

Interview with the Founder of Nil Foundation: ZK Technology Might Be Misused — Public Traceability Is Not the Original Intent of Cryptography
TechFlow Selected TechFlow Selected
Interview with the Founder of Nil Foundation: ZK Technology Might Be Misused — Public Traceability Is Not the Original Intent of Cryptography
Misha believes the cryptocurrency industry originated from financial cryptography, aiming to eliminate trust assumptions rather than making everything traceable and publicly readable.

Interview Introduction
Mikhail Komarov, nicknamed Misha, is the founder and CEO of Nil Foundation. Nil Foundation is working on building the most secure zero-knowledge (zk) prover and a marketplace for zero-knowledge proofs to address one of Web3’s most pressing challenges: constructing secure and reliable zk circuits as infrastructure to pave the way for the future of Web3.
In 2023, zero-knowledge technology became a hot keyword. However, Misha points out, “The black-box nature of zkEVM circuits in currently popular roll-up solutions such as Polygon, zkSync, and Starkware could potentially lead to major industry crises if not handled carefully, given the significant liquidity involved in these systems.”
This interview will delve into the topic of zero-knowledge technology, including its forgotten history and diverse applications on Web3. Misha’s background in traditional database management enables him to offer unique and insightful perspectives on the current state of the blockchain industry for readers.
What are the fundamental differences between blockchain and traditional database management? How can they be compatible? Will zero-knowledge proofs dominate everything in the future? How can zk privacy disrupt the data analytics industry? And how can technical terms like circuits, zk, compilers, and databases be understood in simple terms?
Let’s find the answers in this interview.
Summary
-
The only significant difference between traditional database management and blockchain lies in how commit logs or block sequences are constructed.
-
The scale and complexity of current zkEVM circuits may obscure potential security vulnerabilities. Exploiting such vulnerabilities in popular roll-ups like Polygon, zkSync, or Starkware could trigger a major industry crisis, considering the vast liquidity and dependencies tied to these systems.
-
ZK being misused as a compression tool rather than a privacy tool is why it has seen widespread adoption—applications like roll-ups, zk-bridges, zk-mls, and zk-oracles fundamentally rely on zk’s compression capability, not its privacy features.
-
Misha believes that the crypto industry originated from financial cryptography, aiming to eliminate trust assumptions, not to make everything traceable and publicly readable.
About Misha’s Background
TechFlow: Please introduce yourself and share how you entered the cryptocurrency world?
Misha: Falling down the crypto rabbit hole was very unexpected for me.
Nowadays, many projects start with a technology and then look for applications. But back in 2013, some people realized the importance of securing communication channels and protecting privacy, and Bitmessage offered a solution. I thought, “Let’s make it work.” Then I became an early contributor.
Before that, I had just started my first year at university as a student—what better things did I have to do? I thought, “Well, I’ve been in this space for a while; I think I can build something.” That’s how I began my journey into cryptocurrencies.
Prior to joining Bitmessage, I studied how database management systems (DBMS) work, mainly to practice using the Cypher language at university.
I found blockchain interesting and similar to DBMS, but I didn’t understand why so many people didn’t consider blockchain a suitable database system.
This prompted me to dive deeper into the subject, trying to figure out why it was seen merely as a financial cryptographic protocol rather than a comprehensive data management solution (DBMS).
As I dug deeper, my studies led me into algebraic topology, which eventually brought me to complexity theory and cryptography.
These two paths—DBMS and cryptography—intersected, and that’s where I discovered the connection between the database industry and the crypto industry.
Nil Foundation's Mission and Current Progress
TechFlow: In 2018, Nil Foundation was established, focusing on research in database management systems and applied cryptography. Can you explain how blockchain can be understood as a database management system?
Misha: The architecture of traditional database management systems and crypto markets is actually very similar.
They both stem from the basic idea of managing and storing data—for example, using commit logs in DBMS or a sequence of blocks in blockchain. The fundamental method of timestamp ordering resembles organizing entries in a commit log.
Now, complaints about massive state data in the crypto industry aren’t unique, since enterprises in traditional industries also need to manage and maintain state data.
The only significant difference between the two industries lies in how commit logs or block sequences are constructed. The process of building them isn’t truly different. Both processes and architectures are adapted according to the specific needs of each environment.
In the crypto industry, the focus is on reducing trust assumptions in untrusted environments, whereas the traditional industry prioritizes efficiency and may not emphasize trust assumptions.
Our research aims to apply the principles and achievements of the traditional DBMS industry to the crypto industry, with the goal of handling data management and trust assumptions in ways beneficial to both fields, promoting integration and finding common ground.
TechFlow: What challenges and potential benefits arise from merging the traditional database management system (DBMS) industry with the crypto industry? How do you view the possible impact?
Misha: It should be noted that developing a DBMS can take over five years, while crypto industry projects often have much shorter development cycles. This difference in development timelines affects the convergence of the two industries.
We are one of the few projects attempting to bridge the gap between data management solutions in the crypto industry and the DBMS industry. Our focus is on DBMS solutions within the crypto space, not at the protocol level.
For instance, interoperability is often discussed in the crypto industry.
Using a DBMS approach can simplify interoperability by providing access to all database data. For example, Ethereum’s locked liquidity is data written onto its network and can be accessed directly with the same level of security. This eliminates the need for data migration when creating new databases (such as roll-ups).
This reduces the need for bridges and simplifies data management across different databases.
TechFlow: How has your project evolved in its approach to providing transparent and efficient database management systems for the crypto industry? How do your developments in zkLLVM and commercializing zk-SNARKs contribute to achieving this goal?
Misha: The link between our current focus and our original idea is that we realized the need to reduce trust assumptions in our DBMS solutions. We want to provide transparency and prove computations happening within the database management system.
This led us to explore complex circuits like state proofs and consensus proofs, collaborating with foundations such as Mina and Ethereum to learn and implement these solutions.
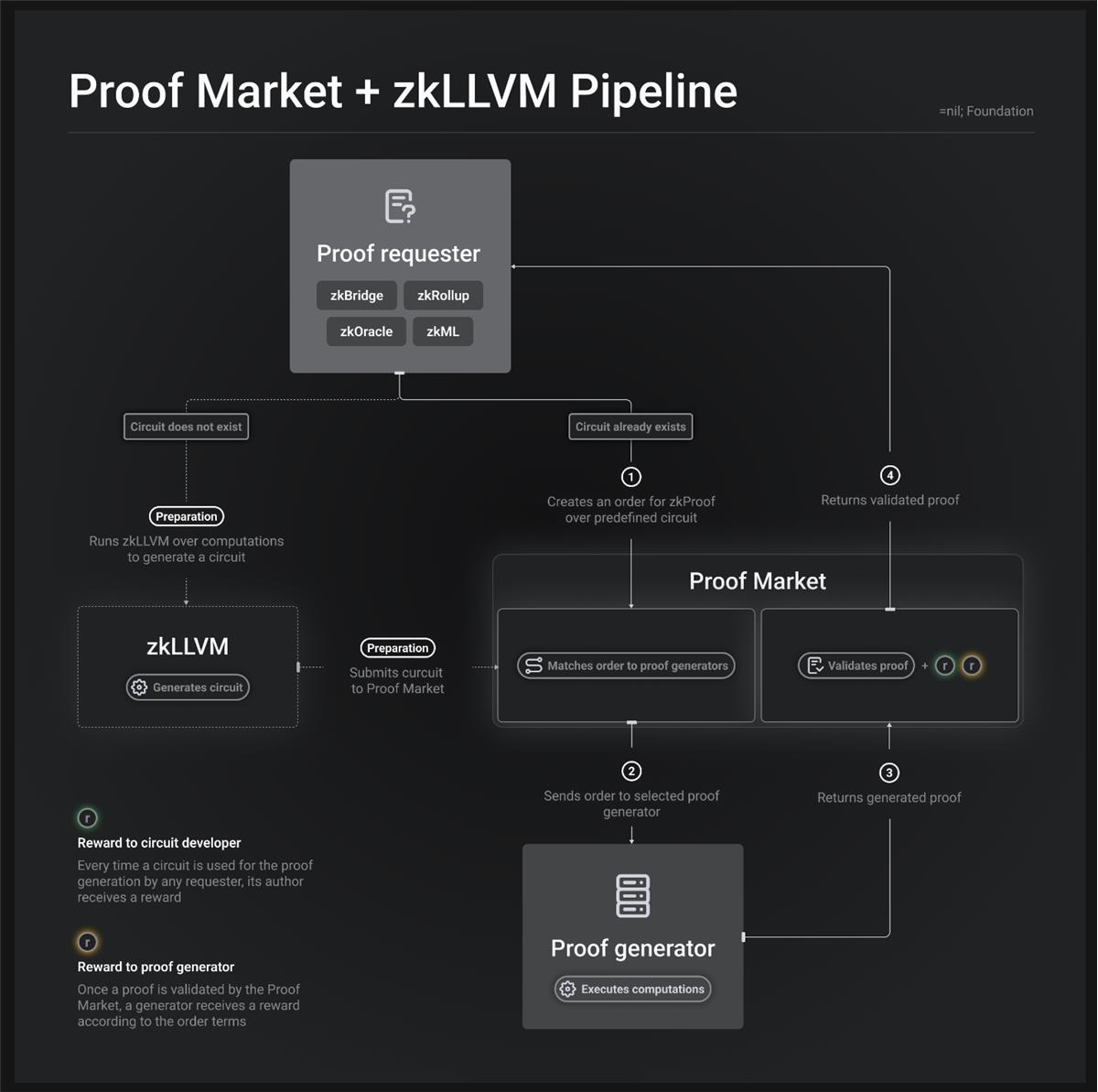
Initially, we built circuits manually, but this was a challenging and time-consuming process. To solve this, we developed zkLLVM—a provable compiler that generates circuits from highly readable code. We did this because this is what people are doing in DBMS, and it can also be applied to future decentralized databases.
Instead of creating custom domain-specific languages (DSL), we decided to leverage existing programming languages and compilers to generate circuits. A circuit compiler can prove almost anything—even simple applications like games. When you can prove nearly anything, including large codebases or complex computations, it typically requires immense computational power and expertise.
When dealing with huge circuits, you need enormous proof times—not just minutes, not just hours, but days, weeks, or even months.
This motivated us to introduce market dynamics to incentivize optimization—by treating zk-SNARKs as tradable commodities, we encourage competition among verifiers and optimizers. This competition drives innovation and improves the efficiency of zk-SNARK proofs. Our goal is to create an ecosystem where optimizing zk-SNARK proofs is in demand, fostering continuous improvement.
Popularity, Misuse, and Impact of ZK Technology in the Crypto Industry
TechFlow: Can you briefly review the research and development history of zero-knowledge proofs? Since mathematicians first proposed the concept in the late 1980s, what limitations and challenges have hindered its widespread application?
Misha: The widespread application of zero-knowledge proofs has been limited by several major obstacles.
Before 2008–2010, prior to the emergence of BFT (Byzantine Fault Tolerance) databases and protocols, people already used zero-knowledge proofs to verify things they didn’t want to disclose publicly, such as authentication in banking or other industrial fields.
However, for a long time, there was no way to prove complex, general-purpose, and Turing-complete computations. Early implementations used simple calculations and couldn’t handle complex ones. Over time, more advanced proof systems and arithmetic operations emerged, enabling the verification of Turing-complete computations and complex organizational processes. Various representations, such as constraint systems, specific organizational structures, and qualification sites, were developed to prove complex computations, process descriptions, and BFT protocols.
Unfortunately, the technology has been widely misused: people realized that these proof systems could not only hide computations and data but also compress massive computations into small, succinct proofs.
As Eli Ben-Sasson of StarkWare often discusses, when people use these proof systems for compression, the zero-knowledge property is no longer needed.
This misuse has led to a series of applications such as roll-ups, zk-bridges, zk-mls, and zk-oracles—applications that exclude privacy-related use cases and instead focus on leveraging the compression mechanism provided by the technology. In fact, the privacy component can be removed from the proof system without breaking functionality.
For example, roll-ups can operate without a privacy component because they primarily use the proof system for data compression. Ironically, this large-scale technological misuse has led to the widespread adoption of the technology in the crypto world.
TechFlow: You mentioned zero-knowledge proofs without privacy features? How do you view this "partial use" of the technology?
Misha: Although the privacy component can be bypassed or omitted, privacy remains an inherent property and advantage of this technology. Removing the privacy aspect actually involves removing certain operations in the proof system, such as multiplication.
This results in loss of privacy but retains the compression feature. This compression property might persist and become one of the defining characteristics of commitment schemes and computation methods in this industry.
TechFlow: Why do we choose ZK over other cryptographic methods?
Misha: ZK offers the most efficient compression ratio—no other mechanism can compress data down to such a small size. Additionally, no other technology allows such easy verification of compressed data.
TechFlow: If ZK is so effective, is zk-Everything the future state of blockchain?
Misha: People have already tried applying zero-knowledge technology to everything. Some have even attempted bringing games into the zero-knowledge realm, which is quite peculiar.
Machine learning (ML) algorithms have also been zero-knowledge-ified. Performing computations in trustless environments and under BFT protocols remains expensive—more costly than outsourcing computation to someone with powerful computers.
Despite efforts, these computations remain expensive. Therefore, although people will try to zero-knowledge-everything, they’ll also pursue private execution atop zk using fully homomorphic encryption (FHE), and explore other solutions within proof systems.
On our website, there are use cases where we need to generate proofs of private data without revealing the data itself. For this, we combine zero-knowledge and fully homomorphic encryption. This will become an essential and critical technical component, like elliptic curve signatures, adding another layer of security and privacy to systems.
Privacy Protection, Anonymity, and On-chain Data Traceability
TechFlow: Vitalik Buterin recently proposed three key shifts, including enhancing scalability and privacy through zero-knowledge technology. Given that transaction data and addresses are often considered anonymized, can you elaborate on the specific role of zero-knowledge proofs in strengthening privacy?
Misha: There’s a distinction between anonymity and pseudonymity.
By default, all these databases and protocols offer pseudonymity. This means you can trace and observe what happens, but you don’t know the identities of the individuals involved. Pseudonymity is the default state.
However, true anonymity and privacy involve more than just hiding identities. They also involve concealing the fact that any activity—such as transfers, operations, or transactions—has occurred at all. It’s about hiding not only the participants’ identities but also the overall activity.
Take Zcash as an example—one of the most well-known cases involving zero-knowledge proofs. In Zcash, data isn’t stored in a publicly readable format; instead, it’s encrypted and stored that way.
When someone needs to modify data, they access it, decrypt it, make necessary changes, re-encrypt it, and upload it back to the public database.
However, to ensure no malicious behavior occurs during this process, the person making the change must provide proof of successful decryption and correct re-encryption. They need to prove they operated on the data in a valid and compliant manner.
TechFlow: What impact does privacy protection have on on-chain data analytics?
Misha: First, this development will trouble on-chain data analytics, making their work difficult.
When all data is encrypted and protected, they’ll have to run around searching for data. It will be like a data hunt, reminiscent of scenes from old movies where someone approaches another asking for transaction data.
People will search for data, and every time they discover a piece, it will feel like finding something usable in the wilderness. So the future will be a very interesting phase, where privacy protection makes data less accessible, leading us toward trading data.
TechFlow: Does untraceability caused by on-chain privacy protection contradict the ideology of blockchain traceability?
Misha: When it comes to privacy applications and their emergence, the situation is somewhat complicated. Regarding your question, sometimes I think the answer is yes, sometimes no.
The idea that everything must be public and traceable is not part of blockchain’s core philosophy.
I believe the crypto industry originated from financial cryptography, aimed at eliminating trust assumptions, not making everything traceable and publicly readable. Its purpose is to reduce reliance on trusting code and overcome this issue. In this evolution, privacy applications do not alter its core purpose.
Trust assumptions will still be eliminated, but the traceability that once seemed crucial may no longer be necessary in the future. The crypto industry wasn’t invented for traceability and publicity, but to eliminate trust assumptions—that is, you can achieve consensus on something through cryptographic techniques under extremely stringent trust conditions.
Challenges Facing ZK Applications
TechFlow: What challenges exist in ZK applications? For example, how long will it take to achieve true anonymity on blockchain via zero-knowledge proofs?
Misha: It might take 3–5 years, as we need to address adversarial flaws. Specifically, the efficiency of ZK technology is our main challenge right now.
Any computation done this way will be slower than native computation.
However, reducing this overhead is something we must prioritize. We’re improving our compiler and also focusing on the demand side, offering data management solutions like a private version of Facebook, ensuring high efficiency. Therefore, efficiency is the primary issue we need to solve.
Second is properly addressing the growing demand for privacy. As more problems arise due to lack of privacy, demand for solutions like ours will increase, accelerating our R&D progress.
Currently, people face various issues and traps due to lack of privacy. The more such problems occur, the faster this process will advance.
But due to the aforementioned efficiency issues, developing and utilizing these solutions is challenging, and some technologies are still experimental, not yet out of the lab. Therefore, this is a highly experimental area requiring careful development.
Nil’s Roadmap
TechFlow: How are the current challenges facing ZK reflected in Nil Foundation’s roadmap?
Misha: I can confidently say that in the next few years, Nil won’t build anything private and untraceable.
We want to make data management appropriate in this industry. So for those who need to access and process data, they shouldn’t have to use complex techniques or pay huge fees to deal with trivial complexities.
Our goal is to make it cheaper, faster, and more convenient. That’s why we will definitely have an operational database management system. We will definitely perform excellently and have no trust assumptions. It will definitely be secure. We aspire to be the most secure option in the industry.
Conclusion
During the conversation, Misha was in Cyprus, the location of their company. When I asked Misha, “How are you?” he gave a shrugging, awkward expression and said, “Just like this.” Very real and adorable!
Misha is one of the most expressive and intelligent tech founders I’ve met. He’s humorous and direct, and genuinely easygoing in person. I’m grateful to Misha for patiently answering all my questions, including those that seemed naive and basic.
For readers without a technical background, if you’re curious about what circuits in zero-knowledge proofs really are, why we need compilers, what traditional circuit-making methods are if no compiler is used—answers to these questions, along with specific application scenarios of zero-knowledge proofs, are detailed in the following supplementary reading.
Supplementary Reading: Background Knowledge on Zero-Knowledge Proofs
TechFlow: How does a circuit compiler work? Why do we need it?
Misha: To prove a specific computation, you need a circuit. People have adopted several different approaches.
Some manually create their own circuits for different types of zkEVMs. Then they use these circuits within their own database or system cluster (like roll-ups), using zkEVM as the execution environment. Similarly, in our database management system, we need an execution layer to process data. This follows the architecture of traditional databases like MySQL, which have an execution layer or virtual machine.
The goal is to transparently prove computations on data, reduce trust assumptions, and avoid black-box approaches. To achieve this, individuals can either build additional zkEVMs or compile code to obtain the required circuits. By doing so, they can prove computations on their own data or data from other sources.
Building a zkEVM can take years and results in complex circuits—even Vitalik has expressed concerns about circuit security.
Rather than spending massive funds auditing or trying to understand complex circuits over the next decade, a more effective approach is compiling circuits from original EVM code or other sources. We faced the same problem when upgrading state proof and consensus proof circuits. It took us about a year to complete, and when finished, we realized its importance, even though not everyone fully understood the entire process from start to finish. To prevent this, we built the compiler.
This approach eliminates security issues and the complexity of handling large circuits.
TechFlow: What does the term “circuit” mean?
Misha: Circuits are used to define the computations being proven. Each specific application requires its own circuit. In the case of zkEVM, they usually use one circuit for all computations, which is acceptable but inefficient.
Moreover, these circuits tend to be large and hard to understand, making it difficult to detect any security issues or vulnerabilities. If a popular roll-up (like Polygon, zkSync, or Starkware) uses a circuit with exploitable vulnerabilities, it could cause an industry-wide disaster, given the massive liquidity and dependencies tied to these databases.
To reduce this risk, our website provides a compiler that generates circuits from readable, understandable, portable, and transparent code. This ensures circuits aren’t based on opaque constructions that are hard to audit or analyze.
Additionally, different services (like ZKML, ZK Oracle, ZK Bridge, and various consensus and state proofs) require different circuits. To improve efficiency and avoid manually creating a unified circuit for all computations, our compiler allows generating dedicated circuits tailored to each specific service. This simplifies the process and ensures higher efficiency when proving required computations.
By providing a compiler that generates circuits from readable code and enables dedicated circuits for different services, our goal is to enhance transparency, prevent industry-wide disasters, and improve overall computational efficiency.
TechFlow: How do circuits work?
Misha: Essentially, all circuits are optimized representations of programs, resulting in polynomial layouts over finite fields.
For example, a simple polynomial representation of computing “a + b” might look like “a + b = 0,” containing substituted data and coefficients. Then you have variables, which are replaced with coefficients, and you substitute the corresponding data. This process follows traditional optimization methods.
As programs grow more complex, the number of circuits or sets of polynomials increases—these circuits or polynomial sets represent the computation through polynomials. Thus, circuits essentially resemble a collection of polynomials performing various operations over finite fields, depending on the computation being proven.
Overall, the goal is to compile circuits from code and represent computations as a set of polynomials to ensure transparency and reduce complexity.
TechFlow: How can your mentioned zkLLVM be applied to a decentralized GPU market?
Misha: Regarding this topic, in some cases, people use the concept of distributed GPU computing for machine learning. If they need to prove that certain computations have been executed, using a ZK-based approach would benefit them.
For example, this could apply to the ZKML use case on our website. When individuals use distributed GPU computing for machine learning and need to provide proof of computation, they likely have access to the code representing the computation.
That code will be available on their cloud platform. If the code can be compiled into zkLLVM—for example, CUDO, OpenCL, or CPP—or even if someone wrote GPU code in Rust, compiling the given code into LLVM and generating the required proof becomes possible. This integration seems straightforward and indeed a great idea.
TechFlow: Can ZK-related technologies also be used in DeFi quantitative trading?
Misha: Cryptographic obfuscation will be the goal in trading—to hide executed algorithms, especially useful for large traders who never disclose their trading strategies.
To run these strategies in a decentralized and trustless environment, they will need cryptographic obfuscation to hide their algorithms while ensuring algorithm integrity.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














