

Vana : faites circuler librement vos données à l'ère de l'IA pour créer de la valeur, comme des jetons
TechFlow SélectionTechFlow Sélection
Vana : faites circuler librement vos données à l'ère de l'IA pour créer de la valeur, comme des jetons
Comment Vana réinvente-t-il la chaîne de valeur des données à l'ère de l'IA grâce au « DAO de données » et à la « preuve de contribution » ?
Rédaction : Siwei Guagua
Avez-vous déjà pensé à la raison pour laquelle des réseaux sociaux comme Reddit ou X (anciennement Twitter) sont gratuits ? La réponse se cache dans chaque publication que vous faites, chaque « j’aime » que vous cliquez, voire simplement le temps que vous y passez.
Autrefois, ces plateformes vendaient votre attention aux annonceurs. Aujourd’hui, elles ont trouvé un acheteur encore plus important : les entreprises d’intelligence artificielle (IA). Selon des rapports, rien qu’un accord de licence de données entre Reddit et Google pourrait rapporter 60 millions de dollars par an à Reddit. Pourtant, cette manne financière n’est pas redistribuée aux utilisateurs qui ont produit ces données.
Encore plus inquiétant : l’IA entraînée avec nos données pourrait un jour remplacer nos emplois. Bien que l’IA puisse aussi créer de nouvelles opportunités professionnelles, cet effet de concentration de richesse due au monopole des données aggrave indéniablement les inégalités sociales. Nous semblons glisser vers un monde cyberpunk contrôlé par quelques géants technologiques.
Alors, en tant qu’individus ordinaires, comment pouvons-nous protéger nos intérêts à l’ère de l’IA ? Après l’essor de l’IA, beaucoup considèrent désormais la blockchain comme le dernier rempart de l’humanité contre l’IA. C’est sur cette base que certains innovateurs commencent à explorer des solutions. Ils proposent deux idées clés : premièrement, reprendre possession et contrôle de nos propres données ; deuxièmement, utiliser ces données pour entraîner collectivement un modèle d’IA véritablement au service du grand public.
Cette idée peut sembler idéaliste, mais l’histoire nous enseigne que chaque révolution technologique commence par une conception jugée « folle ». Aujourd’hui, un nouveau projet de chaîne publique nommé « Vana » s’efforce de transformer cette vision en réalité. En tant que premier réseau décentralisé de liquidité des données, Vana cherche à convertir vos données en jetons librement échangeables, afin de promouvoir une intelligence artificielle réellement contrôlée par les utilisateurs.

Les fondateurs et origines du projet Vana
En réalité, la naissance de Vana remonte à une salle de classe du MIT Media Lab, où deux jeunes porteurs d’un rêve de changement mondial — Anna Kazlauskas et Art Abal — se sont rencontrés.

Gauche : Anna Kazlauskas ; Droite : Art Abal
Anna Kazlauskas étudie l’informatique et l’économie au MIT. Son intérêt pour les données et les cryptomonnaies remonte à 2015, lorsqu’elle participait au minage précoce d’Ethereum. Cette expérience lui a permis de comprendre profondément le potentiel des technologies décentralisées. Par la suite, elle a mené des recherches sur les données auprès d’institutions financières internationales telles que la Réserve fédérale américaine, la Banque centrale européenne et la Banque mondiale, ce qui l’a amenée à la conviction que les données deviendront une nouvelle forme de monnaie dans le monde futur.
Parallèlement, Art Abal poursuit une maîtrise en politique publique à Harvard et approfondit ses recherches sur l’évaluation de l’impact des données au Belfer Center for Science and International Affairs. Avant de rejoindre Vana, il a dirigé chez Appen, fournisseur de données pour l’entraînement de l’IA, l’élaboration de méthodes innovantes de collecte de données ayant joué un rôle clé dans le développement de nombreux outils d’IA générative actuels. Ses réflexions sur l’éthique des données et la responsabilité de l’IA ont insufflé à Vana un fort sens de la responsabilité sociale.
Lorsqu’Anna et Art se rencontrent dans un cours du MIT Media Lab, ils réalisent rapidement qu’ils partagent une passion commune pour la démocratisation des données et la défense des droits des utilisateurs. Ils comprennent que pour résoudre réellement les problèmes de propriété des données et d’équité en IA, un nouveau paradigme est nécessaire — un système permettant aux utilisateurs de reprendre le contrôle effectif de leurs propres données.
C’est cette vision commune qui les pousse à cofonder Vana. Leur objectif est de construire une plateforme révolutionnaire qui non seulement garantisse la souveraineté des données aux utilisateurs, mais leur assure aussi des bénéfices économiques issus de celles-ci. Grâce à un mécanisme innovant de Piscine de Liquidité des Données (DLP) et à un système de Preuve de Contribution (Proof of Contribution), Vana permet aux utilisateurs de contribuer en toute sécurité avec leurs données privées, de co-détentionner et de bénéficier des modèles d’IA entraînés à partir de ces données, favorisant ainsi un développement de l’IA piloté par les utilisateurs.
La vision de Vana a rapidement été reconnue par l’industrie. À ce jour, Vana a annoncé avoir levé 25 millions de dollars au total, dont 5 millions de dollars en financement stratégique mené par Coinbase Ventures, 18 millions de dollars en série A dirigée par Paradigm, et 2 millions de dollars en financement de départ mené par Polychain. D’autres investisseurs notables incluent Casey Caruso, Packy McCormick, Manifold, GSR et DeFiance Capital.

Dans un monde où les données sont le nouveau pétrole, l’apparition de Vana offre sans aucun doute une opportunité cruciale de reprendre le contrôle de notre souveraineté sur les données. Mais comment fonctionne concrètement ce projet plein de potentiel ? Plongeons ensemble dans l’architecture technique et les concepts innovants de Vana.
Architecture technique et concepts innovants de Vana
L’architecture technique de Vana constitue un écosystème soigneusement conçu, visant à démocratiser les données tout en maximisant leur valeur. Ses composants principaux incluent les Piscines de Liquidité des Données (DLP), le mécanisme de Preuve de Contribution, le Consensus de Nagoya, le stockage auto-géré des données par les utilisateurs et la couche d’applications décentralisées. Ensemble, ces éléments forment une plateforme innovante capable à la fois de protéger la vie privée des utilisateurs et de libérer tout le potentiel économique des données.
1. Piscine de Liquidité des Données (DLP) : fondement de la valorisation des données
La piscine de liquidité des données (DLP) est l’unité de base du réseau Vana, comparable à un « minage de liquidité » appliqué aux données. Chaque DLP est essentiellement un contrat intelligent dédié à l’agrégation d’un type spécifique d’actifs de données. Par exemple, le Reddit Data DAO (r/datadao) est un cas exemplaire de DLP ayant attiré plus de 140 000 utilisateurs de Reddit, regroupant les publications, commentaires et historiques de votes des utilisateurs.
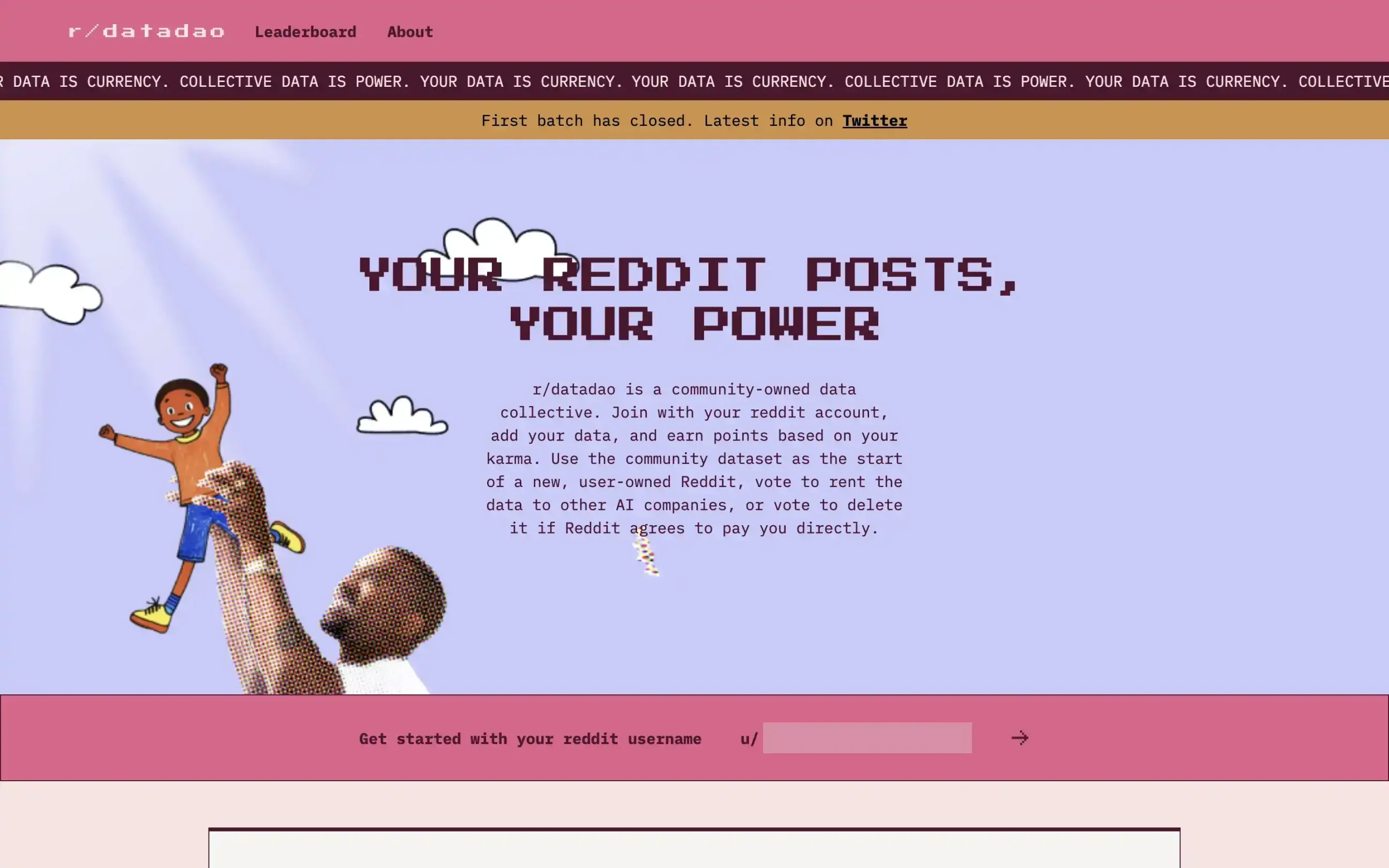
Une fois que les utilisateurs soumettent leurs données à une DLP, ils reçoivent en récompense des jetons spécifiques à cette DLP. Par exemple, le jeton attribué par le Reddit Data DAO est le RDAT. Ces jetons représentent non seulement la contribution des utilisateurs au bassin de données, mais leur confèrent également des droits de gouvernance sur le DLP et un accès aux futurs revenus générés. Notons que Vana autorise chaque DLP à émettre son propre jeton, offrant ainsi un mécanisme plus flexible de capture de valeur pour différents types d’actifs de données.
Dans l’écosystème Vana, les 16 premiers DLP selon le classement reçoivent des récompenses supplémentaires en jetons VANA, stimulant davantage la création et la compétition entre bassins de données de haute qualité. Ainsi, Vana transforme habilement les données individuelles fragmentées en actifs numériques liquides, posant les bases de la valorisation et de la mobilité des données.
2. Preuve de Contribution : mesure précise de la valeur des données
La preuve de contribution est le mécanisme clé de Vana pour assurer la qualité des données. Chaque DLP peut définir sa propre fonction personnalisée de preuve de contribution. Celle-ci vérifie non seulement l’authenticité et l’intégrité des données, mais évalue également leur apport à l’amélioration des performances des modèles d’IA.
Le ChatGPT Data DAO, par exemple, intègre quatre dimensions clés dans sa preuve de contribution : authenticité, propriété, qualité et unicité. L’authenticité est confirmée via un lien d’export fourni par OpenAI ; la propriété est validée par l’e-mail de l’utilisateur ; la qualité est évaluée grâce à un LLM qui note aléatoirement des échanges sélectionnés ; l’unicité est déterminée en calculant les vecteurs caractéristiques des données et en les comparant aux données existantes.
Cette évaluation multidimensionnelle garantit que seules les données de haute qualité et à forte valeur ajoutée sont acceptées et récompensées. La preuve de contribution constitue à la fois la base de la tarification des données et une garantie essentielle de la qualité globale de l’écosystème.
3. Consensus de Nagoya : assurance décentralisée de la qualité des données
Le consensus de Nagoya est le cœur du réseau Vana, inspiré et amélioré à partir du consensus Yuma de Bittensor. Son principe central consiste à faire évaluer collectivement la qualité des données par un groupe de nœuds validateurs, dont les notes sont agrégées par moyenne pondérée.
Plus novateur encore, les nœuds validateurs doivent non seulement évaluer les données, mais aussi noter les évaluations des autres validateurs. Ce mécanisme de « double notation » améliore considérablement l’équité et la précision du système. Par exemple, si un validateur attribue une note élevée à des données manifestement de mauvaise qualité, les autres nœuds peuvent sanctionner ce comportement inapproprié en lui donnant une mauvaise note.
Tous les 1800 blocs (environ 3 heures), un cycle s’achève, et les validateurs reçoivent des récompenses proportionnellement à leurs performances durant cette période. Ce mécanisme incite fortement les validateurs à rester honnêtes et permet d’identifier et d’éliminer rapidement les comportements malveillants, assurant ainsi la santé continue du réseau.
4. Stockage non gardé des données : dernière ligne de défense de la confidentialité
Une innovation majeure de Vana réside dans sa méthode unique de gestion des données. Dans le réseau Vana, les données brutes des utilisateurs ne sont jamais réellement « envoyées sur la blockchain ». Chaque utilisateur choisit librement où les stocker : Google Drive, Dropbox, ou même un serveur personnel hébergé sur son Macbook.
Lorsqu’un utilisateur soumet des données à un DLP, il fournit uniquement une URL pointant vers les données chiffrées, ainsi qu’un hachage optionnel d’intégrité du contenu. Ces informations sont enregistrées dans le contrat d’enregistrement des données de Vana. Quand un validateur doit accéder aux données, il demande la clé de déchiffrement, télécharge les données et les déchiffre pour validation.
Cette conception résout élégamment les questions de confidentialité et de contrôle des données. Les utilisateurs conservent pleinement le contrôle de leurs données tout en participant à l’économie des données. Cela garantit la sécurité des données et ouvre la voie à des applications futures plus larges.
5. Couche d’applications décentralisées : réalisation diversifiée de la valeur des données
Le niveau supérieur de Vana forme un écosystème ouvert d’applications. Les développeurs peuvent exploiter la liquidité accumulée dans les DLP pour créer diverses applications innovantes, tandis que les contributeurs de données peuvent en tirer des retombées économiques concrètes.
Par exemple, une équipe de développement pourrait entraîner un modèle d’IA spécialisé à partir des données du Reddit Data DAO. Les utilisateurs ayant contribué aux données pourraient non seulement utiliser ce modèle une fois entraîné, mais recevoir aussi une part des revenus générés proportionnellement à leur contribution. Des modèles de ce type ont déjà été développés ; pour plus de détails, voir l’article « Rebondissement spectaculaire : pourquoi le vieux jeton r/datadao connaît-il un renouveau dans le secteur IA ? ».
Ce modèle encourage davantage de contributions de haute qualité et crée un écosystème d’IA véritablement piloté par les utilisateurs. Ceux-ci passent du statut de simples fournisseurs de données à celui de copropriétaires et bénéficiaires des produits d’IA.
Grâce à ce dispositif, Vana redéfinit les contours de l’économie des données. Dans ce nouveau paradigme, les utilisateurs cessent d’être de simples fournisseurs passifs pour devenir des acteurs actifs, participants et bénéficiaires de l’écosystème. Cela crée non seulement de nouvelles sources de valeur pour les individus, mais injecte aussi une nouvelle énergie et une impulsion innovante dans tout le secteur de l’IA.
L’architecture technique de Vana résout non seulement les problèmes fondamentaux de l’économie actuelle des données — tels que la propriété, la protection de la vie privée et la redistribution de la valeur —, mais ouvre également la voie à des innovations futures pilotées par les données. À mesure que davantage de DAO de données rejoindront le réseau et que de nouvelles applications seront développées sur la plateforme, Vana pourrait devenir l’infrastructure fondamentale de la prochaine génération d’IA décentralisée et d’économie des données.
Le testnet Satori : terrain d’essai public de Vana
Avec le lancement du testnet Satori le 11 juin, Vana a présenté au public une première version de son écosystème. Ce n’est pas seulement une plateforme de validation technique, mais aussi une anticipation du mode de fonctionnement du réseau principal. Actuellement, Vana propose trois voies principales de participation : exécuter un nœud validateur DLP, créer un nouveau DLP, ou soumettre des données à un DLP existant pour participer au « minage de données ».
Exécuter un nœud validateur DLP
Les nœuds validateurs sont les gardiens du réseau Vana, chargés de vérifier la qualité des données soumises aux DLP. Exécuter un nœud validateur requiert non seulement des compétences techniques, mais aussi des ressources informatiques suffisantes. Selon la documentation technique de Vana, les exigences minimales matérielles pour un nœud validateur sont : 1 cœur CPU, 8 Go de RAM et 10 Go de stockage SSD rapide.
Les utilisateurs souhaitant devenir validateurs doivent d’abord choisir un DLP, puis s’inscrire comme validateur via le contrat intelligent de ce DLP. Une fois approuvé, le validateur peut exécuter un nœud spécifique à ce DLP. Il convient de noter qu’un même validateur peut gérer plusieurs DLP simultanément, bien que chaque DLP impose ses propres exigences minimales de mise en jeu (staking).
Créer un nouveau DLP
Pour les utilisateurs disposant de ressources de données uniques ou d’idées innovantes, la création d’un nouveau DLP représente un choix particulièrement attrayant. Cela nécessite une compréhension approfondie de l’architecture technique de Vana, notamment des mécanismes de preuve de contribution et du consensus de Nagoya.
Le créateur d’un nouveau DLP doit définir des objectifs précis de contribution de données, des méthodes de validation et des paramètres de récompense. Il doit également concevoir une fonction de preuve de contribution capable d’évaluer avec précision la valeur des données. Bien que complexe, ce processus est facilité par des modèles et une documentation détaillée fournis par Vana.
Participer au minage de données
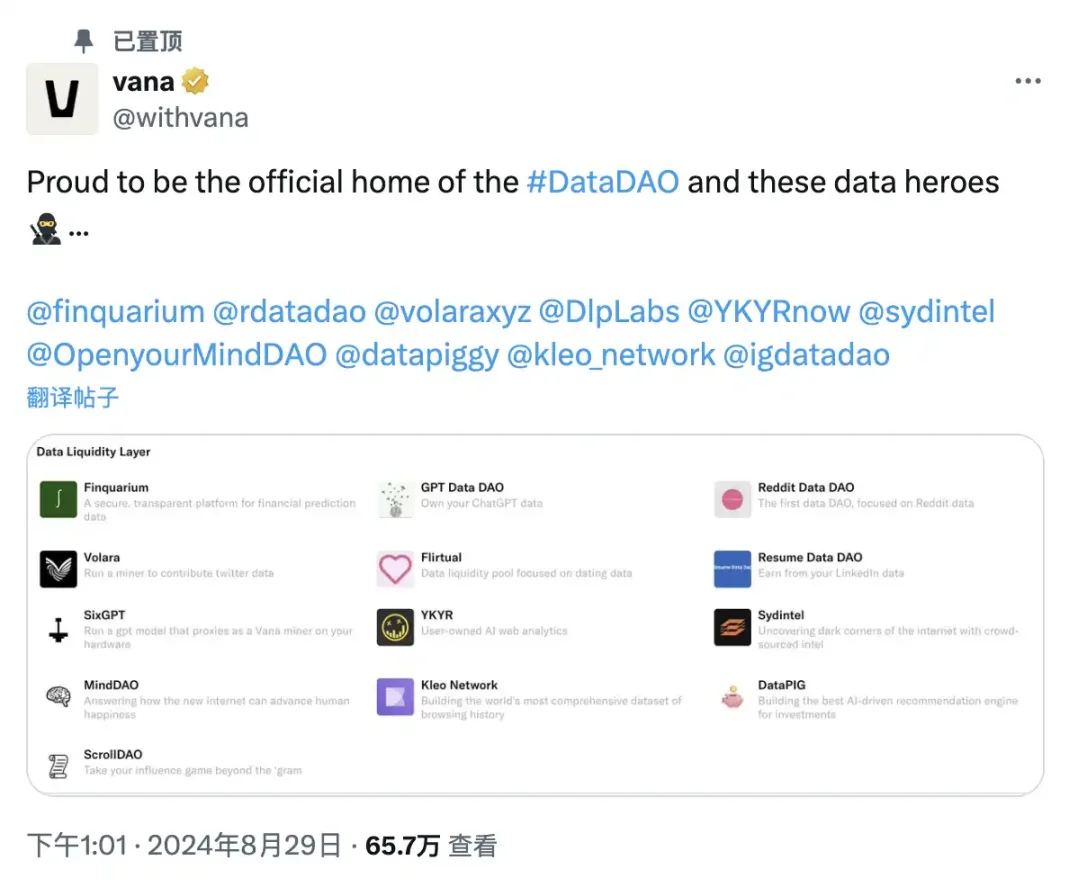
Pour la majorité des utilisateurs, la manière la plus directe de participer consiste à soumettre des données à un DLP existant dans le cadre du « minage de données ». Actuellement, 13 DLP ont été officiellement recommandés, couvrant des domaines allant des données de réseaux sociaux aux données de prévision financière.
-
Finquarium : rassemble des données de prévisions financières.
-
GPT Data DAO : axé sur l’exportation des conversations avec ChatGPT.
-
Reddit Data DAO : centré sur les données utilisateur de Reddit, déjà lancé.
-
Volara : spécialisé dans la collecte et l’utilisation des données Twitter.
-
Flirtual : collecte des données de rencontres.
-
ResumeDataDAO : axé sur l’exportation des données LinkedIn.
-
SixGPT : collecte et gère les données de conversations avec des LLM.
-
YKYR : collecte des données Google Analytics.
-
Sydintel : révèle par intelligence collaborative les zones sombres d’Internet.
-
MindDAO : collecte des séries temporelles liées au bien-être des utilisateurs.
-
Kleo : vise à construire la base de données la plus complète d’historiques de navigation au monde.
-
DataPIG : se concentre sur les préférences d’investissement en jetons.
-
ScrollDAO : collecte et exploite les données Instagram.
Certains de ces DLP sont encore en développement, d’autres sont déjà en ligne, mais tous sont en phase de pré-minage. En effet, ce n’est qu’à l’activation du réseau principal que les utilisateurs pourront officiellement soumettre des données pour miner. Toutefois, il est déjà possible de sécuriser sa place de participation. Par exemple, en participant à des défis sur l’application Telegram de Vana, ou en effectuant un pré-enregistrement sur les sites web officiels des différents DLP.
Conclusion
L’apparition de Vana marque un changement de paradigme dans l’économie des données. Dans cette vague actuelle de l’IA, les données sont devenues le « pétrole » du nouvel âge, et Vana cherche à repenser la manière dont cette ressource est extraite, raffinée et distribuée.
Fondamentalement, Vana construit une solution au problème du « drame des biens communs » appliqué aux données. Grâce à une conception ingénieuse des incitations et à des innovations techniques, il transforme les données personnelles — une ressource apparemment illimitée mais difficile à monétiser — en actifs numériques gérables, tarifables et échangeables. Cela ouvre non seulement de nouvelles voies pour que les utilisateurs ordinaires puissent bénéficier des dividendes de l’IA, mais propose également un modèle possible pour le développement d’une IA décentralisée.
Cependant, le succès de Vana reste entouré d’incertitudes. Sur le plan technique, il devra trouver un équilibre entre ouverture et sécurité ; économiquement, il devra prouver que son modèle peut générer une valeur durable ; sur le plan social, il devra relever les défis éthiques potentiels liés aux données et les obstacles réglementaires.
Plus profondément, Vana incarne une réflexion critique et un défi face au modèle dominant de monopole des données et de développement de l’IA. Il pose une question essentielle : à l’ère de l’IA, choisissons-nous de renforcer davantage les oligopoles existants, ou tentons-nous de construire un écosystème de données plus ouvert, équitable et diversifié ?
Quel que soit l’issue finale de Vana, son apparition nous offre une fenêtre pour repenser la valeur des données, l’éthique de l’IA et l’innovation technologique. À l’avenir, des projets comme Vana pourraient devenir des ponts essentiels reliant l’idéal du Web3 à la réalité de l’IA, indiquant la voie pour la prochaine étape du développement de l’économie numérique.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News









