

Aperçu des secteurs prometteurs : le marché décentralisé de la puissance de calcul (1/2)
TechFlow SélectionTechFlow Sélection
Aperçu des secteurs prometteurs : le marché décentralisé de la puissance de calcul (1/2)
La pénurie de puissance de calcul deviendra inévitable ; le marché décentralisé de la puissance de calcul sera-t-il une bonne affaire ?
Auteur : Zeke, YBB Capital

Introduction
Depuis l'apparition de GPT-3, l'IA générative a connu un point d'inflexion explosif grâce à ses performances impressionnantes et à ses vastes cas d'utilisation, incitant les géants technologiques à s'engouffrer massivement dans le domaine de l'IA. Toutefois, un problème majeur émerge : l'entraînement et l'inférence des grands modèles linguistiques (LLM) nécessitent une puissance de calcul colossale. À mesure que les modèles évoluent, la demande en capacité de calcul et les coûts augmentent de manière exponentielle. Prenons GPT-2 et GPT-3 comme exemples : leur différence en nombre de paramètres est de 1166 fois (GPT-2 compte 150 millions de paramètres contre 175 milliards pour GPT-3). Le coût d’un seul entraînement de GPT-3 atteint jusqu’à 12 millions de dollars selon les tarifs publics des GPU cloud à l’époque, soit 200 fois plus que GPT-2. En pratique, chaque requête utilisateur exige une opération d’inférence. Sur la base des 13 millions d’utilisateurs uniques ayant visité le service au début de cette année, la demande correspondante en puces équivaut à plus de 30 000 GPU A100. L’investissement initial atteindrait ainsi un montant stupéfiant de 800 millions de dollars, avec des frais d’inférence journaliers estimés à 700 000 dollars.
La pénurie de puissance de calcul et les coûts élevés sont devenus des obstacles critiques pour tout le secteur de l’IA. Pourtant, ce même défi menace également l’industrie blockchain. D’une part, la quatrième halving du Bitcoin et l’approbation imminente de son ETF devraient entraîner une hausse future des prix, augmentant fortement la demande des mineurs en matériel informatique. D’autre part, la preuve à divulgation nulle de connaissance (« Zero-Knowledge Proof », ou ZKP) connaît un essor fulgurant. Vitalik lui-même a souligné à plusieurs reprises que l’impact du ZK sur l’écosystème blockchain sera aussi important que celui de la blockchain elle-même au cours des dix prochaines années. Bien que cette technologie suscite de grands espoirs, elle implique des calculs complexes qui, comme l’IA, consomment d’importantes ressources en puissance de calcul et en temps lors de la génération de preuves.
Dans un avenir prévisible, la pénurie de puissance de calcul semble inévitable. Alors, le marché décentralisé de la puissance de calcul pourrait-il représenter une opportunité commerciale prometteuse ?
Définition du marché décentralisé de la puissance de calcul
Le marché décentralisé de la puissance de calcul est fondamentalement équivalent au segment du cloud computing décentralisé. Cependant, personnellement, je trouve ce terme plus approprié pour décrire les nouveaux projets dont nous allons parler. Ce type de marché relève du DePIN (réseau d’infrastructures physiques décentralisées), dont l’objectif est de créer un marché ouvert où toute personne disposant de ressources informatiques inutilisées peut les proposer via des incitations tokenisées, principalement au service des entreprises (B2B) et des développeurs. Parmi les projets bien connus, on peut citer Render Network, un réseau offrant des solutions de rendu basées sur des GPU décentralisés, ou encore Akash Network, un marché distribué peer-to-peer pour le cloud computing.
Nous commencerons ici par des notions de base, puis examinerons trois marchés émergents dans ce secteur : le marché de la puissance de calcul pour l’AGI, celui du Bitcoin et celui de l’accélération matérielle ZK — ce dernier faisant l’objet d’une analyse approfondie dans un second article intitulé « Perspectives prometteuses : le marché décentralisé de la puissance de calcul (2/2) ».
Aperçu de la puissance de calcul
Le concept de puissance de calcul remonte aux origines mêmes de l’informatique. Les premiers ordinateurs effectuaient des tâches de calcul à l’aide de dispositifs mécaniques, et la puissance de calcul désignait alors leur capacité de traitement. Avec l’évolution des technologies informatiques, ce concept s’est enrichi : aujourd’hui, il fait référence à la capacité conjointe du matériel informatique (CPU, GPU, FPGA, etc.) et des logiciels (systèmes d’exploitation, compilateurs, applications, etc.) à fonctionner ensemble efficacement.
Définition
La puissance de calcul (Computing Power) désigne la quantité de données pouvant être traitées ou de tâches de calcul accomplies par un ordinateur ou un autre appareil informatique dans un laps de temps donné. Elle sert généralement à décrire les performances d’un système informatique et constitue un indicateur clé de sa capacité de traitement.
Critères de mesure
La puissance de calcul peut être mesurée selon divers critères : vitesse de calcul, consommation énergétique, précision, parallélisme. Dans le domaine informatique, les indicateurs couramment utilisés incluent les FLOPS (opérations en virgule flottante par seconde), les IPS (instructions par seconde) et les TPS (transactions par seconde).
Les FLOPS (Floating Point Operations Per Second) mesurent la capacité d’un ordinateur à effectuer des opérations arithmétiques sur des nombres à virgule flottante (qui posent des questions de précision et d’arrondi). Ils reflètent le nombre d’opérations en virgule flottante qu’un système peut réaliser chaque seconde. Les FLOPS sont un indicateur clé de la puissance de calcul haute performance, souvent utilisé pour évaluer les supercalculateurs, serveurs haut de gamme et processeurs graphiques (GPU). Par exemple, un système affichant 1 TFLOPS (1000 milliards de FLOPS) peut effectuer mille milliards d’opérations en virgule flottante par seconde.
Les IPS (Instructions Per Second) mesurent la vitesse à laquelle un ordinateur exécute des instructions. Ils indiquent combien d’instructions peuvent être traitées chaque seconde. Les IPS servent à évaluer la performance unitaire d’un processeur, notamment des CPU. Par exemple, un CPU cadencé à 3 GHz peut exécuter 3 milliards d’instructions par seconde.
Les TPS (Transactions Per Second) mesurent la capacité d’un système à gérer des transactions, c’est-à-dire combien d’opérations peuvent être complétées chaque seconde. Ce critère est fréquemment utilisé pour évaluer les serveurs de bases de données. Un serveur DB affichant 1000 TPS peut traiter 1000 transactions par seconde.
Il existe également des indicateurs spécifiques à certains cas d’usage, tels que la vitesse d’inférence, la vitesse de traitement d’image ou le taux de reconnaissance vocale.
Types de puissance de calcul
La puissance de calcul GPU désigne la capacité de traitement d’un processeur graphique (Graphics Processing Unit). Contrairement au CPU (Central Processing Unit), le GPU est conçu spécifiquement pour traiter des données graphiques telles que les images et vidéos. Il dispose d’un grand nombre d’unités de traitement et d’une forte capacité de calcul parallèle, permettant d’exécuter simultanément de nombreuses opérations en virgule flottante. Initialement développé pour le traitement graphique dans les jeux vidéo, le GPU bénéficie généralement d’une fréquence d’horloge plus élevée et d’une bande passante mémoire supérieure comparé au CPU, afin de supporter des calculs graphiques complexes.
Différences entre CPU et GPU
-
Architecture : CPU et GPU ont des architectures différentes. Le CPU repose généralement sur un ou plusieurs cœurs, chacun étant un processeur universel capable d’exécuter divers types d’opérations. Le GPU, en revanche, possède des milliers de processeurs de flux (Stream Processors) et de shaders spécialisés dans les calculs liés au traitement d’images.
-
Calcul parallèle : Le GPU offre une capacité de calcul parallèle nettement supérieure. Le nombre limité de cœurs du CPU ne permet d’exécuter qu’une seule instruction à la fois par cœur, tandis que le GPU, doté de milliers de processeurs de flux, peut exécuter simultanément de nombreuses instructions. Il est donc particulièrement adapté aux tâches nécessitant un fort parallélisme, comme l’apprentissage automatique ou le deep learning.
-
Programmation : La programmation du GPU est plus complexe que celle du CPU. Elle requiert des langages spécifiques (comme CUDA ou OpenCL) et des techniques particulières pour exploiter pleinement son potentiel parallèle. À l’inverse, la programmation CPU est plus simple, utilisant des langages et outils généraux.
Importance de la puissance de calcul
À l’ère de la révolution industrielle, le pétrole était le sang du monde, imprégnant tous les secteurs. À l’avenir, dans l’ère de l’IA, la puissance de calcul deviendra le « pétrole numérique » du monde entier. L’acharnement des grandes entreprises à s’approprier des puces IA, la valorisation record de Nvidia franchissant le seuil du millier de milliards de dollars, ainsi que les restrictions récentes des États-Unis sur les puces haut de gamme chinoises — jusque dans le détail de la puissance de calcul, de la taille des puces, voire envisageant d’interdire l’accès au cloud GPU — illustrent clairement son importance stratégique. La puissance de calcul deviendra une matière première majeure de la prochaine ère.

Aperçu de l’intelligence artificielle générale (AGI)
L’intelligence artificielle (AI) est une science technologique nouvelle visant à étudier, développer des théories, méthodes, techniques et systèmes applicatifs capables de simuler, prolonger et étendre l’intelligence humaine. Née dans les années 1950-1960, après plus d’un demi-siècle d’évolution marqué par les vagues successives du symbolisme, du connexionnisme et des agents intelligents, l’IA est désormais une technologie généraliste émergente qui transforme profondément la société et tous les secteurs économiques. L’IA générative actuelle relève plus précisément de l’intelligence artificielle générale (Artificial General Intelligence, AGI) : un système d’IA doté d’une compréhension large, capable de manifester une intelligence comparable, voire supérieure, à celle de l’humain sur de multiples tâches et domaines. Une AGI repose fondamentalement sur trois éléments : l’apprentissage profond (deep learning, DL), les mégadonnées et une puissance de calcul à grande échelle.
Apprentissage profond
L’apprentissage profond est un sous-domaine de l’apprentissage machine (ML). Ses algorithmes s’inspirent du modèle du cerveau humain via des réseaux neuronaux. Comme le cerveau humain contient des millions de neurones interconnectés qui collaborent pour apprendre et traiter l’information, un réseau neuronal profond (ou réseau neuronal artificiel) est composé de plusieurs couches de neurones artificiels travaillant ensemble dans un environnement informatique. Ces neurones artificiels, appelés nœuds, sont des modules logiciels utilisant des calculs mathématiques pour traiter les données. Le réseau neuronal artificiel constitue l’algorithme de deep learning utilisé pour résoudre des problèmes complexes.
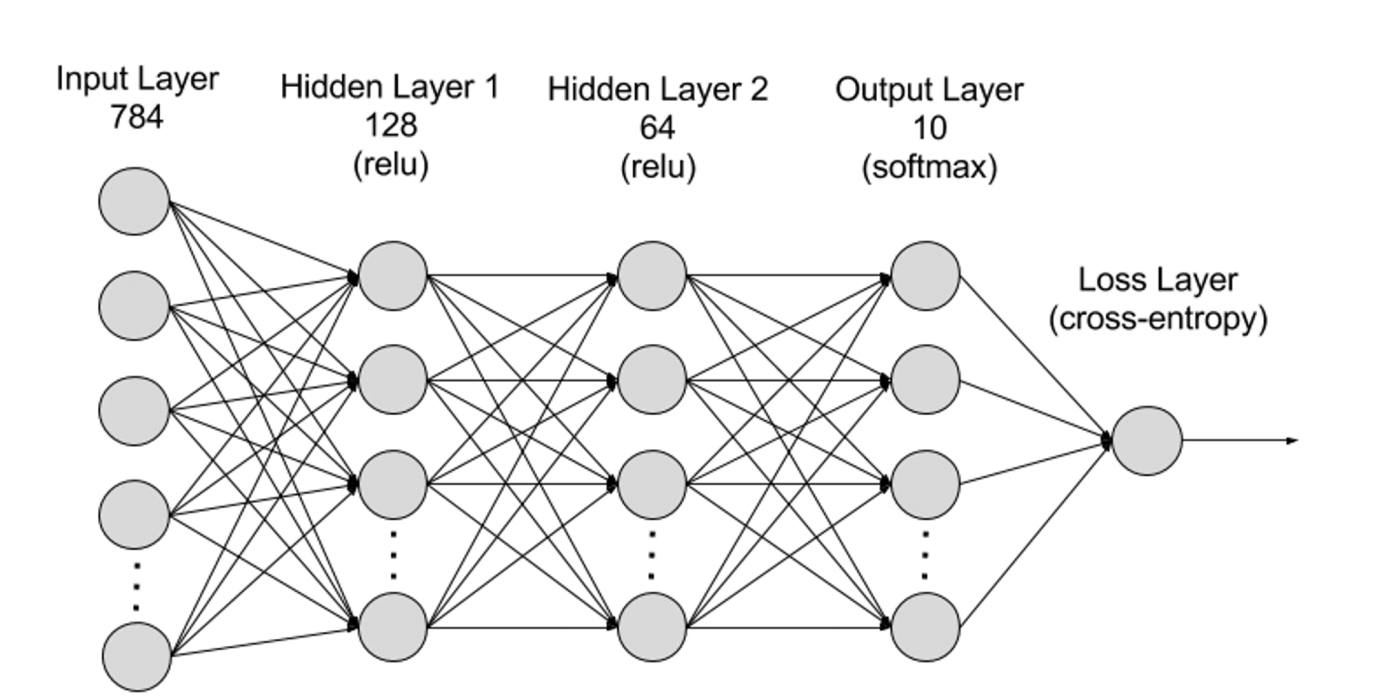
Du point de vue structurel, un réseau neuronal comporte une couche d’entrée, des couches cachées et une couche de sortie. Les connexions entre ces couches sont définies par des paramètres.
-
Couche d’entrée (Input Layer) : Première couche du réseau neuronal, elle reçoit les données externes. Chaque neurone correspond à une caractéristique des données d’entrée. Par exemple, dans le traitement d’image, chaque neurone peut représenter la valeur d’un pixel.
-
Couches cachées (Hidden Layers) : Après traitement par la couche d’entrée, les données sont transmises vers des couches plus profondes. Ces couches analysent l’information à différents niveaux et ajustent leur comportement face aux nouvelles données. Un réseau de deep learning peut compter des centaines de couches cachées, permettant d’analyser un problème sous divers angles. Par exemple, si vous devez classer une image d’un animal inconnu, vous pouvez la comparer à des animaux déjà connus, en examinant la forme des oreilles, le nombre de pattes ou la taille des pupilles. Les couches cachées d’un réseau neuronal profond fonctionnent de manière similaire : chaque couche traite une caractéristique spécifique de l’animal pour tenter une classification précise.
-
Couche de sortie (Output Layer) : Dernière couche du réseau, elle produit le résultat final. Chaque neurone représente une catégorie ou une valeur de sortie possible. Par exemple, dans un problème de classification, chaque neurone peut correspondre à une classe ; dans un problème de régression, un seul neurone peut suffire, dont la valeur représente la prédiction.
-
Paramètres : Dans un réseau neuronal, les connexions entre couches sont définies par des poids (Weights) et des biais (Biases), optimisés durant l’entraînement pour permettre au réseau de reconnaître des motifs dans les données et d’effectuer des prédictions. L’augmentation du nombre de paramètres augmente la capacité du modèle, c’est-à-dire sa capacité à apprendre et représenter des motifs complexes. Mais cela accroît aussi fortement la demande en puissance de calcul.
Big Data
Pour un entraînement efficace, les réseaux neuronaux nécessitent généralement de grandes quantités de données variées, de haute qualité et provenant de sources multiples. Elles constituent la base de l’entraînement et de la validation des modèles d’apprentissage automatique. En analysant ces mégadonnées, les modèles peuvent découvrir des motifs et relations, leur permettant de faire des prédictions ou classifications.
Puissance de calcul à grande échelle
La structure multicouche des réseaux neuronaux, le grand nombre de paramètres, les besoins en traitement de données massives, la méthode itérative d’entraînement (où le modèle doit répéter les phases de propagation avant et arrière, y compris les calculs de fonctions d’activation, de perte, de gradients et de mise à jour des poids), les exigences de précision, la capacité de calcul parallèle, les techniques d’optimisation et de régularisation, ainsi que les processus d’évaluation et de validation du modèle, expliquent collectivement la forte demande en puissance de calcul. Avec les progrès du deep learning, la demande en puissance de calcul pour l’AGI augmente d’environ un facteur 10 chaque année. À ce jour, le dernier modèle GPT-4 compte 1,8 trillion de paramètres, avec un coût d’entraînement unique dépassant 60 millions de dollars et une demande en puissance de calcul de 2,15e25 FLOPS (21 500 billions d’opérations en virgule flottante). Et les futurs modèles continuent d’agrandir cette demande.
Économie de la puissance de calcul pour l’IA
Taille future du marché
Selon les estimations les plus fiables, menées par IDC (International Data Corporation), en collaboration avec Inspur Information et l’Institut mondial de recherche industrielle de l’Université Tsinghua dans leur rapport « Évaluation de l’indice mondial de puissance de calcul 2022-2023 », le marché mondial du calcul IA devrait passer de 19,5 milliards de dollars en 2022 à 34,66 milliards en 2026. Quant au marché du calcul pour l’IA générative, il devrait croître de 820 millions de dollars en 2022 à 10,99 milliards en 2026. Sa part dans le marché global du calcul IA passera ainsi de 4,2 % à 31,7 %.
Monopole économique de la puissance de calcul
La production de GPU pour l’IA est aujourd’hui monopolisée par NVIDIA, à des prix extrêmement élevés (la dernière puce H100 atteint 40 000 dollars pièce). Dès leur sortie, ces GPU sont immédiatement rachetés par les géants de la Silicon Valley, certaines machines servant à l’entraînement de leurs propres modèles internes. D’autres sont louées via des plateformes cloud comme celles de Google, Amazon et Microsoft, qui contrôlent d’immenses ressources de serveurs, GPU et TPU. La puissance de calcul est devenue une ressource monopolisée par quelques géants. De nombreux développeurs liés à l’IA ne peuvent même pas acheter un GPU spécialisé sans surcoût. Pour utiliser les dernières technologies, ils doivent louer des serveurs AWS ou Microsoft. Cette activité génère des marges bénéficiaires exceptionnelles : AWS affiche un taux de marge brute de 61 %, Microsoft atteint même 72 %.

Devons-nous accepter ce contrôle centralisé et payer un profit de 72 % pour accéder à la puissance de calcul ? Les géants du Web2, qui dominent aujourd’hui, domineront-ils aussi la prochaine ère ?
Défis du marché décentralisé de la puissance de calcul pour l’AGI
Face à ce monopole, la décentralisation est souvent perçue comme la meilleure solution. Peut-on, à partir des projets existants, combiner des solutions de stockage DePIN avec des protocoles comme RDNR utilisant les GPU inutilisés pour fournir la puissance de calcul nécessaire à l’AGI ? La réponse est non. Le chemin vers cette alternative n’est pas aussi simple. Les projets actuels n’ont pas été conçus spécifiquement pour l’AGI et ne sont donc pas viables. Intégrer la puissance de calcul à la blockchain pose au moins cinq défis majeurs :
1. Vérification des tâches : Pour construire un réseau de calcul véritablement fiable, et offrir des incitations économiques aux participants, le réseau doit pouvoir vérifier que les calculs d’apprentissage profond ont bien été exécutés. Le cœur du problème réside dans la dépendance d’état des modèles d’apprentissage profond : chaque couche dépend de la sortie de la couche précédente. On ne peut donc pas vérifier une couche isolément sans tenir compte de toutes les précédentes. La vérification d’un point spécifique (par exemple, une couche donnée) exige d’exécuter tous les calculs depuis le début du modèle jusqu’à ce point.
2. Marché : Le marché de la puissance de calcul pour l’IA, encore émergent, souffre d’un dilemme offre-demande, notamment du problème de démarrage à froid. L’offre et la demande doivent être à peu près équilibrées dès le départ pour permettre la croissance du marché. Pour attirer des fournisseurs de puissance de calcul, il faut leur offrir des récompenses claires. Le marché a besoin d’un mécanisme pour suivre les tâches exécutées et payer rapidement les fournisseurs. Dans les marchés traditionnels, les intermédiaires gèrent ces tâches, fixant des seuils de paiement minimum pour réduire les coûts. Mais cette approche devient coûteuse à grande échelle. Seule une petite partie de l’offre peut être capturée économiquement, créant un équilibre de seuil : le marché ne peut capter et maintenir qu’une offre limitée, incapable de croître davantage.
3. Problème de l’arrêt : Ce problème fondamental en théorie du calcul consiste à déterminer si une tâche donnée terminera en un temps fini ou s’exécutera indéfiniment. Ce problème est indécidable : aucun algorithme universel ne peut prédire si une tâche quelconque s’arrêtera. C’est similaire au cas des contrats intelligents sur Ethereum, dont on ne peut pas toujours prédire à l’avance la consommation de ressources ou la durée d’exécution.
(Dans le contexte du deep learning, le problème s’aggrave car les modèles et frameworks passent de graphes statiques à des constructions dynamiques et exécutées en temps réel.)
4. Vie privée : La protection de la vie privée doit être intégrée dès la conception. Bien que de nombreuses recherches en apprentissage machine puissent utiliser des jeux de données publics, les modèles doivent souvent être affinés sur des données propriétaires pour améliorer leurs performances. Ce processus peut impliquer des données personnelles, nécessitant des garanties strictes en matière de confidentialité.
5. Parallélisation : C’est l’obstacle principal à la viabilité actuelle des projets. Les modèles de deep learning sont habituellement entraînés en parallèle sur de grands clusters matériels spécialisés, à très faible latence. Dans un réseau distribué, les GPU doivent échanger fréquemment des données, ce qui introduit de la latence et limite les performances au niveau du GPU le plus lent. Comment assurer une parallélisation hétérogène dans un environnement où les sources de calcul sont non fiables ? Une solution envisageable repose sur les modèles Transformers, comme les Switch Transformers, qui présentent déjà un haut degré de parallélisation.
Solutions : Bien que les tentatives actuelles sur le marché décentralisé de la puissance de calcul AGI en soient encore à leurs balbutiements, deux projets commencent à apporter des réponses concrètes aux défis de conception du consensus dans les réseaux décentralisés, ainsi qu’à la mise en œuvre pratique de l’entraînement et de l’inférence. Nous analysons ci-dessous Gensyn et Together pour comprendre leurs approches et leurs limites.
Gensyn

Gensyn est un projet en cours de développement, visant à créer un marché de puissance de calcul pour l’AGI. Il cherche à relever les défis du calcul décentralisé en deep learning et à réduire les coûts actuels. Fondamentalement, Gensyn est un protocole de première couche basé sur Polkadot, utilisant la preuve d’enjeu. Il récompense directement via des contrats intelligents les « solveurs » (Solver) qui mettent à disposition leurs GPU inutilisés pour exécuter des tâches d’apprentissage machine.
Revenons au problème central : comment construire un réseau de calcul véritablement fiable, capable de vérifier que les tâches d’apprentissage machine ont été correctement exécutées ? C’est une question extrêmement complexe, située à l’intersection de la théorie de la complexité, de la théorie des jeux, de la cryptographie et de l’optimisation.
Gensyn propose une solution simple : les solveurs soumettent les résultats de leurs tâches. Pour vérifier ces résultats, un vérificateur indépendant refait le même travail. Cette méthode, dite « copie unique », implique une seule vérification supplémentaire. Mais si le vérificateur n’est pas le demandeur initial, un problème de confiance subsiste : le vérificateur peut être malhonnête, et son travail doit lui-même être vérifié. Cela crée un risque de chaîne infinie de vérifications. Pour briser ce cercle, Gensyn introduit trois concepts clés et un système à quatre rôles.
Preuve probabiliste d’apprentissage : Utilisation de métadonnées issues du processus d’optimisation basé sur les gradients pour construire un certificat de travail accompli. En reproduisant certaines étapes, la vérification de ces certificats devient rapide, garantissant que le travail a été effectué comme prévu.
Protocole de localisation précise basé sur les graphes : Recours à un protocole multi-niveaux et basé sur les graphes, combiné à une exécution cohérente entre vérificateurs. Cela permet de rejouer et comparer les travaux de vérification, confirmés finalement par la blockchain elle-même.
Jeu d’incitation à la Truebit : Utilisation de dépôts mis en jeu et de pénalités (slashing) pour concevoir un jeu incitatif où tout participant rationnel agit honnêtement et accomplit sa tâche.
Le système comprend quatre rôles : soumissionnaire, solveur, vérificateur et lanceur d’alerte.
Soumissionnaire (Submitter) :
Utilisateur final du système, il fournit la tâche à calculer et paie les unités de travail achevées.
Solveur (Solver) :
Principal acteur du système, il exécute l’entraînement du modèle et génère des preuves vérifiées par les vérificateurs.
Vérificateur (Verifier) :
Relie le processus d’entraînement non déterministe aux calculs linéaires déterministes, reproduit une partie de la preuve du solveur et compare la distance obtenue au seuil attendu.
Lanceur d’alerte (Whistleblower) :
Dernière ligne de défense, il examine le travail des vérificateurs et lance un défi s’il détecte une erreur, espérant obtenir une récompense substantielle.
Fonctionnement du système
Le protocole conçoit un système de jeu en huit étapes, impliquant les quatre rôles principaux, couvrant l’ensemble du processus, de la soumission de la tâche à la vérification finale.
-
Soumission de la tâche (Task Submission) : Une tâche est composée de trois éléments :
- Métadonnées décrivant la tâche et les hyperparamètres ;
- Un fichier binaire de modèle (ou architecture de base) ;
- Des données d’entraînement prétraitées accessibles publiquement.
-
Pour soumettre une tâche, le soumissionnaire fournit les détails au format lisible par machine, accompagnés du binaire du modèle (ou de l’architecture) et de l’emplacement public des données prétraitées. Ces données peuvent être stockées sur des solutions simples comme AWS S3, ou sur des systèmes décentralisés comme IPFS, Arweave ou Subspace.
-
Analyse (Profiling) : Cette étape établit un seuil de distance de base pour valider les preuves d’apprentissage. Les vérificateurs récupèrent périodiquement les tâches d’analyse et génèrent des seuils variables pour comparer les preuves. Pour créer ces seuils, ils exécutent de façon déterministe une partie de l’entraînement avec différentes graines aléatoires, produisant et vérifiant leurs propres preuves. Ils établissent ainsi un seuil global attendu pour la distance des travaux non déterministes.
-
Entraînement (Training) : Après l’analyse, la tâche entre dans un pool public (similaire au Mempool d’Ethereum). Un solveur est sélectionné, la tâche est retirée du pool. Le solveur exécute la tâche selon les métadonnées, le modèle et les données fournies. Pendant l’entraînement, il génère périodiquement des points de contrôle et stocke les métadonnées (y compris les paramètres) pour former une « preuve d’apprentissage », permettant aux vérificateurs de reproduire fidèlement les étapes d’optimisation.
-
Génération de preuve (Proof generation) : Le solveur stocke périodiquement les poids du modèle ou les mises à jour, ainsi que l’index correspondant dans le jeu de données, identifiant les échantillons utilisés. La fréquence des points de contrôle peut être ajustée pour renforcer la garantie ou économiser le stockage. Les preuves peuvent être « empilées » : elles peuvent partir d’une distribution aléatoire ou de poids pré-entraînés eux-mêmes prouvés. Ainsi, le protocole peut constituer une bibliothèque de modèles de base prouvés, affinables pour des tâches spécifiques.
-
Vérification de la preuve (Verification of proof) : Une fois la tâche terminée, le solveur enregistre sa complétion sur la chaîne et expose publiquement sa preuve d’apprentissage. Les vérificateurs extraient cette tâche, refont une partie du calcul et effectuent une comparaison de distance. La chaîne (avec le seuil calculé lors de l’analyse) utilise cette distance pour décider si la vérification correspond à la preuve.
-
Défi de localisation précise basé sur les graphes (Graph-based pinpoint challenge) : Après vérification, un lanceur d’alerte peut recopier le travail du vérificateur pour vérifier son exactitude. S’il pense que la vérification est erronée (malveillante ou non), il peut lancer un défi via le contrat d’arbitrage pour obtenir une récompense. Cette récompense provient soit des dépôts du solveur et du vérificateur (cas positif), soit d’un fonds de loterie (cas de faux positif), l’arbitrage étant géré par la chaîne.
-
Arbitrage contractuel (Contract arbitration) : Quand un vérificateur est contesté, il entre dans un processus avec la chaîne pour identifier l’opération ou l’entrée litigieuse, la chaîne exécutant finalement l’opération de base pour trancher. Pour maintenir l’honnêteté des lanceurs d’alerte et résoudre le dilemme du vérificateur, des erreurs forcées périodiques et des récompenses exceptionnelles sont introduites.
-
Règlement (Settlement) : Lors du règlement, les participants sont payés selon les conclusions des vérifications probabilistes et déterministes. Selon les résultats, différents scénarios conduisent à différents paiements. Si le travail est validé et toutes les vérifications réussies, le solveur et le vérificateur sont récompensés.
Évaluation du projet
Gensyn propose un système de jeu élégant au niveau de la vérification et des incitations, capable de localiser rapidement les divergences. Toutefois, le système actuel manque encore de nombreux détails. Par exemple, comment régler les paramètres pour que les récompenses/pénalités soient justes sans être trop restrictifs ? Les cas extrêmes ou les différences de puissance entre solveurs sont-ils pris en compte ? Le livre blanc actuel ne détaille pas non plus la parallélisation hétérogène. En l’état, le chemin vers une mise en œuvre effective de Gensyn reste long.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News
Ajouter aux favorisPartager sur les réseaux sociaux
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














