

有望な分野の展望:分散型コンピューティング市場(上)
TechFlow厳選深潮セレクト
有望な分野の展望:分散型コンピューティング市場(上)
算力不足は必然となりつつあるが、分散型の計算資源市場は儲かるビジネスになるだろうか?
著者:Zeke, YBB Capital

序論
GPT-3の登場以降、生成AIはその驚異的な性能と広範な応用可能性により、人工知能分野に爆発的な転換点をもたらした。これにより、テクノロジー大手企業が相次いでAI分野へ参入している。しかし、問題も生じている。大規模言語モデル(LLM)の学習および推論には膨大な計算リソースが必要であり、モデルの反復的アップグレードに伴い、計算需要とコストは指数関数的に増加している。GPT-2とGPT-3を例に挙げると、パラメータ数は実に1166倍もの差があり(GPT-2は1.5億、GPT-3は1750億)、GPT-3の単一学習コストは当時のパブリックGPUクラウド価格で最大1200万ドルに達し、これはGPT-2の200倍に相当する。実際に使用される際には、ユーザーの毎回の質問に対して推論処理が必要となるため、年初時点での1300万人の独立ユーザーによるアクセスを想定すると、必要なチップはA100 GPUで3万枚以上に上る。初期投資コストは驚異的な8億ドルに達し、日々のモデル推論費用は約70万ドルと見積もられている。
計算能力の不足と高コストは、AI業界全体が直面する課題となっている。同様の問題は、ブロックチェーン業界にも迫っているように見える。一方では、ビットコインの4度目の半減期とETF承認が目前に迫っており、将来の価格上昇に伴い、鉱業者がハードウェア算力に対して大幅な需要増を見込むだろう。他方で、「ゼロ知識証明」(Zero-Knowledge Proof、略称ZKP)技術は急速に発展しており、Vitalik氏も繰り返し、今後10年間でZKがブロックチェーン分野に与える影響は、ブロックチェーン自体と同等かそれ以上になると強調している。この技術の将来性は高く評価されているものの、ZKは複雑な計算プロセスを伴うため、証明生成時にAIと同様に大量の計算資源と時間を消費する。
予見可能な将来において、計算リソースの不足は避けられないものとなるだろう。その中で、分散型計算市場は有望なビジネスになるのだろうか?
分散型計算市場の定義
分散型計算市場とは、本質的には分散型クラウドコンピューティング分野とほぼ同義である。ただし、個人的には「分散型クラウド」という表現よりも、以下で述べる新規プロジェクトを説明する上で「分散型計算市場」という言葉の方がより適切だと考えている。分散型計算市場はDePIN(Decentralized Physical Infrastructure Networks:分散型物理インフラネットワーク)のサブセットに位置づけられ、空き時間の計算リソースを持つ誰もがトークン報酬を得ながら提供できるオープンな市場の構築を目指すものであり、主にBtoBユーザーおよび開発者層にサービスを提供する。よく知られたプロジェクトとしては、分散型GPUレンダリングネットワークのRender Networkや、分散型P2PクラウドマーケットであるAkash Networkなどが該当する。
以下ではまず基礎概念から説明を始め、その後この分野における三つの新興市場——AGI計算市場、ビットコイン計算市場、ZKハードウェアアクセラレーション市場——の中から特にAGI計算市場について詳しく考察する。残り二つについては、『ポテンシャル市場の展望:分散型計算市場(下)』にて取り上げる予定である。
計算能力の概要
計算能力という概念の起源はコンピュータの誕生にまで遡る。初期のコンピュータは機械装置によって計算タスクを遂行しており、計算能力とはその機械装置の処理能力を指していた。コンピュータ技術の進化とともに、計算能力の概念も変遷を遂げ、現代では通常、CPU、GPU、FPGAなどのハードウェアと、OS、コンパイラ、アプリケーションなどのソフトウェアが協働して発揮する処理能力を意味する。
定義
計算能力(Computing Power)とは、コンピュータまたは他の計算デバイスが一定時間内に処理できるデータ量、または完了できる計算タスクの数を指す。計算能力は通常、コンピュータやその他の計算デバイスの性能を表すものとして用いられ、計算デバイスの処理能力を測る重要な指標である。
計測基準
計算能力は、計算速度、消費電力、精度、並列度など様々な方法で計測できる。コンピュータ分野では、一般的な指標としてFLOPS(1秒あたりの浮動小数点演算回数)、IPS(1秒あたりの命令数)、TPS(1秒あたりのトランザクション数)などが用いられる。
FLOPS(Floating Point Operations Per Second)は、浮動小数点演算(小数点を含む数値の数学的演算で、精度や丸め誤差などを考慮する必要がある)の処理能力を示す。これは1秒間に何回の浮動小数点演算を実行できるかを測るものであり、スーパーコンピュータ、ハイパフォーマンスサーバー、グラフィックスプロセッサ(GPU)などの高性能計算能力を評価する際に用いられる。例えば、あるシステムのFLOPSが1 TFLOPS(1兆回/秒)であれば、それは1秒間に1兆回の浮動小数点演算を実行できることを意味する。
IPS(Instructions Per Second)は、コンピュータが1秒間に処理できる命令の数を示す。これはCPUなどの単一命令性能を評価する指標として使われる。たとえば、あるCPUのIPSが3 GHz(1秒間に30億回の命令を実行可能)であれば、1秒間に30億回の命令を処理できることを意味する。
TPS(Transactions Per Second)は、コンピュータが1秒間に処理できるトランザクション数を示す。これは主にデータベースサーバーの性能評価に用いられる。たとえば、あるデータベースサーバーのTPSが1000であれば、1秒間に1000件のデータベーストランザクションを処理できることを意味する。
その他にも、特定の用途に特化した計算能力の指標が存在する。例えば、推論速度、画像処理速度、音声認識精度などがある。
計算能力の種類
GPU計算能力とは、グラフィックスプロセッシングユニット(Graphics Processing Unit)の処理能力を指す。CPU(Central Processing Unit)とは異なり、GPUは画像や動画などのグラフィカルデータを処理するために専門設計されたハードウェアであり、多数の処理ユニットと高い並列計算能力を持ち、同時に大量の浮動小数点演算を実行できる。当初はゲーム向けのグラフィックス処理のために開発されたため、通常、CPUよりも高いクロック周波数と広帯域のメモリを備えており、複雑なグラフィックス演算をサポートできる。
CPUとGPUの違い
-
アーキテクチャ:CPUとGPUの計算アーキテクチャは異なる。CPUは通常、1つか数個のコアを持ち、各コアは汎用プロセッサとしてさまざまな操作を実行できる。一方、GPUは多数のストリームプロセッサ(Stream Processors)とシェーダー(Shader)を持ち、これらは主に画像処理に関連する演算を実行するために設計されている;
-
並列計算:GPUは通常、より高い並列計算能力を持つ。CPUのコア数は限られており、各コアは一度に1つの命令しか実行できないが、GPUは数千ものストリームプロセッサを持ち、複数の命令を同時実行できる。そのため、機械学習やディープラーニングなど、大量の並列計算を必要とするタスクには、通常GPUの方が適している;
-
プログラミング:GPUのプログラミングはCPUに比べてより複雑であり、CUDAやOpenCLといった特定の言語を使用し、並列計算能力を活かすための特別なプログラミング手法を用いる必要がある。一方、CPUのプログラミングは比較的シンプルで、一般的なプログラミング言語やツールを使用できる。
計算能力の重要性
産業革命の時代、石油は世界の「血液」としてあらゆる産業に浸透していた。そして到来しつつあるAI時代において、計算能力は世界の「デジタル石油」となるだろう。主要企業によるAIチップの争奪戦、NVIDIA株式の時価総額1兆ドル突破、米国による中国向けの先端チップ輸出制限(算力規模、チップ面積に至る詳細な規制)、さらにはGPUクラウド利用の禁止計画まで検討されている現状を考えれば、その重要性は明らかである。計算能力は次の時代におけるコモディティ(商品)となる。

汎用人工知能(AGI)の概要
人工知能(Artificial Intelligence)とは、人間の知能を模倣・拡張・延長するための理論、方法、技術および応用システムを開発する新しい技術科学である。1950~60年代に起源を持ち、記号主義、接続主義、エージェント主義の三つの流れが交錯しながら半世紀以上進化してきた。今日、AGI(Artificial General Intelligence:汎用人工知能)とも呼ばれる生成AIは、多様なタスクや分野において人間と同等あるいはそれを超える知能を発揮できる広範な理解能力を持つAIシステムとして定義される。AGIの実現には、深層学習(Deep Learning:DL)、ビッグデータ、大規模な計算能力の3つの要素が必要とされる。
深層学習
深層学習は機械学習(ML)の一分野であり、アルゴリズムは人間の脳の神経回路を模したニューラルネットワークに基づいている。人間の脳には数百万もの相互接続されたニューロンがあり、これらが協働して情報を学習・処理する。同様に、深層学習のニューラルネットワーク(または人工ニューラルネットワーク)は、コンピュータ内部で協働する複数の人工ニューロン(ノードと呼ばれるソフトウェアモジュール)から構成され、数学的計算を通じてデータを処理する。これらのノードを組み合わせることで、人工ニューラルネットワークは複雑な問題を解決する深層学習アルゴリズムとなる。
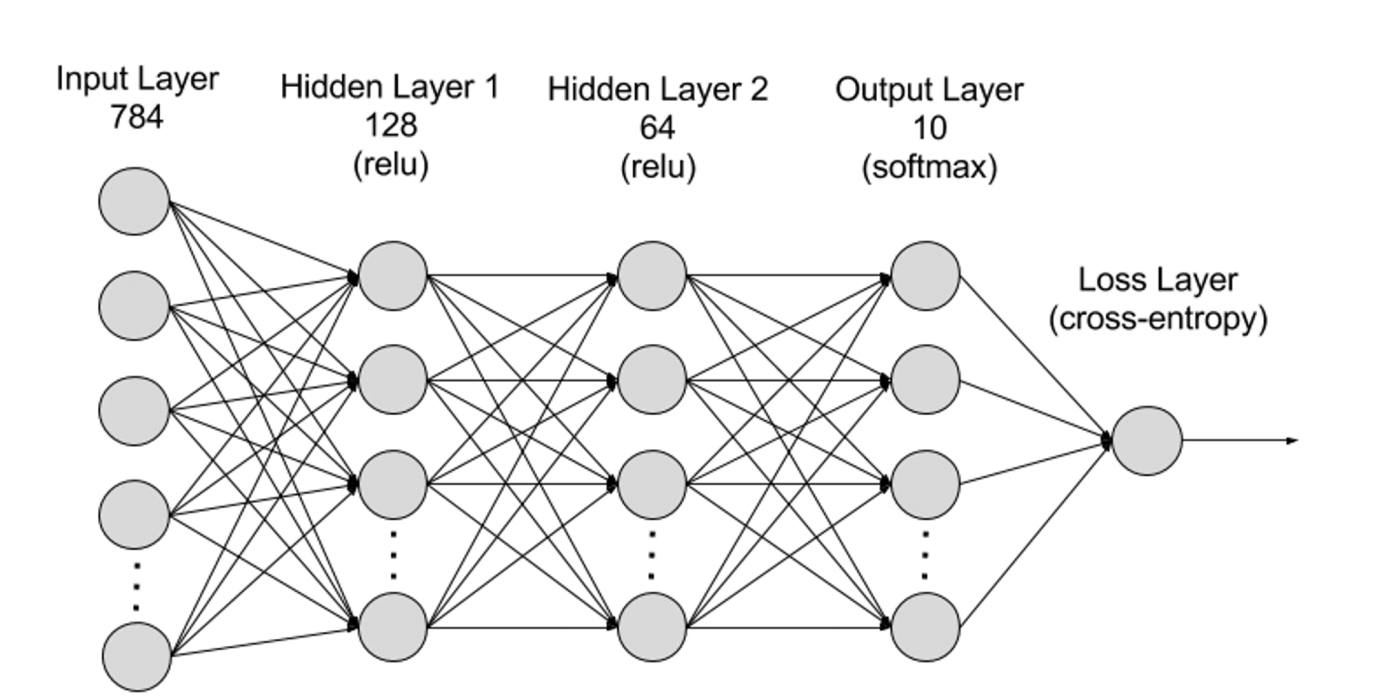
ニューラルネットワークは階層的に入力層、隠れ層、出力層に分けられ、層間の接続は「パラメータ」で表現される。
-
入力層(Input Layer):ニューラルネットワークの最初の層であり、外部からの入力データを受け取る。各ニューロンは入力データの一つの特徴に対応する。たとえば、画像データを扱う場合、各ニューロンは画像の一つのピクセル値に対応する;
-
隠れ層(Hidden Layers):入力層で処理されたデータは、ネットワーク内のさらに深い層へ送られる。隠れ層は複数のレベルで情報を処理し、新たな情報を受けるたびに自身の挙動を調整する。深層学習ネットワークには数百もの隠れ層が存在し、複数の視点から問題を分析できる。たとえば、未知の動物の画像を分類する場合、既知の動物と比較し、耳の形、脚の数、瞳孔の大きさなどを基に判断する。深層ニューラルネットワークの隠れ層も同様に動作する。動物画像の分類を試みる場合、各隠れ層は動物の異なる特徴を処理し、正確な分類を目指す;
-
出力層(Output Layer):ニューラルネットワークの最終層であり、ネットワークの出力を生成する。各ニューロンは可能な出力カテゴリまたは値を表す。たとえば、分類問題では各出力ニューロンが一つのクラスに対応し、回帰問題では出力層は一つのニューロンのみを持ち、その値が予測結果を示す;
-
パラメータ:ニューラルネットワークにおいて、層間の接続は重み(Weights)とバイアス(Biases)というパラメータで表現され、学習中に最適化され、データ内のパターンを正確に識別し予測を行うように調整される。パラメータ数の増加はモデルの容量(複雑なパターンを学習・表現する能力)を高めるが、それに伴い計算能力の要求も高まる。
ビッグデータ
効果的な訓練を行うには、ニューラルネットワークは通常、大量かつ多様で高品質な多源データを必要とする。これは機械学習モデルの訓練と検証の基盤となる。ビッグデータを分析することで、モデルはデータ内のパターンや関係性を学習し、予測や分類を可能にする。
大規模計算能力
ニューラルネットワークの多層構造、大量のパラメータ、ビッグデータ処理の必要性、反復的訓練方式(順伝播・逆伝播の反復計算、活性化関数・損失関数・勾配・重み更新の計算)、高精度演算、並列処理、最適化・正則化技術、モデル評価・検証プロセスなど、多くの要因が高計算能力を必要としている。深層学習の進展に伴い、AGIへの大規模計算能力の要求は年率約10倍ずつ増加している。最新のモデルGPT-4は1.8兆パラメータを有し、単一訓練コストは6000万ドルを超え、必要な計算能力は2.15e25 FLOPS(2京1500兆回の浮動小数点演算)に達する。今後のモデル訓練に対する計算需要はさらに拡大し続け、新しいモデルも継続的に開発されている。
AI計算の経済学
将来の市場規模
最も信頼性の高い調査によると、国際データコーポレーション(IDC)が浪潮情報および清華大学グローバル産業研究院と共同で作成した『2022-2023 Global Computing Power Index Assessment Report』によれば、世界のAI計算市場規模は2022年の195億ドルから2026年には346.6億ドルに成長する見込みである。うち生成AI計算市場は、2022年の8.2億ドルから2026年には109.9億ドルに拡大し、AI計算全体に占める割合は4.2%から31.7%へと上昇する。
計算経済の独占
AI用GPUの製造はNVIDIAが事実上独占しており、非常に高価である(最新H100チップは単体で4万ドルまで高騰)。また、販売開始と同時にシリコンバレーの大手企業が買い占め、一部は自社の新モデル学習に使用している。残りはGoogle、Amazon、Microsoftなどのクラウドプラットフォームを通じてAI開発者に貸し出されている。これらの企業は大量のサーバー、GPU、TPUなどの計算リソースを支配しており、計算能力は巨人企業による新たな独占資源となっている。多くのAI開発者は、価格が吊り上がらない専用GPUさえ入手困難な状況にあり、最新設備を利用するにはAWSやMicrosoftのクラウドサーバーを借りざるを得ない。財務報告によれば、この事業は極めて高い利益率を誇り、AWSのクラウドサービスの粗利益率は61%、Microsoftは72%に達している。

我々はこのような中央集権的な支配を受け入れ、計算リソースに対して72%もの利益率を支払わなければならないのだろうか?Web2時代を支配した巨人たちは、次の時代でも支配を続けるのだろうか?
分散型AGI計算の課題
独占に対抗する手段として、分散化は通常最良の選択肢とされる。既存のプロジェクトから見て、DePINのストレージプロジェクトやRDNRのような空きGPU利用プロトコルで、AGIに必要な大規模計算を実現できるだろうか?答えは否定的である。ドラゴンを倒す道はそう簡単ではない。初期のプロジェクトはAGI計算に特化して設計されておらず、実現可能性に欠ける。計算能力のブロックチェーン化には少なくとも以下の5つの課題がある:
1.作業検証:真に信頼不要な計算ネットワークを構築し、参加者に経済的インセンティブを提供するには、深層学習の計算作業が実際に実行されたことを検証する仕組みが必要である。この問題の核心は、深層学習モデルの状態依存性にある。各層の入力は前の層の出力に依存しており、特定の層だけを検証することは不可能である。つまり、特定の層の作業を検証するには、モデルの開始からその層までのすべての計算を再実行しなければならない;
2.市場:AI計算市場は新興市場であり、供給と需要の不均衡に悩まされる。冷スタート問題に対処するため、供給と需要の流動性は初期段階からある程度一致していなければならない。潜在的な計算供給を獲得するには、参加者に明確な報酬を提供する必要がある。市場は計算作業の追跡と即時支払いの仕組みを備えていなければならない。従来の市場では仲介者が管理や導入を担当し、最低支払い額を設定することで運用コストを抑えるが、この方法では市場拡大に伴うコストが高くなる。わずかな供給しか経済的に捕獲できず、ある閾値に達した時点で成長が止まるというバランス状態に陥る;
3.停止問題:停止問題は計算理論の基本的な問題であり、ある計算タスクが有限時間で終了するか、無限に続くかを判定することに関する。この問題は「決定不能」であり、すべての計算タスクに対してそれが有限時間で停止するかを予測できる一般解法は存在しない。イーサリアムのスマートコントラクト実行も同様の停止問題に直面しており、実行に必要な計算リソース量や合理的时间内に終了するかを事前に確定できない;
(深層学習の文脈では、静的グラフから動的構築・実行への移行により、この問題はさらに複雑になる。)
4.プライバシー:プロジェクト側はプライバシー配慮の設計と開発が不可欠である。多くの機械学習研究は公開データセット上で行えるが、モデル性能を向上させたり特定用途に適合させるには、しばしば独自のユーザーデータでファインチューニングを行う必要がある。この過程では個人データが扱われることもあり、プライバシー保護の要請が生じる;
5.並列化:これが現在のプロジェクトが実現不可能な鍵となる要因である。深層学習モデルは通常、専用アーキテクチャと極低遅延を持つ大規模ハードウェアクラスタ上で並列学習されるが、分散型計算ネットワークのGPU間では頻繁なデータ交換が遅延を引き起こし、最も性能の低いGPUに全体が引っ張られる。信頼できない・不安定な計算源の下で、どのように異種混合並列化を実現するかが必須の課題である。現在有力な方法はTransformerモデル(例:Switch Transformers)を用いた並列化であり、すでに高度な並列特性を持っている。
解決策:分散型AGI計算市場への取り組みはまだ初期段階だが、幸運にも2つのプロジェクトが、分散型ネットワークの合意設計およびモデル学習・推論の実装プロセスに初步的な解決策を提示している。以下ではGensynとTogetherを例に、分散型AGI計算市場の設計手法と課題を分析する。
Gensyn

Gensynは現在開発中のAGI計算市場であり、分散型深層学習計算の諸課題を解決し、現在の深層学習コストを削減することを目指している。Gensynは本質的にPolkadotネットワーク上の第1層プルーフ・オブ・ステークプロトコルであり、スマートコントラクトを通じて「ソルバー」(Solver)に報酬を与え、彼らの空きGPUデバイスを利用して計算を行い、機械学習タスクを実行する。
前述の問題に戻ると、真に信頼不要な計算ネットワークを構築する鍵は、完了した機械学習作業を検証することにある。これは極めて複雑な問題であり、計算複雑性理論、ゲーム理論、暗号学、最適化の境界領域でバランスを取る必要がある。
Gensynが提案するシンプルな解決策は、ソルバーが完了した機械学習タスクの結果を提出し、別の独立した検証者が同じ作業を再実行して結果の正確性を確認するというものだ。これは「単一コピー」と呼ばれる。つまり、元の作業の正確性を検証するために、1回の追加作業だけで済む。しかし、検証者が元の依頼者でない場合、信頼問題が残る。検証者自身が不正かもしれないし、その作業も検証が必要になる。すると、別の検証者がその作業を検証しなければならず、新たな検証者も信頼できない可能性があるため、無限に連鎖するリスクがある。この無限連鎖問題を解決するため、3つのキーコンセプトを統合し、4つの役割からなる参加者システムを構築する。
確率的学習証明(Probabilistic Proof of Learning):勾配ベースの最適化プロセスのメタデータを用いて、作業完了の証明書を構築する。特定の段階をコピーすることで、これらの証明書を迅速に検証でき、作業が適切に完了したことを保証する。
グラフベースのピンポイントプロトコル:多粒度でグラフベースの精確な位置特定プロトコルと、クロスバリデータによる一貫性実行を用いる。これにより、作業の再実行と比較検証が可能となり、最終的にブロックチェーン自体が確認を行う。
Truebitスタイルのインセンティブゲーム:ステーキングとスラッシングを用いてインセンティブゲームを構築し、経済的に合理的なすべての参加者が誠実に行動し、期待されるタスクを遂行するよう促す。
参加者システムは、サブミッター、ソルバー、バリデーター、告発者から構成される。
サブミッター(Submitters):
サブミッターはシステムのエンドユーザーであり、計算対象のタスクを提供し、完了した作業単位に対して支払いを行う;
ソルバー(Solvers):
ソルバーはシステムの主要作業者であり、モデル学習を実行し、バリデーターが検証する証明を生成する;
バリデーター(Verifiers):
バリデーターは非決定性の学習プロセスと決定性の線形計算を結びつける鍵であり、ソルバーの証明の一部を再実行し、距離を予想される閾値と比較する;
告発者(Whistleblowers):
告発者は最後の防衛ラインであり、バリデーターの作業をチェックし、疑義を提起することで多額の報奨金を得ることを望む。
システムの運営
このプロトコルが設計するゲームシステムは8段階からなり、4つの主要参加者役割を含み、タスク提出から最終検証までの全プロセスを完結させる。
-
タスク提出 (Task Submission): タスクは以下の3つの情報から構成される:
-
タスクとハイパーパラメータを記述するメタデータ;
-
モデルバイナリファイル(または基本アーキテクチャ);
-
公開アクセス可能な前処理済みトレーニングデータ。
-
-
タスクを提出するには、サブミッターがタスクの詳細を機械可読形式で指定し、モデルバイナリファイル(または機械可読アーキテクチャ)および前処理済みトレーニングデータの公開場所と共にブロックチェーンに提出する。公開データはAWS S3のようなシンプルなオブジェクトストレージや、IPFS、Arweave、Subspaceなどの分散型ストレージに保存できる。
-
解析(Profiling): 解析プロセスは、学習検証証明のための基準となる距離閾値を決定する。バリデーターは定期的に解析タスクを取得し、学習証明の比較用に変動閾値を生成する。閾値を生成するため、バリデーターは決定論的に学習の一部を実行・再実行し、異なる乱数シードを使用して自身の証明を生成・検証する。このプロセスで、バリデーターは非決定性作業の全体的な期待距離閾値を確立し、ソリューション検証に利用できるようにする。
-
学習(Training): 解析後、タスクはパブリックタスクプール(イーサリアムのMempoolに類似)に入る。ソルバーが選ばれ、タスクを実行し、プールからタスクが削除される。ソルバーはサブミッターが提出したメタデータ、モデル、トレーニングデータに基づいてタスクを実行する。学習中、ソルバーは定期的にチェックポイントを設け、学習プロセス中のメタデータ(パラメータを含む)を保存し、検証者が最適化ステップを可能な限り正確に再現できるようにする。
-
証明生成(Proof generation): ソルバーは周期的にモデル重みまたは更新、およびトレーニングデータセットの対応インデックスを保存し、重み更新に使用されたサンプルを特定する。チェックポイント頻度は、保証の強化またはストレージ節約のため調整可能。証明は「スタック」可能であり、重みの初期化に使用される乱数分布から、または自身の証明で生成された事前学習済み重みから開始できる。これにより、事前学習済みの基礎モデル群(フェイスモデル)を構築し、より具体的なタスクに微調整できるようになる。
-
証明の検証(Verification of proof): タスク完了後、ソルバーはブロックチェーンに完了を登録し、公開場所に学習証明を掲示してバリデーターがアクセスできるようにする。バリデーターはパブリックタスクプールから検証タスクを取得し、証明の一部を再実行し距離計算を行う。ブロックチェーンは(解析段階で計算された閾値とともに)得られた距離を用いて、検証が証明と一致するかを判断する。
-
グラフベースのピンポイントチャレンジ(Graph-based pinpoint challenge): 学習証明の検証後、告発者はバリデーターの作業を再現し、検証作業自体が正しく実行されたかをチェックできる。告発者が検証が誤って実行された(悪意あり/なしに関わらず)と判断した場合、報奨を得るためにコントラクト仲裁に異議を申し立てられる。この報奨はソルバーとバリデーターの預かり金(真正な場合)または宝くじ賞金プール(偽陽性の場合)から支払われ、ブロックチェーン自体が仲裁を実行する。告発者(彼らのケースではバリデーター)は、適切な補償が見込まれる場合にのみ検証・異議申立てを行う。実際には、他の告発者の数(リアルタイムで預かり金を出して異議を申し立てている)に応じてネットワークに出入りする戦略を取ることになる。つまり、告発者数が少ないときにネットワークに入り、預かり金を出し、ランダムにアクティブタスクを選んで検証を開始する。最初のタスク終了後、再びランダムなアクティブタスクを取得し繰り返す。告発者数が支払い閾値を超えるとネットワークから退出(またはハードウェア能力に応じてバリデーターやソルバーに転向)し、状況が逆転するまで待つ。
-
コントラクト仲裁(Contract arbitration):バリデーターが告発者から異議を申し立てられた場合、チェーンとの間で、議論のある操作や入力の位置を特定するプロセスに入る。最終的にチェーンが基本操作を実行し、異議が正当かどうかを判断する。告発者の誠実性を保ち、バリデーターのジレンマを克服するため、定期的な強制エラーと頭奖支払いを導入する。
-
決済(Settlement): 決済プロセスでは、確率的・決定論的検査の結果に基づき参加者に支払いを行う。検証と異議申立ての結果に応じ、異なるシナリオで異なる支払いが行われる。作業が正しく実行され、すべての検査を通過したと判断された場合、実行された操作に応じてソルバーとバリデーターに報酬が支払われる。
プロジェクト評価
Gensynは検証層とインセンティブ層において優れたゲームシステムを設計しており、ネットワーク内の不一致点を特定することで迅速にエラー箇所を特定できる。しかし、現行システムには多くの詳細が欠けている。例えば、報奨・ペナルティが適切かつ参入障壁が高すぎないようなパラメータ設定は可能か?ゲーム内の各環節は極端な状況やソルバーの算力差を考慮しているか?現行のホワイトペーパーには異種並列化の詳細な説明も含まれていない。現時点では、Gensynの実用化は依然として道遠しと言える。
Together.ai
Togetherは大規模モデルのオープンソースに注力し、分散型AI計算ソリューションを提供する企業であり、「誰もがどこでもAIにアクセス・利用できる世界」を目指している。厳密にはブロックチェーンプロジェクトではないが、すでに分散型AGI計算ネットワークにおける遅延問題の解決に初步的な成果を上げている。以下ではTogetherのソリューションのみを分析し、プロジェクト自体の評価は行わない。
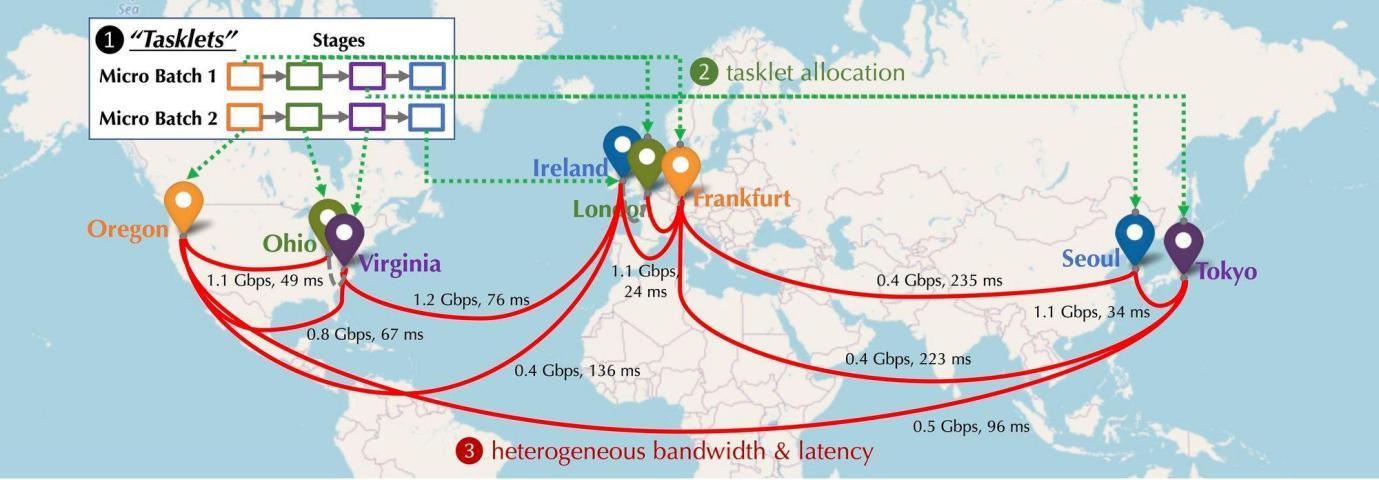
データセンターに比べて100倍遅い分散型ネットワークで、どうやって大規模モデルの学習と推論を実現するのか?
分散環境下で、ネットワークに参加するGPUデバイスはどのように配置されるだろうか?それらは異なる大陸、都市に散在し、デバイス間の接続にはそれぞれ異なる遅延と帯域幅が存在する。下図は北米、欧州、アジアにデバイスが配置された分散環境をシミュレートしたものであり、デバイス間の帯域幅と遅延は異なる。これをどうやって連結すればよいだろうか?
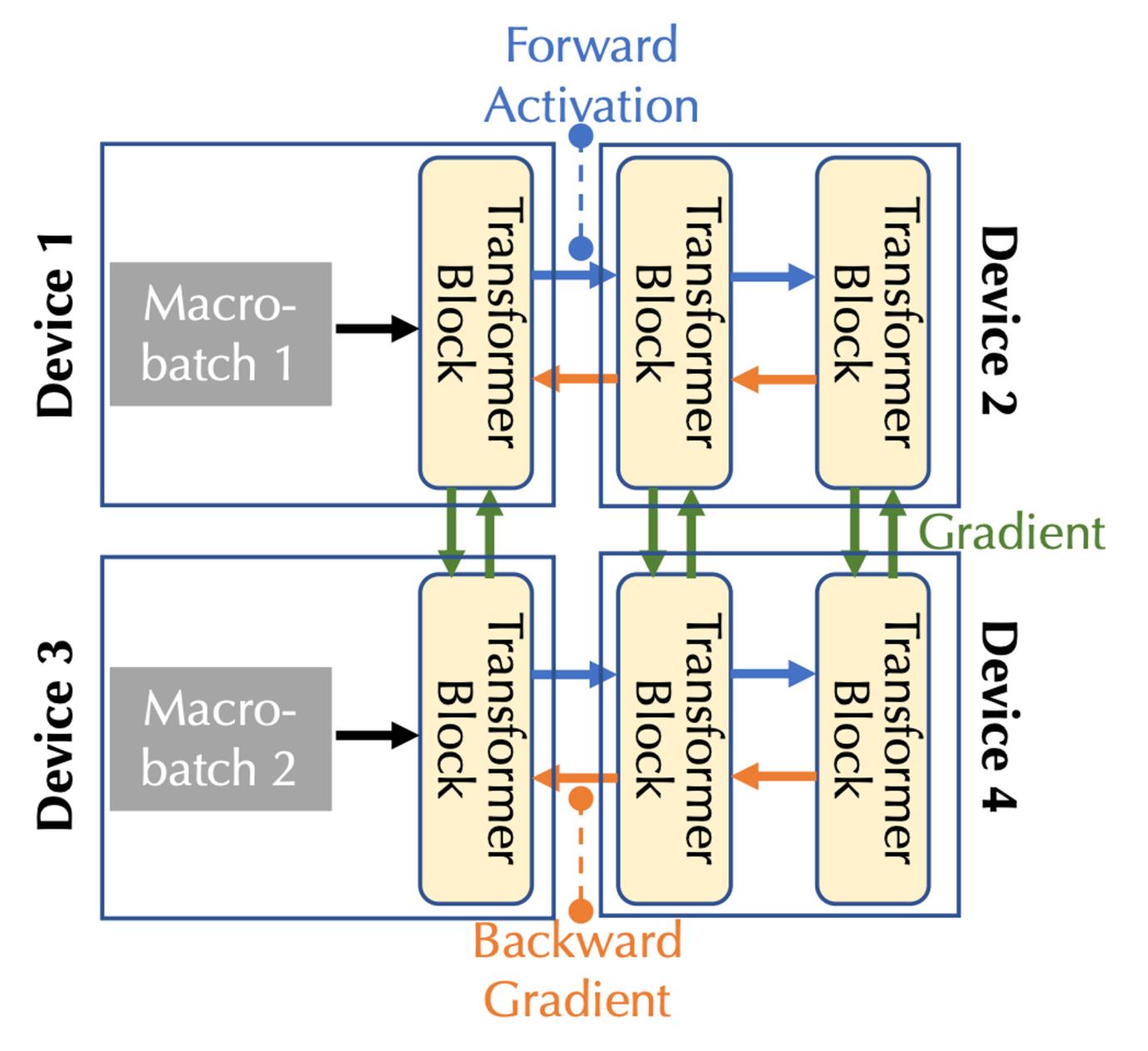
分散型学習計算モデリング:下図は複数のデバイス上で基礎モデルを学習する様子を示しており、通信タイプは順方向活性化(Forward Activation)、逆方向勾配(Backward Gradient)、横方向通信の3種類に分けられる。
通信帯域幅と遅延を考慮すると、パイプライン並列性とデータ並列性の2種類の並列性を考慮する必要がある。これらは多デバイス環境における3種類の通信タイプに対応する:
-
パイプライン並列では、モデルのすべての層が複数の段階に分割され、各デバイスが連続する層の系列(複数のTransformerブロックなど)を処理する。順伝播では活性化が次の段階に渡され、逆伝播では活性化の勾配が前の段階に渡される。
-
データ並列では、デバイスが独立して異なるマイクロバッチの勾配を計算するが、これらの勾配を同期するために通信が必要となる。
スケジューリング最適化:
分散環境では、学習プロセスは通常通信ボトルネックに直面する。スケジューリングアルゴリズムは、大量の通信を必要とするタスクを高速接続のデバイスに割り当てる傾向がある。タスク間の依存関係とネットワークの異種性を考慮し、特定のスケジューリング戦略のコストをモデリングする必要がある。基礎モデル学習の複雑な通信コストを捉えるため、Togetherは新しい数式を提案し、グラフ理論を用いてコストモデルを2つのレベルに分解した:
-
グラフ理論は数学の一分野であり、主にグラフ(ネットワーク)の性質と構造を研究する。グラフは頂点(ノード)と辺(ノードをつなぐ線)から構成される。主な目的は、連結性、彩色、パスやサイクルの性質など、グラフのさまざまな性質を研究することである。
-
第一層は「バランスグラフ分割」(頂点集合を等しいかほぼ等しいサイズのサブセットに分割し、サブセット間の辺の数を最小化する。各サブセットはパーティションを表し、パーティション間の辺を最小化することで通信コストを削減)問題であり、データ並列の通信コストに対応する。
第二層は「結合グラフマッチングと巡回セールスマン問題」(組合せ最適化問題で、グラフマッチングと巡回セールスマン問題の要素を統合したもの。グラフマッチング問題は、コストを最小化または最大化するマッチングを求める。巡回セールスマン問題は、すべてのノードを訪問する最短パスを求める)であり、パイプライン並列の通信コストに対応する。
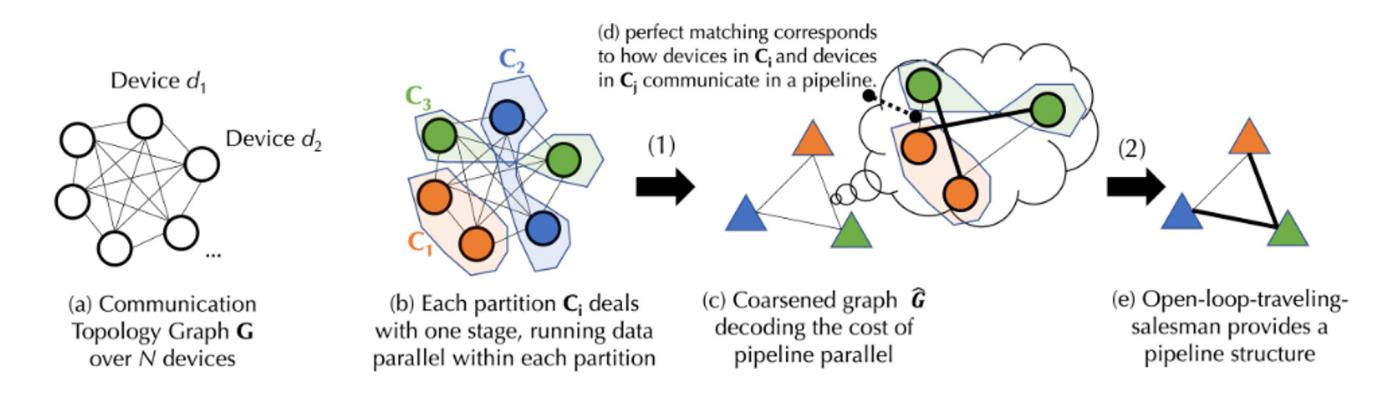
上図はプロセスの概要図である。実際の実装には複雑な数式が含まれるため、以下では図のプロセスを平易に説明する。詳細な実装プロセスはTogether公式サイトのドキュメントを参照されたい。
N台のデバイスからなるデバイス集合Dがあり、その間の通信には不定の遅延(行列A)と帯域幅(行列B)があると仮定する。この集合Dに基づき、まずバランスの取れたグラフ分割を行う。各分割またはデバイスグループ内のデバイス数はほぼ等しく、同じパイプライン段階を処理する。これにより、データ並列時に各デバイスグループがほぼ同量の作業を実行することが保証される。(データ並列とは複数のデバイスが同じタスクを実行すること、パイプライン段階とはデバイスが特定の順序で異なるタスクステップを実行することを指す)。通信の遅延と帯域幅に基づき、数式でデバイスグループ間のデータ転送「コスト」を計算できる。各バランスの取れたデバイスグループを統合し、完全接続の粗いグラフを生成する。各ノードはパイプライン段階を表し、辺は2段階間の通信コストを表す。通信コストを最小化するため、マッチングアルゴリズムを用いてどのデバイスグループが協働すべきかを決定する。
さらに最適化するため、この問題を「オープンループ巡回セールスマン問題」(起点に戻る必要がない)としてモデル化し、すべてのデバイス間でデータ転送する最適パスを求める。最後にTogetherは独自のスケジューリングアルゴリズムを用いて、与えられたコストモデルにおける最適割り当て戦略を見つけ、通信コストを最小化し、学習スループットを最大化する。実測によれば、このスケジューリング最適化により、ネットワークが100倍遅くても、エンドツーエンドの学習スループットはわずか1.7~2.3倍程度しか遅くならない。
通信圧縮最適化:
通信圧縮の最適化に関して、TogetherはAQ-SGDアルゴリズムを導入した(詳細な計算プロセスは論文「Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees」を参照)。AQ-SGDは低速ネットワークでのパイプライン並列学習における通信効率を改善するために設計された、新しい活性化圧縮技術である。従来の活性化値直接圧縮とは異なり、AQ-SGDは同一学習サンプルの異なる時期における活性化値の変化を圧縮する。この独自のアプローチにより、「自己実行」的なダイナミクスが生まれ、学習が安定するにつれて性能が向上すると予想される。AQ-SGDは厳密な理論的分析により、一定の技術条件と有界誤差の量子化関数下で良好な収束率を持つことが証明されている。このアルゴリズムは実用的であるだけでなく、エンドツーエンドの実行時間オーバーヘッドを増加させない(ただし、活性化値の保存に余分なメモリとSSDを必要とする)。一連の分類および言語モデルデータセットでの実験により、AQ-SGDは活性化値を2~4ビットに圧縮しても収束性能を犠牲にしないことが確認された。さらに、最先端の勾配圧縮アルゴリズムと統合することで、「エンドツーエンド通信圧縮」を実現できる。つまり、モデル勾配、順方向活性化値、逆方向勾配を含むすべてのマシン間データ交換を低精度に圧縮し、分散学習の通信効率を大幅に向上させる。集中型計算ネットワーク(例:10 Gbps)で圧縮なしのエンドツーエンド学習性能と比較しても、現状では31%程度の遅延しかない。スケジューリング最適化のデータと併せると、集中型ネットワークとの差はまだあるが、将来的な追いつきの可能性は大きい。
結論
AIブームがもたらす恩恵の期間において、AGI計算市場は間違いなく最も潜在力が大きく、需要も最も高い市場である。しかし、開発難度、ハードウェア要件、資金需要もまた極めて高い。前述の2つのプロジェクトを総合的に見ると、AGI計算市場の実現にはまだ時間がかかり、真の意味での分散型ネットワークは理想状況よりもはるかに複雑であり、現時点ではクラウド巨人と競争できるほどにはなっていない。
本稿執筆中に、いくつかの初期
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














