

Pourquoi la Web3 a-t-elle besoin d'une couche indépendante de disponibilité des données ?
TechFlow SélectionTechFlow Sélection
Pourquoi la Web3 a-t-elle besoin d'une couche indépendante de disponibilité des données ?
Les données sont l'actif central de l'ère Web3, et la propriété des données par les utilisateurs en est une caractéristique principale.
Lorsque l'économie des données atteint un certain niveau de développement, les individus y participent largement et en profondeur, chacun étant inévitablement impliqué dans diverses activités de stockage de données.
Par ailleurs, avec l'arrivée de l'ère Web3, la plupart des domaines technologiques vont progressivement évoluer ou se transformer au cours des prochaines années. Le stockage décentralisé, en tant qu'infrastructure clé du Web3, connaîtra une expansion vers davantage de cas d'utilisation. Par exemple, les réseaux de stockage derrière des données bien connues telles que les interactions sociales, les courtes vidéos, le streaming en direct ou encore les véhicules intelligents adopteront à l’avenir un modèle de stockage décentralisé.
Les données constituent l'actif central de l'ère Web3, et la propriété des données par les utilisateurs en est une caractéristique fondamentale. Permettre aux utilisateurs de posséder leurs données – ainsi que les actifs qu’elles représentent – en toute sécurité, tout en dissipant leurs préoccupations quant à la sécurité de leurs biens, contribuera à attirer les prochains milliards d’utilisateurs sur le Web. Une couche indépendante de disponibilité des données (data availability) sera un élément indispensable du Web3.
Du stockage décentralisé à la couche de disponibilité des données
Dans le passé, les données étaient stockées dans le cloud selon des méthodes traditionnelles centralisées, où elles étaient généralement conservées intégralement sur des serveurs centralisés.
Amazon Web Services (AWS) est le pionnier du stockage cloud et demeure aujourd’hui le plus grand fournisseur mondial de ce service.
-
Avec le temps, les exigences croissantes des utilisateurs en matière de sécurité personnelle et de stockage des données ont mis en lumière les limites du stockage centralisé, notamment après plusieurs fuites majeures impliquant de grands opérateurs de données. Les modèles traditionnels ne répondent désormais plus pleinement aux besoins du marché.
-
En outre, l'avancement continu de l'ère Web3, accompagné du développement des applications blockchain, a conduit à une diversification et à une croissance exponentielle des données. Les dimensions des données personnelles sont devenues plus complètes et plus précieuses, rendant la sécurité et la confidentialité des données encore plus critiques, et augmentant ainsi les exigences en matière de stockage.
Le stockage décentralisé est apparu en réponse à ces défis.
Le stockage décentralisé est l'une des infrastructures les plus anciennes et les plus remarquées du domaine Web3, dont la première mise en œuvre remonte à Filecoin, lancé en 2017.
Comparé à AWS, le stockage décentralisé diffère fondamentalement du modèle centralisé. AWS construit et exploite ses propres centres de données composés de nombreux serveurs, auxquels les utilisateurs paient directement pour accéder aux services de stockage. En revanche, le stockage décentralisé suit un modèle d'économie collaborative, exploitant un vaste réseau de dispositifs périphériques de stockage. Les données sont effectivement stockées sur les nœuds fournis par des Providers. Ainsi, les opérateurs de projets de stockage décentralisé ne contrôlent pas les données elles-mêmes. La différence essentielle entre le stockage décentralisé et AWS réside précisément dans la capacité des utilisateurs à contrôler leurs propres données. Dans un système sans contrôle centralisé, le niveau de sécurité des données est très élevé.
Le stockage décentralisé repose principalement sur un modèle commercial qui utilise le stockage distribué pour fragmenter des fichiers ou ensembles de fichiers sur un espace de stockage partagé. Son importance tient au fait qu’il résout de nombreux problèmes inhérents au stockage cloud centralisé du Web2, s’alignant mieux sur les besoins de l’ère du big data. Il permet de stocker efficacement et à moindre coût des données non structurées issues des terminaux périphériques, soutenant ainsi le développement des nouvelles technologies. De ce fait, le stockage décentralisé constitue une pierre angulaire du développement du Web3.
Actuellement, deux types de projets de stockage décentralisé sont couramment observés :
-
Le premier type vise la production de blocs en utilisant le stockage comme moyen de minage. Ce modèle entraîne cependant des ralentissements lors des opérations de stockage et de téléchargement sur la chaîne : télécharger une simple photo peut prendre plusieurs heures.
-
Le second type repose sur un ou plusieurs nœuds centraux qui valident les opérations de stockage et de téléchargement. Si ces nœuds centraux sont attaqués ou tombent en panne, cela peut entraîner la perte des données stockées.
Comparé au premier type, MEMO a mis en place un mécanisme de hiérarchisation du stockage qui résout efficacement le problème de la vitesse de téléchargement, permettant désormais des temps de transfert de l’ordre de la seconde.
Par rapport au second type, MEMO introduit un rôle appelé « Keeper », qui sélectionne aléatoirement les nœuds de validation, évitant ainsi toute centralisation tout en garantissant la sécurité. De plus, MEMO a développé de manière originale la technologie RAFI, qui améliore considérablement la capacité de réparation, renforçant ainsi la sécurité, la fiabilité et la disponibilité du stockage.
La disponibilité des données (Data Availability, DA) consiste essentiellement pour un nœud léger à pouvoir vérifier la disponibilité et l’exactitude des données sans participer au consensus, sans stocker l’intégralité des données ni maintenir constamment l’état complet du réseau. Pour ce type de nœud, il est crucial de disposer d’un mécanisme efficace assurant la disponibilité et la précision des données. En effet, la blockchain repose sur l’immutabilité des données, garantissant leur cohérence à travers tout le réseau. Toutefois, afin d’optimiser les performances, les nœuds de consensus tendent à devenir plus centralisés. Les autres nœuds doivent alors s’appuyer sur la couche DA pour obtenir les données validées par consensus. Une couche indépendante de disponibilité des données élimine efficacement les risques de défaillance unique, maximisant ainsi la sécurité des données.
De plus, des solutions de scalabilité comme zkRollup (couche 2) nécessitent également une couche de disponibilité des données. En tant que couche d’exécution, la couche 2 s’appuie sur la couche 1 comme couche de consensus. Outre la mise à jour sur la couche 1 des résultats agrégés des transactions, il est essentiel de garantir la disponibilité des données brutes des transactions, afin de permettre la récupération de l’état du réseau de la couche 2 même si aucun générateur de preuve n’est disponible. Cela évite le scénario extrême où les actifs des utilisateurs resteraient bloqués sur la couche 2. Toutefois, stocker directement ces données brutes sur la couche 1 irait à l’encontre du principe de modularité, selon lequel la couche 1 doit rester dédiée au consensus. Il est donc plus rationnel — et inévitable à long terme — de conserver les données sur une couche spécialisée de disponibilité des données, tout en inscrivant uniquement la racine de Merkle de ces données dans la couche de consensus.
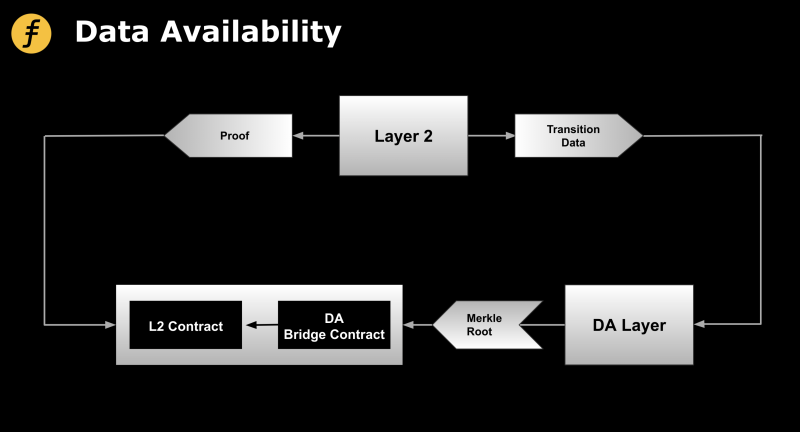
Figure 1 : Modèle universel d’une couche indépendante de disponibilité des données pour la couche 2, conçu par Fox Tech
Analyse de la couche indépendante de disponibilité des données : Celestia
Une couche indépendante de disponibilité des données prend la forme d’une blockchain, offrant un meilleur niveau de sécurité qu’un comité de disponibilité composé d’individus. Si suffisamment de clés privées de membres du comité sont compromises (comme cela s’est produit sur Ronin Bridge et Harmony Horizon Bridge), la disponibilité des données hors chaîne peut être compromise, exposant les utilisateurs à du chantage : ils devraient payer une rançon pour pouvoir retirer leurs fonds depuis la couche 2.
Puisque les comités hors chaîne de disponibilité des données ne sont pas suffisamment sécurisés, pourquoi ne pas recourir à une blockchain comme entité de confiance pour garantir cette disponibilité ?
C’est exactement ce que fait Celestia : rendre la couche de disponibilité des données plus décentralisée, en proposant une blockchain dédiée à la DA, dotée de ses propres nœuds de validation, producteurs de blocs et mécanisme de consensus, renforçant ainsi le niveau de sécurité global.
La couche 2 publie ses données transactionnelles sur la blockchain principale de Celestia. Les validateurs de Celestia signent ensuite la racine de Merkle de l'attestation de disponibilité des données (DA Attestation), qui est envoyée au contrat-pont DA sur la blockchain Ethereum pour vérification et enregistrement. Ainsi, la racine de Merkle remplace efficacement la vérification complète de toutes les données disponibles, réduisant considérablement les coûts pour la blockchain Ethereum.
Celestia utilise des preuves de fraude (fraud proofs) de type optimiste : tant qu’aucune erreur n’est détectée sur le réseau, l’efficacité est maximale. En l’absence d’anomalie, aucune preuve de fraude n’est générée. Les nœuds légers n’ont rien à faire d’autre qu’accepter les données reçues, les restaurer selon le codage utilisé, et le processus fonctionne alors de manière très efficace.
Analyse de la couche indépendante de disponibilité des données : MEMO
MEMO est un nouveau réseau de stockage d'entreprise à haute capacité et haute disponibilité, qui exploite algorithmiquement des dispositifs de stockage périphériques à l’échelle mondiale. Créée en septembre 2017, l’équipe se concentre sur la recherche dans le domaine du stockage décentralisé. MEMO est un protocole de stockage décentralisé à grande échelle, hautement sécurisé et fiable, basé sur la technologie pair-à-pair de la blockchain, capable de gérer de vastes volumes de données.
Contrairement au modèle centralisé « un-à-plusieurs », MEMO permet un stockage véritablement décentralisé, de type « plusieurs-à-plusieurs ».
Sur la blockchain principale de MEMO, les contrats intelligents régissent tous les nœuds. L’ensemble des opérations critiques — chargement des données, mise en relation avec les nœuds de stockage, fonctionnement normal du système, application du mécanisme de sanction — est contrôlé par des contrats intelligents.
Sur le plan technique, les systèmes existants de stockage décentralisé, comme Filecoin, Arweave ou Storj, permettent aux utilisateurs de partager l’espace disque inutilisé de leurs ordinateurs contre une rémunération ou des jetons. Bien qu'ils soient tous décentralisés, ils présentent chacun des particularités. La spécificité de MEMO réside dans l’utilisation du code d’effacement (erasure coding) et des technologies de réparation des données, qui améliorent la sécurité du stockage ainsi que l’efficacité des opérations de stockage et de téléchargement. L’objectif ultime de MEMO est de créer un système de stockage décentralisé plus pur et plus pratique.
MEMO améliore l’utilisabilité du stockage tout en optimisant les incitations pour les Providers. En plus des rôles User et Provider, il introduit un rôle de Keeper pour protéger les nœuds contre les attaques malveillantes. Grâce à l’interaction contrôlée entre ces différents rôles, le système maintient un équilibre économique, supportant des usages commerciaux de stockage d’entreprise à haute capacité et haute disponibilité. MEMO peut fournir des services de stockage cloud sûrs et fiables pour des applications telles que NFT, GameFi, DeFi, SocialFi, tout en restant compatible avec le Web2, incarnant ainsi une fusion réussie entre blockchain et stockage cloud.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














