

Partenaire de Dragonfly : « Ne faites pas confiance, vérifiez par vous-même » appliqué au raisonnement décentralisé
TechFlow SélectionTechFlow Sélection
Partenaire de Dragonfly : « Ne faites pas confiance, vérifiez par vous-même » appliqué au raisonnement décentralisé
La blockchain et l'apprentissage automatique ont manifestement beaucoup de points communs.
Rédaction : Haseeb Qureshi
Traduction : TechFlow
Vous souhaitez exécuter un grand modèle de langage comme Llama2-70B. Un modèle aussi volumineux nécessite plus de 140 Go de mémoire, ce qui signifie que vous ne pouvez pas exécuter le modèle brut sur un ordinateur personnel. Quelles sont vos options ? Vous pourriez vous tourner vers des fournisseurs de cloud, mais vous n'êtes peut-être pas très enclin à faire confiance à une seule entreprise centralisée pour traiter cette charge de travail et collecter toutes vos données d'utilisation. Ce qu'il vous faut, c'est une inférence décentralisée, qui vous permettrait d'exécuter des modèles d'apprentissage machine sans dépendre d'un fournisseur unique.
Le problème de la confiance
Dans un réseau décentralisé, il ne suffit pas simplement d'exécuter un modèle et de faire confiance au résultat obtenu. Supposons que je demande au réseau d'analyser un dilemme de gouvernance à l'aide de Llama2-70B : comment puis-je être certain qu'il n'utilise pas en réalité Llama2-13B, me fournissant ainsi une analyse de moindre qualité, tout en empochant la différence ?
Dans un monde centralisé, vous pourriez faire confiance à une entreprise comme OpenAI, car sa réputation est en jeu (et dans une certaine mesure, la qualité des grands modèles linguistiques est intrinsèque). Mais dans un monde décentralisé, l'honnêteté n'est pas par défaut : elle doit être vérifiée.
C’est ici que l’inférence vérifiable entre en jeu. En plus de répondre à une requête, vous devez prouver qu'elle a bien été exécutée sur le modèle demandé. Mais comment y parvenir ?
La méthode la plus simple consisterait à exécuter le modèle comme un contrat intelligent directement sur la chaîne. Cela garantirait certes la vérification du résultat, mais serait extrêmement irréaliste. GPT-3 représente les mots via un embedding de dimension 12 288. Effectuer une seule multiplication matricielle de cette taille sur la blockchain coûterait environ 10 milliards de dollars au prix actuel du gaz, et remplirait chaque bloc pendant environ un mois.
Nous devons donc adopter une approche différente.
Après avoir observé ce domaine, j'ai clairement identifié trois grandes approches pour résoudre l'inférence vérifiable : les preuves à connaissance nulle, les preuves de fraude optimistes et l'économie cryptographique. Chacune comporte ses propres compromis en termes de sécurité et de coût.
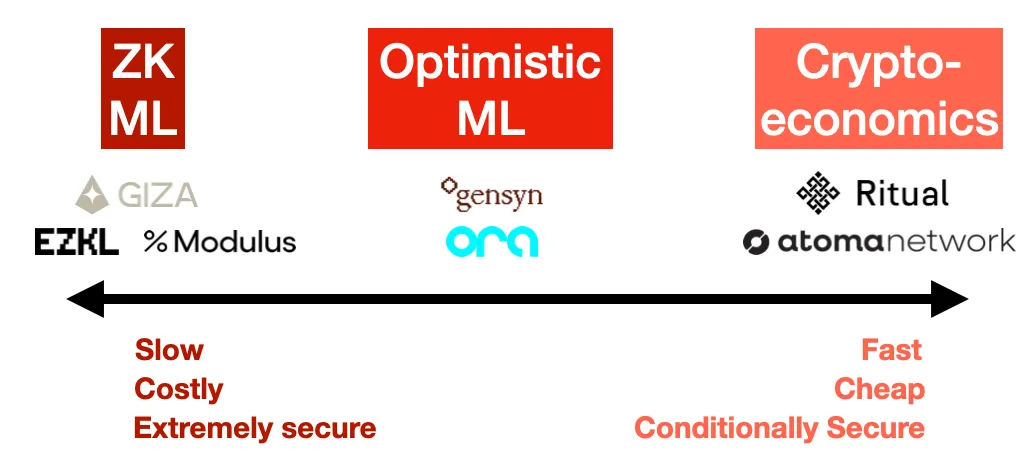
1. Preuves à connaissance nulle (ZK ML)
Imaginez pouvoir prouver que vous avez exécuté un grand modèle, alors que la taille de la preuve reste fixe, indépendamment de la taille du modèle. C’est ce que promet le ZK ML (machine learning), grâce aux ZK-SNARKs.
Bien que cela semble élégant en théorie, compiler un réseau neuronal profond en circuit à connaissance nulle, puis produire une preuve, est extrêmement difficile. Et très coûteux. À tout le moins, vous risquez de voir le coût de l'inférence augmenter d’un facteur 1 000, avec un délai également multiplié par 1 000 (temps nécessaire pour générer la preuve), sans parler de la compilation préalable du modèle lui-même en circuit. Finalement, ce coût sera reporté sur l'utilisateur, rendant cette solution très chère pour les utilisateurs finaux.
En revanche, c’est la seule méthode offrant une garantie cryptographique de correction. Avec ZK, peu importe les efforts du fournisseur de modèle, il ne peut pas tricher. Mais ce niveau de sécurité a un coût si élevé qu’il rend cette approche irréaliste pour les grands modèles, au moins dans un avenir prévisible.
Exemples : EZKL, Modulus Labs, Giza
2. Preuves de fraude optimistes (Optimistic ML)
L’approche optimiste repose sur « croire, mais vérifier ». On suppose que l'inférence est correcte, sauf preuve du contraire. Si un nœud tente de tricher, un « observateur » peut pointer du doigt l’acteur malhonnête dans le réseau et le contester via une preuve de fraude. Ces observateurs doivent surveiller activement la chaîne et réexécuter eux-mêmes le modèle pour s'assurer de la justesse des résultats.
Ces preuves de fraude reposent sur des jeux interactifs de type Truebit : lors d’un tel jeu, on divise itérativement sur la chaîne la trajectoire d’exécution du modèle jusqu’à identifier l’erreur.
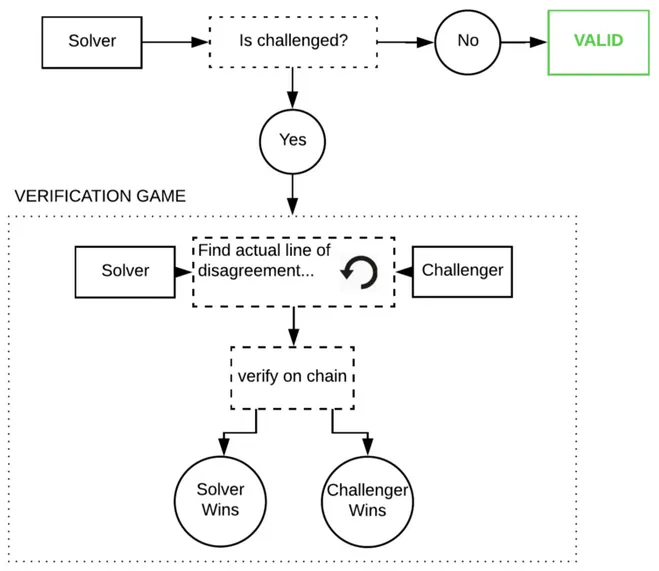
Si cela se produit effectivement, cela serait extrêmement coûteux, car ces programmes sont volumineux et possèdent un état interne énorme : une seule inférence GPT-3 coûte environ 1 petaflop (10⁵ opérations en virgule flottante). Toutefois, la théorie des jeux indique que cela est presque impossible — et par ailleurs, coder correctement ces preuves de fraude est très difficile, car ce code est rarement exécuté en production.
L’avantage de l’approche optimiste est que tant qu’un seul observateur honnête est vigilant, le système ML reste sécurisé. Elle est moins coûteuse que le ZK ML, mais gardez à l’esprit que chaque observateur du réseau réexécute chaque requête. À l’équilibre, cela signifie que si vous avez 10 observateurs, le coût de sécurité doit être reporté sur l’utilisateur, qui devra donc payer plus de 10 fois le coût de l’inférence (ou autant que le nombre d’observateurs).
L’inconvénient est, comme pour les techniques d’agrégation optimistes, qu’il faut attendre la fin de la période de contestation pour s’assurer que la réponse a été validée. Toutefois, selon la configuration du réseau, cette attente peut durer quelques minutes plutôt que plusieurs jours.
3. Économie cryptographique (Cryptoeconomic ML)
Ici, nous abandonnons les technologies sophistiquées pour adopter une approche simple : le vote pondéré par mise. L’utilisateur décide combien de nœuds doivent exécuter sa requête ; chacun soumet sa réponse. S’il y a divergence, les nœuds atypiques sont punis (« slashés »). Mécanisme classique d’oracle, cette méthode offre une approche directe où l’utilisateur règle lui-même son niveau de sécurité, en équilibrant coût et confiance. Si Chainlink faisait du ML, c’est ainsi qu’il procéderait.
La latence est ici faible : il suffit de deux phases, soumission et révélation. Si cela est inscrit sur la blockchain, techniquement, cela peut se produire en deux blocs.
Toutefois, la sécurité est la plus faible. Si la majorité des nœuds collaborent, elles peuvent rationnellement choisir de tricher ensemble. En tant qu’utilisateur, vous devez évaluer combien les nœuds ont misé, et quel coût représenterait pour eux une fraude. Néanmoins, avec des mécanismes comme la re-staking d’Eigenlayer et la sécurité attribuable, le réseau peut offrir une assurance efficace en cas de défaillance de sécurité.
L’avantage de ce système est que l’utilisateur peut choisir son niveau de sécurité. Il peut opter pour 3 ou 5 nœuds dans son quorum, ou tous les nœuds du réseau. S’il veut prendre des risques, il peut même choisir n=1. La fonction de coût est simple : l’utilisateur paie selon le nombre de nœuds qu’il souhaite dans son quorum. S’il choisit 3, il paie 3 fois le coût d’inférence.
La question délicate est la suivante : peut-on rendre n=1 sûr ? Dans une implémentation simple, un nœud isolé tricherait systématiquement s’il n’était pas surveillé. Mais je soupçonne que, si l’on chiffre la requête et que le paiement est conditionné à l’intention, on pourrait cacher au nœud qu’il est le seul à répondre à cette tâche. Dans ce cas, il pourrait être possible de facturer aux utilisateurs ordinaires moins du double du coût d’inférence.
Au final, l’approche cryptoéconomique est la plus simple, la plus facile à mettre en œuvre, et probablement la moins chère, mais c’est aussi, en principe, la moins robuste et la moins sûre. Comme toujours, les détails font toute la différence.
Exemples : Ritual, Atoma Network
Pourquoi l’ML vérifiable est difficile
Vous vous demandez peut-être pourquoi tout cela n’existe pas encore ? Après tout, en dernière analyse, les modèles ML ne sont que de très grands programmes informatiques. Prouver l’exécution correcte d’un programme est au cœur même de la technologie blockchain.
C’est pourquoi ces trois méthodes de vérification reflètent exactement la manière dont les blockchains protègent leur espace bloc : les rollups ZK utilisent des preuves ZK, les rollups optimistes utilisent des preuves de fraude, et la plupart des blockchains de niveau 1 utilisent l’économie cryptographique. Inévitablement, nous aboutissons aux mêmes solutions fondamentales. Alors, pourquoi appliquer cela au ML est-il si difficile ?
Le ML est particulier parce que les calculs ML sont généralement représentés sous forme de graphes de calcul denses, conçus pour fonctionner efficacement sur GPU. Ils ne sont pas pensés pour être prouvés. Par conséquent, si vous souhaitez prouver un calcul ML dans un environnement ZK ou optimiste, il faut le recompiler dans un format adapté, ce qui est extrêmement complexe et coûteux.
Une deuxième difficulté fondamentale du ML est son caractère non déterministe. La vérification de programme suppose que la sortie du programme soit déterministe. Or, si vous exécutez le même modèle sur différentes architectures GPU ou versions de CUDA, vous obtenez des sorties différentes. Même en imposant à tous les nœuds la même architecture, vous êtes confronté au problème de la randomisation utilisée dans les algorithmes (bruit dans les modèles de diffusion, ou échantillonnage de tokens dans les LLM). Vous pouvez contrôler cette aléatoire en fixant la graine du générateur de nombres aléatoires. Mais même ainsi, subsiste un dernier problème troublant : la non-déterminisme inhérent aux opérations en virgule flottante.
Presque toutes les opérations GPU utilisent des nombres à virgule flottante. Ces derniers sont difficiles à manipuler car ils ne sont pas associatifs — autrement dit, pour les flottants, (a + b) + c n’est pas toujours égal à a + (b + c). Du fait de la forte parallélisation des GPU, l’ordre des additions ou multiplications peut varier d’une exécution à l’autre, provoquant de légères différences dans les sorties. Cela affecte rarement la sortie d’un LLM, en raison de la nature discrète des mots, mais pour les modèles d’image, cela peut entraîner des différences subtiles au niveau des valeurs des pixels, empêchant deux images d’être parfaitement identiques.
Cela signifie que vous devez soit éviter complètement les flottants — ce qui aurait un impact majeur sur les performances — soit accepter une certaine flexibilité lors de la comparaison des sorties. Dans les deux cas, les détails sont fastidieux et impossibles à totalement abstraire. (C’est pourquoi la machine virtuelle Ethereum ne supporte pas les flottants, même si certaines blockchains comme NEAR les autorisent.)
En résumé, les réseaux d’inférence décentralisés sont difficiles parce que chaque détail compte, et que les détails du monde réel sont nombreux et imprévisibles.
Conclusion
Actuellement, les blockchains et l’apprentissage machine ont beaucoup en commun. L’un crée des technologies de confiance, l’autre en a désespérément besoin. Bien que chaque méthode d’inférence décentralisée comporte ses compromis, je suis vivement curieux de voir comment les entrepreneurs utiliseront ces outils pour construire les meilleurs réseaux possibles.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













