
Tình trạng "máy chủ bận" của DeepSeek khiến tất cả mọi người phát điên, đằng sau thực sự là chuyện gì?
Tuyển chọn TechFlowTuyển chọn TechFlow
Tình trạng "máy chủ bận" của DeepSeek khiến tất cả mọi người phát điên, đằng sau thực sự là chuyện gì?
Kẹt ở cái thẻ.

Hình ảnh: Được tạo bởi Wujie AI
Thông báo "máy chủ quá tải, vui lòng thử lại sau" liên tục từ DeepSeek đang khiến người dùng khắp nơi phát điên.
Trước đây không mấy nổi tiếng với công chúng, DeepSeek bất ngờ trở nên đình đám nhờ ra mắt mô hình ngôn ngữ V3 vào ngày 26 tháng 12 năm 2024, cạnh tranh trực tiếp với GPT-4o. Ngày 20 tháng 1, DeepSeek tiếp tục phát hành mô hình ngôn ngữ R1, đối trọng với o1 của OpenAI. Sau đó, nhờ chế độ "suy nghĩ sâu" cho ra câu trả lời chất lượng cao và tín hiệu tích cực về việc giảm mạnh chi phí huấn luyện mô hình, công ty và ứng dụng nhanh chóng vượt ra khỏi giới hạn ban đầu. Kể từ đó, DeepSeek R1 luôn trong tình trạng tắc nghẽn, chức năng tìm kiếm kết nối mạng ngắt quãng, chế độ suy nghĩ sâu thường xuyên hiển thị thông báo "máy chủ quá tải", gây nhiều phiền toái cho người dùng.
Khoảng hơn mười ngày trước, DeepSeek bắt đầu gặp sự cố gián đoạn máy chủ. Vào trưa ngày 27 tháng 1, trang web chính thức DeepSeek đã nhiều lần hiện thông báo "trang web/api DeepSeek không khả dụng". Cùng ngày, DeepSeek trở thành ứng dụng được tải xuống nhiều nhất trên iPhone trong kỳ cuối tuần, vượt cả ChatGPT tại khu vực Mỹ.
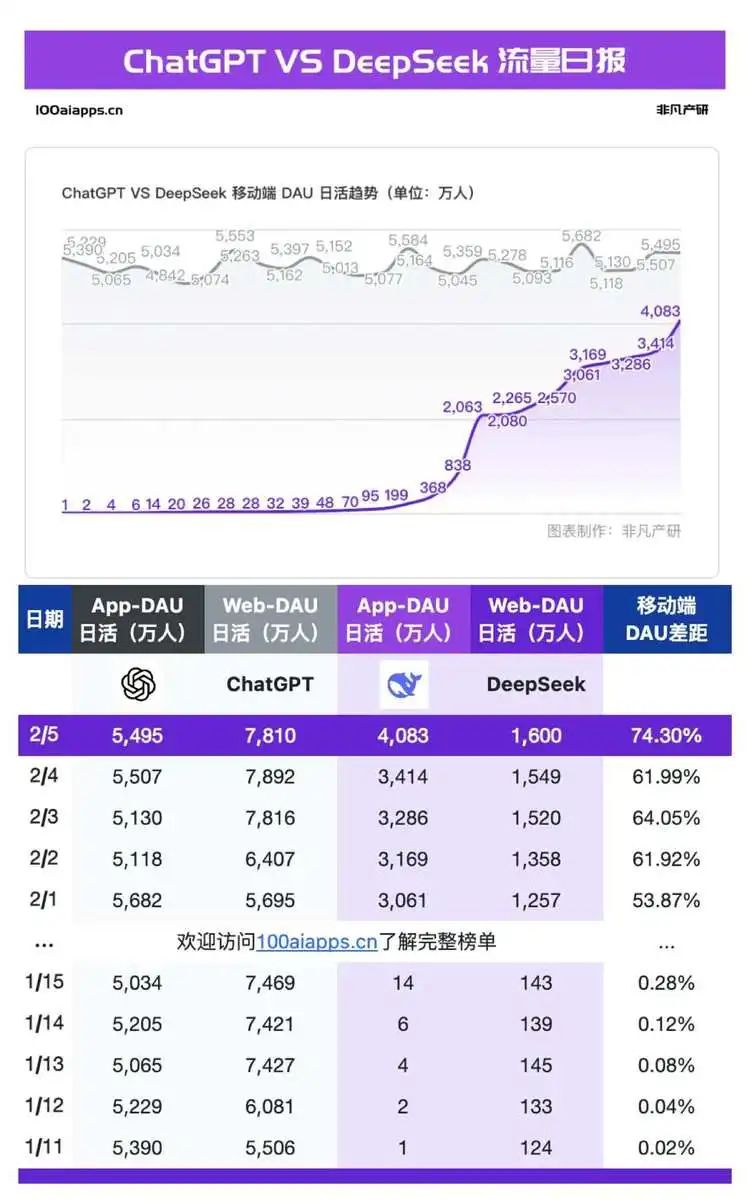
Ngày 5 tháng 2, sau 26 ngày ra mắt ứng dụng di động, số người dùng hoạt động hàng ngày của DeepSeek vượt mốc 40 triệu, đạt 74,3% so với mức 54,95 triệu của ChatGPT. Gần như đồng thời với đà tăng trưởng dốc đứng của DeepSeek, các phàn nàn về tình trạng máy chủ quá tải cũng xuất hiện dày đặc. Người dùng toàn cầu bắt đầu gặp phải tình trạng sập hệ thống chỉ sau vài câu hỏi, các phương án truy cập thay thế dần lan rộng, bao gồm các website thay thế DeepSeek, các nhà cung cấp dịch vụ điện toán đám mây, hãng chip và công ty hạ tầng đều nhanh chóng triển khai dịch vụ, hướng dẫn tự triển khai cá nhân cũng tràn lan khắp nơi. Tuy nhiên, sự bức xúc của người dùng vẫn chưa giảm: gần như tất cả các nhà sản xuất lớn trên toàn cầu đều tuyên bố hỗ trợ triển khai DeepSeek, nhưng người dùng ở khắp nơi vẫn tiếp tục phàn nàn về dịch vụ không ổn định.
Vậy rốt cuộc chuyện gì đang diễn ra phía sau?
1. Người quen dùng ChatGPT không chịu nổi DeepSeek lúc nào cũng không truy cập được
Sự bất mãn với “DeepSeek máy chủ quá tải” đến từ việc trước đây, các ứng dụng AI hàng đầu như ChatGPT rất hiếm khi bị giật lag.
Từ khi OpenAI ra mắt dịch vụ, ChatGPT dù từng trải qua vài lần sự cố P0 (mức độ nghiêm trọng cao nhất), nhưng nhìn chung tương đối đáng tin cậy, đã tìm được sự cân bằng giữa đổi mới và ổn định, dần trở thành một phần thiết yếu giống như các dịch vụ điện toán đám mây truyền thống.

Số lần ChatGPT sập quy mô lớn không nhiều
Quá trình suy luận của ChatGPT tương đối ổn định, bao gồm hai bước mã hóa và giải mã. Trong giai đoạn mã hóa, văn bản đầu vào được chuyển thành vector chứa thông tin ngữ nghĩa; ở giai đoạn giải mã, ChatGPT sử dụng văn bản đã sinh ra trước đó làm ngữ cảnh, dựa trên mô hình Transformer để tạo ra từ hoặc cụm từ tiếp theo, cho đến khi hoàn thành câu đúng yêu cầu. Mô hình lớn thuộc kiến trúc Decoder (bộ giải mã), giai đoạn giải mã là quá trình xuất từng token (đơn vị nhỏ nhất xử lý văn bản của mô hình lớn). Mỗi lần hỏi ChatGPT, một quy trình suy luận sẽ được khởi động.
Ví dụ, nếu hỏi ChatGPT: “Hôm nay tâm trạng bạn thế nào?”, nó sẽ mã hóa câu này, tạo biểu diễn chú ý ở mỗi lớp, dựa trên biểu diễn chú ý của tất cả token trước đó để dự đoán token đầu tiên “Tôi”. Sau đó tiến hành giải mã, ghép “Tôi” vào sau “Hôm nay tâm trạng bạn thế nào?” thành “Hôm nay tâm trạng bạn thế nào? Tôi”, tạo biểu diễn chú ý mới, dự đoán token tiếp theo là “có”, rồi lặp lại các bước này, cuối cùng tạo ra câu hoàn chỉnh: “Hôm nay tâm trạng bạn thế nào? Tâm trạng tôi rất tốt.”
Công cụ sắp xếp container Kubernetes đóng vai trò “nhạc trưởng hậu trường” cho ChatGPT, chịu trách nhiệm điều phối và phân bổ tài nguyên máy chủ. Khi lượng người dùng đổ về vượt quá khả năng chịu tải của mặt phẳng điều khiển Kubernetes, toàn bộ hệ thống ChatGPT sẽ sập.
Tổng số lần ChatGPT sập không nhiều, nhưng đằng sau đó là nguồn lực khổng lồ hỗ trợ vận hành ổn định – tức là sức mạnh tính toán mạnh mẽ, điều mà nhiều người thường bỏ qua.
Nói chung, vì dữ liệu xử lý trong suy luận thường nhỏ, yêu cầu về sức mạnh tính toán thấp hơn nhiều so với huấn luyện. Một chuyên gia trong ngành ước tính rằng, trong quá trình suy luận mô hình lớn bình thường, bộ nhớ video chủ yếu dành cho trọng số tham số mô hình, chiếm hơn 80%. Thực tế là, các mô hình mặc định bên trong ChatGPT đều nhỏ hơn mô hình 671B của DeepSeek-R1, cộng thêm ChatGPT có nhiều GPU hơn hẳn DeepSeek, do đó hiển nhiên thể hiện sự ổn định vượt trội so với DS-R1.
DeepSeek-V3 và R1 đều là mô hình 671B, quá trình khởi động mô hình chính là quá trình suy luận, nhu cầu về sức mạnh tính toán phải tương xứng với lượng người dùng. Ví dụ, có 100 triệu người dùng thì cần trang bị đủ card đồ họa cho 100 triệu người dùng – không chỉ quy mô lớn mà còn tách biệt hoàn toàn với tài nguyên tính toán dùng cho huấn luyện. Theo thông tin từ nhiều nguồn, rõ ràng DeepSeek thiếu hụt card đồ họa và tài nguyên tính toán, dẫn đến tình trạng giật lag liên tục.
Sự so sánh này khiến người dùng vốn quen với trải nghiệm mượt mà của ChatGPT cảm thấy không quen, đặc biệt là khi sự quan tâm đến R1 ngày càng tăng.
2. Giật, giật và vẫn là giật
Hơn nữa, nếu so sánh kỹ hơn, tình hình mà OpenAI và DeepSeek gặp phải rất khác nhau.
Bên kia có Microsoft hậu thuẫn, với tư cách là nền tảng độc quyền, dịch vụ đám mây Microsoft Azure tích hợp ChatGPT, công cụ tạo ảnh Dalle-E 2, công cụ mã hóa tự động GitHub Copilot; tổ hợp này sau đó trở thành mẫu hình kinh điển cloud+AI, nhanh chóng phổ biến thành tiêu chuẩn trong ngành. Bên này, dù là startup nhưng phần lớn tự xây dựng trung tâm dữ liệu, tương tự Google, không phụ thuộc vào nhà cung cấp điện toán đám mây bên thứ ba. Silicon Star kiểm tra thông tin công khai và phát hiện DeepSeek chưa từng hợp tác với bất kỳ nhà cung cấp đám mây hay chip nào ở mọi cấp độ (dù trong dịp Tết các nhà đám mây lần lượt tuyên bố chạy mô hình DeepSeek trên nền tảng của họ, nhưng thực tế không có bất kỳ hợp tác thực sự nào).
Hơn nữa, DeepSeek đang đối mặt với tốc độ tăng trưởng người dùng chưa từng có tiền lệ, điều đó cũng có nghĩa thời gian chuẩn bị cho các tình huống khẩn cấp ít hơn nhiều so với ChatGPT.
Hiệu suất tốt của DeepSeek đến từ tối ưu hóa tổng thể ở cấp độ phần cứng và hệ thống. Công ty mẹ của DeepSeek, Quantitative HFQ, đã chi 200 triệu NDT xây dựng cụm siêu máy tính Yinghuo No.1 từ năm 2019, đến năm 2022 âm thầm lưu trữ hàng vạn card A100, đồng thời tự phát triển khung huấn luyện HAI LLM nhằm phục vụ huấn luyện song song hiệu quả hơn. Ngành cho rằng cụm Yinghuo có thể sử dụng hàng nghìn đến hàng vạn GPU hiệu suất cao (như Nvidia A100/H100 hoặc chip nội địa), cung cấp khả năng tính toán song song mạnh mẽ. Hiện tại, cụm Yinghuo hỗ trợ huấn luyện các mô hình như DeepSeek-R1, DeepSeek-MoE, những mô hình này thể hiện khả năng sánh ngang GPT-4 trong các nhiệm vụ phức tạp như toán học, lập trình.
Cụm Yinghuo đại diện cho hành trình khám phá kiến trúc và phương pháp mới của DeepSeek, khiến bên ngoài cho rằng thông qua các công nghệ đổi mới này, DS giảm được chi phí huấn luyện, có thể đào tạo mô hình R1 đạt hiệu năng tương đương mô hình AI hàng đầu chỉ với một phần nhỏ sức mạnh tính toán so với mô hình tiên tiến nhất phương Tây. SemiAnalysis ước tính, DeepSeek thực tế sở hữu tài nguyên tính toán khổng lồ: tổng cộng tích lũy 60.000 card GPU Nvidia, bao gồm 10.000 A100, 10.000 H100, 10.000 H800 "phiên bản đặc biệt" và 30.000 H20 "phiên bản đặc biệt".
Điều này dường như cho thấy số lượng card cho R1 khá dồi dào. Nhưng thực tế, R1 là mô hình suy luận, đối trọng với O3 của OpenAI, loại mô hình suy luận này cần triển khai thêm sức mạnh tính toán cho khâu phản hồi. Tuy nhiên, hiện chưa rõ chi phí tính toán tiết kiệm được ở khâu huấn luyện và chi phí tăng vọt ở khâu suy luận, cái nào cao hơn.
Đáng chú ý, DeepSeek-V3 và DeepSeek-R1 đều là mô hình ngôn ngữ lớn, nhưng cách vận hành khác nhau. DeepSeek-V3 là mô hình lệnh, tương tự ChatGPT, nhận gợi ý và tạo văn bản phản hồi tương ứng. Còn DeepSeek-R1 là mô hình suy luận, khi người dùng đặt câu hỏi, nó sẽ thực hiện nhiều quá trình suy luận trước khi tạo ra câu trả lời cuối cùng. Các token do R1 tạo ra trước hết là chuỗi quá trình tư duy dài, mô hình sẽ giải thích vấn đề, phân tích vấn đề trước khi tạo câu trả lời, tất cả quá trình suy luận này đều được tạo nhanh dưới dạng token.
Theo ông Ôn Đình Sán, Phó Giám đốc耀途 Capital, lượng tính toán khổng lồ nói trên của DeepSeek là ở giai đoạn huấn luyện, giai đoạn này nhóm tính toán có thể lên kế hoạch, dự báo, khó xảy ra thiếu hụt. Nhưng tính toán suy luận thì bất định hơn, chủ yếu phụ thuộc vào quy mô người dùng và mức sử dụng, mang tính linh hoạt cao hơn: “Tính toán suy luận tăng theo quy luật nhất định, nhưng khi DeepSeek trở thành sản phẩm hiện tượng, quy mô người dùng và mức sử dụng bùng nổ trong thời gian ngắn, dẫn đến nhu cầu tính toán ở giai đoạn suy luận cũng bùng nổ, gây ra tình trạng giật lag.”
Một nhà thiết kế sản phẩm mô hình tích cực trên Jike, nhà phát triển độc lập Quy Tàng, đồng ý rằng nguyên nhân chính gây giật lag là do thiếu card. Anh cho rằng DS dù là ứng dụng di động được tải xuống nhiều nhất ở 140 thị trường toàn cầu, hiện tại dù có thêm card mới cũng không trụ nổi, vì “việc triển khai card mới lên đám mây cần thời gian”.
“Chi phí vận hành chip Nvidia A100, H100 mỗi giờ có giá thị trường công bằng. Xét về chi phí suy luận theo token xuất ra, DeepSeek rẻ hơn 90% so với mô hình o1 cùng loại của OpenAI, con số này không sai lệch nhiều so với tính toán của mọi người, do đó kiến trúc MOE của mô hình không phải vấn đề chính. Nhưng số lượng GPU mà DS sở hữu quyết định số token tối đa họ có thể sản xuất mỗi phút. Dù có thể dùng thêm GPU cho dịch vụ suy luận thay vì nghiên cứu huấn luyện trước, nhưng giới hạn vẫn tồn tại,” nhà phát triển Trần Vân Phi của ứng dụng AI nguyên sinh Xiao Mao Bu Guang Deng đưa ra quan điểm tương tự.
Cũng có chuyên gia trong ngành nói với Silicon Star rằng bản chất giật lag của DeepSeek nằm ở việc đám mây riêng chưa được chuẩn bị tốt.
Một yếu tố khác gây giật lag R1 là tấn công hacker. Ngày 30 tháng 1, truyền thông từ công ty an ninh mạng Qi An Xin cho biết cường độ tấn công vào dịch vụ DeepSeek trực tuyến đột ngột tăng mạnh, lệnh tấn công tăng gấp hàng trăm lần so với ngày 28 tháng 1. Phòng thí nghiệm Xlab của Qi An Xin ghi nhận ít nhất 2 mạng botnet tham gia tấn công.
Nhưng tình trạng giật lag dịch vụ R1 này có một giải pháp dường như rõ ràng: bên thứ ba cung cấp dịch vụ. Đây cũng là cảnh tượng sôi động nhất chúng ta chứng kiến trong dịp Tết – các nhà cung cấp đua nhau triển khai dịch vụ, đáp ứng nhu cầu của người dùng đối với DeepSeek.
Ngày 31 tháng 1, Nvidia tuyên bố NVIDIA NIM đã có thể sử dụng DeepSeek-R1, trước đó Nvidia bị ảnh hưởng bởi DeepSeek, một đêm mất gần 6000 tỷ USD vốn hóa thị trường. Cùng ngày, người dùng AWS có thể triển khai mô hình cơ sở R1 mới nhất của DeepSeek trên nền tảng AI Amazon Bedrock và Amazon SageMaker AI. Sau đó, các ứng dụng AI mới nổi như Perplexity, Cursor cũng đồng loạt tích hợp DeepSeek. Microsoft thậm chí còn nhanh hơn Amazon và Nvidia, triển khai DeepSeek-R1 lên Azure và Github trước.
Từ ngày mùng 4 Tết (1 tháng 2), Huawei Cloud, Alibaba Cloud, Volcano Engine thuộc ByteDance và Tencent Cloud cũng tham gia, thường cung cấp dịch vụ triển khai toàn bộ dòng và kích thước mô hình DeepSeek. Tiếp theo là các hãng chip AI như Biren Technology, Hanhai Semiconductor, Ascend, MXCHIP, tự tuyên bố đã thích nghi với phiên bản gốc DeepSeek hoặc phiên bản chưng cất nhỏ hơn. Về phần công ty phần mềm, Yonyou, Kingdee tích hợp mô hình DeepSeek vào một số sản phẩm để tăng sức mạnh. Cuối cùng là các hãng thiết bị đầu cuối như Lenovo, Huawei, Honor tích hợp mô hình DeepSeek vào một số sản phẩm làm trợ lý cá nhân và khoang lái thông minh ô tô.
Đến nay, DeepSeek đã thu hút được mạng lưới đối tác khổng lồ nhờ giá trị bản thân, bao gồm các nhà cung cấp đám mây trong và ngoài nước, nhà vận hành, công ty chứng khoán và nền tảng quốc gia như Internet siêu máy tính quốc gia. Vì mô hình DeepSeek-R1 hoàn toàn mã nguồn mở, các nhà cung cấp dịch vụ đều trở thành bên hưởng lợi từ mô hình DS. Điều này vừa nâng cao tiếng vang cho DS, đồng thời gây ra hiện tượng giật lag ngày càng thường xuyên, cả nhà cung cấp dịch vụ lẫn DS đều ngày càng bị áp lực bởi lượng người dùng đổ về ào ạt, nhưng vẫn chưa tìm ra then chốt giải quyết vấn đề sử dụng ổn định.
Xét thấy cả hai mô hình gốc DeepSeek V3 và R1 đều có tới 671 tỷ tham số, phù hợp chạy trên đám mây, bản thân các nhà đám mây có tài nguyên và khả năng suy luận dồi dào hơn, việc họ triển khai dịch vụ liên quan DeepSeek nhằm giảm ngưỡng sử dụng cho doanh nghiệp. Sau khi triển khai mô hình DeepSeek, họ cung cấp API mô hình DS bên ngoài, vốn được cho là mang lại trải nghiệm tốt hơn API do DS cung cấp.
Nhưng thực tế, vấn đề trải nghiệm vận hành mô hình R1 vẫn chưa được giải quyết ở các dịch vụ này. Bên ngoài cho rằng các nhà cung cấp không thiếu card, nhưng thực tế mô hình R1 họ triển khai vẫn nhận phản hồi từ nhà phát triển về trải nghiệm phản hồi không ổn định, tần suất hoàn toàn tương đương R1, chủ yếu vì lượng card phân bổ cho suy luận R1 cũng không nhiều.

“R1 duy trì độ nóng cao, nhà cung cấp phải cân nhắc các mô hình khác được tích hợp, lượng card dành cho R1 rất hạn chế, mà độ nóng R1 lại cao, bất kỳ ai vừa lên R1 với giá tương đối thấp sẽ bị sập ngay,” nhà thiết kế sản phẩm mô hình, nhà phát triển độc lập Quy Tàng giải thích nguyên nhân với Silicon Star.
Tối ưu triển khai mô hình là lĩnh vực rộng bao gồm nhiều khâu, từ hoàn thành huấn luyện đến triển khai thực tế trên phần cứng, liên quan đến nhiều mặt công việc, nhưng với sự kiện giật lag DeepSeek, nguyên nhân có thể đơn giản hơn, ví dụ như mô hình quá lớn và chuẩn bị tối ưu trước khi ra mắt chưa đủ.
Trước khi một mô hình lớn nổi bật ra mắt, sẽ gặp nhiều thách thức kỹ thuật, kỹ thuật và kinh doanh, như tính nhất quán giữa dữ liệu huấn luyện và dữ liệu môi trường sản xuất, ảnh hưởng của độ trễ dữ liệu và tính thời gian thực đến hiệu quả suy luận mô hình, hiệu suất suy luận trực tuyến và chiếm dụng tài nguyên quá cao, khả năng tổng quát hóa mô hình chưa đủ, cũng như các khía cạnh kỹ thuật như độ ổn định dịch vụ, tích hợp API và hệ thống.
Nhiều mô hình lớn nổi tiếng trước khi ra mắt đều rất coi trọng việc tối ưu suy luận, vì vấn đề thời gian tính toán và bộ nhớ: vấn đề trước là độ trễ suy luận quá dài, gây trải nghiệm người dùng kém, thậm chí không đáp ứng được yêu cầu độ trễ, tức hiện tượng giật lag; vấn đề sau là tham số mô hình nhiều, tiêu tốn bộ nhớ video, thậm chí một card GPU đơn lẻ không chứa nổi, cũng gây giật lag.
Ôn Đình Sán giải thích với Silicon Star, nhà cung cấp dịch vụ gặp thách thức khi cung cấp R1 về bản chất là do cấu trúc mô hình DS đặc biệt, mô hình quá lớn + kiến trúc MOE (Mixture of Experts - hỗn hợp chuyên gia, cách tính toán hiệu quả), “(nhà cung cấp) cần thời gian tối ưu, nhưng nhiệt độ thị trường có cửa sổ thời gian, nên đều chọn triển khai trước rồi tối ưu sau, chứ không phải tối ưu đầy đủ rồi mới ra mắt.”
Để R1 vận hành ổn định, hiện nay then chốt nằm ở năng lực dự trữ và tối ưu phía suy luận. Điều DeepSeek cần làm là tìm cách giảm chi phí suy luận, giảm lượng card đầu ra, giảm số lượng token xuất ra mỗi lần.
Đồng thời, tình trạng giật lag cũng cho thấy tài nguyên tính toán thực tế của DS có lẽ không lớn như SemiAnalysis mô tả, công ty quỹ HFQ cần dùng card, đội huấn luyện DeepSeek cũng cần dùng card, lượng card dành cho người dùng luôn không nhiều. Theo tình hình phát triển hiện tại, trong ngắn hạn DeepSeek có thể chưa có động lực chi tiền thuê dịch vụ để cung cấp trải nghiệm tốt hơn miễn phí cho người dùng, họ có lẽ sẽ đợi khi mô hình kinh doanh C端 rõ ràng hơn rồi mới xem xét vấn đề thuê dịch vụ, điều này cũng có nghĩa tình trạng giật lag sẽ còn kéo dài một thời gian không ngắn.
“Họ có lẽ cần hai bước: 1) Thiết lập cơ chế trả phí, giới hạn lượng dùng mô hình của người dùng miễn phí; 2) Hợp tác với nhà cung cấp dịch vụ đám mây, sử dụng tài nguyên GPU của bên khác.” Giải pháp tạm thời do nhà phát triển Trần Vân Phi đưa ra được nhiều người trong ngành đồng thuận.
Nhưng hiện tại, DeepSeek dường như không mấy lo lắng về vấn đề “máy chủ quá tải” này. Là một công ty theo đuổi AGI, DeepSeek dường như không muốn quá tập trung vào lượng người dùng ào ạt đổ về. Có thể người dùng sẽ phải quen với giao diện “máy chủ quá tải” trong một thời gian dài sắp tới.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News















