

Quand le cantonais de ChatGPT « ne parle pas correctement » : à l'ère de l'IA, les langues à faibles ressources sont-elles condamnées à être marginalisées ?
TechFlow SélectionTechFlow Sélection
Quand le cantonais de ChatGPT « ne parle pas correctement » : à l'ère de l'IA, les langues à faibles ressources sont-elles condamnées à être marginalisées ?
Derrière le cantonais approximatif de l'IA, se joue une lutte entre transmission linguistique et répartition des ressources sociales.
Rédaction : Anita Zhang
Avez-vous déjà entendu ChatGPT parler cantonais ?
Si vous êtes un locuteur natif du mandarin, félicitations : vous venez d’obtenir instantanément le « succès maîtrise du cantonais ». En revanche, ceux qui parlent couramment le cantonais risquent d’être déroutés. L’accent singulier de ChatGPT ressemble à celui d’un étranger faisant des efforts pour parler cantonais.
En septembre 2023, une mise à jour a permis à ChatGPT de gagner la capacité de « parler » pour la première fois. Le 13 mai 2024, le dernier modèle GPT-4o a été publié. Bien que sa fonction vocale ne soit pas encore officiellement disponible et reste limitée aux démonstrations, on peut déjà deviner, à partir des mises à jour précédentes, les capacités multilingues de ChatGPT en matière de dialogue vocal.
Beaucoup ont remarqué que l’accent cantonais de ChatGPT est très prononcé. Même si son intonation semble naturelle, presque humaine, ce « humain » n’est clairement pas un locuteur natif du cantonais.

Pour vérifier ce phénomène et en comprendre les causes, nous avons mené un test comparatif sur plusieurs logiciels de synthèse vocale cantonaise : les sujets testés étaient ChatGPT Voice, Siri d’Apple, Wenxin Yiyan de Baidu et suno.ai. Les trois premiers sont des assistants vocaux, tandis que suno.ai est une plateforme récemment très populaire d’intelligence artificielle générant de la musique. Tous possèdent la capacité de produire des réponses en cantonais ou en approximation de cantonais selon des indications données.
Sur le plan de la prononciation lexicale, Siri et Wenxin Yiyan sont corrects, mais leurs réponses semblent mécaniques et rigides. Les deux autres présentent diverses erreurs de prononciation, souvent influencées par le mandarin. Par exemple, le mot « 影 » (« jing2 » en cantonais) est prononcé comme « ying » en mandarin ; « 亮晶晶 », qui devrait être « zing1 », est lu « jing ».
Le mot « 高 » dans « 高楼大厦 » est prononcé « gao » par ChatGPT, alors qu’il devrait être « gou1 » selon la romanisation jyutping. Frank, originaire de Hong Kong, souligne que cette erreur typique chez les non-locuteurs natifs est souvent tournée en dérision par les habitants locaux – car « gao » est aussi un juron cantonais désignant un organe sexuel. La prononciation de ChatGPT varie légèrement à chaque essai : parfois, le caractère « 厦 » est correctement prononcé « haa6 », parfois il est mal lu comme « xia », une prononciation inexistante en cantonais, proche du mandarin.
Sur le plan grammatical, les textes produits sont nettement plus formels, avec seulement quelques expressions orales éparses. Le choix des mots et la construction des phrases basculent fréquemment vers des structures mandarines, comme dire « acheter des choses » (cantonais : « 买嘢 ») ou « je vais t’expliquer Hong Kong en cantonais » (cantonais : « 用粤语同你介绍下香港啦 »), des formulations qui s’écartent des habitudes orales naturelles du cantonais.
Lorsque suno.ai compose des paroles de rap en cantonais, il produit des phrases au sens flou telles que « 街坊边个仿得到,香港嘅特色真正靓妙 ». En soumettant cette phrase à ChatGPT pour évaluation, celui-ci répond : « Cette phrase semble être une traduction littérale du mandarin, ou une syntaxe mêlant mandarin et cantonais. »

À titre de comparaison, nous avons constaté que ces erreurs disparaissent presque entièrement lorsque ces systèmes utilisent le mandarin. Certes, même au sein du cantonais, il existe des différences d’accent et de vocabulaire entre Guangzhou, Hong Kong et Macao. L’accent de Xiguan, considéré comme le « standard » du cantonais, diffère beaucoup du cantonais parlé couramment à Hong Kong. Mais le cantonais de ChatGPT ressemble tout au plus à l’accent hésitant, approximatif, d’un locuteur natif du mandarin peu familier avec la langue.
Quelle en est la cause ? ChatGPT ne connaît-il pas le cantonais ? Il ne dit pas explicitement ne pas le supporter, mais plutôt en fait une interprétation imaginaire, clairement fondée sur une langue dominante et institutionnellement valorisée. Cela pose-t-il problème ?
Le linguiste et anthropologue Sapir estimait que la parole influence notre manière d’interagir avec le monde. Quand une langue ne parvient pas à s’exprimer à l’ère de l’intelligence artificielle, que signifie cela ? Allons-nous progressivement partager avec l’IA la même représentation de ce à quoi doit ressembler le cantonais ?
Une langue sans « ressources »
En consultant les informations publiques d’OpenAI, on apprend que la fonction vocale lancée l’an dernier repose sur trois composantes principales : d’abord, le système open source de reconnaissance vocale Whisper transforme la parole en texte ; ensuite, le modèle conversationnel textuel de ChatGPT génère une réponse écrite ; enfin, un modèle de synthèse vocale (Text-To-Speech, TTS) produit l’audio et ajuste finement la prononciation.
Autrement dit, le contenu du dialogue est toujours généré par le noyau de ChatGPT 3.5, entraîné sur d’immenses corpus textuels issus du web, et non sur des données audio.
Sur ce point, le cantonais présente un net désavantage, car il existe surtout à l’état oral, pas écrit. Officiellement, la variété écrite utilisée dans les régions cantonophones est le chinois écrit standard, issu du chinois du Nord, bien plus proche du mandarin que du cantonais. Quant au chinois écrit cantonais (ou « cantonais écrit »), système respectant la grammaire et le lexique du cantonais parlé, il n’apparaît guère que dans des contextes informels, comme les forums en ligne.
Cette pratique manque souvent de règles uniformes. « Environ 30 % des caractères cantonais, je ne sais pas comment les écrire », confie Frank. Sur les chats, face à un mot inconnu, on tape souvent un caractère phonétiquement proche via un clavier拼音. Par exemple, l’expression « 乱噏廿四 » (lyun6 up1 jaa6 sei3 ; parler n’importe quoi) est fréquemment écrite « 乱 up 廿四 ». Bien que compréhensible entre initiés, cela rend les textes cantonais existants désordonnés et hétérogènes.
L’avènement des grands modèles a sensibilisé au rôle crucial des jeux de données d’entraînement et à leurs biais potentiels. Pourtant, bien avant l’IA générative, les écarts de ressources entre langues avaient déjà creusé un fossé. La plupart des systèmes de traitement du langage naturel sont conçus et testés sur des langues « riches en ressources ». Parmi toutes les langues vivantes, seules 20 sont ainsi classées : anglais, espagnol, mandarin, français, allemand, arabe, japonais, coréen, etc.
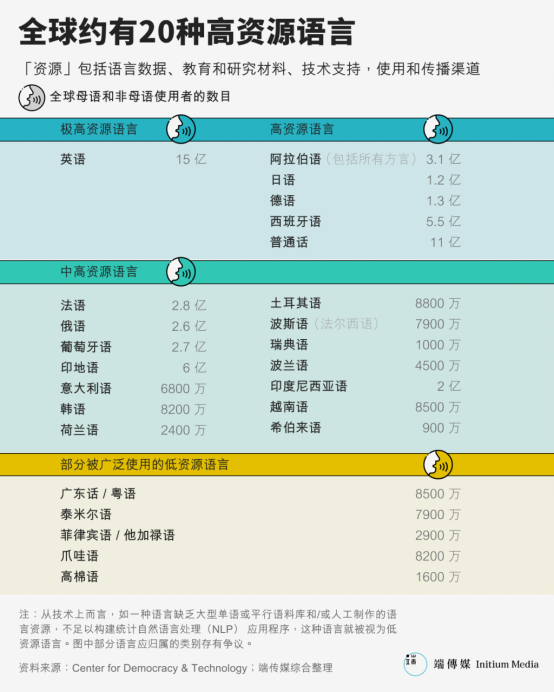
Pourtant, le cantonais, parlé par 85 millions de personnes, est souvent traité comme une langue pauvre en ressources en traitement du langage naturel (NLP). À titre de comparaison, la version compressée de Wikipédia en anglais pèse 15,6 Go, celle en chinois simplifié/traditionnel combiné 1,7 Go, contre seulement 52 Mo pour la version cantonaise — près de 33 fois moins.
De même, dans Common Voice, le plus grand jeu de données vocales ouvert, on trouve 1232 heures d’enregistrements pour « chinois (Chine) », 141 heures pour « chinois (Hong Kong) », et 198 heures pour « cantonais ».
Le manque de corpus affecte profondément les performances du traitement automatique du langage. Une étude de 2018 montre que moins de 13 000 phrases parallèles rendent toute traduction automatique impossible. Cela impacte aussi la « dictée » machine. Les tests de performance du modèle Whisper (version V2), utilisé par ChatGPT Voice, montrent un taux d’erreur bien plus élevé pour le cantonais que pour le mandarin.
Le faible niveau de ressources du cantonais explique donc ses difficultés textuelles. Mais comment expliquer les erreurs de prononciation et d’intonation, celles qui affectent notre perception auditive ?
Comment les machines apprennent-elles à parler ?
Dès le XVIIe siècle, l’idée de faire parler les machines a germé, avec des tentatives mécaniques utilisant des soufflets ou des orgues pour pomper de l’air dans des dispositifs imitant poumons, cordes vocales et bouche. L’inventeur Joseph Faber adopta cette approche pour créer un pantin parlant vêtu à la turque – mais personne alors ne comprenait l’intérêt.
Ce n’est que quand les appareils électroménagers se sont répandus que l’idée de donner la parole aux machines a suscité davantage d’intérêt.
Car pour la majorité, communiquer par code n’est pas naturel, et un grand nombre de personnes handicapées restent exclues des technologies.

En 1939, lors de l’exposition universelle, Homer Dudley, ingénieur des laboratoires Bell, présenta Voder, un synthétiseur vocal produisant la première « voix mécanique » audible par l’homme. Contrairement aux mystérieuses approches actuelles du machine learning, le principe de Voder était simple et visible : une opératrice assise devant une machine rappelant un piano d’enfant actionnait habilement 10 touches pour simuler le frottement des cordes vocales. En pressant une pédale, elle modulait aussi la hauteur du son, imitant des tons joyeux ou graves. Un animateur invitait le public à proposer des mots nouveaux, prouvant que les sons n’étaient pas préenregistrés.
Selon les enregistrements de l’époque, le *New York Times* décrivit la voix de Voder comme « un salut extraterrestre venant des profondeurs marines », ou celle d’un ivrogne bredouillant, difficilement compréhensible. Pourtant, la technologie stupéfiait : plus de 5 millions de visiteurs vinrent admirer Voder durant l’exposition.
Les premières représentations robotiques ou extraterrestres puisèrent leur inspiration dans ces dispositifs. En 1961, des scientifiques des laboratoires Bell firent chanter à l’ordinateur IBM 7094 une vieille chanson anglaise du XVIIIe siècle, « Daisy Bell ». C’est la première chanson chantée par une voix synthétique informatique connue. Clarke, auteur de *2001 : Odyssée de l’espace*, avait assisté à cette démonstration. Dans son roman, l’ordinateur HAL 9000 apprend justement cette chanson en premier. Dans le film, à la fin, alors qu’on le désactive, HAL, perdant conscience, entonne « Daisy Bell », sa voix fluide redevenant progressivement un grognement mécanique.
Depuis, la synthèse vocale a évolué pendant des décennies. Avant la maturité des réseaux neuronaux à l’ère de l’IA, les méthodes dominantes étaient la synthèse par concaténation et la synthèse formantique. Ces techniques sont encore largement utilisées aujourd’hui, notamment dans les lecteurs d’écran. La synthèse formantique, particulièrement répandue à l’époque, fonctionne comme Voder : en contrôlant des paramètres tels que la fréquence fondamentale, les sons sourds et voisés, elle peut produire un nombre illimité de sons. Son avantage majeur : elle permet de parler n’importe quelle langue. Dès 1939, Voder pouvait parler français.
Elle pouvait donc aussi parler cantonais. En 2006, Huang Guanneng, originaire de Guangzhou et alors étudiant en master d’informatique à l’université Sun Yat-sen, envisageait son projet de fin d’études : créer un navigateur Linux pour malvoyants. Durant ses recherches, il découvrit eSpeak, un synthétiseur vocal open source utilisant la synthèse formantique. Grâce à ses atouts linguistiques, eSpeak fut rapidement adopté. En 2010, Google Traduction ajouta la fonction de lecture à haute voix pour de nombreuses langues, dont le mandarin, le finnois, l’indonésien, grâce à eSpeak.

24 novembre 2015, Pékin, un bras robotique écrit des caractères chinois à l’encre avec un pinceau.
Huang Guanneng décida d’ajouter le support du cantonais, sa langue maternelle, à eSpeak. Mais en raison de ses limites techniques, la prononciation synthétisée avait un effet « rapiécé » : « C’est comme apprendre le chinois non pas avec la pinyin, mais avec la transcription anglaise : on dirait un étranger essayant de parler chinois », explique-t-il.
Il créa donc Ekho TTS. Aujourd’hui, ce synthétiseur prend en charge le cantonais, le mandarin, et même des langues plus rares comme le hakka de Zhao’an, le tibétain, le ya yan ou le taishanais du Guangdong. Ekho utilise la méthode par concaténation – ou collage : des sons humains sont préenregistrés, puis assemblés lors de la « parole ». Ainsi, la prononciation des caractères est plus précise, et certains mots fréquents, s’ils sont intégralement enregistrés, sonnent plus naturels. Huang Guanneng a compilé une table de prononciation cantonaise de 5005 sons, dont l’enregistrement complet prend 2 à 3 heures.
L’apprentissage profond a révolutionné ce domaine. Les algorithmes basés sur le deep learning apprennent depuis de vastes corpus vocaux la correspondance entre texte et traits sonores, sans dépendre de règles linguistiques préétablies ni d’unités vocales enregistrées. Cette technologie a fait un bond en avant dans le naturel des voix artificielles, atteignant parfois une indiscernabilité totale avec un humain, et capable de reproduire le timbre et les habitudes d’un locuteur à partir de seulement quelques secondes d’enregistrement — c’est précisément cette technologie que ChatGPT utilise dans son module TTS.
Comparé aux méthodes formantique et par concaténation, ces systèmes réduisent drastiquement les coûts humains initiaux, mais exigent davantage de données appariées texte-vocal. Par exemple, Tacotron, modèle end-to-end lancé par Google en 2017, nécessite plus de 10 heures de données d’entraînement pour produire une qualité vocale satisfaisante.
Face à la rareté des ressources pour de nombreuses langues, les chercheurs ont récemment proposé le transfert d’apprentissage : entraîner d’abord un modèle général sur des langues riches, puis transférer ces connaissances à des langues moins dotées. Ce transfert conserve souvent les caractéristiques du jeu de données initial — comme un locuteur apprenant une nouvelle langue avec l’accent de sa langue maternelle. En 2019, l’équipe de Tacotron a présenté un modèle capable de cloner la voix d’un locuteur entre différentes langues. Dans la démo, un anglophone « parlant » mandarin, bien que correctement prononcé, gardait un accent étranger très marqué.
Un article du *South China Morning Post* note que les Hongkongais, écrivant en chinois standard, doivent utiliser le terme « 他们 » (tāmen) pour dire « ils », bien que ce mot, jamais utilisé à l’oral en cantonais, soit remplacé par « 佢哋 » (keoi5 dei6), complètement différent en prononciation et écriture.
Sur ce principe d’une solution unique pour des problèmes généraux, le nouveau modèle GPT-4o va encore plus loin : OpenAI explique avoir entraîné de bout en bout un modèle unifié traitant texte, image et audio, où toutes les entrées et sorties sont gérées par un seul réseau neuronal. Comment il traite les différentes langues reste flou, mais sa capacité d’universalité entre tâches semble supérieure à celle des modèles passés.
Mais les interactions entre cantonais et mandarin compliquent parfois davantage les choses.
En linguistique, on parle de « diglossie » : situation où deux langues étroitement liées coexistent dans une société, l’une prestigieuse, utilisée par le pouvoir, l’autre dialectale, parlée oralement.
Dans le contexte chinois, le mandarin est la langue supérieure, utilisée pour l’écrit formel, les nouvelles, l’éducation scolaire et les affaires gouvernementales. Les dialectes régionaux comme le cantonais, le minnan (taïwanais), le shanghaïen sont des langues inférieures, utilisées principalement dans les échanges familiaux ou communautaires locaux.
Cela crée donc à Guangdong, Hong Kong et Macao une situation où le cantonais est la langue maternelle de la majorité, utilisée à l’oral, tandis que l’écrit formel suit le standard du mandarin.
Les similitudes trompeuses entre les deux, comme « 他们 » et « 佢哋 », peuvent rendre le transfert du mandarin vers le cantonais difficile et source d’erreurs.
Un cantonais de plus en plus marginalisé
« Les craintes sur l’avenir du cantonais ne sont pas infondées. Le déclin d’une langue peut être rapide, s’effondrer en une ou deux générations, et une fois entamé, il est quasi impossible de le renverser. » James Griffiths, *Speak Mandarin*
On pourrait donc penser que les mauvaises performances de la synthèse vocale en cantonais résultent simplement des limites techniques face aux langues pauvres en données. Face à des termes inconnus, les modèles basés sur l’apprentissage profond produisent des hallucinations sonores. Pourtant, après avoir écouté ChatGPT, Tan Lee, professeur en génie électronique à l’Université chinoise de Hong Kong, propose un autre éclairage.

Représentation d’opéra cantonais au théâtre Yau Ma Tei
Spécialiste de la parole depuis le début des années 1990, Tan Lee a dirigé le développement de plusieurs technologies vocales centrées sur le cantonais, largement appliquées. En 2002, avec son équipe, il lança CU Corpora, alors la plus grande base de données vocales cantonaises au monde, comprenant les enregistrements de plus de 2000 personnes. De nombreuses entreprises et instituts, dont Apple pour sa première reconnaissance vocale, ont acheté ces ressources pour développer des fonctions cantonaises.
Pour lui, la performance vocale cantonaise de ChatGPT « n’est pas bonne, principalement instable, la qualité sonore et la précision de prononciation étant globalement insatisfaisantes ». Mais cette médiocrité ne vient pas d’une limite technique. En réalité, de nombreux produits commerciaux capables de parler cantonais offrent une qualité bien supérieure. Il a du mal à croire aux vidéos circulant en ligne : « Si tu fais un modèle de synthèse vocale et que tu livres ça, tu ne peux plus te montrer, c’est suicide professionnel. »
Prenons le système développé par son université : les meilleurs modèles sont aujourd’hui indiscernables de vraies voix humaines. Comparé à des langues dominantes comme le mandarin ou l’anglais, l’IA cantonaise ne montre un déficit émotionnel que dans des scénarios très personnalisés ou intimes — dialogues parents-enfants, consultations psychologiques, entretiens d’embauche — où elle paraît plus froide.
« Mais franchement, ce n’est pas un problème technique. L’enjeu, c’est le choix des ressources sociales », affirme Tan Lee.
Par rapport à il y a 20 ans, le domaine a changé radicalement. La taille de CU Corpora représente aujourd’hui « moins d’un millième » des bases actuelles. La commercialisation des technologies vocales a fait des données une marchandise : des sociétés spécialisées peuvent fournir à la demande de vastes corpus personnalisés. Le manque de données parallèles texte-parole, lié au caractère oral du cantonais, n’est plus un obstacle grâce aux progrès de la reconnaissance vocale. Selon Tan Lee, qualifier aujourd’hui le cantonais de « langue pauvre en ressources » n’est plus exact.
C’est pourquoi, selon lui, la performance médiocre des machines reflète non pas une incapacité technique, mais des considérations commerciales et de marché. « Imaginons que tout le pays doive apprendre le cantonais demain : on pourrait le faire. Ou bien, si un jour la politique éducative décidait que les écoles de Hong Kong ne peuvent plus parler cantonais mais seulement mandarin, ce serait une autre histoire. »
L’accent produit par le deep learning, ce « mangez ce que vous voyez, vomissez ce que vous mangez », reflète en réalité la compression subie par le cantonais dans l’espace réel.
La fille de Huang Guanneng vient d’entrer en moyenne section dans une école maternelle de Guangzhou. Elle ne parlait que cantonais, mais un mois après la rentrée, elle maîtrisait parfaitement le mandarin. Aujourd’hui, même dans ses échanges quotidiens avec la famille ou les voisins, elle préfère le mandarin — sauf avec son père, « parce qu’elle veut jouer avec moi, elle suit mes préférences ». Pour lui, la façon dont ChatGPT parle cantonais ressemble exactement à celle de sa fille : quand elle ne se souvient plus d’un mot, elle le remplace par le mandarin, ou essaie de deviner sa prononciation à partir du mandarin.
C’est le résultat d’un long mépris du cantonais à Guangdong, voire de son exclusion totale des sphères officielles. Un document gouvernemental de 1981 du gouvernement provincial du Guangdong affirmait : « Propager le mandarin est une tâche politique », surtout dans cette province aux nombreux dialectes et aux échanges fréquents, « visant à ce que toutes les grandes et moyennes villes utilisent exclusivement le mandarin dans les lieux publics en trois à cinq ans, et à généraliser le mandarin dans tous les établissements scolaires sous six ans. »
Frank, originaire de Guangzhou, s’en souvient bien : à la télévision, les films étrangers passaient sans doublage, avec sous-titres, mais les films cantonais devaient obligatoirement être doublés en mandarin pour être diffusés. Dans ce contexte, le cantonais a décliné, son nombre de locuteurs a chuté, et les écoles ont mené des campagnes de « suppression du cantonais », provoquant de vives controverses sur la survie de la langue et l’identité culturelle. En 2010, de larges mouvements « Défendons le cantonais » ont éclaté en ligne et hors ligne à Guangzhou. Comme le notaient alors les médias, on a comparé ce débat à la scène du *Dernier cours* de Daudet, estimant qu’un demi-siècle de radicalisme culturel avait fait dépérir un riche patrimoine linguistique. Pour Hong Kong, le cantonais est un pilier culturel, véhiculé par le cinéma et la musique hongkongais, qui façonnent l’image de la société.
En 2014, un article du site du ministère de l’Éducation qualifiant le cantonais de « dialecte chinois non reconnu comme langue officielle » a déclenché une vive polémique, conclue par des excuses officielles. En août 2023, l’organisation « Hong Kong Language Studies », militante pour la sauvegarde du cantonais, a annoncé sa dissolution. Son fondateur, Chan Lok Hang, a déclaré en interview que le gouvernement promeut activement l’enseignement du mandarin en classe de chinois (« Putonghua teaching Chinese »), mais que la vigilance citoyenne a « ralenti le processus ».
Tout cela illustre l’importance du cantonais aux yeux des Hongkongais, mais aussi la pression durable qu’il subit localement, sa vulnérabilité due à son statut non officiel, et l’affrontement continu entre gouvernement et société civile.
Dictionnaire en ligne de cantonais – Jyutdict
Des voix non représentées
Les hallucinations linguistiques ne touchent pas que le cantonais. Sur Reddit et les forums d’OpenAI, des utilisateurs du monde entier signalent des comportements similaires de ChatGPT lorsqu’il parle des langues non anglaises :
« Sa reconnaissance vocale italienne est excellente, toujours compréhensible et fluide, comme un vrai humain. Mais bizarrement, il a un accent britannique, comme un Anglais parlant italien. »
« En tant que Britannique, je dirais qu’il a un accent américain. Je déteste ça, donc je préfère ne pas l’utiliser. »
« Pareil pour le néerlandais, c’est agaçant, comme si la prononciation était entraînée sur des phonèmes anglais. »
En linguistique, l’accent désigne un mode de prononciation. Influencé par le milieu géographique, la classe sociale, chacun a des variations plus ou moins marquées, visibles dans l’intonation, l’accent tonique ou le choix lexical. Curieusement, les accents traditionnellement discutés proviennent souvent des habitudes maternelles des locuteurs apprenant l’anglais : accent indien, singapourien, irlandais — reflétant la diversité linguistique mondiale. Mais l’intelligence artificielle exhibe désormais une distorsion inverse : celle de la langue dominante sur les langues régionales.
La technologie amplifie cette intrusion. Un rapport de Statista (février 2024) souligne qu’alors que seulement 4,6 % des gens ont l’anglais comme langue maternelle, il occupe 58,8 % du texte en ligne — une influence disproportionnée par rapport à la réalité. Même en incluant tous les locuteurs de l’anglais (1,46 milliard), ils ne représentent pas 20 % de la population mondiale. Environ quatre cinquièmes des humains ne comprennent donc pas la majorité des contenus en ligne, et ont du mal à faire fonctionner une IA spécialisée en anglais pour leurs besoins.
Des informaticiens africains ont découvert que ChatGPT interprète mal souvent les langues africaines, avec des traductions grossières. Pour le zoulou (Zulu ; environ 9 millions de locuteurs), ses performances sont « irrégulières, parfois comiques ». Pour le tigrinya (Tigrinya ; Éthiopie, Israël, environ 8 millions), les réponses sont souvent du charabia. Cette observation les inquiète : l’absence d’outils d’IA adaptés aux langues africaines, capables de reconnaître noms et lieux africains, empêche les Africains de participer pleinement à l’économie mondiale — commerce électronique, logistique, accès à l’information, automatisation — et les exclut des opportunités économiques.
Prendre une langue comme « norme dorée » induit aussi des biais dans les jugements de l’IA. Une étude de Stanford (2023) révèle que l’IA marque souvent à tort comme générés par IA des rédactions d’examen TOEFL (écrites par des non-anglophones), mais pas celles d’étudiants anglophones. Une autre étude montre que les systèmes de reconnaissance vocale ont un taux d’erreur presque double face à des locuteurs afro-américains comparés aux Blancs, et que ces erreurs viennent non de la grammaire, mais des « caractéristiques vocales, phonétiques ou prosodiques » — autrement dit, de l’accent.
Plus inquiétant encore : dans des simulations de procès, les grands modèles attribuent une peine de mort plus fréquem
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News










