

DataFi: How Can Decentralized Data Services Revolutionize the Data Economy?
TechFlow Selected TechFlow Selected
DataFi: How Can Decentralized Data Services Revolutionize the Data Economy?
There is a vast amount of data in the world, growing at an astonishing rate.
Written by: Risk Taker88
Compiled by: TechFlow
There is a massive amount of data in the world, growing at an astonishing rate. Global market intelligence firm IDC estimates that this number will increase from 33 ZB to 175 ZB by 2025.
Despite the vast volume of data, it is not being effectively utilized across companies, industries, and economies. The main issue lies in data silos—situations where data collected by one department or unit cannot be accessed by other departments within the same organization. This also applies at a higher level: data gathered by one company is typically unavailable to others.
The data economy will change all of this.
The data economy is a global digital ecosystem where producers and consumers collect, organize, and share data to gain insights and monetize it. Crucially, they can also profit from it. In this economy, data is often diverse and comes from a wide range of sources: search engines, social media platforms, online data providers, companies using IoT-connected devices—you name it.
Participating in the data economy offers numerous benefits. By exchanging their data with other participants, companies can launch new business lines. For example, medical device manufacturers possess large amounts of user health information, such as heart rate or insulin levels. In addition to revenue from selling medical devices, they could collaborate with healthcare institutions by ethically and securely providing patient tracking data. All parties would benefit from this data exchange, while the manufacturer creates a new revenue stream.
Streamr
It's predicted that nearly 30% of global data will be generated in real time, with 95% of that coming from IoT devices. If this proves accurate, we can say Streamr is building for the future. Streamr is a decentralized platform where users can exchange and monetize their real-time data streams, including those generated by IoT devices. At its core is the Streamr Network, which transmits real-time data streams from producers to consumers.
All data in the Streamr network exists in the form of data streams. A data stream is any sequence of data points, of any type, generated from any source. Sources include—but are not limited to—sensors in smart homes, commercial data providers, or database systems. To illustrate what a data stream might look like, consider the example below.

These numbers come from a high-performance engine, where temperature rises as RPM increases. This is clearly valuable for mechanical engineers, who can now use field data when redesigning their engines.
Under Streamr, users collect data streams and bundle them into data unions. With consent, real-time data from different users can be pooled into a single data union. Data unions are what’s available for sale on the Streamr marketplace—the way users monetize their real-time data. When a buyer purchases (or in Streamr jargon, "subscribes to") a data union, DATA tokens are distributed among all contributing data stream producers. Not all data unions are the same; they may differ in membership models, use cases, revenue structures, or other characteristics.
I believe the Streamr platform and data unions will play a significant role in the data economy. It's a permissionless, decentralized, peer-to-peer product that enables retail data producers to monetize their real-time data.
Ocean Protocol
One of the leading players in the DataFi space is Ocean Protocol. DataFi can be defined as a domain within decentralized finance where data and data services are treated as an emerging asset class. Ocean Protocol stands at the forefront of this field—a decentralized data-sharing protocol that allows data producers to sell directly to consumers.

The protocol enables data providers to securely monetize their data without fully transferring ownership to buyers. Data consumers—such as policymakers, AI or machine learning engineers—benefit by gaining access to private datasets that would otherwise be difficult or impossible to obtain.
One of the most important concepts in Ocean Protocol is datatokens, which grant access to specific datasets or data services. Every dataset or data service on the protocol has its own datatoken. To gain access to a dataset, you must send 1.0 datatoken to the data producer. You can even transfer your access rights to someone else by sending your 1.0 datatoken to them. Importantly, you're not purchasing the data itself—only access to it.
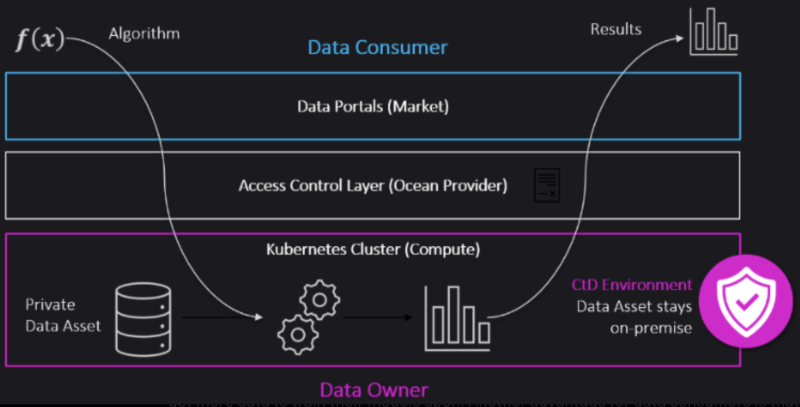
Compute-to-Data (CtD) is an intelligent technical solution that allows businesses or individuals to share data while preserving privacy. Suppose you have a dataset you'd like to "rent out" but are hesitant due to security concerns. A data scientist wants to use your data. CtD is the tool that solves this problem. Any data consumer can run their model on your data, while the data itself never leaves its original location (which could be your hardware, a Google Sheet, or anything else). Think of CtD as a protective layer between data owners and data consumers.
Here’s how it works: when an algorithm runs on the data, only the results are sent back to the data consumer—not the dataset itself. This allows data owners to monetize their data while protecting privacy. You can sell your data directly to consumers or via a marketplace. Data consumers gain more data for training models. Another advantage for data consumers is that they don’t need computational infrastructure, since all processing occurs on the data owner’s hardware.
In Ocean Protocol, not just data—but algorithms themselves—are considered assets. Researchers can monetize their algorithms. Like other data assets, providers can sell either the algorithm outright or just access to it. Algorithm developers can choose to sell only access, meaning the algorithm remains public. If only computational services are sold rather than the algorithm itself, it stays private.
Chainlink
Finally, let's look at a well-established project—Chainlink.
Many DeFi applications require external data. For instance, an on-chain betting market needs real-time odds from multiple bookmakers; or a decentralized trading app allowing securities tied to ETH futures prices should be able to fetch ETH futures prices from external exchanges like CME. Therefore, in most cases, smart contracts need to be connected to information from the outside world.
This is where blockchain oracles come in. They are third-party services that feed real-world data into DeFi-powered smart contracts. Decentralized oracles go further by combining multiple oracles into a single system. They query several data sources and return aggregated data to the blockchain, aiming to reduce the risk of any single point of failure.
Chainlink is a leading decentralized oracle network. Its architecture consists of three components: the Basic Request Model, the Decentralized Data Model, and Off-Chain Reporting. The Basic Request Model does exactly what its name suggests. If a smart contract needs to know the trading price of SOL on Binance, the Basic Request Model handles that task. This part of Chainlink’s architecture is responsible for querying data from a single source.
The Decentralized Data Model introduces the concept of on-chain aggregation. Data is aggregated from multiple independent oracle nodes, increasing reliability and trustworthiness. Chainlink’s Data Feeds functionality is based on the Decentralized Data Model. Data Feeds are off-chain data sources—such as weather events, corporate financials, sports results, or asset prices. Data is aggregated on-chain so consumers can always retrieve the final answer.
Finally, Off-Chain Reporting makes Chainlink truly unique in the decentralized context. Most operations occur off-chain. Oracle operators (nodes) communicate with each other over a peer-to-peer network, each regularly reporting data and signing off on it. All reports are consolidated into a single transaction—the final result of that round—which is then transmitted. The key advantage of aggregating reports into one transaction is significantly lower fees for oracle nodes. Submitting one transaction instead of many reduces congestion on the Chainlink blockchain.
Conclusion
It's no exaggeration to say that data has now become an independent asset class. Data and data services are becoming increasingly vital across the entire economy. The data economy—a global digital ecosystem where data is collected, analyzed, and shared to extract value from information—will impact every sector and industry, from healthcare to e-commerce.
However, there are several issues with "data flows" in the global economy. One of the most serious problems in the current landscape is that data is generated and stored in data silos. When data cannot reach other participants, its value diminishes. A second issue is the lack of ownership. While our data is being extensively recorded and rapidly accumulated by giants such as major social media platforms or medical device manufacturers, we are usually not the owners of that data. It is used or sold without our consent.
Data DeFi will transform how data is collected and shared. Even now, while DataFi is still in its early stages, several projects have emerged aiming to decentralize data services. These include platforms like Ocean Protocol and Streamr, which allow data producers to monetize their products and services on their marketplaces. Beyond creating new income streams for users, these platforms return data ownership to the data producers. For data consumers, the benefits of DataFi lie in secure and ethical access to datasets that were previously hard or impossible to obtain.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














