

Uncovering DeepSeek: Why Does DeepSeek Favor Young People Without Work Experience?
TechFlow Selected TechFlow Selected
Uncovering DeepSeek: Why Does DeepSeek Favor Young People Without Work Experience?
Without work experience, how does DeepSeek select candidates? The answer is: by potential.
Author: Sam Gao, Author of ElizaOS
0. Preface
Recently, the successive emergence of DeepSeek V3 and R1 has triggered FOMO among American AI researchers, entrepreneurs, and investors. This wave of excitement is comparable to the debut of ChatGPT at the end of 2022.

Thanks to DeepSeek R1’s complete open-sourcing (free model download on HuggingFace for local inference) and extremely low cost (just 1/100th the price of OpenAI's o1), DeepSeek climbed to the top of the US Apple App Store within just five days.
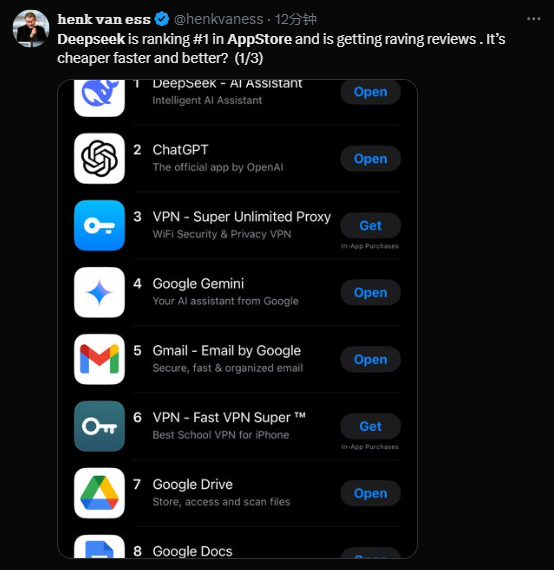
So, where exactly does this mysterious new AI force—spawned by a Chinese quantitative firm—come from?
1. The Origins of DeepSeek
I first heard about DeepSeek back in 2021. At the time, while working at DAMO Academy, I learned that Luo Fuli—a brilliant young researcher from Peking University who had published eight papers at ACL (the top NLP conference) in a single year—had left to join High-Flyer Quant. Everyone was curious: Why would a highly profitable quant firm hire AI talent? Did High-Flyer need to publish academic papers?
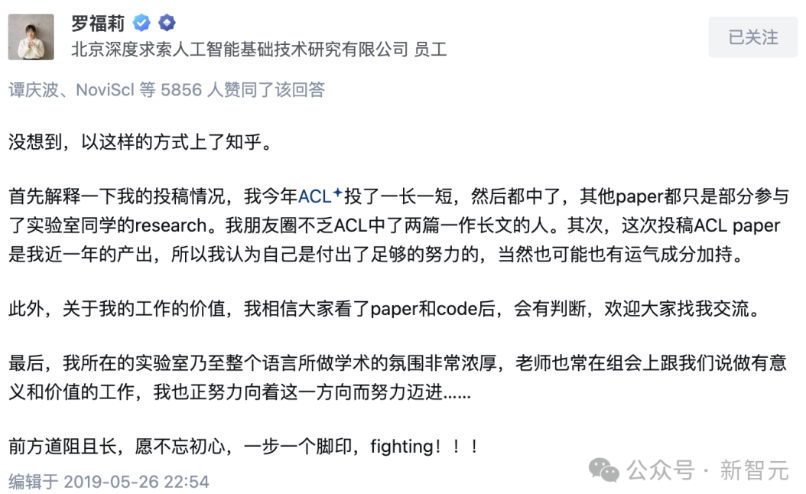
From what I knew then, AI researchers hired by High-Flyer were largely working independently, exploring cutting-edge directions, with large language models (LLMs) and text-to-image models (like OpenAI’s DALL-E at the time) being the most central areas.
By the end of 2022, High-Flyer began attracting more and more top-tier AI talent—mostly current students from Tsinghua and Peking Universities. Inspired by ChatGPT, Liang Wenfeng, High-Flyer’s CEO with years of AI experience, made the decisive move into general artificial intelligence: "We’ve set up a new company, starting with language large models, and later expanding into vision and other areas."
Yes, that company was DeepSeek. In early 2023, as the "Six Little Dragons" (Zhipu, Moonshot, Baichuan, etc.) took center stage amid the bustling tech hubs of Zhongguancun and Wudaokou, DeepSeek remained relatively under the radar, overshadowed by companies flush with capital and attention.
Thus, in 2023, as a pure research-focused entity without celebrity founders (such as Kai-Fu Lee’s 01.ai, Yang Zhiyun’s Moonshot, or Wang Xiaochuan’s Baichuan), DeepSeek struggled to raise funds independently. As a result, High-Flyer decided to spin off DeepSeek and fully fund its development. In that overheated investment climate of 2023, no VC was willing to back DeepSeek—first because most of its team consisted of recent PhD graduates without globally recognized senior researchers; second, because there was no clear path to exit.
Amid noise and frenzy, DeepSeek quietly began writing its own chapters in AI exploration:
-
November 2023: DeepSeek launched DeepSeek LLM, a 67-billion-parameter model performing close to GPT-4.
-
May 2024: DeepSeek-V2 officially launched.
-
December 2024: DeepSeek-V3 released, outperforming Llama 3.1 and Qwen 2.5 in benchmarks, and matching GPT-4o and Claude 3.5 Sonnet—igniting widespread industry attention.
-
January 2025: DeepSeek-R1, the first generation reasoning-capable LLM, was launched. With performance rivaling OpenAI’s o1 at less than 1/100th the cost, it sent shockwaves across the global tech community. The world truly realized: Chinese innovation has arrived... Open source always wins!
2. Talent Strategy
I’ve known several DeepSeek researchers early on, mainly those working in AIGC—such as the authors behind Janus (released November 2024) and DreamCraft3D. One of them even helped optimize my latest paper @xingchaoliu.

From my observations, these researchers are remarkably young—mostly current PhD students or those with fewer than three years since graduation.


Most are graduate or doctoral students based in Beijing, with strong academic credentials—typically having published 3–5 top-tier conference papers.
I asked a friend at DeepSeek why Liang Wenfeng only recruits young people.
They shared Liang Wenfeng’s words directly:
The mystery surrounding DeepSeek’s team has sparked curiosity: What is their secret weapon? Foreign media say it’s “young geniuses” capable of competing with well-funded American giants.
In the AI industry, hiring seasoned veterans is the norm. Many Chinese AI startups prefer senior researchers or those with overseas PhDs. Yet DeepSeek takes the opposite approach, favoring young talent without extensive work experience.
A recruiter who worked with DeepSeek revealed they don’t hire senior technical staff: “Three to five years of experience is already the maximum. Anyone with over eight years is basically out.” In a May 2023 interview with 36Kr, Liang Wenfeng confirmed that most DeepSeek developers are either fresh graduates or early-career professionals. He emphasized: "Our core technical roles are mostly filled by fresh graduates or those with one or two years of experience."
If they lack work history, how does DeepSeek select talent? The answer: potential.
Liang Wenfeng once said, “When doing something long-term, experience isn’t that important. Foundational ability, creativity, and passion matter far more.” He believes that perhaps the world’s top 50 AI talents aren’t yet in China, but “we can cultivate such people ourselves.”
This strategy reminds me of OpenAI’s early days. When OpenAI was founded in late 2015, Sam Altman’s core idea was to recruit ambitious young researchers. Thus, aside from President Greg Brockman and Chief Scientist Ilya Sutskever, the other four founding technical members (Andrew Karpathy, Durk Kingma, John Schulman, Wojciech Zaremba) were all recent PhD graduates—from Stanford, University of Amsterdam, UC Berkeley, and NYU respectively.

From left to right: Ilya Sutskever (former Chief Scientist), Greg Brockman (former President), Andrej Karpathy (former Technical Lead), Durk Kingma (former Researcher), John Schulman (former RL Team Lead), and Wojciech Zaremba (current Technical Lead)
This “young wolf strategy” paid off for OpenAI, nurturing figures like GPT’s co-creator Alec Radford (a graduate of a non-top-tier university), DALL-E’s creator Aditya Ramesh (an NYU undergraduate), and Prafulla Dhariwal, three-time Olympiad gold medalist and multimodal lead for GPT-4o. Through the fearless energy of youth, OpenAI carved out a path from obscurity beside DeepMind to becoming a dominant force.
Liang Wenfeng, inspired by Sam Altman’s success, firmly chose this path. But unlike OpenAI, which waited seven years before ChatGPT emerged, Liang Wenfeng saw results in just over two years—an example of China’s speed.
3. Speaking Up for DeepSeek
The performance metrics reported in DeepSeek R1’s release are astonishing—but have also raised skepticism. Two main concerns:
-
① Its use of Mixture-of-Experts (MoE) technology demands high training complexity and data requirements, leading some to suspect DeepSeek may have used OpenAI’s data for training.
-
② DeepSeek employed reinforcement learning (RL) techniques requiring significant hardware, yet trained using only 2,048 H800 GPUs—far fewer than Meta or OpenAI’s ten-thousand-GPU clusters.
Given computational constraints and MoE complexity, the claim that DeepSeek R1 succeeded in one go with only $5 million seems questionable. Yet whether you revere it as a “low-cost miracle” or question its “substance versus spectacle,” its functional innovations remain dazzling.
Arthur Hayes, co-founder of BitMEX, commented: “Will DeepSeek’s rise cause global investors to question American exceptionalism? Are U.S. assets severely overvalued?”
Stanford professor Andrew Ng publicly stated at this year’s Davos Forum: “I’m very impressed by DeepSeek’s progress. I think they’ve managed to train models in an extremely cost-effective way. Their latest reasoning model is outstanding… ‘Keep going!’”
Marc Andreessen, founder of a16z, stated: “Deepseek R1 is one of the most astonishing, impressive breakthroughs I’ve ever seen—and as an open-source project, it’s a profound gift to the world.”
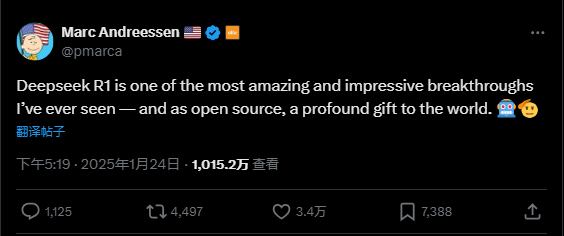
In 2023, DeepSeek stood quietly in the shadows. By early 2025, just before Lunar New Year, it stood atop the global AI stage.
4. Argo and DeepSeek
As a developer of Argo and an AIGC researcher, I’ve integrated key Argo functionalities with DeepSeek. As a workflow system, Argo now uses DeepSeek R1 to generate raw workflows. Additionally, Argo has embedded DeepSeek R1 as its default LLM, choosing to abandon expensive closed-source models like OpenAI’s. The reason: workflow systems typically consume massive tokens and context (average ≥10k tokens). Using costly models like OpenAI or Claude 3.5 would make execution prohibitively expensive. Before Web3 users achieve real value capture, such premature spending harms product sustainability.
As DeepSeek continues to improve, Argo will deepen collaboration with DeepSeek and other rising Chinese AI forces—including, but not limited to, localization of Text-to-Image/Video APIs and broader LLM adoption.
In terms of collaboration, Argo plans to invite DeepSeek researchers to share technical insights and offer grants to top AI researchers, helping Web3 investors and users better understand AI advancements.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














