

LLM Empowers Blockchain, Ushering in a New Era of On-Chain Experience
TechFlow Selected TechFlow Selected
LLM Empowers Blockchain, Ushering in a New Era of On-Chain Experience
LLM's advantages include their ability to understand vast amounts of data, perform various language-related tasks, and customize results according to user needs.
Author: Yiping, IOSG Ventures
Preface
-
With the rapid advancement of large language models (LLMs), we are seeing numerous projects integrating artificial intelligence (AI) with blockchain. As the convergence between LLMs and blockchain grows stronger, we also see renewed opportunities for AI to re-engage with blockchain. Among these, zero-knowledge machine learning (ZKML) stands out as particularly noteworthy.
-
Artificial intelligence and blockchain are two transformative technologies with fundamentally different characteristics. AI demands powerful computing capabilities, typically provided by centralized data centers. Blockchain, on the other hand, offers decentralized computation and privacy protection but performs poorly when handling large-scale computing and storage tasks. We are still exploring and researching best practices for integrating AI and blockchain, and will later introduce several current examples of "AI + Blockchain" projects.
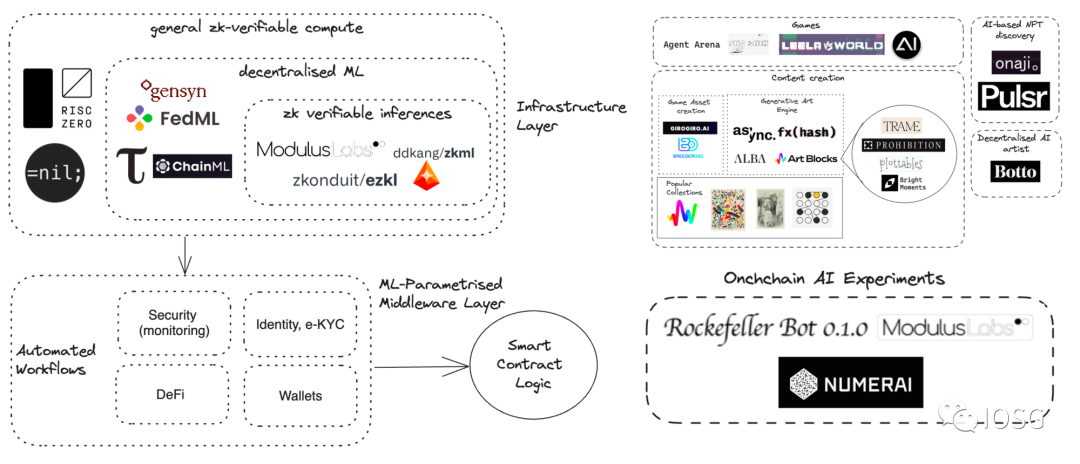
Source: IOSG Ventures
This research report is published in two parts. This is Part 1, where we focus on the applications of LLMs in the crypto space and explore strategies for practical implementation.
What is an LLM?
An LLM (large language model) is a computational language model composed of an artificial neural network with a vast number of parameters—typically billions. These models are trained on massive volumes of unlabeled text.
Around 2018, the emergence of LLMs revolutionized natural language processing research. Unlike previous approaches that required training task-specific supervised models, LLMs serve as general-purpose models that excel across diverse tasks. Their capabilities and applications include:
-
Understanding and summarizing text: LLMs can comprehend and summarize large volumes of human language and textual data. They extract key information and generate concise summaries.
-
Generating new content: LLMs have the ability to generate text-based content. By providing a prompt to the model, it can answer questions, generate new text, create summaries, or perform sentiment analysis.
-
Translation: LLMs can be used for translation between different languages. They leverage deep learning algorithms and neural networks to understand context and relationships between words.
-
Predicting and generating text: LLMs can predict and generate text based on contextual background, producing human-like content such as songs, poems, stories, and marketing materials.
-
Applications across domains: Large language models are widely applicable in natural language processing tasks. They are used in conversational AI, chatbots, healthcare, software development, search engines, tutoring, writing tools, and many other fields.
Advantages of LLMs include their capacity to understand vast datasets, perform multiple language-related tasks, and their potential to deliver customized results based on user needs.
Common Applications of Large Language Models
Due to their exceptional natural language understanding, LLMs hold significant potential. Developers primarily focus on two aspects:
-
Providing users with accurate and up-to-date answers based on extensive contextual data and content
-
Completing specific tasks assigned by users through the use of various agents and tools
It is precisely these two aspects that have led to the explosive growth of LLM applications for chatting with XX—for example, chatting with PDFs, documents, or academic papers.
Subsequently, efforts have been made to integrate LLMs with various data sources. Developers have successfully combined platforms such as GitHub, Notion, and note-taking software with LLMs.
To overcome inherent limitations of LLMs, different tools have been incorporated into these systems. The first such tool was search engines, which granted LLMs access to the latest knowledge. Further advancements integrated tools like WolframAlpha, Google Suites, and Etherscan with large language models.
Architecture of LLM Apps
The diagram below outlines the workflow of an LLM application when responding to a user query: First, relevant data sources are converted into embedding vectors and stored in a vector database. An LLM adapter uses the user’s query and similarity search to retrieve relevant context from the vector database. This context is then inserted into a prompt and sent to the LLM. The LLM executes the prompt and generates a response using available tools. Sometimes, the LLM is fine-tuned on a specific dataset to improve accuracy and reduce costs.
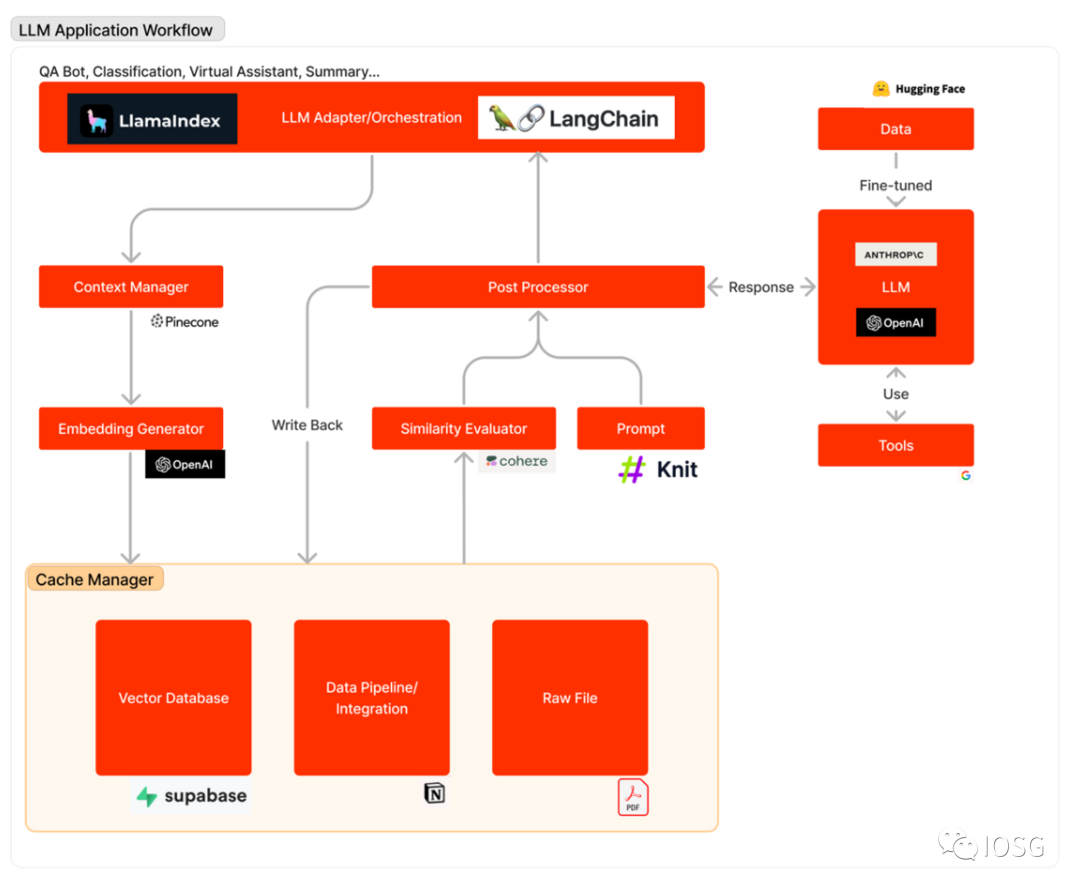
The workflow of LLM applications can be broadly divided into three main stages:
-
Data preparation and embedding: This stage involves preserving confidential information (e.g., project memos) for future access. Typically, files are split and processed through an embedding model, then saved in a special type of database known as a vector database.
-
Prompt formulation and extraction: When a user submits a search request (e.g., searching for project information), the software constructs a series of prompts to input into the language model. The final prompt usually contains hardcoded prompt templates from developers, effective few-shot examples, any required data retrieved from external APIs, and relevant documents extracted from the vector database.
-
Prompt execution and inference: After prompt construction, they are fed into a pre-existing language model for inference. This may involve proprietary model APIs, open-source models, or individually fine-tuned models. At this stage, some developers may also integrate operational systems such as logging, caching, and validation into the pipeline.
Bringing LLMs into the Crypto Space
Although the crypto space (Web3) shares some similarities with Web2 applications, developing high-quality LLM applications in crypto requires particular caution.
The crypto ecosystem is unique, with its own distinct culture, data, and integrations. LLMs fine-tuned on these crypto-specific datasets can deliver superior results at relatively low cost. While data is abundant, there is a noticeable lack of open datasets on platforms like HuggingFace. Currently, only one dataset related to smart contracts exists, containing 113,000 smart contracts.
Developers also face challenges integrating different tools into LLMs. These tools differ from those used in Web2, as they enable LLMs to access transaction-related data, interact with decentralized applications (DApps), and execute transactions. To date, we have not found any DApp integrations within LangChain.
Despite the additional effort required to develop high-quality crypto LLM applications, LLMs are naturally well-suited for the crypto domain. This field offers rich, clean, and structured data. Combined with the fact that Solidity code is typically concise and clear, it becomes easier for LLMs to generate functional code.
In Part 2, we will discuss eight potential directions where LLMs can assist the blockchain space, including:
-
Integrating built-in AI/LLM functionality directly into blockchains
-
Using LLMs to analyze transaction records
-
Using LLMs to identify potential bots
-
Using LLMs to write code
-
Using LLMs to read code
-
Using LLMs to assist communities
-
Using LLMs to track markets
-
Using LLMs to analyze projects
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














