

Podcast Notes | Entretien avec le fondateur de Gensyn : maximiser l'utilisation des ressources informatiques inutilisées grâce à un réseau décentralisé pour soutenir l'apprentissage automatique
TechFlow SélectionTechFlow Sélection
Podcast Notes | Entretien avec le fondateur de Gensyn : maximiser l'utilisation des ressources informatiques inutilisées grâce à un réseau décentralisé pour soutenir l'apprentissage automatique
La blockchain offre un moyen de s'affranchir du besoin d'un décideur unique ou d'un arbitre, car elle permet d'atteindre un consensus entre de grands groupes.
Préparé et traduit par : Sunny, TechFlow
Le protocole de calcul blockchain-AI Gensyn a annoncé le 12 juin avoir levé 43 millions de dollars lors d’un tour de financement de série A mené par a16z.
La mission de Gensyn est de permettre aux utilisateurs d’accéder à une puissance de calcul équivalente à celle des clusters informatiques privés, tout en assurant un accès équitable, crucial, indépendant du contrôle ou de l’arrêt par toute entité centrale. En outre, Gensyn est un protocole de calcul décentralisé spécialisé dans l'entraînement des modèles d'apprentissage machine.
En repassant sur le podcast que les fondateurs de Gensyn, Harry et Ben, ont fait fin 2022 avec Epicenter, on découvre une analyse approfondie des ressources informatiques disponibles, y compris AWS, les infrastructures locales et le cloud, afin de comprendre comment optimiser et utiliser ces ressources pour soutenir le développement des applications d’intelligence artificielle.
Ils ont également exploré en détail la philosophie de conception, les objectifs et le positionnement stratégique de Gensyn, ainsi que les contraintes, hypothèses et stratégies opérationnelles rencontrées au cours du processus de conception.
Le podcast présente les quatre rôles principaux au sein du réseau hors chaîne de Gensyn, examine les caractéristiques du réseau on-chain, ainsi que l’importance du jeton et de la gouvernance de Gensyn.
Par ailleurs, Ben et Harry partagent aussi quelques notions intéressantes sur l’IA, permettant au public de mieux comprendre les principes fondamentaux et les applications de l’intelligence artificielle.

Animatrice : Dr. Friederike Ernst, podcast Epicenter
Intervenants : Ben Fielding & Harry Grieve, cofondateurs de Gensyn
Titre original : 《Ben Fielding & Harry Grieve: Gensyn – The Deep Learning Compute Protocol》
Date de diffusion : 24 novembre 2022
La blockchain comme couche de confiance pour une infrastructure IA décentralisée
L’animatrice demande à Ben et Harry pourquoi ils ont décidé d’allier leur vaste expérience en IA et en apprentissage profond à la technologie blockchain.
Ben explique que cette décision n’a pas été prise du jour au lendemain, mais résulte d’une réflexion prolongée. L’objectif de Gensyn est de construire une infrastructure IA à grande échelle ; lorsqu’ils ont étudié comment atteindre une extensibilité maximale, ils se sont rendu compte qu’il leur fallait une couche sans confiance.
Ils devaient être capables d’agréger des capacités de calcul sans dépendre de nouveaux fournisseurs centralisés, car cela aurait imposé des limites administratives à leur expansion. Pour résoudre ce problème, ils ont commencé à explorer la recherche sur le calcul vérifiable, mais ont constaté qu’elle nécessitait toujours un tiers de confiance ou un juge pour vérifier les calculs.
Cette limitation les a conduits vers la blockchain. La blockchain offre une solution pour éviter de dépendre d’un décideur unique ou d’un arbitre, en permettant un consensus entre de grands groupes.
Harry ajoute qu’il partage avec Ben un fort engagement en faveur de la liberté d’expression et une inquiétude face à la censure.
Avant de s’intéresser à la blockchain, ils étudiaient la formation fédérée, domaine d’apprentissage profond où plusieurs modèles sont formés sur des sources de données distribuées, puis combinés pour créer un méta-modèle capable d’apprendre à partir de toutes les sources. Ils collaboraient avec des banques sur cette méthode. Cependant, ils ont rapidement compris que le véritable obstacle était l’accès aux ressources de calcul ou processeurs nécessaires pour entraîner ces modèles.
Pour maximiser l’agrégation des ressources informatiques, ils avaient besoin d’un mode de coordination décentralisé — c’est là que la blockchain intervient.
Analyse des ressources informatiques disponibles sur le marché : AWS, infrastructures locales et cloud
Harry explique que le choix des ressources informatiques pour exécuter des modèles d’IA dépend de l’échelle du modèle.
Les étudiants peuvent utiliser AWS ou des machines locales, tandis que les startups peuvent opter pour AWS à la demande ou choisir des options moins chères prépayées.
Toutefois, pour des besoins massifs en GPU, AWS peut être limité par le coût et l’évolutivité, auquel cas il est souvent préférable de construire une infrastructure interne.
Des études montrent que de nombreuses organisations peinent à monter en échelle, certaines allant jusqu’à acheter et gérer elles-mêmes leurs GPU. Globalement, acheter des GPU s’avère plus rentable à long terme que d’utiliser AWS.
Les options disponibles pour les ressources de calcul en apprentissage machine incluent le cloud computing, l’exécution locale des modèles d’IA, ou la construction de clusters informatiques propres. L’objectif de Gensyn est de fournir un accès à une puissance de calcul équivalente à celle d’un cluster privé, avec surtout un accès équitable qui ne puisse être contrôlé ou interrompu par aucune entité centralisée.

Tableau 1 : Toutes les options actuelles de ressources informatiques disponibles sur le marché
Discussion sur la philosophie de conception, les objectifs et le positionnement de Gensyn
L’animatrice demande en quoi Gensyn diffère des précédents projets de calcul blockchain comme Golem Network.
Harry explique que la conception de Gensyn repose sur deux axes principaux :
-
Finesse du protocole : contrairement à un protocole de calcul généraliste comme Golem, Gensyn est un protocole spécialisé, conçu spécifiquement pour l’entraînement des modèles d’apprentissage machine.
-
Extensibilité de la vérification : les projets antérieurs reposaient souvent sur la réputation ou des méthodes de duplication peu tolérantes aux pannes byzantines, ce qui ne garantissait pas suffisamment la fiabilité des résultats en apprentissage machine. L’objectif de Gensyn est d’exploiter les enseignements tirés des protocoles de calcul dans l’univers cryptographique, en les adaptant spécifiquement à l’apprentissage machine pour optimiser vitesse et coût, tout en assurant un niveau satisfaisant de vérification.
Harry ajoute que, lorsqu’on considère les propriétés requises par le réseau, celui-ci doit être adapté aux ingénieurs et chercheurs en apprentissage machine. Il doit intégrer une composante de vérification, mais surtout, en permettant à quiconque de participer, il doit être à la fois résistant à la censure et neutre vis-à-vis du matériel.
Contraintes, hypothèses et mise en œuvre durant le processus de conception
Durant la conception de la plateforme Gensyn, Ben insiste sur l’importance des contraintes et hypothèses du système. Leur objectif est de créer un réseau capable de transformer le monde entier en un supercalculateur d’IA, ce qui implique d’équilibrer hypothèses produit, hypothèses recherche et hypothèses techniques.
Concernant le choix de construire Gensyn comme une blockchain de niveau 1, leur justification est de conserver une plus grande flexibilité et autonomie décisionnelle dans des domaines clés tels que le mécanisme de consensus. Ils souhaitent pouvoir prouver leur protocole à l’avenir, sans imposer de restrictions précoces au projet. De plus, ils croient qu’à terme, les différentes blockchains pourront interagir via un protocole d’information largement adopté, ce qui correspond à leur vision.
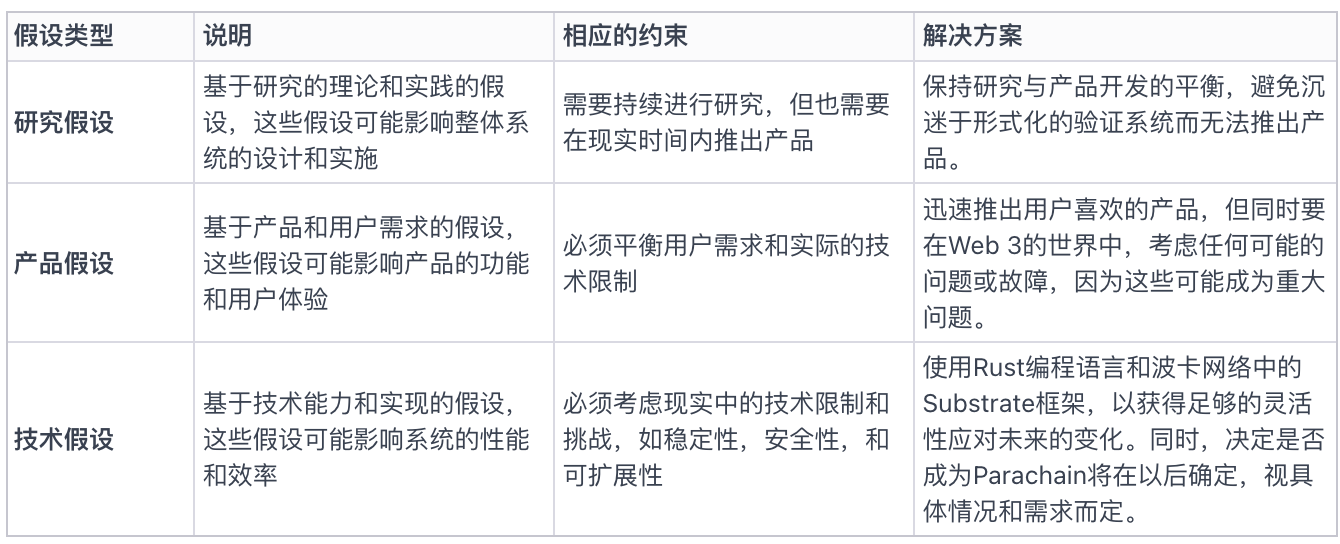
Figure 2 : Hypothèses produit, hypothèses recherche, hypothèses techniques, contraintes et mise en œuvre
Les quatre rôles principaux dans le réseau hors chaîne de Gensyn
Au cours de cette discussion économique autour de Gensyn, quatre rôles principaux sont introduits : le soumissionnaire (submitter), le travailleur (worker), le vérificateur (verifier) et l’indicateur (whistleblower). Le soumissionnaire peut soumettre diverses demandes au réseau Gensyn, comme générer une image spécifique ou développer un modèle d’IA capable de conduire une voiture.
Le soumissionnaire (Submitter) soumet une tâche
Harry explique comment utiliser Gensyn pour entraîner un modèle. L’utilisateur commence par définir le résultat souhaité, par exemple générer une image à partir d’un texte, puis construit un modèle prenant ce texte comme entrée pour produire l’image correspondante. Les données d’entraînement sont cruciales pour l’apprentissage et l’amélioration du modèle. Une fois l’architecture du modèle et les données d’entraînement prêtes, l’utilisateur les soumet au réseau Gensyn avec des hyperparamètres tels que le plan de taux d’apprentissage et la durée de l’entraînement. Le résultat de ce processus est un modèle entraîné que l’utilisateur peut ensuite héberger et utiliser.
Interrogé sur la manière de choisir un modèle non entraîné, Harry propose deux approches :
-
La première repose sur le concept actuel de modèle de base, où de grandes entreprises comme OpenAI ou Midjourney créent des modèles de base que les utilisateurs peuvent ensuite affiner avec leurs propres données.
-
La deuxième option consiste à construire un modèle depuis zéro, différente de l’approche par modèle de base.
Dans Gensyn, les développeurs peuvent utiliser des méthodes similaires à l’optimisation évolutionnaire pour soumettre différentes architectures, les entraîner, les tester et itérer afin d’optimiser le modèle souhaité.
Ben apporte une perspective approfondie sur les modèles de base, qu’il considère comme l’avenir du domaine.
Gensyn, en tant que protocole, espère être utilisé par des DApps mettant en œuvre des techniques d’optimisation évolutionnaire ou similaires. Ces DApps pourront soumettre des architectures individuelles au protocole Gensyn pour entraînement et test, et les raffiner itérativement afin de construire le modèle idéal.
L’objectif de Gensyn est de fournir une base pure de calcul en apprentissage machine, encourageant ainsi le développement d’un écosystème autour de celle-ci.
Bien que les modèles pré-entraînés puissent introduire des biais — car les organisations peuvent utiliser des jeux de données propriétaires ou dissimuler des informations sur le processus d’entraînement — la solution proposée par Gensyn est d’ouvrir le processus d’entraînement, plutôt que d’éliminer la boîte noire ou de compter sur une déterminisme total. En concevant collectivement et en entraînant des modèles de base, nous pouvons créer des modèles globaux exempts des biais liés aux jeux de données d’une entreprise particulière.
Le travailleur (Solver)
-
Concernant l’attribution des tâches, une tâche correspond à un serveur. Toutefois, un modèle peut être divisé en plusieurs tâches.
-
Les grands modèles linguistiques sont conçus pour exploiter pleinement la capacité matérielle maximale disponible à un moment donné. Ce concept peut être étendu au réseau, en tenant compte de l’hétérogénéité des appareils.
-
Pour des tâches spécifiques comme celles du vérificateur ou du travailleur, il est possible de reprendre une tâche depuis le Mempool. Parmi ceux qui se portent volontaires, un travailleur est sélectionné aléatoirement. Si le modèle et les données ne peuvent pas s’adapter à un appareil particulier alors que son propriétaire affirme le contraire, cela pourrait entraîner une amende en cas de congestion du système.
-
La possibilité d’exécuter une tâche sur une machine est déterminée par une fonction aléatoire vérifiable, qui choisit un travailleur parmi un sous-ensemble disponible.
-
Quant à la vérification de la capacité du travailleur, s’il ne dispose pas de la puissance de calcul annoncée, il ne pourra pas mener à bien la tâche, ce qui sera détecté lors de la soumission de la preuve.
-
Cependant, la taille des tâches pose problème. Si elle est trop grande, cela peut provoquer des dysfonctionnements du système, comme une attaque par déni de service (DoS), où un travailleur prétend accomplir une tâche mais ne la termine jamais, gaspillant temps et ressources.
-
Ainsi, le choix de la taille des tâches est crucial et doit prendre en compte des facteurs tels que la parallélisation et l’optimisation de la structure des tâches. Des chercheurs étudient activement les meilleures méthodes selon diverses contraintes.
-
Une fois le testnet lancé, les conditions réelles seront prises en compte pour observer le fonctionnement du système dans le monde réel.
-
Définir la taille idéale des tâches est difficile, et Gensyn est prêt à ajuster et améliorer son approche en fonction des retours et expériences du monde réel.
Mécanisme de vérification et points de contrôle (checkpoints) pour les calculs à grande échelle sur la chaîne
Harry et Ben soulignent que la vérification de la justesse des calculs constitue un défi important, car contrairement aux fonctions de hachage, les calculs en apprentissage machine ne sont pas déterministes, et donc ne peuvent pas être validés simplement par comparaison de hachages. Pour résoudre ce problème, la solution idéale consisterait à appliquer des preuves sans connaissance (zero-knowledge proofs) à l’ensemble du processus de calcul. À ce jour, Gensyn continue de travailler pour atteindre cette capacité.
Actuellement, Gensyn utilise une méthode hybride basée sur des points de contrôle, combinant mécanismes probabilistes et checkpoints pour valider les calculs d’apprentissage machine. En associant un schéma d’audit aléatoire et un chemin dans l’espace des gradients, un système de vérification relativement robuste peut être mis en place. En outre, des preuves sans connaissance sont intégrées pour renforcer le processus de vérification, notamment appliquées à la perte globale du modèle.
Le vérificateur (Verifier) et l’indicateur (Whistleblower)
L’animatrice et Harry discutent des deux rôles supplémentaires impliqués dans le processus de vérification : le vérificateur (Verifier) et l’indicateur (whistleblower). Ils précisent les responsabilités et fonctions spécifiques de chacun.
La tâche du vérificateur est de s’assurer de la justesse des points de contrôle, tandis que celle de l’indicateur est de contrôler l’exactitude du travail du vérificateur. L’indicateur résout le dilemme du vérificateur en garantissant que le travail de ce dernier est correct et digne de confiance. Si le vérificateur commet intentionnellement une erreur, le rôle de l’indicateur est de détecter et de révéler cette erreur, assurant ainsi l’intégrité du processus de vérification.
Le vérificateur introduit intentionnellement des erreurs pour tester la vigilance de l’indicateur et assurer l’efficacité du système. Si une erreur est présente dans le travail, le vérificateur la détecte et informe l’indicateur. L’erreur est ensuite enregistrée sur la blockchain et validée on-chain. Régulièrement, et selon un rythme lié à la sécurité du système, le vérificateur introduit sciemment des erreurs pour maintenir l’engagement de l’indicateur. Si l’indicateur détecte un problème, il participe à un jeu appelé « pinpoint protocol », grâce auquel il peut localiser précisément l’erreur dans un point spécifique de l’arbre de Merkle correspondant à une région spécifique du réseau neuronal. Ces informations sont ensuite soumises à l’arbitrage on-chain. Il s’agit d’une version simplifiée du processus entre vérificateur et indicateur, qui fera l’objet de recherches et développements supplémentaires après la fin de la levée de fonds initiale.
Le réseau on-chain de Gensyn
Ben et Harry discutent en détail du fonctionnement et de la mise en œuvre du protocole de coordination de Gensyn sur la chaîne. Ils abordent d’abord le processus de création des blocs du réseau, impliquant le staking de jetons comme partie intégrante du réseau. Ensuite, ils expliquent comment ces composants interagissent avec le protocole Gensyn.
Ben explique que le protocole Gensyn repose largement sur Substrate, le protocole de Polkadot. Ils utilisent le mécanisme de consensus Grandpa-Babe basé sur la preuve d’enjeu (PoS), avec des validateurs opérant de manière classique. Cependant, tous les composants liés à l’apprentissage machine mentionnés précédemment s’exécutent hors chaîne, impliquant divers participants hors chaîne réalisant leurs tâches respectives.
Ces participants sont incités par le biais de staking, qu’ils peuvent effectuer via le module de staking dans Substrate ou en soumettant un certain nombre de jetons dans un contrat intelligent. Lorsque leur travail est validé, ils reçoivent une récompense.
Ben et Harry mentionnent le défi consistant à équilibrer le montant du staking, les éventuelles sanctions et les récompenses, afin d’éviter d’encourager la paresse ou les comportements malveillants.
En outre, ils discutent de la complexité ajoutée par la présence de l’indicateur, mais soulignent que sa présence est cruciale pour garantir l’honnêteté des vérificateurs, en raison des besoins de calcul à grande échelle. Bien qu’ils explorent continuellement la possibilité d’éliminer l’indicateur grâce aux preuves sans connaissance, ils affirment que le système actuel correspond à ce qui est décrit dans le livre blanc léger, tout en travaillant activement à simplifier chaque aspect.
L’animatrice demande s’ils disposent d’une solution pour la disponibilité des données. Henry explique qu’ils ont introduit sur Substrate une couche nommée proof of availability (POA). Cette couche utilise des technologies telles que le codage d’effacement pour surmonter les limitations rencontrées sur les marchés de stockage étendus. Ils sont très intéressés par les développeurs ayant déjà mis en œuvre de telles solutions.
Ben ajoute que leurs besoins ne concernent pas uniquement le stockage des données d’entraînement, mais aussi les données intermédiaires de preuve, qui n’ont pas besoin d’être conservées longtemps. Par exemple, ces données doivent rester accessibles environ 20 secondes après la publication d’un certain nombre de blocs. Or, le coût actuel de stockage sur Arweave couvre des durées allant jusqu’à des siècles, ce qui est excessif pour ces besoins à court terme. Ils recherchent donc une solution offrant les garanties et fonctionnalités d’Arweave, mais à moindre coût pour les besoins temporaires.
Le jeton et la gouvernance de Gensyn
Ben explique l’importance du jeton Gensyn dans l’écosystème, jouant un rôle clé dans le staking, les pénalités, la distribution des récompenses et le maintien du consensus. Son objectif principal est d’assurer la cohérence financière et l’intégrité du système. Ben mentionne également l’utilisation prudente de l’inflation pour rémunérer les vérificateurs, ainsi que l’application de mécanismes issus de la théorie des jeux.
Il insiste sur l’usage purement technique du jeton Gensyn et affirme qu’ils veilleront à introduire le jeton au bon moment et selon les besoins techniques.
Harry reconnaît qu’ils font partie d’une minorité au sein de la communauté de l’apprentissage profond, notamment face aux scepticismes répandus chez les chercheurs en IA vis-à-vis de la cryptomonnaie. Malgré cela, ils perçoivent la valeur technique et idéologique de la cryptomonnaie.
Toutefois, au lancement du réseau, ils s’attendent à ce que la majorité des utilisateurs d’apprentissage profond utilisent principalement des devises fiduciaires, la conversion en jeton étant effectuée en arrière-plan de manière transparente.
Du côté de l’offre, les travailleurs et soumissionnaires participeront activement aux transactions de jetons, et ils ont déjà reçu de l’intérêt de mineurs Ethereum, possédant de vastes ressources GPU et cherchant de nouvelles opportunités.
Il est ici essentiel d’éliminer la crainte des praticiens de l’apprentissage machine face aux termes cryptographiques (comme « jeton »), en les dissociant de l’interface utilisateur. Gensyn voit là un cas d’usage passionnant reliant les mondes Web 2 et Web 3, grâce à sa logique économique et aux technologies qui soutiennent son existence.
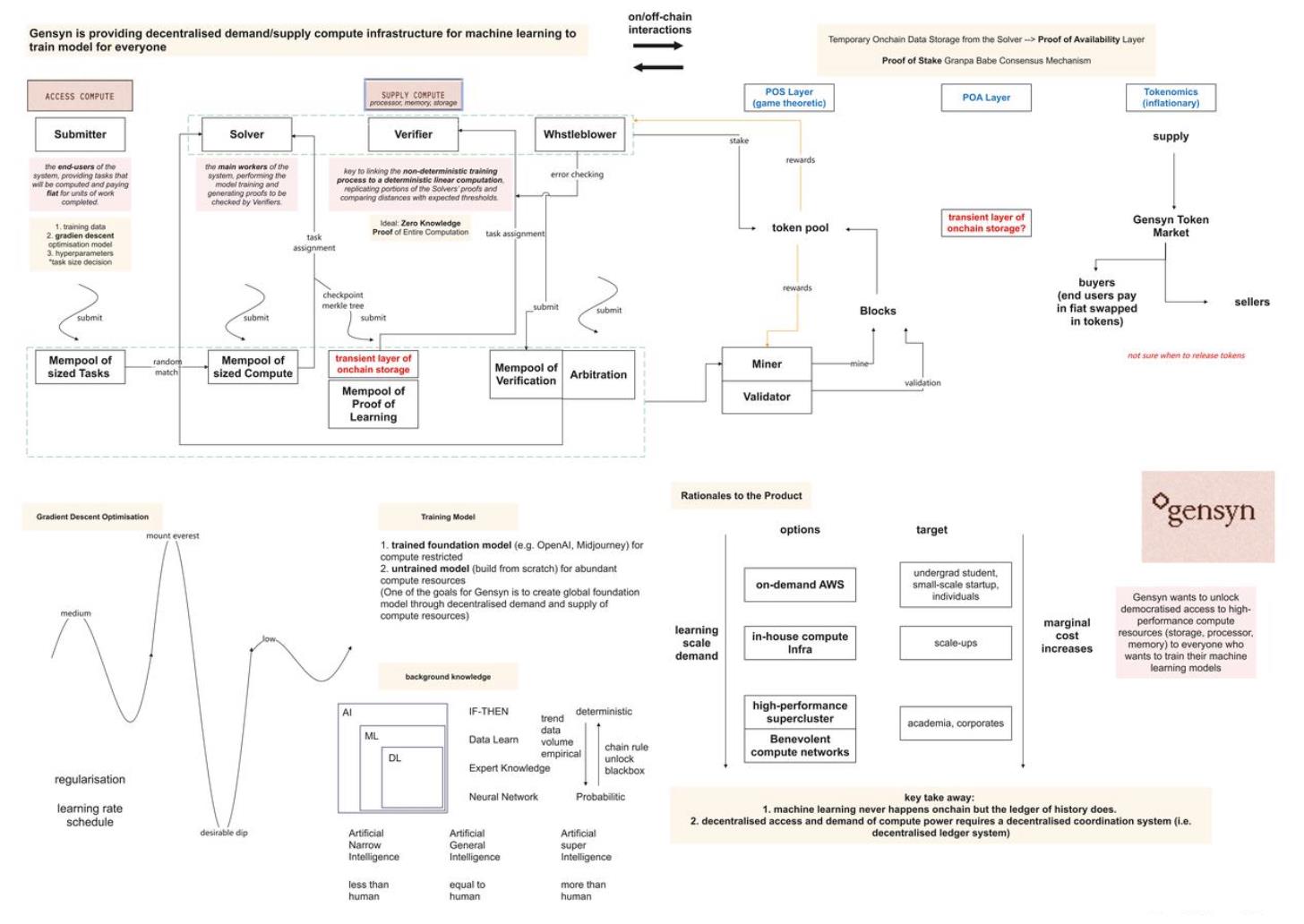
Figure 1 : Schéma du fonctionnement du réseau on-chain et off-chain de Gensyn, basé sur le podcast. Merci aux lecteurs de signaler toute erreur (Source : TechFlow)
Introduction à l’intelligence artificielle
IA, apprentissage profond et apprentissage machine
Ben partage son point de vue sur l’évolution récente du domaine de l’IA. Selon lui, bien que les domaines de l’IA et de l’apprentissage machine aient connu plusieurs petites poussées au cours des sept dernières années, les progrès actuels semblent désormais créer un impact réel et des applications utiles qui parlent à un public plus large. L’apprentissage profond est le moteur fondamental de ces changements. Les réseaux neuronaux profonds ont dépassé les performances des méthodes traditionnelles en vision par ordinateur. De plus, des modèles comme GPT-3 ont accéléré ce progrès.
Harry précise davantage la distinction entre IA, apprentissage machine et apprentissage profond. Il note que ces trois termes sont souvent confondus, alors qu’ils présentent des différences notables. Il compare cela aux poupées russes : l’IA est la couche externe.
-
De façon large, l’IA désigne la programmation permettant à une machine d’exécuter des tâches.
-
L’apprentissage machine, apparu dans les années 90 et 2000, utilise des données pour déterminer la probabilité des décisions, remplaçant les systèmes experts basés sur des règles if-then.
-
L’apprentissage profond s’appuie sur l’apprentissage machine, mais permet des modèles plus complexes.

Figure 3 : Différences entre intelligence artificielle, apprentissage machine et apprentissage profond
Intelligence étroite, intelligence générale, intelligence superintelligente
Dans cette section, l’animatrice et les invités approfondissent trois domaines clés de l’intelligence artificielle : l’intelligence étroite artificielle (ANI), l’intelligence générale artificielle (AGI), et l’intelligence superintelligente artificielle (ASI).
-
Intelligence étroite artificielle (ANI) : l’IA actuelle se situe principalement à ce stade, où les machines excellent à accomplir des tâches spécifiques, par exemple détecter un type particulier de cancer dans des scanners médicaux par reconnaissance de motifs.
-
Intelligence générale artificielle (AGI) : l’AGI désigne une machine capable d’accomplir des tâches simples pour l’humain, mais difficiles à modéliser dans un système informatique. Par exemple, permettre à une machine de naviguer aisément dans un environnement bondé tout en faisant des hypothèses discrètes sur toutes les entrées environnantes illustre l’AGI. AGI signifie qu’un modèle ou système peut exécuter des tâches quotidiennes comme un humain.
-
Intelligence superintelligente artificielle (ASI) : après avoir atteint l’AGI, les machines pourraient évoluer vers l’ASI, surpassant les capacités humaines grâce à la complexité accrue de leurs modèles, une puissance de calcul supérieure, une durée de vie illimitée et une mémoire parfaite. Ce concept est fréquemment exploré dans la science-fiction et les films d’horreur.
Les intervenants mentionnent également que la fusion entre cerveau humain et machine, par exemple via des interfaces cerveau-machine, pourrait être une voie vers l’AGI, bien que cela soulève de nombreuses questions éthiques et morales.
Ouvrir la boîte noire de l’apprentissage profond : déterminisme contre probabilisme
Ben explique que la nature de boîte noire des modèles d’apprentissage profond provient de leur taille absolue. On peut encore suivre un chemin à travers les points de décision du réseau, mais ce chemin est si vaste qu’il devient extrêmement difficile de relier les poids ou paramètres internes du modèle à leurs valeurs spécifiques, car celles-ci résultent de l’entrée de millions d’exemples. On peut le faire de façon déterministe, en traçant chaque mise à jour, mais la quantité de données générée serait alors énorme.
Il observe deux phénomènes :
-
A mesure que notre compréhension des modèles construits augmente, la nature de boîte noire tend à disparaître. L’apprentissage profond est un domaine de recherche qui a traversé une période rapide et intense d’expérimentations, non guidée par des fondements théoriques, mais davantage par la curiosité de voir ce qu’on pouvait obtenir. Nous avons injecté plus de données, testé de nouvelles architectures, juste pour voir ce qui se passait, sans nécessairement concevoir ces systèmes à partir de principes fondamentaux ni comprendre exactement leur fonctionnement. C’était une période passionnante, entièrement opaque. Mais selon lui, cette croissance rapide commence à ralentir, et on assiste à un retour vers l’analyse de ces architectures : « Pourquoi ce modèle fonctionne-t-il si bien ? Étudions-le, prouvons-le. » Ainsi, le voile commence à se lever.
-
Un autre phénomène, potentiellement plus controversé, est l’évolution des mentalités quant à savoir si les systèmes informatiques doivent être totalement déterministes, ou si nous pouvons accepter un monde probabiliste. Les humains vivent dans un monde probabiliste. L’exemple des voitures autonomes est sans doute le plus parlant : quand nous conduisons, nous acceptons qu’un événement aléatoire puisse survenir, qu’un petit accident se produise, ou qu’un système autonome dysfonctionne. Pourtant, nous refusons catégoriquement cela dans le contexte des véhicules autonomes, exigeant un processus parfaitement déterministe. L’un des défis du secteur automobile autonome est que ses acteurs supposent que le public acceptera des mécanismes probabilistes, mais en réalité, ce n’est pas le cas. Il pense que cela changera, même si cela reste débattable : notre société acceptera-t-elle de coexister avec des systèmes informatiques probabilistes ? Il ne sait pas si cette transition sera facile, mais il pense qu’elle adviendra.
L’optimisation par gradient : méthode centrale de l’apprentissage profond
L’optimisation par gradient est l’une des méthodes centrales de l’apprentissage profond, jouant un rôle clé dans l’entraînement des réseaux neuronaux. Dans un réseau neuronal, les paramètres des couches sont essentiellement des nombres réels. L’entraînement consiste à ajuster ces paramètres afin que les données circulent correctement et que la sortie finale corresponde au résultat attendu.
La méthode d’optimisation basée sur le gradient a provoqué une révolution majeure dans les domaines du réseau neuronal et de l’apprentissage profond. Cette méthode utilise le gradient, soit la dérivée partielle des paramètres de chaque couche par rapport à l’erreur. En appliquant la règle de la chaîne, le gradient peut être propagé en arrière à travers l’ensemble du réseau. Ce processus permet de déterminer la position sur la surface d’erreur, qui peut être modélisée comme une surface dans un espace euclidien, ressemblant à un paysage accidenté. L’objectif de l’optimisation est de trouver la zone minimisant l’erreur.
Le gradient indique, pour chaque couche, la position sur cette surface et la direction dans laquelle mettre à jour les paramètres. On peut utiliser le gradient pour naviguer sur ce terrain accidenté, en trouvant la direction qui réduit l’erreur. La taille du pas dépend de la pente de la surface : plus la pente est forte, plus le saut est grand ; plus elle est faible, plus le pas est petit. En somme, on navigue simplement sur cette surface à la recherche d’un creux, et le gradient fournit à la fois la position et la direction.
Cette méthode constitue une percée majeure, car le gradient fournit un signal clair et une direction utile, permettant une navigation bien plus efficace dans l’espace des paramètres qu’une exploration aléatoire. Elle indique si l’on se trouve au sommet, dans un creux ou sur une zone plate.
Bien que de nombreuses techniques existent en apprentissage profond pour trouver des solutions optimales, la réalité est souvent plus complexe. De nombreuses techniques de régularisation utilisées en entraînement d’apprentissage profond en font plus un art qu’une science. C’est pourquoi l’optimisation par gradient, dans la pratique, ressemble davantage à un art qu’à une science exacte.
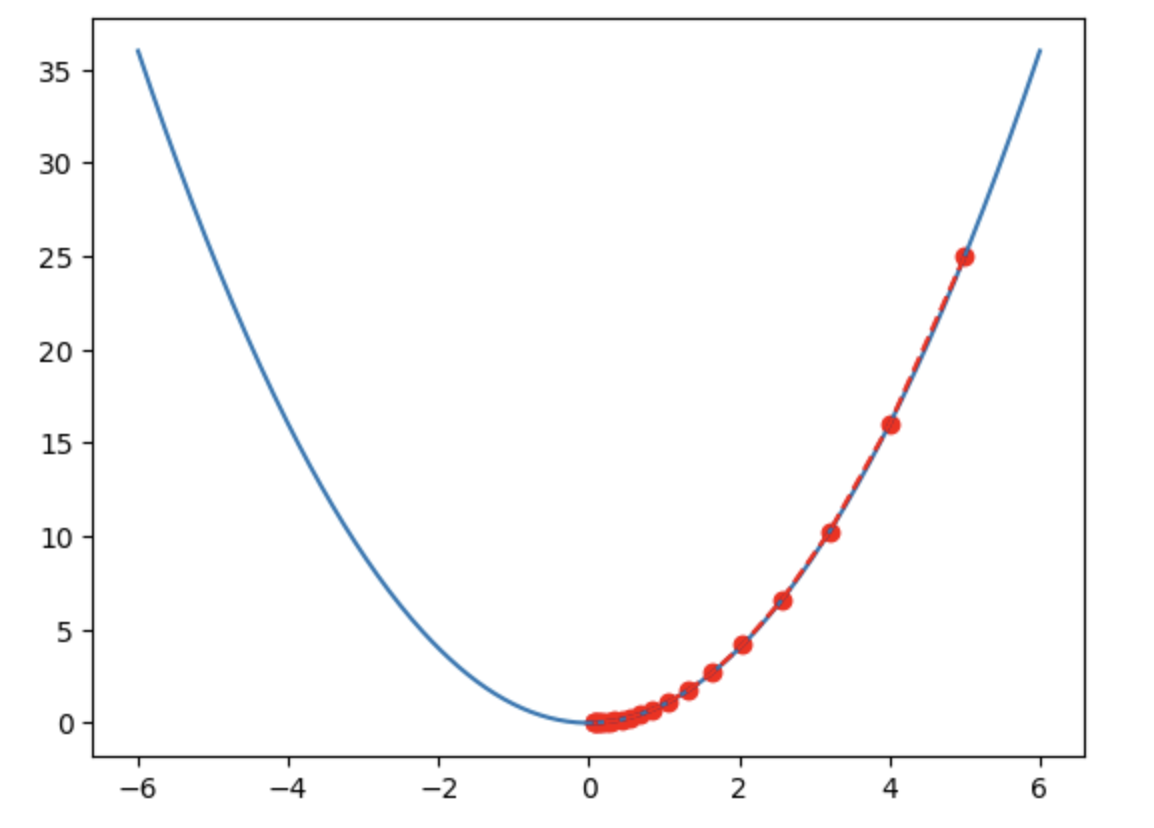
Figure 2 : En résumé, l’objectif est de trouver le fond de la vallée (Source : TechFlow)
Conclusion
L’objectif de Gensyn est de construire le plus grand système mondial de ressources informatiques pour l’apprentissage machine, en exploitant pleinement les ressources informatiques inutilisées ou sous-utilisées, comme les smartphones ou ordinateurs personnels.
Dans le contexte de l’apprentissage machine et de la blockchain, le registre conserve généralement les résultats des calculs, c’est-à-dire l’état des données après traitement par apprentissage machine. Cet état peut être : « J’ai traité ces données via apprentissage machine, valide, horodaté X/X ». L’objectif principal de cet enregistrement est d’exprimer l’état du résultat, pas de décrire le processus de calcul.
Dans ce cadre, la blockchain joue un rôle important :
-
La blockchain offre un moyen d’enregistrer les états résultants des données. Sa conception garantit l’authenticité des données, empêche la falsification et le déni.
-
Elle intègre un mécanisme d’incitation économique permettant de coordonner les comportements des différents rôles du réseau de calcul, comme les quatre rôles mentionnés : soumissionnaire, travailleur, vérificateur et indicateur.
-
L’analyse du marché actuel du cloud computing montre que ce dernier n’est pas sans défauts, et que chaque mode de calcul comporte des problèmes spécifiques. Le calcul décentralisé via blockchain peut jouer un rôle dans certains cas, mais ne peut pas remplacer entièrement le cloud traditionnel — autrement dit, la blockchain n’est pas une solution universelle.
-
Enfin, l’IA peut être vue comme une force productive, mais la manière d’organiser et d’entraîner efficacement l’IA relève des rapports de production. Cela inclut la coopération, le crowdsourcing et les incitations. Dans ce domaine, le Web 3.0 offre de nombreuses solutions et scénarios possibles.
On peut donc conclure que la combinaison de la blockchain et de l’IA, notamment dans le partage des données et modèles, la coordination des ressources de calcul et la vérification des résultats, ouvre de nouvelles possibilités pour résoudre certains problèmes liés à l’entraînement et à l’utilisation de l’IA.
Références
1.https://docs.gensyn.ai/litepaper/
2.https://a16zcrypto.com/posts/announcement/investing-in-gensyn/
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













