
Auteur : Jacob Zhao @IOSG
L'intelligence artificielle évolue d'un apprentissage statistique centré sur « l'ajustement de motifs » vers un système de capacités fondé sur la « raisonnement structuré », faisant rapidement monter en importance la phase post-entraînement (Post-training). L'émergence de DeepSeek-R1 marque un retournement de paradigme au niveau du renforcement learning à l’ère des grands modèles. Un consensus s’est dégagé dans le secteur : l'entraînement préalable construit la base des capacités générales du modèle, tandis que le renforcement learning n’est plus seulement un outil d’alignement des valeurs, mais s’avère capable d'améliorer systématiquement la qualité des chaînes de raisonnement et les capacités décisionnelles complexes. Il devient progressivement une voie technologique pour accroître continuellement le niveau d’intelligence.
Parallèlement, Web3 est en train de reconfigurer les rapports de production de l’IA grâce à des réseaux de calcul décentralisés et des mécanismes incitatifs cryptographiques. Les besoins structurels du renforcement learning en matière d’échantillonnage rollout, de signaux de récompense et de formation vérifiable correspondent naturellement aux forces du blockchain en collaboration computationnelle, distribution incitative et exécution vérifiable. Ce rapport analysera systématiquement les paradigmes d'entraînement de l'IA et les principes techniques du renforcement learning, démontrera les avantages structurels du couplage renforcement learning × Web3, et examinera des projets tels que Prime Intellect, Gensyn, Nous Research, Gradient, Grail et Fraction AI.
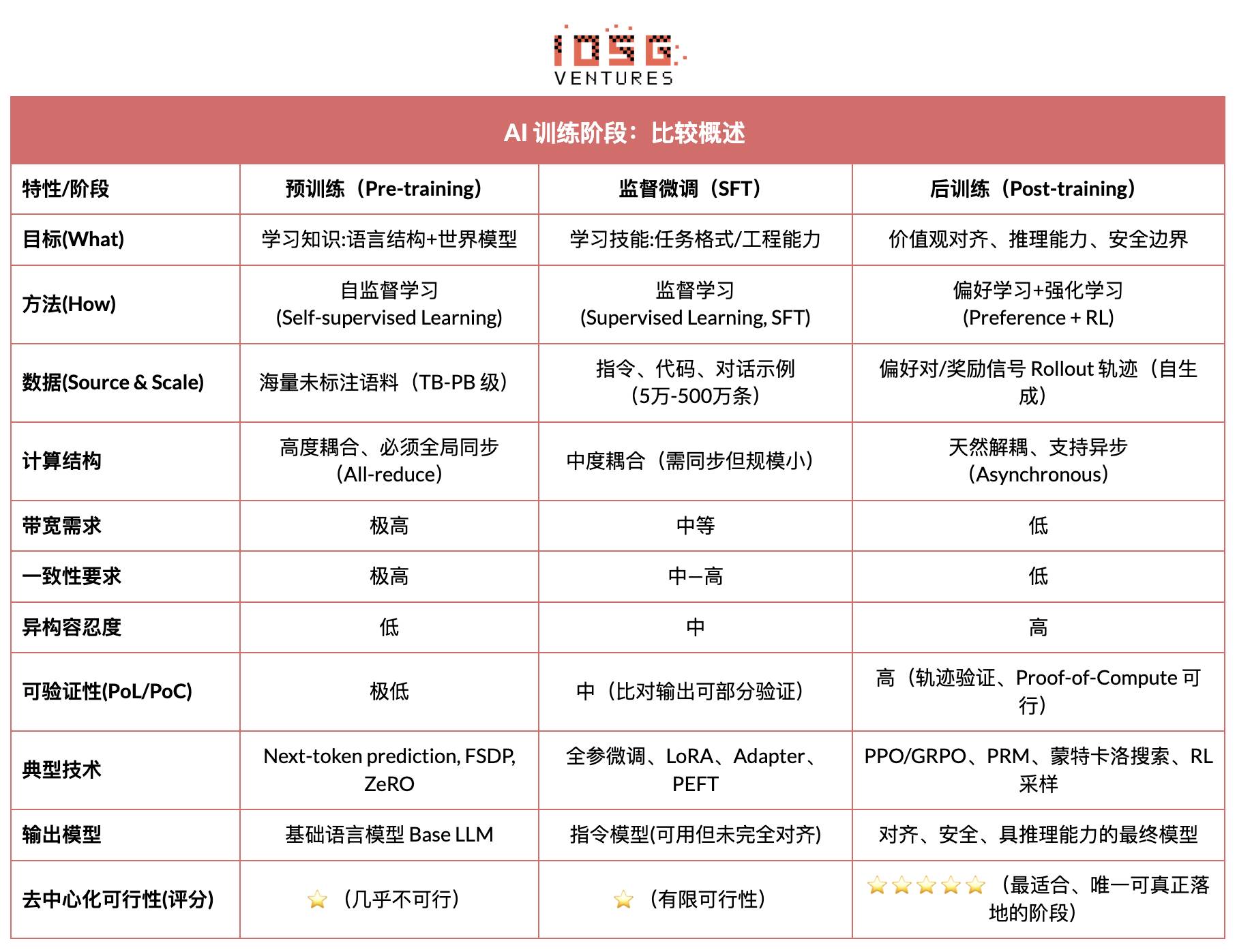
Les trois phases de l’entraînement de l’IA : entraînement préalable, affinement par instructions et alignement post-entraînement
Le cycle complet d’un grand modèle linguistique moderne (LLM) est généralement divisé en trois phases clés : l'entraînement préalable (Pre-training), l'affinement supervisé (SFT) et l'alignement post-entraînement (Post-training/RL). Ces trois étapes assurent respectivement les fonctions suivantes : « construire un modèle du monde — injecter des compétences spécifiques — façonner le raisonnement et les valeurs ». Leur structure de calcul, leurs exigences en données et leur difficulté de validation déterminent leur compatibilité avec la décentralisation.
-
L’entraînement préalable (Pre-training) construit la structure statistique linguistique du modèle et son modèle du monde multimodal via un apprentissage auto-supervisé à grande échelle. C'est la base des capacités du LLM. Cette phase nécessite un entraînement global et synchronisé sur des corpus de plusieurs trillions de tokens, reposant sur des grappes homogènes de milliers à dizaines de milliers de H100. Elle représente 80–95 % des coûts, est extrêmement sensible à la bande passante et aux droits d’auteur, ce qui implique qu’elle doive être réalisée dans un environnement fortement centralisé.
-
L’affinement supervisé (Supervised Fine-tuning) vise à intégrer des compétences spécifiques et des formats d'instructions. Son volume de données et ses coûts sont faibles (environ 5–15 %). Il peut se faire soit par un entraînement complet des paramètres, soit via des méthodes d’affinement efficaces en paramètres (PEFT), telles que LoRA, Q-LoRA ou Adapter, largement utilisées en industrie. Toutefois, il requiert toujours une synchronisation des gradients, limitant ainsi son potentiel de décentralisation.
-
Le post-entraînement (Post-training) comprend plusieurs sous-phases itératives et détermine les capacités de raisonnement, les valeurs et les limites de sécurité du modèle. Ses méthodes incluent notamment les systèmes de renforcement learning (RLHF, RLAIF, GRPO), les approches d’optimisation de préférences sans RL (DPO), ainsi que les modèles de récompense procédurale (PRM). Coût et volume de données y sont faibles (5–10 %), concentrés principalement sur les Rollout et la mise à jour de stratégie. Cette étape supporte naturellement une exécution asynchrone et distribuée, ne nécessitant pas que les nœuds détiennent l’intégralité des poids. Combinée à un calcul vérifiable et à des incitations blockchain, elle permet de former un réseau d’entraînement ouvert et décentralisé, devenant ainsi la phase la plus adaptée à Web3.
Panorama technique du renforcement learning : architecture, cadre et applications
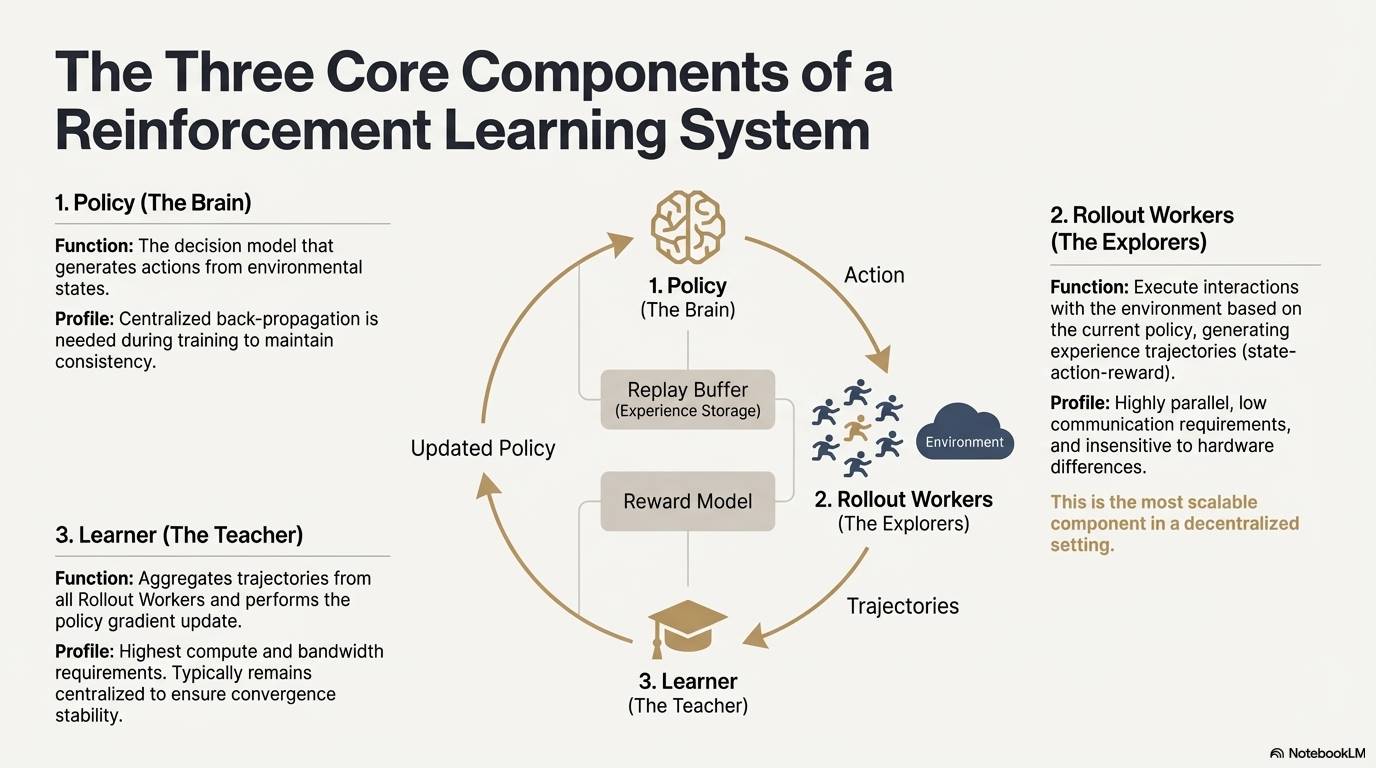
Architecture système et composants clés du renforcement learning
Le renforcement learning (Reinforcement Learning, RL) améliore de manière autonome la capacité décisionnelle du modèle via un cycle « interaction avec l’environnement — retour de récompense — mise à jour de stratégie ». Sa structure centrale forme une boucle de rétroaction constituée d’états, d’actions, de récompenses et de stratégies. Un système RL complet comprend généralement trois types de composants : Policy (stratégie), Rollout (échantillonnage d’expérience) et Learner (mise à jour de la stratégie). La stratégie interagit avec l’environnement pour produire des trajectoires, puis le Learner met à jour la stratégie selon les signaux de récompense, créant ainsi un processus d’apprentissage itératif et optimisé :
-
Réseau de stratégie (Policy) : génère des actions à partir de l’état de l’environnement, constituant le noyau décisionnel du système. Lors de l’entraînement, une rétropropagation centralisée est nécessaire pour assurer la cohérence ; lors de l’inférence, il peut être distribué sur différents nœuds pour un fonctionnement parallèle.
-
Échantillonnage d’expérience (Rollout) : les nœuds exécutent des interactions avec l’environnement selon la stratégie actuelle, générant des trajectoires composées d’états, d’actions et de récompenses. Ce processus hautement parallélisable, peu gourmand en communication et insensible aux différences matérielles, est le mieux adapté à l’extension dans un environnement décentralisé.
-
Apprenant (Learner) : agrège toutes les trajectoires Rollout et effectue la mise à jour du gradient de stratégie. C’est le seul module ayant des exigences élevées en puissance de calcul et en bande passante, donc généralement déployé de façon centralisée ou légèrement centralisée pour garantir la stabilité de convergence.
Phases du renforcement learning (RLHF → RLAIF → PRM → GRPO)
Le renforcement learning peut généralement être divisé en cinq phases, dont le flux global est décrit ci-dessous :
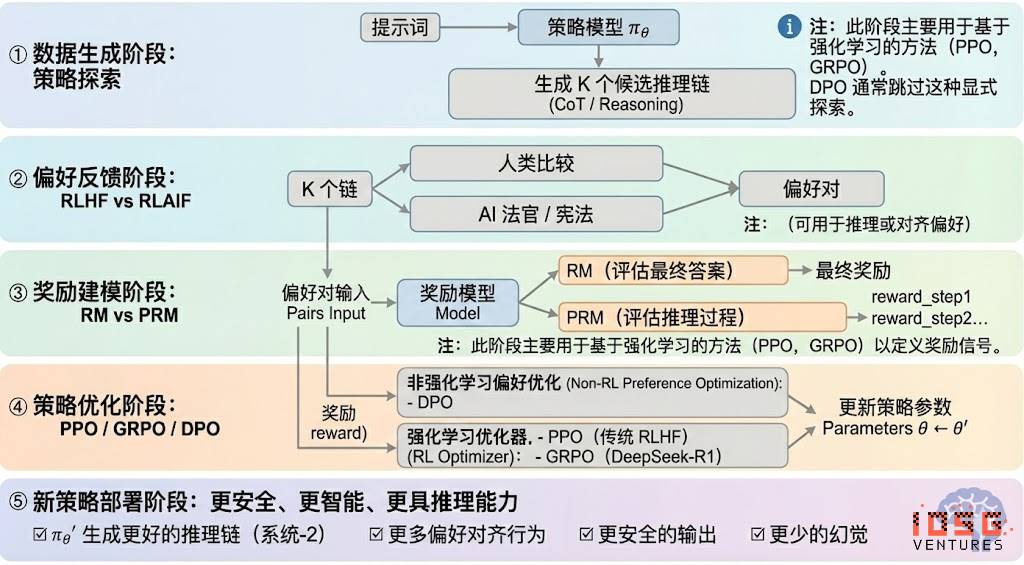
# Phase de génération de données (Exploration de stratégie)
Sous une entrée donnée, le modèle de stratégie πθ génère plusieurs chaînes de raisonnement candidates ou trajectoires complètes, fournissant la base d’échantillons pour l’évaluation des préférences et la modélisation des récompenses, déterminant ainsi l’étendue de l’exploration stratégique.
# Phase de retour de préférence (RLHF / RLAIF)
-
RLHF (Reinforcement Learning from Human Feedback) utilise des réponses multiples annotées manuellement, entraîne un modèle de récompense (RM), puis optimise la stratégie via PPO, rendant la sortie du modèle plus conforme aux valeurs humaines. C’est une étape clé entre GPT-3.5 et GPT-4.
-
RLAIF (Reinforcement Learning from AI Feedback) remplace l’annotation humaine par un juge IA ou des règles constitutionnelles, automatisant ainsi l’acquisition des préférences, réduisant fortement les coûts et permettant une mise à l’échelle. Cette méthode est devenue le paradigme dominant d’alignement chez Anthropic, OpenAI et DeepSeek.
# Phase de modélisation des récompenses (Reward Modeling)
Les paires de préférences alimentent le modèle de récompense, qui apprend à mapper les sorties en scores de récompense. RM enseigne au modèle « quelle est la bonne réponse », tandis que PRM lui enseigne « comment raisonner correctement ».
-
RM (Modèle de Récompense) : évalue la qualité de la réponse finale, attribue uniquement un score à la sortie.
-
Modèle de récompense procédurale PRM (Process Reward Model) : contrairement au RM, il n’évalue pas seulement la réponse finale, mais attribue un score à chaque étape de raisonnement, à chaque token et à chaque segment logique. Cette technologie clé d’OpenAI o1 et DeepSeek-R1 consiste essentiellement à « enseigner au modèle comment penser ».
# Phase de vérification des récompenses (RLVR / Reward Verifiability)
Introduit des « contraintes de vérifiabilité » dans la génération et l’utilisation des signaux de récompense, afin que ceux-ci proviennent autant que possible de règles reproductibles, de faits ou de consensus. Cela réduit les risques de reward hacking et de biais, tout en améliorant l’auditabilité et l’évolutivité dans un environnement ouvert.
# Phase d’optimisation de stratégie (Policy Optimization)
Met à jour les paramètres de stratégie θ selon les signaux fournis par le modèle de récompense, afin d’obtenir une stratégie πθ′ plus performante en raisonnement, plus sûre et plus stable. Les méthodes principales sont :
-
PPO (Proximal Policy Optimization) : optimiseur traditionnel de RLHF, connu pour sa stabilité, mais souvent confronté à une convergence lente et à des instabilités dans les tâches de raisonnement complexes.
-
GRPO (Group Relative Policy Optimization) : innovation centrale de DeepSeek-R1. Il modélise la distribution des avantages au sein d’un groupe de réponses candidates pour estimer la valeur attendue, plutôt que de simplement trier. Cette méthode conserve l’information d’amplitude de récompense, est mieux adaptée à l’optimisation des chaînes de raisonnement et offre une formation plus stable. Considéré comme un cadre majeur après PPO pour les scénarios de raisonnement profond.
-
DPO (Direct Preference Optimization) : méthode de post-entraînement non basée sur le RL. N’engendre pas de trajectoires ni de modèle de récompense, mais optimise directement sur les paires de préférences. Faible coût, résultats stables, largement utilisé pour l’alignement de modèles open source comme Llama et Gemma, mais n’améliore pas les capacités de raisonnement.
# Phase de déploiement de la nouvelle stratégie (New Policy Deployment)
Le modèle optimisé présente désormais : une meilleure capacité de génération de chaînes de raisonnement (raisonnement System-2), des comportements plus conformes aux préférences humaines ou IA, un taux d’hallucinations plus faible et une sécurité accrue. En itérant continuellement, le modèle apprend les préférences, optimise les processus et améliore la qualité des décisions, formant une boucle fermée.
Cinq catégories d'applications industrielles du renforcement learning
Le renforcement learning (Reinforcement Learning) a évolué depuis l’intelligence de jeu pour devenir un cadre central de décision autonome transversal à l’industrie. Selon leur maturité technique et leur déploiement industriel, ses applications peuvent être regroupées en cinq catégories, chacune ayant permis des avancées clés.
-
Jeux et systèmes stratégiques (Game & Strategy) : première application validée du RL. Dans des environnements à « information parfaite + récompense claire » comme AlphaGo, AlphaZero, AlphaStar ou OpenAI Five, le RL a démontré une intelligence décisionnelle comparable, voire supérieure, à celle des experts humains, posant les bases des algorithmes modernes de RL.
-
Robotique et intelligence incarnée (Embodied AI) : le RL permet aux robots d’apprendre la manipulation, le contrôle moteur et des tâches multimodales (ex. RT-2, RT-X) via le contrôle continu, la modélisation dynamique et l’interaction avec l’environnement. Cette technologie clé progresse rapidement vers l’industrialisation.
-
Raisonnement numérique (Digital Reasoning / LLM System-2) : RL + PRM fait passer les grands modèles d’un « mimétisme linguistique » à un « raisonnement structuré ». Exemples marquants : DeepSeek-R1, OpenAI o1/o3, Claude d’Anthropic, AlphaGeometry. L’objectif est ici d’optimiser la récompense au niveau de la chaîne de raisonnement, et non plus seulement d’évaluer la réponse finale.
-
Découverte scientifique automatisée et optimisation mathématique (Scientific Discovery) : le RL explore des espaces de recherche immenses sans étiquettes ni récompenses simples, permettant des percées fondamentales comme AlphaTensor, AlphaDev ou Fusion RL, dépassant parfois l’intuition humaine.
-
Décision économique et systèmes de trading (Economic Decision-making & Trading) : le RL est utilisé pour l’optimisation de stratégies, le contrôle de risques multidimensionnels et la génération de systèmes de trading adaptatifs. Comparé aux modèles quantitatifs classiques, il apprend mieux en environnement incertain, devenant un pilier de la finance intelligente.
Adéquation naturelle entre renforcement learning et Web3
L’adéquation forte entre le renforcement learning (RL) et Web3 découle du fait que les deux sont fondamentalement des « systèmes pilotés par des incitations ». Le RL dépend de signaux de récompense pour optimiser la stratégie, tandis que la blockchain coordonne les participants via des incitations économiques, créant une cohérence mécanique naturelle. Les besoins clés du RL — rollouts massifs hétérogènes, distribution des récompenses et vérification d’authenticité — correspondent précisément aux avantages structurels de Web3.
# Découplage inférence – entraînement
Le processus d’entraînement par RL peut être clairement divisé en deux phases :
-
Rollout (exploration par échantillonnage) : le modèle génère massivement des données selon la stratégie actuelle. Tâche intensive en calcul mais peu communicante, ne nécessitant pas de communication fréquente entre nœuds, idéale pour une génération parallèle sur des GPU grand public répartis mondialement.
-
Update (mise à jour des paramètres) : mise à jour des poids du modèle à partir des données collectées, nécessitant des nœuds centralisés à haute bande passante.
Ce « découplage inférence–entraînement » correspond naturellement à la structure hétérogène des réseaux décentralisés : les Rollout peuvent être externalisés vers un réseau ouvert, rémunérés via des jetons selon la contribution, tandis que la mise à jour du modèle reste centralisée pour garantir la stabilité.
# Vérifiabilité (Verifiability)
ZK et Proof-of-Learning offrent des moyens de vérifier si un nœud a bien exécuté l’inférence, résolvant ainsi le problème de l’honnêteté dans un réseau ouvert. Pour des tâches déterministes comme le code ou les mathématiques, un vérificateur peut confirmer le travail en examinant simplement la réponse, augmentant considérablement la crédibilité des systèmes RL décentralisés.
# Couche incitative : mécanisme de production de feedback basé sur l’économie de jetons
Le mécanisme de jetons de Web3 peut récompenser directement les contributeurs de préférences dans RLHF/RLAIF, dotant ainsi la génération de données préférentielles d’une structure incitative transparente, liquidable et sans permission. Le staking et le slashing permettent de contraindre davantage la qualité du feedback, créant un marché plus efficace et mieux aligné que le crowdsourcing traditionnel.
# Potentiel du renforcement learning multi-agents (MARL)
La blockchain est fondamentalement un environnement multi-agents public, transparent et en évolution continue. Comptes, contrats et agents ajustent constamment leurs stratégies sous l’effet des incitations, ce qui lui donne un potentiel naturel pour servir de terrain d’expérimentation à grande échelle pour le MARL. Bien qu’encore à ses débuts, ses caractéristiques — état public, exécution vérifiable, incitations programmables — offrent des avantages structurels pour le développement futur du MARL.
Analyse des projets emblématiques combinant Web3 et renforcement learning
À partir du cadre théorique ci-dessus, nous analysons brièvement les projets les plus représentatifs de l’écosystème actuel :
Prime Intellect : le paradigme prime-rl de renforcement learning asynchrone
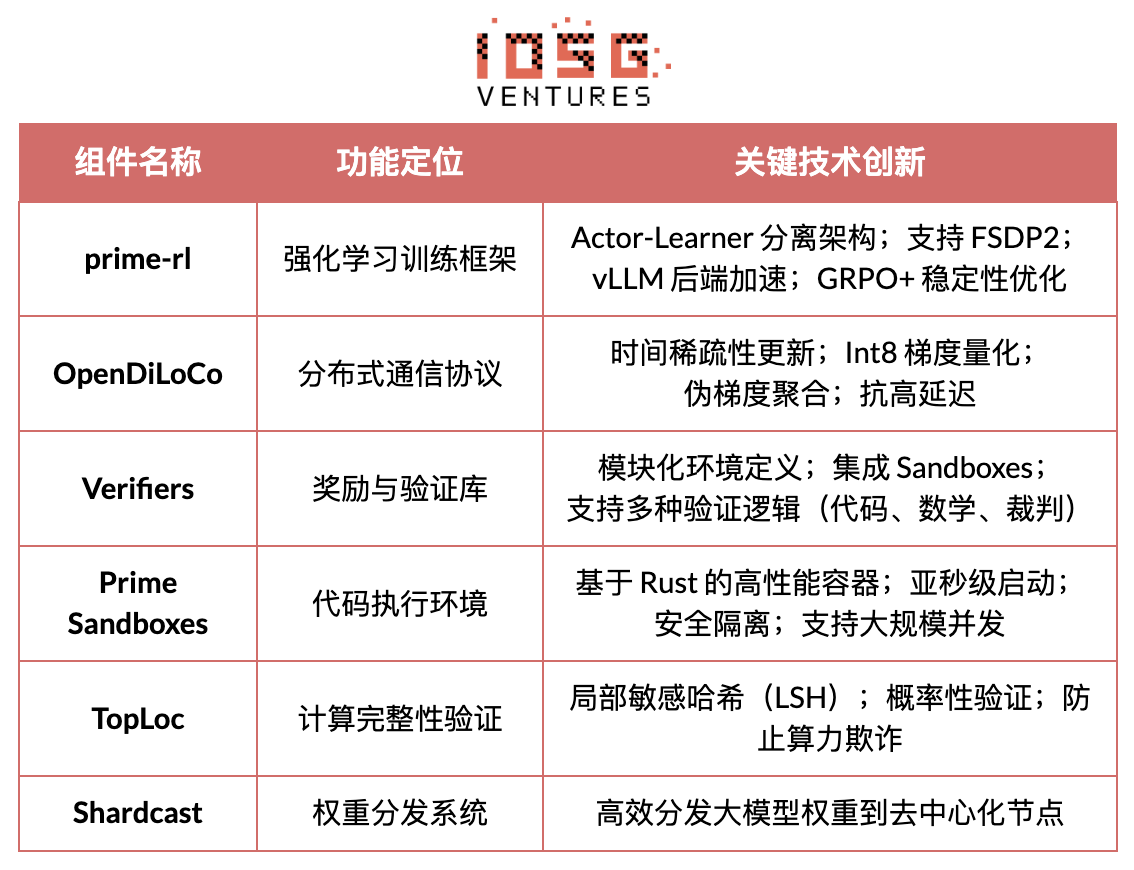
Prime Intellect vise à construire un marché mondial ouvert de puissance de calcul, abaisser les barrières à l’entraînement et promouvoir un entraînement collaboratif décentralisé, tout en développant une pile technologique open source complète pour une superintelligence. Son écosystème inclut : Prime Compute (environnement unifié de calcul cloud/distribué), la famille de modèles INTELLECT (10B–100B+), un centre d’environnements RL ouverts (Environments Hub) et un moteur de données synthétiques à grande échelle (SYNTHETIC-1/2).
Le composant principal de l’infrastructure, le framework prime-rl, est conçu spécifiquement pour les environnements asynchrones et distribués, fortement lié au RL. Il inclut également le protocole OpenDiLoCo (dépassement du goulot d’étranglement de bande passante) et le mécanisme de vérification TopLoc (garantissant l’intégrité du calcul).
# Aperçu des composants clés de l’infrastructure Prime Intellect
# Fondement technique : le framework de renforcement learning asynchrone prime-rl
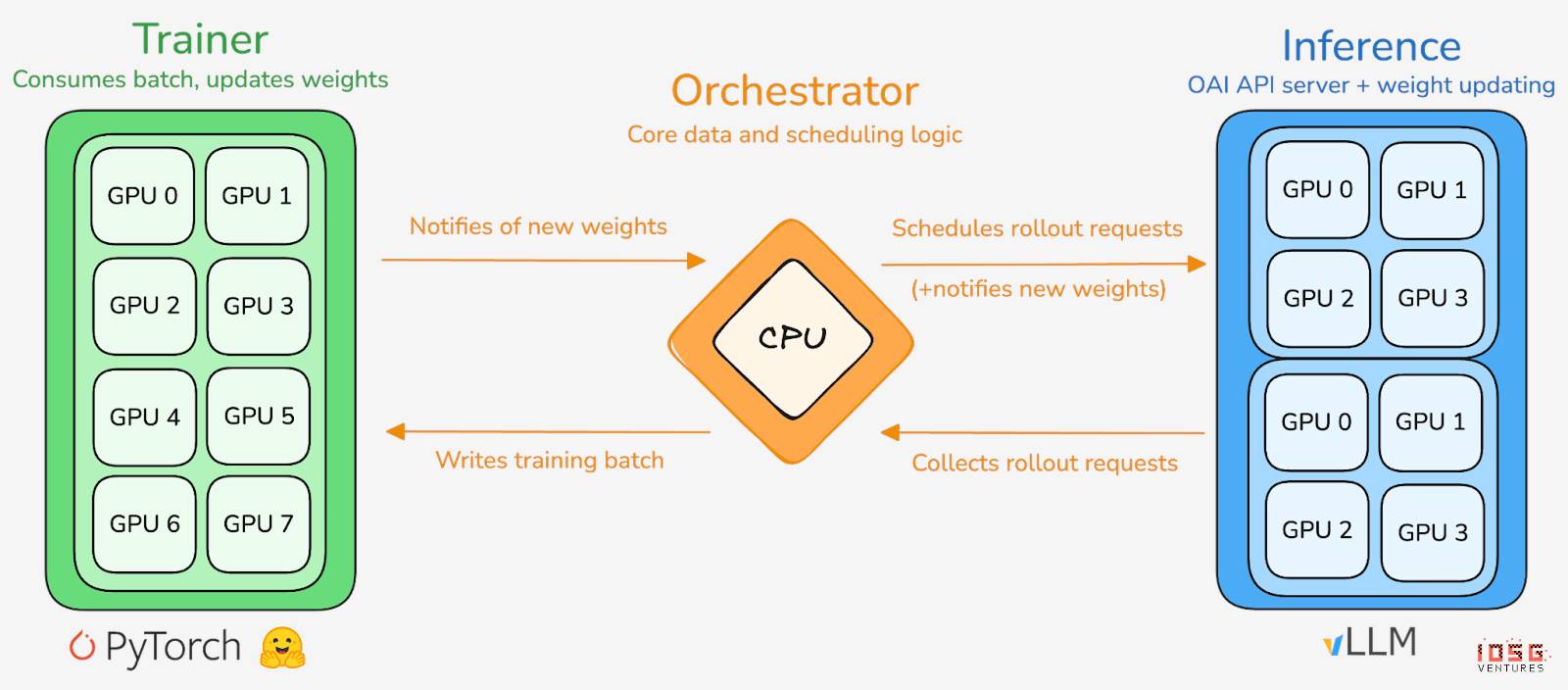
prime-rl est le moteur d’entraînement central de Prime Intellect, conçu pour les environnements massivement asynchrones et décentralisés. Il sépare complètement Actor et Learner pour atteindre un débit élevé et une mise à jour stable. Les exécutants (Rollout Worker) et les apprenants (Trainer) ne sont plus bloqués par synchronisation : les nœuds peuvent rejoindre ou quitter à tout moment, en téléchargeant simplement la dernière stratégie et en envoyant les données générées :
-
Acteur (Rollout Workers) : chargé de l’inférence et de la génération de données. Prime Intellect intègre de manière innovante le moteur d’inférence vLLM côté Acteur. Grâce à PagedAttention et au traitement par lots continu (Continuous Batching), les Acteurs génèrent des trajectoires avec un débit extrêmement élevé.
-
Apprenant (Trainer) : responsable de l’optimisation de stratégie. Le Learner extrait de manière asynchrone des données du tampon d’expérience partagé (Experience Buffer) pour mettre à jour les gradients, sans attendre que tous les Acteurs terminent le lot courant.
-
Orchestrateur (Orchestrator) : gère la planification des poids du modèle et du flux de données.
# Innovations clés de prime-rl
-
Asynchronisme total (True Asynchrony) : prime-rl abandonne le paradigme synchrone traditionnel de PPO, n’attend pas les nœuds lents, n’exige pas d’alignement par lots, permettant à un nombre quelconque de GPU, quelle que soit leur performance, de se connecter à tout moment, rendant ainsi le RL décentralisé viable.
-
Intégration poussée de FSDP2 et MoE : grâce au fractionnement de paramètres FSDP2 et à l’activation creuse de MoE, prime-rl permet un entraînement efficace de modèles à centaines de milliards de paramètres en environnement distribué. L’Acteur exécute uniquement les experts actifs, réduisant fortement la mémoire vidéo et les coûts d’inférence.
-
GRPO+ (Group Relative Policy Optimization) : GRPO élimine le réseau Critic, réduisant nettement les coûts de calcul et de mémoire, s’adaptant naturellement aux environnements asynchrones. La version GRPO+ de prime-rl ajoute un mécanisme de stabilisation pour assurer une convergence fiable même en cas de latence élevée.
# Famille de modèles INTELLECT : indicateur de maturité du RL décentralisé
-
INTELLECT-1 (10B, octobre 2024) a prouvé pour la première fois que OpenDiLoCo pouvait entraîner efficacement sur un réseau hétérogène intercontinental (communication < 2 %, utilisation du calcul 98 %), brisant les limites perçues de l’entraînement géographique.
-
INTELLECT-2 (32B, avril 2025), premier modèle RL Permissionless, a validé la convergence stable de prime-rl et GRPO+ dans des environnements asynchrones avec délais multiples, permettant une participation globale ouverte au RL décentralisé.
-
INTELLECT-3 (106B MoE, novembre 2025) adopte une architecture creuse activant seulement 12B de paramètres, entraîné sur 512×H200, atteignant des performances de raisonnement de niveau phare (AIME 90,8 %, GPQA 74,4 %, MMLU-Pro 81,9 %), rivalisant voire surpassant des modèles centralisés fermés bien plus gros.
Prime Intellect a également construit plusieurs infrastructures complémentaires : OpenDiLoCo, grâce à une communication temporellement creuse et à une quantification des différences de poids, réduit le trafic de communication intercontinental de plusieurs ordres de grandeur, permettant à INTELLECT-1 de maintenir 98 % d’utilisation sur un réseau tri-continental. TopLoc + Verifiers forment une couche d’exécution fiable décentralisée, garantissant l’authenticité des données d’inférence et de récompense via des empreintes d’activation et des sandboxes. Le moteur SYNTHETIC produit massivement des chaînes de raisonnement de haute qualité, permettant à un modèle de 671B de fonctionner efficacement sur des grappes de GPU grand public via un parallélisme en pipeline. Ces composants constituent la base technique indispensable à la génération, vérification et débit d’inférence pour le RL décentralisé. La série INTELLECT démontre que cette pile technologique peut produire des modèles mondiaux matures, marquant la transition du RL décentralisé du concept à la pratique.
Gensyn : la pile centrale de RL, RL Swarm et SAPO
L’objectif de Gensyn est de rassembler la puissance de calcul inutilisée mondiale en une infrastructure d’entraînement IA ouverte, sans confiance et extensible à l’infini. Son cœur inclut une couche d’exécution standardisée inter-appareils, un réseau de coordination pair-à-pair et un système de vérification de tâches sans confiance, avec allocation automatique des tâches et récompenses via des contrats intelligents. Autour des spécificités du RL, Gensyn introduit des mécanismes clés tels que RL Swarm, SAPO et SkipPipe, découplant les phases de génération, d’évaluation et de mise à jour, exploitant une « nuée » de GPU hétérogènes mondiaux pour une évolution collective. Ce qu’il livre n’est pas seulement de la puissance brute, mais une intelligence vérifiable (Verifiable Intelligence).
# Application du stack Gensyn au renforcement learning
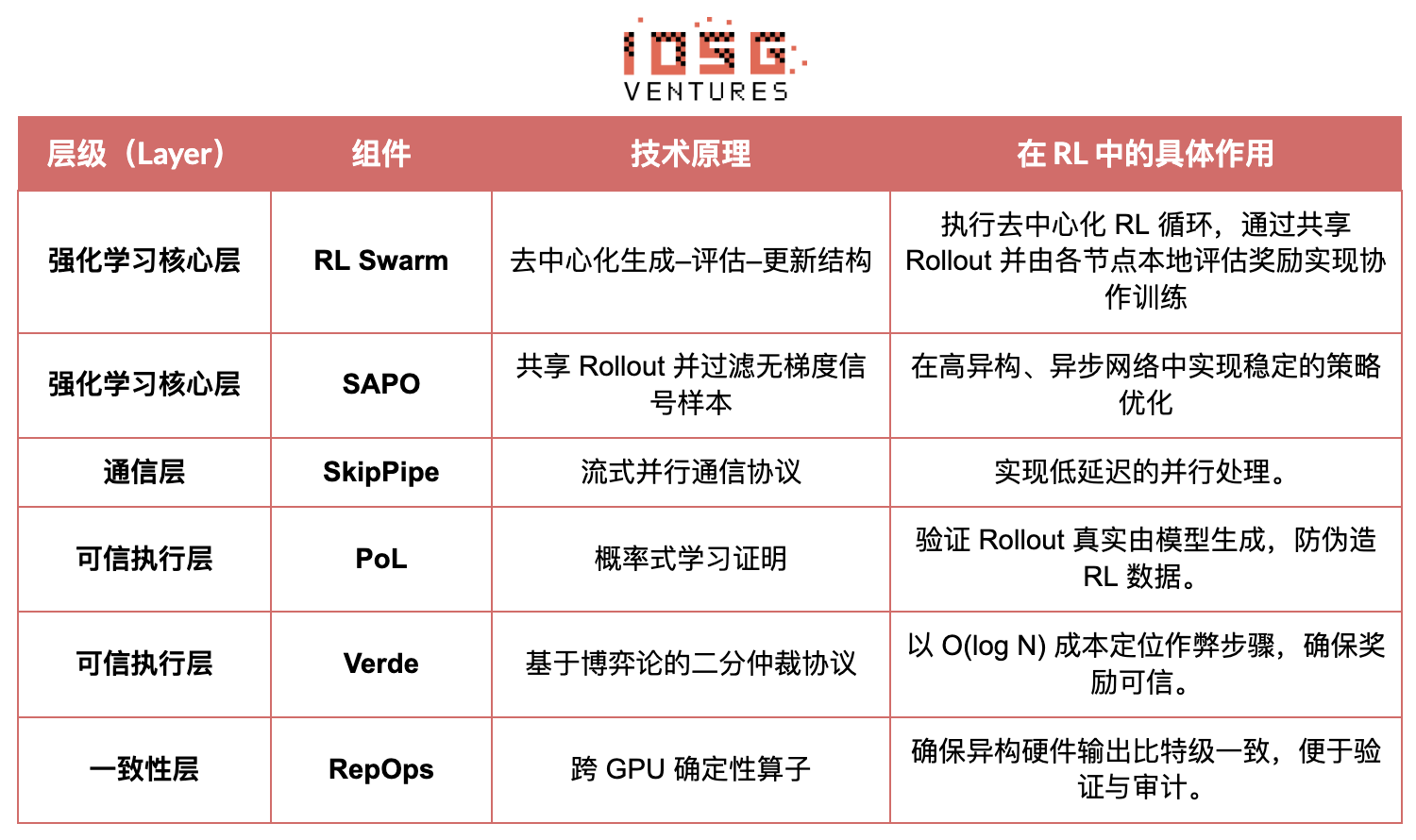
# RL Swarm : moteur de renforcement learning coopératif décentralisé
RL Swarm illustre un nouveau mode de coopération. Ce n’est plus une simple distribution de tâches, mais un cycle décentralisé de type « génération–évaluation–mise à jour », simulant l’apprentissage social humain, en boucle infinie :
-
Solvers (exécutants) : chargés de l’inférence locale et de la génération de Rollout, indifférents à l’hétérogénéité des nœuds. Gensyn intègre localement un moteur d’inférence à haut débit (ex. CodeZero), produisant des trajectoires complètes, pas seulement des réponses.
-
Proposers (proposants) : génèrent dynamiquement des tâches (problèmes mathématiques, questions de code, etc.), soutenant la diversité des tâches et une adaptation progressive de difficulté similaire à un Curriculum Learning.
-
Evaluators (évaluateurs) : utilisent un « modèle-juge » gelé ou des règles pour évaluer localement les Rollout, produisant des signaux de récompense locaux. Le processus d’évaluation est auditables, réduisant les possibilités de malveillance.
Les trois forment ensemble une structure RL pair-à-pair, capable d’apprentissage coopératif à grande échelle sans orchestration centralisée.
# SAPO : algorithme d’optimisation de stratégie reconstruit pour la décentralisation
SAPO (Swarm Sampling Policy Optimization) repose sur le principe de « partager les Rollout et filtrer les échantillons sans signal de gradient, plutôt que de partager les gradients ». Grâce à un échantillonnage massif et décentralisé de Rollout, et en traitant les Rollout reçus comme générés localement, SAPO maintient une convergence stable même dans des environnements sans coordination centrale et avec des retards importants. Contrairement à PPO (coûteux en Critic) ou GRPO (basé sur l’estimation relative), SAPO permet à des GPU grand public de participer efficacement à l’optimisation RL à très faible bande passante.
Grâce à RL Swarm et SAPO, Gensyn démontre que le renforcement learning (notamment la phase RLVR post-entraînement) s’adapte naturellement à une architecture décentralisée — car il dépend davantage d’une exploration massive et diversifiée (Rollout) que d’une synchronisation fréquente des paramètres. Combiné aux systèmes de vérification PoL et Verde, Gensyn propose une alternative à l’entraînement de modèles de trillion de paramètres, ne dépendant plus d’un géant technologique unique : un réseau super-intelligent auto-évolutif composé de millions de GPU hétérogènes à travers le monde.
Nous Research : environnement de RL vérifiable Atropos
Nous Research construit une infrastructure cognitive décentralisée et auto-évolutive. Ses composants clés — Hermes, Atropos, DisTrO, Psyche et World Sim — forment un système d’évolution intelligente en boucle fermée continue. Contrairement au flux linéaire traditionnel « pré-entraînement–post-entraînement–inférence », Nous utilise des techniques de RL comme DPO, GRPO et l’échantillonnage par rejet pour unifier la génération, la vérification, l’apprentissage et l’inférence en une boucle de rétroaction continue, créant ainsi un écosystème IA capable de s’améliorer en permanence.
# Aperçu des composants de Nous Research

# Couche modèle : Hermes et l’évolution des capacités de raisonnement
La série Hermes constitue l’interface principale de Nous Research auprès des utilisateurs. Son évolution reflète clairement la migration du secteur de l’alignement SFT/DPO traditionnel vers le RL de raisonnement (Reasoning RL) :
-
Hermes 1–3 : alignement par instructions et premières capacités d’agent. Hermes 1–3 utilisent un DPO à faible coût pour un alignement robuste, avec Hermes 3 intégrant des données synthétiques et le mécanisme de vérification Atropos pour la première fois.
-
Hermes 4 / DeepHermes : inscrit la « lente réflexion » (System-2) dans les poids via des chaînes de pensée, améliore les performances en maths et code via Test-Time Scaling, et s’appuie sur « échantillonnage par rejet + vérification Atropos » pour construire des données de raisonnement hautement pures.
-
DeepHermes adopte ensuite GRPO à la place de PPO, difficile à déployer de façon distribuée, permettant au RL de raisonnement de fonctionner sur le réseau GPU décentralisé Psyche, posant les bases techniques de l’évolutivité du RL de raisonnement open source.
# Atropos : environnement de renforcement learning piloté par des récompenses vérifiables
Atropos est le véritable pivot du système RL de Nous. Il encapsule les prompts, appels d’outils, exécution de code et interactions multiples dans un environnement RL standardisé, capable de vérifier directement la justesse des sorties, fournissant ainsi des signaux de récompense déterministes, remplaçant les annotations humaines coûteuses et non évolutives. Plus important encore, dans le réseau d’entraînement décentralisé Psyche, Atropos joue le rôle d’« arbitre », vérifiant si les nœuds améliorent réellement la stratégie, prenant en charge un Proof-of-Learning vérifiable, résolvant fondamentalement le problème de crédibilité des récompenses dans le RL distribué.
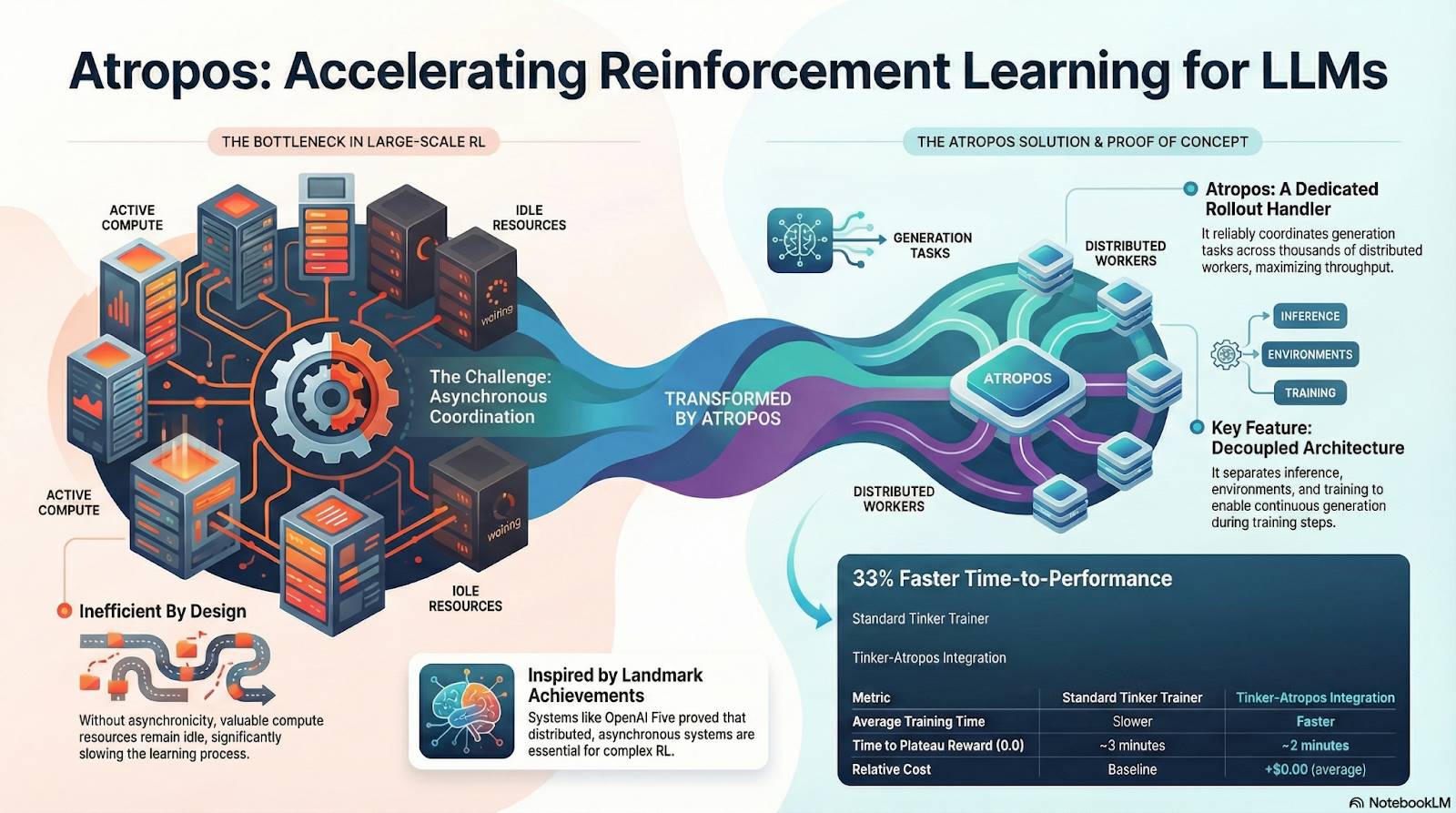
# DisTrO et Psyche : couche d’optimisation du RL décentralisé
Le RL traditionnel (RLHF/RLAIF) dépend de grappes centralisées à haute bande passante, constituant une barrière fondamentale pour l’open source. DisTrO réduit de plusieurs ordres de grandeur les coûts de communication du RL grâce à une désynchronisation de la quantité de mouvement et à une compression des gradients, permettant l’entraînement sur la bande passante Internet. Psyche déploie ensuite ce mécanisme d’entraînement sur un réseau blockchain, où les nœuds peuvent effectuer localement inférence, vérification, évaluation des récompenses et mise à jour des poids, formant une boucle RL complète.
Dans l’architecture de Nous, Atropos valide les chaînes de pensée ; DisTrO compresse la communication d’entraînement ; Psyche exécute la boucle RL ; World Sim fournit des environnements complexes ; Forge collecte le raisonnement réel ; Hermes écrit tout apprentissage dans les poids. Le RL n’est plus une simple phase d’entraînement, mais le protocole central reliant données, environnement, modèle et infrastructure dans l’architecture de Nous, transformant Hermes en un système vivant capable de s’améliorer continuellement sur un réseau de calcul open source.
Gradient Network : architecture de RL Echo
L’objectif central de Gradient Network est de reconstruire le paradigme de calcul de l’IA via une « pile de protocoles d’intelligence ouverte » (Open Intelligence Stack). La pile technique de Gradient est constituée d’un ensemble de protocoles fondamentaux pouvant évoluer indépendamment tout en coopérant de manière hétérogène. Du bas vers le haut, elle comprend : Parallax (inférence distribuée), Echo (entraînement RL décentralisé), Lattica (réseau P2P), SEDM / Massgen / Symphony / CUAHarm (mémoire, coopération, sécurité), VeriLLM (vérification fiable), Mirage (simulation haute fidélité), formant conjointement une infrastructure d’intelligence décentralisée en évolution continue.
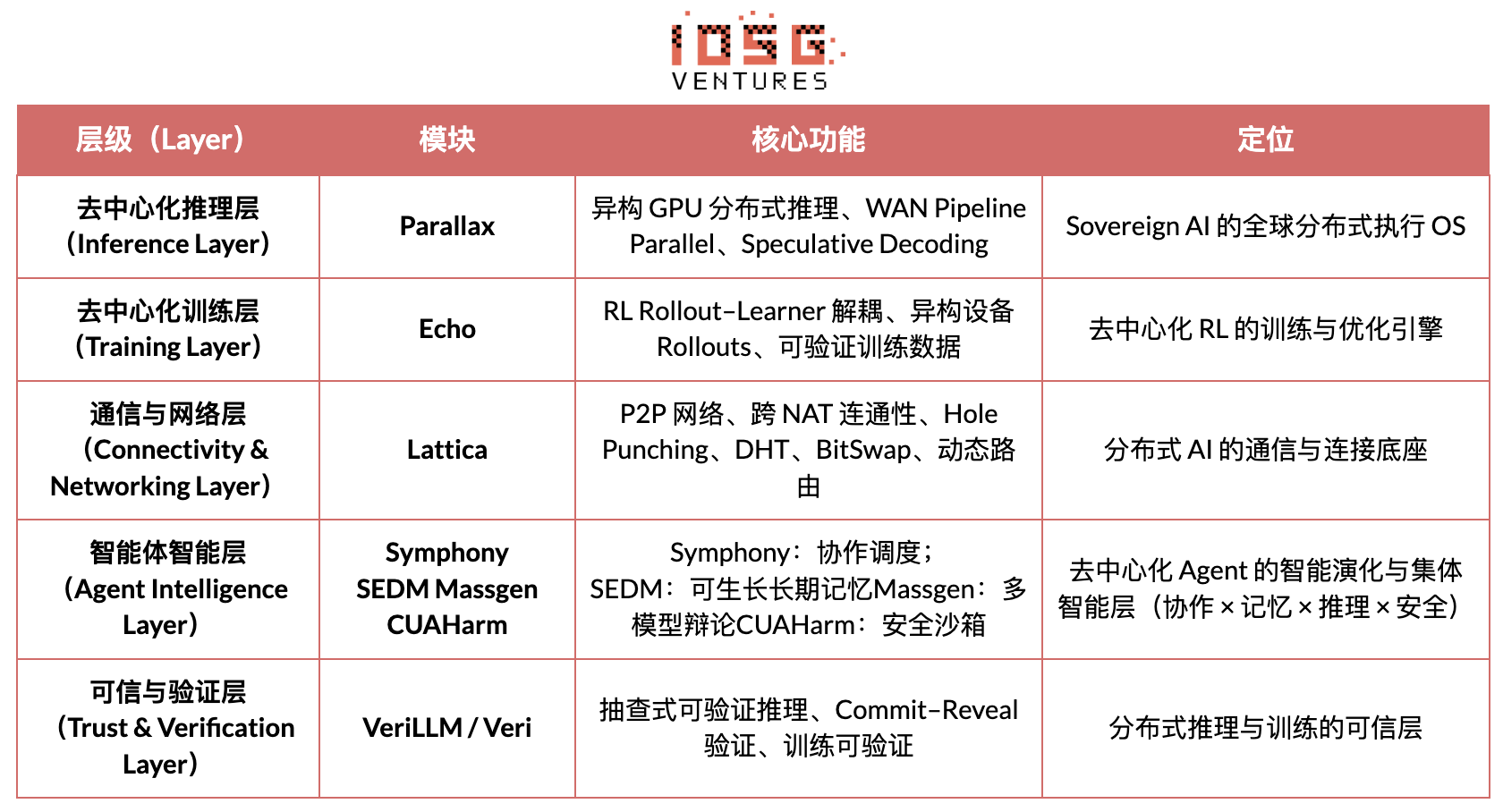
Echo — Architecture d’entraînement par renforcement learning
Echo est le cadre de RL de Gradient, dont le principe central est de découpler les chemins d’entraînement, d’inférence et de données (récompenses) dans le RL, permettant aux phases de génération de Rollout, d’optimisation de stratégie et d’évaluation de récompense de s’étendre et d’être planifiées indépendamment dans des environnements hétérogènes. Fonctionnant de concert dans un réseau hétérogène composé de nœuds d’inférence et d’entraînement, il maintient la stabilité via un mécanisme de synchronisation léger, atténuant efficacement les échecs SPMD et les goulets d’étranglement d’utilisation GPU causés par l’exécution mixte d’inférence et d’entraînement dans les solutions traditionnelles comme DeepSpeed RLHF / VERL.
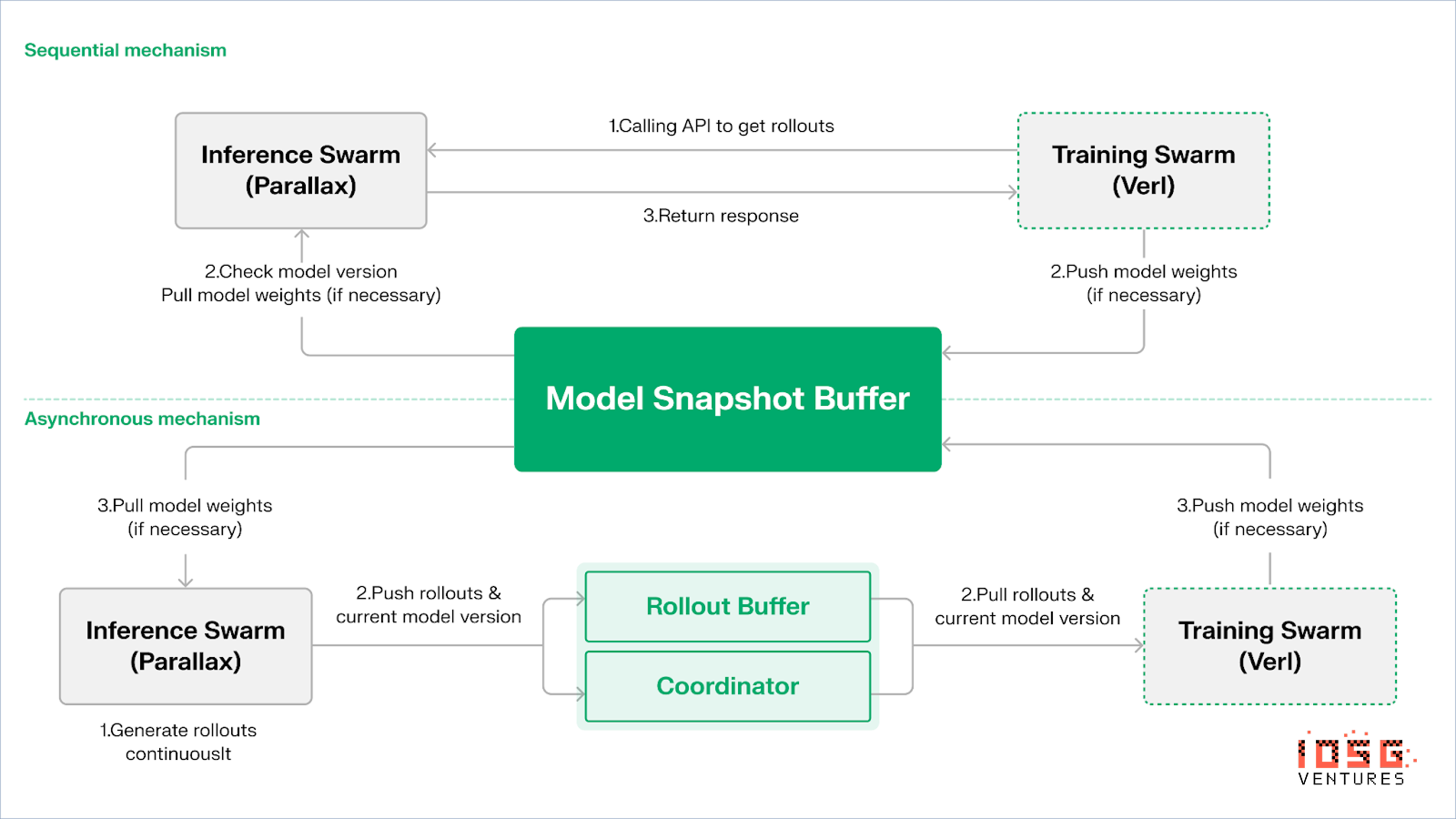
Echo adopte une « architecture double-grappe inférence–entraînement » pour maximiser l’utilisation du calcul, chaque grappe fonctionnant indépendamment, sans blocage mutuel :
-
Maximisation du débit d’échantillonnage : la grappe d’inférence (Inference Swarm), composée de GPU grand public et de dispositifs périphériques, utilise Parallax en parallélisme par pipeline pour créer un échantillonneur à haut débit, spécialisé dans la génération de trajectoires.
-
Maximisation du calcul de gradient : la grappe d’entraînement (Training Swarm), composée de GPU grand public répartis mondialement ou de grappes centralisées, gère la mise à jour des gradients, la synchronisation des paramètres et l’affinement LoRA, spécialisée dans le processus d’apprentissage.
Pour maintenir la cohérence entre stratégie et données, Echo propose deux protocoles de synchronisation légers : séquentiel (Sequential) et asynchrone (Asynchronous), assurant une gestion bidirectionnelle de la cohérence des poids et des trajectoires :
-
Mode de tirage séquentiel (Pull) | priorité précision : le nœud d’entraînement force les nœuds d’inférence à rafraîchir la version du modèle avant de tirer de nouvelles trajectoires, garantissant ainsi leur fraîcheur, adapté aux tâches sensibles à l’obsolescence de la stratégie.
-
Mode push–pull asynchrone | priorité efficacité : les nœuds d’inférence génèrent continuellement des trajectoires étiquetées par version, consommées à leur rythme par le côté entraînement. L’orchestrateur surveille les écarts de version et déclenche le rafraîchissement des poids, maximisant l’utilisation des équipements.
En couche basse, Echo repose sur Parallax (inférence hétérogène en faible bande passante) et des composants légers d’entraînement distribué (comme VERL), utilisant LoRA pour réduire les coûts de synchronisation inter-nœuds, permettant au RL de fonctionner stablement sur des réseaux hétérogènes mondiaux.
Grail : renforcement learning dans l’écosystème Bittensor
Bittensor, via son mécanisme de consensus Yuma unique, construit un vaste réseau de fonctions de récompense creuses, non stationnaires.
Dans l’écosystème Bittensor, Covenant AI développe une chaîne verticale intégrée allant de l’entraînement préalable au post-entraînement RL via SN3 Templar, SN39 Basilica et SN81 Grail. SN3 Templar gère l’entraînement préalable du modèle de base, SN39 Basilica fournit un marché de puissance de calcul distribué, et SN81 Grail agit comme une « couche de raisonnement vérifiable » dédiée au post-entraînement RL, hébergeant les processus clés de RLHF / RLAIF, achevant ainsi l’optimisation en boucle fermée du modèle de base vers la stratégie alignée.
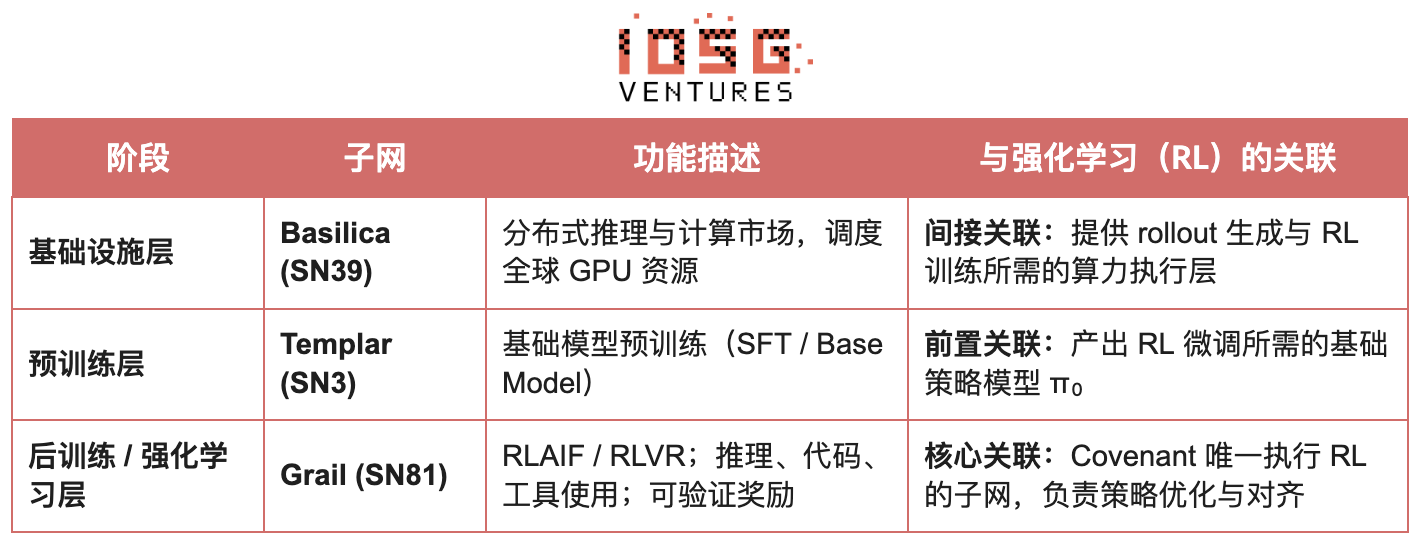
L’objectif de GRAIL est de prouver cryptographiquement l’authenticité de chaque rollout de renforcement learning et de lier l’identité du modèle, garantissant que le RLHF puisse être exécuté en toute sécurité dans un environnement sans confiance. Le protocole établit une chaîne de confiance via trois mécanismes :
-
Génération de défis déterministes : utiliser la balise aléatoire drand et le hachage de bloc pour créer des tâches de défi imprévisibles mais reproductibles (ex. SAT, GSM8K), empêchant la tricherie par calcul préalable.
-
Par échantillonnage PRF et engagements sketch, les vérificateurs peuvent auditer à très faible coût les logprob au niveau token et les chaînes de raisonnement, confirmant que le rollout a bien été généré par le modèle déclaré.
-
Liaison d’identité du modèle : lie le processus d’inférence à l’empreinte des poids du modèle et à la signature structurelle de la distribution des tokens, garantissant que le remplacement du modèle ou la répétition des résultats seront immédiatement détectés. Ainsi, il établit les fondations d’authenticité des trajectoires d’inférence (rollout) dans le RL.
Sur cette base, le sous-réseau Grail implémente un flux de post-entraînement vérifiable de type GRPO : les mineurs génèrent plusieurs chemins de raisonnement pour une même question, les vérificateurs notent selon la justesse, la qualité de la chaîne de raisonnement et la satisfaction SAT, puis écrivent les résultats normalisés sur la chaîne comme poids TAO. Des expériences publiques montrent que ce cadre a fait passer la précision MATH de Qwen2.5-1.5B de 12,7 % à 47,6 %, prouvant qu’il peut à la fois prévenir la tricherie et renforcer significativement les capacités du modèle. Dans la pile d’entraînement de Covenant AI, Grail constitue la pierre angulaire de confiance et d’exécution pour le RLVR/RLAIF décentralisé, bien qu’il ne soit pas encore lancé sur le réseau principal.
Fraction AI : renforcement learning basé sur la compétition RLFC
L’architecture de Fraction AI s’articule clairement autour du renforcement learning par compétition (Reinforcement Learning from Competition, RLFC) et de l’annotation de données gamifiée. Elle remplace la récompense statique et l’annotation humaine traditionnelles du RLHF par un environnement ouvert et dynamique de compétition. Les agents s’affrontent dans différents Spaces, leur classement relatif et les notes d’un juge IA formant ensemble une récompense en temps réel, transformant le processus d’alignement en un système de jeu multi-agents en ligne continu.
Différence fondamentale entre le RLHF traditionnel et le RLFC de Fraction AI :

La valeur fondamentale du RLFC réside dans le fait que la récompense ne provient plus d’un seul modèle, mais d’adversaires et d’évaluateurs en constante évolution, évitant ainsi l’exploitation du modèle de récompense et empêchant l’écosystème de converger vers un optimum local grâce à la diversité stratégique. La structure des Spaces détermine la nature du jeu (somme nulle ou positive), favorisant l’émergence de comportements complexes par confrontation ou coopération.
Architecturalement, Fraction AI décompose le processus d’entraînement en quatre composants clés :
-
Agents : unités stratégiques légères basées sur des LLM open source, étendues par QLoRA via des poids différentiels, facilement mis à jour à faible coût.
-
Spaces : environnements isolés par domaine de tâche, les agents paient pour y entrer et sont récompensés selon leurs victoires.
-
Juges IA : couche de récompense instantanée construite sur RLAIF, offrant une évaluation scalable et décentralisée.
-
Proof-of-Learning : lie la mise à jour de stratégie aux résultats concrets de compétition, garantissant que le processus d’entraînement est vérifiable et anti-triche.
L’essence de Fraction AI est de construire un « moteur évolutif de collaboration homme-machine ». L’utilisateur, en tant que « méta-optimalisateur » au niveau stratégique, guide la direction d’exploration via l’ingénierie de prompt et la configuration d’hyperparamètres ; pendant ce temps, les agents génèrent spontanément des volumes massifs de paires de préférences de haute qualité à l’échelle microscopique. Ce modèle réalise une boucle commerciale via un « affinement sans confiance » (Trust












