

Let's thoroughly discuss Agents: Are they "colleagues" or "tools"? What exactly are the entrepreneurial opportunities and their true value?
TechFlow Selected TechFlow Selected
Let's thoroughly discuss Agents: Are they "colleagues" or "tools"? What exactly are the entrepreneurial opportunities and their true value?
AI products are evolving from "tools" to "relationships," and humans need to decide what kind of relationships to establish.
Compiled by: Moonshot
Source: GeekPark
2025 is the year Agent hits the accelerator.
From the awe sparked by DeepSeek at the beginning of the year, to the successive debuts of GPT-4o and Claude 3.5, the boundaries of large models have been rewritten time and again. But what truly sets the AI industry on edge isn't performance iteration—it's the sudden emergence of Agents.
The explosive popularity of products like Manus and Devin reaffirms a growing consensus: large models will no longer just be tools—they are evolving into intelligent entities capable of self-directed task execution.
Agent has thus become the second major trend in tech after large models, achieving global alignment faster than any previous innovation.
From strategic repositioning among giants to rapid adoption across startups, Agent has become the next frontier for mass investment. Yet, while consumer-facing products flood the market and developers rally around them, very few projects have managed to close the loop on real user value. More and more products now face anxiety over "applying old demands to new technology."
After the hype subsides, the market regains clarity: Is Agent truly a paradigm shift—or just repackaged expectations? Do the so-called "general-purpose" versus "vertical" paths genuinely open sustainable market opportunities? And behind the idea of a “new entry point,” is it an evolution in interaction—or merely a projection of the old world?
Digging deeper into these questions reveals that the true barrier for Agent may not lie in model capability, but in the foundational infrastructure it depends on. From controllable runtime environments to memory systems, context awareness, and tool integration—each missing foundational module stands as the biggest obstacle preventing Agents from moving beyond demos into practical use.
These underlying engineering challenges constitute the greatest hurdle keeping Agents from evolving from "trendy toys" into "productivity tools"—and simultaneously represent the most certain and high-value blue ocean for entrepreneurship today.
At this stage of oversupply and unclear demand, we aim through this conversation to answer an increasingly urgent question: Where do the real problems and genuine opportunities for Agent actually lie?
In this deep dialogue, we invited Li Guangmi, founder of Shixiang Tech, and Zhong Kaiqi, AI Research Lead at Shixiang Tech—two frontline practitioners—who will break down the real issues and opportunities in Agent from multiple dimensions including product design, technical pathways, business models, user experience, and infrastructure development.
We’ll follow their insights to explore where real opportunities exist for startups amid fierce competition from tech giants; how a pragmatic path from "Copilot" to "Agent" can be incrementally validated; and why Coding—a seemingly niche domain—is seen as the "value high ground" and "key indicator" toward AGI.
Ultimately, this conversation looks further ahead—to envision a new collaborative relationship between humans and Agents, and the core challenges and boundless opportunities in building the next generation of intelligent infrastructure.
Key Takeaways
-
The best approach in general-purpose Agent is “Model as Agent.”
-
Building Agent doesn’t need to be “end-to-start”—you don’t have to begin with fully automated agents. Start with Copilot: collect user data, refine UX, capture user mindshare, then gradually transition.
-
AGI may first emerge in the context of Coding, because it’s the simplest environment to train core AI capabilities. Coding is the “universal machine” of this world—once mastered, AI gains the power to build and create. Coding could capture up to 90% of the large model industry’s value in this phase.
-
AI-native products aren’t just for humans—they must serve AI too. A true AI-native product embeds bidirectional mechanisms serving both AI and humans.
-
Today’s AI products are evolving from “tools” to “relationships.” People don’t form relationships with tools—but they do with an AI that remembers, understands them, and achieves “mind-meld” synergy.
Below is the transcript of the live session of TechTalk Tonight, compiled by GeekPark.
01 Beyond the Hype: Which Agent Products Are Emerging?
Zhang Peng: Over the past period, everyone has been talking about Agent, seeing it as a critical topic right now—and a rare growth opportunity for startups.
I know Shixiang Tech has conducted in-depth research on the Agent ecosystem, experiencing and analyzing many related products. I’d like to hear from both of you: which Agent-related products have impressed you recently? Why?
Li Guangmi: Two stand out to me: Claude’s programming capabilities from Anthropic, and OpenAI ChatGPT’s Deep Research feature.
Regarding Claude, it’s mainly its coding ability. Here’s my view: Coding is the most crucial leading indicator for measuring AGI. If AI cannot scale and perform end-to-end software application development, progress in other domains will also be slow. We must first achieve strong ASI (Artificial Superintelligence) within the coding environment before other areas can accelerate. In other words, we first realize AGI in the digital realm, then extend it outward.

The world’s first AI programmer Devin|Image source: Cognition Labs
As for Deep Research, it’s been extremely helpful to me—I use it almost daily. It’s essentially a search Agent that retrieves vast amounts of web content and documents. The experience is excellent and greatly expands my research capacity.
Zhang Peng: Cage, from your perspective, which products left a strong impression?
Zhong Kaiqi (Cage): Let me first share the mental model I use when observing and using Agents, then introduce one or two representative products under each category.
First, people often ask: general-purpose Agent vs. vertical Agent? We believe the best work in general-purpose Agent lies in “Model as Agent.” For example, the Deep Research feature mentioned earlier from OpenAI, or OpenAI’s newly released o3 model—these are standard examples of “Model as Agent.” They integrate all Agent components—large language model (LLM), context, tool usage, and environment—into one system trained end-to-end via reinforcement learning. After training, it can handle various information retrieval tasks seamlessly.
So here’s my bold take: the demand for general-purpose Agent basically boils down to information retrieval and light code writing—and GPT-4o already does this exceptionally well. Therefore, the general-purpose Agent market is largely dominated by large model companies; it’s hard for startups to grow solely by serving general needs.
The startups that impress me most are those focused on vertical domains.
If we consider B2B verticals, we can analogize human work into front-office and back-office roles.
Back-office work tends to be repetitive, requires high concurrency, and usually follows long SOPs (Standard Operating Procedures). Many of these tasks are ideal for AI Agents to execute one-by-one, especially in environments allowing broad exploration space for reinforcement learning. A good example here are startups in AI for Science, building Multi-agent Systems.
In such systems, various research tasks are integrated—literature review, experiment planning, forecasting advances, data analysis, etc. The key difference from something like Deep Research is that instead of a single Agent, it’s a complex system offering higher-resolution support for scientific workflows. One particularly interesting function is “Contradiction Finding,” which handles adversarial tasks—for instance, identifying contradictions between two top-tier journal papers. This represents a compelling new paradigm in research-oriented Agents.
Front-office work often involves interpersonal communication—outreach, customer service—where voice Agents are currently most suitable, such as nurse call-backs in healthcare, recruitment, or logistics coordination.
One company I’d highlight is HappyRobot. They’ve targeted a seemingly small niche: phone calls in logistics and supply chain. For example, if a truck driver faces an issue or delivery is complete, the Agent can quickly make a call. This leverages a unique strength of AI Agents: 24/7 uninterrupted responsiveness and rapid reaction. For most logistics needs, this level of service is sufficient.
Besides these two categories, there are some special cases—like Coding Agents.
02 From Copilot to Agent: Is There a More Practical Path Forward?
Cage: In code development, entrepreneurial enthusiasm is surging. A great example is Cursor. With Cursor 1.0, a product originally resembling a Copilot (assisted driving) transformed into a full-fledged Agent. It supports background asynchronous operations and has memory—exactly what we imagine an Agent should be.
The comparison between Cursor and Devin is telling and instructive: building Agent doesn’t need to start with the final goal in mind. You don’t have to aim straight for full automation. Starting with Copilot allows you to collect user data, refine user experience, capture user mindshare, and gradually evolve. Domestically, Minus AI is another solid example—their early product also began in Copilot mode.
Finally, I use the concept of “environment” to differentiate Agents. For instance, Manus operates in a virtual machine (VM), Devin in a browser, flowith in a notebook, SheetZero in spreadsheets, Lovart on canvas. This “environment” aligns with the definition in reinforcement learning and offers a useful classification framework.

Domestic startup-built flowith|Image source: flowith
Zhang Peng: Let’s dive deeper into Cursor. What’s its tech stack and growth trajectory?
Cage: The analogy with autonomous driving is insightful—even today, Tesla won’t remove the steering wheel, brakes, or accelerator. This shows that in critical decisions, AI still can’t fully surpass humans. As long as AI performs roughly on par with humans, certain key decisions still require human input. This is precisely what Cursor understood early on.
So their initial focus was on the most needed human function: autocompletion. They made it triggerable via the Tab key. With models like Claude 3.5 emerging, Cursor boosted Tab accuracy above 90%. At this level, users can consecutively use it 5–10 times within a task flow, creating a seamless “flow” experience. This marked Cursor’s first phase as a Copilot.
In the second phase, they introduced code refactoring. Both Devin and Cursor aimed for this, but Cursor executed it more cleverly. It pops up a dialog box, and when you enter a request, it opens a parallel editing mode outside the file to refactor code.
Initially, accuracy wasn’t high, but since users perceived it as a Copilot, tolerance was greater. Crucially, they accurately anticipated that model coding abilities would rapidly improve. So while refining product features, they waited for model capabilities to catch up—enabling Agent-like abilities to naturally emerge.
The third phase is Cursor today: a relatively end-to-end Agent running in the background. Behind it lies a sandbox-like environment. I can assign tasks I don’t want to do during work hours, and it executes them using my computing resources, freeing me to focus on core tasks.
Finally, it delivers results asynchronously—via email or messaging apps like Feishu. This smooth progression enabled a natural transition from Copilot to Autopilot (or Agent).
The key is capturing human interaction psychology—starting with synchronous interactions that users readily accept, enabling massive collection of user data and feedback.
03 Why Is Coding the “Crucial Battleground” Toward AGI?
Zhang Peng: Guangmi mentioned earlier: “Coding is the gateway to AGI—if we can’t achieve ASI (superintelligence) here, it’s unlikely elsewhere.” Why?
Li Guangmi: There are several reasons. First, code data is the cleanest, easiest to close the loop on, and its outcomes are verifiable. I suspect chatbots may lack a data flywheel (a feedback mechanism where interaction generates data that improves the model, producing better results and more valuable data). But coding has the potential to create a data flywheel, as it enables multi-round reinforcement learning—and coding is a key environment for such loops.
I see coding both as a programming tool and more importantly as an environment for achieving AGI. AGI may first emerge here because the environment is simplest and best suited to train core AI capabilities. If AI can’t develop end-to-end applications, it will struggle even more in other domains. If it fails to broadly replace basic software development in the near future, it will likely fail elsewhere too.
Moreover, improved coding ability boosts instruction-following skills. For example, handling long prompts—Claude clearly excels here. We suspect this is logically linked to its coding strength.
Another point: I believe future AGI will first manifest in the digital world. Within the next two years, Agents will be able to perform nearly everything humans do on phones and computers. Simple tasks via direct coding; others by invoking virtual tools. Achieving AGI first in the digital world—where it can operate faster—is a fundamental logic.
04 How to Evaluate a Good Agent?
Zhang Peng: Coding is the “universal machine” of this world—once mastered, AI can build and create. And coding is relatively structured, making it ideal for AI. When evaluating Agent quality, beyond user experience, what criteria do you use to assess an Agent’s potential?
Cage: A good Agent must first have an environment that enables a data flywheel—and the data itself must be verifiable.
Recently, researchers at Anthropic have emphasized RLVR (Reinforcement Learning from Verifiable Reward), where the “V” stands for verifiable reward. Coding and math are classic verifiable domains—once a task is done, correctness can be instantly verified, naturally establishing a data flywheel.
Mechanism of the data flywheel|Image source: NVIDIA
Therefore, designing an Agent product means creating such an environment. In it, whether a user succeeds or fails isn’t critical—Agents will inevitably fail today. What matters is that upon failure, the system captures signal-rich data, not noise, to guide product optimization. This data can even serve as cold-start input for reinforcement learning environments.
Second, whether the product is truly “Agent Native.” That is, during design, both human and Agent needs must be considered. A classic example is The Browser Company—why build a new browser? Because Arc was designed purely to boost human efficiency. Their new browser, however, includes features specifically designed for future use by AI Agents. When the foundational design logic shifts, it becomes profoundly significant.
Objectively, evaluation metrics matter too.
1. Task completion rate + success rate: First, the task must finish, so users receive feedback. Then, success rate. For a 10-step task with 90% accuracy per step, overall success drops to only 35%. So optimizing transitions between steps is essential. Currently, an industry benchmark might be over 50% success rate.
2. Cost and efficiency: Includes computational cost (token cost) and user time cost. If GPT-4o completes a task in 3 minutes while another Agent takes 30, that’s a huge burden for users—and massive compute consumption, affecting scalability.
3. User metrics: Most notably, user stickiness. After initial trial, do users return repeatedly? Metrics like DAU/MAU ratio, month-over-month retention, and payment rate are fundamental to avoid “false prosperity” (five minutes of fame).
Li Guangmi: Let me add another angle: how well the Agent matches current model capabilities. Today, 80% of an Agent’s ability relies on the model engine. For example, once GPT reached 3.5, the general pattern of multi-turn dialogue emerged, making Chatbot viable. Cursor rose because models advanced to Claude 3.5, enabling reliable code completion.
Devin launched slightly too early. This underscores how vital it is for founders to understand model capability boundaries—knowing where models stand today and where they’ll be in six months directly impacts what goals an Agent can achieve.
Zhang Peng: What defines an “AI Native” product? I think an AI Native product isn’t just for humans—it must also serve AI.
In other words, if a product lacks proper data for tuning and hasn’t built an environment for future AI work, it treats AI merely as a cost-cutting tool. Such products have limited lifespan and are easily swept away by technological waves. A true AI Native product embeds bidirectional mechanisms serving both AI and humans. Simply put: while AI serves the user, is the user also serving AI?
Cage: I love this concept. Agent data doesn’t exist in the real world—no one breaks down their thought process step-by-step when completing a task. So what do we do? One way is professional annotation firms; another is leveraging users—capturing real usage patterns and the Agent’s own operational traces.
Zhang Peng: If we use Agents to get humans to “feed” data to AI, which types of tasks are most valuable?
Cage: Rather than thinking about feeding data to AI, we should consider where AI’s strengths lie and amplify them. For example, in scientific research, before AlphaGo, humans believed Go and mathematics were the hardest. But with reinforcement learning, these turned out to be easiest for AI. Similarly in science: no scholar today can master every corner of every discipline, but AI can. That’s why we should find more data and services to support AI in such domains. These tasks yield more verifiable returns—and in the future, humans might literally “shake test tubes” for AI, reporting back whether results are correct, helping AI collectively advance scientific discovery.
Li Guangmi: Cold-start data is essential at the beginning. Building an Agent is like starting a company—the founder must bootstrap, doing things manually. Next, building the environment is crucial, determining the Agent’s direction. Beyond that, constructing a reward system becomes paramount. I believe environment and reward are the two most critical factors. On this foundation, Agent entrepreneurs simply need to act as the Agent’s “CEO.” Today, AI can already write code that humans can’t understand but runs correctly—we don’t need to fully grasp end-to-end reinforcement learning logic. Just set up the environment and define rewards properly.
05 Where Is the Agent Business Model Heading?
Zhang Peng: Recently, we’ve seen many B2B Agents, especially in the U.S.—have their business or growth models changed? Are new models emerging?
Cage: The biggest trend now is increasing number of products entering organizations bottom-up, starting from individual C-end users. The prime example is Cursor. Beyond that, many AI Agents or Copilots are adopted organically by individuals. This breaks from traditional SaaS, which required selling to CIOs and signing contracts one-on-one—at least initially.
Another interesting product is OpenEvidence, targeting doctors. They first captured individual doctors, then gradually embedded ads for medical devices and drugs. They didn’t need to negotiate with hospitals upfront—because hospital deals are slow. Speed is key for AI startups—technical moats alone aren’t enough. Bottom-up adoption enables this speed.

AI healthcare unicorn OpenEvidence|Image source: OpenEvidence
Regarding business models, there’s a clear shift from cost-based pricing to value-based pricing.
1. Cost-based: Like traditional cloud services—adding software value atop CPU/GPU costs.
2. Pay-per-action: For Agents, charging per “action.” For example, the logistics Agent I mentioned earlier charges a few cents per call to a truck driver.
3. Pay-per-workflow: A higher abstraction—charging per “workflow,” e.g., completing an entire logistics order. This moves farther from cost, closer to value, as the Agent actively participates in work. But it requires a relatively well-defined scenario.
4. Pay-for-results: Even higher—charging only for successful outcomes. Given low Agent success rates, users prefer paying only when results are achieved. This demands exceptional product refinement from Agent companies.
5. Pay-per-Agent: In the future, we may pay directly for the Agent itself. For example, Hippocratic AI offers an AI nurse. Hiring a human nurse in the U.S. costs ~$40/hour, while their AI nurse costs $9–10—an 75% reduction. In labor-expensive markets like the U.S., this makes perfect sense. If Agents improve further, I might even give them bonuses or annual raises. These are innovative business models.
Li Guangmi: We’re most excited about value-based pricing. For example, is a website built by Manus AI worth $300? Is an app worth $50,000? Today, valuing such tasks remains difficult. How to establish a robust valuation mechanism is a rich area for entrepreneurs to explore.
Also, Cage mentioned paying per Agent—this resembles signing employment contracts. In the future, when we hire an Agent, should we issue it an ID? Sign a labor contract? This is essentially a smart contract. I’m excited to see how crypto’s smart contracts might apply to digital Agents—automatically allocating economic benefits upon task completion via sound valuation methods. This could be a powerful convergence of Agent and crypto smart contracts.
06 What Will Human-Agent Collaboration Look Like?
Zhang Peng: Recently, two terms are widely discussed in Coding Agent circles: “Human in the loop” and “Human on the loop.” What do they mean?
Cage: “Human on the loop” means minimizing human involvement in decision loops, only stepping in at critical moments. Similar to Tesla’s FSD, which alerts humans to take control during risky situations. In virtual worlds, this typically refers to non-real-time, asynchronous collaboration—humans intervene only when AI is uncertain about key decisions.
“Human in the loop” means AI frequently “pings” the user to confirm actions. For example, Minus AI has a VM on the right side—I can see in real time what it’s doing in the browser, like an open white box, giving me insight into the Agent’s intentions.
These aren’t binary opposites but points on a spectrum. Today, we’re mostly in “in the loop” mode—humans still approve many critical points. The reason is simple: the software isn’t mature yet—someone must be accountable when things go wrong. The gas pedal and brakes won’t disappear anytime soon.
Looking ahead, for highly repetitive tasks, outcomes will likely involve humans only reviewing summaries—with very high automation. For complex tasks—like having AI analyze pathology reports—we could set a higher “false positive” rate, making the Agent more likely to flag “issues,” then send these cases via email (“on the loop”) to human doctors. While doctors review more cases, all cases judged “negative” by the Agent can be automatically approved. If only 20% of reports are truly difficult, doctor bandwidth increases fivefold. So don’t obsess over “in” vs. “on”—find the right balance to optimize human-AI collaboration.
Li Guangmi: Underlying your question, Peng, lies a massive opportunity: “new interaction paradigms” and “how humans and Agents collaborate.” This can be simplified into online (synchronous) and offline (asynchronous). For example, live meetings require real-time presence. But if I, as a CEO, assign tasks to colleagues, project progress is asynchronous.
The deeper significance is that once Agents are widely deployed, how humans and Agents interact—and how Agents interact with each other—becomes a rich field for exploration. Today we interact with AI via text, but future interactions with Agents will diversify. Some may run autonomously in the background; others require human supervision. Exploring new interactions is a massive opportunity.
07 Capability Oversupply, Demand Shortage: When Will the “Killer App” Emerge?
Zhang Peng: Coding Agents are still largely extensions of IDEs. Will this change? If everyone rushes down this path, how can latecomers catch up with Cursor?
Cage: IDE is just one environment—replicating another IDE adds little value. But building Agents within IDEs or other strong environments is valuable. The key question is: are the users only professional developers, or can we expand to “citizen developers”—white-collar workers with automation needs beyond coding expertise?
What’s missing today? Not supply—products like Cursor have amplified AI coding capability by 10x or even 100x. Previously, building a product required outsourcing an IT team with high trial cost. Now, theoretically, I can say one sentence and test ideas for $20/month.
What’s missing is demand. Everyone is applying old demands to new technology—like “hammer in search of a nail.” Current use cases mostly involve landing pages or simple toy websites. The future needs a convergent product form. This resembles the early days of recommendation engines—great technology that later found mass adoption through “news feeds.” But AI Coding hasn’t yet found its “news feed” killer app.
Li Guangmi: I believe Coding could capture up to 90% of the large model industry’s value in this phase. How does this value grow? The first stage still targets the world’s 30 million programmers. Consider Photoshop—it serves 20–30 million professional designers, with high barriers. But when tools like CapCut, Canva, and Meitu emerged, perhaps 500 million or more users could create viral content.
Coding has an advantage: it’s a platform for creative expression. Over 90% of societal tasks can be expressed through code—making it a potential creativity platform. Previously, app development had high barriers, leaving vast long-tail needs unmet. Once barriers drop significantly, these demands will surge. I anticipate an “app explosion.” Mobile internet generated massive content; this AI wave may generate massive new applications. Think of Youku, iQiyi versus Douyin. You can view large models as cameras—on top of which emerge killer apps like Douyin and CapCut. This may be the essence of “Vibe Coding”—a new creative platform.
Zhang Peng: To enhance Agent output value, input quality becomes critical. But from product and technical perspectives, what methods can improve input quality to ensure better outputs?
Cage: In product design, we shouldn’t assume poor user experience is the user’s fault. The key effort centers on “context.” Can an Agent achieve “context awareness”?
For example, if I’m coding at an internet giant, the Agent should see not only my current code but also the entire company’s codebase, my Feishu conversations with PMs and colleagues, and my past coding and communication habits. Equipped with this context, my input becomes far more efficient.
Thus, for Agent developers, the most critical challenge is building robust memory mechanisms and strong context-linking capabilities—one of the biggest hurdles in Agent infrastructure (Infra).
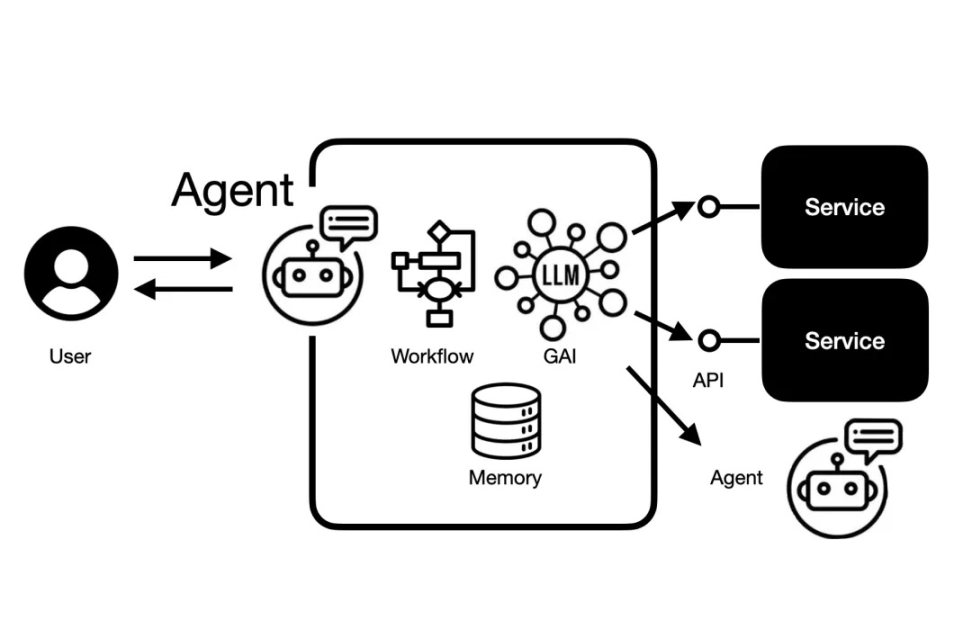
Agent challenge: robust memory and context connection|Image source: Retail Science
Additionally, for developers, ensuring good cold-start data for reinforcement learning and defining clear rewards is crucial. Behind rewards lies the ability to decompose vague user requests. For example, when my query is unclear, OpenAI’s Deep Research offers four guiding questions. Through interaction, I clarify my own needs.
For users today, the main task is learning to express needs clearly and validate outcomes. While we don’t need to be “end-to-start,” we should have a rough expectation of quality. Writing prompts should resemble coding—clear instructions and logic—to avoid wasteful outputs.
Li Guangmi: Let me add two points. First, the importance of context. Internally, we often discuss: mastering context could unlock PayPal- or Alipay-level opportunities.
Previously, e-commerce focused on GMV (Gross Merchandise Volume); going forward, it will track task completion rates. Task completion hinges on two sides: intelligence and context. For example, building a personal website—if I provide AI with my Notion notes, WeChat data, emails—the content will be immensely richer.
Second, autonomous learning. After setting up the environment, the Agent must iterate independently—this is crucial. Without continuous learning and iteration, the Agent risks being consumed by the model itself, as the model is already a learning system. In the last mobile internet wave, companies without machine learning and recommendation didn’t scale. This time, if Agents can’t achieve end-to-end autonomous learning and iteration, they likely won’t succeed either.
08 Amid Giant Rivalry: What Changes and Opportunities Lie Ahead?
Zhang Peng: How do we judge whether future Agent capabilities will emerge as a super interface or remain scattered across scenarios?
Cage: I observe a major trend: first, it will definitely be multi-agent. Even for a single task, in products like Cursor, different Agents may handle code completion and unit testing—because they require different “personalities” and strengths.
Second, will entry points change? I see entry as a second-order question. First, people will have many Agents and collaborate with them. These Agents will underpin a network I call “Botnet.” For example, in the future, over 60% of routine purchases may be handled by Agents.
In productivity settings too, daily stand-ups for programmers may be replaced by Agent-to-Agent collaboration, sharing metric anomalies and development progress. Only after such developments might entry point changes occur. Then, API calls will no longer be primarily human-driven, but Agent-to-Agent.
Zhang Peng: What strategies and actions are big players like OpenAI, Anthropic, Google, Microsoft taking regarding Agents?
Li Guangmi: One keyword in my mind is “divergence.” Last year, everyone chased GPT-4, but now possibilities have expanded—players are diverging.
The first to diverge is Anthropic. Arriving later than OpenAI with weaker overall capabilities, it focused on Coding. I feel it has grasped the first major card toward AGI: the Coding Agent. They likely believe AGI can be achieved through coding, enhancing instruction-following and Agent capabilities—a logically coherent loop.
But OpenAI holds more cards. First is ChatGPT—Sam Altman may aim to make it a 1-billion-daily-active-user product. Second is its “o” series models (e.g., GPT-4o), with high expectations and broader generalization. Third is multimodality—its multimodal reasoning is improving, which will enhance generation. So Anthropic drew one big card; OpenAI drew three.
Another giant is Google. By year-end, Google may catch up comprehensively. It owns TPUs, Google Cloud, top-tier Gemini models, Android, and Chrome. Globally, no other company possesses all these elements with near-zero external dependency. Google’s end-to-end capability is formidable. Many worry its ad business will be disrupted, but I think it may find new product integrations—evolving from an information engine to a task engine.
Look at Apple—without native AI, its iterations are passive. Microsoft excels in developer tools, but Cursor and Claude have drawn developer attention. Still, Microsoft’s position is stable—backed by GitHub and VS Code—but it must possess strong AGI and model capabilities. Hence, it announced GitHub’s default models now include Claude and continues iterating developer products. Microsoft must defend its developer base—otherwise its foundation crumbles.
So divergence is underway. Perhaps OpenAI aims to become the next Google, while Anthropic wants to be the next Windows (living off APIs).
Zhang Peng: What changes and opportunities exist in Agent-related infrastructure (Infra)?
Cage: Agents have several key components. Beyond the model, the first is Environment. In early Agent development, 80% of issues stem from environment. Early AutoGPT either launched via Docker—very slow—or ran locally—highly insecure. If an Agent works alongside me, I need to equip it with a “computer”—creating an opportunity for environment providers.
Equipping a “computer” involves two needs:
1. Virtual Machine / Sandbox: Provides a secure execution environment. Mistakes can be rolled back; execution must not harm the actual system; fast startup and stable operation are essential. Companies like E2B and Modal Labs offer such solutions.
2. Browser: Information retrieval is the biggest need. Agents must scrape data from various sites. Traditional scrapers get blocked easily—so Agents need dedicated, intelligent browsers. This gave rise to companies like Browserbase and Browser Use.
The second component is Context, including:
-
Retrieval: Traditional RAG companies persist, but new ones emerge—like MemGPT, offering lightweight memory and context management tools for AI Agents.
-
Tool Discovery: Future tools will proliferate. We’ll need a “Yelp-like” platform to help Agents discover and select effective tools.
-
Memory: Agents need infrastructure simulating human-like integration of short-term and long-term memory.
The third component is Tools—ranging from simple search to complex payments and backend automation.
Finally, as Agent capabilities grow stronger, a major opportunity arises: Agent Security.
Li Guangmi: Agent Infra is critically important. Thinking “end-to-start,” in three years, when trillions of Agents operate in the digital world performing tasks, infrastructure demand will be enormous—reshaping the entire cloud computing and digital landscape.
But today, we don’t yet know which Agents will scale or what exact Infra they’ll need. So this is a golden window for entrepreneurs—to co-design and co-create Infra tools with leading Agent companies.
I believe the two most important areas today are virtual machines and tools. For example, future Agent search will differ fundamentally from human search, generating massive machine search demand. Today, global human searches may total 20 billion daily; future machine searches could reach hundreds of billions or even trillions. Such searches don’t need human-style ranking—perhaps a large database suffices. Huge cost optimization and entrepreneurial opportunities await.
09 When AI Evolves Beyond Large Models, Where Will It Head?
Zhang Peng: Agent always revolves around models. Looking from today’s vantage, what key milestones has model technology passed through in the past two years?
Li Guangmi: I think there are two key milestones. The first is the Scaling Law paradigm represented by GPT-4—during pre-training, scaling up remains effective, delivering generalization.
The second major milestone is the “thinking model” paradigm embodied by the “o” series—achieving significantly enhanced reasoning through extended thinking time (chain-of-thought).
I see these two paradigms as the twin pillars of today’s AGI. On this foundation, Scaling Law continues, and thinking models will advance further. For example, multimodal scaling will continue, and “o”-style reasoning can be applied to multimodal contexts—enabling longer inference chains, greatly improving controllability and consistency in generation.
Personally, I think progress in the next two years may outpace the last two. We may be entering a phase where thousands of top AI scientists globally drive a technological and cultural renaissance—well-resourced, well-platformed, ripe for breakthroughs.
Zhang Peng: What technical leaps in AI over the next one to two years are you most anticipating?
Cage: First, multimodality. Current multimodal understanding and generation are fragmented. The future lies in “unified” multimodal systems—integration of understanding and generation. This will vastly expand product imagination.
Second, autonomous learning. I deeply resonate with Richard Sutton’s (father of reinforcement learning) concept of “the era of experience”—AI improving through real-world task execution. This was unimaginable before due to lack of foundational world knowledge. But from this year onward, it will become a continuous reality.

Richard Sutton, 2024 Turing Award winner|Image source: Amii
Third, memory. If models can truly deliver robust memory for Agents at product and technical levels, the breakthrough will be immense. Real product stickiness will emerge. I felt genuine stickiness with ChatGPT the moment GPT-4o gained memory.
Finally, new interaction modes. Will we move beyond text input boxes? Typing is actually a high barrier. Could future interactions be more intuitive and instinctive? For example, an “always-on” AI that listens continuously in the background, thinks asynchronously, and captures key context the moment inspiration strikes. These are what I look forward to.
Zhang Peng: Indeed, today we face both challenges and opportunities. On one hand, we must avoid being overwhelmed by the pace of technological advancement, maintaining sustained attention. On the other, today’s AI products are evolving from “tools” to “relationships.” People don’t form relationships with tools—but they do with an AI that remembers, understands them, and achieves “mind-meld” synergy. This relationship—built on habit and inertia—is itself a future moat.
This discussion has been deeply insightful. Thank you, Guangmi and Cage, for your brilliant insights. Thanks also to our live audience. See you next time on TechTalk Tonight.
Li Guangmi: Thank you.
Zhong Kaiqi (Cage): Thank you.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News












