

Analyse détaillée en 10 000 mots sur l'EVM parallèle : comment surmonter les goulots d'étranglement des performances de la blockchain ?
TechFlow SélectionTechFlow Sélection
Analyse détaillée en 10 000 mots sur l'EVM parallèle : comment surmonter les goulots d'étranglement des performances de la blockchain ?
L'EVM parallèle est une nouvelle narration qui émerge lorsque le volume des transactions sur la blockchain atteint un certain niveau.
Rédaction : @leesper6
Encadrant : @CryptoScott_ETH
TL;DR
-
L’EVM parallèle est une nouvelle narration apparue à mesure que le volume des transactions en chaîne atteignait un certain niveau. L’EVM parallèle se divise principalement en blockchains monolithiques et modulaires. Les blockchains monolithiques se subdivisent elles-mêmes en L1 et L2. Les blockchains publiques parallèles de niveau 1 (L1) se répartissent en deux camps : EVM et non-EVM. Actuellement, la narration autour de l’EVM parallèle en est encore à ses débuts ;
-
L’analyse des voies techniques de mise en œuvre de l’EVM parallèle couvre principalement deux aspects : la machine virtuelle et le mécanisme d’exécution parallèle. Dans le contexte blockchain, une machine virtuelle désigne un processus virtuel qui simule une machine d’état distribuée, utilisée pour exécuter des contrats ;
-
L’exécution parallèle consiste à tirer parti des processeurs multicœurs afin d’exécuter simultanément plusieurs transactions dans la mesure du possible, tout en garantissant que l’état final soit identique à celui obtenu avec une exécution séquentielle ;
-
Les mécanismes d’exécution parallèle se classent en trois grandes catégories : passage de messages, mémoire partagée et listes strictes d’accès à l’état. La mémoire partagée se subdivise elle-même en modèle à verrous mémoire et parallélisation optimiste. Quel que soit le mécanisme choisi, tous augmentent la complexité technique ;
-
La narration de l’EVM parallèle repose à la fois sur des moteurs internes de croissance sectorielle, mais nécessite également une attention particulière aux risques éventuels en matière de sécurité ;
-
Chaque projet retenu dans le domaine de l’EVM parallèle propose sa propre approche originale de l’exécution parallèle, combinant des points communs techniques et des innovations spécifiques.
1. Aperçu du secteur
1.1 Évolution historique
Les performances sont désormais un goulot d’étranglement pour le développement du secteur. Les réseaux blockchain ont créé une nouvelle base de confiance décentralisée pour les transactions entre particuliers et entreprises.
La première génération de réseaux blockchain, incarnée par Bitcoin, a révolutionné l’ère numérique en introduisant un nouveau modèle de monnaie électronique décentralisée basé sur la comptabilité distribuée. La deuxième génération, représentée par Ethereum, a pleinement exploité son imagination en proposant un modèle d’application décentralisée (dApp) fondé sur une machine d’état distribuée.
Depuis lors, les réseaux blockchain ont entamé une décennie et demie de développement fulgurant, passant des infrastructures Web3 aux diverses niches telles que la DeFi, les NFT, les réseaux sociaux ou le GameFi, générant d’innombrables innovations technologiques ou commerciales. Ce dynamisme sectoriel exige continuellement l’entrée de nouveaux utilisateurs dans l’écosystème des applications décentralisées, ce qui renforce à son tour les exigences en matière d’expérience utilisateur.
Le Web3, en tant que forme produit inédite, doit non seulement innover dans la satisfaction des besoins fonctionnels, mais aussi trouver un équilibre entre sécurité et performance (besoins non fonctionnels). Depuis sa création, diverses solutions ont été proposées pour résoudre le problème des performances.
Ces solutions peuvent être grossièrement divisées en deux catégories : celles de mise à l’échelle « on-chain » comme le sharding ou les graphes acycliques orientés (DAG), et celles « off-chain » comme Plasma, Lightning Network, les sidechains ou les Rollups. Cependant, ces solutions ne suffisent pas à suivre la croissance rapide du volume des transactions en chaîne.
En particulier après l’été DeFi de 2020 et l’explosion continue des inscriptions dans l’écosystème Bitcoin fin 2023, le secteur a un besoin urgent de nouvelles solutions performantes répondant aux attentes de « haute performance et faibles frais ». C’est dans ce contexte que sont nées les blockchains parallèles.

1.2 Taille du marché
La narration de l’EVM parallèle marque l’émergence d’un duel entre deux géants dans le domaine des blockchains parallèles. Ethereum traite les transactions de manière séquentielle : chaque transaction s’exécute l’une après l’autre, ce qui entraîne une faible utilisation des ressources. Passer à un traitement parallèle permettrait un gain considérable en performance.
Des concurrents d’Ethereum tels que Solana, Aptos et Sui intègrent nativement une capacité d’exécution parallèle et ont développé des écosystèmes florissants, avec des valorisations boursières respectives de 45, 3,3 et 1,9 milliards de dollars. Ils forment ainsi le courant non-EVM parallèle. Face à ce défi, l’écosystème Ethereum riposte vigoureusement en dotant l’EVM de capacités parallèles, constituant le courant EVM parallèle.
Sei a annoncé fièrement dans sa proposition de mise à jour v2 qu’il deviendrait la « première blockchain EVM parallèle », avec une capitalisation actuelle de 2,1 milliards de dollars, et un potentiel de croissance plus important encore. Monad, la nouvelle blockchain publique EVM parallèle la plus médiatisée actuellement, attire fortement les investisseurs institutionnels et possède un potentiel non négligeable. Par ailleurs, Canto, une blockchain L1 d’une capitalisation de 170 millions de dollars dotée d’infrastructures publiques gratuites, a également annoncé sa proposition de mise à niveau vers l’EVM parallèle.
En outre, plusieurs projets L2 en phase précoce cherchent à améliorer les performances inter-écosystèmes en intégrant les capacités de plusieurs blockchains L1. À l’exception de Neon, dont la capitalisation atteint 69 millions de dollars, les autres projets manquent encore de données pertinentes. On peut s’attendre à voir apparaître davantage de projets L1 et L2 rejoignant le champ de bataille des blockchains parallèles.
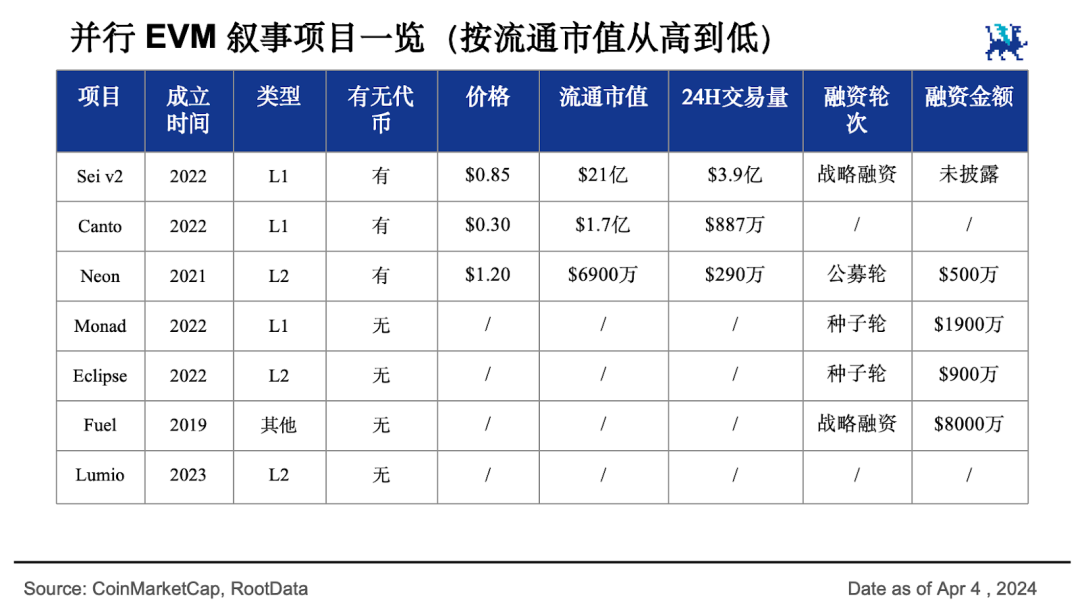
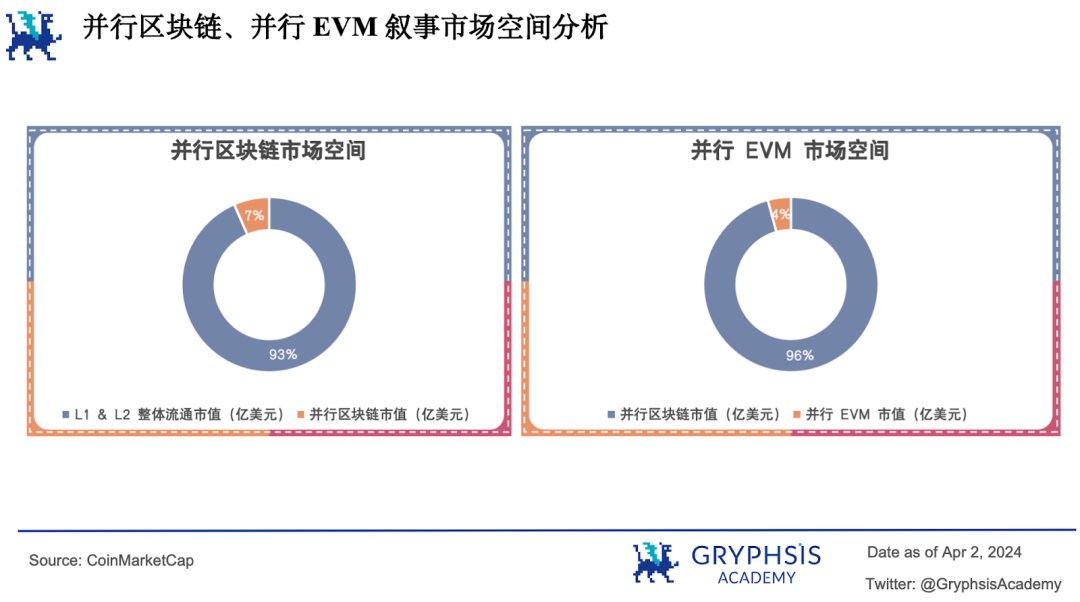
Non seulement la narration autour de l’EVM parallèle dispose d’un fort potentiel de croissance, mais l’ensemble du segment des blockchains parallèles offre également d’importantes perspectives, rendant l’horizon très prometteur.
Actuellement, la capitalisation totale des blockchains L1 et L2 s’élève à 752,123 milliards de dollars, contre 52,539 milliards pour les blockchains parallèles, soit environ 7 %. Parmi celles-ci, les projets liés à la narration de l’EVM parallèle représentent 2,339 milliards de dollars, soit seulement 4 % du total des blockchains parallèles.
1.3 Cartographie du secteur
On distingue généralement quatre couches dans les réseaux blockchain :
-
Couche 0 (réseau) : réseau de base traitant les protocoles de communication élémentaires
-
Couche 1 (infrastructure) : réseau décentralisé validant les transactions via divers mécanismes de consensus
-
Couche 2 (extension) : protocoles secondaires reposant sur la couche 1, destinés à pallier ses limitations, notamment en termes d’évolutivité
-
Couche 3 (applications) : construite sur la couche 2 ou la couche 1, pour développer diverses applications décentralisées (dApps)
Les projets axés sur l’EVM parallèle se divisent en blockchains monolithiques et modulaires, eux-mêmes subdivisés en L1 et L2. Le nombre total de projets et le développement de plusieurs niches clés montrent que les écosystèmes des blockchains L1 parallèles EVM ont encore un grand potentiel par rapport à celui d’Ethereum.
Le secteur DeFi exige « rapidité élevée et frais faibles », tandis que le gaming requiert une « interaction temps réel forte » ; les deux domaines ont donc besoin d’une vitesse d’exécution élevée. L’EVM parallèle apportera inévitablement une meilleure expérience utilisateur, propulsant le secteur vers une nouvelle ère.
Les blockchains L1 sont de nouvelles blockchains publiques dotées nativement de capacités d’exécution parallèle, formant des infrastructures hautement performantes. Dans cette catégorie, des projets comme Sei v2, Monad et Canto conçoivent leur propre EVM parallèle, compatible avec l’écosystème Ethereum et offrant une grande capacité de traitement des transactions.
Les solutions L2 intègrent les capacités d’autres blockchains L1 pour fournir une évolutivité transversale, incarnant l’art des rollups. Neon est un simulateur EVM sur le réseau Solana, Eclipse exécute les transactions sur Solana mais effectue le règlement sur EVM. Lumio suit une approche similaire à Eclipse, mais remplace la couche d’exécution par Aptos.

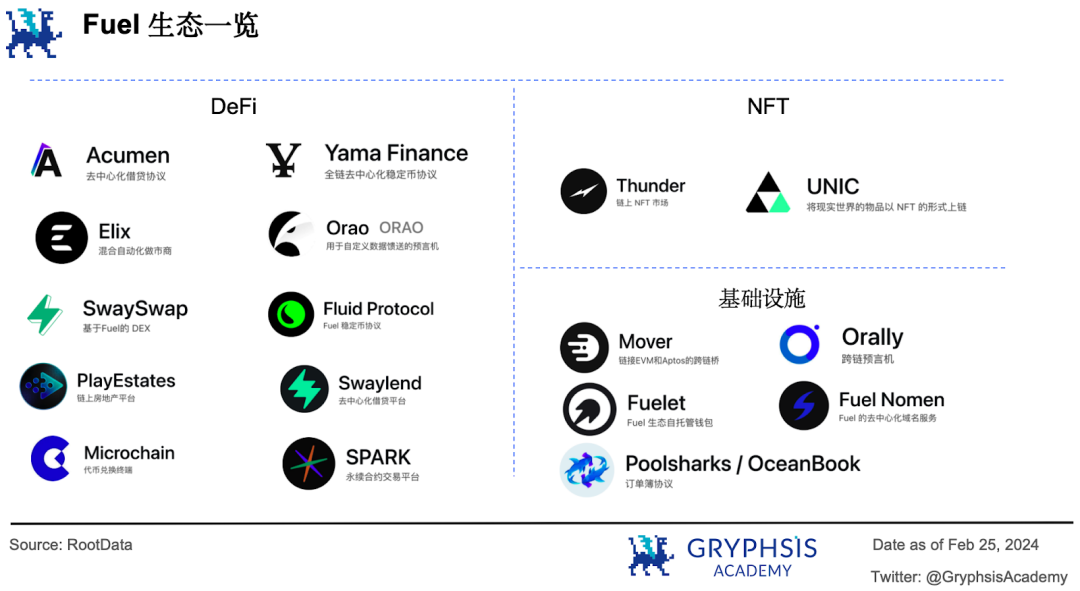
Outre ces solutions monolithiques, Fuel propose une vision modulaire de la blockchain. Il se positionnera dans sa deuxième version comme un système d’exploitation de rollup pour Ethereum, offrant une modularité d’exécution plus flexible et plus poussée.
Fuel se concentre uniquement sur l’exécution des transactions, externalisant les autres fonctions à une ou plusieurs couches indépendantes, permettant ainsi une combinaison plus souple : il peut devenir un L2, un L1, ou même une sidechain ou un canal d’état. Actuellement, l’écosystème Fuel compte 17 projets, principalement concentrés sur la DeFi, les NFT et les infrastructures.
Toutefois, seul l’oracle跨链 Orally est déjà opérationnel. La plateforme de prêt décentralisée Swaylend et la plateforme de contrats perpétuels SPARK sont en testnet, les autres projets étant encore en développement.
2. Voies techniques de mise en œuvre
Pour exécuter des transactions de façon décentralisée, un réseau blockchain doit assumer quatre responsabilités :
-
Exécution : exécuter et valider les transactions
-
Disponibilité des données : diffuser les nouveaux blocs à tous les nœuds du réseau
-
Mécanisme de consensus : valider les blocs et parvenir à un accord
-
Règlement : consigner l’état final des transactions
L’EVM parallèle vise principalement à optimiser les performances au niveau de l’exécution. Cela donne lieu à deux types de solutions : les solutions de niveau 1 (L1) et les solutions de niveau 2 (L2). Les solutions L1 introduisent un mécanisme d’exécution parallèle des transactions, permettant leur traitement quasi simultané dans la machine virtuelle. Les solutions L2 exploitent essentiellement une machine virtuelle L1 déjà parallélisée, réalisant une forme de « traitement hors chaîne + règlement en chaîne ».
Comprendre les principes techniques de l’EVM parallèle implique donc de les décomposer : d’abord comprendre ce qu’est une machine virtuelle (virtual machine), puis ce qu’est l’exécution parallèle (parallel execution).
2.1 Machine virtuelle
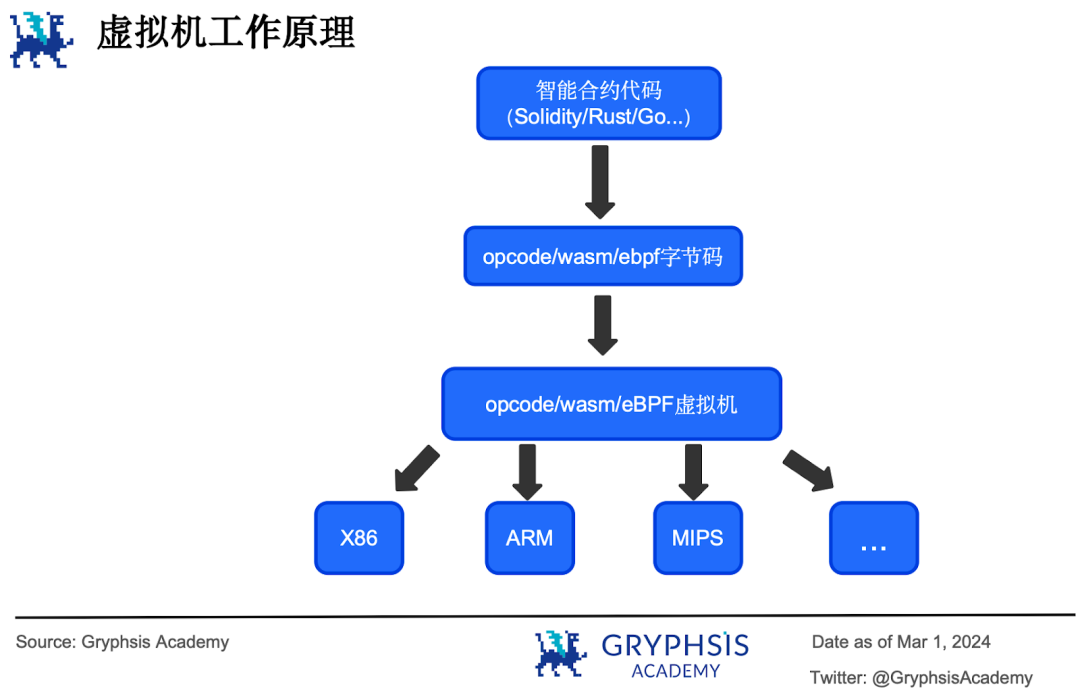
En informatique, une machine virtuelle désigne une virtualisation (virtualization) ou une émulation (emulation) d’un système informatique.
Il existe deux types de machines virtuelles : les machines virtuelles système (system virtual machine), qui virtualisent un ordinateur physique en plusieurs machines distinctes capables d’exécuter différents systèmes d’exploitation, augmentant ainsi l’utilisation des ressources ; et les machines virtuelles de processus (process virtual machine), qui fournissent une abstraction pour certains langages de programmation avancés, permettant aux programmes écrits dans ces langages de s’exécuter indépendamment de la plateforme.
La JVM est une machine virtuelle de processus conçue pour le langage Java. Les programmes Java sont d’abord compilés en bytecode Java (code binaire intermédiaire), puis interprétés et exécutés par la JVM : celle-ci transmet le bytecode à un interpréteur qui le traduit en code machine adapté à chaque architecture avant son exécution.
La machine virtuelle blockchain est une variante de la machine virtuelle de processus. Dans le contexte blockchain, elle correspond à la virtualisation d’une machine d’état distribuée, utilisée pour exécuter des contrats et faire fonctionner des dApps de manière distribuée. Par analogie avec la JVM, l’EVM est une machine virtuelle de processus conçue pour le langage Solidity. Les contrats intelligents sont d’abord compilés en bytecode opcode, puis interprétés et exécutés par l’EVM.
Les nouvelles blockchains émergentes adoptent souvent des machines virtuelles basées sur le bytecode WASM ou eBPF. WASM est un format de bytecode compact, rapide à charger, portable et sécurisé grâce à un bac à sable. Les développeurs peuvent écrire des contrats intelligents dans divers langages (C, C++, Rust, Go, Python, Java ou même TypeScript), les compiler en bytecode WASM, puis les exécuter. C’est précisément ce format que la blockchain Sei utilise pour ses contrats intelligents.
eBPF découle initialement de BPF (Berkeley Packet Filter), initialement utilisé pour filtrer efficacement les paquets réseau, puis enrichi progressivement en eBPF avec un jeu d’instructions étendu.
Il s’agit d’une technologie révolutionnaire permettant d’intervenir dynamiquement sur le noyau d’un système d’exploitation sans modifier son code source, afin d’en modifier le comportement. Cette technologie s’est ensuite étendue au-delà du noyau avec l’apparition de runtimes eBPF en espace utilisateur, offrant hautes performances, sécurité et portabilité. Sur Solana, les contrats intelligents sont compilés en bytecode eBPF et exécutés sur le réseau blockchain.
Parmi les autres blockchains L1, Aptos et Sui utilisent le langage Move, compilé en bytecode propriétaire exécuté sur la machine virtuelle Move. Monad, quant à lui, a conçu sa propre machine virtuelle compatible avec le bytecode opcode EVM (fork Shanghai).
2.2 Exécution parallèle
L’exécution parallèle est une technique qui :
-
Permet de tirer parti des processeurs multicœurs pour traiter plusieurs tâches simultanément, augmentant ainsi le débit du système ;
-
Garantit que les résultats obtenus soient strictement identiques à ceux d’une exécution séquentielle.
Les réseaux blockchain utilisent couramment le TPS (transactions par seconde) comme indicateur technique de vitesse de traitement. Le mécanisme d’exécution parallèle est complexe et exige un haut niveau technique. Pour l’expliquer clairement, prenons l’exemple d’une « banque ».
(1) Qu’est-ce que l’exécution séquentielle ?
Cas 1 : Si l’on assimile le système à une banque et le processeur traitant les tâches à un guichet, alors l’exécution séquentielle revient à n’avoir qu’un seul guichet pour traiter toutes les opérations. Les clients (tâches) doivent alors former une longue file d’attente et être servis un par un. Chaque employé doit répéter les mêmes actions (exécuter les instructions) pour chaque client. En attendant leur tour, les clients ne peuvent que patienter, ce qui allonge le temps de traitement.
(2) Qu’est-ce que l’exécution parallèle ?
Cas 2 : La banque constate l’affluence et ouvre plusieurs guichets supplémentaires. Quatre employés traitent simultanément les opérations, multipliant ainsi la vitesse par environ 4. Le temps d’attente des clients est réduit à environ un quart, améliorant ainsi significativement la rapidité du service.
(3) Sans protection, que se passe-t-il si deux personnes transfèrent simultanément de l’argent à une troisième ?
Cas 3 : Trois personnes A, B et C disposent respectivement de 2 ETH, 1 ETH et 0 ETH. A et B veulent chacun transférer 0,5 ETH à C. Dans un système à exécution séquentielle, aucun problème ne survient (la flèche gauche « <= » signifie lecture du grand livre, la flèche droite « => » signifie écriture, idem ci-dessous) :

Mais l’exécution parallèle n’est pas aussi simple qu’elle en a l’air. Des détails subtils peuvent facilement provoquer des erreurs graves. Si les transferts d’A et B vers C sont exécutés en parallèle, selon l’ordre d’exécution des étapes, des résultats incohérents peuvent apparaître :
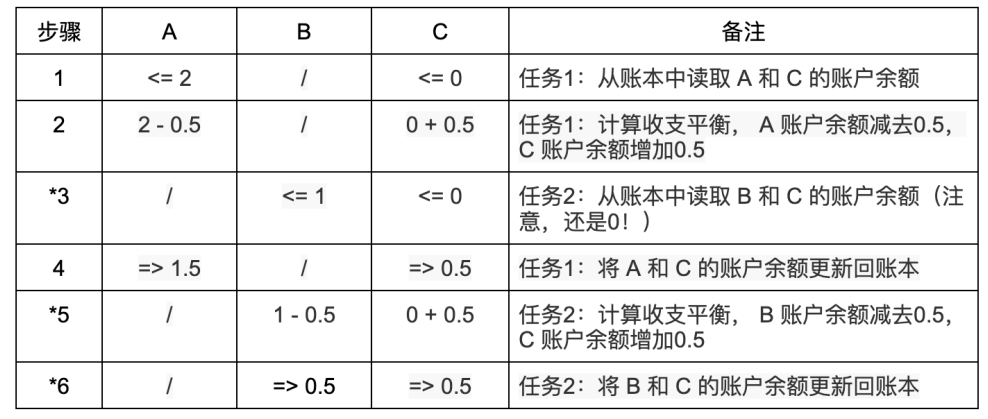
La tâche parallèle 1 exécute le transfert de A vers C, et la tâche parallèle 2 celui de B vers C. Les étapes marquées d’un astérisque (*) sont problématiques : comme les tâches s’exécutent en parallèle, lors de l’étape 2, le calcul d’équilibre effectué par la tâche 1 n’a pas encore été écrit dans le grand livre ; lors de l’étape 3, la tâche 2 lit déjà le solde de C (encore à 0), puis effectue un calcul erroné basé sur ce solde nul à l’étape 5, et finalement met à jour le solde à 0,5 à l’étape 6, écrasant ainsi la mise à jour précédente de 0,5. Résultat : bien que A et B aient chacun transféré 0,5 ETH à C, le solde final de C n’est que de 0,5 ETH — l’autre moitié a disparu.
(4) Sans protection, deux tâches indépendantes peuvent s’exécuter en parallèle sans erreur
Cas 4 : La tâche parallèle 1 transfère 0,5 ETH de A (solde 2 ETH) à C (solde 0 ETH), et la tâche parallèle 2 transfère 0,5 ETH de B (solde 1 ETH) à D (solde 0 ETH). Ces deux transferts sont indépendants. Peu importe l’ordre d’exécution des étapes, le problème précédent n’apparaît pas :

L’analyse comparative de ces deux scénarios montre que lorsque des tâches (transactions) ont une dépendance, une exécution parallèle peut entraîner une erreur de mise à jour d’état ; sinon, aucune erreur ne survient. Deux conditions définissent une dépendance entre transactions :
-
Une transaction écrit une adresse que l’autre lit en entrée ;
-
Deux transactions écrivent dans la même adresse.
Ce phénomène n’est pas spécifique à la décentralisation. Dans tout scénario d’exécution parallèle, l’accès non protégé à des ressources partagées (le « grand livre » dans l’exemple bancaire, la mémoire partagée dans les systèmes informatiques, etc.) par des tâches dépendantes entraîne une incohérence des données, appelée problème de course (data races).
Le secteur propose trois mécanismes pour résoudre ce problème : mécanisme de passage de messages, mécanisme de mémoire partagée et mécanisme de listes strictes d’accès à l’état.
2.3 Mécanisme de passage de messages
Cas 5 : Supposons que la banque dispose de 4 guichets traitant simultanément les clients. Chaque employé reçoit un registre personnel, modifiable uniquement par lui-même, contenant les soldes des clients qu’il gère.
Lorsqu’un employé traite une opération, s’il trouve les informations du client dans son propre registre, il procède directement ; sinon, il crie aux autres employés pour leur demander de traiter l’opération.
C’est le principe du modèle de passage de messages. Le modèle Actor en est une variante : chaque exécuteur responsable du traitement des transactions est un « acteur » (guichetier), possédant ses propres données privées (registre personnel). Pour accéder aux données privées d’un autre, il doit envoyer un message.
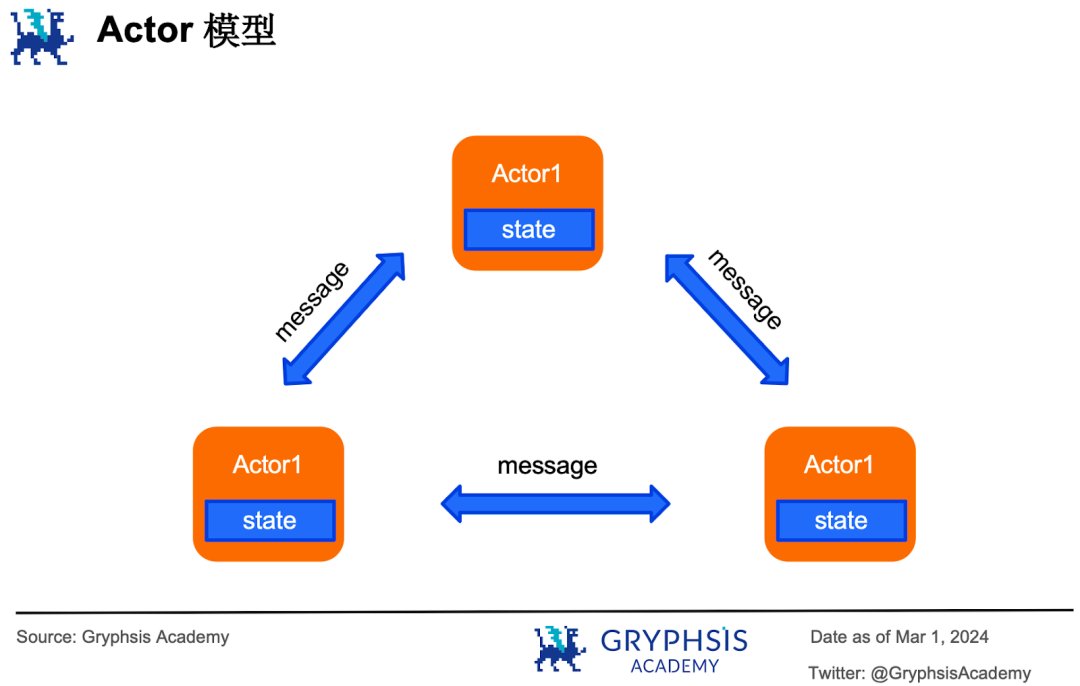
L’avantage du modèle Actor est que chaque acteur n’accède qu’à ses propres données, éliminant ainsi les problèmes de course.
Ses inconvénients sont doubles : d’abord, chaque acteur ne peut exécuter qu’un traitement séquentiel, perdant ainsi l’avantage du parallélisme dans certains cas (par exemple, si les guichetiers 2, 3 et 4 demandent simultanément au guichetier 1 le solde du client A, ce dernier ne peut les traiter qu’un par un, alors que cela pourrait être parallélisé).
Ensuite, l’absence d’une vue globale de l’état du système rend difficile la compréhension d’ensemble, le diagnostic et la correction des bogues en cas de logique complexe.
2.4 Mécanisme de mémoire partagée
2.4.1 Modèle à verrous mémoire
Cas 6 : Supposons que la banque ne possède qu’un seul grand registre contenant tous les soldes clients, et qu’un seul stylo soit disponible pour modifier ce registre.
Dans ce cas, les 4 guichetiers doivent se disputer le stylo : celui qui l’attrape en premier (verrouillage) commence à traiter une opération et modifier le registre, pendant que les trois autres attendent. Une fois terminé, il pose le stylo (déverrouillage), permettant aux autres de se le disputer à nouveau. C’est le modèle à verrous mémoire (memory locks).
Le verrou mémoire consiste à verrouiller l’accès à une ressource partagée lorsqu’une tâche parallèle veut y accéder. Pendant le verrouillage, seule cette tâche peut lire ou écrire ; les autres doivent attendre le déverrouillage pour acquérir à leur tour le verrou.
Le verrou de lecture-écriture (read-write lock) affiné davantage le contrôle : il permet d’ajouter un verrou de lecture (read lock) ou un verrou d’écriture (write lock). Plusieurs tâches peuvent simultanément poser des verrous de lecture pour consulter les données, mais aucune modification n’est autorisée. Un verrou d’écriture est exclusif : seul le détenteur peut accéder à la ressource.
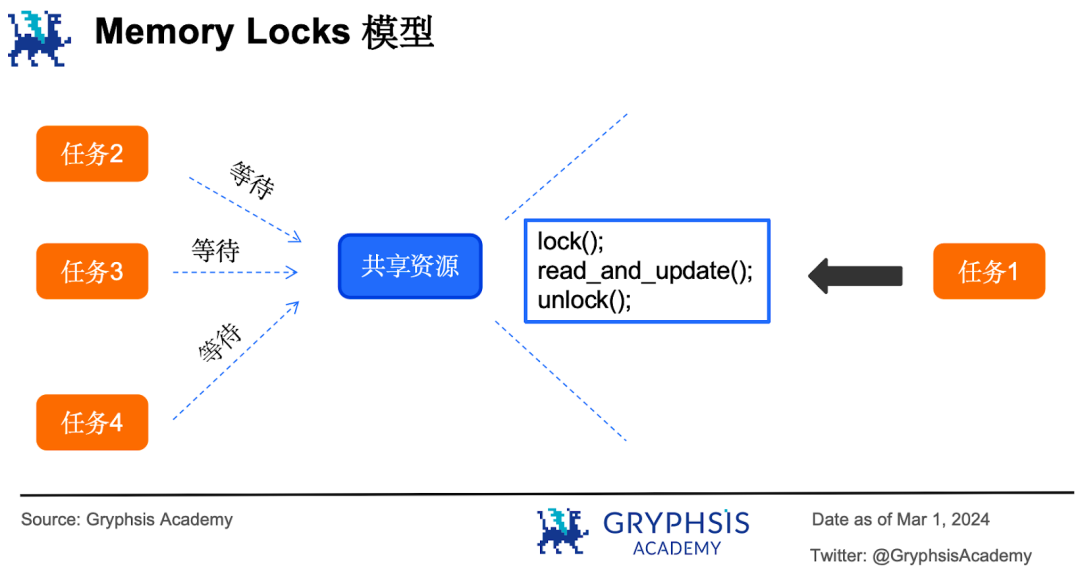
Solana, Sui et Sei v1 utilisent le modèle de mémoire partagée basé sur des verrous mémoire. Bien que ce mécanisme semble simple, sa mise en œuvre est complexe et exige une maîtrise avancée de la programmation multithread. Une erreur peut engendrer divers bogues :
-
Cas 1 : Une tâche verrouille la ressource partagée mais plante avant de libérer le verrou, bloquant définitivement l’accès ;
-
Cas 2 : Une tâche ayant déjà verrouillé tente de re-verrouiller (double verrouillage), entraînant une attente infinie.
Le modèle à verrous mémoire est particulièrement sujet aux problèmes de deadlock (interblocage), livelock (blocage actif) et starvation (famine) :
(1) Plusieurs tâches parallèles se disputent plusieurs ressources, chacune en occupe une partie et attend que l’autre libère la sienne, causant un deadlock ;
(2) Une tâche détecte qu’une autre est active et libère volontairement sa ressource, entraînant un cycle infini d’attentes mutuelles (livelock) ;
(3) Les tâches prioritaires monopolisent toujours l’accès, laissant les autres en attente prolongée (starvation).

2.4.2 Parallélisation optimiste
Cas 7 : Chaque guichetier de la banque peut librement consulter et modifier le registre, indépendamment des autres. Lorsqu’il consulte ou modifie une donnée, il y appose une étiquette personnelle. Après chaque opération, il vérifie : s’il trouve une étiquette différente de la sienne, cela signifie que la donnée a été modifiée par un autre guichetier, et l’opération doit être annulée et recommencée.
C’est le principe de base de la parallélisation optimiste. Son idée centrale est de supposer a priori que toutes les tâches sont indépendantes. Elles s’exécutent en parallèle, puis sont validées individuellement. Si la validation échoue, la tâche est relancée jusqu’à succès. Imaginons 8 tâches parallèles accédant à deux ressources partagées A et B.
À l’étape 1, les tâches 1, 2 et 3 s’exécutent en parallèle. Mais les tâches 2 et 3 accèdent simultanément à la ressource B, créant un conflit : la tâche 3 est donc replanifiée à l’étape suivante. À l’étape 2, les tâches 3 et 4 accèdent à B, entraînant la replanification de la tâche 4, et ainsi de suite jusqu’à la complétion. On observe que les tâches en conflit s’exécutent en boucle.
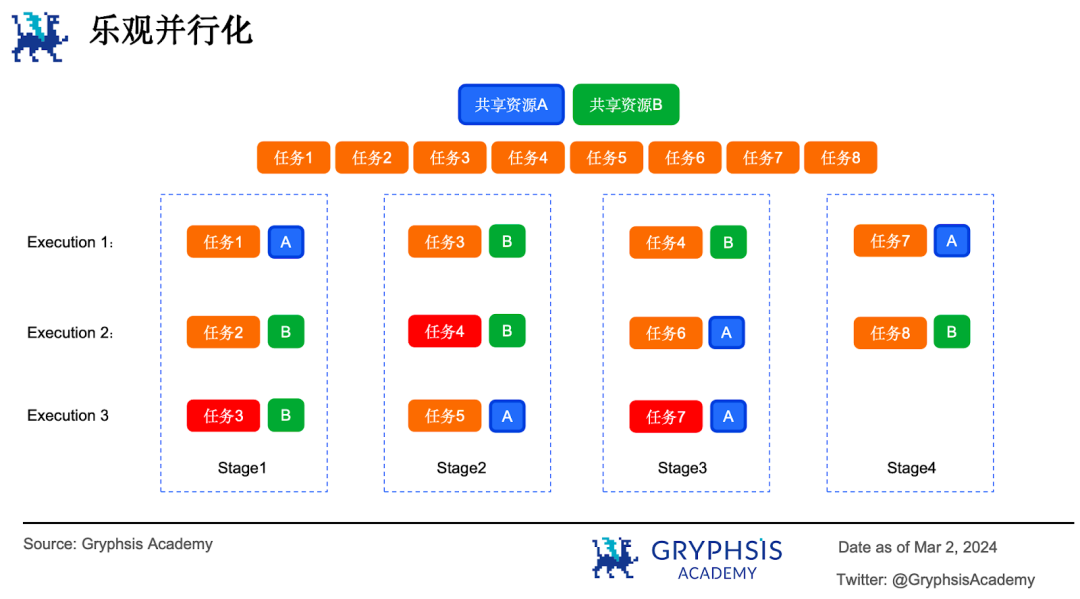
Le modèle de parallélisation optimiste utilise une structure de données en mémoire à versions multiples (multi-version in-memory data structure) pour enregistrer chaque valeur écrite avec son numéro de version (comme les étiquettes des guichetiers).
Chaque tâche parallèle comporte deux phases : exécution et validation. Pendant l’exécution, toutes les lectures et écritures sont enregistrées sous forme d’ensembles de lecture (read set) et d’écriture (write set). Lors de la validation, ces ensembles sont comparés à la structure de données à versions multiples ; si les données ne sont pas à jour, la validation échoue.
Ce modèle provient de la mémoire transactionnelle logicielle (Software Transaction Memory, STM), un mécanisme sans verrou dans le domaine des bases de données. Comme les transactions blockchain ont naturellement un ordre déterminé, ce concept a été adapté en mécanisme Block-STM. Aptos et Monad utilisent Block-STM comme moteur d’exécution parallèle.
Notons que Sei abandonnera son ancien modèle à verrous mémoire dans sa version v2 imminente, au profit de la parallélisation optimiste. Block-STM est extrêmement rapide : dans des tests, Aptos a atteint 160 000 tps, soit 18 fois plus vite qu’une exécution séquentielle.
Block-STM délègue la complexité de l’exécution et de la validation à l’équipe du noyau technique, permettant aux développeurs d’écrire leurs contrats comme s’ils étaient exécutés séquentiellement, sans effort supplémentaire.
2.5 Listes strictes d’accès à l’état
Les mécanismes de passage de messages et de mémoire partagée reposent sur le modèle de données compte/solde, qui enregistre le solde de chaque compte sur la chaîne. Comme un registre bancaire indiquant que le client A a 1000 € et B a 600 €, chaque transaction modifie simplement l’état du solde.
Autre approche : enregistrer uniquement le contenu des transactions sous forme de journal, permettant de recalculer les soldes. Par exemple :
-
Client A ouvre un compte et dépose 1000 € ;
-
Client B ouvre un compte (0 €) ;
-
Client A transfère 100 € à B.
En lisant le journal, on calcule que A a maintenant 900 € et B 100 €.
UTXO (Unspent Transaction Output, sortie de transaction non dépensée) suit ce modèle de journalisation. Il s’agit de la méthode utilisée par Bitcoin, première génération de blockchain, pour représenter la monnaie numérique. Chaque transaction a des entrées (origine) et des sorties (utilisation), et un UTXO correspond simplement à une réception non dépensée.
Par exemple, si A possède 6 BTC
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













