

Googleが多モーダル「切り札」Geminiを投入、果たしてGPT-4を圧倒できるのか?
TechFlow厳選深潮セレクト
Googleが多モーダル「切り札」Geminiを投入、果たしてGPT-4を圧倒できるのか?
Geminiは、複雑なデータの理解や高度なタスクの実行において、GPT-4と強力に競争するだろう。
執筆:木沐
「最大」「最も能力が高い」「最良」「最も効率的」と、グーグルは12月7日に発表したマルチモーダル大規模モデルGeminiに対し、複数の「最」を冠しました。これは明らかにOpenAIのGPT-4と「どちらが優れているか」を競おうとする意図を示しています。
Ultra、Pro、Nanoの3つのサイズに分類されるGeminiは、「AIテスト」で高得点を取ったと称するだけでなく、デモンストレーション動画では文字通り「聞く・話す・読む・書く」すべてをこなす「スーパー・ツール」として描かれています。
公式によれば、Gemini Ultraは最も強力で、マルチモーダル性、専門性、正確性を兼ね備え、テキストや音声での入出力に加えて、数学の宿題の採点、アスリートの動作や筋力の指導、複雑なグラフ作成やコード生成などのタスクも実行可能です。MMLU(大規模多タスク言語理解)テストでは「人間の専門家を超えた」とされています。
ただし、現時点で一般ユーザーが体験できるのはGemini Pro版です。公式の位置付けでは「さまざまなタスクで拡張された最適モデル」とされ、すでにグーグルが以前から提供するチャットボットBardに統合されています。「デバイス上でタスクを実行する最も効率的なモデル」であるGemini Nanoは、グーグルのスマートフォンPixel 8 Proに搭載されます。一方、「最大かつ最も能力が高く、高度に複雑なタスク向け」のGemini Ultraについては、来年初頭に開発者および企業ユーザー向けに提供予定です。
では、Geminiは本当にGPT-4よりも優れているのでしょうか?
ネットユーザーの一部は、グーグルが提示したGemini Ultraの「テスト成績」は自社独自の「試験問題」(評価方法)を使用していることに気づきました。ブルームバーグも指摘するように、Geminiのデモ映像はリアルタイムではなく、編集の痕跡があると感じたユーザーも少なくありません。
『メタバース・デイリー』がBardの数学能力を実際にテストしたところ、このチャットボットには微調整済みのGemini Proモデルが組み込まれていましたが、複雑な数学問題に対して依然として理解ミスがあり、特に画像認識の面で課題が残りました。
グーグルがGeminiの「聞く・話す・読む・書く」能力を披露
Geminiは、グーグルが一から構築したマルチモーダル人工知能モデルです。GPT-4より発表時期が遅れたものの、「最も能力が高い」として外部に発表されており、その「強さ」の象徴がマルチモーダル能力です。
テキスト、画像、音声、動画、コードなど、複数のデータ形式を同時に処理・解析でき、ユーザーはあらゆる形態の情報をGeminiに入力できます。それらを理解するだけでなく、分析や要求に応じたタスク処理も可能になります。
現在Geminiはまだ1.0版ですが、規模によりUltra、Pro、Nanoの3種類に分けられます。Ultra版は極めて複雑なタスク向け、Pro版は多タスク処理に特化、Nano版はモバイル端末向けです。それぞれ異なる用途に応じて設計されており、複数のベンチマークテストでも卓越した性能を示しています。
グーグルが公開したプロモーション動画では、Geminiの非常に高いマルチモーダル能力が紹介されており、視聴すれば驚嘆することでしょう。
「スーパーモデル」Gemini Ultraの裏には、グーグルが公表したテストデータがあります。大規模言語モデル(LLM)の評価に広く使われる32の学術的ベンチマークのうち、30で現行技術水準を上回る性能を記録しています。
Gemini Ultraは、MMLU(大規模多タスク言語理解)テストで90.0%の得点を記録し、「人類の専門家を超えた最初のモデル」と称されています。このテストは数学、物理、歴史、法律、医学、倫理学など57の分野から構成され、世界知識と問題解決能力を測定します。Geminiはテキスト処理やコード生成を含む一連のベンチマークでも、現在の技術水準を上回っています。
MMLUは大規模モデルの言語理解力を評価するもので、初等数学、アメリカ史、コンピュータサイエンス、法律など57分野の選択問題からなり、高校レベルから専門家レベルまでの人間の知識をカバーしており、現在主流の大規模モデルの意味理解評価の一つです。
グーグルが提示したテスト結果から見ると、Geminiは複雑なデータの理解や高度なタスク遂行において、GPT-4に対して強力な競争となるでしょう。
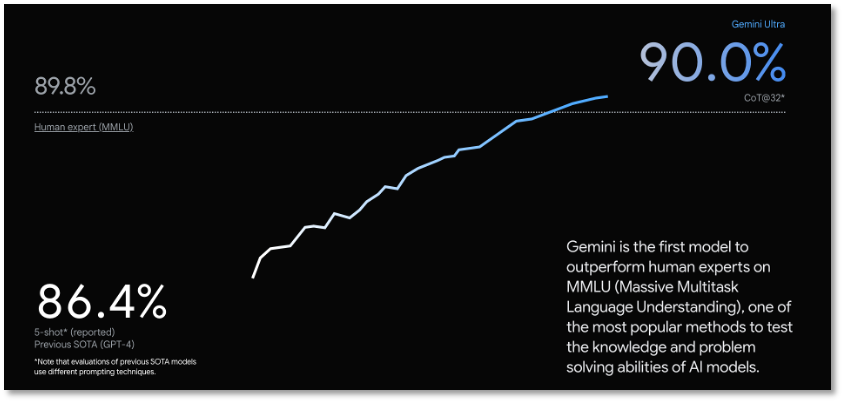
グーグルはGeminiがMMLU評価で初めて人間の専門家を超えました
初めからマルチモーダル訓練に基づいて構築されているため、Gemini Ultraは理論的にはテキスト、画像、音声、動画、コードなどあらゆる形態の情報を理解でき、AIの応用範囲や利用シーンに新たな可能性をもたらします。
例えば教育分野では、Gemini Ultraのマルチモーダル推論能力を使い、乱雑な手書きノートを理解したり、生徒が解く過程でどこで間違えたかを特定し、正しい解答とプロセスを提示できます。これによって教師が完全に不要になるとは言いませんが、少なくとも先生たちには非常に高性能なAIアシスタントが与えられたことになります。
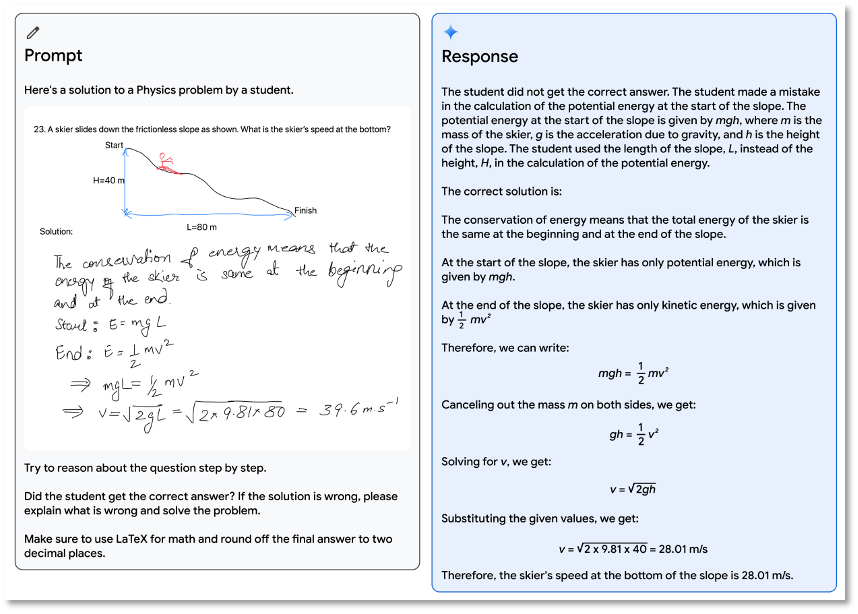
Geminiは生徒の宿題を採点できます
動画の理解と推論において、Gemini Ultraは「サッカー監督」のような素養を見せ、アスリートの動きや筋力の使い方を分析し、具体的な改善提案も行います。

Geminiは動画コンテンツを理解し、アスリートに指導提案を提供できます
複雑な画像理解、コード生成、指示追跡なども、Gemini Ultraにとっては難なくこなせます。画像と以下のプロンプト「左上のサブプロットに描かれた関数を取り、それを1000倍にして、左下のサブプロットに描かれた関数に加算し、matplotlibコードで単一の結果グラフを生成してください」と入力すると、Gemini Ultraは逆グラフィックスタスクを完璧に実行し、グラフ生成コードを推論し、さらに数学変換を行い、関連コードを生成できます。
グーグルが提示したこれらの事例から見ると、Gemini Ultraはまさに「地球上最強」の大規模モデルのように見えます。視聴者の皆さんが最も気になるのは、この大規模モデル界の「超サイヤ人」がいつ使えるようになるか、ということでしょう。
グーグルの発表によれば、12月6日からBardにGemini Proのファインチューニング版が搭載され、より高度な推論、計画、理解などが可能になります。これはBardが発表以来最大のアップデートです。
注意すべき点は、Gemini Proを統合したBardは英語のみの対応であり、世界170以上の国と地域で利用可能ですが、今後さらに異なるモダリティや新しい言語・地域への拡張が予定されています。つまり、中国語ユーザーは現時点ではGemini Proを完全に体験できません。
Gemini NanoはまずグーグルのスマートフォンPixel 8 Proに搭載され、WhatsAppから導入され、来年以降、より多くのメッセージアプリをサポートする予定です。
今後数ヶ月のうちに、GeminiはSearch、Ads、Chrome、Duet AIなど、より多くの製品やサービスにも展開されます。つまり、グーグルの検索エンジンにもGeminiの能力が取り入れられることになります。
そして「最強」とされるGemini Ultraについては、一般ユーザーはもう少し待つ必要があります。グーグルは現在、信頼性と安全性のチェックを行っており、リリース前に人間からのフィードバックによるファインチューニングや強化学習(RLHF)によるさらなる改良が必要だと述べています。
このプロセスにおいて、Gemini Ultraは顧客、開発者、パートナー、セキュリティおよび責任の専門家に限定的に早期実験用として提供され、フィードバックを得た後に来年初頭に開発者および企業顧客向けに開放されます。
UltraのMMLU「試験問題」はグーグル独自版の疑い
最も強力なGemini Ultraを披露しながら、その提供と利用は延期されるというグーグルの対応は、すぐに疑問を呼びました。「本当にGPT-4より優れているのか?」
ブルームバーグは直ちに反論し、グーグルのモデルはOpenAIと比べてまだ差があると指摘。今の能力はデモに限られ、しかもその動画は録画されておりリアルタイムではない。おそらく「精巧に調整されたテキストプロンプトと静止画像」によるものだろうと述べています。また、Geminiの回答は他の情報の補助を必要とし、実際のインタラクションでは非常に暗示的なプロンプトが必要になると指摘しています。
デモ動画を見守っていたネットユーザーも、動画には明確な編集の痕跡があると感じ、「強力な能力には水分がある」との声が上がりました。
また、グーグルがGemini Ultraに適用したMMLU評価について、ネットユーザーはこれが自社独自の「試験問題」ではないかと指摘しています。57科目の選択問題テストで90点を取ったUltraの成績欄には、明確に「CoT@32*」と記載されています。これはグーグル自身が調整した評価方式です。もしGPT-4と同じ基準を採用すれば、その得点は83.7となり、GPT-4の86.4を下回ります。
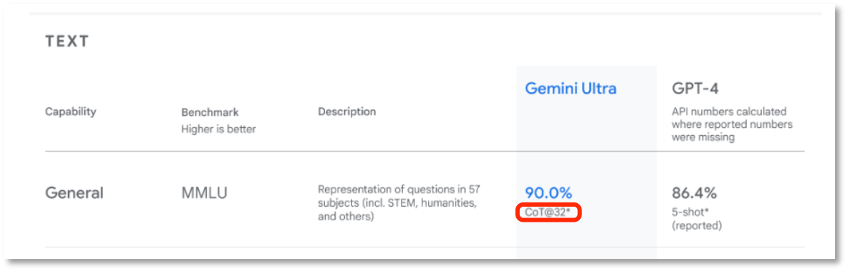
Gemini Ultraはグーグルが調整した評価方式で90点を取得
学術的な話は専門的すぎますが、幸いにもグーグルはすでにGeminiをBardに組み込んでいます。使用されているのはUltraの低仕様版であるProですが、多タスク処理が可能なはずであり、一般大衆がGeminiを直接テストできる最も身近な手段です。
『メタバース・デイリー』は、ChatGPTが数学にあまり強くないことを踏まえ、唯一の正解を持つ数学問題をテストに選びました。OpenAIは数学をAGI達成への基礎と見なしているため、Gemini搭載のBardが数学にどれだけ強いのかを確認してみました。
質問はすべて英語で統一し、問題1は円錐の体積計算、問題2はやや難しい幾何学的証明問題としました。
テスト結果によると、Gemini Proは画像および画像内の文字を正確に認識でき、簡単な数学問題も正しく解けましたが、複雑な数学問題の処理では明らかな誤りがありました。問題2では、Bardが第2ステップでEGとABの二本の線を誤って垂直であると証明しています。
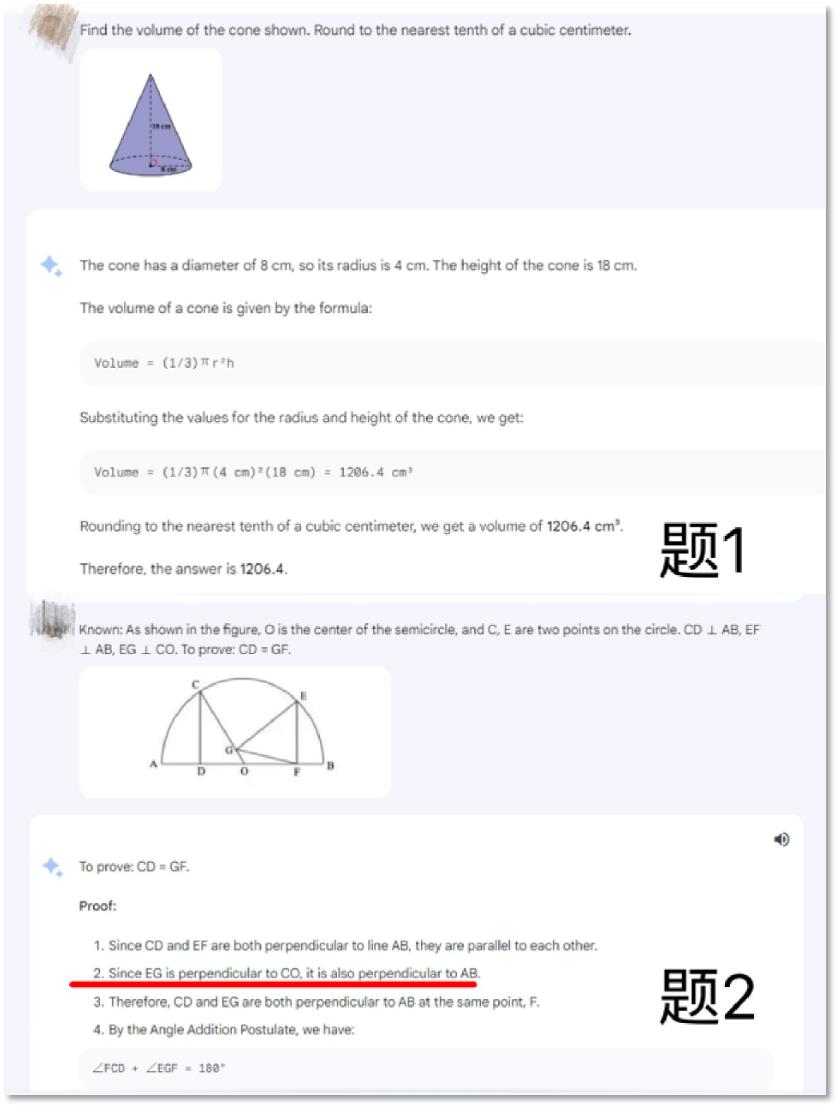
Gemini Pro搭載のBardでも、数学問題の処理はまだ完璧ではありません
これはBardがGemini Proを使用しているために十分に強力ではないからでしょうか?それならば、Ultra版の導入を待って再テストするしかありません。
スマートフォンPixel 8 Proに搭載されるGemini Nanoは、「レコーダー要約」と「Gboardスマートリプライ」の2つの機能に利用されます。
グーグルによれば、スマホがインターネットに接続されていなくても、通話録音、インタビュー、プレゼンテーションなどの内容を要約できます。スマートリプライ機能は電話切断後の自動返信のようなもので、Gemini Nanoが受信メッセージの内容を識別し、適切な返信を生成できます。ただし、これら2つの機能も現時点では英語テキストの認識のみに対応しています。
DeepMindが以前に提唱したAGI評価フレームワークによれば、AGI-1段階では、人工知能は複数の領域やモダリティにまたがって学習・推論ができ、質問応答、要約、翻訳、対話など複数の領域・タスクで知的能力を示し、人間や他のAIと基本的なコミュニケーション・協働ができ、単純な感情や価値観を認識・表現できるようになります。
グーグルの公式発表と実際のテスト体験を総合的に見ると、期待できるのは未だ公開されていないUltra版です。このバージョンのマルチモーダル能力が、デモのように真に発揮されれば、グーグルは自ら定義するAGIに近づくことができるでしょう。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














