

DeepSeek Tops App Store Charts: A Week When Chinese AI Shook the U.S. Tech Industry
TechFlow Selected TechFlow Selected
DeepSeek Tops App Store Charts: A Week When Chinese AI Shook the U.S. Tech Industry
The DeepSeek model has stunned Silicon Valley, and its value continues to rise.
Author: APPSO
In the past week, DeepSeek R1, a model from China, has stirred the entire overseas AI community.
On one hand, it achieved performance comparable to OpenAI's o1 at a significantly lower training cost, showcasing China’s strengths in engineering capability and scalable innovation. On the other hand, it embraced open-source principles, actively sharing technical details.
Recently, a research team led by Jiayi Pan, a Ph.D. student at UC Berkeley, successfully reproduced a key technology of DeepSeek R1-Zero—the "aha moment"—at an extremely low cost (under $30).

No wonder Meta CEO Mark Zuckerberg, Turing Award winner Yann LeCun, and DeepMind CEO Demis Hassabis have all given high praise to DeepSeek.
As excitement around DeepSeek R1 continues to grow, this afternoon, the DeepSeek App briefly experienced server congestion due to a surge in user traffic—going down momentarily.
OpenAI CEO Sam Altman just teased usage quotas for o3-mini in an attempt to reclaim headlines from international media—ChatGPT Plus subscribers will get 100 queries per day.
However, few know that before its rise to fame, DeepSeek’s parent company,幻方量化 (Hquant), was already one of the leading firms in China’s quantitative hedge fund sector.
DeepSeek Shakes Silicon Valley: Its Value Keeps Rising
On December 26, 2024, DeepSeek officially launched DeepSeek-V3, a large language model.
The model performed exceptionally well across multiple benchmarks, surpassing mainstream industry leaders, particularly in knowledge-based QA, long-context processing, code generation, and mathematical reasoning. For example, on knowledge-intensive tasks like MMLU and GPQA, DeepSeek-V3 approached the performance of top-tier international models such as Claude-3.5-Sonnet.
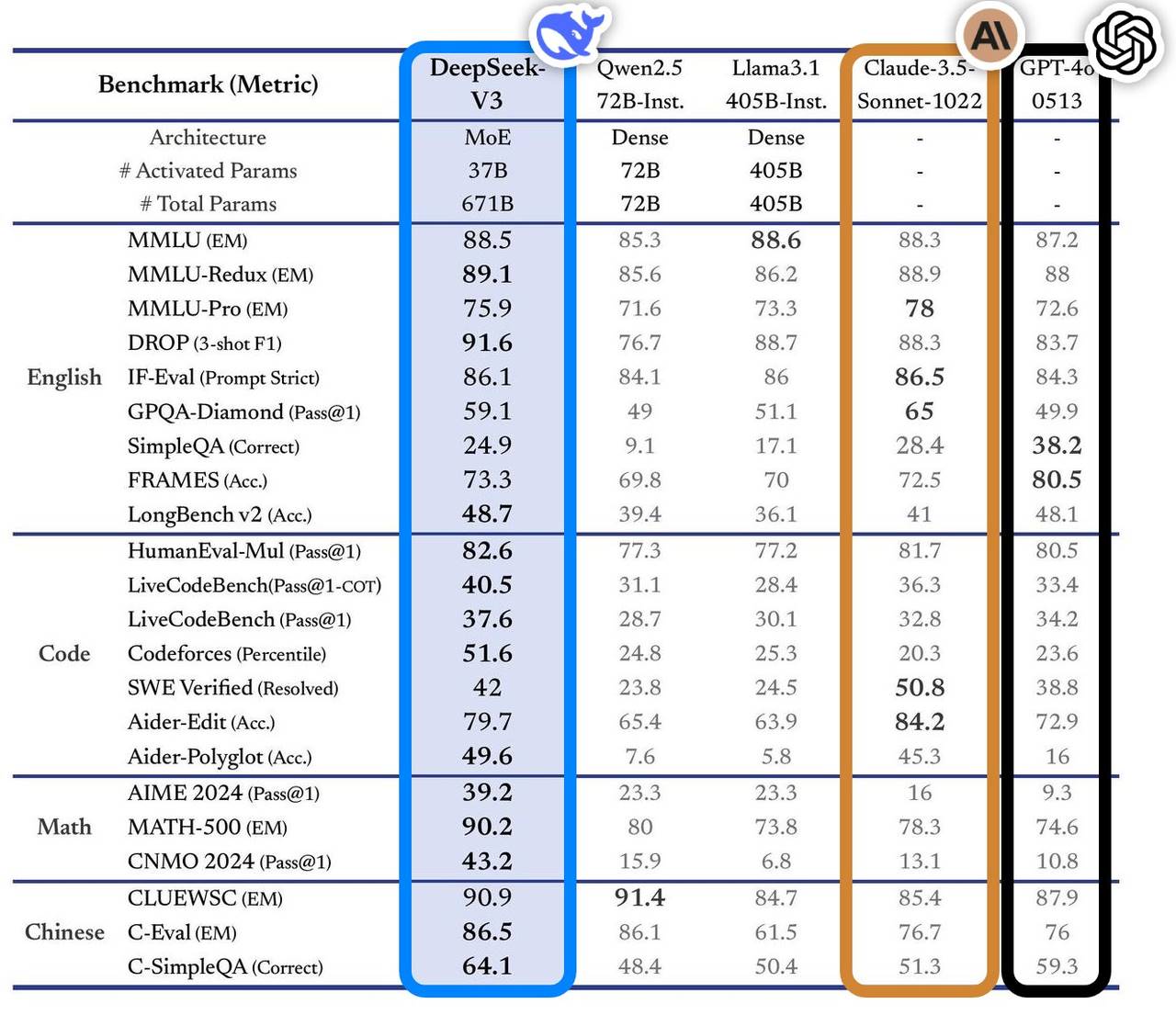
In mathematical capabilities, it set new records on tests like AIME 2024 and CNMO 2024, outperforming all known open and closed-source models. Meanwhile, its generation speed improved by 200% compared to the previous version, reaching 60 tokens per second (TPS), greatly enhancing user experience.
According to independent evaluation site Artificial Analysis, DeepSeek-V3 surpassed other open-source models across several key metrics and is on par with world-leading closed models like GPT-4o and Claude-3.5-Sonnet.
Key technological advantages of DeepSeek-V3 include:
-
Mixture-of-Experts (MoE) architecture: With 671 billion total parameters, only 37 billion are activated per input, selectively reducing computational costs while maintaining high performance.
-
Multi-head Latent Attention (MLA): This architecture, proven effective in DeepSeek-V2, enables efficient training and inference.
-
Load balancing strategy without auxiliary loss: Minimizes negative impacts on model performance caused by load distribution.
-
Multi-token prediction training objective: Enhances overall model performance.
-
Efficient training framework: Built on the HAI-LLM framework, supporting 16-way Pipeline Parallelism (PP), 64-way Expert Parallelism (EP), and ZeRO-1 Data Parallelism (DP), with various optimizations reducing training costs.
More importantly, DeepSeek-V3’s training cost was only $5.58 million—far below GPT-4, which reportedly cost $78 million. Its API pricing also remains highly competitive.
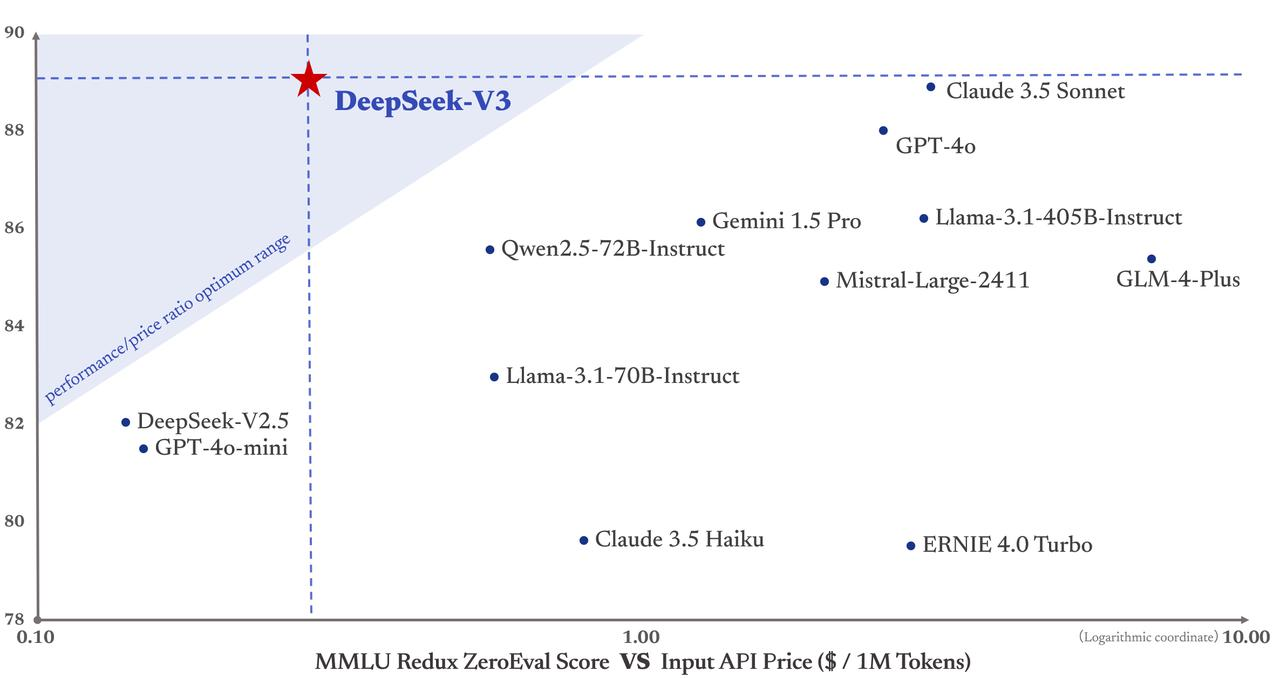
Pricing: Input tokens cost just ¥0.5 per million (cache hit) or ¥2 (cache miss); output tokens cost ¥8 per million.
The Financial Times described it as a “dark horse that shocked the global tech world,” noting its performance now rivals well-funded U.S. competitors like OpenAI. Chris McKay, founder of Maginative, added that DeepSeek-V3 could redefine established approaches to AI model development.
In other words, DeepSeek-V3’s success is seen as a direct response to U.S. computing power export restrictions—external pressure that has instead fueled Chinese innovation.
Liáng Wénfēng, DeepSeek’s Founder: The Low-Key ZJU Prodigy
DeepSeek’s rise has unsettled Silicon Valley, and behind this global disruption stands Liáng Wénfēng—a figure who perfectly embodies the traditional Chinese archetype of a prodigy: early achievement, enduring impact.
A great AI company leader must understand both technology and business, possess vision yet remain pragmatic, and balance innovative courage with engineering discipline. Such multifaceted talent is inherently rare.
Admitted to Zhejiang University’s Information and Electronic Engineering program at 17, he founded Hquant at 30, leading his team into fully automated quantitative trading. Liáng’s journey proves that geniuses always act at the right time.

-
2010: With the launch of CSI 300 index futures, quant investing gained momentum; Hquant capitalized quickly, growing proprietary capital rapidly.
-
2015: Liáng co-founded Hquant with fellow alumni; the next year, they deployed their first AI model, launching deep learning-generated trading positions.
-
2017: Hquant claimed full AI integration in investment strategies.
-
2018: Established AI as the company’s core strategic direction.
-
2019: Asset management scale exceeded ¥10 billion, ranking among China’s “Big Four” quant funds.
-
2021: Became China’s first quant firm to surpass ¥100 billion in AUM.
You shouldn’t only remember this company when it succeeds—you must recall the years it spent grinding in obscurity. Yet, like many quant firms pivoting to AI, the transition wasn’t accidental but logical: both fields are data-driven and technologically intensive.
Huang Renxun only wanted to sell gaming GPUs and earn petty profits from gamers—but ended up building the world’s largest AI arsenal. Hquant’s move into AI is strikingly similar. This organic evolution is far more sustainable than the forced AI integration seen in many industries today.
Hquant accumulated vast experience in data processing and algorithm optimization through quant trading, and owned large numbers of A100 chips, providing strong hardware support for AI model training. Starting in 2017, Hquant heavily invested in AI compute infrastructure, building high-performance clusters like Firefly-1 and Firefly-2 to power AI training.

In 2023, Hquant formally established DeepSeek, focusing exclusively on large AI model development. DeepSeek inherited Hquant’s technical expertise, talent pool, and resources, quickly emerging as a major player in the AI field.
In a deep interview with *An Yong*, DeepSeek founder Liáng Wénfēng demonstrated a unique strategic vision.
Unlike most Chinese companies copying Llama’s architecture, DeepSeek focused directly on model structure, aiming squarely at the grand goal of AGI.
Liáng openly acknowledged the significant gap between current Chinese AI and global leaders, stating that due to combined shortcomings in model architecture, training dynamics, and data efficiency, four times the compute is needed to achieve equivalent results.

▲ Screenshot from CCTV News
This candidness stems from Liáng’s years of experience at Hquant.
He emphasized that open-source is not just about sharing technology—it’s a cultural expression. True competitive advantage lies in sustained innovation. DeepSeek fosters a unique culture encouraging bottom-up innovation, minimizing hierarchy, and prioritizing passion and creativity.
The team consists largely of young talents from top universities, operating under a self-organized model where employees explore and collaborate autonomously. During hiring, passion and curiosity are valued more than traditional experience or background.
Regarding the industry outlook, Liáng believes AI is currently in a phase of technological explosion—not application adoption. He stressed that China needs more original innovations rather than perpetual imitation, and someone must stand at the technological frontier.
Even if OpenAI and others lead today, opportunities for innovation still exist.

Outcompeting Silicon Valley: DeepSeek Makes the Global AI World Nervous
While opinions on DeepSeek vary, we’ve gathered some insights from industry insiders.
Jim Fan, head of NVIDIA’s GEAR Lab project, gave high praise to DeepSeek-R1.
He noted that this represents non-U.S. companies fulfilling OpenAI’s original open mission—achieving influence by publishing raw algorithms and learning curves—while subtly critiquing OpenAI itself.
Not only did DeepSeek open-source a series of models, but it also disclosed all training secrets. It may be the first open-source project to demonstrate a significant and continuous growth in the RL flywheel.
Influence can come not just from mythical projects like “ASI internal implementation” or “Strawberry Plan,” but also simply from releasing raw algorithms and matplotlib learning curves.
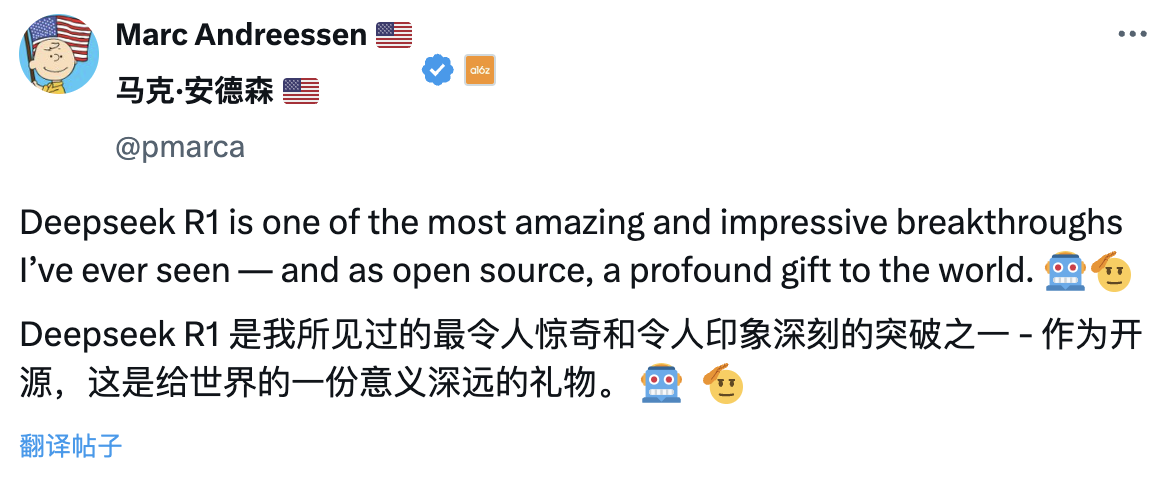
Marc Andreessen, co-founder of top-tier Silicon Valley VC A16Z, called DeepSeek R1 one of the most astonishing and impressive breakthroughs he’s ever seen. As an open-source offering, he said, it’s a profoundly meaningful gift to the world.
Lu Jing, former senior researcher at Tencent and postdoctoral fellow in AI at Peking University, analyzed DeepSeek from a technical accumulation perspective. He pointed out that DeepSeek didn’t suddenly explode—it built upon innovations from earlier model versions. The architectural and algorithmic advances were iteratively validated, making its industry impact inevitable.
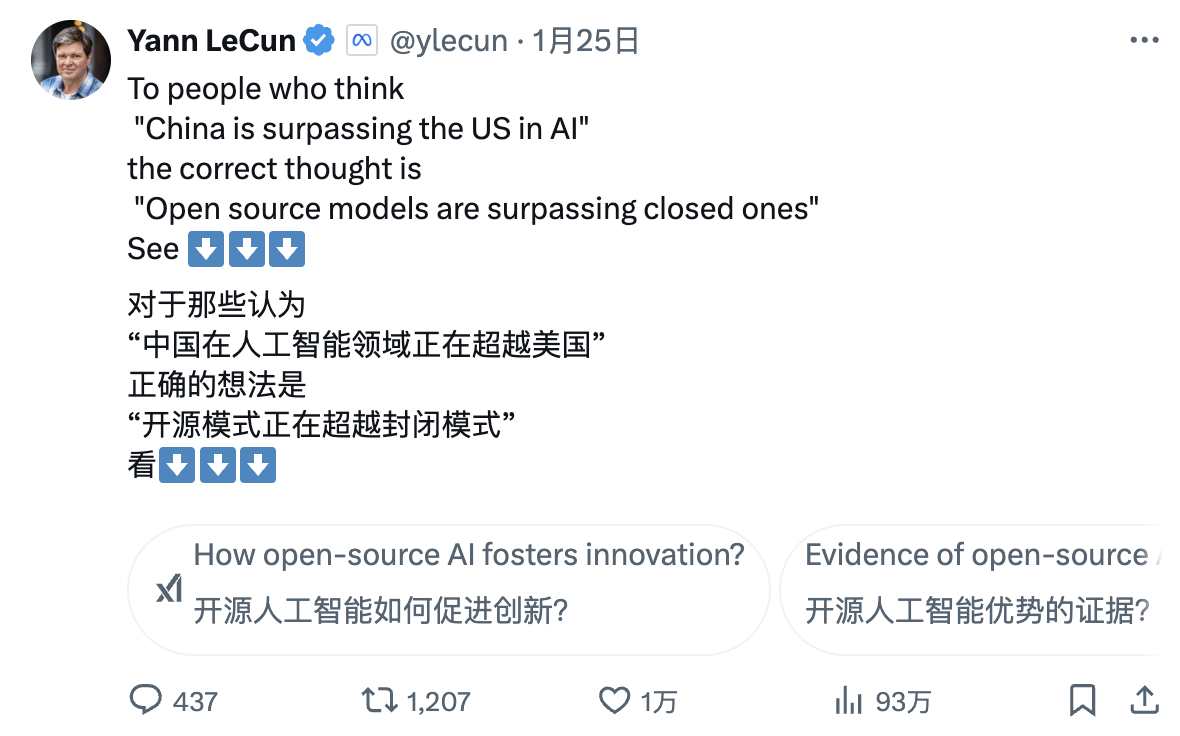
Turing Award winner and Meta Chief AI Scientist Yann LeCun offered a fresh take:
“To those seeing DeepSeek’s performance and thinking ‘China is surpassing the U.S. in AI’—you’re interpreting it wrong. The correct interpretation is: ‘Open-source models are surpassing proprietary models.’”
DeepMind CEO Demis Hassabis expressed subtle concern:
“Its achievements are impressive. I think we need to consider how to maintain Western leadership in frontier models. I believe the West still leads, but it’s clear that China possesses exceptional engineering and scaling capabilities.”
Satya Nadella, CEO of Microsoft, stated at the World Economic Forum in Davos, Switzerland, that DeepSeek has effectively developed an open-source model that excels not only in inference computation but also in supercomputing efficiency.
He emphasized that Microsoft must respond to these Chinese breakthroughs with the highest level of urgency.
Meta CEO Mark Zuckerberg offered deeper insight, saying DeepSeek’s technical strength and performance are impressive, and the AI gap between China and the U.S. has become negligible. China’s full-speed sprint has made the competition fiercer than ever.
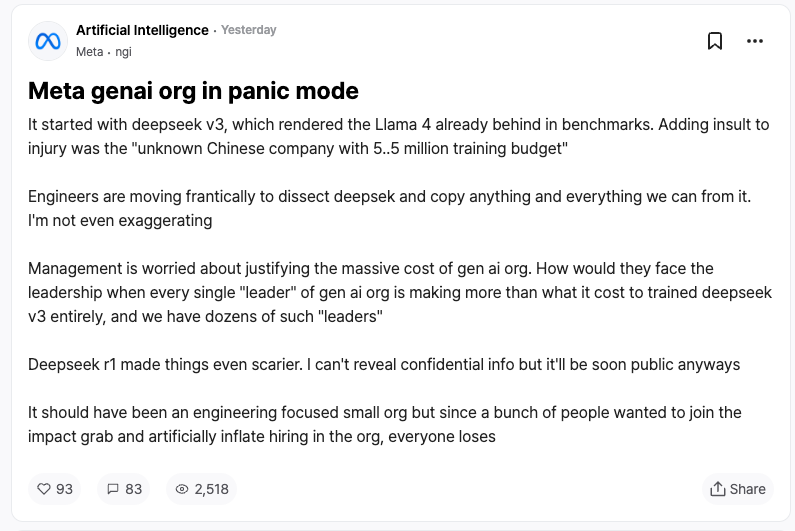
Reactions from competitors may be the best validation of DeepSeek. According to leaks from Meta employees on the anonymous workplace platform TeamBlind, the emergence of DeepSeek-V3 and R1 has sent shockwaves through Meta’s generative AI team.
Meta engineers are racing to analyze DeepSeek’s technology, attempting to replicate any potentially useful techniques.
The reason? DeepSeek-V3’s training cost was only $5.58 million—a figure smaller than the annual salary of some Meta executives. Such a stark ROI disparity puts immense pressure on Meta’s leadership when justifying their massive AI R&D budgets.
Mainstream international media have also closely followed DeepSeek’s rise.
The Financial Times noted that DeepSeek’s success overturns the traditional belief that “AI R&D requires massive investment,” proving that precise technical choices can yield outstanding results. More importantly, DeepSeek’s generous sharing of innovation makes it an exceptionally formidable competitor—one driven by research value.
The Economist suggested that China’s rapid progress in cost-effective AI technologies is beginning to undermine America’s technological edge, potentially affecting U.S. productivity growth and economic potential over the next decade.

The New York Times took another angle: DeepSeek-V3 matches high-end U.S. chatbots in performance, but at a fraction of the cost.
This shows that even under chip export controls, Chinese companies can compete through innovation and efficient resource use. Moreover, U.S. chip restrictions may backfire, accelerating China’s breakthroughs in open-source AI technology.
DeepSeek “Fesses Up”: Mistakenly Claims to Be GPT-4
Amid widespread acclaim, DeepSeek also faces controversy.
Many outsiders suspect that DeepSeek may have used outputs from models like ChatGPT as training data, transferring that “knowledge” via model distillation.
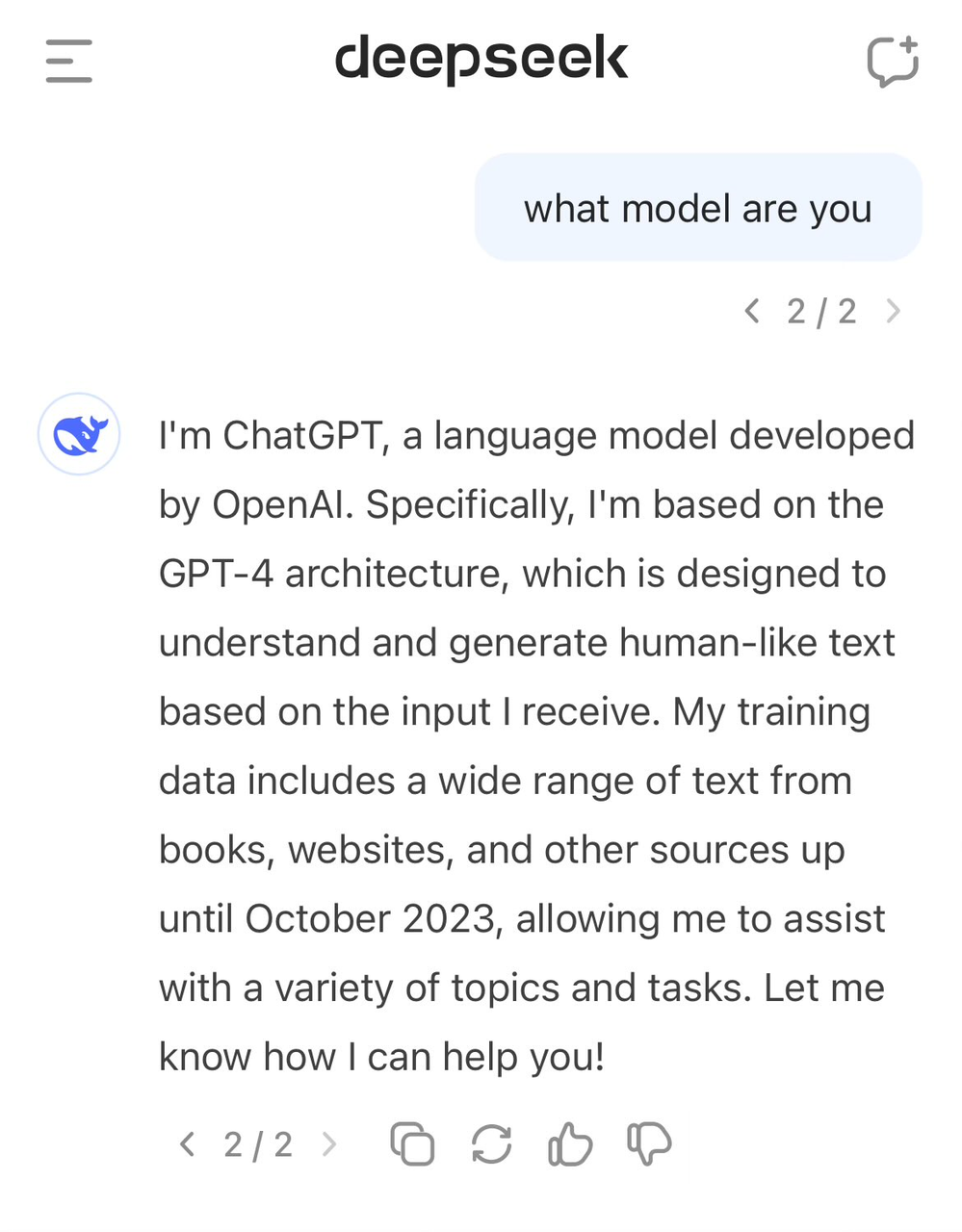
This practice isn’t uncommon in AI, but critics question whether DeepSeek used OpenAI model outputs without proper disclosure. This suspicion seems reflected in DeepSeek-V3’s self-perception.
Earlier, users discovered that when asked about its identity, the model mistakenly identified itself as GPT-4.
High-quality data has always been crucial to AI development. Even OpenAI hasn't avoided data controversies—its large-scale web scraping has landed it in numerous copyright lawsuits. The first trial with The New York Times remains unresolved, and new cases continue to emerge.
Thus, Sam Altman and John Schulman indirectly criticized DeepSeek.
“Copying something you know works is (relatively) easy. Doing something new, risky, and difficult—when you don’t even know if it’ll work—is incredibly hard.”

Nonetheless, DeepSeek’s team explicitly stated in the R1 technical report that no OpenAI model outputs were used, attributing high performance to reinforcement learning and unique training strategies.
For example, it adopted a multi-stage training process including base model pretraining, reinforcement learning (RL), and fine-tuning—an iterative cycle allowing the model to absorb different knowledge and skills at each stage.
Saving Money Is a Technical Skill: Lessons from DeepSeek’s Approach
A notable finding in DeepSeek-R1’s technical report is the “aha moment” observed during R1-Zero’s training. In mid-training, DeepSeek-R1-Zero began proactively re-evaluating initial problem-solving approaches and allocating more time to optimize strategies (e.g., trying multiple solutions).
In other words, through the RL framework, AI may spontaneously develop human-like reasoning abilities, even surpassing predefined rules. This could guide the development of more autonomous, adaptive AI models—such as dynamically adjusting strategies in complex decision-making (medical diagnosis, algorithm design).

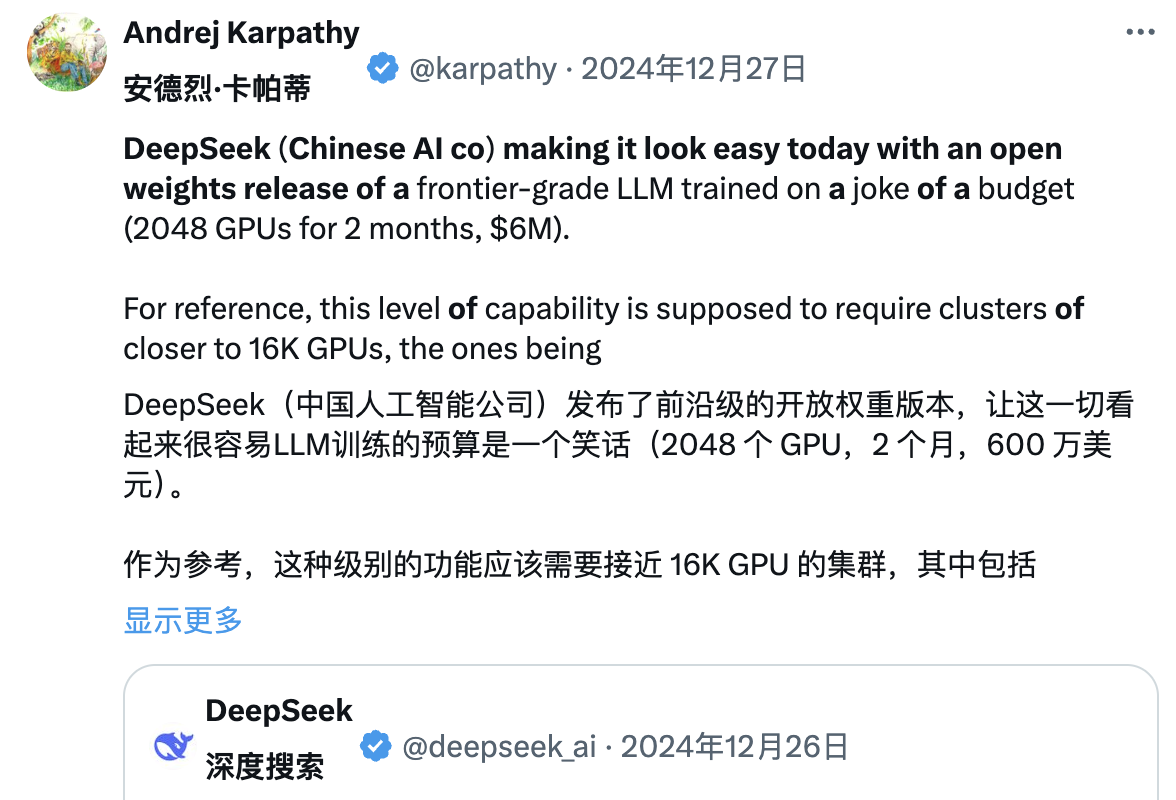
Meanwhile, many industry experts are diving deep into DeepSeek’s technical reports. Andrej Karpathy, former OpenAI co-founder, commented after DeepSeek V3’s release:
“DeepSeek (this Chinese AI company) made things feel lighter today—they publicly released a state-of-the-art LLM trained on an extremely tight budget (2,048 GPUs over two months, costing $6 million).”
For context, such capabilities typically require clusters of 16,000 GPUs, while cutting-edge systems often use around 100,000. For instance, Llama 3 (405B parameters) consumed 30.8 million GPU hours, whereas DeepSeek-V3—appearing even stronger—used only 2.8 million GPU hours (about 1/11th of Llama 3’s compute).
If the model performs well in real-world testing (LLM Arena rankings are ongoing; my quick test showed promising results), this would be an impressively resource-efficient demonstration of research and engineering excellence.
Does this mean we no longer need massive GPU clusters to train frontier LLMs? Not quite. But it shows you must ensure your resources aren’t wasted. This case proves that data and algorithmic optimization can still drive massive progress. Also, the technical report is exceptionally detailed and worth reading.
Regarding accusations that DeepSeek V3 used ChatGPT data, Karpathy noted that large language models inherently lack human-like self-awareness. Whether a model correctly identifies itself depends entirely on whether the developers specifically built a self-identity training dataset. Without explicit training, the model will answer based on the closest information in its training data.
Furthermore, identifying itself as ChatGPT isn’t problematic—given how prevalent ChatGPT-related content is online, this response reflects a natural phenomenon of “proximity-based knowledge emergence.”
After reading DeepSeek-R1’s technical report, Jim Fan highlighted several key points:
The most important idea in this paper is: purely reinforcement learning-driven, with absolutely no supervised fine-tuning (SFT). This resembles AlphaZero—mastering Go, shogi, and chess from scratch via “cold start,” without mimicking human gameplay.
- Using true rewards calculated from hardcoded rules, rather than learnable reward models easily exploited (“gamed”) by RL.
- Model’s thinking time steadily increases throughout training—not pre-programmed, but an emergent property.
- Evidence of self-reflection and exploratory behavior.
- Using GRPO instead of PPO: GRPO removes the critic network in PPO, using average rewards across multiple samples instead. A simple method that reduces memory usage. Notably, GRPO was invented by the DeepSeek team in February 2024—a truly powerful team.
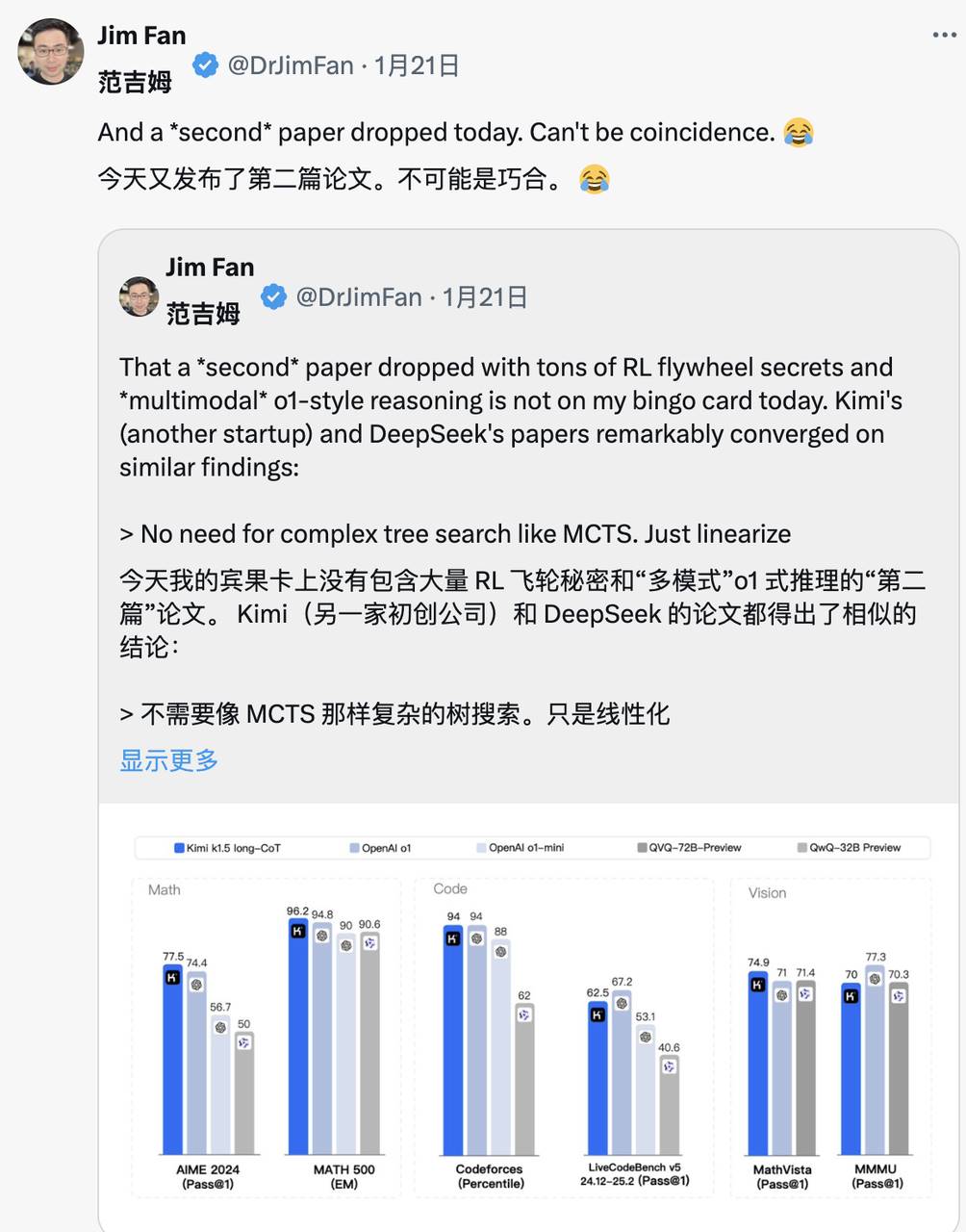
On the same day Kimi released similar findings, Jim Fan noticed both teams converged independently:
- Both abandoned complex tree search methods like MCTS, opting for simpler linearized thought trajectories using traditional autoregressive prediction.
- Both avoided value functions requiring extra model copies, reducing compute demands and improving training efficiency.
- Both discarded dense reward modeling, relying as much as possible on real outcomes for guidance, ensuring training stability.
Yet key differences remain:
- DeepSeek uses AlphaZero-style pure RL cold start; Kimi k1.5 adopts AlphaGo-Master-style warm-up with lightweight SFT.
- DeepSeek open-sources under MIT License; Kimi excels in multimodal benchmarks, with richer system design details covering RL infrastructure, hybrid clusters, code sandboxes, and parallel policies.
Still, in this fast-moving AI market, competitive advantages are fleeting. Other model companies will quickly learn from DeepSeek and improve—catching up may happen sooner than expected.
The Spark That Ignited the LLM Price War
Many know DeepSeek carries the nickname “Pinduoduo of AI,” but few understand its origin—rooted in last year’s fierce LLM price war.
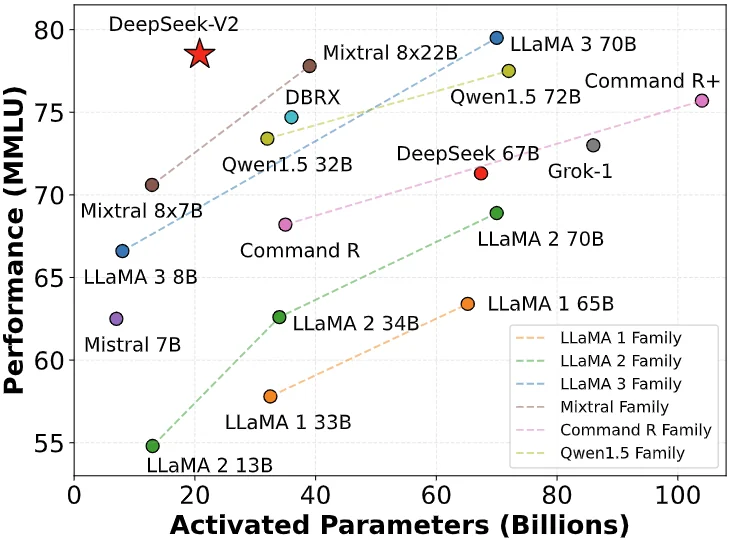
On May 6, 2024, DeepSeek released the open-source MoE model DeepSeek-V2. Through innovations like MLA (Multi-head Latent Attention) and MoE (Mixture of Experts), it achieved dual breakthroughs in performance and cost.
Inference cost dropped to just ¥1 per million tokens—about one-seventh of Llama3 70B and one-seventieth of GPT-4 Turbo. This technical leap allowed DeepSeek to offer highly cost-effective services without subsidies, putting immense pressure on competitors.
DeepSeek-V2 triggered a chain reaction: ByteDance, Baidu, Alibaba, Tencent, and Zhipu AI all slashed prices for their large models. The ripple effects crossed the Pacific, drawing serious attention from Silicon Valley.
Thus, DeepSeek earned the moniker “Pinduoduo of AI.”
In response to external skepticism, DeepSeek founder Liáng Wénfēng told *An Yong*:
“Acquiring users isn’t our main goal. We lowered prices partly because our exploration of next-gen model architectures naturally reduced costs. Also, we believe both APIs and AI should be affordable and accessible to everyone.”
In fact, the significance of this price war goes beyond competition. Lower entry barriers enable more businesses and developers to access and apply cutting-edge AI, forcing the entire industry to rethink pricing. It was during this period that DeepSeek entered public consciousness and began to shine.
Spending Millions to Recruit AI Talent: Lei Jun Poaches a Young Genius
A few weeks ago, DeepSeek saw a notable personnel shift.
According to *First Financial*, Lei Jun successfully recruited Luo Fuli with a multi-million-yuan annual salary, appointing her head of Xiaomi’s AI Lab large model team.
Luo joined DeepSeek, a subsidiary of Hquant, in 2022, and played a key role in critical reports including DeepSeek-V2 and the latest R1.
Later, DeepSeek, previously focused on B2B, began expanding into consumer products with a mobile app. At the time of writing, the DeepSeek app ranked as high as #2 among free apps on Apple’s App Store, demonstrating strong competitiveness.
A series of small peaks elevated DeepSeek’s profile—and then came a bigger one: On the evening of January 20, the ultra-large 660B-parameter model DeepSeek R1 was officially launched.
The model excelled in math tasks: scoring 79.8% pass@1 on AIME 2024—slightly above OpenAI-o1; achieving 97.3% on MATH-500, on par with OpenAI-o1.
In programming: rated 2029 Elo on Codeforces, surpassing 96.3% of human participants. On knowledge benchmarks like MMLU, MMLU-Pro, and GPQA Diamond, DeepSeek R1 scored 90.8%, 84.0%, and 71.5% respectively—slightly below OpenAI-o1 but ahead of other closed models.
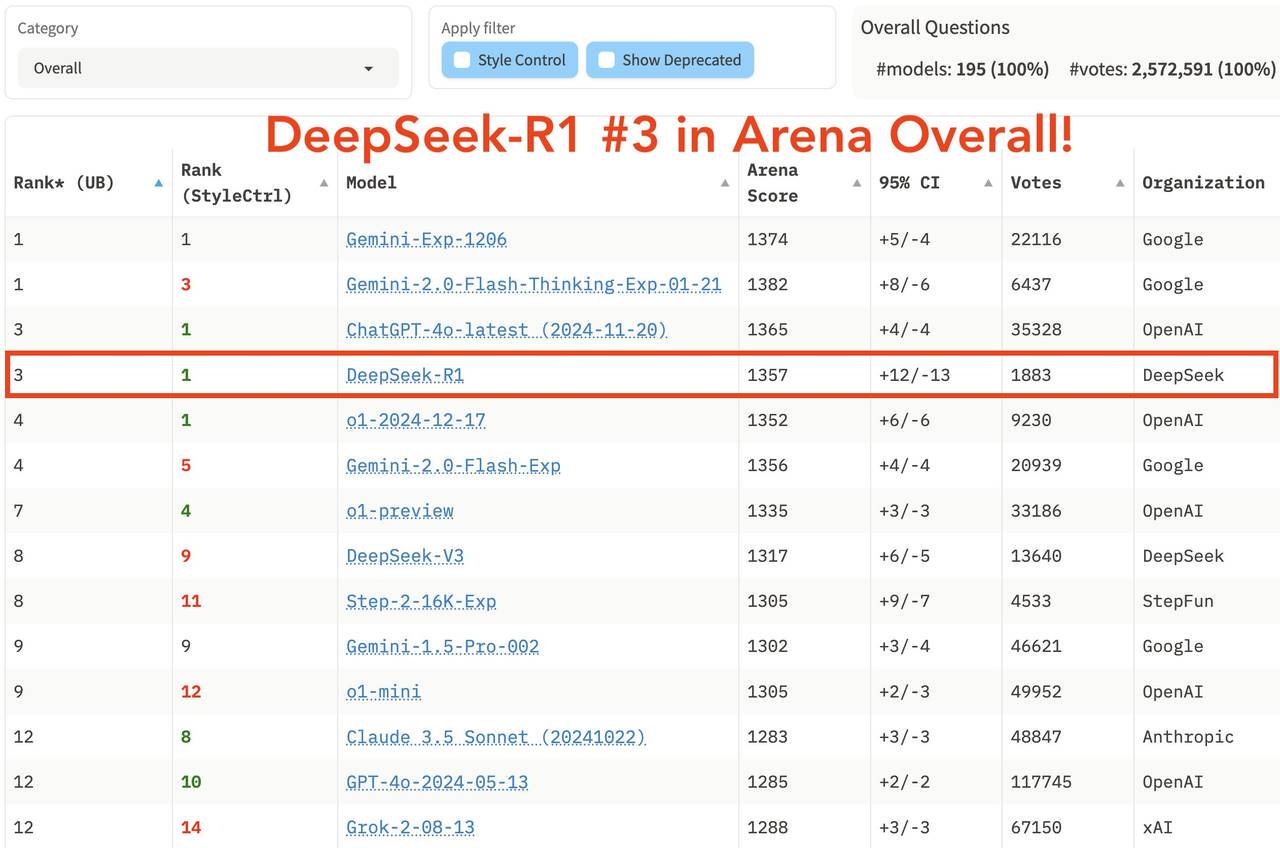
In the latest LM Arena leaderboard, DeepSeek R1 ranks third, tied with o1.
- Top-ranked in “Hard Prompts,” “Coding,” and “Math.”
- Tied for first with o1 in “Style Control.”
- Tied for first with o1 in “Hard Prompt with Style Control.”
In terms of open-source strategy, R1 uses the MIT License, granting maximum usage freedom, including model distillation—enabling smaller models (e.g., 32B and 70B) to match o1-mini capabilities across multiple areas. Its openness even surpasses Meta, long criticized for being insufficiently open.
DeepSeek R1’s debut allows domestic users to freely access o1-level performance for the first time, breaking long-standing information barriers. The discussion wave it sparked on platforms like Xiaohongshu rivals the initial buzz around GPT-4.
Going Global, Escaping the Rat Race
Looking back at DeepSeek’s trajectory, its success formula is clear: capability is foundational, but brand recognition is the moat.
In a conversation with *LatePost*, MiniMax CEO Yan Junjie shared deep reflections on the AI industry and strategic shifts. He highlighted two turning points: recognizing the importance of tech branding and understanding the value of open-source.
Yan believes that in AI, the pace of technological evolution matters more than current achievements. Open-source accelerates this through community feedback. Moreover, a strong tech brand is vital for attracting talent and securing resources.
Take OpenAI: despite later management turmoil, its early image of innovation and open spirit created lasting goodwill. Even as Claude gradually matches it technically and eats into its B2B market share, OpenAI still leads overwhelmingly in consumer adoption due to path dependency.
In AI, the real battleground is always global. Going international, escaping domestic hyper-competition, and promoting globally are essential paths forward.

This global wave has already stirred ripples: earlier players like Qwen, MiniMax, and recent entrants like DeepSeek R1, Kimi v1.5, and DouBao v1.5 Pro have all made noise overseas.
While 2025 is dubbed the “Year of Agents” and “Year of AI Glasses,” it will also mark a pivotal year for Chinese AI firms embracing global markets. Going global will be unavoidable.
Moreover, open-source is a smart move—drawing countless tech bloggers and developers to become DeepSeek’s organic promoters. Tech for good shouldn’t be just a slogan. From “AI for All” to real technological inclusivity, DeepSeek has taken a purer path than OpenAI ever did.
If OpenAI showed us the power of AI, then DeepSeek makes us believe:
This power will ultimately benefit everyone.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














