

How is the cost of DeepSeek and others calculated?
TechFlow Selected TechFlow Selected
How is the cost of DeepSeek and others calculated?
The large model battle rages on, with competition focused on capabilities on one side and "cost" on the other.
Author: Wang Lu, original from Dingjiao One (dingjiaoone)
DeepSeek has completely shaken the entire world.
Yesterday, Musk appeared live with "the smartest AI on Earth"—Grok 3, claiming its "reasoning capabilities surpass all currently known models," outperforming both DeepSeek R1 and OpenAI o1 in reasoning-time testing scores. Not long ago, China's national super app WeChat announced integration with DeepSeek R1, currently undergoing gray-scale testing. This powerful combination is widely seen as a sign of upheaval in the AI search field.
Today, major global tech companies including Microsoft, NVIDIA, Huawei Cloud, and Tencent Cloud have all integrated DeepSeek. Netizens have developed novel uses such as fortune-telling and lottery predictions. The hype has directly translated into real revenue, driving DeepSeek’s valuation upward—reaching a peak of $100 billion.
Beyond being free and effective, DeepSeek stands out because it trained its DeepSeek R1 model—comparable in capability to OpenAI o1—with only $5.576 million in GPU costs. Over the past few years of the "hundred-model war," AI companies worldwide have poured tens or even hundreds of billions of dollars into large models. The cost for Grok 3 to become the "world's smartest AI" was steep: Musk said training Grok 3 consumed a cumulative total of 200,000 NVIDIA GPUs (each costing about $30,000), while industry insiders estimate DeepSeek used only around 10,000.
Yet others are pushing cost efficiency even further. Recently, Li Feifei's team claimed to train a reasoning model S1 for under $50 in cloud computing fees, matching o1 and R1 in math and coding benchmarks. However, note that S1 is a medium-sized model, far smaller than the hundreds-of-billions parameter scale of DeepSeek R1.
Nonetheless, the vast difference—from $50 to hundreds of billions—in training costs raises public curiosity: How capable is DeepSeek really? Why are so many players rushing to catch up or surpass it? And how much does it actually cost to train a large model? What components are involved? Can training costs be reduced further in the future?
The Misrepresented DeepSeek
From an industry perspective, answering these questions requires clarifying several concepts first.
First, there's a tendency toward overgeneralization regarding DeepSeek. People are amazed by one of its many large models—the reasoning model DeepSeek-R1—but it also has other models with different functionalities. The $5.576 million figure refers specifically to GPU spending during the training of its general-purpose model DeepSeek-V3, representing pure compute cost.
A simple comparison:
-
General-Purpose Large Model:
Takes clear instructions, breaks down steps; users must describe tasks explicitly, including response order—for example, whether to summarize before giving a title or vice versa.
Faster response, based on probabilistic prediction (quick reaction), predicting answers from massive datasets.
-
Reasoning Large Model:
Takes simple, goal-oriented tasks; users state what they want directly, and the model plans autonomously.
Slower response, based on chain-of-thought reasoning (slow thinking), solving problems step-by-step.
The key technical difference lies in training data: general models use question + answer pairs; reasoning models use question + thought process + answer.
Second, due to higher visibility of DeepSeek-R1, many mistakenly assume reasoning models are inherently superior to general-purpose models.
It's true reasoning models represent a cutting-edge type—an innovation introduced by OpenAI after hitting limits in standard pretraining paradigms, adding more compute during inference. Compared to general models, reasoning models are more expensive and require longer training times.
However, this doesn't mean reasoning models are always better. For certain tasks, they can even be inefficient.
Liu Cong, a well-known expert in the field, explained to DingjiaoOne that for queries like a country's capital or provincial capital, reasoning models perform worse than general models.

Overthinking by DeepSeek-R1 on simple questions
He noted that for such simple queries, reasoning models not only respond less efficiently but also consume more compute resources, sometimes overthink, and may even produce incorrect answers.
He recommends using reasoning models for complex tasks like advanced math problems or challenging coding, while general models work better for simpler tasks like summarization, translation, and basic Q&A.
Third is the actual strength of DeepSeek.
Based on authoritative rankings and expert opinions, DingjiaoOne ranked DeepSeek within both reasoning and general-purpose model categories.
The first-tier reasoning models include four: OpenAI's o-series (e.g., o3-mini), Google's Gemini 2.0, DeepSeek-R1, and Alibaba's QwQ.
Multiple experts believe that although DeepSeek-R1 is widely discussed as China's top model rivaling OpenAI, technically it still lags behind OpenAI's latest o3.
Its greater significance lies in drastically narrowing the gap between domestic and international top-tier levels. "If the previous gap was 2–3 generations, DeepSeek-R1 has narrowed it to just half a generation," said Jiang Shu, an experienced AI industry practitioner.
Based on personal experience, he outlined the strengths and weaknesses of each:
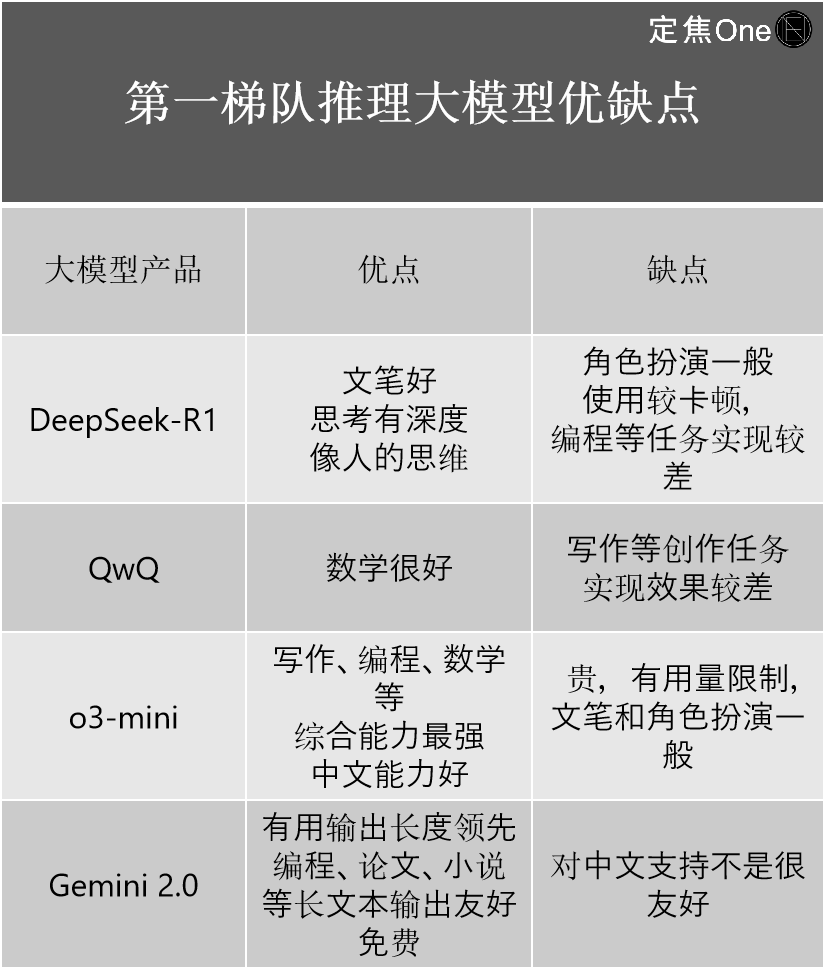
In the general-purpose model category, according to the LM Arena (an open-source platform for evaluating LLM performance), five lead the first tier: Google's Gemini (closed-source), OpenAI's ChatGPT, Anthropic's Claude, DeepSeek, and Alibaba's Qwen.
Jiang Shu shared his user experience with them:
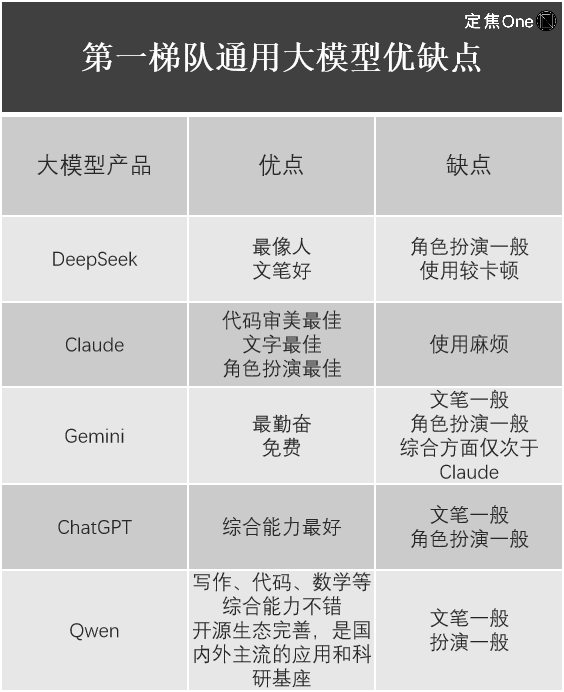
Clearly, despite DeepSeek-R1 stunning the global tech community and proving its undeniable value, every large model has trade-offs—DeepSeek isn't flawless across the board. For instance, Liu Cong found that Janus-Pro, DeepSeek’s latest multimodal model focused on image understanding and generation, delivered mediocre results.
How Much Does It Cost to Train a Large Model?
Returning to the cost issue: how exactly is a large model born?
Liu Cong explained that large model development mainly involves two stages: pre-training and post-training. If we compare a large model to a child, pre-training and post-training transform the child from crying at birth to understanding adult speech, and eventually speaking independently.
Pre-training primarily involves training data. For example, feeding vast text corpora to the model enables knowledge acquisition—but at this stage, the child knows facts without knowing how to apply them.
Post-training teaches the child how to use that knowledge, involving two methods: Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF).
Liu Cong emphasized that whether general or reasoning models, domestic or foreign, all follow this same process. Jiang Shu added that all companies use Transformer-based models, meaning there is no fundamental difference in core architecture and training steps.
Multiple practitioners noted significant differences in training costs, concentrated in three areas: hardware, data, and labor. Each component allows various approaches, leading to differing costs.
Liu Cong gave examples: buying vs. renting hardware leads to vastly different pricing. Buying requires high upfront investment but lowers long-term costs (mainly electricity), whereas renting avoids initial burden but incurs ongoing expenses. Similarly, using purchased data versus self-collected (e.g., web crawling) data differs greatly. Training costs vary per iteration—initial efforts involve writing crawlers and filtering data, while subsequent versions reuse prior work, reducing costs. The number of iterations before final deployment also affects total cost, though companies rarely disclose this.
In short, every stage involves substantial hidden costs.
External estimates based on GPU usage suggest GPT-4 cost ~$78 million, Llama3.1 over $60 million, and Claude3.5 about $100 million. But since these top models are closed-source, and inefficiencies in compute usage remain unknown, accurate figures were elusive—until DeepSeek reported $5.576 million for a comparable model.

Image source / Unsplash
Note: $5.576 million refers to the training cost of base model DeepSeek-V3 as stated in DeepSeek’s technical report. "This figure represents only the final successful training run; it excludes earlier research, architectural experimentation, and algorithmic trial-and-error," said Liu Cong. In other words, $5.576 million is just a small fraction of the total model cost.
SemiAnalysis, a semiconductor market analysis firm, estimated that factoring in server capital expenditure and operational costs, DeepSeek’s total cost could reach $2.573 billion over four years.
Industry insiders agree that even at $2.573 billion, DeepSeek’s cost remains low compared to other companies’ investments of tens of billions.
Moreover, DeepSeek-V3 required only 2,048 NVIDIA GPUs and 2.788 million GPU hours—compared to OpenAI’s tens of thousands of GPUs and Meta’s 30.84 million GPU hours for Llama-3.1-405B.
DeepSeek achieves higher efficiency not only during training but also in inference, resulting in lower operational costs.
Differences in API pricing reflect this cost advantage. Developers use APIs to access large models for text generation, dialogue, code generation, etc. Generally, high development costs necessitate higher API prices to recoup investment.
DeepSeek-R1’s API pricing: ¥1 per million input tokens (cache hit), ¥16 per million output tokens. In contrast, OpenAI’s o3-mini charges $0.55 (~¥4) per million input tokens and $4.4 (~¥31) per million output tokens.
Cache hit means retrieving data from cache instead of recomputing or regenerating via the model, reducing processing time and cost. By distinguishing cache hit vs. miss, the industry enhances API competitiveness. Lower prices make adoption easier for SMEs.
Recently ended discounts for DeepSeek-V3 raised prices from ¥0.1 per million input tokens and ¥2 per million output tokens (both cache hit) to ¥0.5 and ¥8 respectively—still below mainstream models.
While total training cost remains hard to pin down, industry consensus holds that DeepSeek likely represents the lowest cost among current top-tier large models, setting a benchmark others will aim to beat.
DeepSeek’s Cost-Reduction Insights
Where did DeepSeek save money? According to practitioners, optimizations occurred at every level: model architecture, pre-training, and post-training.
For professional responses, many large model companies use MoE (Mixture of Experts), splitting complex problems into subtasks assigned to different experts. While many mention MoE, DeepSeek achieved ultimate expert specialization.
The secret lies in fine-grained expert partitioning (further subdividing experts within categories) and shared expert isolation (isolating some experts to reduce knowledge redundancy). Benefits include significantly improved MoE parameter efficiency and performance, enabling faster, more accurate responses.
One practitioner estimated DeepSeekMoE achieves similar performance to LLaMA2-7B with only about 40% of the compute.
Data processing is another hurdle. Companies strive to boost computational efficiency while lowering memory and bandwidth demands. DeepSeek adopted FP8 low-precision training during data processing—a technique accelerating deep learning training. "This approach is relatively advanced among known open-source models, as most use FP16 or BF16 mixed-precision training. FP8 offers much faster training speed," said Liu Cong.
In post-training reinforcement learning, policy optimization is a major challenge—essentially teaching the model better decision-making. For example, AlphaGo used policy optimization to learn optimal moves in Go.
DeepSeek chose GRPO (Group Relative Policy Optimization) instead of PPO (Proximal Policy Optimization). The key difference lies in whether a value model is used during optimization: GRPO estimates advantage functions via intra-group relative rewards, while PPO relies on a separate value model. Eliminating one model reduces compute requirements and saves costs.
At the inference layer, DeepSeek uses Multi-head Latent Attention (MLA) instead of traditional Multi-head Attention (MHA), significantly reducing VRAM usage and computational complexity—directly lowering API costs.
However, DeepSeek’s biggest revelation for Liu Cong was that strong reasoning capabilities can emerge from multiple directions: pure supervised fine-tuning (SFT) and pure reinforcement learning (RLHF) can both yield excellent reasoning models.
Image source / Pexels
In other words, today there are four viable paths to build reasoning models:
Method 1: Pure reinforcement learning (DeepSeek-R1-zero)
Method 2: SFT + reinforcement learning (DeepSeek-R1)
Method 3: Pure SFT (DeepSeek distilled models)
Method 4: Pure prompting (low-cost small models)
"Previously, the industry assumed SFT + RLHF was necessary. No one expected pure SFT or pure RLHF alone could achieve such strong results," said Liu Cong.
DeepSeek’s cost reduction not only provides technical inspiration but also influences AI company strategies.
Wang Sheng, partner at INNO Angel Fund, noted that AI companies pursuing AGI typically follow two paths: one follows the "compute arms race" paradigm—stacking technology, money, and compute to maximize model performance before considering commercialization; the other follows the "algorithm efficiency" paradigm—aiming from the start for practical deployment through architectural innovation and engineering excellence, delivering low-cost, high-performance models.
"DeepSeek’s series of models proves that when performance ceilings plateau, focusing on efficiency optimization rather than raw capability growth is viable," said Wang Sheng.
Practitioners believe algorithmic advances will continue to drive down large model training costs.
Cathie Wood, founder and CEO of ARK Invest, pointed out that before DeepSeek, AI training costs declined 75% annually, and inference costs dropped 85–90%. Wang Sheng added that re-releasing a model at year-end often cuts costs dramatically—potentially to just 1/10th of the original.
Independent research firm SemiAnalysis recently stated in a report that declining inference costs are a hallmark of AI progress. Performance once requiring supercomputers and multiple GPUs, like GPT-3, can now be matched by small models running on laptops—at a fraction of the cost. Dario Amodei, CEO of Anthropic, believes algorithmic improvements have already reduced costs equivalent to GPT-3 quality by 1,200-fold.
Going forward, large model cost reductions will accelerate even further.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














