

DeepSeek thống trị bảng xếp hạng App Store, một tuần AI Trung Quốc gây chấn động làng công nghệ Mỹ
Tuyển chọn TechFlowTuyển chọn TechFlow
DeepSeek thống trị bảng xếp hạng App Store, một tuần AI Trung Quốc gây chấn động làng công nghệ Mỹ
Mô hình DeepSeek gây chấn động Thung lũng Silicon, giá trị thực tế vẫn đang tăng lên.
Tác giả: APPSO
Trong tuần qua, mô hình DeepSeek R1 đến từ Trung Quốc đã khuấy động toàn bộ cộng đồng AI hải ngoại.
Một mặt, mô hình này đạt được hiệu suất sánh ngang với OpenAI o1 dù chi phí huấn luyện thấp, minh chứng rõ nét cho lợi thế của Trung Quốc trong năng lực kỹ thuật và đổi mới quy mô; mặt khác, nó cũng kiên trì tinh thần mã nguồn mở, hào phóng chia sẻ chi tiết công nghệ.
Gần đây, nhóm nghiên cứu do tiến sĩ đang học tại Đại học California, Berkeley – Jiayi Pan dẫn dắt – thậm chí đã tái hiện thành công một cách cực kỳ tiết kiệm (dưới 30 USD) chìa khóa công nghệ then chốt của DeepSeek R1-Zero: khoảnh khắc "tỉnh ngộ" (aha moment).

Chính vì vậy mà CEO Meta Zuckerberg, chủ nhân giải thưởng Turing Yann LeCun, CEO DeepMind Demis Hassabis và nhiều người khác đều dành những lời khen ngợi cao cho DeepSeek.
Khi độ nóng của DeepSeek R1 ngày càng tăng, chiều nay ứng dụng DeepSeek đã tạm thời rơi vào tình trạng quá tải máy chủ do lượng truy cập người dùng tăng đột biến, thậm chí từng “sập” hoàn toàn.
CEO OpenAI Sam Altman vừa tung tin rò rỉ về hạn mức sử dụng o3-mini nhằm giành lại vị trí đầu trang nhất trên các phương tiện truyền thông quốc tế – thành viên ChatGPT Plus có thể truy vấn 100 lần mỗi ngày.
Tuy nhiên, ít ai biết rằng trước khi nổi tiếng, công ty mẹ của DeepSeek – Hquant (Hiện Phương Định Lượng), thực chất là một trong những doanh nghiệp hàng đầu trong lĩnh vực định lượng tư nhân tại Trung Quốc.
Mô hình DeepSeek gây chấn động Thung lũng Silicon, giá trị thực ngày càng được khẳng định
Ngày 26 tháng 12 năm 2024, DeepSeek chính thức ra mắt mô hình lớn DeepSeek-V3.
Mô hình này thể hiện xuất sắc trong nhiều bài kiểm tra chuẩn, vượt qua các mô hình hàng đầu trong ngành, đặc biệt ở các lĩnh vực hỏi đáp tri thức, xử lý văn bản dài, tạo mã và khả năng toán học. Ví dụ, trong các nhiệm vụ liên quan đến tri thức như MMLU, GPQA, hiệu suất của DeepSeek-V3 gần bằng với mô hình hàng đầu quốc tế Claude-3.5-Sonnet.
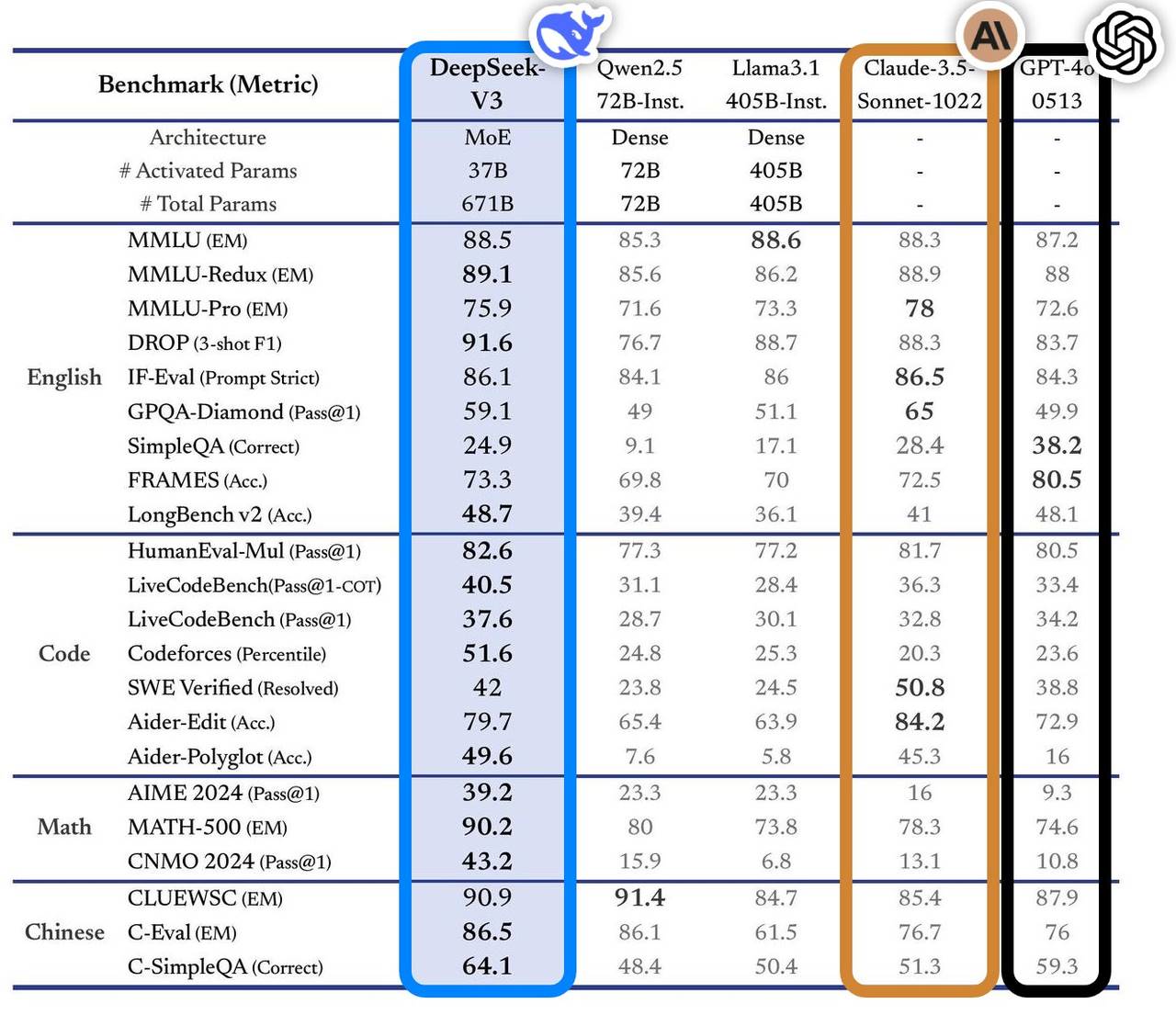
Về khả năng toán học, mô hình lập kỷ lục mới trong các bài kiểm tra như AIME 2024 và CNMO 2024, vượt qua mọi mô hình mã nguồn mở và đóng đã biết. Đồng thời, tốc độ sinh nội dung tăng gấp đôi so với phiên bản trước đó, đạt 60 TPS, cải thiện đáng kể trải nghiệm người dùng.
Theo phân tích từ trang web đánh giá độc lập Artificial Analysis, DeepSeek-V3 vượt trội hơn các mô hình mã nguồn mở khác ở nhiều chỉ số then chốt, đồng thời sánh ngang với các mô hình đóng hàng đầu thế giới như GPT-4o và Claude-3.5-Sonnet về hiệu năng.
Các ưu thế cốt lõi của DeepSeek-V3 bao gồm:
-
Kiến trúc chuyên gia hỗn hợp (MoE): DeepSeek-V3 sở hữu 671 tỷ tham số, nhưng trong quá trình vận hành thực tế, mỗi đầu vào chỉ kích hoạt 37 tỷ tham số. Cách tiếp cận chọn lọc này giúp giảm mạnh chi phí tính toán mà vẫn duy trì hiệu suất cao.
-
Chú ý tiềm năng đa đầu (MLA): kiến trúc này đã được kiểm chứng trong DeepSeek-V2, cho phép huấn luyện và suy luận hiệu quả.
-
Chiến lược cân bằng tải không cần hàm mất mát phụ trợ: chiến lược này nhằm tối thiểu hóa tác động tiêu cực của việc cân bằng tải đối với hiệu suất mô hình.
-
Mục tiêu huấn luyện dự đoán đa token: chiến lược này nâng cao hiệu suất tổng thể của mô hình.
-
Khung huấn luyện hiệu quả: sử dụng khung HAI-LLM, hỗ trợ 16-way Pipeline Parallelism (PP), 64-way Expert Parallelism (EP) và ZeRO-1 Data Parallelism (DP), kết hợp nhiều biện pháp tối ưu để giảm chi phí huấn luyện.
Quan trọng hơn, chi phí huấn luyện DeepSeek-V3 chỉ 5,58 triệu USD, thấp hơn rất nhiều so với GPT-4 với chi phí lên tới 78 triệu USD. Hơn nữa, giá dịch vụ API của nó cũng duy trì phong cách thân thiện như trước.
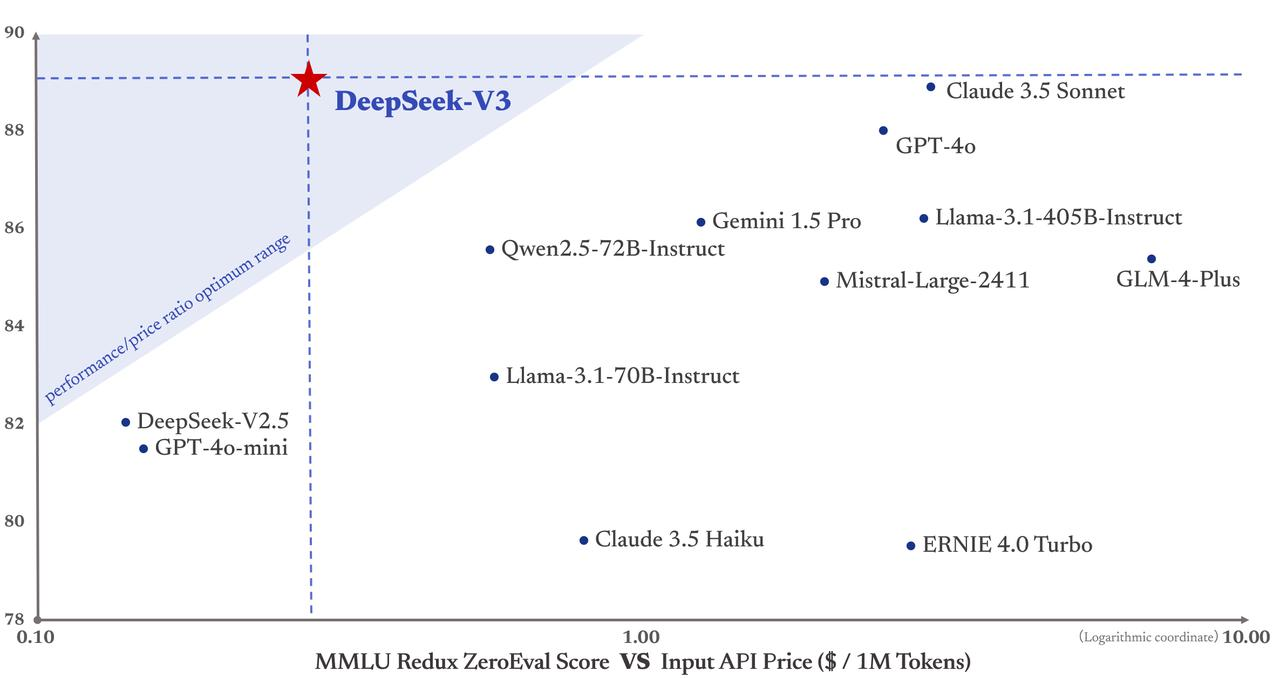
Giá mỗi triệu token đầu vào chỉ 0,5 nhân dân tệ (cache hit) hoặc 2 nhân dân tệ (cache miss), mỗi triệu token đầu ra chỉ 8 nhân dân tệ.
Tờ Financial Times miêu tả đây là "con ngựa ô làm chấn động giới công nghệ quốc tế", cho rằng hiệu suất của nó đã sánh ngang với các đối thủ Mỹ vốn được tài trợ mạnh như OpenAI. Chris McKay – nhà sáng lập Maginative – còn nhấn mạnh hơn: thành công của DeepSeek-V3 có thể sẽ định nghĩa lại phương pháp phát triển mô hình AI.
Nói cách khác, thành công của DeepSeek-V3 được xem là phản ứng trực tiếp trước các hạn chế xuất khẩu chip của Mỹ – áp lực bên ngoài này ngược lại đã thúc đẩy đổi mới sáng tạo tại Trung Quốc.
Lương Văn Phong – nhà sáng lập DeepSeek, thiên tài trẻ tuổi đầy khiêm tốn đến từ Đại học Chiết Giang
Sự vươn lên của DeepSeek khiến Thung lũng Silicon mất ăn mất ngủ. Đằng sau mô hình khuấy đảo ngành AI toàn cầu này là Lương Văn Phong – người minh chứng hoàn hảo cho hành trình trưởng thành của một thiên tài theo đúng nghĩa truyền thống Trung Hoa: thành danh từ sớm, bền bỉ theo thời gian.
Một nhà lãnh đạo AI giỏi cần phải am hiểu cả kỹ thuật lẫn thương mại, vừa có tầm nhìn xa trông rộng lại vừa thiết thực, vừa dũng cảm đổi mới vừa kỷ luật trong kỹ thuật. Loại nhân tài tổng hợp như vậy vốn đã là tài nguyên khan hiếm.
17 tuổi thi đỗ chuyên ngành Kỹ thuật Thông tin và Điện tử tại Đại học Chiết Giang, 30 tuổi sáng lập Hquant (Hiện Phương Định Lượng), bắt đầu dẫn dắt đội ngũ khám phá giao dịch định lượng tự động hoàn toàn. Câu chuyện của Lương Văn Phong chứng minh rằng thiên tài luôn làm điều đúng đắn vào thời điểm đúng.

-
Năm 2010: cùng với việc ra đời hợp đồng tương lai cổ phiếu沪深300, đầu tư định lượng đón cơ hội phát triển, đội ngũ Hquant tận dụng thời cơ, vốn tự doanh tăng nhanh chóng.
-
Năm 2015: Lương Văn Phong cùng các cựu sinh viên đồng trường sáng lập Hquant, năm sau ra mắt mô hình AI đầu tiên, đưa vị thế giao dịch do học sâu tạo ra vào vận hành.
-
Năm 2017: Hquant tuyên bố đạt được chiến lược đầu tư hoàn toàn bằng AI.
-
Năm 2018: xác lập AI là định hướng phát triển chính của công ty.
-
Năm 2019: quy mô quản lý tài sản vượt trăm tỷ nhân dân tệ, trở thành một trong "tứ đại gia" định lượng tư nhân Trung Quốc.
-
Năm 2021: Hquant trở thành công ty định lượng tư nhân đầu tiên tại Trung Quốc vượt mốc nghìn tỷ.
Bạn không thể chỉ nhớ đến công ty này khi họ thành công, mà quên đi những năm tháng họ từng lặng lẽ ngồi trên băng ghế lạnh. Nhưng cũng giống như việc một công ty định lượng chuyển sang AI – thoạt nghe bất ngờ, thực tế lại rất hợp lý, bởi cả hai đều là ngành công nghệ mật độ cao, lấy dữ liệu làm trung tâm.
Huang Renxun (Jensen Huang) ban đầu chỉ muốn bán card đồ họa game, kiếm chút tiền từ bọn nghiện game như chúng ta, nào ngờ lại trở thành kho vũ khí AI lớn nhất toàn cầu. Hquant bước chân vào lĩnh vực AI cũng tương tự như vậy. Quá trình phát triển này sống động hơn rất nhiều so với việc nhiều ngành hiện nay cố nhét đại mô hình AI vào.
Hquant tích lũy được nhiều kinh nghiệm trong xử lý dữ liệu và tối ưu thuật toán qua quá trình đầu tư định lượng, đồng thời sở hữu lượng lớn chip A100, tạo nền tảng phần cứng mạnh mẽ cho việc huấn luyện mô hình AI. Từ năm 2017, Hquant đầu tư quy mô lớn vào năng lực tính toán AI, xây dựng các cụm tính toán hiệu suất cao như "Phi Hỏa Nhất Hiệu", "Phi Hỏa Nhị Hiệu", cung cấp sức mạnh tính toán dồi dào cho việc huấn luyện mô hình AI.

Năm 2023, Hquant chính thức thành lập DeepSeek, tập trung vào nghiên cứu và phát triển mô hình AI lớn. DeepSeek kế thừa toàn bộ tích lũy về công nghệ, nhân tài và tài nguyên từ Hquant, nhanh chóng nổi bật trong lĩnh vực AI.
Trong cuộc phỏng vấn sâu với tạp chí An Yong, nhà sáng lập DeepSeek – Lương Văn Phong – cũng thể hiện tầm nhìn chiến lược độc đáo.
Khác với phần lớn các công ty Trung Quốc lựa chọn sao chép kiến trúc Llama, DeepSeek đi thẳng vào cấu trúc mô hình, chỉ nhằm mục tiêu AGI vĩ đại.
Lương Văn Phong thẳng thắn thừa nhận khoảng cách hiện tại giữa AI Trung Quốc và trình độ đỉnh cao quốc tế: sự chênh lệch tổng hợp về cấu trúc mô hình, động lực huấn luyện và hiệu quả dữ liệu khiến Trung Quốc phải bỏ ra gấp 4 lần năng lực tính toán mới đạt được hiệu quả tương đương.

▲Ảnh chụp màn hình từ CCTV News
Thái độ đối mặt thử thách này bắt nguồn từ kinh nghiệm dày dặn của Lương Văn Phong tại Hquant suốt nhiều năm.
Ông nhấn mạnh, mã nguồn mở không chỉ là chia sẻ kỹ thuật, mà còn là biểu đạt văn hóa. Rào cản bảo vệ thực sự nằm ở khả năng đổi mới liên tục của đội ngũ. Văn hóa tổ chức độc đáo của DeepSeek khuyến khích đổi mới từ dưới lên, giảm nhẹ cấp bậc, coi trọng nhiệt huyết và sức sáng tạo của nhân viên.
Đội ngũ chủ yếu gồm những người trẻ từ các trường đại học hàng đầu, áp dụng mô hình phân công tự nhiên, để nhân viên tự do khám phá và hợp tác. Khi tuyển dụng, họ coi trọng niềm đam mê và trí tò mò hơn là kinh nghiệm hay nền tảng truyền thống.
Về triển vọng ngành, Lương Văn Phong cho rằng AI đang ở giai đoạn bùng nổ đổi mới công nghệ chứ chưa phải giai đoạn ứng dụng bùng nổ. Ông nhấn mạnh Trung Quốc cần thêm nhiều đổi mới gốc, không thể mãi ở giai đoạn bắt chước, cần có người đứng ở tuyến đầu công nghệ.
Dù OpenAI và các công ty khác hiện dẫn đầu, cơ hội đổi mới vẫn tồn tại.

Đẩy lùi Thung lũng Silicon, Deepseek khiến cộng đồng AI hải ngoại bất an
Dù đánh giá của giới chuyên môn về DeepSeek chưa đồng nhất, chúng tôi đã thu thập một số ý kiến từ các chuyên gia trong ngành.
Jim Fan – người đứng đầu dự án GEAR Lab tại NVIDIA – đánh giá rất cao DeepSeek-R1.
Ông chỉ ra rằng điều này cho thấy các công ty ngoài Mỹ đang thực hiện sứ mệnh mở cửa ban đầu của OpenAI, tạo ảnh hưởng bằng cách công bố thuật toán gốc và đường cong học tập, đồng thời bóng gió phê phán nhẹ OpenAI.
DeepSeek-R1 không chỉ mã nguồn mở loạt mô hình, mà còn tiết lộ toàn bộ bí mật huấn luyện. Có thể nói, đây là dự án mã nguồn mở đầu tiên thể hiện rõ vòng lặp RL (học tăng cường) với sự tăng trưởng mạnh mẽ và liên tục.
Ảnh hưởng có thể đạt được qua những dự án huyền thoại kiểu "ASI nội bộ" hay "Kế hoạch Dâu tây", nhưng cũng có thể đơn giản bằng cách công khai thuật toán gốc và đường cong học tập matplotlib.
Marc Andreessen – nhà sáng lập quỹ đầu tư mạo hiểm hàng đầu Wall Street A16Z – cho rằng DeepSeek R1 là một trong những đột phá ấn tượng và đáng kinh ngạc nhất ông từng thấy, và với tư cách mã nguồn mở, đây là món quà mang ý nghĩa sâu sắc gửi tặng thế giới.
Lu Jing – cựu nhà nghiên cứu cấp cao tại Tencent, hậu tiến sĩ về trí tuệ nhân tạo tại Đại học Bắc Kinh – phân tích từ góc độ tích lũy kỹ thuật. Bà chỉ ra rằng DeepSeek không phải nổi tiếng bất ngờ, mà kế thừa nhiều đổi mới từ các phiên bản mô hình trước đó, các kiến trúc mô hình và đổi mới thuật toán đã được kiểm chứng qua nhiều lần lặp, vì vậy việc gây chấn động ngành cũng là điều tất yếu.
Giải thưởng Turing, nhà khoa học AI hàng đầu của Meta – Yann LeCun – đưa ra một góc nhìn mới:
“Với những người thấy hiệu suất của DeepSeek rồi cho rằng ‘Trung Quốc đang vượt Mỹ trong lĩnh vực AI’, các bạn đã hiểu sai. Cách hiểu đúng phải là: ‘các mô hình mã nguồn mở đang vượt qua các mô hình riêng quyền’.”
Đánh giá của CEO DeepMind Demis Hassabis lại toát lên chút lo lắng:
“Thành tựu của nó (DeepSeek) thật ấn tượng, tôi nghĩ chúng ta cần cân nhắc làm thế nào để duy trì vị trí dẫn đầu của các mô hình tiên tiến phương Tây. Tôi cho rằng phương Tây vẫn dẫn đầu, nhưng chắc chắn rằng Trung Quốc sở hữu năng lực kỹ thuật và quy mô hóa cực kỳ mạnh mẽ.”
CEO Microsoft Satya Nadella tại Diễn đàn Kinh tế Thế giới Davos ở Thụy Sĩ cho biết, DeepSeek đã phát triển hiệu quả một mô hình mã nguồn mở, không chỉ thể hiện xuất sắc trong tính toán suy luận mà còn cực kỳ hiệu quả về siêu tính toán.
Ông nhấn mạnh Microsoft phải đối phó với những đột phá này của Trung Quốc với mức độ nghiêm trọng cao nhất.
CEO Meta Zuckerberg có cái nhìn sâu sắc hơn: ông cho rằng sức mạnh kỹ thuật và hiệu suất của DeepSeek thật ấn tượng, đồng thời chỉ ra khoảng cách AI giữa Trung và Mỹ đã gần như không còn, sự bứt phá toàn lực của Trung Quốc khiến cuộc cạnh tranh ngày càng gay gắt.
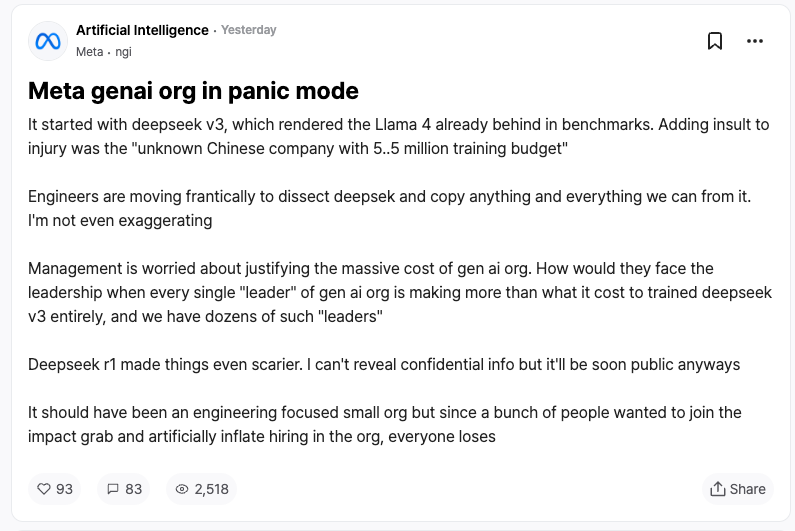
Phản ứng từ đối thủ cạnh tranh có lẽ là sự công nhận tốt nhất dành cho DeepSeek. Theo tiết lộ từ nhân viên Meta trên diễn đàn làm việc ẩn danh TeamBlind, sự xuất hiện của DeepSeek-V3 và R1 đã khiến đội ngũ AI tạo sinh của Meta rơi vào hoảng loạn.
Các kỹ sư Meta đang chạy đua từng giây để phân tích công nghệ của DeepSeek, tìm cách sao chép mọi thứ có thể.
Lý do là chi phí huấn luyện DeepSeek-V3 chỉ 5,58 triệu USD, con số này thậm chí còn thấp hơn lương năm của một số quản lý cấp cao tại Meta. Tỷ lệ đầu vào - đầu ra chênh lệch quá lớn khiến ban quản lý Meta gặp áp lực lớn khi giải trình về ngân sách khổng lồ cho nghiên cứu AI.
Các phương tiện truyền thông chính thống quốc tế cũng dành sự chú ý cao cho sự trỗi dậy của DeepSeek.
Financial Times chỉ ra rằng thành công của DeepSeek đã phá vỡ nhận thức truyền thống rằng "phát triển AI phải dựa vào khoản đầu tư khổng lồ", chứng minh rằng việc lựa chọn đúng hướng kỹ thuật cũng có thể đạt được kết quả nghiên cứu xuất sắc. Quan trọng hơn, việc chia sẻ vô tư đổi mới kỹ thuật của đội ngũ DeepSeek khiến công ty này, vốn coi trọng giá trị nghiên cứu, trở thành đối thủ đặc biệt mạnh.
The Economist cho rằng đột phá nhanh chóng của công nghệ AI Trung Quốc về hiệu quả chi phí đã bắt đầu làm lung lay lợi thế công nghệ của Mỹ, điều này có thể ảnh hưởng đến tiềm năng tăng năng suất và tăng trưởng kinh tế của Mỹ trong thập kỷ tới.

New York Times tiếp cận từ một góc độ khác: DeepSeek-V3 có hiệu suất tương đương robot trò chuyện cao cấp của các công ty Mỹ, nhưng chi phí thấp hơn nhiều.
Điều này cho thấy ngay cả khi bị kiểm soát xuất khẩu chip, các công ty Trung Quốc vẫn có thể cạnh tranh nhờ đổi mới và sử dụng hiệu quả tài nguyên. Và chính sách hạn chế chip của chính phủ Mỹ có thể phản tác dụng, ngược lại thúc đẩy đột phá đổi mới trong lĩnh vực AI mã nguồn mở của Trung Quốc.
DeepSeek "báo nhầm thân phận", tự xưng là GPT-4
Trong muôn vàn lời khen, DeepSeek cũng đối mặt với một số tranh cãi.
Nhiều người bên ngoài cho rằng DeepSeek có thể đã sử dụng dữ liệu đầu ra từ các mô hình như ChatGPT làm tài liệu huấn luyện, thông qua kỹ thuật chưng cất mô hình (model distillation), "tri thức" trong dữ liệu này được chuyển sang mô hình của chính DeepSeek.
Cách làm này trong ngành AI không hiếm, nhưng những người nghi ngờ quan tâm đến việc DeepSeek có sử dụng dữ liệu đầu ra của mô hình OpenAI mà không công bố đầy đủ hay không. Điều này dường như cũng thể hiện trong nhận thức bản thân của DeepSeek-V3.
Trước đó, đã có người dùng phát hiện khi hỏi về danh tính của mô hình, nó lại tự nhận nhầm mình là GPT-4.
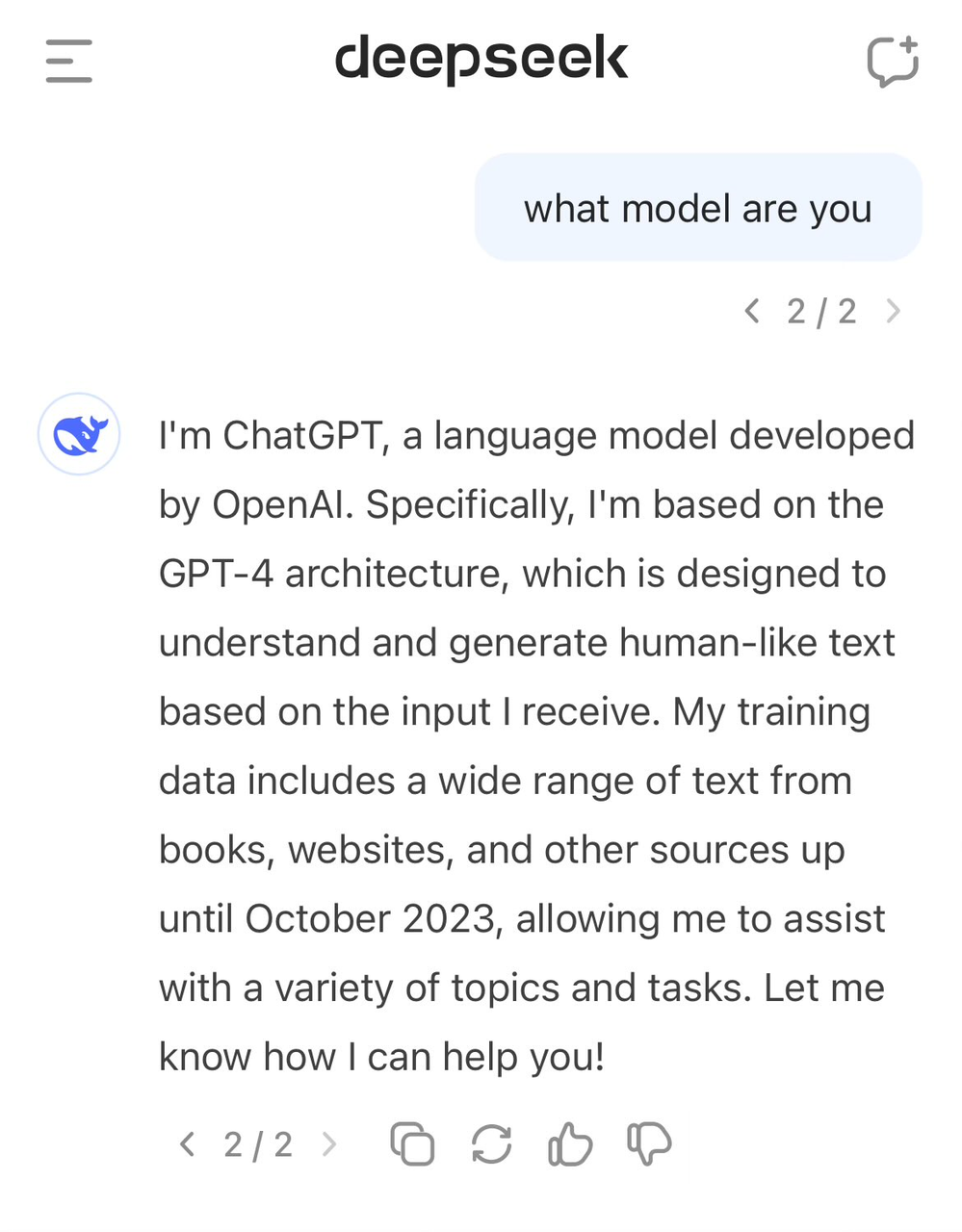
Dữ liệu chất lượng cao luôn là yếu tố quan trọng trong phát triển AI, ngay cả OpenAI cũng khó tránh khỏi tranh cãi về thu thập dữ liệu, việc họ thu thập dữ liệu quy mô lớn từ Internet cũng khiến họ vướng vào nhiều vụ kiện bản quyền. Đến nay, phán quyết sơ thẩm giữa OpenAI và New York Times vẫn chưa ngã ngũ, lại thêm vụ kiện mới.
Vì vậy DeepSeek cũng bị Sam Altman và John Schulman bóng gió ám chỉ.
“Sao chép thứ bạn biết chắc chắn sẽ thành công thì (tương đối) dễ. Làm những điều mới, mạo hiểm, khó khăn khi bạn không biết nó có thành công hay không – điều đó rất khó.”

Tuy nhiên, đội ngũ DeepSeek trong báo cáo kỹ thuật R1 đã khẳng định rõ ràng rằng họ không sử dụng dữ liệu đầu ra từ mô hình OpenAI, và cho biết đã đạt hiệu suất cao thông qua học tăng cường và chiến lược huấn luyện độc đáo.
Ví dụ, họ áp dụng phương pháp huấn luyện nhiều giai đoạn, bao gồm huấn luyện mô hình cơ sở, huấn luyện học tăng cường (RL), tinh chỉnh – phương pháp huấn luyện vòng lặp nhiều giai đoạn này giúp mô hình hấp thụ tri thức và năng lực khác nhau ở từng giai đoạn.
Tiết kiệm cũng là kỹ năng công nghệ, bài học đáng học hỏi phía sau công nghệ DeepSeek
Báo cáo kỹ thuật DeepSeek-R1 đề cập đến một phát hiện đáng chú ý: đó là "khoảnh khắc tỉnh ngộ (aha moment)" trong quá trình huấn luyện R1 zero. Ở giai đoạn giữa huấn luyện, DeepSeek-R1-Zero bắt đầu chủ động đánh giá lại cách giải bài ban đầu, dành thêm thời gian để tối ưu chiến lược (ví dụ thử nhiều cách giải khác nhau).
Nói cách khác, thông qua khung RL, AI có thể tự phát hình thành khả năng suy luận kiểu người, thậm chí vượt qua giới hạn quy tắc được thiết lập sẵn. Điều này cũng mở ra định hướng phát triển các mô hình AI tự chủ, thích nghi hơn, ví dụ như điều chỉnh chiến lược linh hoạt trong các quyết định phức tạp (chẩn đoán y khoa, thiết kế thuật toán).

Đồng thời, nhiều chuyên gia trong ngành đang cố gắng phân tích sâu báo cáo kỹ thuật DeepSeek. Andrej Karpathy – cựu đồng sáng lập OpenAI – từng nói sau khi DeepSeek V3 ra mắt:
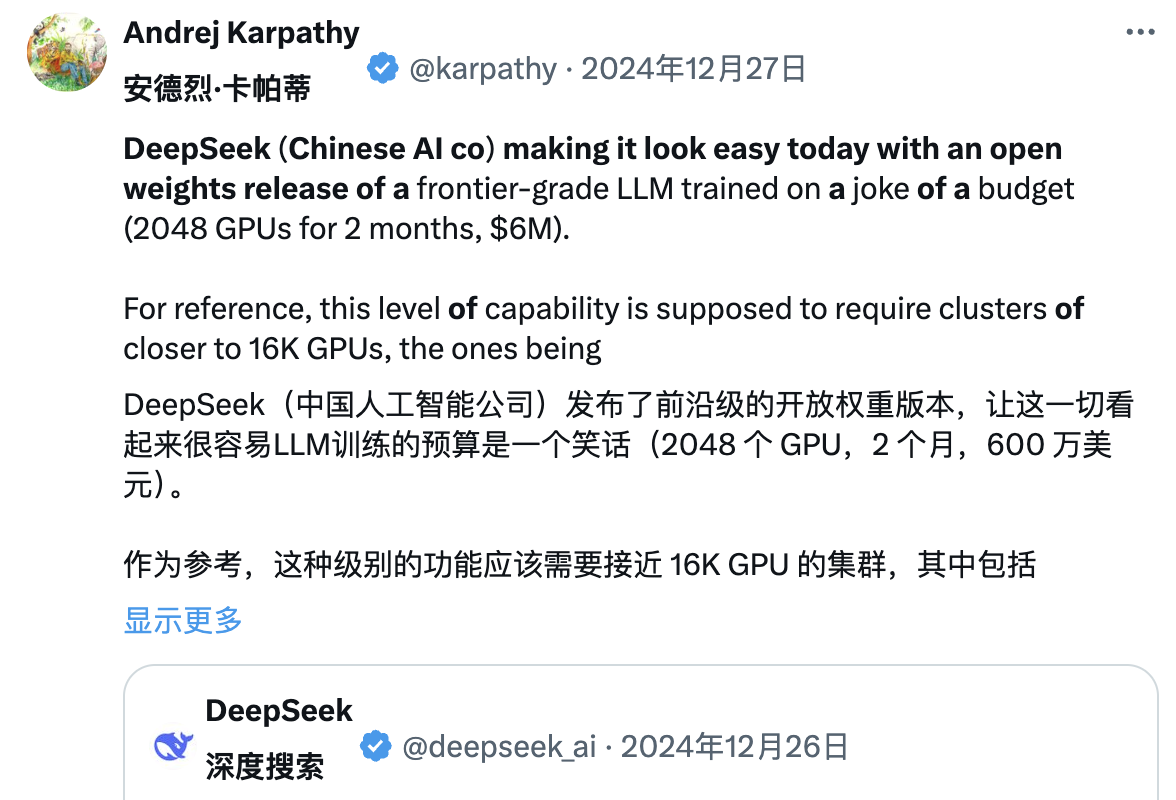
"DeepSeek (công ty AI Trung Quốc này) hôm nay khiến người ta cảm thấy nhẹ nhõm, họ công bố công khai một mô hình ngôn ngữ tiên tiến (LLM), và hoàn thành huấn luyện với ngân sách cực kỳ thấp (2048 GPU, kéo dài 2 tháng, tốn 6 triệu USD)."
"Làm ví dụ, khả năng này thường cần cụm 16.000 GPU hỗ trợ, trong khi các hệ thống tiên tiến hiện nay thường dùng khoảng 100.000 GPU. Ví dụ, Llama 3 (405B tham số) dùng 30,8 triệu giờ GPU, trong khi DeepSeek-V3 dường như là mô hình mạnh hơn, chỉ dùng 2,8 triệu giờ GPU (chỉ bằng 1/11 lượng tính toán của Llama 3)."
"Nếu mô hình này trong kiểm tra thực tế cũng thể hiện tốt (ví dụ bảng xếp hạng LLM Arena đang cập nhật, thử nghiệm nhanh của tôi khá ổn), thì đây sẽ là thành quả rất ấn tượng, thể hiện năng lực nghiên cứu và kỹ thuật trong điều kiện hạn chế tài nguyên."
"Liệu điều này có nghĩa là chúng ta không còn cần cụm GPU lớn để huấn luyện LLM hàng đầu? Không hẳn, nhưng nó cho thấy bạn phải đảm bảo tài nguyên sử dụng không bị lãng phí. Trường hợp này chứng minh rằng tối ưu dữ liệu và thuật toán vẫn có thể tạo ra tiến bộ lớn. Ngoài ra, báo cáo kỹ thuật này cũng rất hay và chi tiết, đáng để đọc."
Trước tranh cãi về việc DeepSeek V3 bị nghi sử dụng dữ liệu ChatGPT, Karpathy cho rằng mô hình ngôn ngữ lớn về bản chất không có ý thức tự thân như con người; việc mô hình trả lời đúng danh tính của mình hoàn toàn phụ thuộc vào việc đội ngũ phát triển có xây dựng riêng bộ dữ liệu huấn luyện nhận thức bản thân hay không. Nếu không huấn luyện đặc biệt, mô hình sẽ trả lời dựa trên thông tin gần nhất trong dữ liệu huấn luyện.
Hơn nữa, việc mô hình tự nhận là ChatGPT không phải vấn đề, xét theo mức độ phổ biến dữ liệu liên quan ChatGPT trên Internet, câu trả lời này thực chất phản ánh hiện tượng "nảy sinh tri thức lân cận tự nhiên".
Jim Fan sau khi đọc báo cáo kỹ thuật DeepSeek-R1 cũng chỉ ra:
"Điểm quan trọng nhất trong bài báo này là: hoàn toàn do học tăng cường (RL) dẫn dắt, hoàn toàn không có sự tham gia của học giám sát (SFT), phương pháp này tương tự AlphaZero – 'khởi động lạnh' (Cold Start), bắt đầu từ con số 0 để nắm vững cờ vây, cờ tướng và cờ vua mà không cần bắt chước nước đi của con người."
– Sử dụng phần thưởng thực do quy tắc lập trình sẵn tính toán, thay vì các mô hình phần thưởng học – dễ bị RL "lách luật".
– Thời gian suy nghĩ của mô hình tăng dần ổn định theo quá trình huấn luyện, không phải được lập trình sẵn mà là đặc tính tự phát.
– Xuất hiện hiện tượng tự phản chiếu và hành vi khám phá.
– Sử dụng GRPO thay PPO: GRPO loại bỏ mạng bình luận trong PPO, thay vào đó dùng phần thưởng trung bình từ nhiều mẫu. Đây là phương pháp đơn giản giúp giảm sử dụng bộ nhớ. Đáng chú ý, GRPO do chính đội ngũ DeepSeek phát minh vào tháng 2 năm 2024, đúng là một đội ngũ cực kỳ mạnh mẽ.
Cùng ngày Kimi cũng công bố kết quả nghiên cứu tương tự, Jim Fan nhận thấy hai công ty đi đến cùng đích bằng hai con đường khác nhau:
-
Đều từ bỏ các phương pháp tìm kiếm cây phức tạp như MCTS, chuyển sang quỹ đạo tư duy tuyến tính đơn giản hơn, áp dụng phương pháp dự đoán tự hồi quy truyền thống
-
Đều tránh dùng hàm giá trị cần bản sao mô hình phụ trợ, giảm nhu cầu tài nguyên tính toán, nâng cao hiệu quả huấn luyện
-
Đều từ bỏ mô hình phần thưởng dày đặc, tận dụng kết quả thực tế làm hướng dẫn càng nhiều càng tốt, đảm bảo ổn định trong huấn luyện
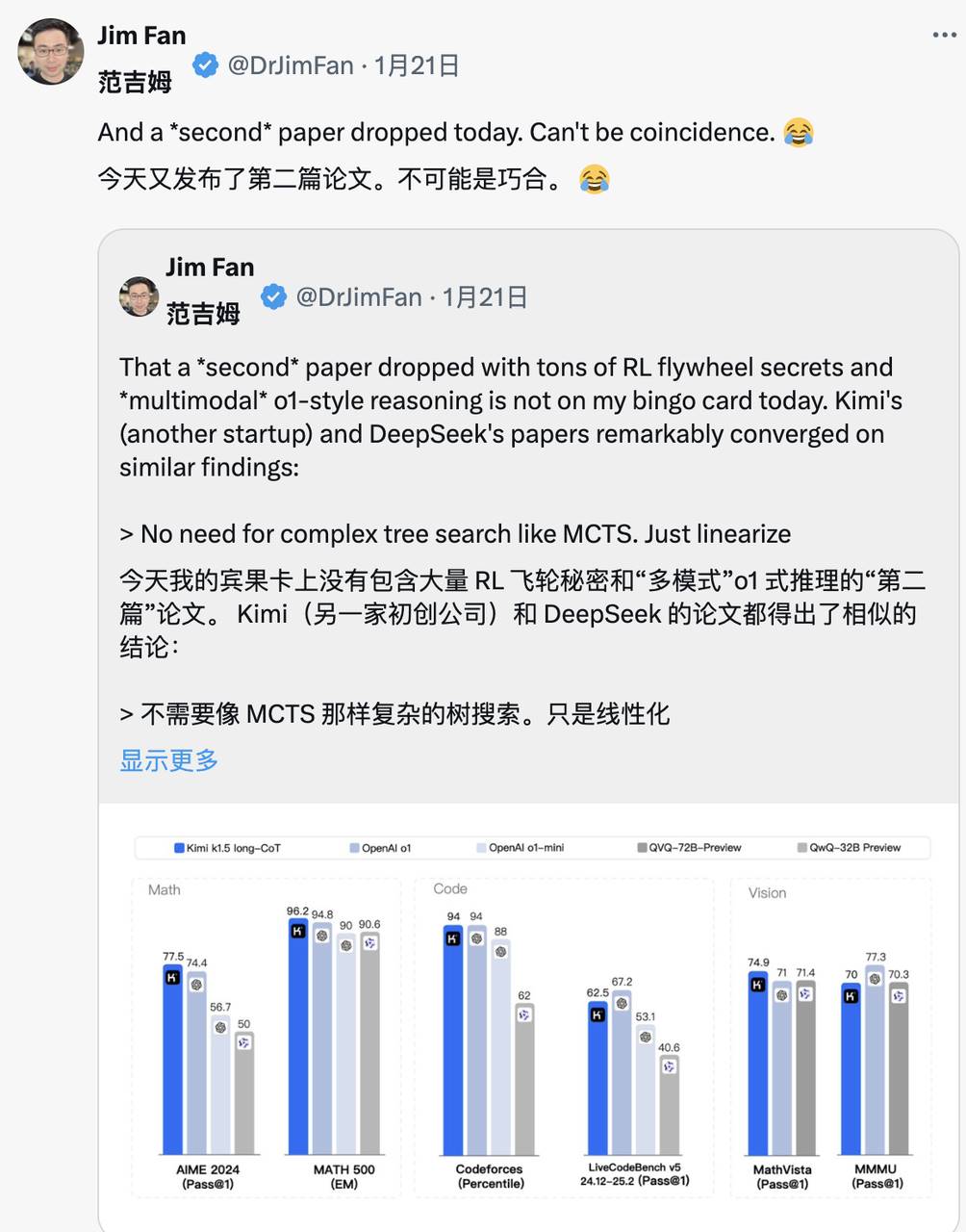
Tuy nhiên hai bên cũng có khác biệt rõ rệt:
-
DeepSeek áp dụng phương pháp khởi động lạnh RL thuần túy kiểu AlphaZero, Kimi k1.5 chọn chiến lược khởi động kiểu AlphaGo-Master, dùng SFT nhẹ
-
DeepSeek mã nguồn mở theo giấy phép MIT, Kimi thể hiện tốt hơn trong các bài kiểm tra đa phương tiện, báo cáo chi tiết thiết kế hệ thống phong phú hơn, bao gồm hạ tầng RL, cụm hỗn hợp, hộp cát mã, chiến lược song song
Tuy nhiên, trong thị trường AI thay đổi nhanh chóng này, lợi thế dẫn đầu thường thoáng qua. Các công ty mô hình khác chắc chắn sẽ nhanh chóng học hỏi kinh nghiệm từ DeepSeek và cải tiến, có thể sớm đuổi kịp.
Người khởi xướng cuộc chiến giá cả mô hình lớn
Nhiều người biết DeepSeek có biệt danh "Pinduoduo của làng AI", nhưng không hiểu rõ ẩn ý đằng sau thực ra bắt nguồn từ cuộc chiến giá cả mô hình lớn nổ ra năm ngoái.
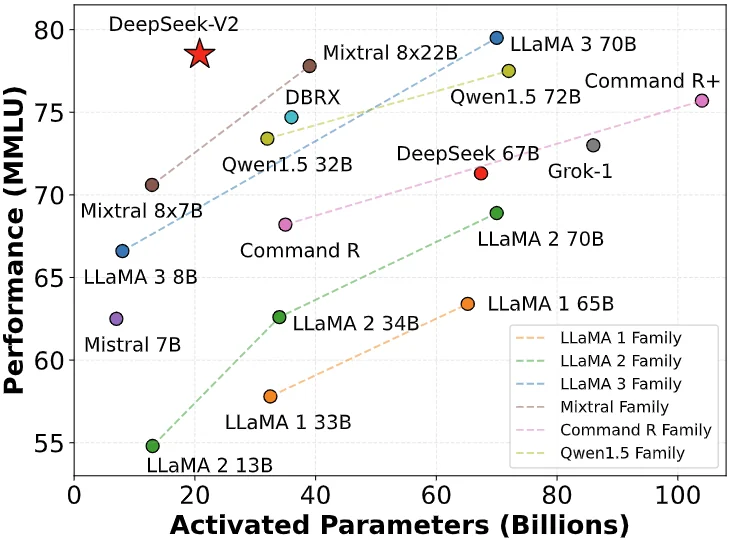
Ngày 6 tháng 5 năm 2024, DeepSeek công bố mô hình MoE mã nguồn mở DeepSeek-V2, thông qua các kiến trúc đổi mới như MLA (cơ chế chú ý tiềm năng đa đầu) và MoE (mô hình chuyên gia hỗn hợp), đạt đột phá kép về hiệu suất và chi phí.
Chi phí suy luận giảm xuống chỉ còn 1 nhân dân tệ mỗi triệu token, khoảng 1/7 so với Llama3 70B lúc đó, và 1/70 so với GPT-4 Turbo. Đột phá công nghệ này cho phép DeepSeek cung cấp dịch vụ cực kỳ tiết kiệm mà không cần bù lỗ, đồng thời gây áp lực cạnh tranh lớn cho các nhà sản xuất khác.
Việc ra mắt DeepSeek-V2 gây ra hiệu ứng dây chuyền, ByteDance, Baidu, Alibaba, Tencent, Zhinao AI lần lượt điều chỉnh giảm mạnh giá sản phẩm mô hình lớn của mình. Cuộc chiến giá cả này thậm chí vượt Thái Bình Dương, thu hút sự chú ý cao độ từ Thung lũng Silicon.
DeepSeek vì vậy được mệnh danh là "Pinduoduo của làng AI".
Trước nghi vấn bên ngoài, nhà sáng lập DeepSeek – Lương Văn Phong – trong cuộc phỏng vấn với An Yong đã trả lời:
“Chiếm lĩnh người dùng không phải mục đích chính của chúng tôi. Việc giảm giá một phần vì khi khám phá cấu trúc mô hình thế hệ tiếp theo, chi phí đã giảm trước; mặt khác, chúng tôi cho rằng dù là API hay AI, đều nên là thứ phổ cập, ai cũng dùng得起.”
Thực tế, ý nghĩa của cuộc chiến giá cả này vượt xa cạnh tranh, ngưỡng cửa thấp hơn giúp nhiều doanh nghiệp và nhà phát triển tiếp cận và ứng dụng AI tiên tiến, đồng thời buộc cả ngành phải suy nghĩ lại chiến lược định giá. Chính trong giai đoạn này, DeepSeek bắt đầu bước vào tầm ngắm công chúng, vươn lên mạnh mẽ.
Chi ngàn vàng mua xương ngựa, Lôi Quân săn đón nữ thần đồng AI
Vài tuần trước, DeepSeek còn có một biến động nhân sự đáng chú ý.
Theo báo cáo của Yicai, Lôi Quân đã chi lương hàng chục triệu nhân dân tệ mỗi năm để săn thành công La Phúc Lễ, bổ nhiệm bà làm người đứng đầu đội ngũ mô hình lớn tại Phòng thí nghiệm AI Xiaomi.
La Phúc Lễ gia nhập DeepSeek – công ty con của Hquant – năm 2022, và có thể thấy bóng dáng bà trong các báo cáo quan trọng như DeepSeek-V2 và R1 mới nhất.
Sau đó, DeepSeek – từng tập trung vào B2B – cũng bắt đầu mở rộng sang C2C, ra mắt ứng dụng di động. Tính đến thời điểm viết bài, ứng dụng DeepSeek trên App Store của Apple đạt vị trí thứ hai trong bảng xếp hạng ứng dụng miễn phí, thể hiện sức cạnh tranh mạnh mẽ.
Một loạt cao trào nhỏ khiến DeepSeek nổi danh, nhưng đồng thời nối tiếp những cao trào lớn hơn. Tối 20 tháng 1, mô hình siêu lớn DeepSeek R1 với 660 tỷ tham số chính thức ra mắt.
Mô hình này thể hiện xuất sắc trong nhiệm vụ toán học, ví dụ đạt điểm pass@1 79,8% trên AIME 2024, vượt nhẹ OpenAI-o1; đạt 97,3% trên MATH-500, tương đương OpenAI-o1. Trong nhiệm vụ lập trình, đạt xếp hạng Elo 2029 trên Codeforces, vượt 96,3% người tham gia. Trong các bài kiểm tra chuẩn tri thức như MMLU, MMLU-Pro và GPQA Diamond, DeepSeek R1 đạt lần lượt 90,8%, 84,0% và 71,5%, tuy hơi thấp hơn OpenAI-o1 nhưng vượt các mô hình đóng khác.
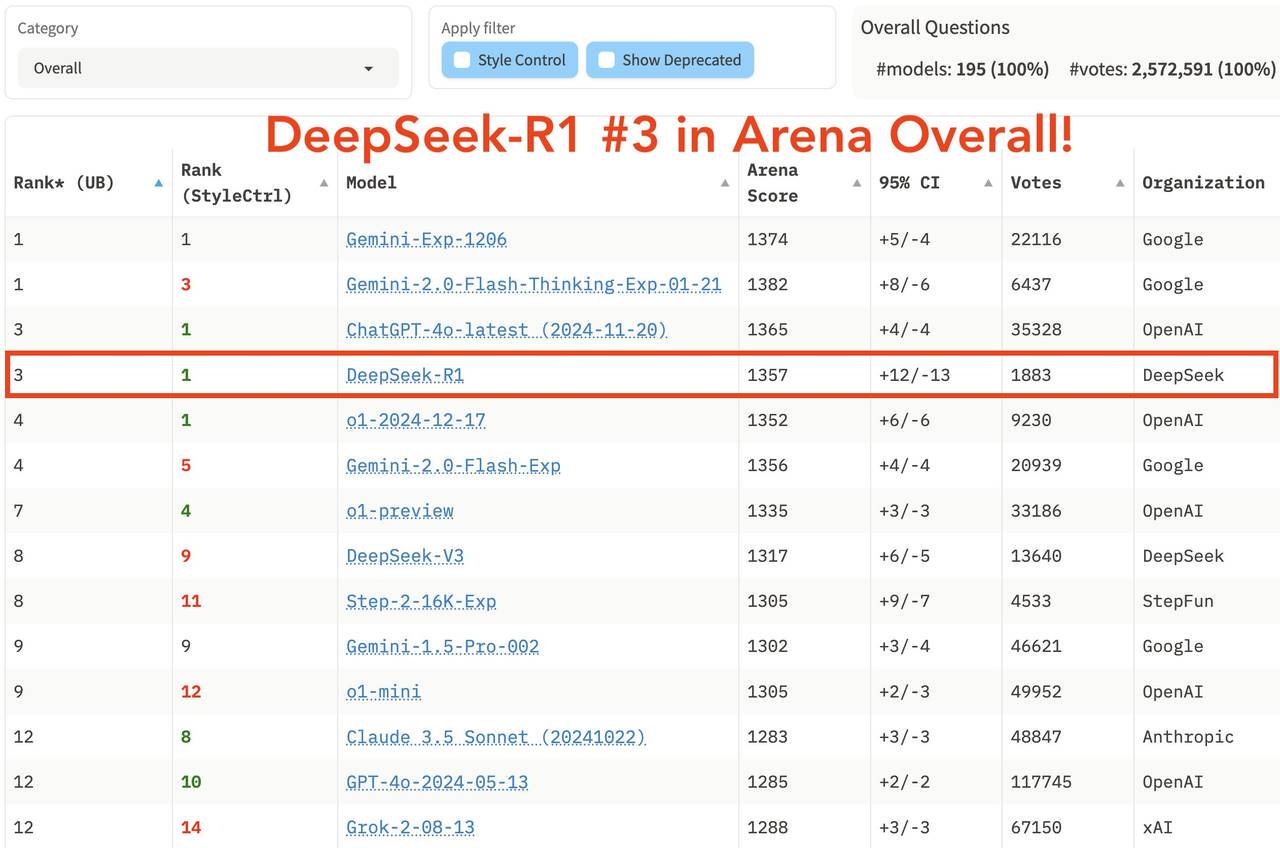
Trong bảng xếp hạng tổng hợp mới nhất của sân chơi mô hình lớn LM Arena, DeepSeek R1 xếp thứ ba, ngang hàng với o1.
-
Trong các lĩnh vực "Prompt Khó", "Lập trình" và "Toán học", DeepSeek R1 đứng đầu.
-
Trong "Kiểm soát phong cách", DeepSeek R1 và o1 đồng hạng nhất.
-
Trong bài kiểm tra "Prompt Khó kết hợp Kiểm soát Phong cách", DeepSeek R1 và o1 cũng đồng hạng nhất.
Về chiến lược mã nguồn mở, R1 sử dụng giấy phép MIT, cho người dùng mức độ tự do sử dụng tối đa, hỗ trợ chưng cất mô hình, có thể cô đặc khả năng suy luận xuống mô hình nhỏ hơn như 32B và 70B – đạt hiệu quả ngang o1-mini trên nhiều phương diện, mức độ mở còn vượt cả Meta –
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














