

Outre la génération de revenus et le storytelling, que peut faire la crypto pour l'IA ?
TechFlow SélectionTechFlow Sélection
Outre la génération de revenus et le storytelling, que peut faire la crypto pour l'IA ?
Dans le domaine de l'IA, de nombreux problèmes fondamentaux peuvent être résolus grâce à la cryptographie.
Auteur : Pavel Paramonov
Traduction : TechFlow
@newmichwill, le fondateur de Curve Finance, a récemment affirmé sur X que l'objectif principal des cryptomonnaies est la DeFi (finance décentralisée), et que l'IA (intelligence artificielle) n'a fondamentalement pas besoin des cryptomonnaies. Bien que je convienne que la DeFi est une composante majeure de l'écosystème crypto, je ne partage pas l'idée selon laquelle l'IA n'aurait aucun besoin des cryptomonnaies.
Avec la montée en puissance des agents d'IA (AI agents), nombreux sont ceux qui associent automatiquement les cryptomonnaies à ces seuls agents, oubliant un sujet crucial : « l’IA décentralisée », étroitement liée à l'entraînement même des modèles d'IA.
Ce qui me gêne dans certains récits, c’est que la plupart des utilisateurs croient aveuglément qu’un phénomène populaire est nécessairement important et utile, voire pire, qu’il n’a d’autre but que d’extraire un maximum de valeur (autrement dit, de générer des profits).
Lorsqu’on aborde la question de l’IA décentralisée, nous devrions d’abord nous demander : pourquoi l’IA aurait-elle besoin d’être décentralisée ? Et quelles en seraient les conséquences ?
En réalité, le concept de décentralisation est presque inévitablement lié à celui de « l’alignement des incitations ».
Dans le domaine de l’IA, plusieurs problèmes fondamentaux peuvent être résolus grâce aux technologies blockchain, tandis que certaines mécaniques permettent non seulement de régler des difficultés existantes, mais aussi d’ajouter davantage de crédibilité aux systèmes d’IA.
Pourquoi donc l’IA aurait-elle besoin des cryptomonnaies ?
1. Le coût élevé du calcul limite la participation et l’innovation
Fort heureusement ou malheureusement, les grands modèles d’IA exigent d’importantes ressources informatiques, ce qui naturellement restreint la participation de nombreux utilisateurs potentiels. Dans la plupart des cas, les modèles d’IA nécessitent d’énormes volumes de données ainsi que des capacités réelles de calcul, des ressources quasi inaccessibles pour un individu isolé.
Ce problème est particulièrement marqué dans le développement open source. Les contributeurs doivent non seulement investir du temps dans l’entraînement des modèles, mais aussi fournir des ressources de calcul, ce qui rend le processus peu efficace.
Bien sûr, un individu peut allouer d’importantes ressources pour exécuter un modèle d’IA, tout comme un utilisateur peut affecter des ressources informatiques au fonctionnement d’un nœud de blockchain.
Toutefois, cela ne résout pas fondamentalement le problème, car la puissance de calcul reste insuffisante pour accomplir les tâches requises.
Les développeurs indépendants ou chercheurs ne peuvent pas participer au développement de grands modèles comme LLaMA simplement parce qu’ils ne peuvent pas supporter le coût de calcul nécessaire à leur entraînement : des milliers de GPU, des centres de données et des infrastructures supplémentaires.
Voici quelques chiffres pour illustrer l’échelle du problème :
→ Elon Musk affirme que le dernier modèle Grok 3 a été entraîné avec 100 000 GPU Nvidia H100.
→ Chaque puce coûte environ 30 000 dollars.
→ Le coût total des puces d’IA utilisées pour entraîner Grok 3 s’élève à environ 3 milliards de dollars.
Cette situation rappelle celle de la création d’une startup : une personne peut disposer du temps, des compétences techniques et d’un plan d’exécution, mais lui manquent initialement les ressources nécessaires pour concrétiser sa vision.
Comme l’a souligné @dbarabander, les projets logiciels open source traditionnels demandent uniquement aux contributeurs de donner de leur temps, alors que les projets open source d’IA exigent à la fois du temps et des ressources importantes, telles que la puissance de calcul et les données.
Seule la bonne volonté ou l’effort bénévole ne suffit pas à inciter suffisamment d’individus ou de groupes à fournir ces ressources coûteuses. Des incitations supplémentaires sont nécessaires pour stimuler la participation.
2. La cryptographie est l’outil idéal pour aligner les incitations
L’« alignement des incitations » consiste à établir des règles qui encouragent les participants à contribuer au système tout en poursuivant leurs propres intérêts.
La technologie blockchain a déjà fait ses preuves à maintes reprises pour permettre cet alignement dans divers systèmes, notamment dans le secteur DePIN (réseaux physiques d’infrastructure décentralisés), où ce principe trouve une application parfaite.
Des projets comme @helium et @rendernetwork ont mis en place des réseaux distribués de nœuds et de GPU, créant ainsi des modèles exemplaires d’alignement des incitations.
Alors, pourquoi ne pas appliquer ce modèle au domaine de l’IA afin de rendre son écosystème plus ouvert et accessible ?
En réalité, nous le pouvons.
Le cœur de la philosophie Web3 et des cryptomonnaies repose sur la notion de « propriété ».
Vous possédez vos propres données, vous contrôlez vos propres incitations, et lorsque vous détenez certains jetons, vous possédez même une partie du réseau. En octroyant une forme de propriété aux fournisseurs de ressources, on les motive à mettre leurs actifs à disposition du projet, espérant tirer profit du succès du réseau.
Pour démocratiser davantage l’accès à l’IA, les cryptomonnaies offrent la meilleure solution. Les développeurs peuvent librement partager leurs conceptions de modèles entre projets, tandis que les fournisseurs de calcul et de données reçoivent en échange une part de propriété (incitation).
3. Alignement des incitations et vérifiabilité sont étroitement liés
Si nous imaginons un système d’IA décentralisé doté d’un bon alignement des incitations, il devrait intégrer certaines caractéristiques classiques des blockchains :
-
Effets de réseau (Network Effects).
-
Exigences initiales faibles, avec des retours futurs pour les nœuds participants.
-
Mécanismes de sanction (Slashing Mechanisms), pour punir les comportements malveillants.
En particulier, pour les mécanismes de sanction, la vérifiabilité est essentielle. Sans capacité à identifier les comportements malveillants, il est impossible de les sanctionner, rendant le système vulnérable aux fraudes, surtout dans des contextes de collaboration inter-équipes.
Dans un système d’IA décentralisé, la vérifiabilité est cruciale, car nous n’avons pas de point central de confiance. Au contraire, nous visons un système sans confiance mais vérifiable. Voici quelques composants qui nécessitent potentiellement une vérification :
-
Phase de benchmark : le système surpasse-t-il d'autres systèmes selon certains critères (x, y, z) ?
-
Phase d’inférence : le système fonctionne-t-il correctement, c’est-à-dire lors de la phase de « réflexion » de l’IA ?
-
Phase d’entraînement : le système a-t-il été correctement entraîné ou ajusté ?
-
Phase des données : les données ont-elles été collectées correctement ?
Actuellement, des centaines d’équipes construisent sur @eigenlayer, mais j’ai remarqué récemment que l’intérêt pour l’IA est plus fort que jamais. Je me demande si cela correspond à la vision initiale de re-staking.
Tout système d’IA souhaitant un bon alignement des incitations doit être vérifiable.
Dans ce cas, le mécanisme de sanction équivaut à la vérifiabilité : si un système décentralisé peut sanctionner un comportement malveillant, c’est qu’il est capable d’identifier et de vérifier ce comportement.
Si le système est vérifiable, l’IA peut alors utiliser la technologie blockchain pour accéder aux ressources mondiales de calcul et de données, permettant ainsi de créer des modèles plus grands et plus puissants. Car plus de ressources (calcul + données) conduisent généralement à de meilleurs modèles (du moins dans l’état actuel de la technologie).
@hyperbolic_labs a déjà démontré le potentiel du calcul collaboratif. N’importe quel utilisateur peut louer des GPU pour entraîner des modèles d’IA plus complexes que ceux qu’il pourrait exécuter chez lui, et ce à moindre coût.
Comment rendre la vérification de l’IA à la fois efficace et fiable ?
On pourrait objecter que de nombreuses solutions cloud permettent déjà de louer des GPU, résolvant ainsi le problème des ressources de calcul.
Cependant, des solutions comme AWS ou Google Cloud sont fortement centralisées et adoptent une stratégie dite de « liste d’attente » (Waitlist Strategy), créant artificiellement une forte demande pour augmenter les prix — un phénomène courant dans les structures oligopolistiques du secteur.
En réalité, d’importants GPU restent inutilisés dans des centres de données, des fermes minières, voire chez des particuliers, des ressources gaspillées qui pourraient contribuer à l’entraînement de modèles d’IA.
Vous avez peut-être entendu parler de @getgrass_io, qui permet aux utilisateurs de vendre leur bande passante inutilisée aux entreprises, évitant ainsi le gaspillage et recevant une compensation en retour.
Je ne prétends pas que les ressources de calcul soient illimitées, mais tout système peut être optimisé pour créer une situation gagnant-gagnant : d’un côté, offrir un marché plus ouvert à ceux qui ont besoin de ressources pour entraîner des modèles d’IA ; de l’autre, permettre aux contributeurs d’obtenir une rémunération.
L’équipe Hyperbolic a développé un marché ouvert de GPU. Ici, les utilisateurs peuvent louer des GPU pour entraîner des modèles d’IA, économisant jusqu’à 75 % des coûts, tandis que les fournisseurs monétisent leurs ressources inutilisées.
Voici un aperçu de son fonctionnement :
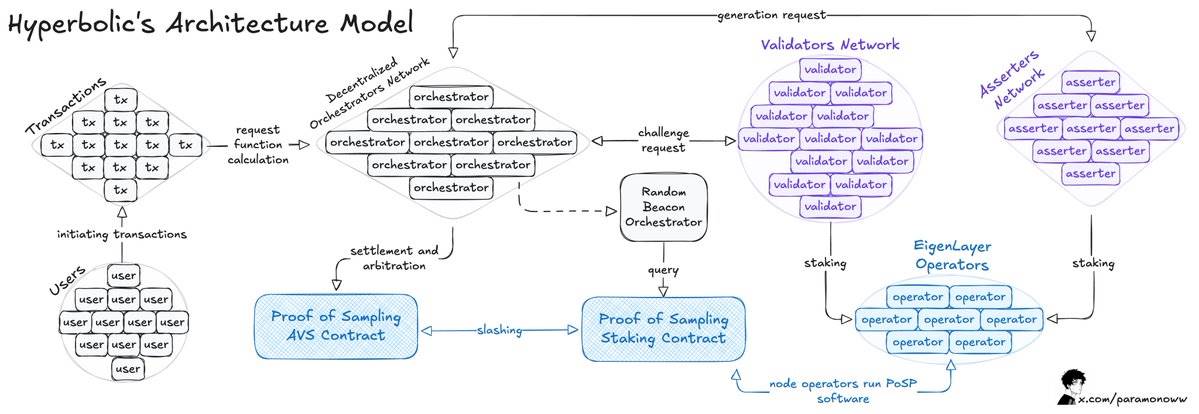
Hyperbolic organise les GPU connectés en clusters et nœuds, permettant une scalabilité de la puissance de calcul selon la demande.
Le cœur de cette architecture repose sur le modèle « Proof of Sampling » (Preuve d’Échantillonnage), qui traite les transactions par échantillonnage : en sélectionnant aléatoirement et en vérifiant certaines transactions, il réduit la charge de travail et les besoins de calcul.
Le problème principal survient durant l’inférence (Inference) de l’IA : chaque inférence exécutée sur le réseau doit être vérifiée, de préférence sans surcoût computationnel significatif.
Comme mentionné précédemment, si une action peut être vérifiée, alors toute violation des règles doit entraîner une sanction (Slashing).
Quand Hyperbolic adopte le modèle AVS (Adaptive Verification System, système de vérification adaptative), il renforce la vérifiabilité du système. Dans ce modèle, des validateurs sont choisis aléatoirement pour vérifier les résultats, assurant ainsi l’alignement des incitations : les comportements malhonnêtes deviennent non rentables.
Pour entraîner un modèle d’IA et l’améliorer, deux ressources principales sont nécessaires : la puissance de calcul et les données. Louer de la puissance de calcul est une solution, mais il reste encore à obtenir les données, et celles-ci doivent être variées pour éviter les biais du modèle.
Vérifier les données provenant de sources multiples pour l’IA
Plus il y a de données, meilleur est le modèle ; mais le défi réside dans la diversité des données. C’est l’un des principaux obstacles auxquels l’IA est confrontée.
Les protocoles de données existent depuis des décennies. Qu’elles soient publiques ou privées, les données sont collectées par des intermédiaires, parfois payés, parfois non, puis revendues pour générer des profits.
Les problèmes que nous rencontrons pour obtenir des données appropriées pour les modèles d’IA incluent : points de défaillance unique, censure, et absence de moyen fiable et sans confiance pour fournir des données authentiques destinées à « nourrir » les modèles d’IA.
Qui a besoin de ces données ?
D’abord, les chercheurs et développeurs d’IA, qui veulent entraîner et effectuer des inférences sur leurs modèles avec des entrées réelles et pertinentes.
Par exemple, OpenLayer permet à quiconque d’ajouter sans permission des flux de données vers le système ou un modèle d’IA, et chaque donnée disponible est enregistrée de manière vérifiable.
OpenLayer utilise également zkTLS (zero-knowledge Transport Layer Security), un protocole que j’ai décrit en détail dans un article précédent. Ce protocole garantit que les données rapportées par un opérateur proviennent bien de leur source (vérifiabilité).
Voici comment fonctionne OpenLayer :
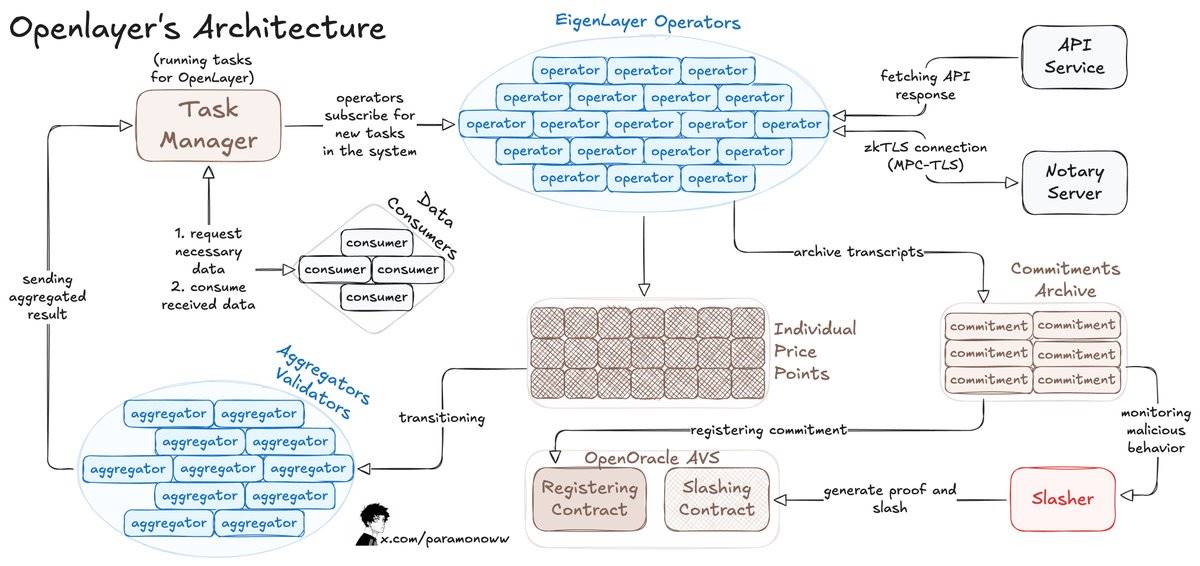
-
Un consommateur de données publie une requête via le contrat intelligent d’OpenLayer et récupère les résultats via une API similaire à celle d’un oracle de données principal (on-chain ou off-chain).
-
Un opérateur s’enregistre via EigenLayer pour garantir les actifs en jeu d’OpenLayer AVS et exécute le logiciel AVS.
-
L’opérateur souscrit à une tâche, traite les données et les soumet à OpenLayer, tout en stockant la réponse brute et les preuves dans un stockage décentralisé.
-
Pour les résultats variables, un agrégateur (un type particulier d’opérateur) normalise les sorties.
Les développeurs peuvent demander les données les plus récentes à n’importe quel site web et les intégrer au réseau. Si vous développez un projet lié à l’IA, vous pouvez ainsi accéder à des données fiables et en temps réel.
Après avoir examiné le calcul IA et les moyens d’acquérir des données vérifiables, nous devons maintenant nous concentrer sur les deux piliers fondamentaux du modèle d’IA : le calcul lui-même et sa vérification.
Le calcul IA doit être vérifié pour garantir sa justesse
Dans un scénario idéal, chaque nœud doit prouver sa contribution au calcul pour assurer le bon fonctionnement du système.
Dans le pire des cas, un nœud pourrait prétendre faussement avoir fourni de la puissance de calcul sans avoir accompli aucun travail réel.
Exiger une preuve de contribution garantit que seuls les participants légitimes sont reconnus, évitant ainsi les comportements malveillants. Ce mécanisme est proche du « proof of work » (preuve de travail) classique, à ceci près que le type de travail effectué par les nœuds diffère.
Même avec un bon alignement des incitations, si les nœuds ne peuvent pas prouver sans permission leur contribution, ils pourraient recevoir des récompenses disproportionnées par rapport à leurs efforts réels, voire entraîner une distribution injuste des récompenses.
Si le réseau ne peut pas évaluer les contributions en calcul, certains nœuds pourraient se voir attribuer des tâches dépassant leurs capacités, tandis que d’autres resteraient inactifs, causant inefficacité ou défaillance du système.
En prouvant la contribution au calcul, le réseau peut quantifier l’effort de chaque nœud via des indicateurs standardisés (par exemple, FLOPS, nombre d’opérations flottantes par seconde). Ainsi, les récompenses sont distribuées selon le travail effectivement accompli, et non simplement en fonction de la présence du nœud dans le réseau.
L’équipe de @HyperspaceAI a développé un système de « Proof-of-FLOPS », permettant aux nœuds de louer leur puissance de calcul inutilisée. En échange, ils reçoivent des points « flops », qui servent de monnaie universelle au sein du réseau.
Voici comment fonctionne cette architecture :
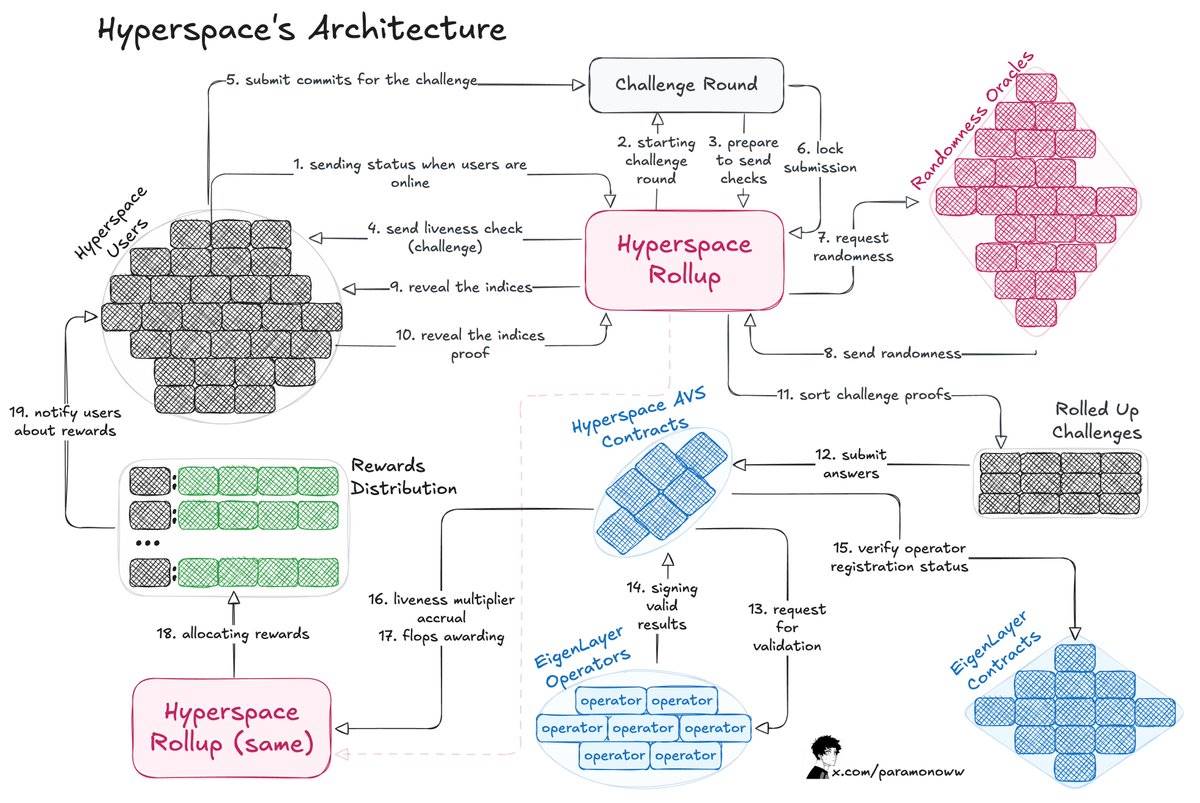
-
Le processus commence par une mise au défi envoyée à l’utilisateur, qui répond en soumettant un engagement.
-
Hyperspace Rollup gère le processus, assure la sécurité des soumissions et récupère un nombre aléatoire via un oracle.
-
L’utilisateur révèle l’index, complétant ainsi le processus de challenge.
-
L’opérateur vérifie la réponse et notifie le contrat AVS d’Hyperspace des résultats valides, qui sont ensuite confirmés via le contrat EigenLayer.
-
Le multiplicateur d’activité (Liveness Multiplier) est calculé, et des points « flops » sont attribués à l’utilisateur.
La preuve de contribution au calcul donne une image claire des capacités de chaque nœud, permettant au système d’attribuer intelligemment les tâches : des calculs complexes d’IA aux nœuds performants, des tâches plus légères aux nœuds moins puissants.
La partie la plus intéressante réside dans la manière de rendre ce système vérifiable, de sorte que n’importe qui puisse attester de la justesse du travail accompli. Le système AVS d’Hyperspace envoie continuellement des défis, des requêtes de nombres aléatoires, et exécute un processus de vérification en plusieurs couches, comme illustré dans le schéma ci-dessus.
Les opérateurs peuvent participer en toute confiance, car les résultats sont vérifiés et les récompenses équitablement distribuées. Si un résultat est incorrect, le comportement malveillant sera sanctionné sans ambiguïté (Slashing).
La vérification des résultats du calcul IA présente de nombreuses raisons importantes :
-
Encourager les nœuds à rejoindre et contribuer des ressources.
-
Répartir les récompenses équitablement selon l’effort fourni.
-
S’assurer que la contribution soutient directement un modèle d’IA spécifique.
-
Attribuer efficacement les tâches selon la capacité de vérification des nœuds.
Décentralisation et vérifiabilité de l’IA
Comme l’a souligné @yb_effect, « décentralisé » (decentralized) et « distribué » (distributed) sont des concepts totalement différents. Distribué signifie simplement que le matériel est réparti géographiquement, mais qu’un point central de connexion persiste.
En revanche, le décentralisé implique l’absence de nœud principal unique, et le processus d’entraînement doit pouvoir tolérer les pannes — un mode de fonctionnement similaire à celui de la plupart des blockchains actuelles.
Pour qu’un réseau d’IA soit véritablement décentralisé, plusieurs solutions sont nécessaires, mais une chose est sûre : nous devons pouvoir vérifier presque tous les composants.
Si vous souhaitez construire un modèle ou un agent d’IA, vous devez vous assurer que chaque composant et chaque dépendance est vérifié.
Inférence, entraînement, données, oracles — tout cela peut être vérifié, permettant non seulement d’introduire des récompenses cryptographiques compatibles avec les incitations, mais aussi de rendre le système plus juste et plus efficace.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News









