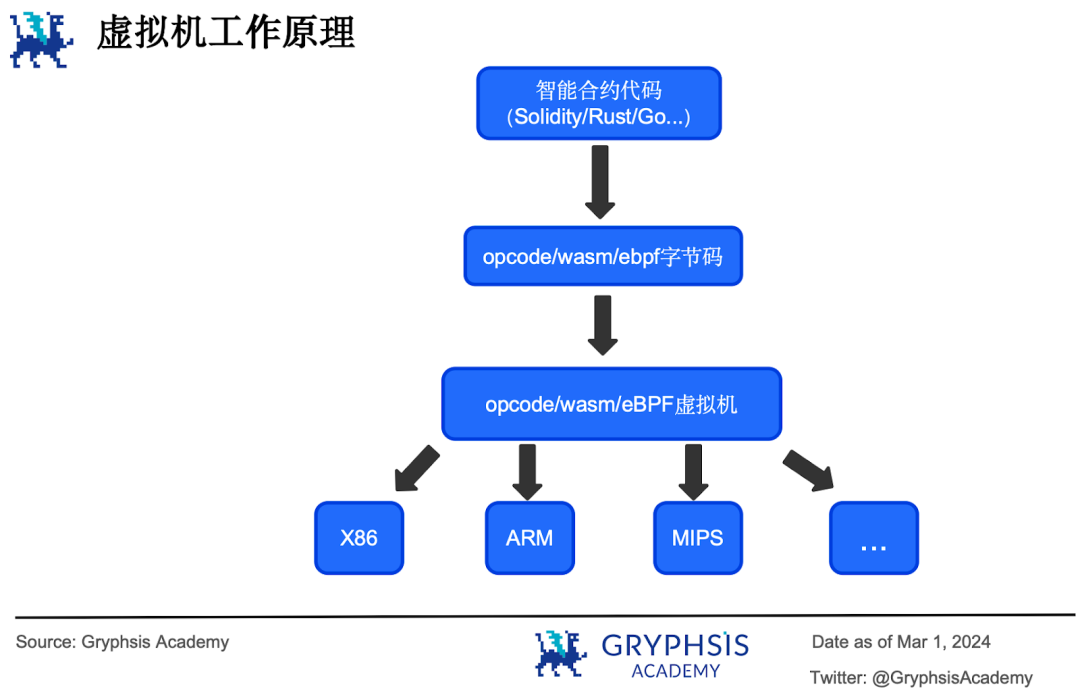
コンピュータ科学において、仮想マシンとはコンピュータシステムの仮想化(virtualization)またはエミュレーション(emulation)を指す。
仮想マシンは二種類に分けられる。一つはシステム仮想マシン(system virtual machine)で、物理マシンを複数の仮想マシンに分割し、複数のオペレーティングシステムを動作させることでリソース利用率を高める。もう一つはプロセス仮想マシン(process virtual machine)で、特定の高水準プログラミング言語に抽象層を提供し、その言語で書かれたプログラムが異なるプラットフォームでプラットフォーム非依存的に動作できるようにする。
JVMはJava言語向けに設計されたプロセス仮想マシンの一例である。Javaで書かれたプログラムはまずJavaバイトコード(中間状態のバイナリコード)にコンパイルされ、JVMがそれを解釈実行する。つまりJVMがバイトコードをインタプリタに渡し、インタプリタがそれを各マシンのマシン語に翻訳して実行する。
ブロックチェーン仮想マシンはプロセス仮想マシンの一種である。ブロックチェーンの文脈では、仮想マシンとは分散状態機械の仮想化を指し、分散的に契約を実行し、dAppを稼働させるために使用される。JVMに類推すれば、EVMはSolidity言語向けに設計されたプロセス仮想マシンであり、スマートコントラクトはまずopcodeバイトコードにコンパイルされ、EVMによって解釈実行される。
イーサリアム以外の新興パブリックチェーンは、WASMやeBPFバイトコードベースの仮想マシンを採用することが多い。WASMはサイズが小さく、読み込みが速く、移植性が高く、サンドボックスセキュリティ機構に基づくバイトコード形式であり、開発者はC、C++、Rust、Go、Python、Java、TypeScriptなど複数の言語でスマートコントラクトを書き、それをWASMバイトコードにコンパイルして実行できる。Seiチェーン上で実行されるスマートコントラクトはまさにこのバイトコード形式を採用している。
eBPFの前身はBPF(Berkeley Packet Filter、バークレー・パケットフィルタ)であり、当初はネットワークパケットの効率的なフィルタリングに使われていたが、進化してeBPFとなり、より豊かな命令セットを備えるようになった。
これはソースコードを変更せずにオペレーティングシステムカーネルに動的に介入し、その挙動を変更できる画期的な技術である。その後、この技術はカーネルから外へ出て、ユーザースペースeBPFランタイムが発展し、高性能、安全、移植性を備えるようになった。Solana上で実行されるスマートコントラクトはすべてeBPFバイトコードにコンパイルされ、ブロックチェーンネットワーク上で動作する。
他のL1チェーンでは、AptosとSuiはMoveスマートコントラクト言語を使用し、独自のバイトコードにコンパイルしてMove仮想マシン上で実行する。MonadはEVM opcodeバイトコード(Shanghai fork)と互換性のある仮想マシンを独自に設計している。
2.2 並列実行
並列実行とは以下のような技術である:
-
マルチコアプロセッサの利点を活かし、複数のタスクを同時に処理してシステムスループットを増大させる。
-
得られる取引結果が、順序通り逐次実行した場合と完全に一致することを保証する。
ブロックチェーンネットワークでは、TPS(1秒あたりの取引処理数)を処理速度の技術指標としてよく使う。並列実行のメカニズムは複雑で、開発者の技術レベルも試されるため、説明は容易ではない。以下では「銀行」の例を使って、並列実行とは何かを説明する。
(1)まず、逐次実行とは何か?
ケース1:システムを銀行に、処理タスクのCPUをカウンターに例えると、逐次実行タスクとは、この銀行が業務を取り扱うカウンターが一つしかない状態。このとき、銀行に来店して業務を依頼する顧客(タスク)は長蛇の列を作り、順番に業務を処理するしかない。各顧客に対して、カウンター職員は同じ動作(命令実行)を繰り返して業務を処理する。自分の番が来るまでは顧客は待機を余儀なくされ、取引時間の延長につながる。
(2)では、並列実行とは何か?
ケース2:銀行は混雑を見て、業務処理のために複数のカウンターを開設し、4人の窓口担当者が同時に業務を処理する。これにより、処理速度は従来の約4倍になり、顧客の待ち時間もおよそ1/4に短縮され、銀行の業務処理速度が向上する。
(3)保護なしの場合、二人が同時に第三者に送金するとどのようなエラーが起きるか?
ケース3:A、B、Cの3人がいて、それぞれの口座残高は2ETH、1ETH、0ETH。今、AとBが同時にCに0.5ETHを送金しようとしている。取引が逐次実行されるシステムでは、何の問題も生じない(左矢印「<=」は台帳の読み取り、右矢印「=>」は台帳への書き込みを表す。以下同様):

しかし、並列実行は見た目ほど簡単ではない。非常に微妙な細部が多く、少し注意を怠ると重大なエラーを引き起こす可能性がある。もしAからCへの送金とBからCへの送金が並列実行された場合、各ステップの実行順序の違いにより、不整合な結果を生む可能性がある:
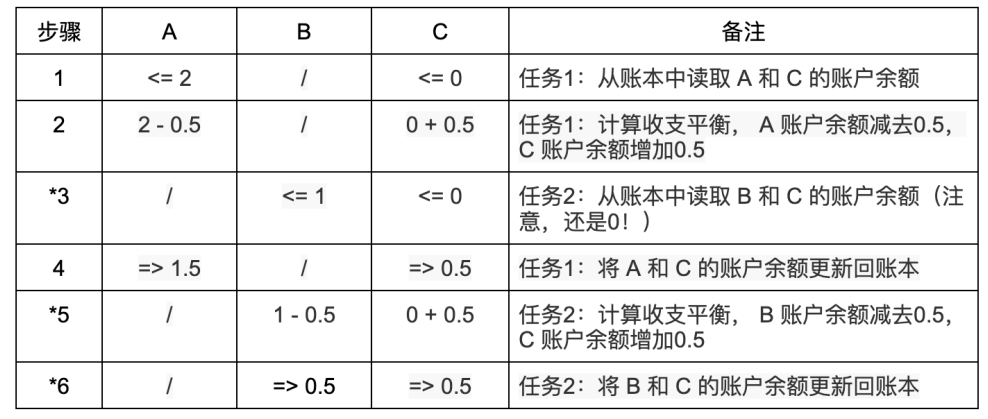
並列タスク1はAからCへの送金を処理し、並列タスク2はBからCへの送金を処理する。表中の*付きステップが問題である。タスクが並列実行されているため、ステップ2で並列タスク1が行った収支計算がまだ台帳に書き込まれていない間に、ステップ3でタスク2がCの口座残高(この時点ではまだ0)を読み取り、ステップ5で残高0を基に誤った収支計算を行い、ステップ6の台帳更新操作でステップ4ですでに更新された残高0.5を再び0.5に誤って上書きしてしまう。その結果、AとBが同時にCに0.5ETHずつ送金したにもかかわらず、取引終了後のCの口座残高は0.5ETHしかなく、もう0.5ETHがどこかへ消えてしまう。
(4)保護なしでも、依存関係のない2つのタスクは並列実行してもエラーにならない
ケース4:並列タスク1はA(残高2ETH)からC(残高0ETH)に0.5ETH送金、並列タスク2はB(残高1ETH)からD(残高0ETH)に0.5ETH送金。両方の送金タスクの間には依存関係がない。したがって、両タスクのステップがどのように交錯しても、上記のような問題は発生しない:

二つのシナリオを比較すると、タスク間に依存関係がある場合、並列実行時に状態更新エラーが発生する可能性があり、逆に依存関係がなければエラーは発生しないことがわかる。以下の条件のいずれかを満たす場合、タスク(取引)間には依存関係があるとされる:
-
あるタスクが書き込む出力アドレスが、別のタスクが読み取る入力アドレスであること。
-
二つのタスクが同じアドレスに出力すること。
これは非中央集権に特有の問題ではない。並列実行に関わるあらゆるシーンでは、依存関係のある複数のタスクが共有リソース(銀行例の「台帳」、コンピュータシステムの共有メモリなど)に保護なしにアクセスすることで、データ不整合が生じ、競合状態(data races)と呼ばれる。
業界では並列実行の競合状態問題を解決するために、メッセージ渡しメカニズム、共有メモリメカニズム、厳密な状態アクセスリストメカニズムの三つの実行メカニズムが提案されている。
2.3 メッセージ渡しメカニズム
ケース5:銀行が4つのカウンターで同時に顧客の業務を処理し、4人の窓口担当者にそれぞれ専用の台帳を配布するとする。この台帳は本人だけが編集可能であり、そこに自分が担当する顧客の口座残高が記録されている。
各担当者が顧客の業務を処理する際、顧客情報が自分の台帳にあればそのまま処理する。そうでなければ、他の担当者に声をかけて業務内容を伝える。他の担当者はそれを聞いて処理を行う。
これがメッセージ渡しモデルの原理である。アクターモデルはメッセージ渡しモデルの一種で、取引処理を担当する各実行者はアクター(担当者)であり、それぞれがプライベートデータ(専用台帳)にアクセスできる。他人のプライベートデータにアクセスしたい場合は、メッセージ送信を通じてのみ可能となる。
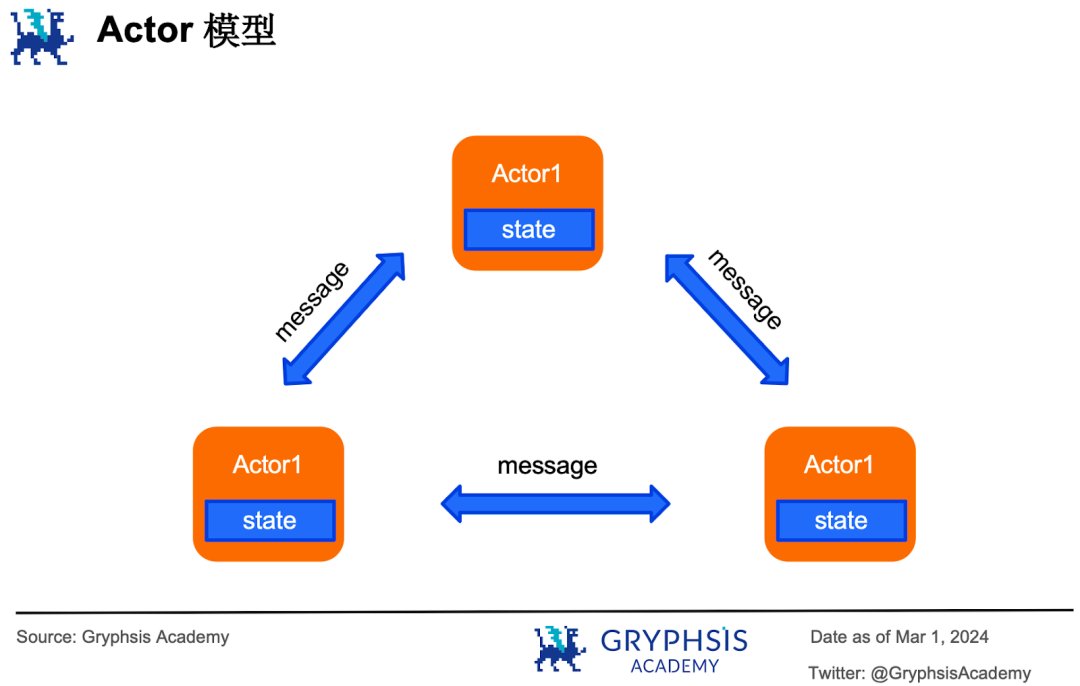
アクターモデルの利点は、各アクターが自分のプライベートデータにのみアクセスできることから、競合状態の問題が発生しない点である。
欠点は二つある。第一に、各アクターは逐次的にしか実行できず、あるシーンでは並列の利点を活かせない(例えば、2番、3番、4番の担当者が同時に1番の担当者に顧客Aの口座残高を問い合わせた場合、このモデルでは1番の担当者が一つずつメッセージを処理しなければならず、本来並列処理可能なはずである)。
第二に、現在のシステム状態に関するグローバルな情報がないため、システムが複雑になると全体像の把握やバグの特定・修復が困難になる。
2.4 共有メモリメカニズム
2.4.1 メモリロックモデル
ケース6:銀行が一つの大きな台帳を持ち、そこにすべての顧客の口座残高が記録されていると仮定する。台帳の横には台帳を編集するためのサインペンが一本だけある。
この状況下では、4人の担当者が業務を処理する際は、誰が速いかにかかっている。一人の担当者が先にサインペンを手にし(ロック)、台帳の編集を開始すると、他の3人は待たなければならない。担当者がペンを置いて(ロック解除)初めて、他の3人がペンの使用権を争奪し、以降これを繰り返す。これがメモリロックモデル(memory locks)である。
メモリロックとは、並列実行タスクが共有リソースにアクセスする際にロック操作を行い、ロック後に共有リソースにアクセスするもの。このとき、他のタスクはロック解除後に再びロックしてアクセスできるようになるまで待機しなければならない。
読み書きロック(read-write lock)はより精緻な処理で、共有リソースに読み取りロック(read lock)または書き込みロック(write lock)をかけることができる。違いは、複数の並列タスクが同時に複数回の読み取りロックをかけ、共有リソースのデータを読み取ることができ(この間、書き換えは禁止)、一方で書き込みロックは一度に一つしかかけられず、ロック保持者だけが排他的にアクセスできることである。
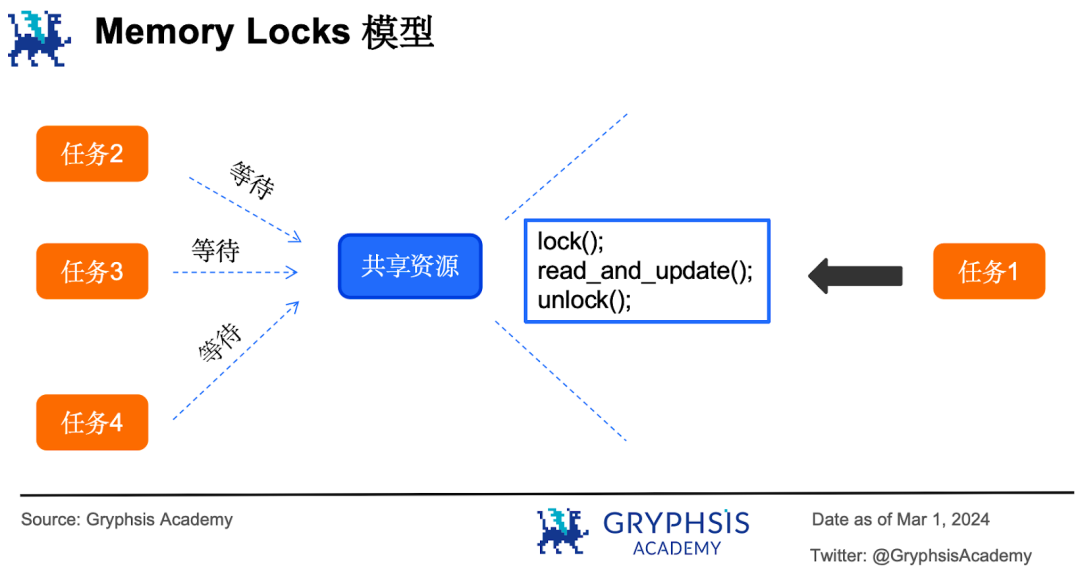
Solana、Sui、Sei v1は、メモリロックに基づく共有メモリモデルを採用している。このメカニズムは一見シンプルだが、実装は非常に複雑で、開発者のマルチスレッドプログラミングのスキルが試される。ちょっとしたミスで、さまざまなバグが発生する:
-
ケース1:タスクが共有リソースをロックするが、処理中にエラーでクラッシュし、共有リソースがロックされたままアクセス不能になる。
-
ケース2:タスクがロックをかけたが、処理中にビジネスロジックの入れ子構造により再ロックがかかり、自分自身を待ってしまう。
メモリロックモデルでは最もデッドロック(dead lock)、ライブロック(live lock)、スタベーション(starvation)といった問題が発生しやすい:
(1)複数の並列タスクが複数の共有リソースを争奪し、それぞれ一部を占有したまま、相手がリソースを解放するのを待ち続けることでデッドロックが発生する。
(2)並列タスクが他の並列タスクがアクティブであることを検出し、自発的に占有している共有リソースを手放すことで、お互いに譲り合い続け、ライブロックが発生する。
(3)優先度の高い並列タスクが常に共有リソースのアクセス権を得られるため、他の低優先度タスクが長期間待機し、「スタベーション」が発生する。

2.4.2 楽観的並列化
ケース7:銀行の4人の担当者が業務を処理する際、他人が台帳を使っているかどうかに関係なく、独立して台帳を参照・編集できる。担当者は台帳を使用する際、参照・編集した箇所に個人専用のラベルを貼る。業務終了後、再度確認し、貼られたラベルが自分のものでなければ、記録が他の担当者によって変更されたことを意味し、今回の業務は無効となり、再処理が必要となる。
これが楽観的並列化の基本原理である。楽観的並列化の核心思想はすべてのタスクが相互に独立していると仮定すること。まず並列実行を行い、その後各タスクを検証し、検証に失敗すればそのタスクを再実行し、すべてのタスクが完了するまで繰り返す。8つの並列タスクが楽観的並列化方式で実行され、途中で2つの共有リソースAとBにアクセスすると仮定する。
フェーズ1の実行時、タスク1、タスク2、タスク3が並列実行される。しかし、タスク2とタスク3が同時に対象リソースBにアクセスし衝突が発生したため、タスク3は次のフェーズで再スケジューリングされる。フェーズ2ではタスク3とタスク4が同時に対象リソースBにアクセスし、タスク4が再スケジューリングされる。以降、すべてのタスクが完了するまで繰り返される。この過程で、衝突が発生したタスクは繰り返し再実行される。
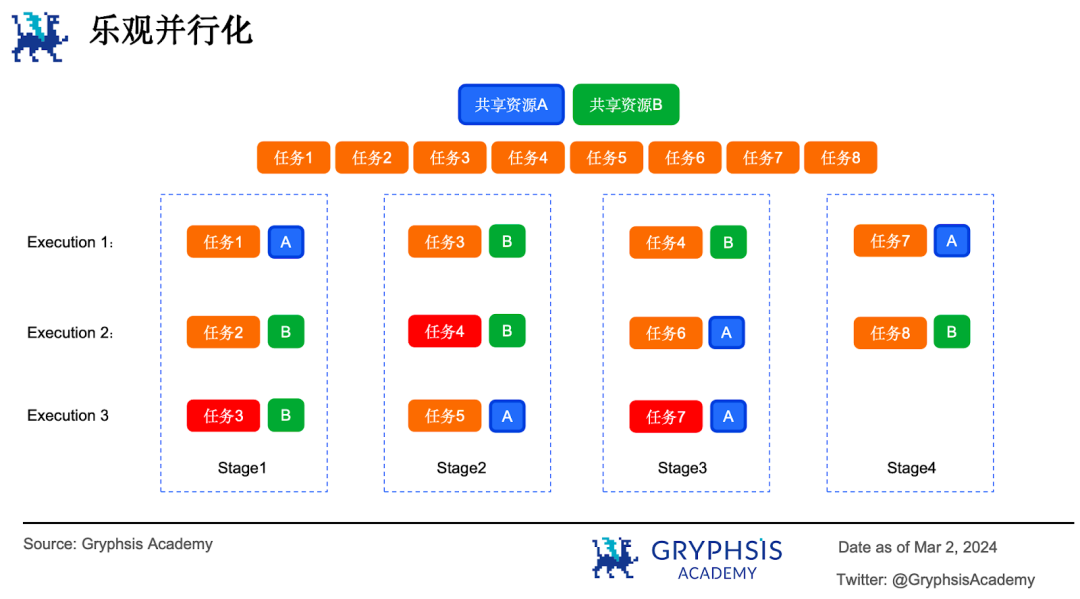
楽観的並列化モデルは、マルチバージョンインメモリデータ構造(multi-version in-memory data structure)を採用し、各書き込み値とそのバージョン情報を記録する(銀行の担当者がラベルを貼るのに似ている)。
各並列タスクの実行は二つのフェーズに分けられる:実行(execution)と検証(validation)。実行フェーズでは、すべての読み取り・書き込み操作を記録し、読み取りセット(read set)と書き込みセット(write set)を形成する。検証フェーズでは、読み取りセットと書き込みセットをマルチバージョンデータ構造と照合し、最新でないことが判明すれば検証失敗となる。
楽観的並列化モデルはソフトウェアトランザクションメモリ(Software Transaction Memory、略称STM)に由来する。STMはデータベース分野のロックフリープログラミング手法の一種である。ブロックチェーンネットワークの取引処理は自然に決定的な順序を持つため、この概念が導入され、Block-STMメカニズムに進化した。AptosとMonadはBlock-STMを自らの並列実行メカニズムとして採用している。
注目に値するのは、Seiチェーンが間もなくリリースするv2バージョンで、従来のメモリロックモデルを廃止し、楽観的並列化モデルに移行することである。Block-STMの実行速度は極めて速く、実験環境下でのAptosの取引処理速度は驚異の16万TPSに達し、逐次実行に比べ18倍高速である。
Block-STMは複雑な取引実行と検証を基盤メカニズムのコアチームに任せ、開発者はまるで逐次実行プログラムを書くように簡単にスマートコントラクトを記述できる。
2.5 厳密な状態アクセスリスト
メッセージ渡しと共有メモリメカニズムはアカウント/残高データモデルに基づいている。これは各チェーン上のアカウントの残高情報を記録するもの。銀行の台帳が顧客Aに1000円、顧客Bに600円の残高を記録し、取引処理のたびにアカウント残高状態を修正するのと同じである。
別の考え方として、取引ごとに取引内容だけを記録し、取引履歴(トランザクションログ)を形成してもよい。取引履歴からユーザーのアカウント残高を算出できる。例えば、以下の取引履歴があるとする:
-
顧客Aが口座開設し1000円預入。
-
顧客Bが口座開設(0円)。
-
顧客Aが顧客Bに100円送金。
この履歴を読み取り計算することで、顧客Aの現在の口座残高は900円、顧客Bは100円であることがわかる。
UTXO(unspent tx output、未使用取引出力)はこのような取引履歴データモデルに似ており、初代ブロックチェーンであるビットコインがデジタル通貨を表現する方法である。各取引には入力(どうやって得たか)と出力(どう使ったか)があり、UTXOは単純に言えばまだ使っていない受取金額と見なせる。
例えば、顧客Aが6BTCを持っており、顧客Bに5.2BTC送金した場合、残り0.8BTCとなる。UTXOの観点からは、Aの6個の価値1BTCのUTXOが破棄され、Bが新たに生成された価値5.2BTCのUTXOを獲得し、Aには0.8BTCの新たなUTXOがお釣りとして与えられる。つまり、6つのUTXOが破棄され、2つの新しいUTXOが生成された。
TechFlow公式コミュニティへようこそ Telegram購読グループ:https://t.me/TechFlowDaily Twitter公式アカウント:https://x.com/TechFlowPost Twitter英語アカウント:https://x.com/BlockFlow_News













