Test pratique de Kimi Claw : Sous l’engouement pour OpenClaw, l’IA automatisée reste encore à ses débuts
TechFlow SélectionTechFlow Sélection
Test pratique de Kimi Claw : Sous l’engouement pour OpenClaw, l’IA automatisée reste encore à ses débuts
Kimi Claw, l’IA chinoise parmi les premières à « profiter » d’OpenClaw.
Auteur : Xu Shan

En 2026, une écrevisse a secoué l’ensemble du secteur de l’IA : OpenClaw continue de faire parler de lui bien après la période fériée.
Récemment, plusieurs fabricants chinois de modèles ont successivement lancé des produits concurrents d’OpenClaw : MaxClaw, présenté par Mini Max, et Kimi Claw, lancé par Kimi. Il est clair que l’exécution IA démontrée par OpenClaw, ainsi que la tolérance manifestée par les développeurs face aux résultats produits par l’IA, ont révélé un espace de valeur perçu par le marché.
Parmi cette vague de produits concurrents, Kimi Claw se distingue par une position bien définie : il ne s’agit pas d’un produit Claw entièrement développé en interne, mais d’un service cloud hébergé basé sur OpenClaw. Les données sont stockées dans le cloud Moonshot, et plus de 5 000 compétences issues de la communauté ClawHub sont préconfigurées.
Ses avantages résident dans sa stabilité d’utilisation, sa facilité de déploiement et sa simplicité d’adoption. Grâce à son hébergement dans le cloud, il peut fonctionner en continu, 24 heures sur 24, 7 jours sur 7. En accédant au site officiel de Kimi, il suffit d’un simple clic pour créer une instance : Kimi déploie alors immédiatement Kimi Claw.

Déploiement en un clic de Kimi Claw|Source de l’image : GeekPark
Autrement dit, Kimi Claw n’est pas un produit entièrement nouveau : il correspond essentiellement à une machine virtuelle distante déjà configurée, permettant aux utilisateurs d’accéder directement, via Kimi, à un environnement OpenClaw exécuté dans le cloud.
Il n’applique aucune réduction fonctionnelle ni encapsulation supplémentaire ; il est quasiment identique à une installation locale d’OpenClaw, à ceci près que l’étape de déploiement, de configuration et de mise en place de l’environnement est entièrement prise en charge pour l’utilisateur. En revanche, aucune assistance n’est fournie concernant les ajustements nécessaires une fois OpenClaw déployé. Si l’utilisateur ne maîtrise pas la formulation précise des instructions ou la planification adéquate des tâches, la courbe d’apprentissage reste élevée.
Pour les utilisateurs totalement novices avec des produits comme OpenClaw, cela engendre souvent un décalage entre attentes et réalité : ils pensent qu’une simple intégration d’OpenClaw leur permettra immédiatement d’automatiser des tâches IA, alors qu’il ne s’agit en fait que d’une interface pratique supplémentaire, nécessitant encore de nombreuses configurations à explorer personnellement. C’est pourquoi la fourniture, par les fabricants de modèles IA, de « compétences » (skills) prédéfinies populaires deviendra probablement l’un des axes stratégiques prioritaires dans les prochains temps.
Actuellement, Kimi Claw est toujours en phase de test bêta, accessible uniquement aux membres Kimi Allegretto.
I. Construire un flux de travail automatisé pour le bureau en 30 minutes
Nous avons constaté que de nombreux utilisateurs, tout comme nous, restent désorientés quant aux limites réelles des capacités d’exécution de l’IA une fois OpenClaw intégré — ils se demandent ce qu’il peut ou ne peut pas faire, sans savoir par où commencer.
En pratique, qu’il s’agisse d’une installation locale d’OpenClaw ou d’une intégration directe via une interface externe telle que Kimi Claw, l’approche générale d’utilisation peut se diviser en deux voies : construire une application « à partir de zéro », ou optimiser une application existante « à partir de 0,5 ». Nous avons testé concrètement ces deux approches. Nous commençons ici par le développement d’une application « à partir de zéro », afin d’optimiser un flux de travail.
Avant d’expérimenter Kimi Claw, j’ai d’abord examiné quels aspects de mon travail pouvaient être transformés en un flux de travail standardisé, ou quelles tâches de mon flux habituel pourraient être améliorées grâce à l’IA. Jusqu’alors, ma seule considération portait sur le type d’outil IA avec lequel interagir pour obtenir les meilleurs résultats.
J’ai choisi le processus de tenue d’un journal de travail : intégré à mon flux quotidien, il inclut la prise de notes, la synthèse des activités et la réflexion critique, aboutissant à un rapport journalier. Rédiger manuellement un tel rapport prenait beaucoup de temps ; désormais, je souhaite que l’IA le génère automatiquement, en extrayant les données pertinentes puis en structurant le résultat sous forme de tableau interactif.
J’ai d’abord transmis à l’IA une esquisse générale de mon idée, afin qu’elle optimise l’instruction finale. Celle-ci couvre ensuite plusieurs dimensions complexes : définition du rôle, configuration des compétences, intégration des données, flux de travail central, structure du tableau multimédia, points clés à retenir, ainsi que gestion des autorisations et des limites. J’ai ensuite envoyé cette instruction détaillée à Kimi Claw.
Kimi Claw a rapidement analysé l’instruction puis m’a demandé confirmation sur certains détails d’exécution : informations de base, autorisations Lark, stockage des données et mode de déclenchement. Nous avons ensuite procédé, conformément à l’instruction, à la création d’une application Lark, dont nous avons transmis l’ID et le secret à Kimi Claw.
Lors d’une étape impliquant la création d’un tableau dans Lark, j’ai demandé directement à Kimi Claw de me fournir un modèle de tableau, que j’ai ensuite transmis au système IA intégré à Lark afin qu’il le crée automatiquement.

Une des pages d’application créées avec Kimi Claw|Source de l’image : GeekPark
Après avoir traversé divers obstacles — collaborateurs introuvables, page d’application inaccessible, ID non localisé — j’ai finalement reçu, environ trente minutes plus tard, mon premier message provenant de Kimi Claw.
La rapidité de ce déploiement a dépassé mes attentes. À chaque blocage, je précisais simplement à Kimi Claw à quelle étape je butais, puis je sélectionnais parmi les solutions proposées celle qui me semblait la plus adaptée. Si aucune solution ne convenait, je posais à nouveau des questions à Kimi Claw afin d’obtenir d’autres pistes.

Déploiement en un clic de Kimi Claw vers Lark|Source de l’image : GeekPark
Cette expérience a aussi mis en lumière l’importance cruciale de la capacité d’interopérabilité entre plateformes. Après avoir activé douze autorisations Lark, mon application IA n’avait toutefois pas atteint l’état souhaité. Notamment, j’espérais que l’IA puisse analyser mes conversations avec autrui afin d’en extraire mes tâches professionnelles. Or, après plusieurs tentatives, la liste des discussions collectives restait vide : l’application IA de Lark n’est autorisée à lire que les conversations auxquelles elle participe directement, et ne peut donc pas accéder à la liste des salons de discussion.
Dans l’ensemble, Kimi Claw semble très familier avec les outils de développement des plateformes classiques de workflows professionnels, comme Lark ou DingTalk : il identifie presque systématiquement la méthode d’exécution correspondant aux instructions données, même pour des utilisateurs débutants, capables de comprendre et appliquer les consignes. Toutefois, ces applications d’entreprise accordent une grande importance à la protection de leurs propres données, et imposent des conditions strictes pour toute ouverture d’autorisations. Ainsi, pour que l’IA s’intègre réellement aux flux de travail, il ne suffit pas seulement d’outils ouverts comme Kimi Claw : il faut aussi attendre l’émergence d’applications mieux conçues pour une intégration fluide avec l’IA.
Par ailleurs, de nombreux bogues surviennent durant l’exécution : par exemple, les interactions entre l’utilisateur et Kimi Claw, ou les tâches en cours d’exécution par un agent, peuvent être comptabilisées à tort dans l’agenda personnel. Apprendre à corriger ces bogues devient donc une composante essentielle de la « formation » de l’IA.
Si l’on choisit de concevoir soi-même, « à partir de zéro », une application ou une fonctionnalité personnalisée, il faut impérativement disposer d’une vision claire du chemin opérationnel à suivre, ainsi que d’une compréhension élémentaire des principes de conception produit. Il convient notamment de bien définir le niveau d’ouverture et de connectivité des interfaces d’entrée et de sortie, tout en maîtrisant rigoureusement le coût associé à chaque appel ou exécution.
Pour ce flux de travail, la consommation totale de tokens s’est élevée à environ 15 000–25 000, soit environ 1 yuan selon la tarification de Kimi. Le coût journalier moyen est d’environ 0,53 yuan, soit environ 15,90 yuan par mois.
II. Test pratique : Assistant IA automatisé pour les actualités — les applications « prédéfinies » sont rapides à mettre en œuvre, mais leur adaptation comporte un coût
Outre la personnalisation d’une application imaginée par moi-même, j’ai également testé des applications « prédéfinies », comme celle permettant à Kimi Claw de récupérer automatiquement des actualités.
Lors de notre première tentative de veille automatisée sur les actualités, nous avons demandé à Kimi Claw de surveiller le site officiel d’un média technologique. Notre instruction était la suivante :
« Veuillez surveiller le site sectoriel xxxx et, dès la publication d’un nouvel article contenant le mot-clé « IA », en extraire automatiquement le titre, le résumé et la date de publication, puis regrouper ces éléments dans un tableau en ligne. Par ailleurs, veuillez analyser les articles virals selon le style que j’ai défini. »
Kimi Claw nous a demandé de préciser certaines informations de configuration. Toutefois, lors de cette première tentative, nous avons constaté que de nombreux sites officiels intègrent des mécanismes anti-robots (anti-scraping), rendant difficile la surveillance fiable de sources de qualité. Kimi Claw peine également à effectuer une extraction ciblée, ce qui entraîne des cycles vides d’exécution — chaque cycle vide consommant néanmoins une quantité importante de tokens.
Cette tâche de surveillance, lancée entre 4 h et 11 h ce matin, s’est exécutée environ huit fois, consommant environ 180 000 tokens pour un coût d’environ 3,68 yuans. Avec une fréquence initiale d’une exécution horaire, le coût quotidien serait d’environ 11 yuans, soit près de 330 yuans par mois.
Nous avons ensuite consulté des experts, abandonnant l’idée de rédiger nous-mêmes les instructions pour télécharger, depuis des sites comme ClawHub, un « paquet d’instructions » préétabli, puis adapter celui-ci à nos besoins spécifiques en matière d’actualités.
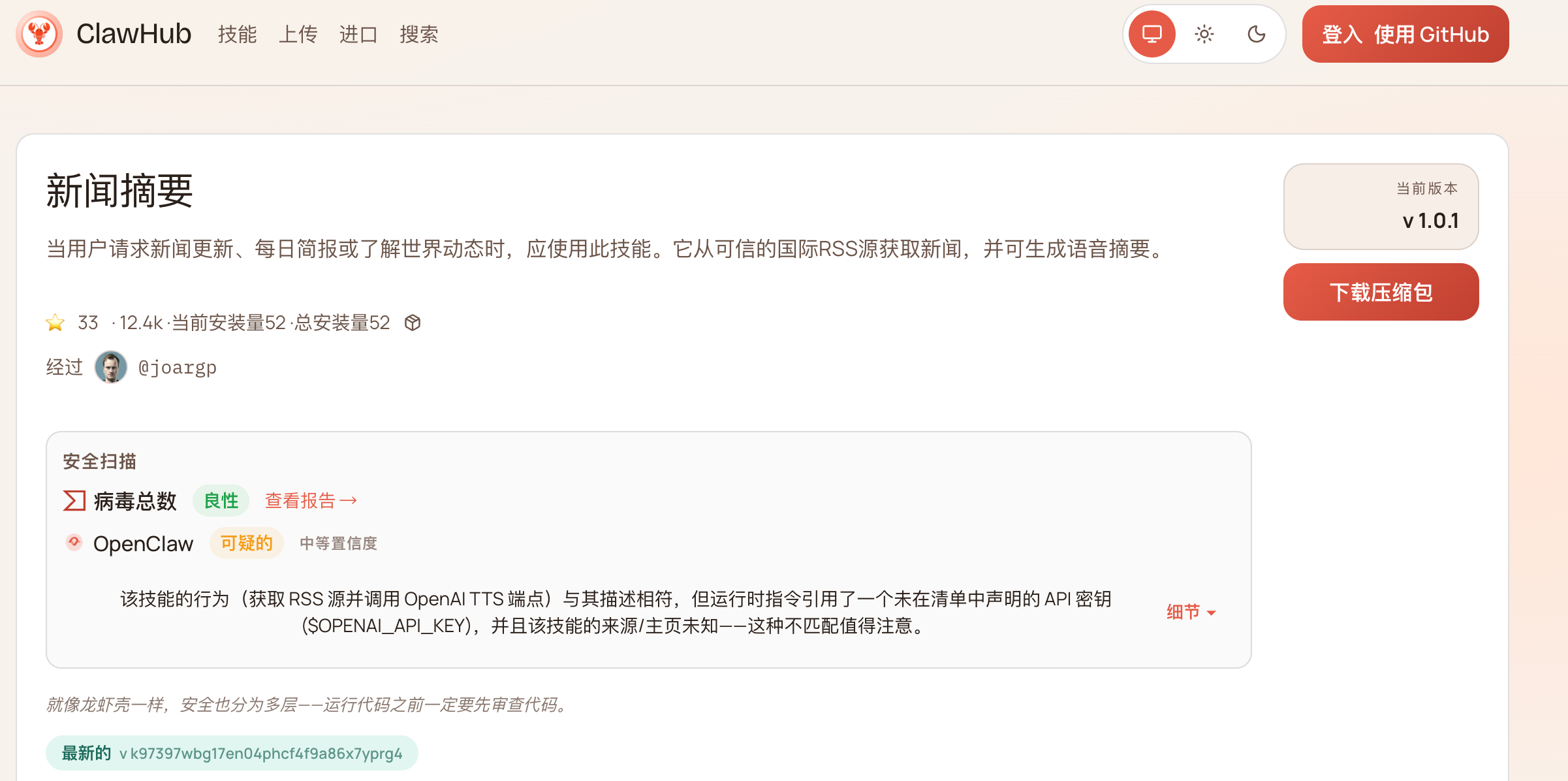
Déploiement d’un fichier ClawHub sur Kimi Claw|Source de l’image : GeekPark
Nous avons ensuite affiné en détail les paramètres relatifs aux médias chinois, aux critères de filtrage des actualités, ainsi qu’à la fréquence et au calendrier d’envoi des informations. Le résultat final s’est avéré satisfaisant.
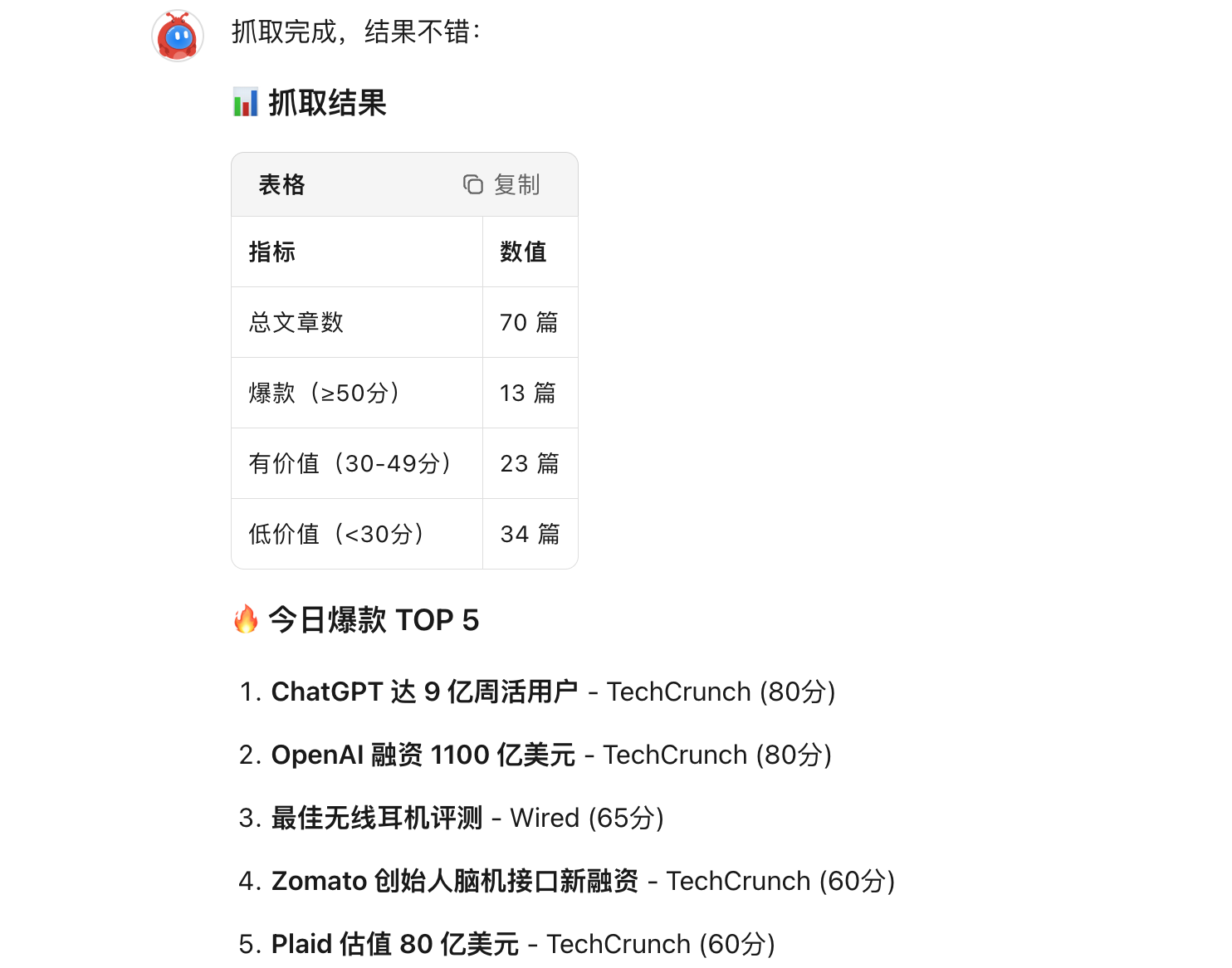
Résultats de la veille automatisée par Kimi Claw|Source de l’image : GeekPark
Il est évident que, dans le cas d’une utilisation passive d’applications prédéfinies, l’enjeu principal consiste à apprendre à sélectionner judicieusement des « paquets de compétences » (skills) de haute qualité, puis à adapter et optimiser les fonctionnalités existantes à son propre contexte d’usage.
Toutefois, toute tentative de modification personnalisée de ces applications IA prédéfinies ramène inévitablement aux mêmes difficultés rencontrées lors de la construction « à partir de zéro » : la complexité du développement et de l’optimisation reste élevée, et les résultats obtenus après modifications ne sont pas forcément optimaux.
Durant ce processus, l’utilisateur doit consacrer beaucoup de temps à tester, au sein d’une même catégorie de produits, la facilité d’usage et l’adéquation de différentes « compétences », afin de décider sur laquelle d’entre elles il va bâtir sa propre version étendue, modifiée ou enrichie. Cette démarche sollicite également fortement le sens produit de l’utilisateur.
III. Retour d’expérience utilisateur sur Kimi Claw : renforcement de l’exécution IA, l’instruction devient productivité
À ce stade, la valeur fondamentale de Kimi Claw réside simplement dans la réduction du seuil technique d’adoption d’OpenClaw, permettant aux utilisateurs chinois de s’y connecter rapidement. Mais le produit lui-même ne propose aucun scénario d’usage ni compétence intégrée : il agit davantage comme un « point de passage », plutôt qu’un « produit fini ».
Notre expérience a également révélé que, bien que Kimi Claw repose en profondeur sur le modèle Kimi K2.5, il utilise une combinaison « modèle nu + OpenClaw natif », sans hériter des capacités hautement optimisées du Kimi disponible sur le site officiel — notamment la recherche multi-étapes, le renforcement de contenu et la correction automatique, toutes développées par l’équipe spécialisée en recherche.
Autrement dit, Kimi sur le site officiel fonctionne si bien parce qu’une équipe dédiée a largement optimisé le modèle pour les scénarios d’usage les plus fréquents des utilisateurs, notamment grâce à des fonctions d’auto-complétion avancées. En revanche, le « modèle nu » utilisé dans l’environnement OpenClaw est plus proche d’un appel API brut, dépourvu de toute optimisation spécifique.
Après une immersion approfondie, j’ai nettement perçu que la différence fondamentale entre l’usage de Kimi Claw et celui des IA traditionnelles ou des produits agents classiques réside principalement sur deux dimensions : la puissance d’exécution de l’IA et la primauté de l’instruction. Ce sont là les deux logiques centrales de ce type de produit.
Premièrement, en termes d’exécution : Kimi Claw peut accomplir des tâches même lorsque vous n’utilisez pas votre ordinateur, contrairement au modèle traditionnel où l’utilisateur lance une instruction puis attend passivement la fin de l’exécution. Je peux même indiquer à Kimi Claw *quand* exécuter une instruction donnée, afin de retrouver, dès mon retour en ligne, les résultats générés à intervalles réguliers. Cela me rappelle toutefois qu’il est essentiel de définir des points d’arrêt explicites pour les applications orientées expérience, afin de limiter la consommation inutile de ressources.
Deuxièmement, en ce qui concerne les instructions : auparavant, mes instructions adressées à l’IA étaient brèves et ciblées directement sur la question posée ; si la piste de réponse fournie n’était pas pertinente, je la reformulais. Avec Kimi Claw, chaque exécution d’une instruction complexe mobilise de nombreux agents, entraînant une multiplication exponentielle de la consommation de tokens. Il devient donc crucial de formuler des instructions extrêmement précises, définissant clairement la méthode d’opération, la portée des autorisations, le chemin d’exécution, ainsi que les contraintes de sécurité et de coût.
Par exemple, mon ancienne instruction pour rechercher des actualités était la suivante : « Fournissez-moi 10 pistes d’actualités liées à OpenClaw et indiquez-moi leur intérêt journalistique. » Aujourd’hui, mon instruction est devenue :
« En tant qu’agent spécialisé en veille informationnelle, vous disposez de l’autorisation d’utiliser des outils de recherche en ligne (uniquement web_search et web_open_url ; l’accès aux bases de données payantes ou nécessitant une authentification est strictement interdit). Vous devez respecter les contraintes suivantes : 1) Effectuez d’abord une recherche avec les mots-clés « dernières actualités sur OpenClaw », en ne conservant que les 5 premiers résultats de haute autorité (privilégiant les médias techniques et les blogs officiels, excluant les messages de forums peu fiables) ; 2) Lors de l’analyse de la valeur journalistique de chaque article, limitez-vous strictement aux trois dimensions suivantes : « percée technologique », « impact commercial », « risques de sécurité » ; chaque dimension doit être résumée en une phrase unique, sans développement ni contexte superflu ; 3) Interdiction absolue d’utiliser des fonctions d’automatisation de navigation ou de scraping approfondi, afin d’éviter tout déclenchement des mécanismes anti-robots et toute consommation inutile de tokens ; 4) Le format de sortie doit être un tableau comportant les colonnes suivantes : Titre de l’article | Source | Étiquette de valeur journalistique | Justification concise (≤ 30 caractères par ligne) ; 5) Si moins de 10 résultats sont obtenus, cessez immédiatement toute recherche complémentaire et produisez la sortie avec le nombre effectif de résultats ; évitez toute recherche élargie (broad search) artificielle pour atteindre un chiffre arbitraire. Le budget de tokens prévu est inférieur à 8 000 ; en cas d’écart significatif par rapport au chemin attendu, interrompez immédiatement l’exécution et signalez-le, sans tenter de correction autonome. »
Dans la plupart des cas, je demande même à l’IA d’optimiser ma formulation d’instruction avant de la transmettre à Kimi Claw. Seules des instructions concrètes et précises permettent d’obtenir des résultats de haute qualité dans un budget raisonnable de tokens. Même sur des forums publics, des bibliothèques de « compétences » (skills) spécifiquement conçues pour OpenClaw aident les utilisateurs à mieux appréhender les usages les plus populaires.
Une instruction précise et concrète constitue la condition préalable indispensable pour obtenir des résultats de qualité dans un cadre de consommation de tokens maîtrisé. Utiliser Kimi Claw revient, en substance, à trouver un équilibre subtil entre les capacités du modèle, la qualité des résultats attendus et le coût d’utilisation.
Kimi Claw|Source de l’image : GeekPark
Enfin, la « formation » de l’IA.
Même après avoir rapidement déployé une application IA, vous constaterez qu’elle ne fonctionne pas parfaitement dès le départ. Ses interprétations des instructions, ses regroupements de tâches, diffèrent souvent fortement de la compréhension humaine, et vous devrez la former progressivement, itération après itération, pour explorer les limites exactes du produit. En particulier, de nombreuses sources d’information ne rendent pas leurs interfaces entièrement publiques. Dans ce contexte, garantir une intégration sécurisée des droits d’accès aux données, ainsi qu’une délégation maîtrisée de ces droits, relève d’un défi considérable.
En définitive, les résultats actuels obtenus avec Kimi Claw ne correspondent pas à ceux d’un simple chatbot doté de fonctions IA prêtes à l’emploi. Il s’agit d’un outil destiné aux développeurs, exigeant une compréhension du processus de développement et une capacité à prendre des décisions éclairées après une analyse multicritère. Ce n’est toutefois qu’un outil de développement simplifié, capable de supporter des déploiements automatisés élémentaires.
L’IA automatisée conserve encore un fort potentiel de développement
Bien qu’OpenClaw ait, dès 2026, totalement embrasé l’imaginaire autour de l’IA automatisée, les récents incidents de sécurité récurrents et les tests pratiques de nouveaux produits montrent clairement qu’OpenClaw demeure, à ce jour, une simple clé ou une opportunité, et non la solution définitive.
Que ce soit en termes de scénarios applicables réellement opérationnels ou de modèles commerciaux pouvant être déployés à grande échelle, le secteur de l’IA n’a pas encore tracé une voie claire et mature. À l’inverse, chaque nouvelle vague de fièvre spéculative du marché relève encore davantage les attentes placées sur les produits de type Claw, attirant même de nombreux utilisateurs novices vers des opérations à haut risque, dépassant largement leurs compétences réelles.
Il est certain que l’IA automatisée a été un enjeu majeur dès les débuts de l’IA. Toutefois, la forme hébergée dans le cloud, incarnée par OpenClaw et Kimi Claw, doit encore prouver sa capacité à générer des produits véritablement réussis et évolutifs à grande échelle. En particulier, ces outils IA obtiennent aujourd’hui un accès direct aux terminaux et fichiers des utilisateurs.
Aux débuts de l’IA, lorsque les limites de ses capacités n’étaient pas encore clairement comprises, de nombreux débutants accordaient sans réfléchir des autorisations étendues, sans songer à mettre en place des restrictions de sécurité ni des confirmations secondaires. Accorder un tel niveau de contrôle à l’IA revient, en effet, à exposer directement le système à des risques systémiques. C’est pourquoi, pour que ces produits parviennent réellement à une adoption massive et une monétisation viable, la gouvernance de la sécurité et des autorisations constituera un obstacle bien plus redoutable que la simple question de « performances ».
Du dialogue direct avec un grand modèle, à l’interaction avec un agent isolé, puis à la collaboration entre une grappe d’agents, jusqu’à la manière actuelle d’utiliser OpenClaw, l’industrie a généré, sur une même base de capacités IA, une multitude d’expérimentations fonctionnellement similaires mais aux parcours radicalement différents. Cela illustre précisément que le secteur se trouve encore dans une phase d’exploration fonctionnelle de l’IA. Hormis le paradigme d’interaction stable et éprouvé de ChatGPT, la logique d’usage, les limites et la valeur des nouvelles formes comme les agents ou les Claw restent encore en cours de découverte collective.
Peut-être faudra-t-il attendre la fin de l’année 2026 pour voir émerger une première génération d’applications IA automatisées réellement stables, utilisables et dotées d’une valeur tangible.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News