

Dernier article de Vitalik : Quel est le point d'intersection le plus fructueux entre la cryptomonnaie et l'IA ?
TechFlow SélectionTechFlow Sélection
Dernier article de Vitalik : Quel est le point d'intersection le plus fructueux entre la cryptomonnaie et l'IA ?
Cet article classera les différentes manières possibles d'intersection entre Crypto et l'IA, et examinera pour chaque catégorie les perspectives et les défis.
Rédaction : Vitalik Buterin
Traduction : Karen, Foresight News
Remerciements particuliers aux équipes de Worldcoin et Modulus Labs, ainsi qu'à Xinyuan Sun, Martin Koeppelmann et Illia Polosukhin pour leurs retours et discussions.
Depuis des années, beaucoup m'ont posé la question suivante : « Quel est le point de convergence le plus fructueux entre les cryptomonnaies et l'IA ? » C’est une question légitime : les cryptomonnaies et l’IA sont deux grandes tendances technologiques logicielles profondes des dix dernières années, il doit donc exister un lien entre elles.
À première vue, il est facile d’identifier des synergies : la décentralisation des cryptomonnaies peut contrebalancer la centralisation de l’IA, l’IA étant opaque alors que les cryptomonnaies apportent de la transparence ; l’IA a besoin de données, et la blockchain excelle dans le stockage et le suivi des données. Mais pendant des années, lorsque l’on me demandait de préciser ces applications concrètes, ma réponse restait plutôt décevante : « Oui, il existe bien quelques cas intéressants, mais pas tant que ça. »
Au cours des trois dernières années, avec l’émergence d’IA plus puissantes comme les grands modèles linguistiques (LLM), ainsi que de technologies cryptographiques avancées – au-delà du simple scaling blockchain – telles que les preuves à connaissance nulle, le chiffrement homomorphe complet, ou encore le calcul sécurisé multiparti (deux ou plusieurs parties), j’ai commencé à percevoir un changement. Il existe bel et bien des applications prometteuses combinant IA et cryptographie au sein de l’écosystème blockchain, même si leur mise en œuvre requiert une grande prudence. Un défi particulier réside dans le fait que, en cryptographie, l’open source est la seule manière de garantir véritablement la sécurité d’un système, tandis qu’en IA, un modèle ouvert (voire ses données d’entraînement) augmente considérablement sa vulnérabilité aux attaques par apprentissage adversaire. Cet article vise à classer les différentes manières dont crypto et IA peuvent se croiser, et à analyser les perspectives et défis de chaque catégorie.
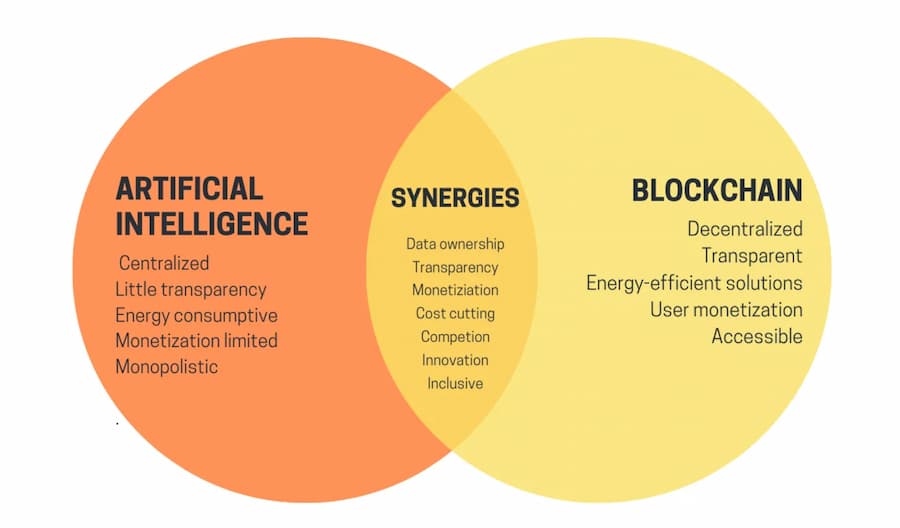
Résumé des points de convergence Crypto+IA depuis le blog uETH. Mais comment concrétiser réellement ces synergies ?
Les quatre grands points de convergence entre Crypto et IA
L’IA est un concept extrêmement vaste : on peut voir l’IA comme un ensemble d’algorithmes créés non pas par spécification explicite, mais en brassant une « soupe computationnelle » sur laquelle on applique une pression d’optimisation pour pousser cette soupe à générer des algorithmes ayant les propriétés désirées.
Cette description ne doit surtout pas être prise à la légère, car elle inclut le processus même qui a créé les êtres humains ! Elle implique aussi que les algorithmes d’IA partagent certaines caractéristiques communes : ils possèdent une capacité très élevée, tout en nous limitant dans notre compréhension ou explication de leur fonctionnement interne.
Il existe de nombreuses façons de catégoriser l’IA. Pour cet article, en lien avec ce que Virgil Griffith expose dans son article « Ethereum is Game-Changing Technology, Literally », je propose la classification suivante :
-
L’IA comme participant au jeu (faisabilité la plus élevée) : dans un mécanisme où l’IA participe, la source ultime des incitations provient d’humains via un protocole.
-
L’IA comme interface du jeu (potentiel élevé, mais risqué) : l’IA aide les utilisateurs à comprendre leur environnement cryptographique, et s’assure que leurs actions (messages signés, transactions) correspondent à leurs intentions, afin d’éviter les tromperies.
-
L’IA comme règle du jeu (nécessite une extrême prudence) : la blockchain, les DAO ou systèmes similaires appellent directement l’IA. Par exemple, un « juge IA ».
-
L’IA comme objectif du jeu (long terme, intéressant) : concevoir une blockchain, une DAO ou système similaire dont le but est de construire et maintenir une IA utilisable à d’autres fins. L’usage de la cryptographie sert soit à mieux inciter à l’entraînement, soit à empêcher la fuite de données privées ou la mauvaise utilisation de l’IA.
Examinons chacune de ces catégories.
L’IA comme participant au jeu
En réalité, cette catégorie existe depuis près de dix ans, au moins depuis que les DEX (échanges décentralisés) ont commencé à être largement utilisés. Dès qu’il y a un marché, apparaissent des opportunités d’arbitrage, et les robots surpassent les humains dans ce domaine.
Ce cas d’usage existe depuis longtemps, même avec des IA bien plus simples qu’aujourd’hui, et constitue bel et bien un point de convergence réel entre IA et cryptomonnaies. Récemment, on observe souvent des bots MEV (Maximal Extractable Value) s’exploitant mutuellement. Chaque application blockchain impliquant enchères ou échanges voit apparaître des bots d’arbitrage.
Mais les bots d’arbitrage alimentés par l’IA ne sont que le premier exemple d’une catégorie plus large, qui devrait rapidement s’étendre à de nombreuses autres applications. Prenons AIOmen, une démonstration de marchés prévisionnels où l’IA est un participant :
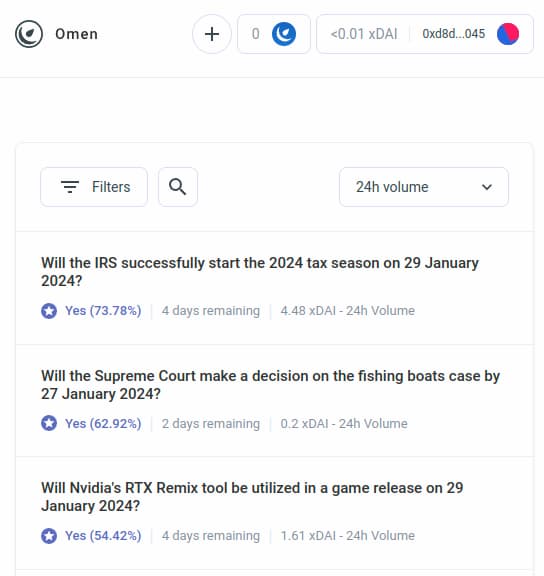
Les marchés prévisionnels ont longtemps été le Saint Graal des technologies cognitives. Dès 2014, j’étais enthousiaste à l’idée d’utiliser les marchés prévisionnels comme entrée pour la gouvernance (« futur gouvernement »), et j’ai récemment testé cela massivement lors d’une élection. Pourtant, jusqu’à présent, ces marchés n’ont pas connu de succès pratique, pour plusieurs raisons : les acteurs principaux sont souvent irrationnels, ceux qui ont la bonne information hésitent à parier sans enjeu financier substantiel, les marchés manquent généralement de liquidité, etc.
Une réponse consiste à souligner les améliorations d’expérience utilisateur apportées par Polymarket ou d’autres nouveaux marchés prévisionnels, espérant qu’ils réussiront là où leurs prédécesseurs ont échoué. Des centaines de milliards de dollars sont misés sur le sport ; pourquoi ne pas investir suffisamment dans l’élection américaine ou LK99 pour attirer des joueurs sérieux ? Mais cet argument bute sur le fait que les versions précédentes n’ont jamais atteint cette échelle (du moins comparées aux rêves de leurs promoteurs), suggérant qu’un élément nouveau est nécessaire. Une autre réponse met donc en avant une particularité de l’écosystème des marchés prévisionnels qu’on peut désormais envisager dans les années 2020, mais pas dans les années 2010 : la participation massive de l’IA.
L’IA peut travailler pour moins d’un dollar de l’heure, avec une connaissance encyclopédique. Et si cela ne suffit pas, elle peut intégrer une recherche web en temps réel. Si vous créez un marché avec une subvention de liquidité de 50 $, les humains s’en moqueront, mais des milliers d’IA afflueront instantanément pour faire leurs meilleures prédictions.
La motivation individuelle pour bien performer sur une question peut être faible, mais celle de créer une IA capable de bonnes prévisions peut valoir des millions. Notez que vous n’avez même pas besoin d’humains pour trancher la plupart des questions : vous pouvez utiliser un système de contestation en plusieurs tours comme Augur ou Kleros, où l’IA participerait aux premiers tours. Les humains n’interviendraient qu’exceptionnellement, quand un litige s’aggrave et que les deux parties ont engagé de grosses sommes.
C’est un primitif puissant : une fois que le « marché prévisionnel » fonctionne à cette micro-échelle, on peut le réutiliser pour de nombreux autres types de problèmes, par exemple :
-
Ce message sur les réseaux sociaux respecte-t-il les [conditions d'utilisation] ?
-
Quelle sera l'évolution du prix de l'action X ? (voir par exemple Numerai)
-
Le compte qui m’envoie ce message est-il vraiment Elon Musk ?
-
Le travail soumis sur cette plateforme est-il acceptable ?
-
L’application DApp sur https://examplefinance.network est-elle une arnaque ?
-
0x1b54....98c3 est-il l'adresse du jeton ERC20 « Casinu In » ?
Vous remarquerez peut-être que beaucoup de ces idées vont dans la direction de ce que j’appelais précédemment la « défense de l’information » (info defense). Globalement, la question est : comment aider les utilisateurs à distinguer vrai et faux, détecter la fraude, sans donner à une autorité centralisée le pouvoir de décider du bien et du mal – pouvoir susceptible d’être abusé ? À l’échelle micro, la réponse pourrait être « l’IA ».
Mais à l’échelle macro, la question devient : qui construit l’IA ? L’IA reflète son processus de création, donc inévitablement ses biais. Il faut un jeu de niveau supérieur pour évaluer les performances des différentes IA, permettant à celles-ci de participer comme joueurs.
L’utilisation de l’IA de cette manière – participant à un mécanisme où elle reçoit des récompenses ou subit des sanctions (probabilistes) issues d’humains via un protocole blockchain – me semble très prometteuse. Le moment est opportun pour explorer ces cas d’usage, car l’évolutivité des blockchains a enfin progressé au point de rendre possible ce qui auparavant était trop coûteux à faire « en chaîne ».
Une classe connexe d’applications explore les agents hautement autonomes, utilisant la blockchain pour coopérer plus efficacement, que ce soit via des paiements ou des engagements crédibles par contrats intelligents.
L’IA comme interface du jeu
Un des points que j’ai avancé dans mon article « My techno-optimism » est qu’il existe un potentiel commercial dans les logiciels grand public capables de protéger les utilisateurs en expliquant leur environnement numérique et en identifiant les dangers. La fonction de détection de fraudes de MetaMask en est un exemple existant.
Un autre exemple est la fonction de simulation du portefeuille Rabby, qui montre à l’utilisateur les conséquences attendues de la transaction qu’il s’apprête à signer.
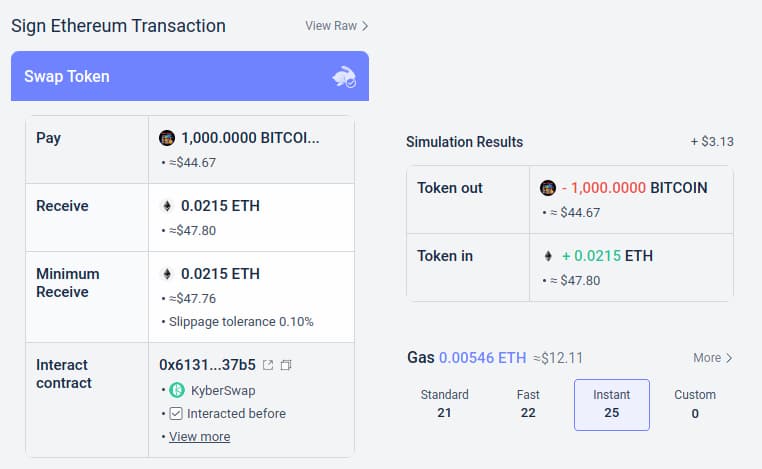
Ces outils peuvent être améliorés par l’IA. L’IA peut fournir des explications plus riches et compréhensibles par l’humain sur la nature d’un DApp, les conséquences d’opérations complexes, ou encore vérifier si un jeton est légitime (par exemple, BITCOIN n’est pas seulement une chaîne de caractères, c’est le nom d’une vraie cryptomonnaie, pas un jeton ERC20 dont le prix serait de 0,045 $). Certains projets avancent déjà fortement dans cette direction (comme le portefeuille LangChain, utilisant l’IA comme interface principale). Mon avis personnel est que les interfaces purement basées sur l’IA comportent aujourd’hui des risques trop élevés, car elles augmentent d’autres types d’erreurs, mais qu’une combinaison IA + interface traditionnelle est très viable.
Un risque spécifique mérite d’être mentionné. Je le développerai plus en détail dans la section suivante sur « l’IA comme règle du jeu », mais le problème général est celui de l’apprentissage adversaire : si un utilisateur a accès à un assistant IA dans un portefeuille open source, alors les malveillants y auront aussi accès, et pourront donc optimiser indéfiniment leurs arnaques pour contourner les défenses du portefeuille. Toutes les IA modernes ont des failles, et même avec un accès limité au modèle, il est facile de les trouver durant l’entraînement.
C’est là que le modèle de « micro-marchés en chaîne avec IA participantes » fonctionne mieux : chaque IA individuelle présente le même risque, mais on crée intentionnellement un écosystème ouvert, composé de dizaines d’acteurs itérant et s’améliorant constamment.
De plus, chaque IA est fermée : la sécurité du système vient de l’ouverture des règles du jeu, pas du fonctionnement interne de chaque participant.
Conclusion : l’IA peut aider les utilisateurs à comprendre simplement ce qui se passe, agir comme tuteur en temps réel, et les protéger contre les erreurs, mais attention face aux manipulateurs et escrocs.
L’IA comme règle du jeu
Nous arrivons maintenant à une application qui enthousiasme beaucoup de monde, mais que je trouve la plus risquée, nécessitant une prudence extrême : l’IA comme composante fondamentale des règles du jeu. Cela rappelle l’enthousiasme des élites politiques mainstream pour les « juges IA » (ex. : voir cet article sur le site du « Sommet du gouvernement mondial »), et des aspirations similaires dans les applications blockchain. Si un contrat intelligent ou une DAO basée sur blockchain doit prendre une décision subjective, peut-on faire de l’IA une partie intégrante du contrat ou de la DAO pour aider à appliquer ces règles ?
C’est ici que l’apprentissage machine adversaire devient un défi extrêmement ardu. Voici un argument simple :
-
Si un modèle IA jouant un rôle clé dans un mécanisme est fermé, on ne peut pas vérifier son fonctionnement interne, donc il n’est pas meilleur qu’une application centralisée.
-
Si le modèle IA est ouvert, les attaquants peuvent le télécharger localement, le simuler, concevoir des attaques hautement optimisées pour le tromper, puis les rejouer sur le réseau en direct.

Exemple d’apprentissage adversaire. Source : researchgate.net
Les lecteurs habituels de ce blog (ou natifs du monde crypto) ont probablement déjà compris où je veux en venir… Mais attendez.
Nous disposons de preuves à connaissance nulle avancées et d’autres formes très sophistiquées de cryptographie. Ne pouvons-nous pas effectuer une sorte de magie cryptographique : cacher le fonctionnement interne du modèle afin que les attaquants ne puissent pas optimiser leurs attaques, tout en prouvant que le modèle s’exécute correctement et a été construit selon un processus d’entraînement raisonnable sur un jeu de données solide ?
Habituellement, c’est précisément le type de raisonnement que je milite sur ce blog. Mais dans le cas du calcul IA, deux objections majeures se présentent :
-
Surcoût cryptographique : exécuter une tâche dans un SNARK (ou MPC, etc.) est beaucoup moins efficace que son exécution en texte clair. Compte tenu de la demande déjà élevée en calcul de l’IA, est-il réellement faisable d’exécuter des calculs IA dans une boîte noire cryptographique ?
-
Attaques adversaires en boîte noire : même sans connaître le fonctionnement interne du modèle, il existe des méthodes pour optimiser des attaques contre un modèle IA. S’il est trop bien caché, cela facilite davantage pour ceux qui choisissent les données d’entraînement de compromettre l’intégrité du modèle via des attaques par empoisonnement.
Ces deux points sont des trous de lapin complexes, qu’il faut examiner séparément.
Surcoût cryptographique
Les outils cryptographiques, notamment les ZK-SNARK et MPC, ont un coût élevé. Vérifier directement un bloc Ethereum prend quelques centaines de millisecondes, mais générer un ZK-SNARK pour prouver sa validité peut prendre plusieurs heures. D’autres outils (comme MPC) ont un coût encore plus élevé.
Le calcul IA est lui-même très coûteux : les meilleurs modèles linguistiques génèrent des mots à peine plus vite que la lecture humaine, et entraîner ces modèles coûte souvent des millions de dollars. L’écart qualitatif entre les modèles de pointe et ceux cherchant à réduire les coûts d’entraînement ou de paramètres est immense. À première vue, cela semble justifier le scepticisme vis-à-vis de l’idée d’envelopper l’IA dans de la cryptographie pour ajouter des garanties.
Heureusement, l’IA est un type de calcul très particulier, offrant diverses possibilités d’optimisation inaccessibles aux calculs plus « désorganisés » comme le ZK-EVM. Examinons la structure de base d’un modèle IA :
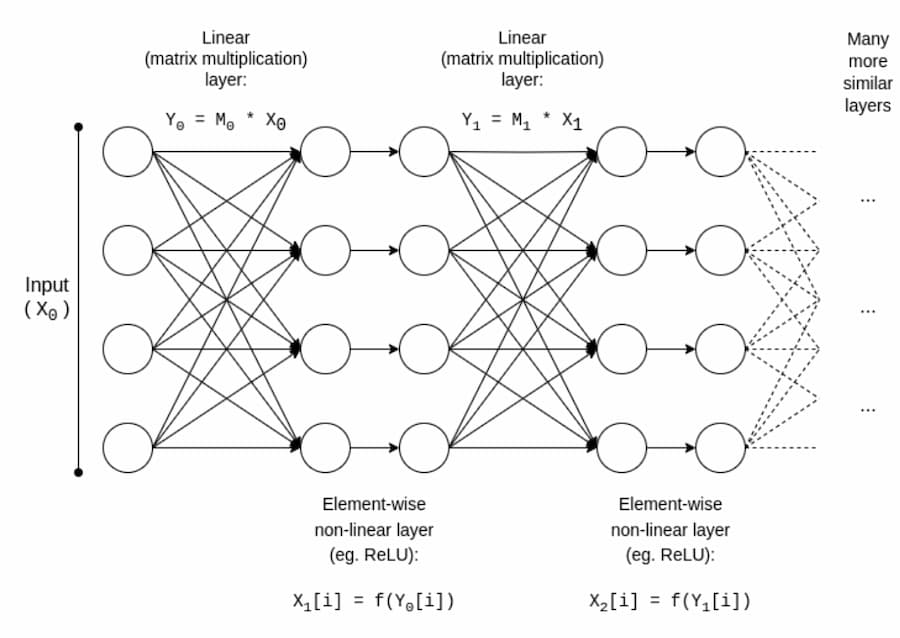
Typiquement, un modèle IA est principalement constitué d’une série de multiplications matricielles entrecoupées d’opérations non linéaires élément par élément, comme la fonction ReLU (y = max(x, 0)). Asymptotiquement, les multiplications matricielles dominent le calcul. C’est favorable à la cryptographie, car de nombreuses techniques peuvent effectuer presque « gratuitement » les opérations linéaires (du moins quand on chiffre le modèle, pas l’entrée, pour multiplier des matrices).
Si vous êtes cryptographe, vous avez peut-être entendu parler d’un phénomène similaire dans le chiffrement homomorphe : additionner des textes chiffrés est très facile, mais la multiplication est très difficile – nous n’avons trouvé une méthode pour la faire en profondeur illimitée qu’en 2009.
Pour les ZK-SNARK, certains protocoles, comme celui de 2013, ont un surcoût inférieur à 4 fois pour les multiplications matricielles. Malheureusement, les couches non linéaires restent coûteuses, avec des implémentations pratiques affichant un facteur ~200.
Mais grâce à des recherches supplémentaires, on peut espérer réduire fortement ce coût. Voyez la présentation de Ryan Cao, qui expose une méthode récente basée sur GKR, ainsi que ma propre simplification des composants principaux de GKR.
Mais pour de nombreuses applications, nous voulons non seulement prouver que le calcul IA est correct, mais aussi cacher le modèle. Il existe des méthodes simples : diviser le modèle pour que différents serveurs le stockent de façon redondante couche par couche, en espérant qu’une fuite partielle n’expose pas trop de données. Mais il existe aussi des formes étonnamment efficaces de calcul multiparti spécialisé.
Dans les deux cas, la morale est la même : la majeure partie du calcul IA repose sur des multiplications matricielles, pour lesquelles on peut concevoir des ZK-SNARK, MPC (voire FHE) très efficaces. Le coût total d’intégrer l’IA dans un cadre cryptographique est donc étonnamment bas. Généralement, les couches non linéaires restent le goulot d’étranglement principal, malgré leur petite taille. Peut-être que des techniques nouvelles comme les arguments de recherche (lookup) pourront aider.
Apprentissage adversaire en boîte noire
Passons maintenant à l’autre problème majeur : même si le contenu du modèle reste secret et qu’on n’y accède qu’en « API », quelles attaques restent possibles ? Citons un article de 2016 :
Beaucoup de modèles d’apprentissage machine sont sensibles aux exemples adverses : des entrées spécialement conçues induisent une sortie incorrecte. Un exemple qui trompe un modèle affecte souvent un autre modèle, même avec une architecture différente ou entraîné sur un autre jeu de données, dès lors qu’ils accomplissent la même tâche. Ainsi, un attaquant peut entraîner son propre modèle substitut, créer des exemples adverses contre ce substitut, et les transférer au modèle victime, avec très peu d’information sur ce dernier.
Potentiellement, même avec un accès très limité ou nul au modèle ciblé, on peut créer des attaques rien qu’avec les données d’entraînement. En 2023, ces attaques restent un problème majeur.
Pour contrer efficacement ces attaques en boîte noire, deux choses sont nécessaires :
-
Restreindre fortement qui ou quoi peut interroger le modèle, et combien de fois. Une boîte noire avec API illimitée est insécurisée ; une API très restreinte peut être sécurisée.
-
Cacher les données d’entraînement, tout en assurant que le processus de création de ces données n’a pas été corrompu.
Concernant le premier point, le projet allant le plus loin est probablement Worldcoin, dont j’ai analysé en détail une version précoce (et d’autres protocoles). Worldcoin utilise intensivement des modèles IA au niveau du protocole pour (i) convertir un scan d’iris en un court « code d’iris » facilement comparable, et (ii) vérifier que l’objet scanné est bien un humain.
La principale défense de Worldcoin est de ne pas permettre à quiconque d’appeler directement le modèle IA : il utilise du matériel de confiance (trusted hardware) pour s’assurer que le modèle n’accepte que des entrées signées numériquement par la caméra orb.
Cette approche n’est pas garantie : on peut attaquer l’IA de reconnaissance biométrique par des patchs physiques ou des bijoux portés sur le visage.

Ajouter un objet sur le front peut contourner la détection ou même usurper l’identité. Source : https://arxiv.org/pdf/2109.09320.pdf
Mais notre espoir est que, combinant toutes les défenses – masquage du modèle IA, restriction stricte du nombre de requêtes, authentification obligatoire de chaque requête – les attaques adversaires deviennent très difficiles, rendant le système plus sûr.
Cela mène à la deuxième question : comment cacher les données d’entraînement ? C’est là que l’idée d’« IA gérée démocratiquement par une DAO » pourrait avoir un sens : créer une DAO en chaîne qui gère qui peut soumettre des données d’entraînement (et les déclarations requises), qui peut interroger, combien de fois, et utiliser des techniques cryptographiques comme le MPC pour chiffrer tout le processus, de l’entrée individuelle des utilisateurs à la sortie finale du modèle. Cette DAO pourrait aussi atteindre l’objectif populaire de rémunérer ceux qui fournissent des données.
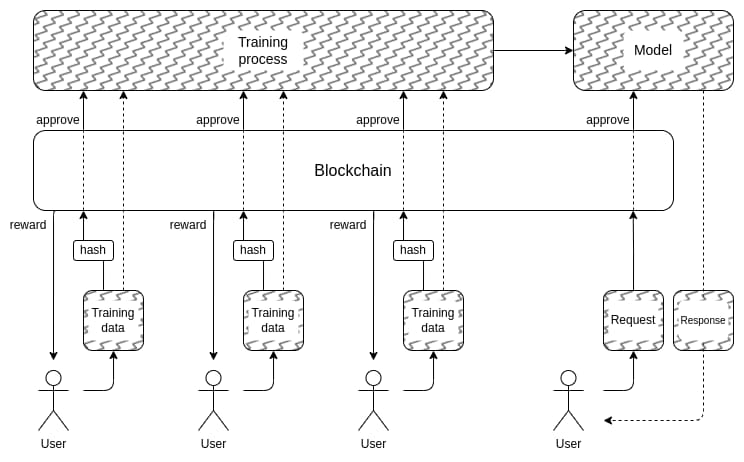
Il faut le dire : ce plan est très ambitieux, et plusieurs aspects pourraient s’avérer irréalistes :
-
Le surcoût cryptographique pour une architecture totalement en boîte noire pourrait rester trop élevé pour concurrencer les méthodes fermées traditionnelles du type « faites-moi confiance ».
-
Il se peut qu’il n’existe aucun bon moyen de décentraliser la soumission des données d’entraînement et d’empêcher les attaques par empoisonnement.
-
Le calcul multiparti pourrait perdre ses garanties de sécurité ou de confidentialité à cause de collusion entre participants : après tout, cela s’est déjà produit plusieurs fois avec les ponts cross-chain.
L’une des raisons pour lesquelles je n’ai pas lancé un avertissement initial du type « Ne devenez pas des juges IA, c’est une anti-utopie » est que notre société dépend déjà fortement d’IA centralisées irresponsables : celles qui décident quels contenus ou opinions politiques sont promus, dégradés, voire cens
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News












