

DeepSeek's New Model Unveiled: Why Is It Shaking the Global AI Community?
TechFlow Selected TechFlow Selected
DeepSeek's New Model Unveiled: Why Is It Shaking the Global AI Community?
DeepSeek-R1 achieved performance comparable to top-tier models such as GPT-4o and Claude Sonnet 3.5 by employing a purely reinforcement learning-based approach.
Tencent Tech "AI Future Guide" Contributing Author: Hao Boyang
Less than a month later, DeepSeek has once again shaken the global AI community.
Last December, DeepSeek's release of DeepSeek-V3 sent shockwaves through the global AI field. With extremely low training costs, it achieved performance comparable to top-tier models like GPT-4o and Claude Sonnet 3.5, stunning the industry. Tencent Tech previously conducted an in-depth analysis of this model, explaining in the simplest terms the technical background behind its ability to simultaneously achieve low cost and high efficiency.
This time is different—DeepSeek’s newly released model, DeepSeek-R1, not only maintains ultra-low cost but also achieves significant technological advancements, and it is open-source.
The new model continues its high cost-performance advantage, achieving GPT-o1-level performance at just one-tenth the cost.
As a result, many industry insiders have even begun chanting “DeepSeek succeeds OpenAI,” with growing attention focused on breakthroughs in its training methodology.
For example, Elvis, a former Meta AI researcher and well-known AI paper commentator on Twitter, emphasized that the DeepSeek-R1 paper is a treasure trove—it explores multiple methods for enhancing large language model reasoning and identifies clearer emergent properties.

Another influential AI figure, Yuchen Jin, believes the discovery in the DeepSeek-R1 paper—that models can use pure RL methods to guide autonomous learning and reflective reasoning—is highly significant.
Jim Fan, project lead at NVIDIA GEAR Lab, also pointed out on Twitter that DeepSeek-R1 uses hard-coded rule-based true rewards instead of any learnable reward models that RL can easily game. This led to the emergence of self-reflective and exploratory behaviors in the model.
Because all these critical discoveries are fully open-sourced by DeepSeek-R1, Jim Fan even remarked that this was something OpenAI should have done.

So what exactly is the “pure RL method” they refer to? And why does the model’s “Aha moment” prove AI has emergent capabilities? More importantly, what does DeepSeek-R1’s groundbreaking innovation mean for the future of AI?
Simplest Recipe, Returning to Pure Reinforcement Learning
After o1’s release, reinforcement of reasoning became the most discussed approach in the industry.
Typically, during training, a model employs a fixed method to enhance reasoning ability.
However, during R1’s training process, the DeepSeek team experimented simultaneously with three entirely different technical pathways: direct reinforcement learning training (R1-Zero), multi-stage progressive training (R1), and model distillation—all successfully. Both the multi-stage progressive training and model distillation approaches contain innovative elements with major implications for the industry.
The most exciting path, however, remains direct reinforcement learning. DeepSeek-R1 is the first model to prove the effectiveness of this method.
Let’s first understand traditional methods for training AI reasoning: typically, massive chain-of-thought (CoT) examples are added during SFT (supervised fine-tuning), along with complex neural network-based reward models such as Process Reward Models (PRM), to teach the model how to reason step-by-step.
Sometimes Monte Carlo Tree Search (MCTS) is even incorporated, allowing the model to search among multiple possibilities for the optimal solution.
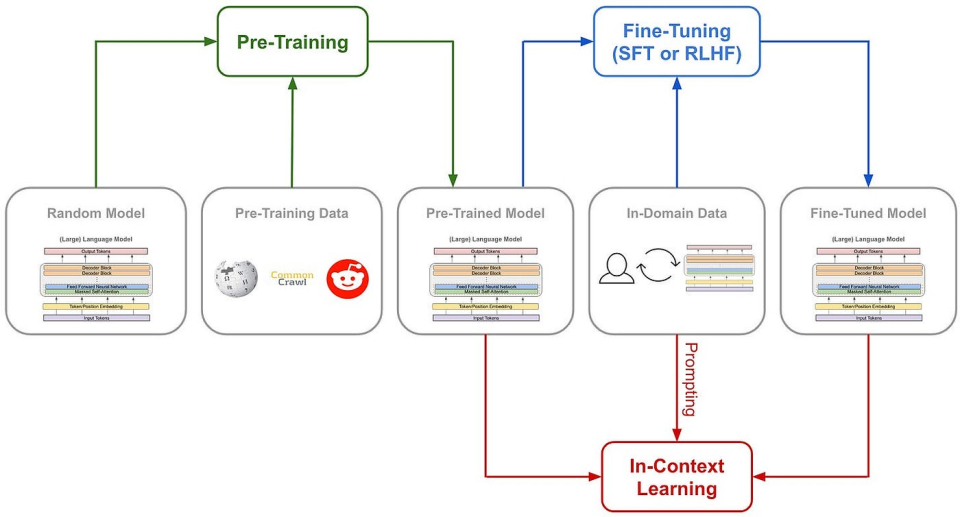
(Traditional model training pipeline)
But DeepSeek-R1 Zero chose an unprecedented path—the “pure” reinforcement learning route. It completely abandoned pre-defined Chain-of-Thought templates and Supervised Fine-Tuning (SFT), relying solely on simple reward and penalty signals to optimize model behavior.
It’s like letting a genius child learn problem-solving purely through trial and error and feedback, without any examples or guidance.
All DeepSeek-R1 Zero had was a minimal reward system designed to stimulate AI reasoning.
The rules were just two:
1. Accuracy Reward: A reward model evaluates whether the response is correct—points added for correctness, deducted for errors. The evaluation method is straightforward: for deterministic math problems, the model must provide the final answer in a specified format (e.g., between <answer> and </answer>); for programming tasks, compilers generate feedback based on predefined test cases.
2. Format Reward: A format reward model enforces that the model place its thinking process between <think> and </think> tags. Points are deducted if not followed, added if compliant.
To accurately observe the model’s natural progression during reinforcement learning (RL), DeepSeek deliberately constrained system prompts solely to this structural format, avoiding any content-specific bias—such as forcing reflective reasoning or promoting specific problem-solving strategies.

(System prompt for R1 Zero)
With such a simple rule set, the AI improves itself under GRPO (Group Relative Policy Optimization) via self-sampling and comparison.
GRPO is relatively simple—it computes policy gradients through relative comparisons within groups of samples, effectively reducing training instability while improving learning efficiency.
In simple terms, imagine a teacher posing a question, having the model generate multiple answers, scoring each using the above reward rules, then updating the model based on the pursuit of higher scores and avoidance of lower ones.
The process looks roughly like this:
Input question → Model generates multiple responses → Rule system scores them → GRPO calculates relative advantages → Model updates.
This direct training method brings several clear advantages. First, improved training efficiency—completion in significantly less time. Second, reduced resource consumption—by eliminating SFT and complex reward models, computational demands drop sharply.
More importantly, this method actually taught the model to think—and to do so through “epiphanies.”
Learning Through “Epiphanies” in Its Own Language
How do we know the model truly learned to “think” under such a “primitive” method?
The paper documents a striking case: when tackling a complex mathematical expression √a - √(a + x) = x, the model suddenly paused and said, “Wait, wait. Wait. That’s an aha moment I can flag here,” then re-examined the entire solution process. This human-like epiphany emerged spontaneously, not pre-programmed.
Such moments often mark leaps in the model’s cognitive abilities.
According to DeepSeek’s research, the model’s progress isn’t uniform. During RL training, response lengths show sudden, significant increases—these “jump points” often coincide with qualitative shifts in problem-solving strategies. This pattern closely resembles human sudden insights after prolonged thought, suggesting a deep cognitive breakthrough.
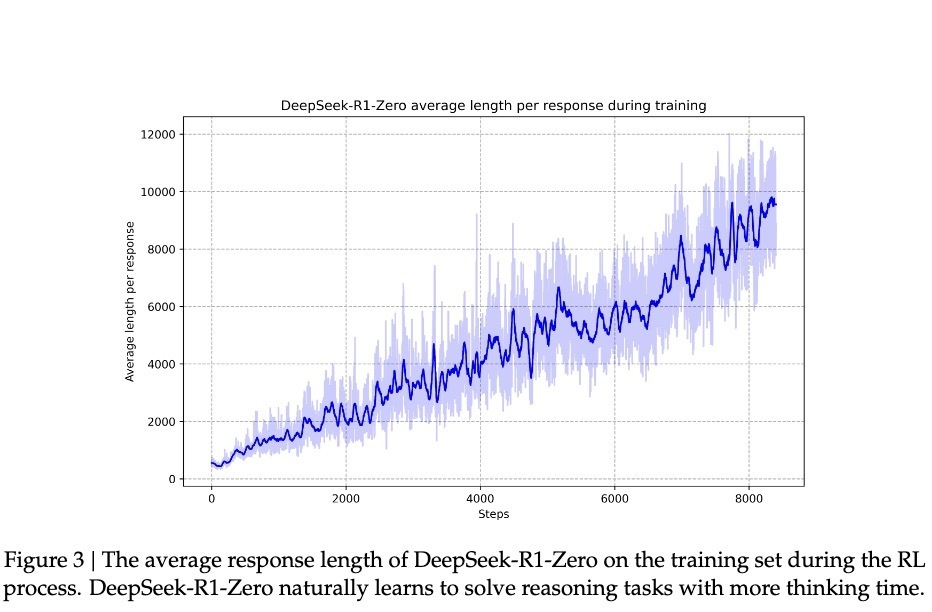
With such epiphany-driven improvements, R1-Zero’s accuracy on the prestigious AIME math competition rose from an initial 15.6% to 71.0%. When allowed multiple attempts on the same problem, accuracy reached 86.7%. This isn’t mere memorization—AIME problems require deep mathematical intuition and creative thinking, not mechanical formula application. Such improvement is only possible if the model can genuinely reason.
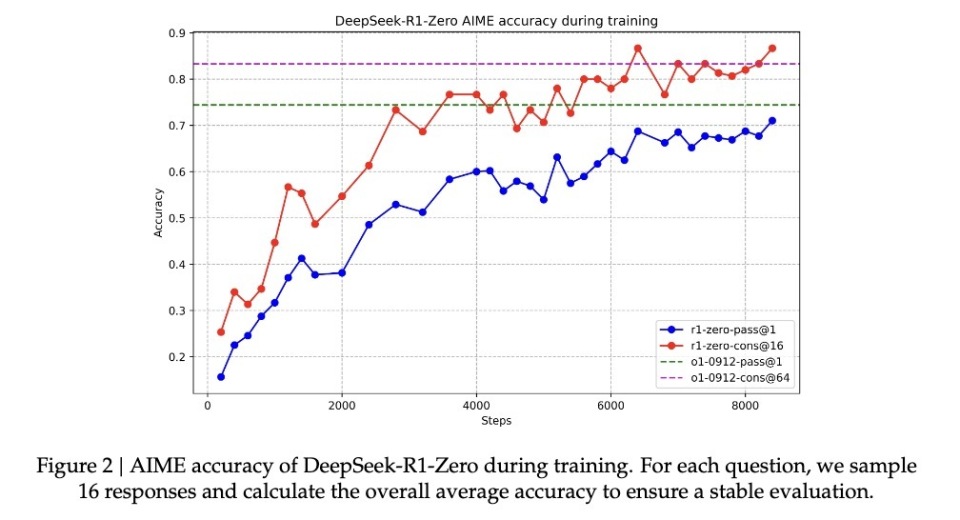
Another core piece of evidence that the model truly learned reasoning is that its response length naturally adjusts according to problem complexity. This adaptive behavior shows it’s not simply applying templates, but genuinely understanding difficulty levels and allocating more “thinking time” accordingly—just as humans spend more time thinking about integrals than basic addition. R1-Zero demonstrates similar intelligence.
Perhaps most compelling is the model’s transfer learning capability. On the completely different programming competition platform Codeforces, R1-Zero outperformed over 96.3% of human participants. This cross-domain performance indicates the model isn’t memorizing domain-specific tricks, but has mastered a generalizable reasoning ability.
A Genius Who Is Brilliant—but Hard to Understand
Despite R1-Zero’s astonishing reasoning ability, researchers quickly identified a serious issue: its thought processes are often difficult for humans to comprehend.
The paper candidly notes that this purely RL-trained model suffers from “poor readability” and “language mixing.”
This phenomenon is easy to understand: R1-Zero optimizes behavior solely through reward-penalty signals, with no human-provided “standard answers” as reference. Like a genius child inventing their own problem-solving method—effective but incoherent when explaining to others. The model may use multiple languages simultaneously or develop unique expressions, making its reasoning hard to trace.
To address this, the research team developed the improved version, DeepSeek-R1. By introducing more conventional “cold-start data” and a multi-stage training pipeline, R1 retained strong reasoning power while learning to express thoughts in human-understandable ways. It’s like assigning a communication coach to that genius child, teaching them to articulate ideas clearly.
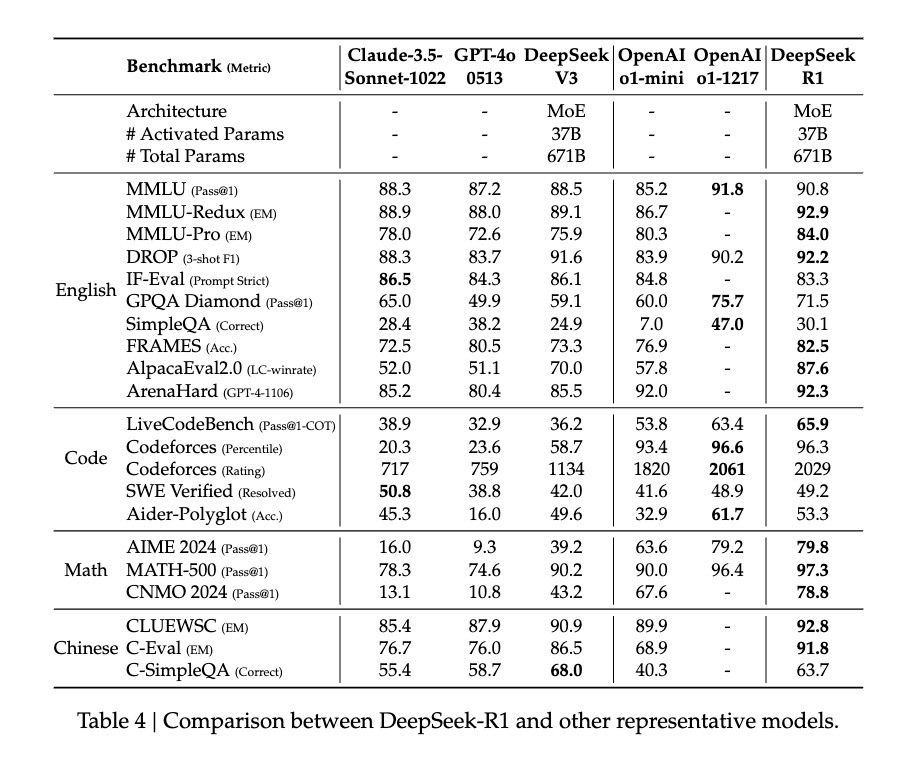
After this refinement, DeepSeek-R1 demonstrated performance comparable to—or even exceeding—OpenAI’s o1. On the MATH benchmark, R1 achieved 77.5% accuracy, slightly above o1’s 77.3%; on the more challenging AIME 2024, R1 scored 71.3%, surpassing o1’s 71.0%. In coding, R1 reached 2441 on Codeforces, outperforming 96.3% of human participants.
Yet, R1-Zero appears to hold even greater potential. Using majority voting on AIME 2024, it achieved 86.7% accuracy—surpassing even OpenAI’s o1-0912. This “more attempts, better accuracy” trait suggests R1-Zero may have grasped a fundamental reasoning framework, not merely memorized patterns. Paper data shows stable cross-domain performance from MATH-500 to AIME to GSM8K, especially on creatively demanding problems. This broad-spectrum capability suggests R1-Zero may indeed have cultivated foundational reasoning skills—a stark contrast to traditionally task-specific optimized models.
So despite being hard to understand, perhaps DeepSeek-R1 Zero is the true reasoning “genius.”
Pure Reinforcement Learning—An Unexpected Shortcut to AGI?
Why has DeepSeek-R1 drawn the industry’s focus to pure reinforcement learning? Because it has essentially opened a new evolutionary path for AI.
R1-Zero—the AI model trained entirely through reinforcement learning—has demonstrated surprising general reasoning ability. It didn’t just excel in math competitions.
More importantly, R1-Zero isn’t mimicking thought—it’s genuinely developing a form of reasoning.
This discovery could reshape our understanding of machine learning: traditional AI training may have been repeating a fundamental error—we’ve overly focused on making AI mimic human thinking. The industry needs to re-evaluate the role of supervised learning in AI development. Through pure reinforcement learning, AI systems appear capable of developing more native problem-solving abilities, unbound by pre-defined solution frameworks.
While R1-Zero clearly struggles with output readability, this “flaw” may precisely confirm the uniqueness of its cognition. Like a genius child inventing novel solutions but unable to explain them conventionally. This suggests: true artificial general intelligence may require cognitive modes entirely different from humans.
This is real reinforcement learning. As famed educator Piaget theorized: true understanding comes from active construction, not passive reception.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














