

Vous avez manqué Nvidia ? Ne manquez plus Crypto AI
TechFlow SélectionTechFlow Sélection
Vous avez manqué Nvidia ? Ne manquez plus Crypto AI
Nous sommes à la veille d'une explosion de l'innovation.
Auteur : Teng Yan
Traduction : TechFlow

Bonjour ! Ça y est, c’est enfin arrivé.
Notre article complet est très dense. Pour le rendre plus accessible (et éviter les limites de taille des fournisseurs de messagerie), j’ai décidé de le diviser en plusieurs parties que je partagerai progressivement au cours du mois à venir. Commençons donc sans plus tarder !
Il y a un énorme regret que je n’arrive jamais à oublier.
Cela me hante encore aujourd’hui, car il s’agissait d’une opportunité évidente que toute personne suivant les marchés aurait pu repérer — mais je l’ai manquée, n’y investissant pas un seul centime.
Non, ce n’était ni le prochain tueur de Solana, ni un memecoin avec un chien portant un chapeau rigolo.
C’était… NVIDIA.
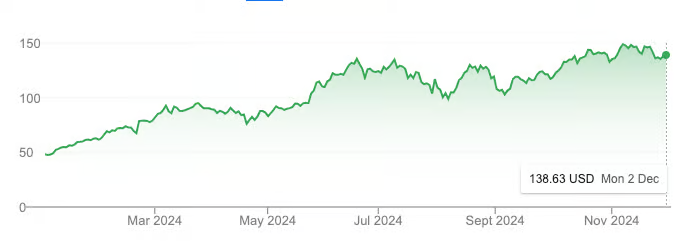
Performance boursière de NVDA depuis le début de l’année. Source : Google
En seulement une année, la capitalisation boursière de NVIDIA est passée de 1 000 milliards à 3 000 milliards de dollars, triplant son cours, dépassant même celui du Bitcoin sur la même période.
Bien sûr, une partie de cette croissance est due à l’engouement pour l’intelligence artificielle. Mais surtout, elle repose sur des fondamentaux solides. Le chiffre d'affaires de NVIDIA a atteint 60 milliards de dollars lors de l’exercice 2024, soit une hausse de 126 % par rapport à 2023. Cette croissance spectaculaire s’explique par la ruée mondiale des grandes entreprises technologiques pour acquérir des GPU et prendre une longueur d’avance dans la course à l’intelligence générale artificielle (AGI).
Pourquoi ai-je raté ça ?
Durant ces deux dernières années, mon attention était entièrement focalisée sur la cryptographie, sans prêter attention aux développements dans le domaine de l’IA. C’était une erreur monumentale, dont je me repens encore aujourd'hui.
Mais cette fois, je ne ferai pas la même erreur.
L’actuelle Crypto AI m’évoque une sensation familière.
Nous sommes au seuil d’une explosion d’innovation. Cela rappelle fortement la ruée vers l’or en Californie au milieu du XIXe siècle — des industries et des villes qui surgissent du jour au lendemain, des infrastructures qui se développent rapidement, et ceux qui prennent des risques qui amassent des fortunes.
Comme NVIDIA au tout début, Crypto AI semblera rétrospectivement tellement évidente.
Crypto AI : une opportunité d'investissement au potentiel illimité
Dans la première partie de mon article, j’ai expliqué pourquoi Crypto AI constitue aujourd’hui l’opportunité la plus passionnante, tant pour les investisseurs que pour les développeurs. Voici les points clés :
-
Beaucoup la considèrent encore comme une « chimère ».
-
Crypto AI en est encore à ses débuts, et nous sommes probablement à 1 ou 2 ans du pic de spéculation.
-
Ce domaine présente un potentiel de croissance d’au moins 230 milliards de dollars.
Crypto AI consiste essentiellement à combiner l'intelligence artificielle et les infrastructures cryptographiques. Cela signifie qu'elle est plus susceptible de suivre la trajectoire exponentielle de l'IA plutôt que celle du marché crypto plus large. Pour rester en avance, vous devez suivre les dernières recherches publiées sur Arxiv et dialoguer avec des fondateurs convaincus de construire le prochain grand truc.
Les quatre grands domaines clés de Crypto AI
Dans la deuxième partie de mon article, je vais analyser en détail les quatre sous-domaines les plus prometteurs de Crypto AI :
-
Calcul décentralisé : entraînement de modèles, inférence et marchés de GPU
-
Réseaux de données
-
IA vérifiable
-
Agents IA fonctionnant sur la blockchain
Cet article résulte de semaines de recherche approfondie ainsi que d’échanges avec des fondateurs et équipes du secteur Crypto AI. Il ne s’agit pas d’une analyse exhaustive de chaque domaine, mais d’une feuille de route stratégique visant à stimuler votre curiosité, affiner vos axes de recherche et guider vos décisions d’investissement.
La carte écosystémique de Crypto AI
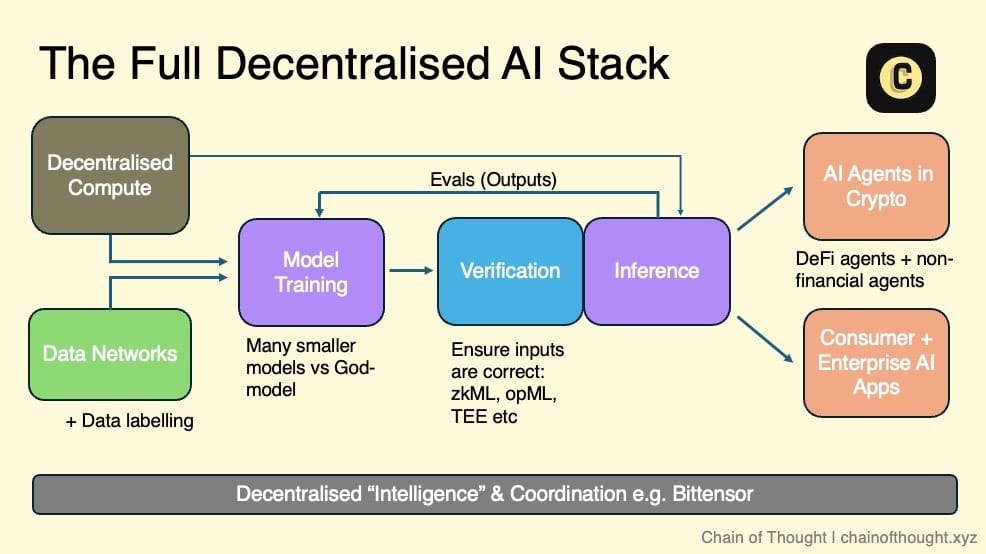
J’imagine l’écosystème de l’IA décentralisée comme une structure en couches : partant des réseaux de calcul décentralisés et des données ouvertes, qui constituent la base pour l’entraînement de modèles d’IA décentralisés.
Toutes les entrées et sorties de l’inférence sont validées via la cryptographie, des incitations économiques et des réseaux d’évaluation. Ces résultats vérifiés alimentent ensuite des agents IA autonomes sur la chaîne, ainsi que des applications IA grand public et professionnelles dignes de confiance.
Des réseaux de coordination relient l’ensemble de l’écosystème, permettant une communication et une collaboration transparentes.
Dans cette vision, toute équipe travaillant sur l’IA peut intégrer un ou plusieurs niveaux de l’écosystème selon ses besoins. Que ce soit pour former un modèle grâce au calcul décentralisé ou garantir une sortie de haute qualité via un réseau d’évaluation, l’écosystème offre une grande diversité de choix.
Grâce à la composable des blockchains, je crois que nous nous dirigeons vers un futur modulaire. Chaque couche sera hautement spécialisée, avec des protocoles optimisés pour des fonctions spécifiques, plutôt que des solutions tout-en-un.
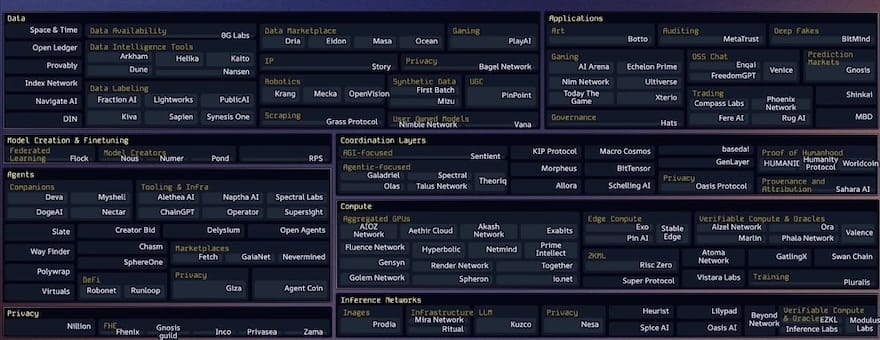
Ces dernières années, chaque niveau de la stack technique de l’IA décentralisée a vu exploser le nombre de startups, dans une véritable explosion « cambrienne ». La plupart ont été créées il y a seulement 1 à 3 ans. Cela montre que nous en sommes toujours aux toutes premières étapes de ce secteur.
Parmi les cartographies d’écosystèmes Crypto AI que j’ai vues, celle maintenue par Casey et son équipe chez topology.vc est la plus complète et à jour. Elle constitue une ressource indispensable pour toute personne souhaitant suivre l’évolution de ce domaine.
Lorsque j’explore les différents sous-domaines de Crypto AI, je me pose toujours la même question : quelle est réellement l’ampleur de l’opportunité ? Je ne cherche pas de petits marchés, mais des occasions capables de s’étendre à plusieurs centaines de milliards de dollars.
-
Taille du marché
Pour évaluer la taille du marché, je me demande : ce sous-domaine crée-t-il un tout nouveau marché, ou perturbe-t-il un marché existant ?
Prenons le calcul décentralisé, typique exemple de perturbation. On peut estimer son potentiel à partir du marché actuel du cloud computing, qui représente environ 680 milliards de dollars, et devrait atteindre 2 500 milliards d’ici 2032.
À l’inverse, un marché entièrement nouveau, comme celui des agents IA, est plus difficile à quantifier. Faute de données historiques, on doit s’appuyer sur l’intuition concernant sa capacité à résoudre des problèmes, et faire des extrapolations raisonnables. Attention toutefois : parfois, un produit perçu comme un marché nouveau n’est en réalité qu’une solution à la recherche d’un problème.
-
Timing
Le timing est crucial. Bien que la technologie tende à s’améliorer et à devenir moins chère avec le temps, les vitesses de progression varient fortement selon les domaines.
Quel est le degré de maturité technologique dans un sous-domaine donné ? Est-il déjà suffisamment mature pour être appliqué à grande échelle, ou reste-t-il au stade de recherche, encore loin d’une utilisation pratique ? Le timing détermine si un domaine mérite une attention immédiate ou s’il faut simplement l’observer pour l’instant.
Prenons le cas du chiffrement homomorphe complet (Fully Homomorphic Encryption, FHE) : son potentiel est indéniable, mais ses performances actuelles sont encore trop lentes pour une adoption massive. Nous devrons probablement attendre plusieurs années avant de le voir arriver sur le marché principal. C’est pourquoi je privilégie les domaines dont la technologie est proche de la maturité, concentrant mon temps et mes efforts sur les opportunités qui gagnent en élan.
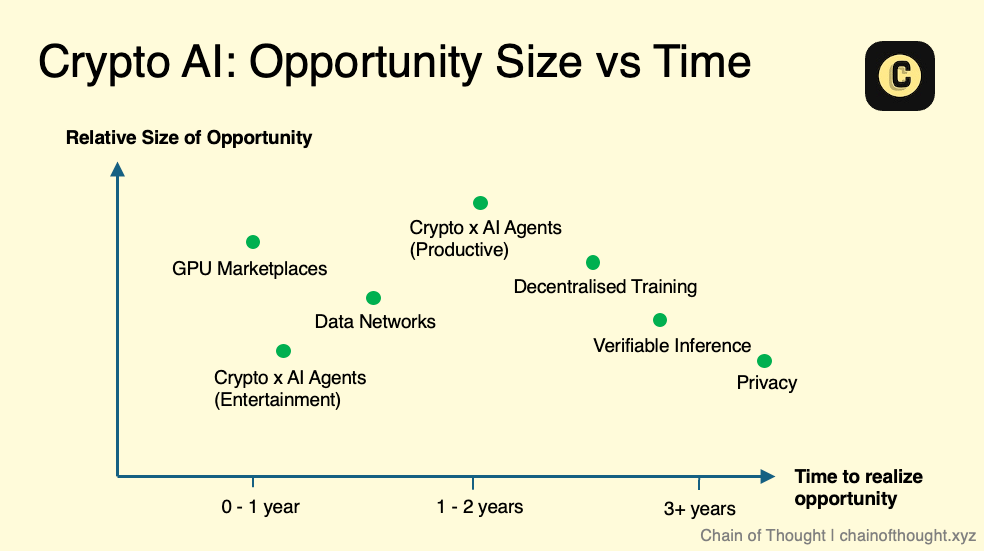
Si l’on représentait ces sous-domaines sur un graphique « taille du marché vs. timing », cela donnerait une configuration similaire à celle-ci. Notez bien qu’il s’agit d’un schéma conceptuel, non d’un guide strict. Chaque domaine recèle aussi sa propre complexité — par exemple, dans l’inférence vérifiable (verifiable inference), différentes méthodes (comme zkML et opML) se trouvent à des stades différents de maturité technologique.
Malgré tout, je suis convaincu que l’avenir de l’IA sera d’une ampleur exceptionnelle. Même des domaines perçus aujourd’hui comme « de niche » pourraient devenir des marchés importants demain.
Par ailleurs, il faut reconnaître que le progrès technologique n’est pas toujours linéaire — il progresse souvent par bonds. Lorsqu’une percée technologique majeure survient, ma perception du timing et de la taille du marché change en conséquence.
Sur la base de ce cadre, examinons maintenant chacun des sous-domaines de Crypto AI afin d’explorer leur potentiel de développement et leurs opportunités d’investissement.
Domaine 1 : Calcul décentralisé
Résumé
-
Le calcul décentralisé est le pilier central de toute l’IA décentralisée.
-
Les marchés de GPU, l’entraînement décentralisé et l’inférence décentralisée sont étroitement liés et évoluent ensemble.
-
L’offre provient principalement de centres de données de petite et moyenne taille, ainsi que des GPU de consommateurs ordinaires.
-
La demande est actuellement faible mais croît progressivement, incluant principalement des utilisateurs sensibles au prix et peu exigeants en latence, ainsi que certaines jeunes startups IA.
-
Le plus grand défi actuel pour les marchés Web3 de GPU est de faire fonctionner efficacement ces réseaux.
-
Coordonner l’utilisation des GPU dans un réseau décentralisé exige une ingénierie avancée et une architecture réseau robuste.
1.1 Marchés de GPU / Réseaux de calcul
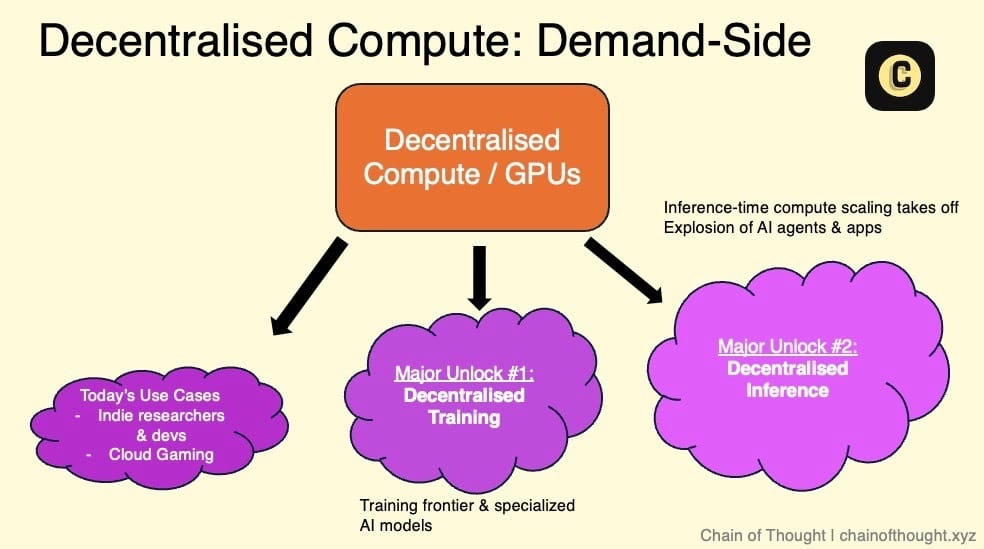
Actuellement, certaines équipes Crypto AI construisent des réseaux de GPU décentralisés afin d’exploiter le vaste gisement mondial de ressources informatiques inexploitées, face à une demande de GPU largement supérieure à l’offre.
La valeur fondamentale de ces marchés de GPU peut se résumer en trois points :
-
Un coût de calcul pouvant être jusqu’à 90 % inférieur à AWS. Cette économie provient de deux sources : l’élimination des intermédiaires et l’ouverture de l’offre. Ces marchés permettent d’accéder aux ressources informatiques ayant le coût marginal le plus bas au monde.
-
Pas de contrat à long terme, pas de vérification d’identité (KYC), pas d’attente d’approbation.
-
Résistance à la censure
Pour résoudre le problème de l’offre, ces marchés tirent leurs ressources informatiques des sources suivantes :
-
GPU professionnels : des GPU haut de gamme comme A100 ou H100, provenant généralement de centres de données de taille modeste (qui peinent à trouver assez de clients en indépendants), ou de mineurs de Bitcoin cherchant à diversifier leurs revenus. Certains projets exploitent également des infrastructures massives financées par des gouvernements, où de nombreux centres de données ont été construits dans le cadre de programmes de développement technologique. Ces fournisseurs sont souvent incités à connecter durablement leurs GPU au réseau, afin d’amortir le coût de leurs équipements.
-
GPU grand public : des millions de joueurs et d’utilisateurs domestiques connectent leurs ordinateurs au réseau et sont récompensés par des tokens.
Actuellement, la demande sur les réseaux de calcul décentralisés provient principalement des catégories suivantes :
-
Utilisateurs sensibles au prix et peu exigeants en latence : chercheurs à budget limité, développeurs IA indépendants, etc. Ils priorisent le coût plutôt que la rapidité de traitement. Contrairement aux géants du cloud (AWS ou Azure), ces services offrent des tarifs abordables. Un marketing ciblé est essentiel pour toucher ce public.
-
Jeunes startups IA : elles ont besoin de ressources flexibles et évolutives, sans vouloir signer de contrats à long terme avec de grands fournisseurs cloud. Attirer ces entreprises nécessite des partenariats commerciaux actifs, car elles cherchent activement des alternatives au cloud traditionnel.
-
Startups Crypto AI : elles développent des produits d’IA décentralisée mais, sans ressources propres, doivent s’appuyer sur ces réseaux décentralisés.
-
Cloud gaming : bien que peu lié directement à l’IA, la demande de GPU pour le jeu en nuage croît rapidement.
Un point essentiel à garder à l’esprit : les développeurs priorisent toujours le coût et la fiabilité.
Le vrai défi : la demande, pas l’offre
De nombreuses startups considèrent la taille du réseau d’offre de GPU comme un indicateur de succès, mais en réalité, c’est un simple « vanity metric ».
Le véritable goulot d’étranglement réside dans la demande, pas dans l’offre. L’indicateur clé n’est pas le nombre de GPU dans le réseau, mais leur taux d’utilisation et le volume réellement loué.
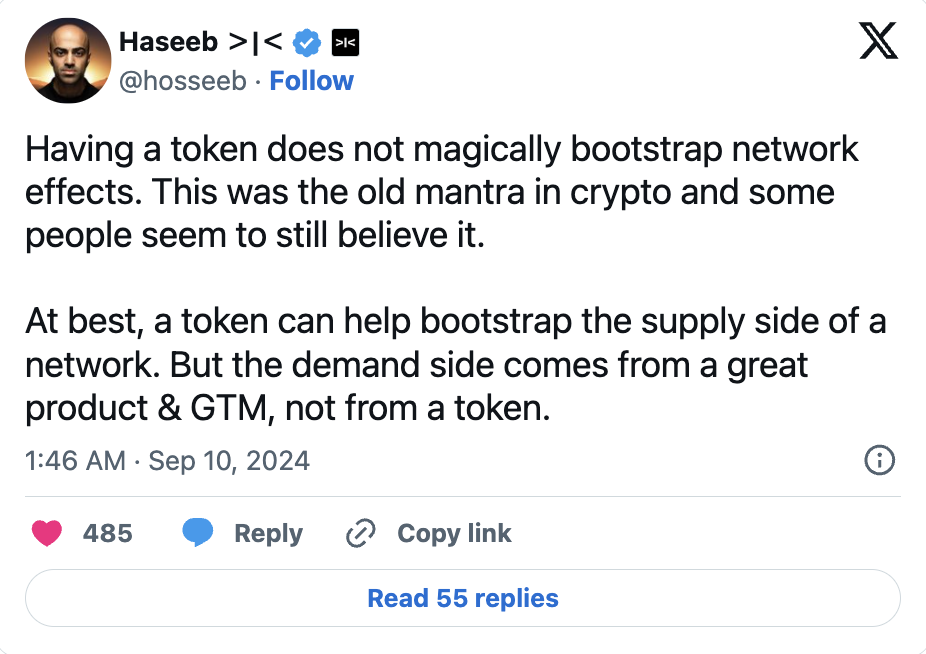
Les mécanismes d’incitation par token sont très efficaces pour lancer l’offre et attirer rapidement des ressources. Mais ils ne résolvent pas directement le problème du manque de demande. Le vrai test consiste à savoir si le produit est suffisamment bon pour susciter une demande organique.
Comme le dit Haseeb Qureshi (de Dragonfly), c’est là que tout se joue.
Faire fonctionner réellement les réseaux de calcul
Le plus grand défi actuel pour les marchés Web3 de GPU distribués est précisément de faire fonctionner efficacement ces réseaux.
Ce n’est pas une tâche simple.
Coordonner des GPU dans un réseau distribué est une tâche extrêmement complexe, impliquant de multiples défis techniques : allocation des ressources, extension dynamique des charges de travail, équilibrage de charge entre nœuds et GPU, gestion de la latence, transfert de données, tolérance aux pannes, et prise en compte du matériel hétérogène réparti à travers le monde. Ces obstacles s’accumulent, créant un défi d’ingénierie colossal.
Pour relever ces défis, une expertise technique solide et une architecture réseau robuste et bien conçue sont indispensables.
Pour mieux comprendre, pensez au système Kubernetes de Google. Considéré comme la référence en matière d’orchestration de conteneurs, Kubernetes automatise des tâches comme l’équilibrage de charge et l’extension dans des environnements distribués — des problèmes similaires à ceux rencontrés par les réseaux de GPU distribués. À noter que Kubernetes s’appuie sur plus de dix ans d’expérience en calcul distribué, et a nécessité plusieurs années d’itérations pour être finalisé.
Certains marchés de calcul GPU actuellement opérationnels peuvent gérer de petites charges, mais dès qu’on tente de passer à l’échelle, des failles apparaissent — souvent dues à des lacunes fondamentales dans leur architecture.
Problème de fiabilité : défi et opportunité
Un autre défi majeur pour les réseaux de calcul décentralisés est de garantir la fiabilité des nœuds — c’est-à-dire vérifier qu’un nœud fournit bien la puissance de calcul annoncée. Actuellement, cette validation repose souvent sur des systèmes de réputation, où les fournisseurs sont classés selon leur score. La technologie blockchain offre ici un avantage naturel, permettant des mécanismes de vérification sans confiance. Certaines startups, comme Gensyn et Spheron, explorent justement des méthodes sans confiance pour y parvenir.
De nombreuses équipes Web3 continuent de lutter contre ces difficultés, ce qui signifie que les opportunités dans ce domaine restent vastes.
Taille du marché du calcul décentralisé
Quelle est la taille potentielle du marché des réseaux de calcul décentralisés ?
Pour l’instant, il ne représente qu’une infime fraction du marché du cloud computing mondial (680 milliards à 2 500 milliards de dollars). Toutefois, tant que le calcul décentralisé coûte moins cher que les fournisseurs traditionnels, une demande subsistera, même avec une expérience utilisateur légèrement moins fluide.
Je pense qu’à court et moyen terme, le coût du calcul décentralisé restera inférieur, grâce à deux facteurs : les subventions par tokens et la mise à disposition de ressources provenant d’utilisateurs insensibles au prix. Par exemple, si je peux louer mon ordinateur portable de jeu et gagner quelques dizaines de dollars par mois, je serai satisfait.
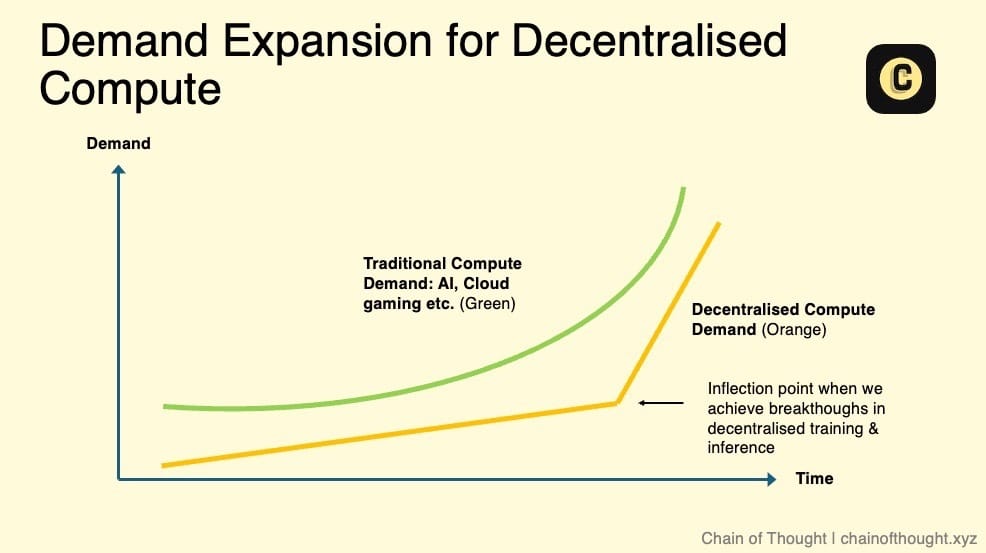
La véritable croissance potentielle et l’expansion significative de ce marché dépendront de plusieurs facteurs clés :
-
Faisabilité de l’entraînement d’IA décentralisée : lorsque les réseaux décentralisés pourront supporter l’entraînement de modèles IA, une demande massive émergera.
-
Explosion de la demande d’inférence : la demande croissante en inférence pourrait dépasser la capacité des centres de données existants. Ce phénomène a déjà commencé. Jensen Huang de NVIDIA prévoit que la demande d’inférence augmentera de « milliards de fois ».
-
Mise en place d’accords de niveau de service (SLA) : actuellement, le calcul décentralisé fonctionne sur une base « best effort », avec une incertitude sur la qualité de service (disponibilité). Les SLA permettraient d’offrir des indicateurs standardisés de fiabilité et de performance, levant ainsi un obstacle majeur à l’adoption par les entreprises, et faisant du calcul décentralisé une alternative viable au cloud traditionnel.
Le calcul décentralisé et sans permission est la couche fondamentale de l’écosystème d’IA décentralisée, et l’une de ses infrastructures les plus cruciales.
Même si la chaîne d’approvisionnement matérielle (GPU, etc.) continue de s’étendre, je crois que nous sommes encore à l’aube de l’ère de l’intelligence humaine. À l’avenir, la demande en puissance de calcul sera sans fin.
Soyez attentifs aux points de basculement critiques susceptibles de redéfinir le marché des GPU — ils pourraient arriver très bientôt.
Autres remarques :
-
La concurrence sur le marché pur des GPU est féroce, entre plateformes décentralisées et nouveaux venus Web2 comme Vast.ai ou Lambda.
-
Les petits nœuds (ex. : 4 GPU H100) ont une utilité limitée et peu de demande. En revanche, trouver des fournisseurs disposant de grands clusters est presque impossible, car leur demande reste très forte.
-
L’offre de ressources des protocoles décentralisés sera-t-elle consolidée par un acteur dominant, ou restera-t-elle fragmentée entre plusieurs marchés ? Je penche pour la première hypothèse, anticipant une distribution en loi de puissance, car la consolidation améliore l’efficacité des infrastructures. Bien sûr, cela prendra du temps, et la fragmentation persistera d’ici là.
-
Les développeurs veulent se concentrer sur la création d’applications, pas sur la gestion du déploiement. Les marchés de calcul doivent donc simplifier ces complexités, réduisant autant que possible les frictions liées à l’obtention de ressources.
1.2 Entraînement décentralisé
Résumé
-
Si les lois d’extension (Scaling Laws) tiennent, entraîner les prochains modèles IA de pointe dans un seul centre de données deviendra physiquement impossible.
-
L’entraînement de modèles IA requiert d’importants transferts de données entre GPU ; la faible vitesse de connexion dans les réseaux GPU distribués est le principal obstacle technique.
-
Les chercheurs explorent plusieurs solutions et ont réalisé des percées récentes (Open DiLoCo, DisTrO). Ces innovations s’additionneront, accélérant le développement de l’entraînement décentralisé.
-
L’entraînement décentralisé pourrait davantage se concentrer sur des modèles spécialisés de petite taille que sur des modèles AGI de pointe.
-
Avec la popularisation de modèles comme o1 d’OpenAI, la demande d’inférence va exploser, créant une immense opportunité pour les réseaux d’inférence décentralisés.
Imaginez : un modèle d’IA gigantesque et révolutionnaire, non conçu par un laboratoire secret d’élite, mais par des millions de personnes ordinaires. Les GPU des joueurs ne servent plus seulement à rendre des graphismes époustouflants dans Call of Duty, mais à soutenir un objectif plus grand — un modèle d’IA open source, collectivement détenu, sans aucun gardien centralisé.
Dans ce futur, les modèles d’IA de base ne sont plus l’apanage des laboratoires d’élite, mais le fruit d’une participation collective.
Mais revenons à la réalité : la majorité de l’entraînement IA lourd se fait encore dans des centres de données centralisés, et cette tendance devrait perdurer encore quelque temps.
Des sociétés comme OpenAI agrandissent continuellement leurs clusters massifs de GPU. Elon Musk a récemment révélé que xAI achève un centre de données doté de l’équivalent de 200 000 GPU H100.
Mais le problème ne se limite pas au nombre de GPU. Dans leur article PaLM de 2022, Google introduit un indicateur clé : l’utilisation des FLOPS du modèle (Model FLOPS Utilization, MFU), mesurant l’efficacité d’utilisation de la puissance maximale des GPU. Surprise : ce taux tourne autour de 35-40 %.
Pourquoi si bas ? Malgré les progrès fulgurants des GPU selon la loi de Moore, les avancées en réseau, mémoire et stockage sont nettement plus lentes, créant un goulot d’étranglement. Résultat : les GPU restent souvent inactifs, en attente de transferts de données.
La raison fondamentale de la centralisation actuelle de l’entraînement IA est unique : l’efficacité.
L’entraînement de grands modèles repose sur deux techniques clés :
-
Parallélisme de données : division du jeu de données entre plusieurs GPU pour accélérer l’entraînement.
-
Parallélisme de modèle : répartition des différentes parties du modèle sur plusieurs GPU pour contourner les limites de mémoire.
Ces techniques exigent des échanges fréquents de données entre GPU, rendant la vitesse de connexion (débit du réseau) critique.
Quand l’entraînement d’un modèle de pointe coûte jusqu’à un milliard de dollars, chaque gain d’efficacité est vital.
Les centres de données centralisés bénéficient de connexions ultra-rapides, permettant des transferts rapides entre GPU et réduisant drastiquement le temps et le coût d’entraînement. C’est ce que les réseaux décentralisés ne peuvent encore égaler… du moins pour l’instant.
Surmonter les connexions lentes
Si vous parlez à des experts en IA, beaucoup vous diront que l’entraînement décentralisé est irréaliste.
Dans une architecture décentralisée, les clusters de GPU ne sont pas physiquement proches, ce qui ralentit fortement les transferts de données, devenant le goulot principal. L’entraînement nécessite une synchronisation constante entre GPU. Plus la distance est grande, plus la latence augmente — ce qui ralentit l’entraînement et augmente les coûts.
Une tâche qui prend quelques jours dans un centre de données centralisé pourrait demander deux semaines dans un environnement décentralisé, à coût supérieur. Clairement, ce n’est pas viable.
Pourtant, la situation évolue.
Encourageant : la recherche sur l’entraînement distribué connaît un essor rapide. Des chercheurs explorent plusieurs voies simultanément, comme en témoignent les nombreuses publications récentes. Ces avancées s’additionneront, accélérant le développement de l’entraînement décentralisé.
De plus, les tests en environnement de production sont cruciaux pour repousser les limites technologiques.
Certaines technologies d’entraînement décentralisé peuvent déjà traiter des modèles de petite taille dans des environnements à faible bande passante. La recherche de pointe cherche désormais à étendre ces méthodes à des modèles plus volumineux.
-
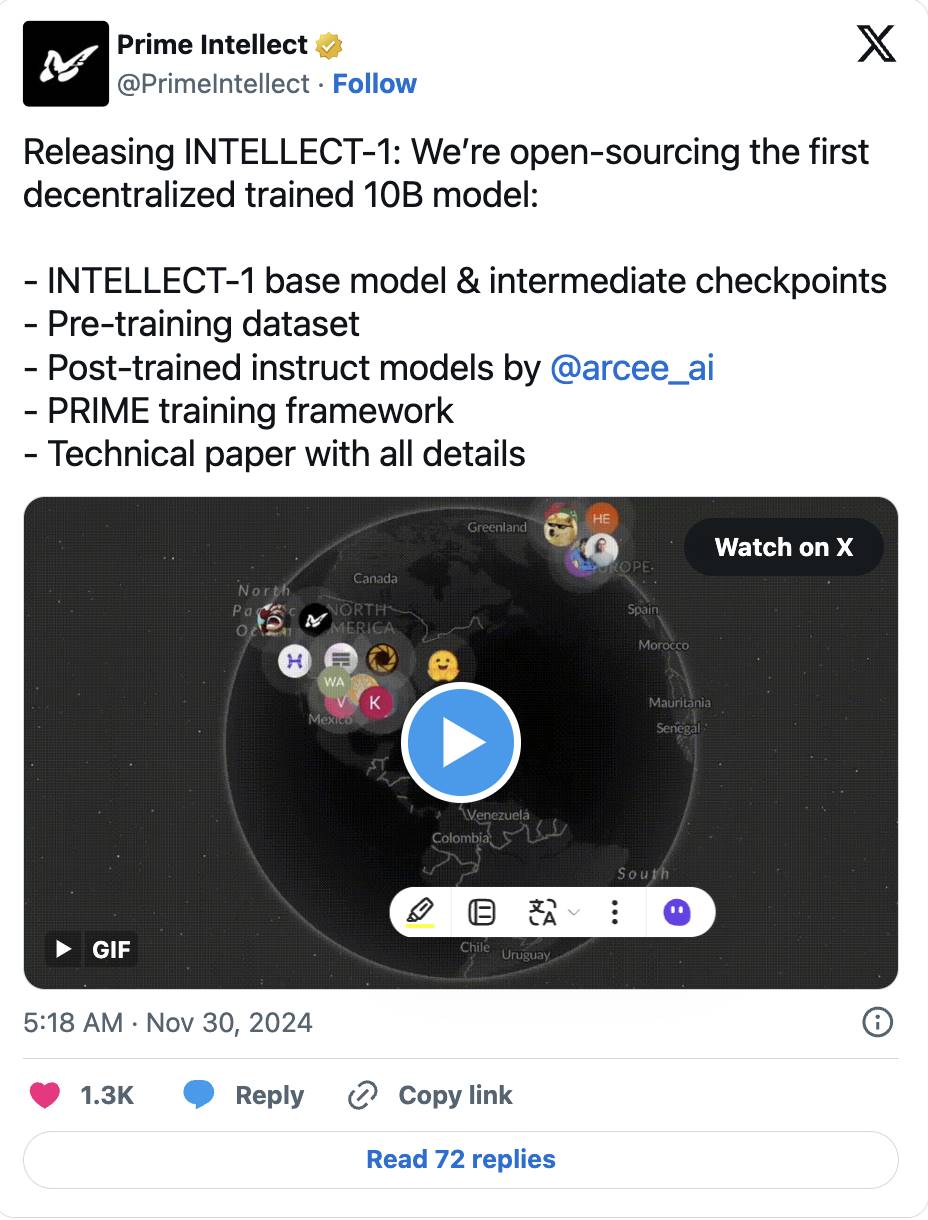
Par exemple, le papier Open DiCoLo de Prime Intellect propose une méthode pratique : diviser les GPU en « archipels », chacun effectuant 500 calculs locaux avant synchronisation, réduisant la demande de bande passante à 1/500. Initialement une recherche de Google DeepMind sur de petits modèles, cette technique a été étendue à un modèle de 10 milliards de paramètres, désormais entièrement open source.
-
Nous Research a poussé plus loin avec son cadre DisTrO, réduisant les communications entre GPU jusqu’à 10 000 fois via des techniques d’optimiseur, tout en entraînant un modèle de 1,2 milliard de paramètres.
-
L’élan se poursuit : Nous a récemment annoncé avoir achevé la pré-entraîne d’un modèle de 15 milliards de paramètres, dont la courbe de perte et la vitesse de convergence surpassent même celles de l’entraînement centralisé traditionnel.
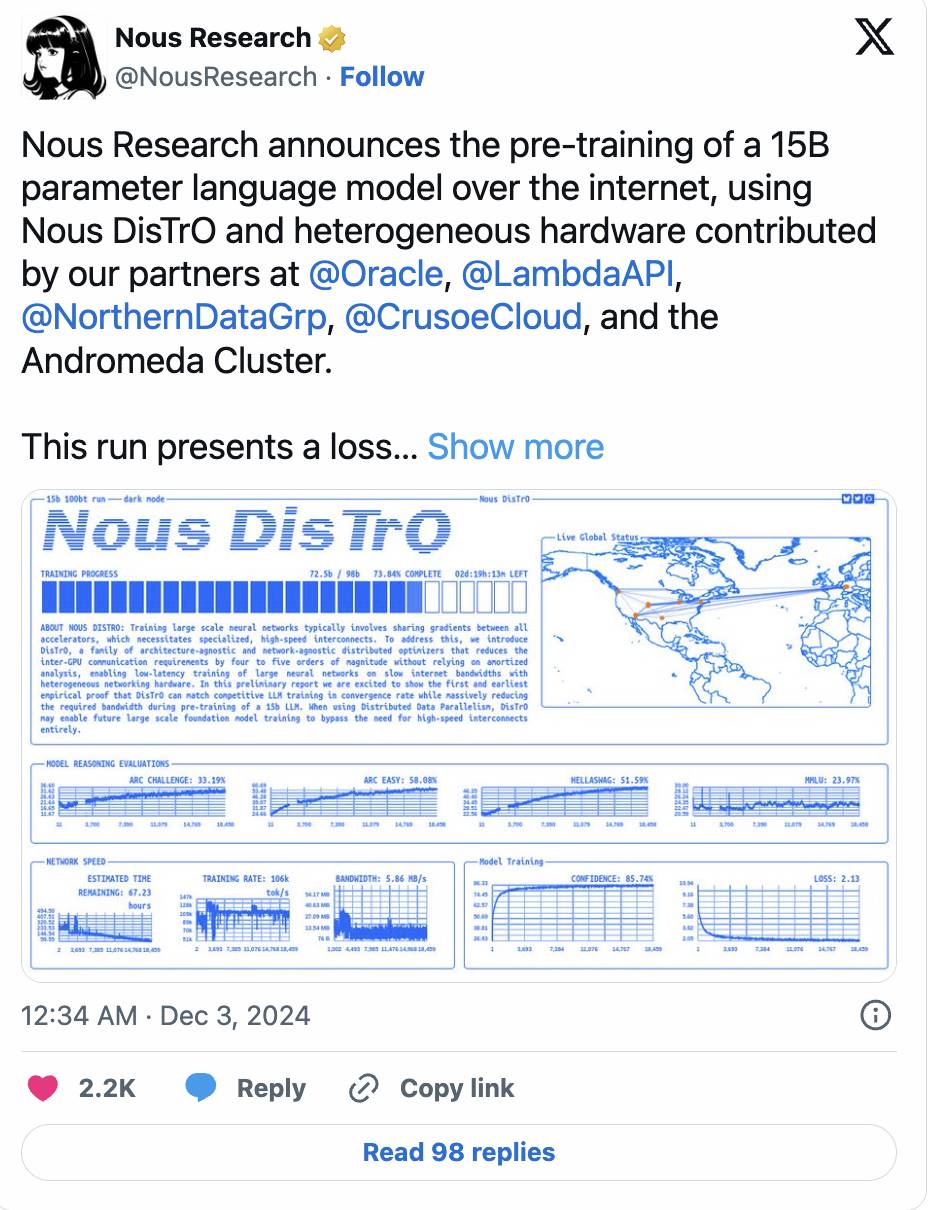
-
Des méthodes comme SWARM Parallelism ou DTFMHE explorent aussi comment entraîner des modèles d’IA massifs sur des appareils variés, aux vitesses et conditions de connexion différentes.
Un autre défi : gérer l’hétérogénéité du matériel GPU, notamment les GPU grand public courants dans les réseaux décentralisés, souvent limités en mémoire. Grâce au parallélisme de modèle (répartition des couches sur plusieurs appareils), ce problème est progressivement résolu.
L’avenir de l’entraînement décentralisé
Pour l’instant, l’échelle des modèles formés par des méthodes décentralisées reste très en dessous des modèles de pointe (GPT-4 aurait près de mille milliards de paramètres, 100 fois plus que le modèle de 10 milliards de Prime Intellect). Pour vraiment évoluer, des percées majeures sont nécessaires en architecture de modèle, infrastructure réseau et stratégie d’allocation de tâches.
Mais imaginons : l’entraînement décentralisé pourrait un jour mobiliser plus de puissance de calcul GPU que le plus grand centre de données centralisé.
Pluralis Research (une équipe à surveiller dans ce domaine) pense que c’est non seulement possible, mais inévitable. Les centres centralisés sont limités par des contraintes physiques — espace, alimentation électrique — tandis que les réseaux décentralisés peuvent tirer parti de ressources quasi infinies à l’échelle mondiale.
Même Jensen Huang de NVIDIA a mentionné que l’entraînement asynchrone décentralisé pourrait être la clé pour libérer le potentiel d’extension de l’IA. De plus, les réseaux d’entraînement distribués offrent une meilleure tolérance aux pannes.
Ainsi, dans un futur plausible, le modèle d’IA le plus puissant au monde pourrait être entraîné de manière décentralisée.
Cette vision est passionnante, mais je reste prudent. Il nous faut davantage de preuves que l’entraînement décentralisé de modèles ultra-grands est techniquement et économiquement viable.
Je pense que l’entraînement décentralisé trouvera son meilleur usage dans des modèles open source plus petits et spécialisés, conçus pour des cas d’usage précis, plutôt que de rivaliser avec les modèles géants orientés AGI. Certaines architectures, notamment non Transformer, se prêtent déjà bien à l’environnement décentralisé.
En outre, les incitations par token joueront un rôle clé. Une fois que l’entraînement décentralisé atteindra une échelle viable, les tokens pourront efficacement motiver et récompenser les contributeurs, propulsant ces réseaux.
Malgré un long chemin, les progrès actuels sont encourageants. Les percées en entraînement décentralisé profiteront non seulement aux réseaux décentralisés, mais aussi aux grandes entreprises technologiques et laboratoires d’IA de pointe…
1.3 Inférence décentralisée
Actuellement, la majeure partie des ressources de calcul IA est consacrée à l’entraînement de grands modèles. Une course aux armements oppose les laboratoires d’IA de pointe, visant à créer le meilleur modèle de base et atteindre l’AGI.
Mais je pense que cet accent mis sur l’entraînement va progressivement se déplacer vers l’inférence au cours des prochaines années. Alors que l’IA s’intègre de plus en plus dans nos applications quotidiennes — santé, divertissement, etc. — les ressources nécessaires à l’inférence deviendront colossales.

Cette tendance n’est pas infondée. L’extension du calcul à l’inférence (Inference-time Compute Scaling) est devenue un sujet brûlant en IA. OpenAI a récemment publié une version préliminaire/minimale de son nouveau modèle o1 (nom de code : Strawberry), caractérisé par sa capacité à « prendre le temps de réfléchir ». Il analyse d’abord les étapes nécessaires pour répondre, puis les exécute progressivement.
Conçu pour des tâches complexes nécessitant planification — comme résoudre des mots croisés — il excelle dans les questions exigeant un raisonnement profond. Bien que plus lent à produire une réponse, il est plus réfléchi. Mais cela a un coût élevé : son inférence coûte 25 fois plus
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














