

Preuve de stockage approfondie : réaliser une perception de l'état blockchain transversale dans le temps et entre chaînes
TechFlow SélectionTechFlow Sélection
Preuve de stockage approfondie : réaliser une perception de l'état blockchain transversale dans le temps et entre chaînes
Les preuves de stockage pourraient permettre à Ethereum d'émerger comme une couche d'identité et de propriété des actifs, et pas seulement comme une couche de règlement.
Rédaction : LongHash Ventures
Traduction : TechFlow
Et si vous perdiez la mémoire chaque heure, et deviez constamment demander à autrui ce que vous avez fait ? C’est exactement la situation actuelle des contrats intelligents. Sur une blockchain comme Ethereum, les contrats intelligents ne peuvent pas accéder directement à un état antérieur à plus de 256 blocs. Ce problème est encore plus aigu dans les écosystèmes multi-chaînes, où la récupération et la vérification des données entre différentes couches d’exécution sont encore plus difficiles.
En 2020, Vitalik Buterin et Tomasz Stanczak ont proposé une méthode permettant d’accéder aux données à travers le temps. Bien que cette proposition EIP soit restée en suspens, sa nécessité réapparaît dans un monde multi-chaîne centré sur les rollups. Aujourd’hui, les preuves de stockage (storage proofs) sont au cœur de l’innovation, visant à doter les contrats intelligents de conscience et de mémoire.
Méthodes d'accès aux données sur chaîne
Les DApps peuvent accéder aux données et à l’état via plusieurs méthodes. Chacune de ces approches implique un certain niveau de confiance accordée à des humains/entités, à la sécurité cryptographico-économique ou au code lui-même, avec des compromis inévitables :
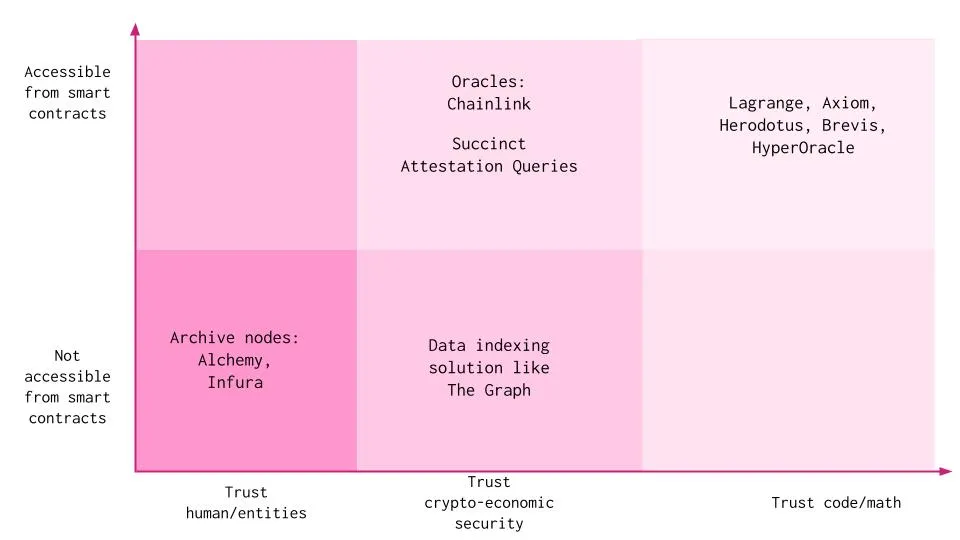
Faire confiance à des humains / entités :
Nœuds d’archive : Un opérateur peut exécuter son propre nœud d’archive, ou s’appuyer sur des fournisseurs de services tels qu’Alchemy ou Infura pour accéder à toutes les données depuis le bloc de genèse. Ces services offrent les mêmes données qu’un nœud complet, incluant également tous les états historiques de la blockchain. Des services hors chaîne comme Etherscan ou Dune Analytics utilisent des nœuds d’archive pour consulter les données. Des participants hors chaîne peuvent attester de la validité de ces données, et les contrats intelligents peuvent vérifier que les données ont été signées par des parties ou comités de confiance. Toutefois, l’intégrité des données sous-jacentes ne peut être vérifiée. Cette méthode oblige les DApps à faire confiance aux fournisseurs de nœuds d’archive quant au bon fonctionnement de leur infrastructure, sans intention malveillante.
Faire confiance à la sécurité cryptographico-économique :
-
Indexeurs : Les protocoles d’indexation organisent toutes les données de la blockchain, permettant aux développeurs de créer et publier des API ouvertes pour que les applications puissent interroger les données. Un indexeur individuel est un nœud qui mise des jetons pour fournir des services d'indexation et de traitement de requêtes. Toutefois, si les données fournies sont incorrectes, un litige peut survenir, dont le processus d’arbitrage prend du temps. De plus, les données provenant d’indexeurs comme The Graph ne peuvent pas être directement intégrées à la logique métier d’un contrat intelligent, mais sont plutôt utilisées dans des contextes analytiques web2.
-
Oracles : Les services d’oracles agrègent des données provenant de nombreux nœuds indépendants. Le défi ici est que les données obtenues peuvent ne pas être fréquemment mises à jour, et leur portée est souvent limitée. Des oracles comme Chainlink maintiennent généralement uniquement des états spécifiques, comme les prix, mais ne conviennent pas pour des données historiques ou personnalisées à une application. En outre, cette méthode introduit un certain biais dans les données, car elle repose sur la confiance envers les opérateurs de nœuds.
Faire confiance au code :
Variabales et fonctions spéciales : Des blockchains comme Ethereum disposent de variables et fonctions spéciales principalement destinées à fournir des informations sur la blockchain ou à servir de fonctions utilitaires générales. Les contrats intelligents ne peuvent accéder qu’aux hachages de blocs des 256 derniers blocs. Pour des raisons de scalabilité, tous les hachages de blocs ne sont pas disponibles. Pouvoir accéder aux anciens hachages de blocs serait extrêmement utile, car cela permettrait de réaliser des vérifications basées sur ceux-ci. L’environnement d’exécution EVM ne dispose d’aucun opcode permettant d’accéder au contenu des blocs anciens, aux transactions précédentes ou aux résultats des reçus, ce qui permet aux nœuds d’oublier ces éléments en toute sécurité tout en continuant à traiter de nouveaux blocs. Cette méthode est également limitée à une seule blockchain.
Étant donné les défis et limitations de ces solutions, il est clair qu’il existe un besoin explicite de stocker et fournir des hachages de blocs sur chaîne. C’est précisément là qu’interviennent les preuves de stockage. Pour mieux comprendre les preuves de stockage, examinons rapidement le stockage des données dans la blockchain.
Stockage des données dans la blockchain
Une blockchain est une base de données publique mise à jour et partagée entre de nombreux ordinateurs du réseau. Les données et l’état sont stockés sous forme de blocs continus, chaque bloc faisant référence cryptographiquement à son bloc parent en incluant le hachage de l’en-tête du bloc précédent.
Prenons l'exemple d'un bloc Ethereum. Ethereum utilise un type particulier d'arbre de Merkle appelé « Arbre de Merkle Patricia » (MPT). L'en-tête d'un bloc Ethereum contient les racines de quatre arbres Merkle-Patricia distincts : l'arbre d'état, l'arbre de stockage, l'arbre des reçus et l'arbre des transactions. Ces quatre arbres codent les mappages contenant toutes les données Ethereum. L'utilisation des arbres de Merkle découle de leur efficacité en matière de stockage des données. Grâce à un hachage récursif, seul le hachage racine doit être conservé, économisant ainsi beaucoup d'espace. Ils permettent à quiconque de prouver l'existence d'un élément dans l'arbre en montrant que le hachage récursif des nœuds aboutit à la même racine. Les preuves de Merkle permettent aux clients légers d'Ethereum d'obtenir des réponses aux questions suivantes :
-
Cette transaction existe-t-elle dans un bloc spécifique ?
-
Quel est le solde actuel de mon compte ?
-
Ce compte existe-t-il ?
Contrairement au téléchargement de chaque transaction et de chaque bloc, les « clients légers » peuvent simplement télécharger la chaîne des en-têtes de blocs et utiliser les preuves de Merkle pour valider les informations. Cela rend tout le processus très efficace.
Preuves de stockage
Les preuves de stockage nous permettent d’utiliser des preuves cryptographiques pour démontrer qu’un événement a bien été enregistré dans une base de données et qu’il est valide. Si nous pouvons fournir une telle preuve, il s’agit alors d’une affirmation vérifiable qu’un événement s’est produit sur la blockchain.
À quoi servent les preuves de stockage ?
Les preuves de stockage permettent deux fonctionnalités principales :
-
Accéder aux données historiques sur chaîne au-delà des 256 derniers blocs, jusqu’au bloc de genèse
-
Accéder aux données sur chaîne d'une autre blockchain (historiques et actuelles) depuis une blockchain donnée, grâce à la validation du consensus ou à un pont L2 (pour les L2)
Comment fonctionnent les preuves de stockage ?
En termes simples, les preuves de stockage vérifient si un bloc spécifique fait partie de l’histoire canonique de la blockchain, puis confirment que les données demandées font bien partie de ce bloc. Cela peut être réalisé de plusieurs façons :
-
Traitement sur chaîne : Une DApp peut obtenir un bloc initial de confiance, transmettre le bloc comme Calldata pour accéder au bloc précédent, et remonter ainsi jusqu’au bloc de genèse. Cela nécessite d’énormes calculs sur chaîne et une grande quantité de Calldata. En raison du coût massif de ces opérations sur chaîne, cette méthode est totalement impraticable. Aragon a tenté en 2018 d'utiliser cette approche, mais a dû y renoncer en raison du coût prohibitif.
-
Utilisation de preuves à connaissance nulle (zero-knowledge proofs) : La méthode est similaire au traitement sur chaîne, sauf que les calculs complexes sont déplacés hors chaîne grâce aux preuves ZK.
Accès aux données sur la même chaîne : on peut utiliser une preuve ZK pour affirmer qu’un en-tête de bloc historique arbitraire est l’ancêtre d’un des 256 derniers en-têtes accessibles dans l’environnement d’exécution. Une autre approche consiste à indexer toute l’histoire de la chaîne source et à générer une preuve ZK attestant que l’indexation a été correctement effectuée. Cette preuve est régulièrement mise à jour à mesure que de nouveaux blocs sont ajoutés à la chaîne source.
-
Accès aux données inter-chaînes : le fournisseur collecte les en-têtes de blocs de la chaîne source sur la chaîne cible, et utilise une preuve de consensus à connaissance nulle pour prouver la validité de ces en-têtes. On peut aussi recourir à des solutions existantes de messagerie inter-chaînes comme Axelar, Celer ou LayerZero pour interroger les en-têtes de blocs.
-
Maintenir sur la chaîne cible un cache des hachages d’en-têtes de blocs de la chaîne source, ou la racine d’un accumulateur de hachages hors chaîne. Ce cache est mis à jour régulièrement, et sert à prouver efficacement sur chaîne qu’un bloc donné existe et est cryptographiquement lié au dernier bloc accessible depuis l’état. Ce processus s'appelle la preuve de continuité de la chaîne. On peut aussi utiliser une blockchain spécialisée pour stocker tous les en-têtes de blocs de la chaîne source.
-
Selon la requête de la DApp sur la chaîne cible, accéder aux données historiques/blocs via un index hors chaîne ou un cache sur chaîne (selon la complexité de la requête). Les hachages d’en-têtes de blocs sont maintenus sur chaîne, tandis que les données elles-mêmes peuvent être stockées hors chaîne.
-
Vérifier via une preuve d’inclusion de Merkle si les données demandées se trouvent bien dans le bloc spécifié, puis générer une preuve ZK correspondante. Cette preuve est combinée avec une preuve ZK d’indexation correcte ou une preuve de consensus ZK, puis fournie sur chaîne pour une vérification sans confiance.
-
La DApp peut ensuite vérifier la preuve sur chaîne et utiliser les données pour exécuter l’opération souhaitée. Outre la vérification de la preuve ZK, des paramètres publics (comme le numéro et le hachage du bloc) sont également comparés au cache d’en-têtes maintenu sur chaîne.
Des projets comme Herodotus, Lagrange, Axiom, HyperOracle, Brevis Network et la fondation nil adoptent cette approche. Bien que des efforts considérables soient faits pour rendre les applications conscientes de l’état sur plusieurs blockchains, l’IBC (Inter-Blockchain Communication) se distingue comme norme d’interopérabilité, permettant aux applications d’utiliser des fonctionnalités comme ICQ (requêtes inter-chaînes) et ICA (comptes inter-chaînes). ICQ permet à une application sur la chaîne A d’interroger l’état de la chaîne B en incluant une requête dans un simple paquet IBC. ICA permet à une blockchain de contrôler en toute sécurité un compte sur une autre blockchain. Combinées, ces fonctionnalités permettent des cas d’usage inter-chaînes intéressants. Des fournisseurs RaaS comme Saga intègrent par défaut l’IBC pour offrir ces fonctionnalités à toutes les chaînes applicatives.
Les preuves de stockage peuvent être optimisées de diverses manières afin de trouver un équilibre optimal entre consommation mémoire, temps de génération de preuve, temps de vérification, efficacité computationnelle et expérience développeur. Le processus global peut être divisé en trois sous-processus principaux :
-
Accès aux données ;
-
Traitement des données ;
-
Génération de preuves ZK pour l’accès et le traitement des données.
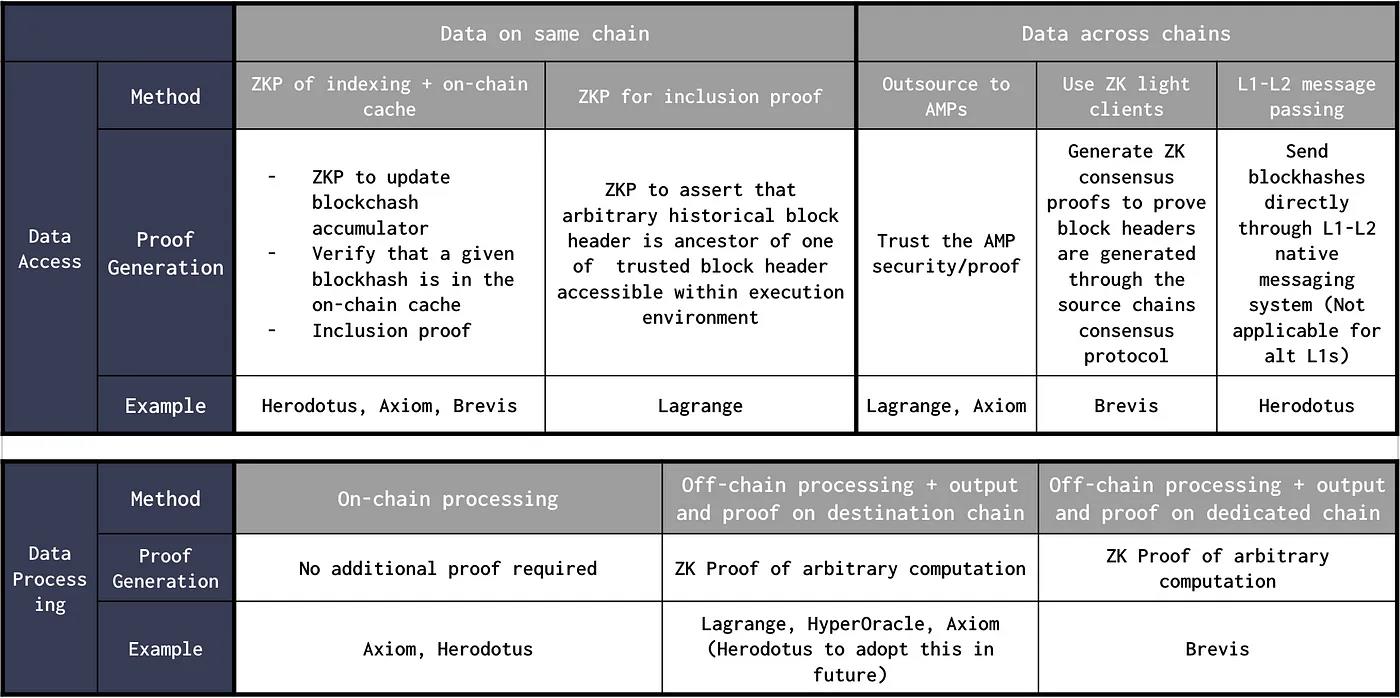
Accès aux données : dans ce sous-processus, le fournisseur accède aux en-têtes de blocs de la chaîne source directement au niveau d’exécution, ou via un cache sur chaîne. Pour l’accès aux données inter-chaînes, la validation du consensus de la chaîne source doit être assurée sur la chaîne cible. Les méthodes et optimisations utilisées incluent :
-
Blockchain Ethereum existante : on peut tirer parti de la structure existante d’Ethereum, en utilisant des preuves ZK pour prouver la valeur d’un emplacement de stockage historique arbitraire par rapport à l’en-tête de bloc courant. Cela peut être vu comme une grande preuve d’inclusion : étant donné un en-tête X à la hauteur b, il existe un en-tête Y à la hauteur b-k qui est son ancêtre. Cela repose sur la sécurité du consensus Ethereum et nécessite un système de preuve efficace. C’est la méthode adoptée par Lagrange.
-
Cache sur chaîne de Merkle Mountain Range (MMR) : Un MMR peut être vu comme une liste d’arbres de Merkle qui se combinent lorsqu’ils atteignent la même taille. Dans un MMR, un arbre de Merkle unique est formé en ajoutant le nœud parent à la racine précédente. Similaire à l’arbre de Merkle, le MMR offre des avantages supplémentaires, notamment un ajout efficace d’éléments et des requêtes de données rapides, surtout pour des données séquentielles issues de grands jeux de données. L’ajout d’un nouvel en-tête via un arbre de Merkle nécessite de transmettre tous les nœuds sœurs à chaque niveau. Pour ajouter efficacement des données, Axiom utilise un MMR pour maintenir un cache sur chaîne des hachages d’en-têtes de blocs. Herodotus stocke sur chaîne la racine du hachage accumulateur MMR. Cela leur permet de vérifier par preuve d’inclusion que les données récupérées correspondent à ces hachages d’en-têtes. Cette méthode nécessite une mise à jour régulière du cache, et pose des problèmes de vivacité si elle n’est pas suffisamment décentralisée.
-
Pour optimiser l’efficacité et le coût computationnel, Herodotus maintient deux types différents de MMR. Selon la blockchain ou couche concernée, l’accumulateur peut être personnalisé avec différentes fonctions de hachage. Par exemple, le hachage Poseidon pourrait être utilisé pour Starknet, tandis que Keccak serait utilisé pour les chaînes EVM.
-
Cache hors chaîne de MMR : Herodotus maintient un cache hors chaîne des requêtes et résultats précédemment obtenus, afin de répondre plus rapidement aux futures demandes identiques. Cela nécessite plus d’infrastructure qu’un simple nœud d’archive. Les optimisations sur l’infrastructure hors chaîne peuvent potentiellement réduire les coûts pour les utilisateurs finaux.
-
Blockchain spécialisée pour le stockage : Brevis s’appuie sur un rollup ZK spécialisé (couche d’agrégation) pour stocker tous les en-têtes de blocs de toutes les chaînes qu’il prouve. Sans cette couche d’agrégation, chaque chaîne devrait stocker les en-têtes de toutes les autres chaînes, entraînant O(N²) connexions pour N blockchains. En introduisant une couche d’agrégation, chaque blockchain n’a besoin que de stocker la racine d’état du rollup, réduisant ainsi le nombre total de connexions à O(N). Cette couche sert également à agréger plusieurs preuves d’en-têtes ou de résultats de requêtes, et à soumettre une seule preuve de vérification sur chaque blockchain connectée.
-
Messagerie L1-L2 : Puisque les L2 prennent en charge nativement la messagerie entre L1 et L2 pour mettre à jour les contrats L2, la validation du consensus de la chaîne source peut être évitée. Le cache peut être mis à jour sur Ethereum, et la messagerie L1-L2 peut être utilisée pour envoyer vers d'autres L2 les hachages de blocs ou les racines d’arbre compilés hors chaîne. Herodotus adopte cette approche, mais celle-ci n’est pas applicable aux alt-L1.
Traitement des données :
Outre l’accès aux données, les contrats intelligents devraient pouvoir effectuer des calculs arbitraires sur celles-ci. Bien que certains cas d’usage n’en aient pas besoin, pour de nombreux autres, il s’agit d’un service ajouté important. De nombreux fournisseurs supportent le calcul sur les données sous forme de preuves ZK, fournissant cette preuve sur chaîne pour en valider la validité. Étant donné que des solutions existantes de messagerie inter-chaînes comme Axelar, LayerZero ou Polyhedra Network peuvent être utilisées pour l’accès aux données, le traitement des données pourrait devenir un point de différenciation pour les fournisseurs de preuves de stockage.
Par exemple, HyperOracle permet aux développeurs de définir des calculs personnalisés hors chaîne en JavaScript. Brevis a conçu un marché ouvert de moteurs de requêtes ZK, acceptant des requêtes de données des DApps et les traitant à l’aide des en-têtes de blocs prouvés. Un contrat intelligent envoie une requête de données, récupérée par un prover du marché. Ce dernier génère une preuve basée sur l’entrée de la requête, les en-têtes de blocs associés (issus de la couche d’agrégation Brevis) et le résultat. Lagrange introduit une pile technologique ZK pour le big data, permettant de prouver des modèles de programmation distribuée comme SQL, MapReduce et Spark/RDD. Ces preuves sont modulaires et peuvent être générées à partir de n’importe quels en-têtes de blocs provenant de ponts inter-chaînes ou protocoles de messagerie existants. Le premier produit de cette pile technologique est le MapReduce ZK, un moteur de calcul distribué permettant de prouver des résultats impliquant de grandes quantités de données multi-chaînes (basé sur le célèbre modèle de programmation MapReduce). Par exemple, une seule preuve ZK MapReduce peut prouver les variations de liquidité sur un DEX déployé sur 4 à 5 chaînes pendant une fenêtre temporelle donnée. Pour des requêtes simples, les calculs peuvent aussi être effectués directement sur chaîne, comme le fait actuellement Herodotus.
Génération de preuves :
-
Preuves actualisables : Lorsqu’il faut calculer et maintenir efficacement des preuves sur un flux continu de blocs, on peut utiliser des preuves actualisables. Quand un nouveau bloc est créé, pour maintenir une preuve de moyenne mobile d’une variable sur chaîne (comme le prix d’un jeton), la preuve existante peut être mise à jour efficacement sans avoir à recalculer entièrement la nouvelle preuve. Pour prouver des calculs parallèles dynamiques sur des données d’état chaîne, Lagrange construit un engagement vectoriel par lots sur une partie de l’arbre MPT, appelé Recproof, qu’il met à jour en temps réel et sur lequel il effectue des calculs dynamiques. En créant récursivement un arbre Verkle au-dessus de l’arbre MPT, Lagrange peut calculer efficacement de grandes quantités de données d’état chaîne dynamiques.
-
Arbres Verkle : Contrairement aux arbres de Merkle, qui nécessitent tous les nœuds partageant un parent commun, les arbres Verkle ne nécessitent que le chemin racine. Ce chemin est nettement plus petit que tous les nœuds sœurs dans un arbre de Merkle. Ethereum envisage d’ailleurs d’utiliser les arbres Verkle dans de futures versions pour minimiser la quantité d’état que doivent conserver les nœuds complets. Brevis utilise les arbres Verkle pour stocker sur sa couche d’agrégation les en-têtes prouvés et les résultats de requêtes. Cela réduit considérablement la taille des preuves d’inclusion, surtout lorsque l’arbre contient de nombreux éléments, et permet des preuves efficaces par lots.
-
Surveillance du mempool pour accélérer la génération de preuves : Herodotus a récemment lancé turbo, permettant aux développeurs d’ajouter quelques lignes de code dans leurs contrats pour spécifier des requêtes de données. Herodotus surveille le mempool des transactions interagissant avec les contrats turbo. Dès qu’une transaction est dans le mempool, le processus de génération de preuve commence. Une fois la preuve générée et vérifiée sur chaîne, le résultat est écrit dans un contrat d’échange turbo. Seuls les résultats authentifiés par preuve de stockage peuvent être inscrits. Une fois cela fait, une partie des frais de transaction est partagée avec le séquenceur ou le producteur de blocs, les incitant à attendre plus longtemps pour percevoir des frais. Pour des requêtes simples, les données demandées pourraient être disponibles sur chaîne avant même que la transaction de l’utilisateur ne soit incluse dans un bloc.
Applications des preuves d’état / stockage
Les preuves d’état et de stockage peuvent débloquer de nouveaux cas d’usage pour les contrats intelligents aux niveaux applicatif, middleware et infrastructure. Parmi ceux-ci :
Niveau applicatif :
Gouvernance :
-
Vote inter-chaînes : les protocoles de vote sur chaîne peuvent permettre aux utilisateurs sur la chaîne B de prouver qu’ils possèdent des actifs sur la chaîne A, sans avoir à transférer leurs actifs pour obtenir des droits de vote sur une nouvelle chaîne. Exemple : SnapshotX sur Herodotus.
-
Distribution de jetons de gouvernance : une application peut distribuer davantage de jetons de gouvernance aux utilisateurs actifs ou aux premiers adoptants. Exemple : RetroPGF sur Lagrange.
Identité et réputation :
-
Preuve de possession : un utilisateur peut prouver qu’il possède un NFT, un SBT ou un actif sur la chaîne A, afin d’exécuter certaines actions sur la chaîne B. Par exemple, une chaîne applicative de jeu peut décider de lancer sa collection de NFT sur une autre chaîne ayant déjà de la liquidité, comme Ethereum ou un L2. Cela permettrait au jeu de tirer parti de la liquidité existante ailleurs, sans avoir besoin de NFTs inter-chaînes.
-
Preuve d’utilisation : les utilisateurs peuvent obtenir des réductions ou des fonctionnalités avancées selon leur historique d’utilisation sur une plateforme (par exemple, avoir effectué X volumes d’échanges sur Uniswap).
-
Preuve d’ancienneté (OG) : un utilisateur peut prouver qu’il possède un compte actif depuis plus de X jours.
-
Score de crédit sur chaîne : une plateforme de score de crédit inter-chaînes peut agréger les données de plusieurs comptes d’un même utilisateur pour générer un score de crédit.
Toutes ces preuves peuvent être utilisées pour offrir une expérience personnalisée aux utilisateurs. Les DApps peuvent proposer des réductions ou des privilèges pour fidéliser les traders expérimentés, ou simplifier l’expérience pour les nouveaux utilisateurs.
DeFi :
-
Prêt inter-chaînes : un utilisateur peut bloquer des actifs sur la chaîne A et obtenir un prêt sur la chaîne B, sans transférer de jetons.
-
Assurance sur chaîne : les sinistres peuvent être déterminés en accédant aux données historiques, et les paiements d’assurance peuvent être entièrement automatisés sur chaîne.
-
Prix moyen pondéré dans le pool : une application peut calculer et obtenir le prix moyen d’un actif dans un pool AMM sur une période donnée. Exemple : oracle TWAP Uniswap sur Axiom.
-
Tarification d'options : un protocole d'options sur chaîne peut utiliser la volatilité passée d’un actif sur un DEX pendant les n derniers blocs pour tarifer une option.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














