

Kernel Ventures : Analyse complète de la conception des DA et des couches de données historiques
TechFlow SélectionTechFlow Sélection
Kernel Ventures : Analyse complète de la conception des DA et des couches de données historiques
La fonctionnalité des chaînes de blocs devient de plus en plus complexe, entraînant une demande accrue d'espace de stockage.
Auteur : Jerry Luo, Kernel Ventures
TL ; DR
-
Les blockchains initiales exigeaient que tous les nœuds du réseau maintiennent une cohérence des données afin d’assurer sécurité et décentralisation. Cependant, avec le développement de l’écosystème blockchain, la pression de stockage augmente continuellement, entraînant une tendance à la centralisation dans l’exploitation des nœuds. À ce stade, les Layer1 doivent impérativement résoudre le problème croissant du coût de stockage induit par la hausse du TPS.
-
Face à ce problème, les développeurs doivent proposer de nouvelles solutions pour le stockage des données historiques, tout en tenant compte simultanément de la sécurité, du coût de stockage, de la vitesse d’accès aux données et de la généralité de la couche DA.
-
Durant cette résolution, de nombreuses technologies et idées émergent, telles que le sharding, le DAS (Data Availability Sampling), les arbres Verkle ou encore les composants intermédiaires DA. Ces approches visent à optimiser le stockage au niveau de la couche DA en réduisant la redondance des données ou en améliorant l’efficacité de leur vérification.
-
Actuellement, les solutions DA se divisent globalement en deux catégories selon l’emplacement du stockage : DA intégrée à la chaîne principale et DA tierce. La première adopte des stratégies comme le nettoyage périodique des données ou le stockage fragmenté pour alléger la charge sur les nœuds. Quant à la DA tierce, conçue spécifiquement pour le stockage, propose des solutions adaptées à de grandes quantités de données, effectuant un compromis entre compatibilité mono-chaîne et multi-chaînes, aboutissant ainsi à trois modèles : DA dédiée à une chaîne principale, DA modulaire et DA basée sur une blockchain de stockage.
-
Les blockchains orientées paiement exigent une sécurité élevée des données historiques, rendant la chaîne principale appropriée comme couche DA. En revanche, pour les blockchains anciennes avec de nombreux mineurs actifs, une solution DA tierce, ne nécessitant pas de modification du consensus mais garantissant la sécurité, serait plus indiquée. Les blockchains généralistes préféreront davantage une solution DA dédiée, offrant grande capacité, faible coût et sécurité. Toutefois, compte tenu des besoins inter-chaînes, une solution DA modulaire constitue aussi une option intéressante.
-
Globalement, la blockchain évolue vers une réduction de la redondance des données et une spécialisation fonctionnelle entre plusieurs chaînes.
1. Contexte
En tant que grand livre distribué, la blockchain requiert que chaque nœud conserve une copie complète des données historiques, assurant sécurité et décentralisation suffisantes. Étant donné que la validité de chaque changement d’état dépend de l’état précédent (origine de la transaction), une blockchain doit, en principe, archiver toutes les transactions depuis sa création jusqu’à aujourd’hui. Prenons Ethereum comme exemple : même en estimant une taille moyenne de 20 Ko par bloc, la taille totale atteint déjà environ 370 Go. Un nœud complet doit en outre stocker l’état global et les reçus des transactions. Avec ces éléments supplémentaires, la capacité totale par nœud dépasse désormais 1 To, ce qui concentre progressivement leur exploitation entre quelques mains.
Hauteur actuelle du dernier bloc Ethereum, source : Etherscan
2. Indicateurs de performance de la DA
2.1 Sécurité
Contrairement aux bases de données ou structures de type liste chaînée, l’immutabilité de la blockchain repose sur la possibilité de vérifier les nouvelles données via les données historiques. Ainsi, la sécurité des données historiques est prioritaire dans la conception de la couche DA. Pour évaluer la sécurité des données dans un système blockchain, on s’appuie généralement sur deux critères : la quantité de redondance des données et la méthode de vérification de disponibilité des données.
-
Quantité de redondance : La redondance des données dans un système blockchain joue plusieurs rôles clés. Premièrement, plus il y a de copies disponibles sur le réseau, plus un validateur peut consulter divers exemplaires lorsqu’il doit vérifier l’état d’un compte dans un ancien bloc, lui permettant de choisir les données confirmées par la majorité des nœuds. Dans une base de données classique, où les données sont stockées sous forme de paires clé-valeur sur un seul nœud, modifier l’historique nécessite une attaque ciblée extrêmement simple et peu coûteuse. En théorie, plus la redondance est élevée, plus la fiabilité des données augmente. De plus, plus il y a de nœuds stockant les données, moins celles-ci risquent d’être perdues. Ce point peut être comparé aux serveurs centralisés des jeux Web2 : si tous les serveurs sont arrêtés, le jeu ferme définitivement. Toutefois, cette redondance ne doit pas être excessive, car chaque copie consomme de l’espace mémoire supplémentaire. Une trop grande redondance alourdit inutilement le système. Une bonne couche DA doit donc trouver un équilibre optimal entre sécurité et efficacité de stockage.
-
Vérification de disponibilité des données : La redondance garantit une présence suffisante des données sur le réseau, mais il reste nécessaire de contrôler leur exactitude et intégrité avant utilisation. Actuellement, les blockchains utilisent couramment des algorithmes cryptographiques d’engagement (commitment schemes). Un petit « engagement cryptographique » est conservé publiquement, généré à partir des données transactionnelles. Pour vérifier l’authenticité d’une donnée historique, on recalcule cet engagement à partir de la donnée candidate, puis on le compare à celui enregistré sur le réseau. S’ils correspondent, la validation réussit. Les méthodes courantes incluent Merkle Root et Verkle Root. Un bon algorithme de vérification assure une haute sécurité tout en nécessitant très peu de données auxiliaires, permettant une vérification rapide.
2.2 Coût de stockage
Après avoir assuré un niveau de sécurité de base, l’objectif suivant de la couche DA est de réduire les coûts et d’améliorer l’efficacité. Réduire le coût de stockage signifie diminuer la place mémoire occupée par unité de données, sans tenir compte des différences matérielles. Actuellement, les principales méthodes utilisées sont le sharding et le stockage incitatif, qui permettent de minimiser le nombre de sauvegardes tout en garantissant une conservation efficace des données. Toutefois, comme on peut le constater, une tension existe entre coût de stockage et sécurité : réduire l’espace utilisé implique souvent une baisse de sécurité. Une excellente couche DA doit donc équilibrer ces deux aspects. De plus, si la couche DA est elle-même une blockchain indépendante, il faut limiter autant que possible les étapes intermédiaires lors des transferts de données afin de réduire les coûts. Chaque étape intermédiaire génère des données d’index nécessaires aux recherches ultérieures, augmentant ainsi le coût total de stockage. Enfin, le coût de stockage est directement lié à la persistance des données : plus il est élevé, plus il devient difficile pour une blockchain de conserver durablement ses données.
2.3 Vitesse d’accès aux données
Une fois les coûts maîtrisés, vient l’amélioration de l’efficacité : la rapidité avec laquelle les données peuvent être récupérées de la couche DA. Ce processus comporte deux étapes. Premièrement, localiser le nœud contenant les données — étape cruciale uniquement pour les blockchains dont les nœuds ne partagent pas tous l’intégralité des données. Si la synchronisation globale est assurée, ce délai est négligeable. Deuxièmement, la plupart des systèmes blockchain actuels (Bitcoin, Ethereum, Filecoin) utilisent une base de données Leveldb. Dans Leveldb, les données sont stockées selon trois modalités. Les données nouvellement écrites vont d’abord dans un fichier de type Memtable, puis, une fois plein, deviennent un Immutable Memtable. Ces deux types résident en mémoire vive. L’Immutable Memtable ne permet plus d’écriture, seulement de lecture. Le stockage « chaud » utilisé par IPFS consiste justement à garder les données ici, permettant un accès très rapide. Toutefois, la RAM d’un nœud standard étant limitée à quelques Go, elle se remplit vite, et toute panne entraîne la perte immédiate des données en mémoire. Pour une conservation permanente, les données doivent être écrites sous forme de fichiers SST sur un disque SSD. Mais lors de la lecture, elles doivent d’abord être chargées en RAM, ce qui ralentit considérablement l’accès. Enfin, dans les systèmes utilisant le sharding, la reconstruction des données nécessite de demander des fragments à plusieurs nœuds, ce qui ajoute également un retard significatif.
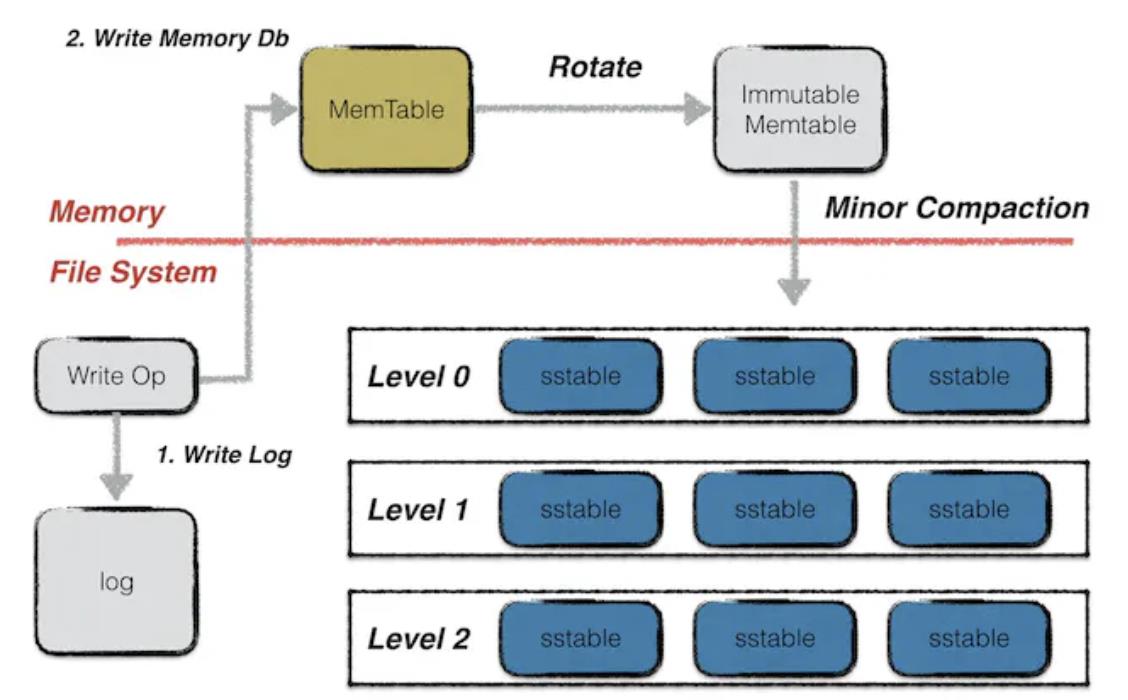
Mode de stockage Leveldb, source : Leveldb-handbook
2.4 Généralité de la couche DA
Avec le développement du DeFi et les problèmes récurrents des CEX, la demande des utilisateurs pour des échanges d’actifs décentralisés inter-chaînes ne cesse de croître. Quelle que soit la méthode inter-chaînes utilisée — verrouillage par hachage, notaires ou chaînes relais — il est indispensable de confirmer simultanément les données historiques sur les deux chaînes concernées. Or, ces données sont séparées, et les différents systèmes décentralisés ne peuvent pas communiquer directement. Une solution proposée consiste alors à stocker les données historiques de plusieurs blockchains sur une même chaîne de confiance. La vérification s’effectue ensuite simplement en consultant cette unique chaîne. Cela suppose que la couche DA puisse établir une communication sécurisée avec différents types de blockchains, autrement dit qu’elle dispose d’une forte généralité.
3. Exploration des technologies DA
3.1 Sharding
-
Dans les systèmes distribués classiques, un fichier n’est pas stocké intégralement sur un seul nœud. Il est divisé en plusieurs blocs, chacun étant affecté à un nœud différent. De plus, chaque bloc n’est pas unique : des sauvegardes sont créées sur d’autres nœuds. Dans les systèmes distribués modernes, on fixe généralement ce nombre de sauvegardes à 2. Cette technique de sharding diminue la charge individuelle de stockage, étendant ainsi la capacité totale du système à la somme des capacités locales, tout en maintenant la sécurité grâce à une redondance raisonnable. Les blockchains adoptent un schéma similaire, bien que certains détails varient. Tout d’abord, comme les nœuds blockchain sont supposés non fiables, un nombre bien supérieur de sauvegardes est nécessaire pour valider l’authenticité des données. Ainsi, le nombre de copies doit largement dépasser 2. Idéalement, si le nombre total de nœuds validateurs est T et le nombre de fragments N, chaque fragment devrait être copié T/N fois. Ensuite, concernant l’affectation des blocs, les systèmes classiques utilisent des algorithmes de hachage cohérent pour mapper les données sur un anneau, puis attribuer à chaque nœud une plage spécifique de blocs. Un nœud peut même ne recevoir aucun bloc à stocker lors d’un cycle. En revanche, dans les blockchains, chaque nœud reçoit nécessairement un bloc à stocker. L’affectation se fait aléatoirement : le hachage combiné des données du bloc et de l’identité du nœud est pris modulo N. Si chaque donnée est divisée en N blocs, la taille effective de stockage par nœud devient 1/N de l’original. En ajustant correctement N, on équilibre augmentation du TPS et pression de stockage.
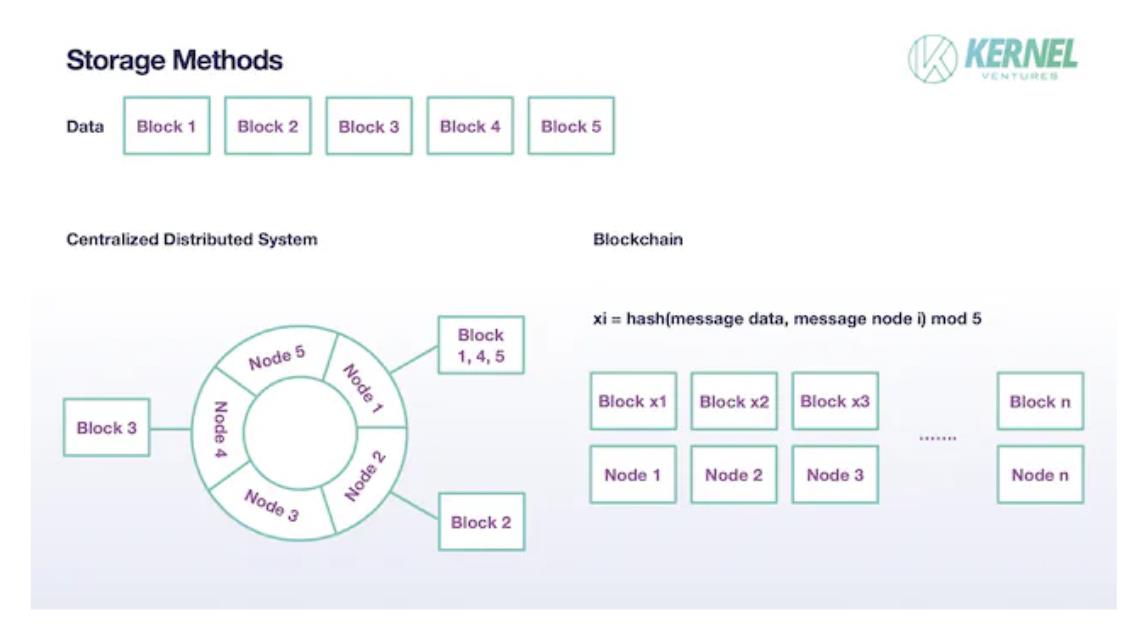
Architecture de stockage après sharding, source : Kernel Ventures
3.2 DAS (Data Availability Sampling)
Le DAS constitue une amélioration du sharding en matière de stockage. Dans le sharding classique, le stockage aléatoire des nœuds peut conduire à la perte d’un bloc. De plus, lors de la reconstruction, il est crucial de vérifier l’authenticité et l’intégrité des données fragmentées. Le DAS résout ces deux problèmes grâce au code d’effacement (Erasure Code) et aux engagements polynomiaux KZG.
-
Erasure code : Compte tenu du grand nombre de nœuds validateurs sur Ethereum, la probabilité qu’un bloc ne soit stocké par aucun nœud est quasi nulle. Toutefois, en théorie, ce scénario extrême reste possible. Pour atténuer ce risque, on n’applique pas directement le sharding aux données brutes. On commence par projeter les données brutes sur les coefficients d’un polynôme de degré n, puis on évalue ce polynôme en 2n points. Chaque nœud choisit aléatoirement un de ces points à stocker. Or, un polynôme de degré n peut être reconstruit à partir de n+1 points seulement. Ainsi, dès que la moitié des blocs sont présents, les données originales peuvent être restaurées. Grâce à l’erasure code, la sécurité du stockage et la capacité de récupération du réseau sont fortement renforcées.
-
Engagement polynomial KZG : La vérification de l’authenticité des données est essentielle. Dans un réseau sans erasure code, diverses méthodes peuvent être utilisées. Mais avec l’introduction de l’erasure code, l’engagement polynomial KZG devient particulièrement adapté. Il permet de vérifier directement le contenu d’un bloc sous forme polynomiale, évitant ainsi la conversion en données binaires. Le mécanisme est similaire à Merkle Tree, mais contrairement à ce dernier, il ne nécessite pas les nœuds intermédiaires du chemin (path), seulement le KZG Root et les données du bloc pour valider son authenticité.
3.3 Méthodes de vérification des données DA
La vérification des données garantit qu’elles n’ont pas été altérées ni perdues lors du stockage. Afin de minimiser les données et calculs requis durant cette vérification, la couche DA utilise principalement des structures arborescentes. La plus simple est l’arbre de Merkle, qui utilise un arbre binaire complet. Il suffit de conserver le Merkle Root et les valeurs de hachage des nœuds frères sur le chemin pour vérifier une donnée. La complexité temporelle est en O(logN) (logarithme en base 2 par défaut). Bien que cela simplifie grandement le processus, la quantité de données à transmettre augmente toujours avec la taille totale. Pour pallier cela, une nouvelle méthode a été proposée : l’arbre Verkle. Dans un arbre Verkle, chaque nœud contient non seulement sa valeur, mais aussi un Vector Commitment. Grâce à cette preuve d’engagement, la vérification peut s’effectuer rapidement sans avoir besoin des nœuds frères. Le nombre d’opérations par vérification dépend uniquement de la profondeur de l’arbre, restant constant quelle que soit la taille. Toutefois, le calcul du Vector Commitment requiert la participation de tous les nœuds frères du même niveau, augmentant fortement le coût d’écriture et de mise à jour. Mais pour les données historiques, qui sont stockées de façon permanente et immuable, où seule la lecture intervient, l’arbre Verkle est particulièrement adapté. Notons enfin que Merkle Tree et Verkle Tree ont également des variantes K-ary, similaires en principe mais avec un nombre variable de fils par nœud. Le tableau ci-dessous compare leurs performances.
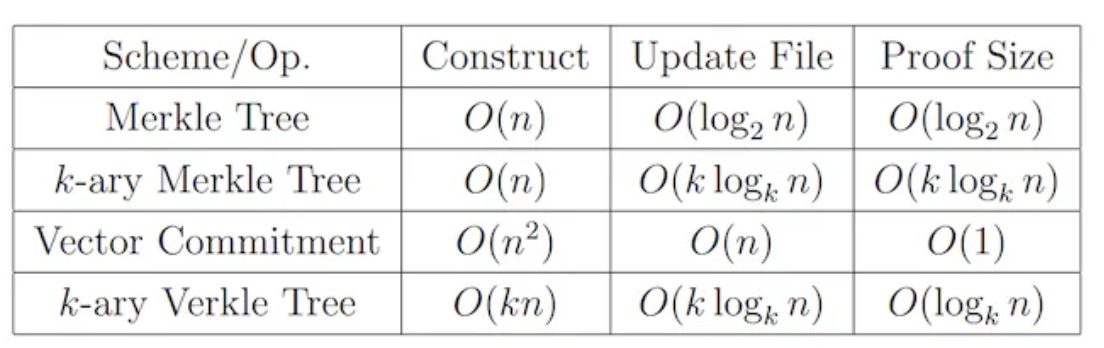
Comparaison des performances de vérification, source : Verkle Trees
3.4 Middleware DA universel
L’expansion continue de l’écosystème blockchain entraîne une multiplication des blockchains. Chacune possédant ses avantages spécifiques et son rôle irremplaçable, une convergence des Layer1 semble improbable à court terme. Parallèlement, avec le développement du DeFi et les dysfonctionnements des CEX, la demande pour des échanges inter-chaînes décentralisés ne cesse de croître. Ainsi, le stockage multichaîne au niveau de la couche DA, capable d’éliminer les risques liés aux échanges de données inter-chaînes, attire de plus en plus d’attention. Toutefois, pour accepter les données historiques provenant de différentes blockchains, la couche DA doit fournir un protocole décentralisé normalisant le stockage et la vérification des flux de données. Par exemple, kvye, un middleware basé sur Arweave, récupère activement les données en ligne pour les stocker de manière standardisée sur Arweave, minimisant ainsi les différences lors des transferts. En comparaison, les solutions Layer2 dédiées à une seule blockchain, bien qu’offrant une interaction sécurisée et économique via des nœuds partagés, sont limitées à une seule chaîne.
4. Solutions de stockage DA
4.1 DA intégrée à la chaîne principale
4.1.1 Type DankSharding
Cette catégorie de solutions n’a pas encore de nom officiel, mais le représentant le plus emblématique en est DankSharding sur Ethereum. Nous parlerons donc de « solutions de type DankSharding ». Elles combinent deux techniques présentées précédemment : le sharding et le DAS. D’abord, les données sont divisées en fragments appropriés via le sharding, puis chaque nœud stocke un bloc selon le principe du DAS. Lorsque le nombre total de nœuds est suffisamment élevé, on peut choisir un nombre élevé de fragments N, réduisant ainsi la charge de stockage par nœud à 1/N de l’original, multipliant par N la capacité globale de stockage. Pour éviter le cas extrême où aucun nœud ne stockerait un bloc donné, DankSharding encode les données avec un Erasure Code, permettant la reconstruction complète à partir de la moitié seulement des blocs. Enfin, pour la vérification, la structure de l’arbre Verkle et les engagements polynomiaux sont utilisés, permettant une validation ultra-rapide.
4.1.2 Stockage temporaire
Pour la DA intégrée à la chaîne principale, la méthode la plus simple consiste à conserver les données historiques de façon temporaire. Fondamentalement, la blockchain agit comme un registre public, permettant de modifier son contenu sous le regard collectif du réseau, sans nécessiter de stockage permanent. Par exemple, Solana synchronise ses données historiques vers Arweave, mais ses nœuds principaux ne conservent que les transactions des deux derniers jours. Sur une blockchain basée sur des comptes, il suffit de garder l’état final des comptes à chaque instant pour valider les modifications futures. Pour les projets ayant un besoin spécifique de données antérieures, ils peuvent choisir de les stocker eux-mêmes sur une autre blockchain décentralisée ou auprès d’un tiers de confiance. Autrement dit, ceux qui ont des besoins supplémentaires doivent payer pour le stockage des données historiques.
4.2 DA tierce
4.2.1 DA dédiée à la chaîne : EthStorage
-
DA dédiée à la chaîne principale : La sécurité du transfert des données est primordiale dans la couche DA, et elle est maximale lorsque celle-ci est intégrée à la chaîne principale. Toutefois, le stockage sur la chaîne principale est limité par l’espace disponible et la concurrence des ressources. Quand le volume de données croît rapidement, une DA tierce devient une meilleure option pour un stockage à long terme. Si cette DA tierce est hautement compatible avec le réseau principal — notamment en partageant des nœuds — la sécurité des échanges de données s’en trouve renforcée. Ainsi, dans un souci de sécurité, la DA dédiée à la chaîne principale présente un avantage majeur. Prenons Ethereum : une condition fondamentale pour une telle DA est la compatibilité avec la machine virtuelle Ethereum (EVM), assurant l’interopérabilité entre les données et contrats. Des projets comme Topia ou EthStorage illustrent cette approche. EthStorage se distingue particulièrement par son haut niveau de compatibilité, non seulement au niveau EVM, mais aussi via des interfaces spécifiques intégrées à des outils de développement Ethereum comme Remix ou Hardhat.
-
EthStorage : EthStorage est une blockchain indépendante d’Ethereum, mais ses nœuds forment un sur-ensemble des nœuds Ethereum : tout nœud Ethereum peut aussi exécuter EthStorage. Grâce à des opcodes spécifiques, les actions sur Ethereum peuvent directement manipuler EthStorage. Le modèle de stockage conserve uniquement de petites métadonnées sur la chaîne principale pour l’indexation. En réalité, EthStorage crée une base de données décentralisée pour Ethereum. Actuellement, cette interaction est réalisée par un contrat déployé sur Ethereum appelé « EthStorage Contract ». Lorsqu’Ethereum souhaite stocker des données, il appelle la fonction put() du contrat, avec deux paramètres : key (clé) et data (données). data correspond aux données à stocker, tandis que key sert d’identifiant unique sur le réseau Ethereum, similaire au CID dans IPFS. Une fois le couple (key, data) stocké sur le réseau EthStorage, celui-ci génère un identifiant kvldx retourné à Ethereum, associé à la clé. Ce kvldx représente l’adresse de stockage sur EthStorage. Ainsi, un problème de stockage volumineux devient un simple stockage d’un couple (key, kvldx), réduisant drastiquement la charge sur Ethereum. Pour récupérer les données, on utilise la fonction get() d’EthStorage avec la clé, et via le kvldx enregistré sur Ethereum, une recherche rapide est effectuée sur EthStorage.
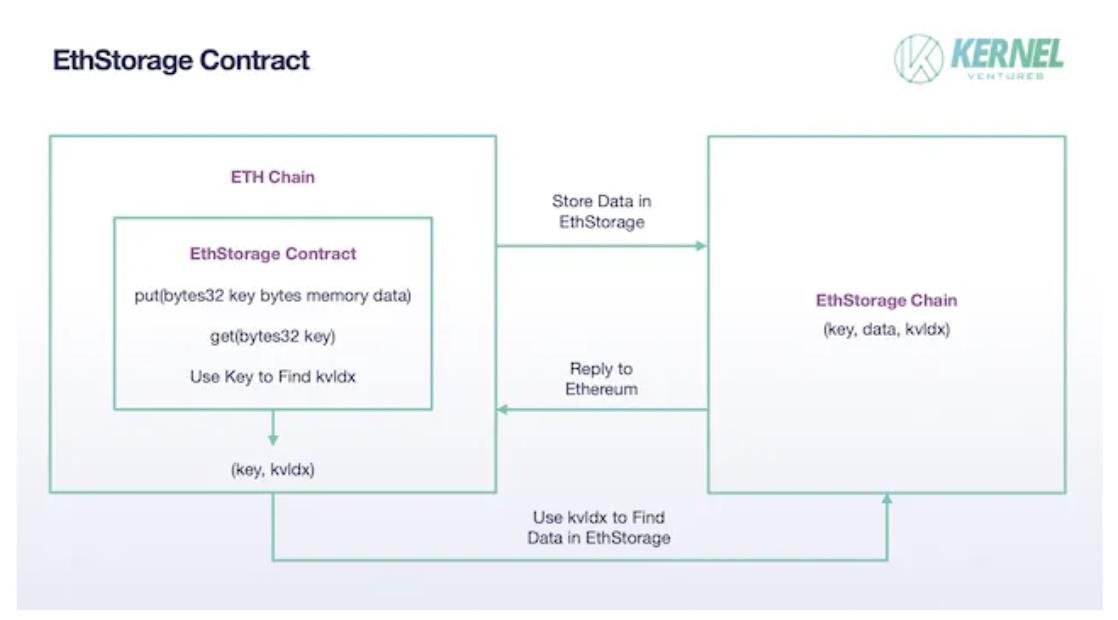
Contrat EthStorage, source : Kernel Ventures
-
Concernant la méthode de stockage physique, EthStorage s’inspire du modèle d’Arweave. Les nombreux couples (k,v) provenant d’Ethereum sont fragmentés en shards, chaque shard contenant un nombre fixe de paires, avec une limite de taille par paire, assurant ainsi une distribution équitable des récompenses aux mineurs. Pour distribuer les récompenses, il faut d’abord vérifier que les nœuds stockent bien les données. EthStorage divise chaque shard (de taille téraoctet) en nombreux chunks, et conserve sur Ethereum un Merkle Root pour la vérification. Ensuite, un mineur doit fournir un nonce qui, combiné au hachage du dernier bloc d’EthStorage, génère aléatoirement plusieurs adresses de chunks. Le mineur doit alors fournir les données de ces chunks pour prouver qu’il stocke l’intégralité du shard. Cependant, ce nonce ne peut pas être choisi librement, sinon un nœud pourrait sélectionner des chunks qu’il détient. Le nonce doit donc produire, après mélange et hachage, une difficulté conforme aux exigences du réseau. Seul le premier nœud à soumettre un nonce valide et une preuve d’accès aléatoire reçoit la récompense.
4.2.2 DA modulaire : Celestia
-
Modules blockchain : Actuellement, les tâches principales d’une blockchain Layer1 comprennent quatre volets : (1) concevoir la logique de base du réseau, sélectionner les nœuds validateurs selon un certain mécanisme, écrire les blocs et distribuer les récompenses ; (2) regrouper et traiter les transactions, puis publier les informations associées ; (3) valider les transactions entrantes et déterminer leur état final ; (4) stocker et maintenir les données historiques. Selon leurs fonctions, on peut diviser la blockchain en quatre modules distincts : couche de consensus, couche d’exécution, couche de règlement et couche de disponibilité des données (DA).
-
Conception modulaire de la blockchain : Pendant longtemps, ces quatre modules étaient intégrés dans une seule et même blockchain, dite monolithique. Cette architecture est stable et facile à maintenir, mais impose une forte pression sur la chaîne unique. En pratique, les modules s’entravent mutuellement en compétition pour les ressources limitées de calcul et de stockage. Par exemple, améliorer la vitesse de traitement augmente la pression sur la couche DA ; garantir la sécurité de l’exécution nécessite des mécanismes complexes qui ralentissent le traitement. Ainsi, les développeurs sont constamment confrontés à des compromis. Pour surmonter ce goulot d’étranglement, la solution de la blockchain modulaire a été proposée. Son idée centrale est de séparer un ou plusieurs de ces modules et de les confier à une blockchain dédiée. Cela permet à chaque chaîne de se concentrer sur une seule fonction, comme la vitesse ou la capacité de stockage, dépassant ainsi les limites imposées par l’effet de goulot d’étranglement.
-
DA modulaire : Isoler la couche DA de la blockchain principale et la confier à une blockchain spécialisée est considéré comme une solution viable face à la croissance exponentielle des données historiques sur les Layer1. Cette exploration en est encore à ses débuts, mais le projet le plus emblématique est actuellement Celestia. Concrètement, Celestia s’inspire de la méthode de stockage de Danksharding : les données sont divisées en blocs, chaque nœud en stockant une partie, avec validation d’intégrité via l’engagement polynomial KZG. De plus, Celestia utilise un code d’effacement RS bidimensionnel avancé, réécrivant les données sous forme de matrice k×k, permettant de restaurer les données complètes à partir de seulement 25 % des fragments. Cependant, le sharding ne fait que multiplier la charge de stockage totale par un facteur — la pression sur chaque nœud croît toujours linéairement avec la quantité de données. À mesure que les Layer1 améliorent leur vitesse de transaction, cette pression pourrait un jour atteindre un seuil critique. Pour résoudre ce problème, Celestia introduit le composant IPLD. Les données de la matrice k×k ne sont pas stockées directement sur Celestia, mais sur le réseau LL-IPFS, et seuls leurs CID (identifiants de contenu) sont conservés sur les nœuds Celestia. Lorsqu’un utilisateur demande une donnée historique, le nœud interroge le composant IPLD avec le CID correspondant, qui récupère les données via IPFS. Si les données existent, elles sont renvoyées ; sinon, la requête échoue.
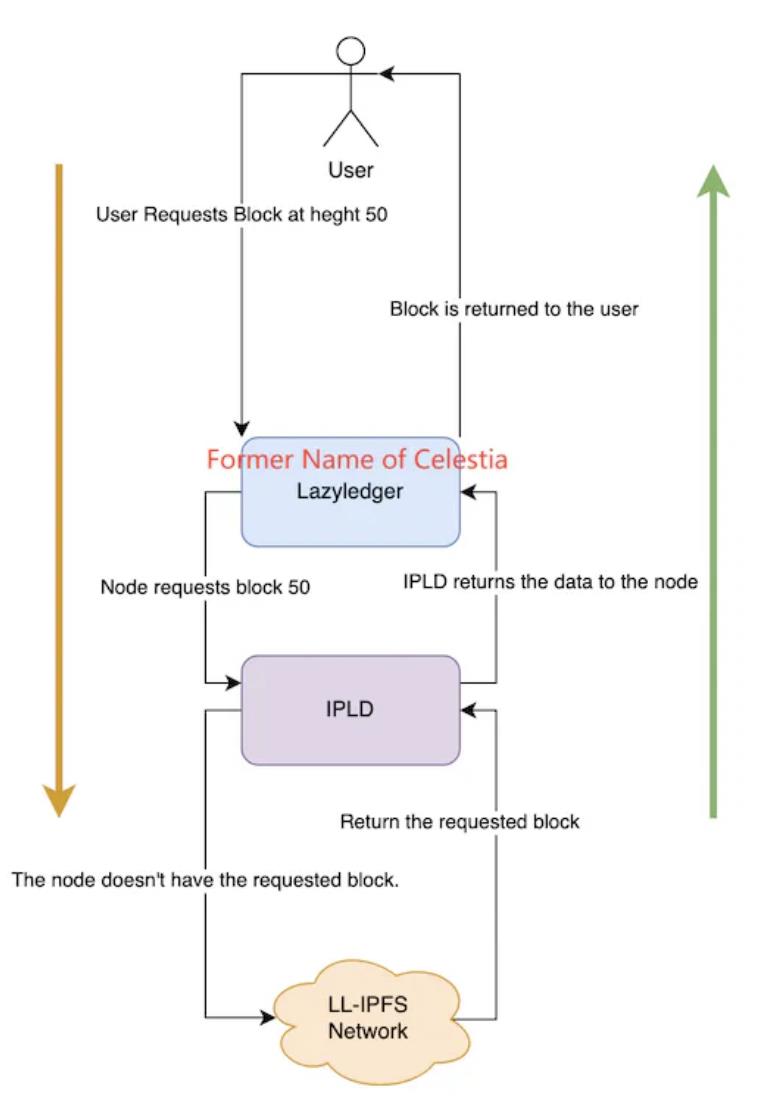
Méthode de lecture des données dans Celestia, source : Celestia Core
-
Celestia : Celestia illustre concrètement comment la blockchain modulaire peut résoudre le problème de stockage d’Ethereum. Les nœuds Rollup envoient à Celestia les données transactionnelles regroupées et validées, qui sont alors stockées. Celestia se contente de stocker ces données sans les interpréter. En retour, les nœuds Rollup paient à Celestia des frais de stockage en jetons tia, proportionnels à l’espace utilisé. Le stockage dans Celestia utilise des principes similaires à EIP4844 — DAS et code d’effacement — mais améliore le code polynomial unidimensionnel par un code RS bidimensionnel, renforçant encore la sécurité : seulement 25 % des fragments suffisent à restaurer l’ensemble. En essence, Celestia n’est qu’une blockchain PoS à faible coût de stockage. Pour résoudre pleinement le problème du stockage historique d’Ethereum, d’autres modules doivent coopérer avec elle. Par exemple, côté Rollup, Celestia recommande fortement le modèle Sovereign Rollup. Contrairement aux Rollups classiques qui se limitent à l’exécution, les Sovereign Rollups gèrent à la fois l’exécution et le règlement, minimisant ainsi le traitement sur Celestia. Cela maximise la sécurité globale, surtout quand la sécurité de Celestia est inférieure à celle d’Ethereum. Concernant la sécurité de l’accès aux données d’Ethereum, la solution dominante est actuellement le pont quantique gravitationnel (quantum gravity bridge), un contrat intelligent. Pour les données stockées sur Celestia, un Merkle Root (preuve de disponibilité) est conservé sur ce contrat Ethereum. Chaque fois qu’Ethereum accède à des données historiques sur Celestia, leur hachage est comparé à ce Merkle Root : s’ils correspondent, les données sont authentiques.
4.2.3 DA sur blockchain de stockage
Sur le plan technique, les solutions DA intégrées à la chaîne principale s’inspirent largement du sharding utilisé par les blockchains de stockage. Parmi les solutions tierces, certaines délèguent même directement une partie du stockage à ces blockchains, comme Celestia qui place les données transactionnelles sur LL-IPFS. Outre la création d’une blockchain dédiée pour résoudre le problème de stockage des Layer1, une approche plus directe consiste à connecter directement une blockchain de stockage à une Layer1 afin d’y stocker massivement les données historiques. Pour les blockchains hautes performances, le volume de données historiques est colossal : à plein régime, Solana atteint près de 4 pétaoctets, bien au-delà des capacités d’un nœud standard. Solana a donc opté pour le stockage sur Arweave, ne conservant que deux jours de données sur ses nœuds principaux pour les validations. Pour garantir la sécurité du processus, Solana et Arweave ont conçu ensemble un pont de stockage appelé Solar Bridge. Les données validées par les nœuds Solana sont synchronisées sur Arweave, qui renvoie un tag. Grâce à ce tag, tout nœud Solana peut accéder à l’historique complet de la blockchain. Sur Arweave, contrairement aux blockchains classiques, les nœuds ne doivent pas tous partager les mêmes données. Le système repose sur des incitations au stockage. Arweave n’utilise pas une structure de chaîne traditionnelle, mais plutôt un graphe. Un nouveau bloc pointe non seulement vers le précédent, mais aussi vers un bloc aléatoire antérieur appelé Recall Block. La position de ce Recall Block est déterminée par le hachage du bloc précédent et de sa hauteur, et reste inconnue jusqu’à la découverte du bloc précédent. Pour miner un nouveau bloc, un nœud doit posséder les données du Recall Block afin de calculer, via un mécanisme POW, un hachage de difficulté requise. Le premier à réussir obtient la récompense, ce qui incite les mineurs à conserver autant de données historiques que possible. Moins un bloc historique est stocké, moins il y a de concurrents lors du calcul du nonce, ce qui encourage les mineurs à stocker les blocs rares. Enfin, pour garantir le stockage permanent, Arweave introduit WildFire, un système de notation des nœuds. Les nœuds préfèrent communiquer avec ceux capables de fournir rapidement des données historiques. Les nœuds mal notés reçoivent lentement les nouveaux blocs et transactions, perdant ainsi tout avantage compétitif dans le minage.
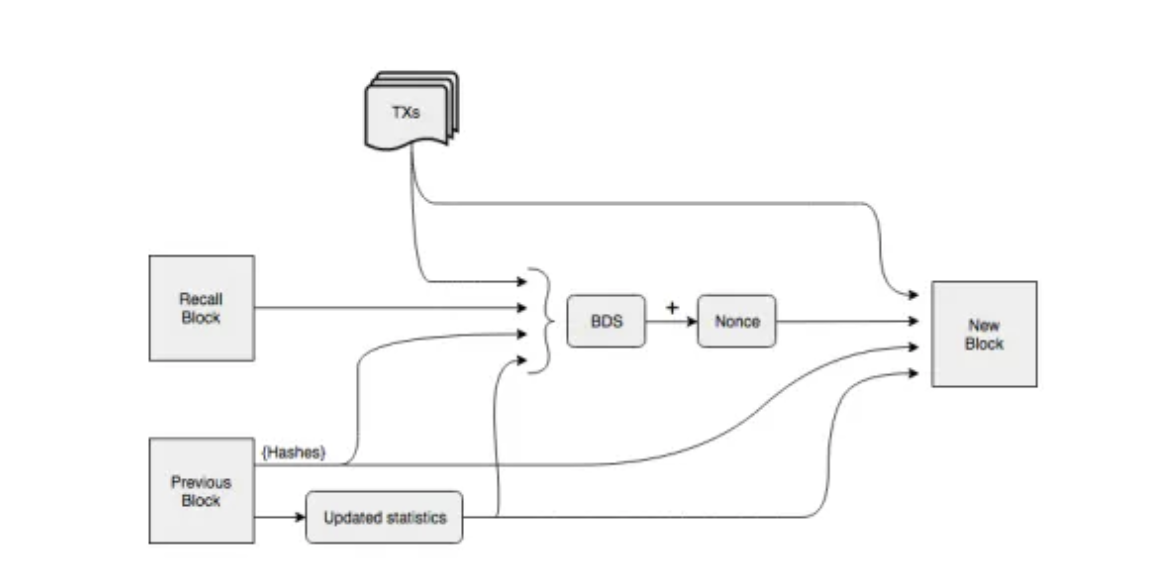
Construction des blocs dans Arweave, source : Arweave Yellow-Paper
5. Comparaison synthétique
Nous allons maintenant comparer les forces et faiblesses de cinq solutions de stockage selon les quatre dimensions définies précédemment.
-
Sécurité : Les principales menaces pour la sécurité des données proviennent de la perte pendant le transfert ou de la falsification par des nœuds malhonnêtes. Le passage inter-chaînes, en raison de l’indépendance et du manque de partage d’état entre chaînes, est particulièrement vulnérable. De plus, les Layer1 nécessitant une couche DA spécialisée disposent souvent d’une grande communauté de consensus, leur sécurité intrinsèque étant bien supérieure à celle d’une blockchain de stockage ordinaire. Ainsi, les solutions DA intégrées à la chaîne principale offrent une sécurité supérieure. Une fois la sécurité du transfert assurée, il faut garantir la sécurité des données consultées. Si l’on considère uniquement les données historiques temporaires utilisées pour valider les transactions, le stockage temporaire, où chaque donnée est copiée sur tous les nœuds du réseau, offre une redondance maximale. En revanche, dans les solutions de type DankSharding, chaque donnée n’est copiée qu’environ T/N fois, ce qui réduit la redondance. Plus la redondance est élevée, moins les données risquent d’être perdues, et plus il y a d’échantillons disponibles pour la validation. Le stockage temporaire est donc relativement plus sûr. Parmi les solutions tierces, la DA dédiée à la chaîne principale bénéficie d’une sécurité accrue grâce à l’utilisation de nœuds communs, permettant un transfert direct des données via des nœuds-relais, sans passer par des ponts complexes.
-
Coût de stockage : Le facteur ayant le plus d’impact sur le coût est la quantité de redondance. Dans le stockage temporaire sur la chaîne principale, chaque nouvelle donnée est synchronisée sur tous les nœuds, entraînant le coût de stockage le plus élevé. Ce coût élevé limite son usage aux données temporaires, surtout dans les réseaux à haut TPS. Viennent ensuite les solutions basées sur le sharding, que ce soit sur la chaîne principale ou en tierce. Comme la chaîne principale dispose généralement de plus de nœuds, chaque bloc y est copié davantage, rendant le sharding sur chaîne principale plus coûteux. La solution la moins chère est la DA basée sur une blockchain de stockage utilisant un modèle incitatif, où le nombre de copies fluctue autour d’une constante fixée. De plus, ces blockchains intègrent des mécanismes dynamiques : en augmentant les récompenses, elles incitent les nœuds à stocker les données les moins sauvegardées, assurant ainsi la sécurité globale.
-
Vitesse d’accès aux données : La vitesse d’accès dépend principalement de l’emplacement physique des données (mémoire ou SSD), du chemin d’indexation et de la distribution des données entre les nœuds. L’emplacement est crucial : le stockage en RAM peut être des dizaines de fois plus rapide que sur SSD. Les blockchains de stockage utilisent majoritairement des SSD, car elles hébergent non seulement des données DA, mais aussi des fichiers personnels volumineux (vidéos, images). Sans SSD, elles ne pourraient supporter la charge ni assurer un stockage durable. Ensuite, pour les solutions DA tierces ou intégrées utilisant la mémoire, la différence est notable : les DA tierces doivent d’abord chercher l’index sur la chaîne principale, puis transférer cet index inter-chaînes, passer par un pont de stockage et enfin récupérer les données. En revanche, la DA intégrée peut accéder directement aux données via les nœuds locaux, offrant une vitesse de récupération supérieure. Enfin, parmi les solutions intégrées, le sharding nécessite de récupérer plusieurs blocs sur différents nœuds et de les recomposer, ce qui est plus lent que le stockage non fragmenté.
-
Généralité de la couche DA : La DA intégrée à la chaîne principale a une généralité quasi nulle, car il est impossible de transférer les données d’une blockchain à faible capacité vers une autre également limitée. Parmi les solutions tierces, la généralité est inversement proportionnelle à la compatibilité avec une chaîne spécifique. Par exemple, une DA dédiée à une chaîne principale, fortement optimisée au niveau des nœuds et du consensus, rencontre de graves obstacles lorsqu’elle tente de communiquer avec d’autres chaînes. À l’intérieur des solutions tierces, la DA modulaire est moins universelle que la DA basée sur une blockchain de stockage. Cette dernière bénéficie d’une communauté de développeurs plus large et d’infrastructures plus riches, pouvant s’adapter à diverses blockchains. De plus, elle récupère les données activement (par exemple via des scrapers), plutôt que de les recevoir passivement. Elle peut donc encoder les données selon ses propres standards, normalisant ainsi le flux de données, facilitant la gestion multichaîne et améliorant l’efficacité de stockage.
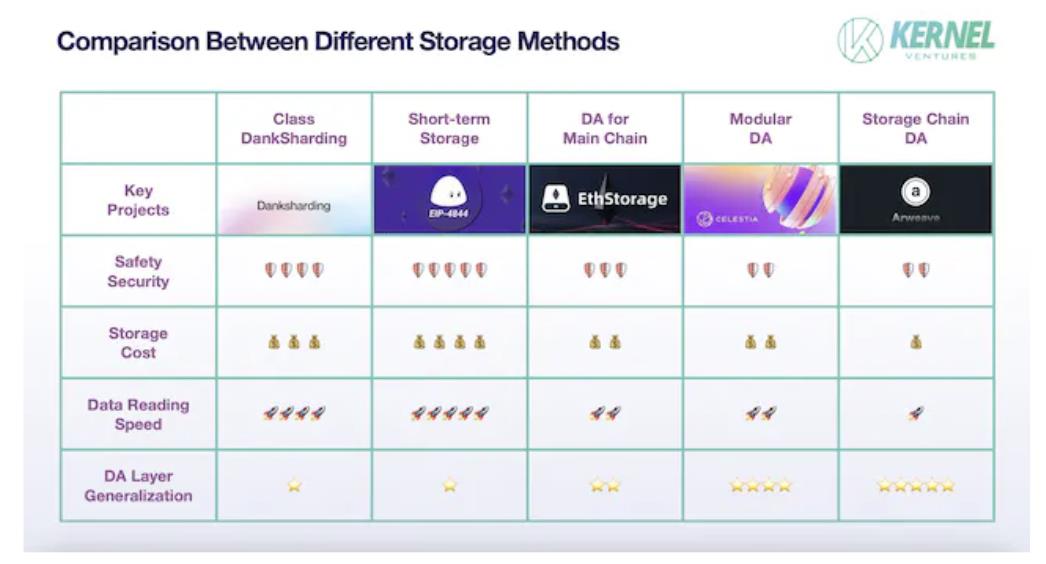
Comparaison des performances des solutions de stockage, source : Kernel Ventures
6. Conclusion
Actuellement, la blockchain traverse une transformation de Crypto vers un Web3 plus inclusif, apportant non seulement une diversité accrue de projets. Pour accueillir simultanément un grand nombre de projets sur Layer1 tout en assurant une expérience fluide aux applications GameFi et SocialFi, des blockchains comme Ethereum ont adopté des solutions comme les Rollups et les Blobs pour augmenter le TPS. Parallèlement, le nombre de blockchains hautes performances ne cesse de croître. Mais un TPS plus élevé signifie aussi une pression accrue sur le stockage. Face à ce volume mass
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News












