

Phỏng vấn CEO FLock.io: Vì sao Google không thể thực hiện học tập liên kết thực sự, trong khi blockchain lại có thể?
Tuyển chọn TechFlowTuyển chọn TechFlow
Phỏng vấn CEO FLock.io: Vì sao Google không thể thực hiện học tập liên kết thực sự, trong khi blockchain lại có thể?
Thế giới là chủ nghĩa thực dụng, còn thuật toán lại là một hộp đen thực sự, nhưng kết quả lại thực sự tạo ra điều kỳ diệu lớn.
Bài viết: Sunny, TechFlow
Khách mời: Jiahao Sun, FLock
"Học máy phi tập trung dần không còn chỉ là một khẩu hiệu, mà đang trở thành một giải pháp kỹ thuật khả thi."
– Jiahao Sun, CEO của FLock.io
Trí tuệ nhân tạo phi tập trung không phải khái niệm mới, nhưng nhờ sự nổi lên của tiền mã hóa, lĩnh vực này đang hồi sinh và mang tiềm năng dân chủ hóa AI. Tuy nhiên, với những người chưa quen thuộc, khái niệm "dân chủ hóa AI" có thể nghe mơ hồ.
Blockchain như nền tảng mạng hiện đại giúp điều phối và cộng tác lao động, tài nguyên.
AI bao gồm huấn luyện và suy luận để dự đoán, phụ thuộc vào sức mạnh tính toán, mô hình và dữ liệu. Hiện tại, những yếu tố này thường nằm trong tay một vài công ty công nghệ lớn. Dù mọi người tin họ không làm điều xấu, nhưng không có đảm bảo kiểm chứng được, do đó cần một phương pháp mới để mở rộng sự tham gia vào phát triển AI.
Google từng thử nghiệm Học liên kết (Federated Learning), trong đó thiết bị người dùng đóng góp dữ liệu và tính toán cục bộ, sau đó tổng hợp vào một mô hình toàn cầu. Nhưng mô hình này vẫn giữ quyền kiểm soát tập trung.
Blockchain cung cấp giải pháp bằng cách kích hoạt hệ thống kinh tế riêng tư, cho phép mọi người tham gia đóng góp dữ liệu, sức tính toán và mô hình thông qua cơ chế token và tiền mã hóa.
FLock (học liên kết dựa trên blockchain) đưa học liên kết thực sự vào thực tiễn bằng hợp đồng thông minh và kinh tế học token, đảm bảo sự tham gia rộng rãi hơn. Hôm nay, chúng tôi xin chào đón CEO của FLock để thảo luận về khái niệm AI dân chủ và tính ứng dụng của nó trong các lĩnh vực như y tế toàn cầu — ngay cả khi không cần lập luận phi tập trung, học liên kết vẫn có ý nghĩa lớn.
Từ giám đốc AI tài chính truyền thống đến học liên kết hóa hợp đồng thông minh
TechFlow: Trước tiên, anh hãy tự giới thiệu ngắn gọn và nói rõ FLock, hay nói cách khác là học liên kết phi tập trung, thực chất là gì?
Jiahao:
Tôi đã làm trong lĩnh vực fintech Web2 truyền thống suốt mười năm. Ngay sau khi tốt nghiệp, tôi gia nhập vườn ươm Entrerpreneur First, lúc đó tôi đang làm Credit Scoring hỗ trợ AI – lần đầu tiên khởi nghiệp. Sau đó, tôi nhanh chóng được săn đầu người vào một tổ chức tài chính hàng đầu, làm Innovation Lead, và sau tám năm trở thành Giám đốc AI toàn cầu. Vì vậy, tôi có thể nói là đã gắn bó sâu sắc với ngành nghiên cứu và ứng dụng AI.
Tôi bắt đầu quan tâm đến lĩnh vực Web3 vì mùa ICO năm 2017. Khi thấy nhiều nhóm chỉ cần một ý tưởng đơn giản cũng huy động được vốn, tôi cảm thấy rất kỳ lạ. Rõ ràng thị trường thời điểm đó còn non nớt, hoặc theo cách nói hiện nay là "rất nhiều dự án rác", cảm giác thiếu đẳng cấp, nên tôi không nghĩ sẽ tham gia thật sự, chỉ coi đây là một lĩnh vực thú vị để theo dõi.
Trong thời gian dịch bệnh, thời gian dường như kéo dài, cả châu Âu và Mỹ đều làm việc từ xa, ai cũng bất ngờ có thêm nhiều thời gian rảnh. Thời gian dư ra này có thể dùng để chơi game cả ngày, hoặc làm điều gì có ý nghĩa. Tôi chơi game một năm rồi nhận thấy thật phí hoài cuộc sống, nên quyết định làm điều gì đó giá trị. Nhìn lại cuối năm 2021, dù thị trường crypto đang trong chu kỳ giảm mạnh, tôi vẫn thấy nhiều dự án hấp dẫn. Những dự án này do các đội ngũ có kinh nghiệm Web2 dày dặn triển khai trong không gian Web3, khiến tôi vô cùng ấn tượng, bắt đầu say mê sự phát triển của Web3 và những công nghệ, câu chuyện thực sự có ý nghĩa.
Cuối cùng tôi quyết định bước vào Web3 vì một bài báo nghiên cứu đạt giải tại hội nghị hàng đầu – kết quả thảo luận và suy ngẫm sâu sắc của các nhà sáng lập và nhóm nghiên cứu về bản chất thực sự của học máy phi tập trung. Đây cũng là lần đầu tiên FLock (viết tắt của Federated Learning on the Blockchain) xuất hiện trên thị trường, đồng thời nhận được sự ủng hộ từ giới học thuật thông qua đánh giá đồng nghiệp cao nhất, điều này tiếp thêm rất nhiều niềm tin và động lực để chúng tôi khởi động dự án FLock.
Liên kết bài báo: https://scholar.google.com/citations?user=s0eOtD8AAAAJ&hl=en
Học liên kết hay học máy phi tập trung luôn tồn tại trong ngành.
Ví dụ, Nvidia và AWS cũng đầu tư nhiều vào các hệ thống tính toán phân tán, học máy phân tán tương tự. Nhưng vấn đề mãi tồn tại: giả sử AWS nói "tất cả tài nguyên điện toán đám mây của tôi đều phân tán, bạn sở hữu nền tảng điện toán của riêng bạn", nhưng bạn rõ ràng sẽ không tin điều đó, vì bạn vẫn mua dịch vụ điện toán từ AWS, và AWS vẫn có quyền kiểm soát trung gian – họ là người kiểm soát cuối cùng. Bạn không thực sự sở hữu AWS, bạn chỉ thuê nó. Tương tự, người dùng không sở hữu dữ liệu của mình.
Về mặt bảo vệ quyền riêng tư, Google đã đề xuất khái niệm Học liên kết (Federated Learning) từ năm 2017.
Khái niệm học liên kết vẫn là một khuôn khổ Machine Learning, chỉ khác ở chỗ tất cả tính toán được phân tán đến từng nút, do đó dữ liệu không cần phải rời khỏi thiết bị. Mỗi người thực hiện tính toán cục bộ (Local Compute), đơn giản là tổng hợp kết quả để tạo ra một mô hình tổng thể lớn, mô hình này phản ánh kết quả huấn luyện từ tất cả dữ liệu, nhưng lại ngăn việc phải gửi dữ liệu đến máy chủ bên thứ ba.
Toàn bộ logic này gọi là học liên kết. Sau khi Google đề xuất, họ áp dụng ngay vào dự đoán bàn phím. Vì thế, nhiều người dùng Pixel Phone đã sớm trải nghiệm học liên kết: khi bạn gõ chữ bằng điện thoại Google, nó sẽ dự đoán chữ tiếp theo. Đây là ứng dụng thực tế đầu tiên của học liên kết.
Nhưng như ví dụ tôi vừa nêu, Google vẫn kiểm soát toàn bộ quá trình huấn luyện, họ có thể hành xử xấu – họ thấy được toàn bộ mã nguồn và dữ liệu gốc, không thể chứng minh họ không nhìn thấy. Lúc đó xảy ra một sự cố lớn: một phần mềm gõ tiếng Trung tuyên bố dùng học liên kết để bảo vệ quyền riêng tư, nhưng sau đó bị phát hiện đã gửi toàn bộ dữ liệu gõ phím người dùng trực tiếp về máy chủ tập trung – hoàn toàn không dùng học liên kết.
Do đó, những sự kiện này gần đây khiến cộng đồng công nghệ đặt câu hỏi: “Nếu để một người kiểm soát tất cả tài nguyên này, liệu họ có thể cam kết không làm điều xấu? Và nếu họ cam kết, ta có nên tin?” Rõ ràng các hãng khác không tin, nếu không Apple và Google đã cùng nhau tham gia huấn luyện một mô hình dự đoán bàn phím rồi.
Vì vậy, chúng tôi đưa cơ chế hợp đồng thông minh blockchain vào khung học liên kết truyền thống, loại bỏ Google và bất kỳ người trung gian nào trong phân bổ tài nguyên. Mỗi người là một cá thể độc lập, có nút riêng, chỉ tính toán phần của mình, sau đó hợp đồng thông minh quyết định gradient nào hữu ích, gradient nào cần tổng hợp – toàn bộ được giải quyết bởi cơ chế đồng thuận (Consensus) trên chuỗi. Đây là điểm khởi đầu của FLock như một ý tưởng nghiên cứu.
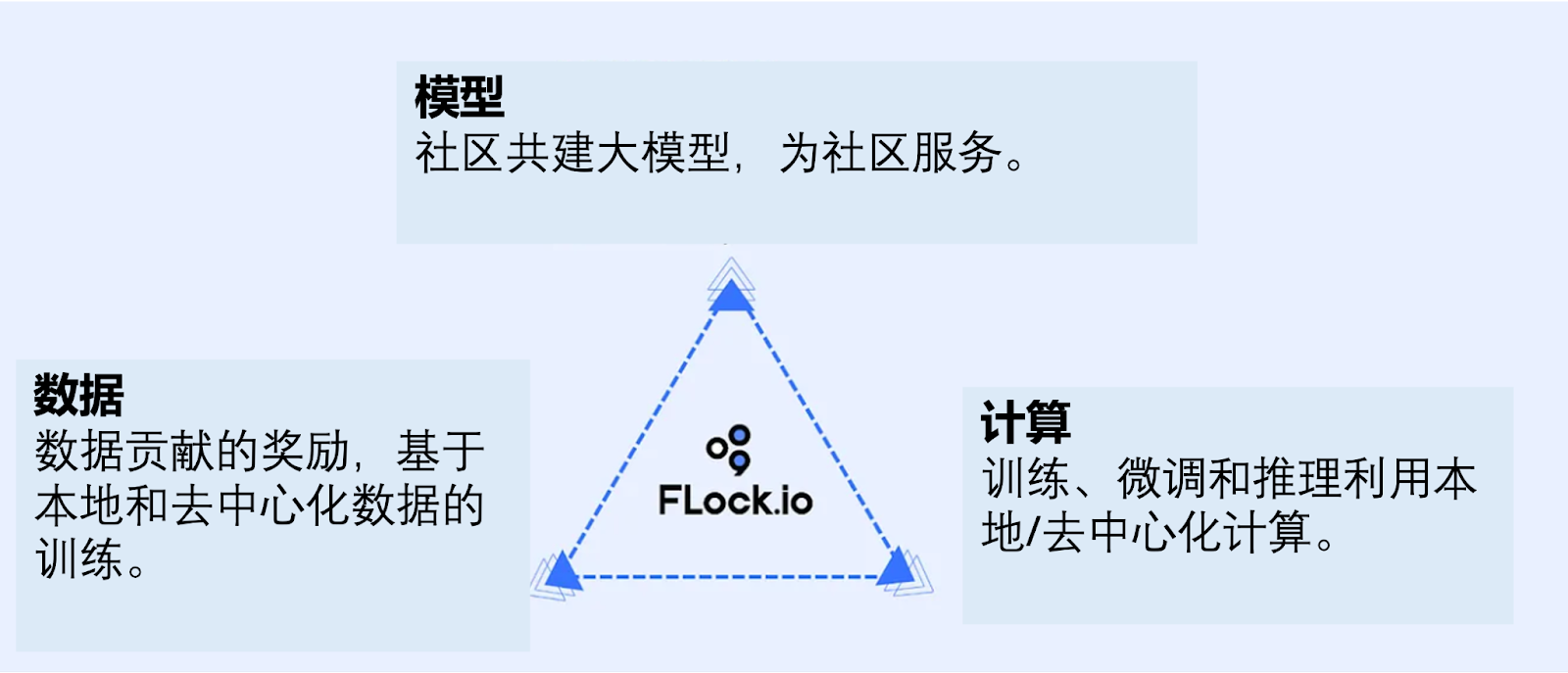
FLock điều phối cộng đồng xây dựng chung dữ liệu, mô hình và tính toán qua hợp đồng thông minh
Hiểu trước: Dữ liệu đã được huấn luyện còn là dữ liệu của bạn không?
TechFlow: Vậy trước tiên, tại các nút cá nhân, dữ liệu cục bộ được mã hóa và tham gia huấn luyện mô hình tổng thể như thế nào, đồng thời vẫn đảm bảo quyền riêng tư của dữ liệu ban đầu dù đã có kết quả huấn luyện?
Jiahao:
Tôi lấy ví dụ: WorldCoin chụp ảnh mống mắt, sau đó đưa qua mạng nơ-ron để chuyển thành một Embedding. Embedding đó không còn là ảnh mống mắt nữa, đúng không? Câu hỏi là liệu mọi người có tin vào logic này không.
– “Nó không còn là mống mắt của tôi, mà là một Embedding mới.”
Tất nhiên, một số người không chấp nhận logic này, họ cho rằng đó vẫn là sản phẩm phái sinh từ dữ liệu của họ.
Chúng ta cứ đi từng bước: những người chấp nhận logic này hiểu rằng trong học liên kết, dữ liệu cá nhân chưa bao giờ rời khỏi nút cá nhân. Thứ được gửi ra là sự thay đổi của mô hình cục bộ sau khi được huấn luyện bằng dữ liệu của bạn, giá trị thay đổi này gọi là gradient.
Chúng ta chỉ truyền gradient sang nút tiếp theo, không có bất kỳ thông tin nào liên quan đến dữ liệu gốc được gửi đi – nó hoàn toàn bí mật. Về lý thuyết, không cần mã hóa gì cả, vì thứ được gửi đi vốn dĩ không phải dữ liệu của bạn.
Nếu bạn không chấp nhận logic này, cho rằng sản phẩm phái sinh từ dữ liệu cũng là dữ liệu của bạn – dù thứ đó không còn là mống mắt, đã được xử lý qua mạng nơ-ron thành một embedding – nhưng embedding này vẫn có thể liên hệ ngược về dữ liệu gốc, thì chúng tôi sẽ mã hóa thêm một lớp trên kênh truyền tải này.
Khi truyền từ nút này sang nút khác, chúng tôi cũng mã hóa luôn quá trình truyền tải nút. Có nhiều phương pháp, hiện nay có một số phương pháp rất thú vị như Deep Gradient Compression, giúp nén dữ liệu truyền tải xuống dưới 5%. Đồng thời tăng tốc độ truyền, giải quyết vấn đề riêng tư, mà không ảnh hưởng độ chính xác mô hình – ba lợi ích trong một.
Tại sao vậy? Thứ nhất, trong Machine Learning, để tránh overfitting dữ liệu hoặc mô hình, mỗi lần tính toán đều thực hiện Dropout – cố ý bỏ sót một số dữ liệu để đạt độ chính xác cao hơn. Ví dụ, dù tính ra 100%, chúng tôi vẫn cố tình giảm xuống 70-80% trước khi truyền đi, vì sợ nếu để 100% thì mô hình sẽ lao thẳng vào điểm overfitting – một cực tiểu cục bộ chứ không phải cực tiểu toàn cục. Phương pháp này thực tế giúp nâng cao độ chính xác tính toán.
Thứ hai, chúng tôi phát hiện trong học sâu, khi nén gradient đến mức cực đoan (ví dụ dưới 5%), lượng thông tin trong gradient đã bị nén đến mức không ai có thể phục hồi dữ liệu gốc – giống như đánh dấu mờ dày đặc lên ảnh, ngay cả AI tốt nhất cũng không thể khôi phục chi tiết ảnh gốc. Nó có thể suy diễn, đoán mò, nhưng vì thông tin khai thác được quá ít, khả năng phục hồi là cực kỳ hạn chế. Theo lý thuyết thông tin, không ai có thể khôi phục dữ liệu gốc từ gradient đã nén – đây là lớp mã hóa đáng tin cậy.
Thứ ba, dung lượng dữ liệu nhỏ hơn tự nhiên cải thiện hiệu suất truyền tải. Ngay cả các mô hình lớn hàng chục tỷ tham số, với tối ưu hóa của chúng tôi, việc tinh chỉnh phi tập trung trên nhiều máy thông thường cũng hoàn thành trong vài giờ.
Học máy phi tập trung dần không còn là khẩu hiệu, mà là một giải pháp kỹ thuật khả thi.
Vấn đề này không liên quan đến bản thân cơ chế blockchain hay học liên kết, mà là mã hóa giữa các nút – miễn là đảm bảo an toàn là được. Tôi vừa nêu chỉ là một hướng giải quyết, còn ZK, FHE, TEE đều có thể dùng làm phương án mã hóa. FLock hoàn toàn tương thích với tất cả các công nghệ này, thậm chí chúng tôi còn công bố một bài báo tên zkFL.
Học liên kết + Hợp đồng thông minh = FLock
TechFlow: Trong học liên kết, mỗi nút xử lý dữ liệu riêng, sau đó gửi một nút – chuyện gì xảy ra tiếp theo? Làm sao giải thích Consensus cho người không am hiểu AI?
Jiahao:
Một nhóm nút này giống như một cộng đồng, chúng tôi dùng phương pháp Ring-all Reduce, truyền từ nút này sang nút khác, không cần người quản lý trung gian, đến khi một nút nhận dữ liệu lần thứ hai thì vòng tròn hoàn tất – gọi là Gradient Additive. Sau khi cộng gradient, mọi người cập nhật mô hình cục bộ thành mô hình mới.
Consensus xảy ra trong hệ thống không người quản lý. Tại sao Google cần quản lý hệ thống học liên kết tập trung?
Họ sợ có nút làm điều xấu – ví dụ như tính toán không dùng dữ liệu thật, hoặc gửi dữ liệu nhiễu. Đó là lý do cần người quản lý trung gian. Cũng là lý do trong thế giới Web2 truyền thống, mọi người phải ký hợp đồng trước khi làm học liên kết – bạn chỉ làm cùng những người đáng tin cậy.
FLock dùng giải pháp phi tập trung để ngăn nút xấu, dùng hợp đồng thông minh thay thế người quản lý trung gian, chúng tôi đóng vai trò Validator, dùng hợp đồng thông minh để xác thực.
Machine learning định hướng kết quả – chỉ cần kiểm tra xem kết quả mô hình sau khi chạy có tiến về phía độ chính xác cao hơn hay không.
Nếu mọi người đều tiến về hướng độ chính xác cao, mà bạn lại đi ngược, bạn sẽ bị Slash – không bị loại ngay lập tức, mà bị phạt dần, chỉ khi tiếp tục sai lệch mới bị loại hoàn toàn.
Đây là cơ chế trò chơi (game theory), được quản lý bởi hợp đồng thông minh.
Liệu có thể xảy ra các tình huống cực đoan? Đó chính là ý nghĩa của Tokenomics.
Chúng tôi đã chứng minh nhiều tình huống cực đoan trong bài báo, tôi lấy một ví dụ đơn giản:
Giả sử dữ liệu của tôi toàn bộ là người thuận tay phải, chỉ có một nút là người thuận tay trái – dữ liệu của họ thực sự khác biệt, nhưng là dữ liệu thật. Lần tính toán đầu, mô hình của mọi người thuận tay phải đều nghiêng về bên phải, còn mô hình người thuận tay trái nghiêng về bên trái. Ở vòng đầu, theo Consensus của FLock, nút người thuận tay trái sẽ bị slash nhẹ vì khác biệt. Sang vòng hai, lại bị phạt thêm chút nữa. Nhưng sau vài vòng, do dữ liệu của họ là thật và đóng góp thật sự cho mô hình, xu hướng huấn luyện sẽ bắt đầu nghiêng dần về phía người thuận tay trái. Kết quả, mô hình của những người khác cũng bắt đầu dịch chuyển theo.
Theo Tokenomics của chúng tôi, trong hệ thống FLock, mô hình cuối cùng nghiêng về ai, phần thưởng sẽ phân bổ nhiều hơn về phía đó. Do đó, dù nút người thuận tay trái có bị phạt nhẹ ban đầu vì tính độc đáo của dữ liệu, nhưng nhờ đóng góp thực sự vào mô hình cuối cùng, họ sẽ nhận được phần thưởng lớn hơn – ngược lại thu lợi nhiều hơn.
Đây là lý do chúng tôi thiết kế cơ chế FLock, cũng là lý do chúng tôi bắt đầu từ bài báo khoa học, công bố tại hội nghị hàng đầu trước khi triển khai – vì có quá nhiều điều cần suy ngẫm. Đội ngũ chúng tôi ban đầu hoàn toàn không nghĩ đến thương mại hóa, chỉ tập trung viết bài, code, thí nghiệm, mô phỏng, và nhận được sự đánh giá tích cực từ cộng đồng chuyên môn (NeurIPS, TAI, Science...) để đảm bảo nền tảng vững chắc, vượt qua kiểm nghiệm thực tế, sau đó mới xây dựng SDK và testnet.
TechFlow: Anh có thể tóm tắt ai là các Player trong Tokenomics hay mạng lưới này không?
Jiahao:
Có ba bên: Planer, Trainer và Validator. Có thể hình dung như một nền tảng nhiệm vụ, giống HuggingFace trong cộng đồng AI truyền thống. Planer là bên phát hành nhiệm vụ, cung cấp động lực (incentive) cho người tham gia. Trainer là các nhà phát triển AI, chủ sở hữu dữ liệu – có mô hình hoặc dữ liệu, đóng góp để nhận thưởng. Validator cung cấp sức tính toán và xác minh độ chính xác mô hình, đảm bảo hệ thống vận hành công bằng và hiệu quả.
Chiến lược thị trường (Go-to-Market)
TechFlow: Hợp đồng thông minh FLock hiện diện ở giao diện người dùng như thế nào? Ví dụ như nhận dạng hình ảnh anh vừa nói, các bước ra sao?
Jiahao:
Người dùng mở website hoặc ứng dụng, chọn dữ liệu cục bộ, nhấn "Training" là bắt đầu quy trình. Với người dùng phổ thông, chúng tôi tạo trải nghiệm liền mạch (seamless).
TechFlow: Việc ghép nối (matching) các nhiệm vụ khác nhau được xử lý thế nào?
Jiahao:
Là người huấn luyện, dữ liệu của tôi có thể khớp với nhiều thứ. Ví dụ, một bệnh viện có dữ liệu ngủ, tôi chọn tham gia nhiệm vụ đó – giống như một sàn giao dịch. Là chủ sở hữu dữ liệu, tôi có quyền lựa chọn tham gia mạng con (subnet) nào. Động lực trên sàn này do doanh nghiệp cung cấp. Ví dụ bệnh viện, ngân hàng, DeFi đặt phần thưởng (bounty), như 200K, để khuyến khích người tham gia subnet họ xây dựng trên FLock.
TechFlow: Vậy các anh tiếp cận thị trường bằng cách tìm đối tác doanh nghiệp trước?
Jiahao:
Đúng, hiện tại khách hàng trả phí của chúng tôi đều là doanh nghiệp (contract). Chúng tôi đã giao hàng thành công vài dự án, giờ muốn ra mắt Marketplace để doanh nghiệp có thể tự đăng nhiệm vụ, hướng tới người dùng cá nhân (2C) nhiều hơn, thay vì chỉ theo mô hình B2B.
TechFlow: Mức độ chấp nhận Web3 của các doanh nghiệp cung cấp dữ liệu truyền thống ra sao?
Jiahao:
Việc này giúp họ giảm chi phí. Nếu làm ngoài chuỗi (off-chain), quy trình có thể mất vài tháng và phải qua nhiều vòng xét duyệt. Hơn nữa, nếu muốn làm thử nghiệm lâm sàng xuyên quốc gia, vấn đề càng nghiêm trọng – vì hầu như không quốc gia nào cho phép dữ liệu y tế xuất cảnh, nên nhiều trường hợp không thể thực hiện.
Vì vậy, sự xuất hiện của FLock là bước đột phá đối với họ:
Thứ nhất, dữ liệu cá nhân vẫn ở lại địa phương, không cần qua nhiều quy định kiểm soát.
Thứ hai, có thể làm những việc trước đây không tưởng, ví dụ như hợp tác Trung – Nhật – Hàn để xây dựng mô hình học liên kết tốt hơn dự đoán và theo dõi glucose huyết cho người Đông Á.
Ngoài ra còn có những ý tưởng lớn hơn, cũng là điều các bệnh viện đối tác từng trao đổi với chúng tôi – như chăm sóc y tế từ xa. Trước đây điều này gần như bất khả thi vì dữ liệu không thể xuất cảnh, nhưng với học liên kết, tôi có thể theo dõi ở đây, họ đưa ra kết luận ở đó – cả hai bên không nhìn thấy dữ liệu của nhau, nhưng bệnh nhân đỡ phiền phức – tôi không cần bay đến một nước thứ ba để khám sức khỏe. Theo những gì tôi biết, ngành y tế có lẽ là ngành hiểu rõ nhất về học liên kết, đứng thứ hai là ngành tài chính vì họ đã bị hàng loạt công ty công nghệ pitch quá nhiều lần.
Tuy nhiên, chúng tôi không làm với ngành tài chính truyền thống, mà hợp tác trực tiếp với DeFi vì họ hoàn toàn hiểu Web3, rào cản hiểu biết thấp nhất.
Khi ra mắt Marketplace, chúng tôi sẽ tập trung vào các startup AI gần gũi nhu cầu cá nhân hơn, ví dụ như mô phỏng giọng nói. Trước đây một ứng dụng AI tạo ảnh chụp bằng camera bỗng dưng hết hot vì trong điều khoản riêng tư có câu rất đáng sợ: “Toàn bộ bản quyền ảnh của bạn thuộc về ****”, khiến nhiều người không muốn dùng – nhất là khi phải tải lên 10 ảnh khuôn mặt. Nhưng với các startup mô phỏng giọng, họ muốn dùng FLock như viên "thuốc an thần" về bảo vệ riêng tư dán trên sản phẩm, khiến người dùng yên tâm – giọng nói vẫn ở thiết bị tôi, và kiểm tra trên chuỗi thấy chưa từng gửi đến bên thứ ba, nhưng vẫn dùng để mô phỏng giọng – học cách nói như Triệu Bản Sơn chẳng hạn.
Vì vậy, về lâu dài, tôi hy vọng FLock trở thành CertiK trong ngành bảo vệ riêng tư – người định nghĩa tiêu chuẩn cho bảo vệ riêng tư và huấn luyện mô hình phi tập trung.
TechFlow: Anh nghiên cứu mạng P2P bao lâu thì thấy khả thi?
Jiahao:
Chúng tôi làm chưa đầy một năm. Một vài bài báo gửi đi nhanh chóng được chấp nhận, khiến chúng tôi thấy có vẻ khả thi.
Tôi nghĩ phản hồi từ hội đồng phản biện cũng là tín hiệu. Nếu những gì bạn làm bị cho là nhàm chán, không mới mẻ, thì khó mà thương mại hóa. Nhưng khi chúng tôi công bố, phản hồi rất tích cực – những phản hồi tích cực này rất có giá trị.
Nhưng đây mới chỉ là phản hồi từ giới học thuật. Chuyển sang giai đoạn thương mại hóa vẫn còn nhiều việc phải làm – làm sao để nhà đầu tư thấy điều này hợp lý? Thấy tiềm năng? Đó là thách thức khác.
Giai đoạn đầu tiên là R&D. Sau khi ra mắt phiên bản thử nghiệm và thư viện mã nguồn mở, chúng tôi bước vào giai đoạn hai. Trong thời điểm thị trường crypto giảm sâu 2023, chúng tôi huy động thành công 6 triệu USD vòng hạt giống, do Lightspeed Faction (Quang Tốc Mỹ) dẫn đầu. Điều này tiếp thêm rất nhiều niềm tin – ngay cả trong thời điểm tệ nhất, một quỹ hàng đầu chuyên đầu tư AI vẫn rót vốn – tạo kỳ vọng dài hạn cho sự phát triển.
Hiện tại là giai đoạn ba – giành sự công nhận từ thị trường. Chúng tôi sẽ ra mắt nền tảng huấn luyện phi tập trung FLock, một sàn giao dịch nơi mọi người có thể xây dựng mô hình AI cho cộng đồng riêng. Mạng của chúng tôi cũng đã được các Validator lớn nhất toàn cầu đặt chỗ hỗ trợ.
TechFlow: Mọi người đang thấy tiềm năng Web3, nhiều dự án ứng dụng blockchain vào đời sống – các anh cũng vậy. Làm sao tăng độ phủ thị trường?
Jiahao:
Chúng tôi hơi theo hướng tạo ứng dụng bùng nổ – hoặc ứng dụng đáp ứng nhu cầu bức thiết. Ví dụ, chúng tôi gần gũi với cộng đồng DeFi vì ở đó có nhiều nhu cầu thực sự bức thiết nhưng chưa được đáp ứng.
Ví dụ khi làm tín dụng cá nhân, dữ liệu tín dụng không thể liên kết với thẻ ngân hàng ngoại tuyến. FLock có thể tính toán trong nút của bạn để tạo điểm tín dụng, làm chứng nhận tín dụng cho người khác. Dù hiện tại chưa thể cho vay với tài sản thế chấp thấp, chắc chắn vẫn phải siêu thế chấp, nhưng nếu người khác cần 150% tài sản thế chấp, bạn có thể chỉ cần 105% – tăng hiệu quả cho thị trường cho vay. Với nhiều người, đây là nhu cầu thiết yếu.
Thứ hai là ứng dụng bùng nổ, như mô phỏng giọng nói – lại gây sốt một lần nữa, mọi người chia sẻ, người nổi tiếng cũng chia sẻ, khiến tôi cũng muốn tải app đó về dùng.
Chủ yếu theo hai hướng này để thu hút khách hàng.
TechFlow: FLock cũng thuộc赛道 DePin, mối quan hệ giữa FLock với Decentralized Compute và Decentralized Storage hiện tại là gì?
Jiahao:
Tôi nghĩ giữa các bên là quan hệ hợp tác chuỗi cung ứng. Chúng tôi là tầng huấn luyện (Training Layer), chỉ là một lớp. Trong hệ thống, chúng tôi giống TensorFlow, PyTorch – so sánh với ngành truyền thống là tầng trung gian huấn luyện. Bạn vẫn cần AWS để lưu mô hình, dùng S3 của AWS để lưu dữ liệu. Chúng tôi chỉ làm nhiệm vụ kết nối. Sức tính toán đến từ đâu? Và cũng có nhiều nhà cung cấp giải pháp lưu trữ.
Tôi nghĩ công nghệ lưu trữ phi tập trung có ít cơ hội đổi mới, vì đã khá lớn rồi. Phiên bản Testnet đầu tiên của chúng tôi đã hợp tác tốt với IPFS, dùng Decentralized Compute giúp người dùng phổ thông trải nghiệm cơ chế FLock dễ dàng, không khó khăn.
Theo nghĩa nguyên giáo, Bitcoin nên dùng thế nào? Dùng máy tính cá nhân tải toàn bộ sổ cái (Ledger), sau đó chuyển tiền sang máy khác. Cách dùng nguyên giáo của FLock cũng vậy – bạn mở máy tính nhà, dữ liệu để tại nhà, không gửi cho bất kỳ bên thứ ba nào vì đó mới là an toàn tuyệt đối, sau đó kết nối vào mạng FLock. Nhưng bạn không thể yêu cầu mọi người đều có máy tính mạnh và luôn bật mạng. Vì vậy, điểm hợp tác quan trọng nhất với Decentralized Compute và Data là người dùng có thể đăng nhập FLock, lưu dữ liệu trên Decentralized Storage, dùng sức tính toán phi tập trung, FLock đóng vai trò điều phối trung gian giữa dữ liệu và sức tính toán của người khác để đưa ra kết quả, đồng thời phân bổ phần thưởng công bằng, minh bạch. Người dùng chỉ cần như dùng Metamask – đăng nhập, nhấn nút, xong việc, rời đi. Không cần đích thân có máy tính để lưu trữ dữ liệu.
Với chúng tôi, hợp tác chuỗi cung ứng là để cải thiện trải nghiệm người dùng.
Chuyện bên lề về AI: GPT, GNN và các mô hình lớn khác
TechFlow: Trước khi làm ở ngân hàng, anh có làm học liên kết không?
Jiahao:
Thực ra không. Trong ngân hàng chủ yếu làm NLP, cụ thể là Graph Neural Network, Knowledge Graph... nên tôi hiểu đôi chút về ngành này. Khi GPT nổi lên, tôi chợt thấy ngành đồ thị tri thức và mạng nơ-ron bỗng dưng nguội lạnh. Tôi đang hướng dẫn hai nghiên cứu sinh tại Imperial College, luận văn của họ phải viết lại, phải đổi đề tài, nếu không dễ bị chất vấn: “Sao không dùng thẳng GPT?”
TechFlow: GPT là Semantic Data, còn Graph thiên về Non-Semantic Data?
Jiahao:
Có thể nói vậy, nhưng "sức mạnh tạo nên kỳ tích". Nếu GPT giải quyết được vấn đề, sao còn phải đề xuất thêm Graph phía sau GPT? Năm 2022 tại NeurIPS, tôi là diễn giả trong một buổi tọa đàm cùng thầy Boxing Chen từ Huawei Research, thầy Yu Cheng từ Microsoft, thầy Marjan từ Meta, nói về tương lai NLP. Lúc đó tôi cố gắng "hô biến" thêm tí lưu lượng cho Knowledge Graph của mình.
Nhưng phản hồi chủ lưu là: nếu có đủ sức tính toán cao nhất, thuật toán mạnh nhất, dữ liệu tốt nhất, có thể đạt kết quả End-to-End ngay, sao còn phải phân tích sâu từng mối quan hệ trong mạng đồ thị? Thế giới là vị lợi, thuật toán là hộp đen, nhưng kết quả thật sự tạo ra kỳ tích lớn.
Nếu bạn làm phân tích phán đoán, chi phí quá cao và hiệu quả chậm. Tôi xin lấy ví dụ trực quan: khi mạng nơ-ron mới xuất hiện, nhiều người phản đối, các học giả cổ hủ phản đối, họ nói phải dùng phương pháp thống kê, phải biết quan hệ nhân quả: a vì sao dẫn đến b, phải tính ra công thức – đó mới là machine learning.
Nhưng nhóm làm mạng nơ-ron nói: cần gì? a chỉ cần tạo ra b, tôi làm mạng nơ-ron chuyển a thành b là được. Không được thì tăng kích thước mạng lên, lại không được thì tăng tiếp, cho đến khi ra b. Ngày nay, còn ai nghi ngờ mạng nơ-ron thiếu minh bạch? Ngược lại, những ngành từng đòi hỏi phân tích nhân quả (như quỹ giao dịch tần suất cao) đã thay đổi phương án kiểm toán nội bộ, dùng kiểm thử end-to-end để giải thích chiến lược, bỏ luôn các báo cáo phân tích nhân quả.
Từ góc nhìn thị trường tiêu dùng, tôi nghĩ tương lai của Graph cũng vậy. Khi mô hình lớn tiến đến bước này, sang chu kỳ tiếp theo, con người có thể nhanh chóng quên lý do cần tồn tại của Graph. Có thể bị thế hệ sau coi là nghiên cứu thống kê thuật toán của các học giả già đời.
Tuy nhiên, tôi vẫn phải khẳng định: nghiên cứu khoa học cơ bản luôn cần thiết, và tôi sẽ luôn ủng hộ trong khả năng. Graph trong nghiên cứu vẫn còn con đường dài và đầy hứa hẹn.毕竟能也是 nền tảng nghiên cứu tôi dành 10 năm. Ha ha.
Đọc thêm
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














