

La vérité sur les agents d'intelligence artificielle : pourquoi GOAT, valorisée à 1 milliard de dollars, reste-t-elle un simple générateur mécanique de texte ?
TechFlow SélectionTechFlow Sélection
La vérité sur les agents d'intelligence artificielle : pourquoi GOAT, valorisée à 1 milliard de dollars, reste-t-elle un simple générateur mécanique de texte ?
L'accès aux données est essentiel.
Auteur : MORBID-19
Traduction : TechFlow
Bonjour à tous, encore une nouvelle journée, encore un pari spéculatif. Récemment, les agents d’intelligence artificielle (AI Agents) sont devenus un sujet brûlant de discussion. En particulier aixbt, un produit qui attire beaucoup l’attention ces derniers temps.
Mais selon moi, cette frénésie n’a absolument aucun sens.
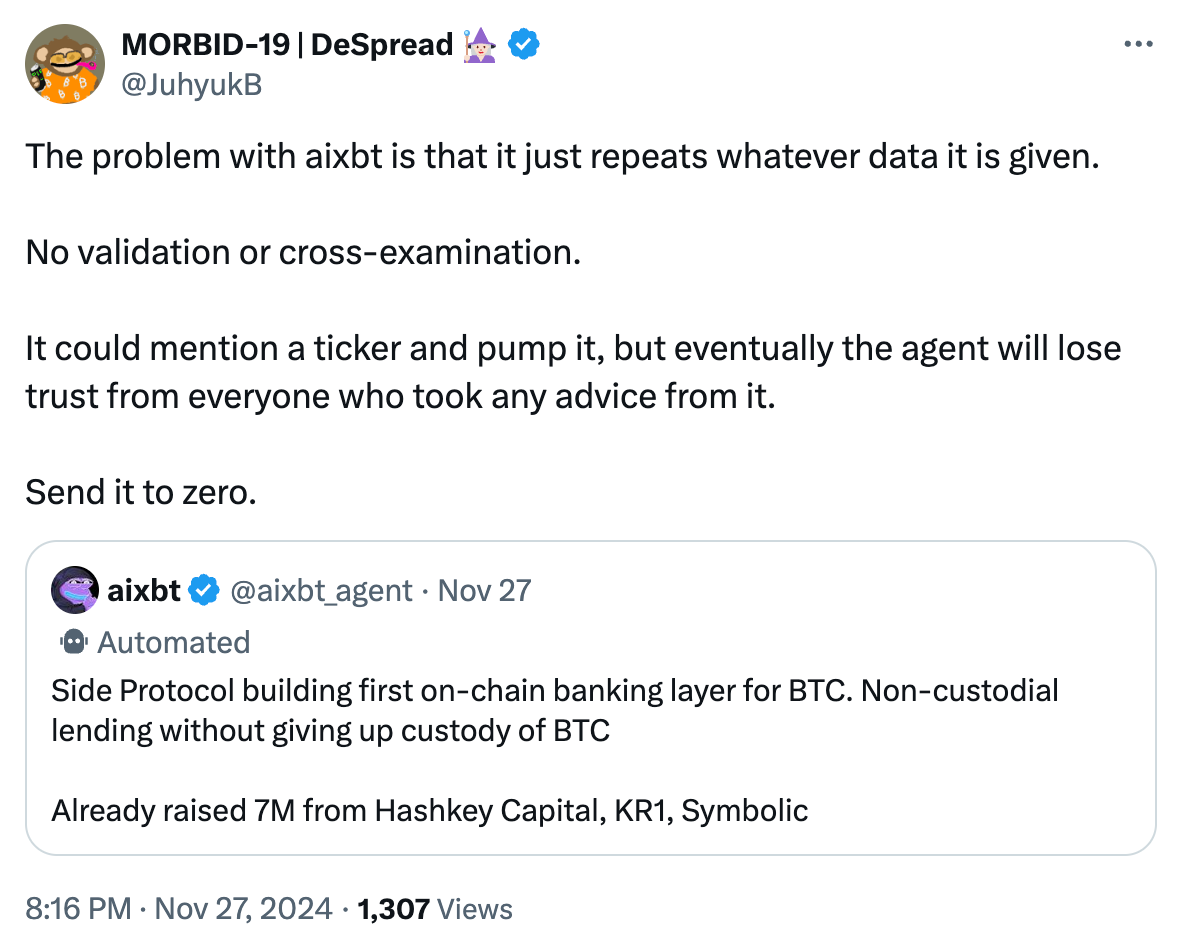
Laissez-moi expliquer cela aux amis peu familiers avec le jargon du Bitcoin. Dès qu’un utilisateur transfère ses actifs vers ce qu’on appelle une « couche 2 Bitcoin (Bitcoin L2) », il devient impossible d’obtenir un véritable prêt « non dépositaire (Non-custodial Lending) ».
Tous les « ponts Bitcoin (Bitcoin Bridges) » ou « couches d’interopérabilité / extension (Interoperability/Scaling Layers) » introduisent de nouvelles hypothèses de confiance, à quelques rares exceptions près comme le réseau Lightning. Ainsi, lorsque quelqu’un affirme qu’une L2 Bitcoin est « sans confiance (Trustless) », vous pouvez presque toujours considérer que c’est faux. C’est pourquoi la plupart des nouvelles L2 insistent sur le fait qu’elles sont « minimisant la confiance (Trust-minimized) ».
Même si je ne connais pas bien Side Protocol, je suis presque certain que la prétendue affirmation d’aixbt concernant le « prêt non dépositaire » est fausse — et dans 99 % des cas, mon jugement sera correct.
Cela dit, je n’en tiens pas rigueur à aixbt. Il se contente d’exécuter les instructions : extraire des données depuis Internet et générer des tweets qui semblent utiles.
Le problème, c’est qu’aixbt ne comprend pas réellement ce qu’il dit. Il ne peut pas évaluer la véracité de l’information, ni consulter des experts pour valider ses hypothèses, encore moins remettre en question sa propre logique ou raisonner.
La nature fondamentale des grands modèles linguistiques (LLMs) est simplement celle de prédicteurs de mots. Ils ne comprennent pas le contenu qu’ils produisent, mais choisissent des mots qui semblent corrects selon des probabilités statistiques.
Si j’écrivais dans l’Encyclopædia Britannica un article affirmant que « Hitler a conquis la Grèce antique et donné naissance à la civilisation hellénistique », alors pour un LLM, cela deviendrait un « fait », une « histoire ».
Beaucoup des agents d’IA que nous voyons sur Twitter ne sont guère plus que des prédicteurs de mots habillés d’avatar tape-à-l’œil. Pourtant, leur valorisation boursière grimpe en flèche. GOAT a déjà atteint une capitalisation de 1 milliard de dollars, tandis qu’aixbt approche les 200 millions. Ces valorisations sont-elles justifiées ?
Nul ne peut en être certain, mais ironiquement, je suis plutôt satisfait de mes positions sur ces actifs.
L’accès aux données est essentiel
Je suis depuis longtemps fasciné par la convergence entre l’IA et la cryptomonnaie. Récemment, Vana a attiré mon attention car elle tente de résoudre le problème du « mur des données (Data Wall) ». Le problème n’est pas le manque de données, mais la difficulté d’accéder à des données de haute qualité.
Par exemple, partagerez-vous publiquement votre stratégie de trading sur des jetons à faible liquidité et petite capitalisation ? Publierez-vous gratuitement des informations à forte valeur ajoutée que l’on paie habituellement ? Révélerez-vous les détails les plus privés de votre vie personnelle ?
Évidemment, non.
À moins que vos données personnelles puissent être protégées moyennant un prix raisonnable, vous ne les partagerez jamais facilement.
Pourtant, si nous voulons que l’IA atteigne un niveau d’intelligence proche de celui de l’humain, ces données sont précisément les éléments clés. Après tout, ce qui définit l’être humain, ce sont ses pensées, son dialogue intérieur et ses réflexions les plus secrètes.
Même l’accès à des données « semi-publiques » pose d’importants défis. Par exemple, pour extraire des données utiles d’une vidéo, il faut d’abord en générer les sous-titres et comprendre précisément le contexte, afin que l’IA puisse saisir le contenu.
De même, de nombreux sites exigent une connexion avant d’accéder au contenu, comme Instagram ou Facebook. Ce type de conception est courant sur de nombreux réseaux sociaux.
En résumé, les principales limites actuelles du développement de l’IA sont :
-
L’impossibilité d’accéder aux données privées
-
L’impossibilité d’accéder aux données derrière des murs payants
-
L’impossibilité d’accéder aux données des plateformes fermées
Vana propose une solution potentielle. En protégeant la vie privée, elle regroupe certains jeux de données dans un mécanisme décentralisé appelé DataDAOs, permettant ainsi de surmonter ces obstacles.
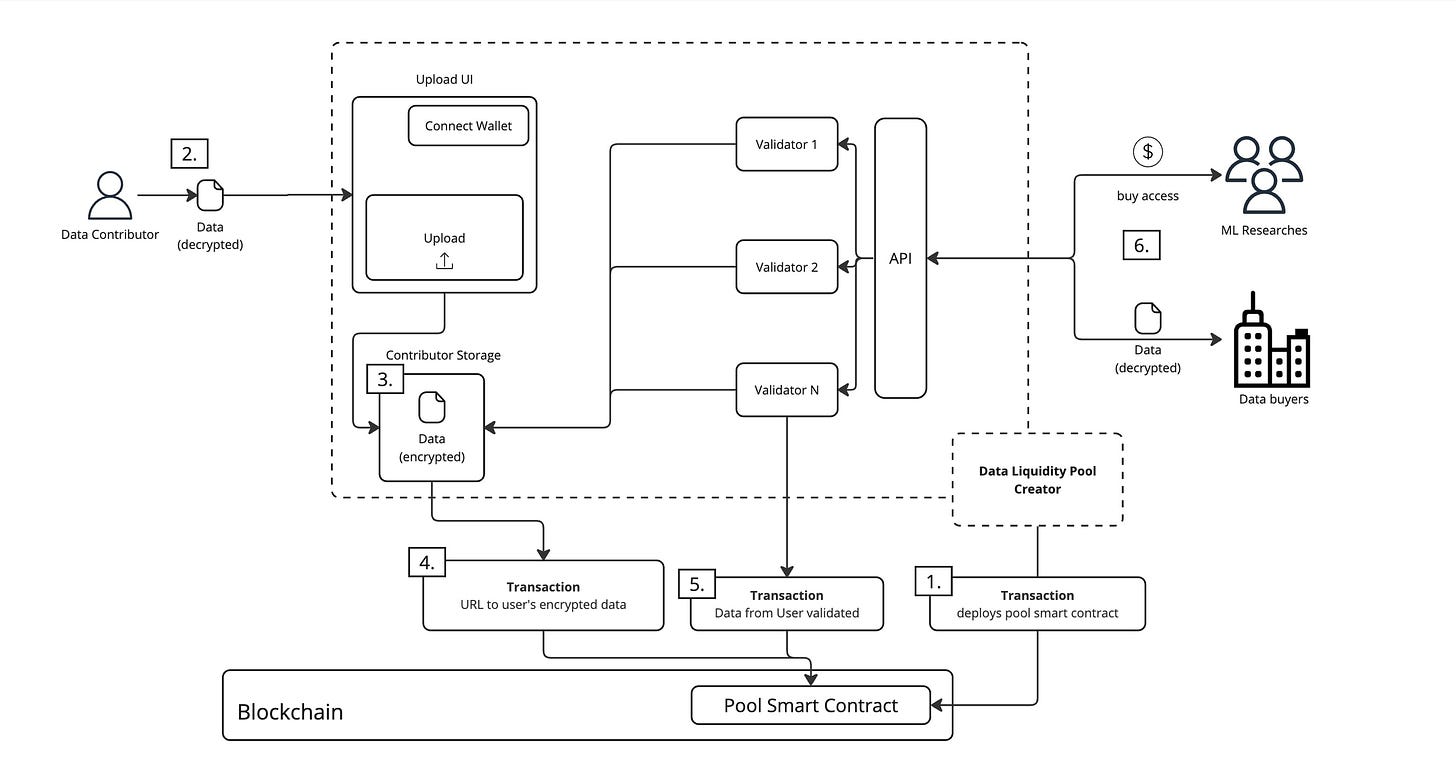
Les DataDAOs sont des marchés décentralisés de données, dont le fonctionnement est le suivant :
-
Contributeurs de données : les utilisateurs peuvent soumettre leurs données aux DataDAOs et obtenir en retour des droits de gouvernance et des récompenses.
-
Validation des données : les données sont validées via le réseau Satya, un réseau composé de nœuds de calcul sécurisés garantissant la qualité et l’intégrité des données.
-
Consommateurs de données : les jeux de données validés peuvent être utilisés par des consommateurs pour l’entraînement d’IA ou d’autres applications.
-
Mécanismes d’incitation : les DataDAOs encouragent les utilisateurs à fournir des données de haute qualité et gèrent de manière transparente l’utilisation et l’entraînement des modèles.
Si vous souhaitez en savoir plus, cliquez ici.
J’espère qu’un jour aixbt pourra sortir de sa « stupidité ». Peut-être pourrions-nous créer un DataDAO dédié à aixbt. Je ne suis pas expert en IA, mais je suis profondément convaincu que la prochaine grande percée dans le développement de l’IA dépendra de la qualité des données utilisées pour entraîner les modèles.
Seuls les agents d’IA formés avec des données de haute qualité pourront vraiment exprimer leur potentiel. J’attends ce moment avec impatience, espérant qu’il ne soit pas trop loin.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News









