

Towards World Supercomputers: A New Paradigm of Large-Scale Decentralized Execution
TechFlow Selected TechFlow Selected
Towards World Supercomputers: A New Paradigm of Large-Scale Decentralized Execution
To achieve decentralization—leveraging cryptography's inherent trustlessness, the natural economic incentives of MEV, driving mass adoption, the potential of ZK technology, and the demand for decentralized general-purpose computing including machine learning—the emergence of a world supercomputer has become necessary.
Authors: mspew, Kartin, Xiaohang Yu, Qi Zhou
Compiled by: TechFlow
*Note: This article is from the Stanford Blockchain Review. TechFlow is an official partner of the Stanford Blockchain Review and has been exclusively authorized to compile and republish this content.

Introduction
How far is Ethereum from becoming that world supercomputer?
From Bitcoin's peer-to-peer consensus algorithm to Ethereum's EVM, and further to the concept of network states, one persistent goal within the blockchain community has been to build a world supercomputer—a decentralized, unstoppable, trustless, and scalable unified state machine.
While it has long been understood that this is theoretically very feasible, most efforts to date have been fragmented and involve significant trade-offs and limitations.
In this article, we will explore some of the trade-offs and limitations in existing attempts to build a world computer, analyze the essential components such a machine would require, and ultimately propose a novel architecture for a world supercomputer.
A new possibility worth understanding.
1. Limitations of Current Approaches
a) Ethereum and L2 Rollups
Ethereum was the first real attempt—and arguably the most successful—to build a world supercomputer. However, throughout its development, Ethereum has heavily prioritized decentralization and security over scalability and performance. As a result, while reliable, vanilla Ethereum falls far short of being a world supercomputer—it is simply not scalable.
The current solution is L2 rollups, which have become the most widely adopted scaling approach to enhance the performance of Ethereum’s world computer. Built as an additional layer atop Ethereum, L2 rollups offer significant advantages and enjoy strong community support.
While there are various definitions of L2 rollups, they are generally networks with two key features: on-chain data availability on Ethereum (or another base layer) and off-chain execution of transactions. Essentially, historical state or input transaction data is publicly accessible and committed on Ethereum, but all individual transactions and state transitions occur off the main chain.
Although L2 rollups significantly improve the performance of these “global computers,” many suffer from systemic centralization risks that fundamentally undermine blockchain principles of decentralization. This is because off-chain execution involves not just individual state transitions, but also the ordering or batching of transactions. In most cases, an L2 sequencer handles ordering, while L2 validators compute the new state. Granting this sequencing power to a single sequencer introduces a centralization risk—centralized sequencers can abuse their authority, arbitrarily censor transactions, harm network vitality, and profit from MEV extraction.
Although numerous proposals exist to reduce centralization risks in L2s—such as shared or outsourced sequencers, decentralized sequencer solutions (e.g., PoA, PoS leader selection, MEV auctions, PoE)—many remain at the conceptual design stage and are far from being a silver bullet. Moreover, many L2 projects appear reluctant to implement decentralized sequencer solutions. For example, Arbitrum suggests decentralized sequencing as an optional feature. Beyond sequencer centralization, L2 rollups may face additional centralization issues arising from full-node hardware requirements, governance risks, and trends toward application-specific rollups.
b) L2 Rollups and the World Computer Trilemma
All these centralization issues stemming from relying on L2 rollups to scale Ethereum reveal a fundamental challenge—the "World Computer Trilemma," derived from the classic blockchain trilemma:
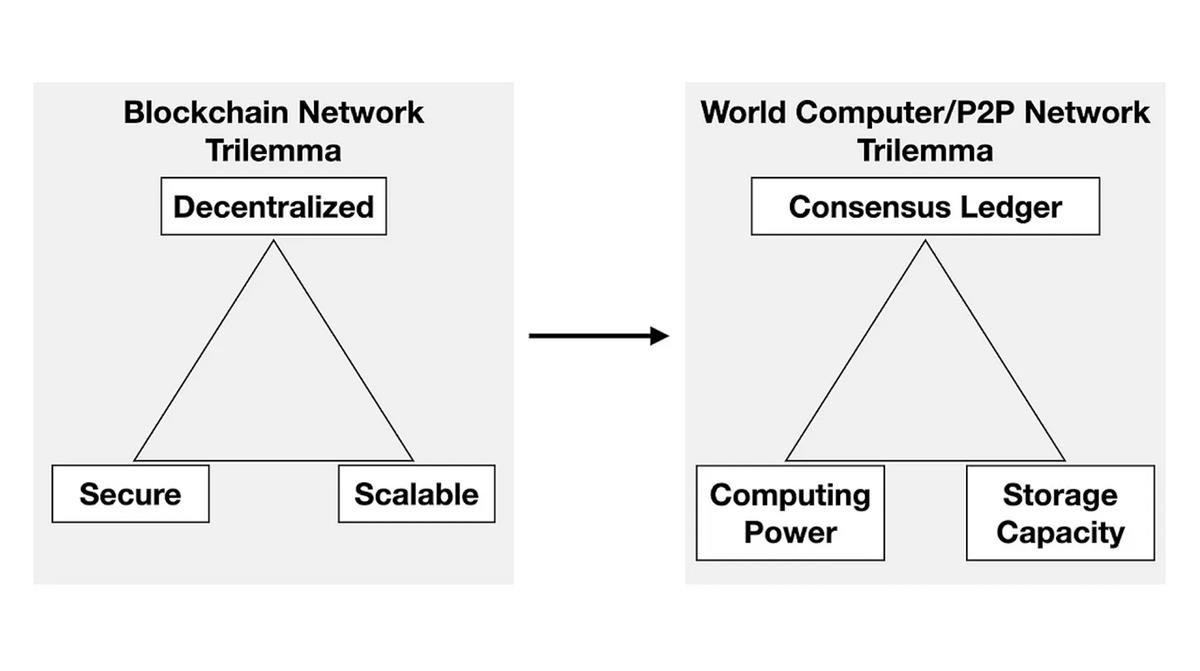
Different priorities in this trilemma lead to different trade-offs:
-
Strong Consensus Ledger: Requires redundant storage and computation, making it unsuitable for scaling storage and computing.
-
Strong Computing Power: Requires repeated use of consensus during heavy computation and proof generation, making it unsuitable for large-scale storage.
-
Strong Storage Capacity: Requires repeated use of consensus during frequent random sampling proofs, making it unsuitable for computation.
Traditional L2 approaches essentially build the world computer in a modular fashion. However, without partitioning different functions based on the above priorities, even when scaled, the world computer retains Ethereum’s original monolithic architecture. This structure fails to satisfy other critical needs such as decentralization and performance and cannot resolve the world computer trilemma.
In other words, L2 rollups effectively achieve the following:
-
Modularity of the world computer (enabling more experimentation at the consensus layer and introducing external trust via centralized sequencers);
-
Enhanced throughput of the world computer (though not strictly “scaling”);
-
Open innovation on the world computer.
However, L2 rollups do not provide:
-
Decentralization of the world computer;
-
Performance enhancement of the world computer (the maximum combined TPS of rollups is still insufficient, and L2s cannot achieve faster finality than L1);
-
Computation for the world computer (involving tasks beyond transaction processing, such as machine learning and oracles).
While world computer architectures can incorporate L2s and modular blockchains, they fail to address the root problem. L2s may solve the blockchain trilemma, but not the world computer trilemma itself. Therefore, as we see, current approaches are insufficient to realize the truly decentralized world supercomputer originally envisioned by Ethereum. We need scalability with full decentralization—not scalability with gradual decentralization.
2. Design Goals for a World Supercomputer
To achieve this, we need a network capable of handling truly general-purpose intensive computation—especially machine learning and oracles—while preserving the full decentralization of the base-layer blockchain. Furthermore, we must ensure the network can support high-intensity computations like machine learning (ML) directly on the network, with results verifiable on-chain. Additionally, we must provide ample storage and computing capacity beyond existing world computer implementations, guided by the following goals and design principles:
a) Computational Requirements
To meet the needs and purpose of a world computer, we expand upon Ethereum’s vision of a world computer and aim to realize a world supercomputer.
A world supercomputer must first be able to perform, in a decentralized manner, any task that today’s—and tomorrow’s—computers can accomplish. To prepare for mass adoption, developers need a world supercomputer to accelerate the development and deployment of decentralized machine learning, enabling model inference and verification.
For computation-intensive tasks like machine learning, achieving this goal requires not only minimal-trust computational techniques such as zero-knowledge proofs, but also significantly greater data capacity on decentralized networks—something unattainable on a single P2P network like a traditional blockchain.
b) Solving Performance Bottlenecks
During the early development of computers, pioneers faced similar performance bottlenecks due to trade-offs between computing power and storage capacity. Consider the most basic components of a circuit.
We can compare computing power to a light bulb/transistor and storage capacity to a capacitor. In a circuit, a light bulb requires current to emit light, much like computational tasks require processing power to execute. On the other hand, a capacitor stores charge, analogous to how storage holds data.
For the same voltage and current, there is a trade-off in energy allocation between the light bulb and capacitor. Typically, higher computation demands more current, leaving less energy stored in the capacitor. A larger capacitor stores more energy but may result in lower computational performance under high load. This trade-off makes it difficult to integrate both computing and storage efficiently in certain scenarios.
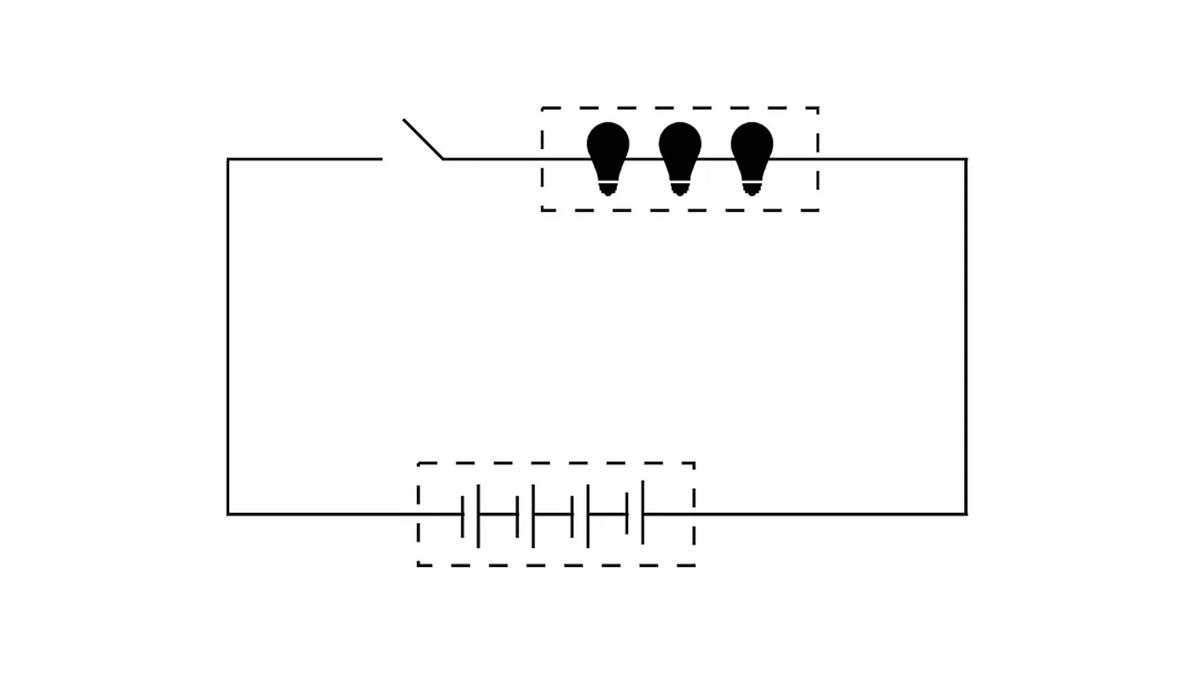
The von Neumann computer architecture addressed this by separating storage devices from the central processor. Similar to separating the light bulb from the capacitor, this approach can resolve performance bottlenecks in our world supercomputer system.
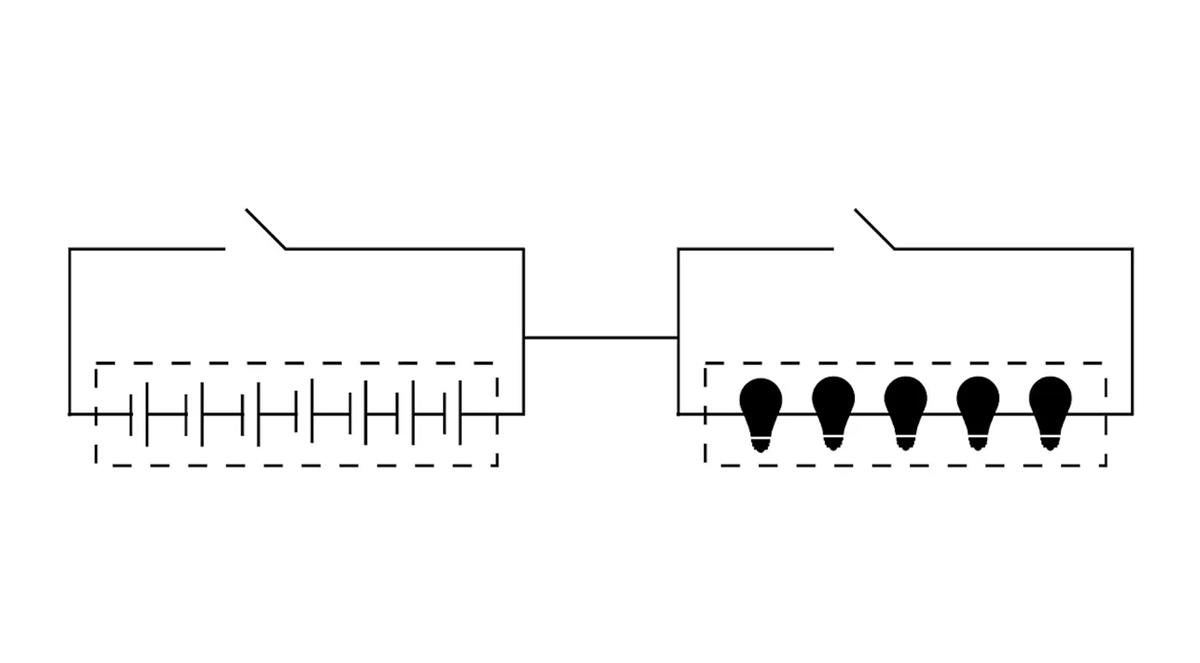
Likewise, traditional high-performance distributed databases adopt a design that separates storage and computation—a model well-aligned with the characteristics of a world supercomputer.
c) Novel Architectural Topology
The key difference between modular blockchains (including L2 rollups) and world computer architectures lies in their purpose:
-
Modular Blockchains: Aim to create new blockchains by selecting and combining modules (consensus, data availability layer DA, settlement, and execution).
-
World Supercomputer: Aims to build a global decentralized computer/network by integrating distinct networks (base-layer blockchain, storage network, computation network) into a unified system.
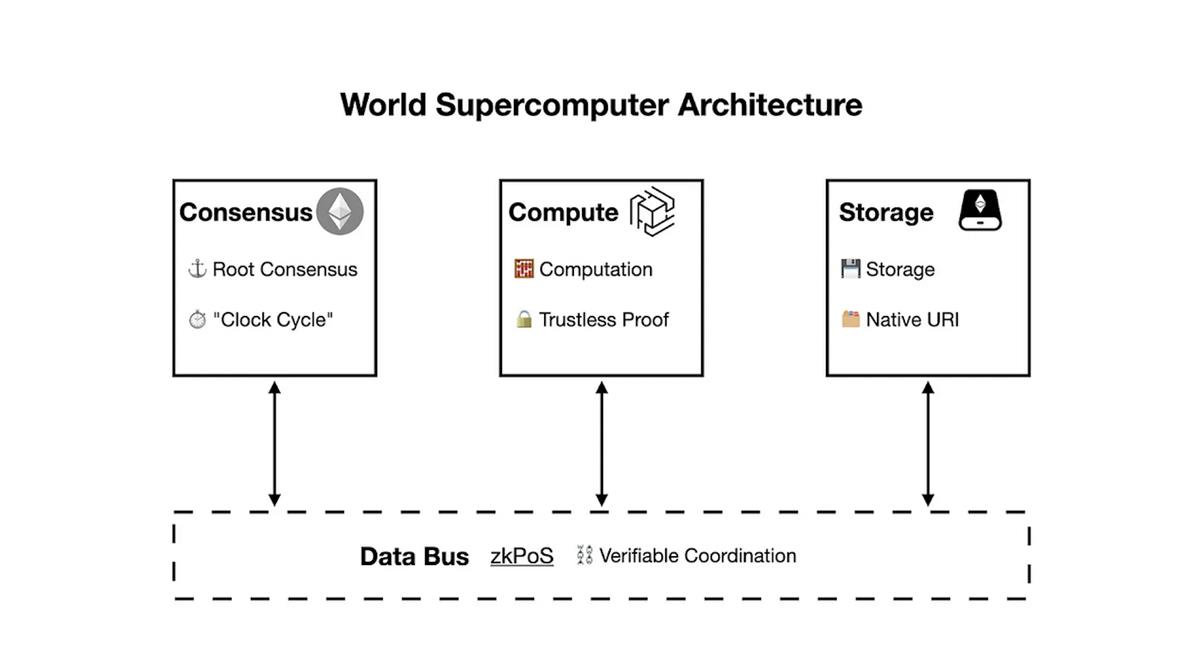
We propose an alternative: the ultimate world supercomputer will consist of three topologically heterogeneous P2P networks connected via trustless buses (connectors) such as zero-knowledge proof technology—the consensus ledger, computation network, and storage network. This foundational setup enables the world supercomputer to overcome the world computer trilemma and allows for additional components tailored to specific application needs.
Notably, topological heterogeneity involves not only architectural and structural differences but also fundamental divergence in topology forms. For instance, while Ethereum and Cosmos differ in network layers and interconnectivity, they remain equivalent in topological form (blockchain).
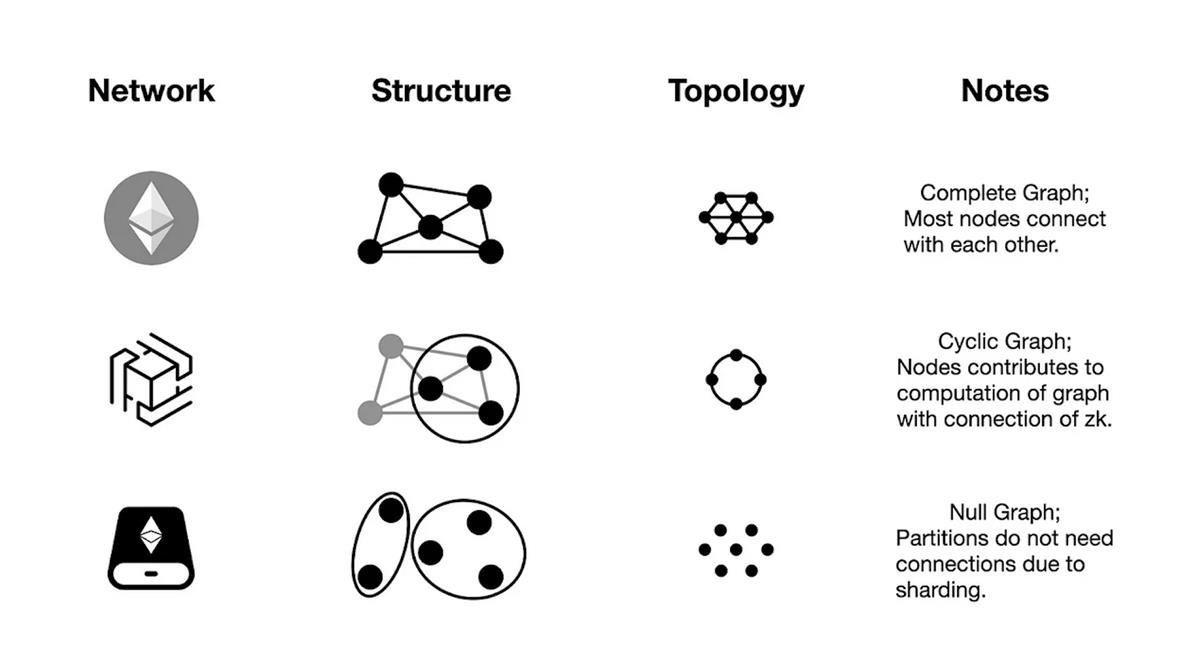
In the world supercomputer, the consensus ledger blockchain adopts a blockchain structure with nodes forming a complete graph; Hyper Oracle’s zkOracle network is a ledgerless network where nodes form a cyclic graph; and the storage rollup network takes yet another variant, with partitions forming subnets.
By using zero-knowledge proofs as a data bus, we can connect these three topologically heterogeneous P2P networks to achieve a fully decentralized, unstoppable, permissionless, and scalable world supercomputer.
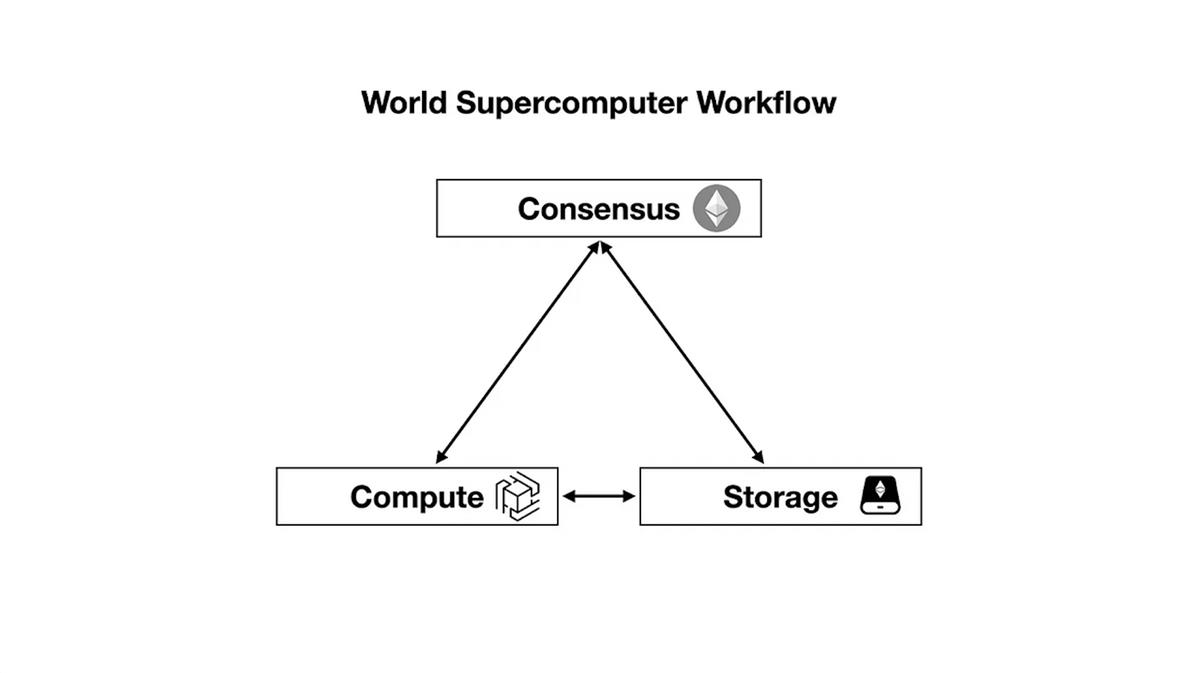
3. Architecture of the World Supercomputer
Similar to building a physical computer, we must assemble the previously mentioned consensus, computation, and storage networks into a world supercomputer.
Carefully selecting and connecting each component will help us balance the trilemma among consensus ledger, computational power, and storage capacity, ultimately ensuring the world supercomputer’s decentralization, high performance, and security.
The architecture of the world supercomputer, described by function, is as follows:
The node structure of a world supercomputer network with consensus, computation, and storage resembles the following:
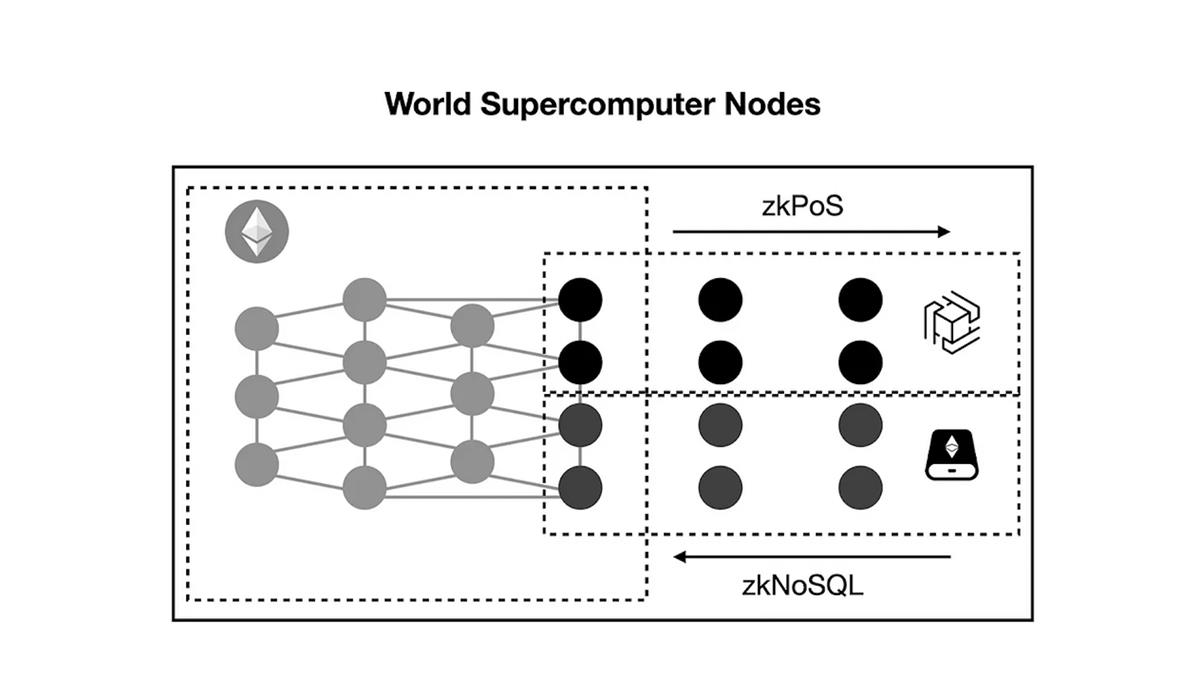
To bootstrap the network, nodes of the world supercomputer will leverage Ethereum’s decentralized infrastructure. Nodes with high computational performance can join the zkOracle computation network to generate proofs for general computation or machine learning, while nodes with high storage capacity can join EthStorage’s storage network.
The above example describes nodes simultaneously running Ethereum and the computation/storage networks. For nodes running only the computation/storage networks, they can access Ethereum’s latest blocks or prove data availability from storage via zero-knowledge proof-based buses (e.g., zkPoS and zkNoSQL) without requiring trust.
a) Ethereum Consensus
Currently, the world supercomputer uses Ethereum specifically for its consensus network. Ethereum offers strong social consensus and network-level security, ensuring decentralized agreement.

The world supercomputer is built on an architecture centered around a consensus ledger. The consensus ledger serves two primary purposes:
-
Providing consensus for the entire system;
-
Defining CPU clock cycles via block intervals.
Compared to computation or storage networks, Ethereum cannot simultaneously handle massive computational loads or store large volumes of general-purpose data.
In the world supercomputer, Ethereum acts as a consensus network, storing data such as L2 rollups, reaching agreement for computation and storage networks, and loading critical data so the computation network can perform further off-chain processing.
b) Storage Rollup
Ethereum’s Proto-danksharding and Danksharding are essentially methods to scale the consensus network. To achieve the storage capacity required by a world supercomputer, we need a solution that is native to Ethereum and supports permanent storage of vast amounts of data.

Storage rollups, such as EthStorage, are designed to scale Ethereum for massive storage. Moreover, since computation-intensive applications like machine learning require substantial memory to run on physical machines, it’s important to note that Ethereum’s “memory” cannot be excessively expanded. Storage rollups are necessary to enable the “swap space” that allows the world supercomputer to run computation-heavy tasks.
Additionally, EthStorage provides a web3:// access protocol (ERC-4804), akin to a native URI or storage resource addressing system for the world supercomputer.
c) zkOracle Computation Network
The computation network is the most critical element of the world supercomputer, as it determines overall performance. It must be capable of handling complex computations such as oracles or machine learning and should operate faster than consensus and storage networks in accessing and processing data.
The zkOracle network is a decentralized, minimal-trust computation network capable of handling arbitrary computations. Any executed program generates a ZK proof that can be easily verified by consensus (Ethereum) or other components.
Hyper Oracle is a zkOracle network powered by zkWASM and EZKL, capable of running any computation with execution trace proofs.
The zkOracle network is a ledgerless blockchain (without global state), following the chain structure of the underlying blockchain (Ethereum), but operating as a computation network without maintaining a ledger. Unlike traditional blockchains that ensure validity through re-execution, zkOracle provides computational verifiability through generated proofs. The ledgerless design and dedicated node setup allow zkOracle networks (like Hyper Oracle) to focus on high-performance, minimal-trust computation. Results are output directly to the consensus network, not used to generate new consensus.
In the zkOracle computation network, each computation unit or executable is represented by a zkGraph. These zkGraphs define computation and proof generation behavior, just as smart contracts define computation on consensus networks.
I. General Off-Chain Computation
zkGraph programs in zkOracle computation can be used for two primary use cases without external stacks:
-
Indexing (accessing blockchain data);
-
Automation (automating smart contract calls);
-
Any other off-chain computation.
These two use cases fulfill middleware and infrastructure needs for any smart contract developer. As a world supercomputer developer, you can experience a fully decentralized end-to-end development process—from on-chain smart contracts on the consensus network to off-chain computation on the computation network—when building complete decentralized applications.
II. ML / AI Computation
To achieve internet-scale adoption and support any application scenario, the world supercomputer must support machine learning computation in a decentralized manner.
Through zero-knowledge proof technology, machine learning and artificial intelligence can be integrated into the world supercomputer and verified on Ethereum’s consensus network, enabling true on-chain computation.
In this case, zkGraphs can connect to external tech stacks, integrating zkML directly with the world supercomputer’s computation network. This enables all types of zkML applications:
-
User privacy-preserving ML/AI;
-
Model privacy-preserving ML/AI;
-
Computationally verifiable ML/AI.
To enable ML and AI computation on the world supercomputer, zkGraphs will integrate with advanced zkML tech stacks, providing direct integration with consensus and storage networks:
-
EZKL: Performs inference for deep learning models and other computational graphs in zk-SNARKs.
-
Remainder: Enables fast machine learning operations in Halo2 provers.
-
circomlib-ml: Circuit library for machine learning in Circom.
e) zk as Data Bus
Now that we have all the essential components of the world supercomputer, we need a final piece to connect them: a verifiable, minimal-trust bus for communication and coordination among components.
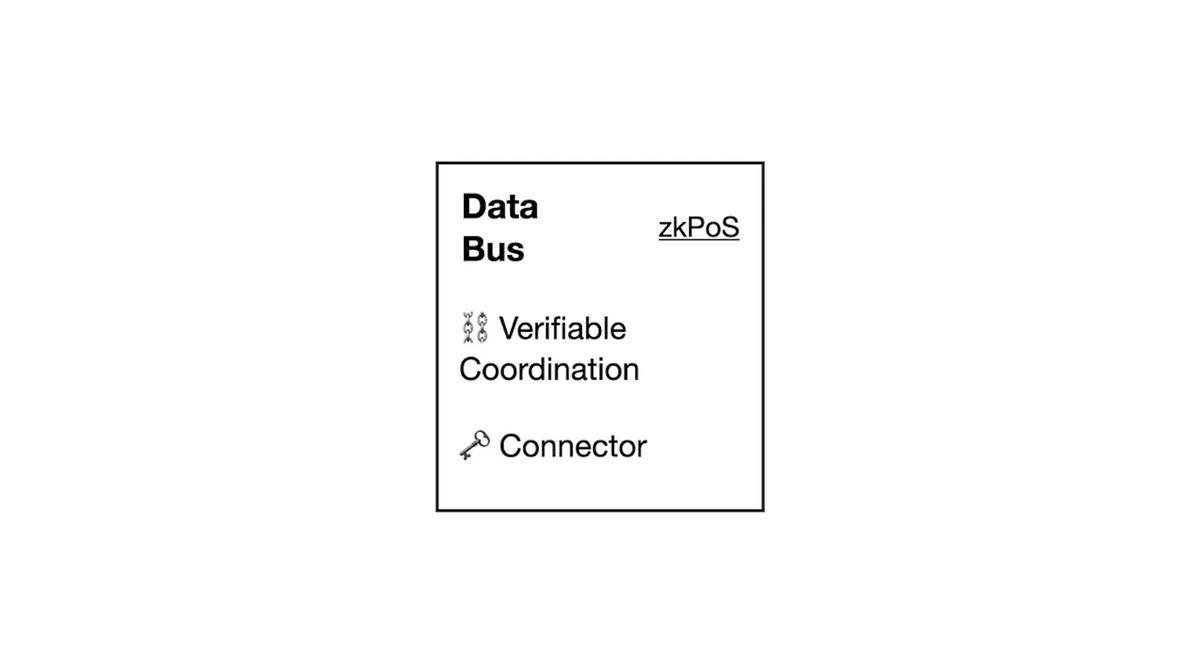
For a world supercomputer using Ethereum as its consensus network, Hyper Oracle’s zkPoS is a suitable candidate for the zk Bus. zkPoS is a core component of zkOracle that verifies Ethereum’s consensus via ZK proofs, allowing Ethereum’s consensus to be propagated and validated in any environment.
As a decentralized, minimal-trust bus, zkPoS can connect all components of the world supercomputer via ZK proofs with nearly negligible verification overhead. With a bus like zkPoS, data can flow freely within the world supercomputer.
When Ethereum’s consensus can be relayed from the consensus layer to the bus as initial consensus data for the world supercomputer, zkPoS can prove it via state/event/transaction proofs. The resulting data can then be passed to the computation network of the zkOracle network.
Moreover, for the storage network bus, EthStorage is developing zkNoSQL to enable proofs of data availability, allowing other networks to quickly verify that BLOBs have sufficient replicas.
f) Alternative Case: Bitcoin as Consensus Network
Like many sovereign L2 rollups, decentralized networks such as Bitcoin can also serve as the consensus backbone for a world supercomputer.
To support such a world supercomputer, we need to replace the zkPoS bus, as Bitcoin is a PoW-based blockchain network.
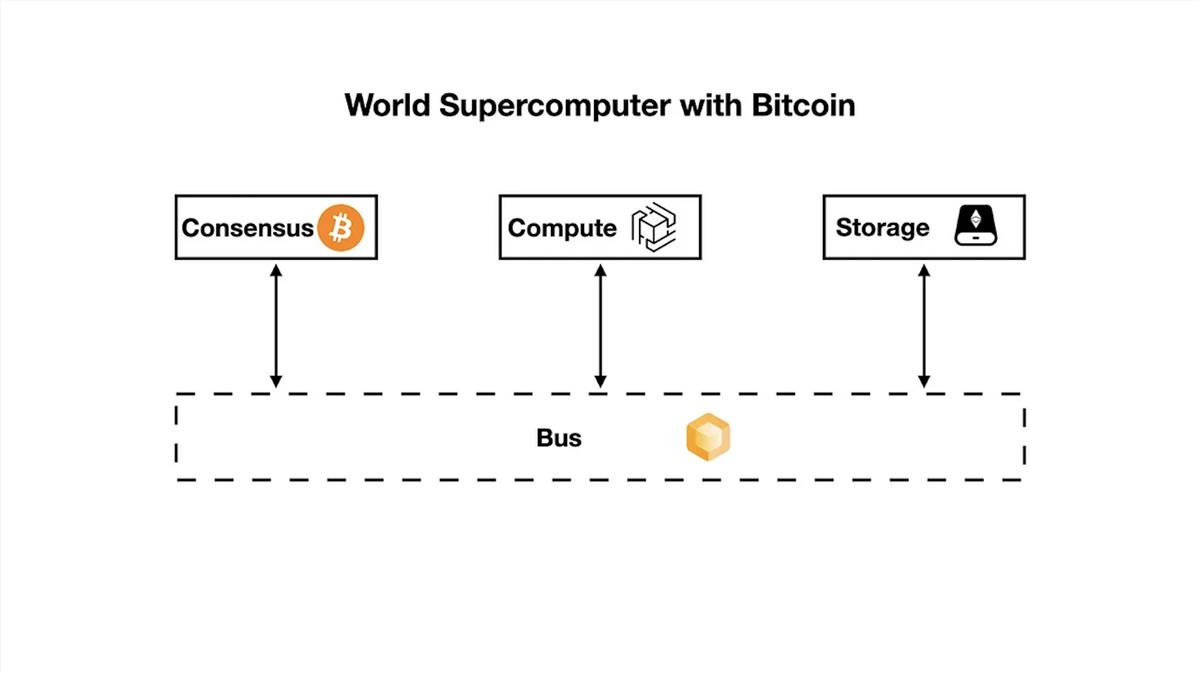
We can use ZeroSync to implement zk as the bus for a Bitcoin-based world supercomputer. ZeroSync, analogous to “zkPoW,” synchronizes Bitcoin’s consensus via zero-knowledge proofs, enabling any computing environment to verify and obtain Bitcoin’s latest state in milliseconds.
g) Workflow
Below is an overview of the transaction process for an Ethereum-based world supercomputer, broken into several steps:
-
Consensus: Ethereum processes and reaches consensus on transactions.
-
Computation: The zkOracle network executes relevant off-chain computations (defined by zkGraphs loaded from EthStorage) by rapidly verifying proofs and consensus data relayed via zkPoS as the bus.
-
Consensus: In cases such as automation and machine learning, the computation network returns data and transactions to Ethereum or EthStorage via proofs.
-
Storage: For storing large amounts of data from Ethereum (e.g., NFT metadata), zkPoS acts as a messenger between Ethereum smart contracts and EthStorage.
Throughout this process, the bus plays a crucial role in connecting each step:
-
When consensus data is transferred from Ethereum to the zkOracle computation network or EthStorage’s storage, zkPoS and state/event/transaction proofs generate verifiable proofs, enabling recipients to quickly validate and retrieve exact data (e.g., corresponding transactions).
-
When the zkOracle network needs to load data from storage for computation, it uses zkPoS to access data addresses from the consensus network, then retrieves actual data via zkNoSQL from storage.
-
When data from zkOracle or Ethereum needs to be presented as final output, zkPoS generates proofs for clients (e.g., browsers) to enable rapid verification.
Conclusion
Bitcoin laid a solid foundation for creating World Computer v0, successfully establishing the “world ledger.” Subsequently, Ethereum effectively demonstrated the “world computer” paradigm through its more programmable smart contract mechanism. To achieve decentralization—leveraging cryptography’s inherent trustlessness, MEV’s natural economic incentives, driving mass adoption, harnessing the potential of ZK technology, and meeting the demand for decentralized general-purpose computing including machine learning—the emergence of the world supercomputer has become necessary.
Our proposed solution constructs the world supercomputer by connecting topologically heterogeneous P2P networks via zero-knowledge proofs. As the consensus ledger, Ethereum provides foundational agreement and uses block intervals as the system-wide clock cycle. As the storage network, storage rollups store massive datasets and provide URI standards for data access. As the computation network, the zkOracle network runs resource-intensive computations and generates verifiable proofs. As the data bus, zero-knowledge proof technology connects all components, enabling data and consensus to be linked and verified across the system.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














