

$VVV 심층 분석: 과소평가된 프라이버시 AI 인프라 및 성장 곡선
저자: Yan Liberman
번역 및 정리: TechFlow
TechFlow 서론: Venice의 최근 3주간 구독 데이터에 따르면 신규 ARR(연간 반복 수익) 증가율이 34%에 달했으며, 현재 시가총액 기준으로 향후 12개월 예상 매출 대비 기업 가치는 단지 2.5배에 불과합니다. 이 전직 암호화폐 투자가는 Venice의 프라이버시 아키텍처에서 비즈니스 모델까지 전반을 분석하며, 시장이 ‘프라이버시 AI 추론’이라는 세그먼트의 실제 규모를 심각하게 과소평가하고 있으며, Venice가 이 분야에서 타의 추종을 불허하는 복합적 경쟁 우위를 확보했다고 주장합니다. 또한 $VVV에 대한 강력한 상승 전망을 제시합니다.

Venice는 프라이버시를 최우선으로 하는 AI 추론 플랫폼으로, 사용자가 최신 모델 및 오픈소스 모델을 활용할 때 밑바닥 모델 공급자에게 자신의 신원을 노출하지 않아도 됩니다. 저는 이것이 현재 AI 시장에서 가장 완전한 프라이버시 솔루션이라고 봅니다. 익명 프록시, 오픈소스 모델 라우팅, 하드웨어 인증 TEE(Trusted Execution Environment) 기반 추론, 엔드투엔드 암호화 추론 — 이 네 가지 기능이 모두 소비자용 제품 하나에 통합되어 있으며, 프라이버시 모드는 요청 단위로 선택 가능합니다. 이러한 네 가지 기능을 동시에 제공하는 경쟁사는 현재 존재하지 않습니다.
이 사업은 꾸준히 급성장하고 있습니다. Crypto Twitter 상의 Venice 관련 논의는 일반적으로 현재 매출, 최근 성장률 및 향후 전망을 과소평가하고 있습니다. Venice는 최근 일일 구독 데이터를 공개하기 시작했는데, 3주간의 세밀한 데이터는 신규 구독 ARR의 가파른 가속화를 명확히 보여줍니다:
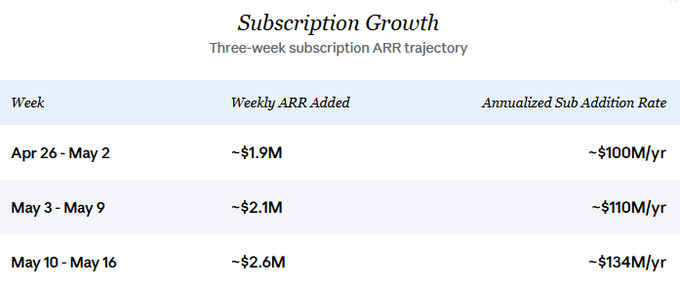
지속적인 고성장세는 본 분석의 핵심 가정입니다. 또한 API 수익이 최근 구독 성장과 동조해 증가하고 있다는 점도 가정하고 있으며, 이는 아래 “현재 상태 및 성장” 섹션에서 자세히 설명됩니다. 보수적으로 4월 말 기준 연간 신규 구독 수익 1억 달러(이 수치와 동일한 속도로 유지됨)를 기준으로 삼고, API 신규 수익도 동일한 금액으로 가정하면, 향후 12개월간 총 신규 수익은 약 2억 달러에 달합니다.
최근 가속화 추세는 이 속도가 유지된다면 실적 측면에서 상당한 상향 조정 여지가 있음을 시사합니다.
본 글에서는 Venice의 차별화 요소를 하나씩 해부합니다:
- 프라이버시 레벨: ‘비밀 AI 채팅’과 같은 일반적인 표현을 훨씬 초월하는 깊이 있는 프라이버시 아키텍처.
- 사용자 유형: Venice의 사용자층은 주류 경로(콘텐츠 정책, 규정 준수, 위협 모델, 원칙 등)에서 배제된 집단이며, 마케팅을 통해 유입된 것이 아님.
- 시장 규모: 지속적으로 성장하는 프라이버시 중심 추론 시장으로, 일반적인 소비자 채팅 프레임워크는 이를 과소평가함.
- 경쟁 구도: Venice는 프라이버시 심도, 검열 없는 모델 접근성, 암호화 기반 원생 유통을 한데 묶은 독특한 조합을 제공하며, 경쟁사 중 현재 이와 동일한 패키지를 갖춘 사례는 없습니다.
- 토큰 설계 및 VVV 평가: VVV와 DIEM의 메커니즘이 플랫폼 성장을 어떻게 토큰 가치로 전환시키는지, 그리고 VVV의 평가 배수(예: OpenRouter, Fireworks, Together AI 등 다른 프라이버시 추론 플레이어와 비교)가 어떤지.
최근 급등 후 14달러로 조정된 이후, VVV의 시가총액은 약 6.6억 달러, 완전희석 시가총액(FDV)은 약 11.2억 달러입니다. 현재 ARR은 약 6000만 달러(아래 “현재 상태 및 성장” 섹션에서 산출됨)이며, 연간 약 2억 달러 속도로 증가 중이며, 여전히 가속화되고 있습니다. 현재 ARR 기준으로 VVV의 P/S(매출 대비 기업 가치)는 약 11배(FDV 기준 약 19배)이며, 프라이버시 추론 분야 경쟁사인 OpenRouter의 26배보다 낮습니다. 향후 12개월 ARR을 현재 6000만 달러에 연간 2억 달러 신규 증가분을 더한 약 2.6억 달러로 계산할 경우, VVV의 P/S는 약 2.5배(FDV 기준 약 4.3배)가 됩니다.
현재 상태 및 성장
Venice는 최근 일일 신규 구독 데이터를 공개하기 시작했습니다. 정기적으로 발표되는 공개 등록 사용자 마일스톤 정보와 결합하면, 현재 ARR 추정치 및 향후 전망을 도출할 수 있습니다.
현재 ARR을 추정하기 위해 등록자 총수에서 출발합니다. 일정 기간 동안의 공식 발표 주기를 바탕으로, 등록자 수는 월평균 약 30만 명 속도로 증가해 왔습니다. 최근 확인된 마일스톤은 2026년 5월 16일 기준 약 300만 명의 등록 사용자로, 2월 1일 약 200만 명과 비교해 월 30만 명 증가 속도와 일치합니다. 평생 유료 전환율을 약 5%로 가정합니다(일일 데이터에 따르면 신규 등록자의 전환 속도가 더 빠르므로 이는 보수적 추정). 이에 따라 5월 중순 기준 약 15만 명의 활성 유료 구독자가 있는 것으로 추정됩니다. 4월 중하순까지는 기본 Pro 요금제(월 18달러)만 제공되었고, Pro+(월 68달러) 및 Max(월 200달러) 요금제는 최근에야 출시되어 구조 변화를 시작했으나, 대부분의 유료 사용자는 여전히 18달러 요금제에 머물러 있습니다. 가중 평균 ARPPU(사용자당 평균 매출)는 월 18~19달러 수준으로, 현재 구독 MRR(월 반복 수익)은 약 280만 달러, 즉 구독 기반 ARR은 약 3300만 달러입니다. 이는 구독 부문만을 반영한 수치이며, 본 섹션 후반부에서 API 수익을 추가하여 전체 현재 ARR을 산출합니다.
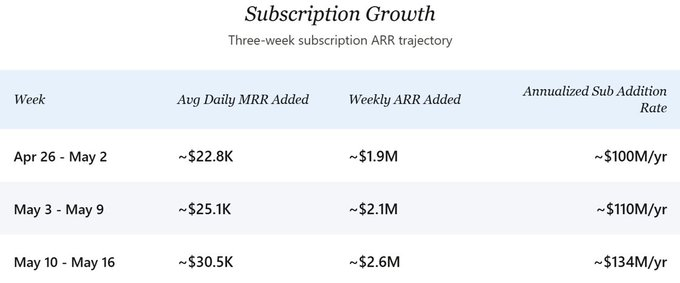
향후 전망 측면에서는 신규 구독 ARR의 증가 속도가 계속해서 가속화되고 있습니다. 4월 하순 기준 회사는 주당 약 200만 달러의 구독 ARR을 신규 창출하고 있었으나, 최근 주(5월 10~16일)에는 이 속도가 주당 약 260만 달러로 급등해, 연간 환산 시 약 1.34억 달러의 구독 신규 수익 속도를 의미합니다. 본 분석의 핵심 시나리오에서는 최근 가속화를 과대평가하지 않기 위해 보수적으로 연간 1억 달러를 기준으로 삼습니다. 이탈을 감안한 순성장률은 다소 낮아질 수 있으나, 현재 규모에서는 이 차이가 방향성 판단에 중요하지 않을 정도로 미미하며, 총성장률이 본 전망 분석의 핵심을 이룹니다.
3주간의 세밀한 데이터(4월 26일~5월 16일)는 명확한 상승 추세를 보여줍니다:
1주차에서 3주차까지 일일 MRR 신규 증가분은 약 34% 증가했습니다. API 수익이 신규 구독 MRR과 1:1 비율로 연동된다고 가정하면(아래 설명), 암묵적인 총 연간 신규 수익은 약 2억 달러에서 약 2.68억 달러로 상승했습니다. 이 전환점의 주요 요인은 두 가지입니다: 첫째, Pro+ 및 Max 요금제 출시로 지불 의사가 높은 사용자에게 이전에 없던 선택권이 생겨 가중 평균 ARPPU가 상승했고, 둘째, 요금제 확장 후 유료 전환율이 가속화된 것으로 보입니다.
API 수익은 직접 공개되지 않아 측정이 어렵습니다. 기본 시나리오에서는 최근 신규 API 운영 수익이 신규 구독 MRR과 1:1 비율로 연동되며, 역사적 신규 비율은 이보다 낮았다고 가정합니다. 결과적으로 현재 API ARR 기반은 상당하나 구독 ARR보다 약간 작으며, 시간이 지남에 따라 균형을 맞추고 있습니다.
50:50 분할 비율의 근거는 동종 업계 벤치마크에서 출발합니다. 대규모 폐쇄형 모델 플랫폼에서는 ChatGPT의 API 비중이 약 25%, 구독 비중이 약 75%인데, 이는 거대한 소비자 구독 기반이 API 비중을 작게 만들기 때문입니다. Anthropic의 경우 API 비중이 약 80%, 구독 비중이 약 20%인데, 이는 사용자 기반이 개발자 및 기업 중심이기 때문입니다. Venice는 구조적으로 이 둘 사이에 위치합니다: 프라이버시 포지셔닝 때문에 ChatGPT처럼 일반 소비자를 끌어들이지는 않으나, 유료 사용자 기반은 Anthropic의 기업 중심 혼합보다 더 광범위합니다. 50:50 분할은 이 범위의 중간값에 해당합니다.
이 범위는 Venice 특유의 두 가지 증거로 더욱 강화됩니다.
첫째, Venice의 API는 이미 다수의 개발자 유통 채널을 확보했습니다. OpenRouter는 Venice 모델을 라우팅하고, Fleek은 모든 호스팅 프록시를 기본적으로 Venice 추론으로 설정하며, Cursor, Brave Leo(BYOM을 통해), VSCode 커뮤니티 확장 등도 Venice를 지원합니다. 이러한 통합은 지난 1년 이상 축적되어, API가 실질적이며 중요한 비즈니스임을 입증하고, 규모화된 생산 트래픽을 확보하고 있음을 보여줍니다.
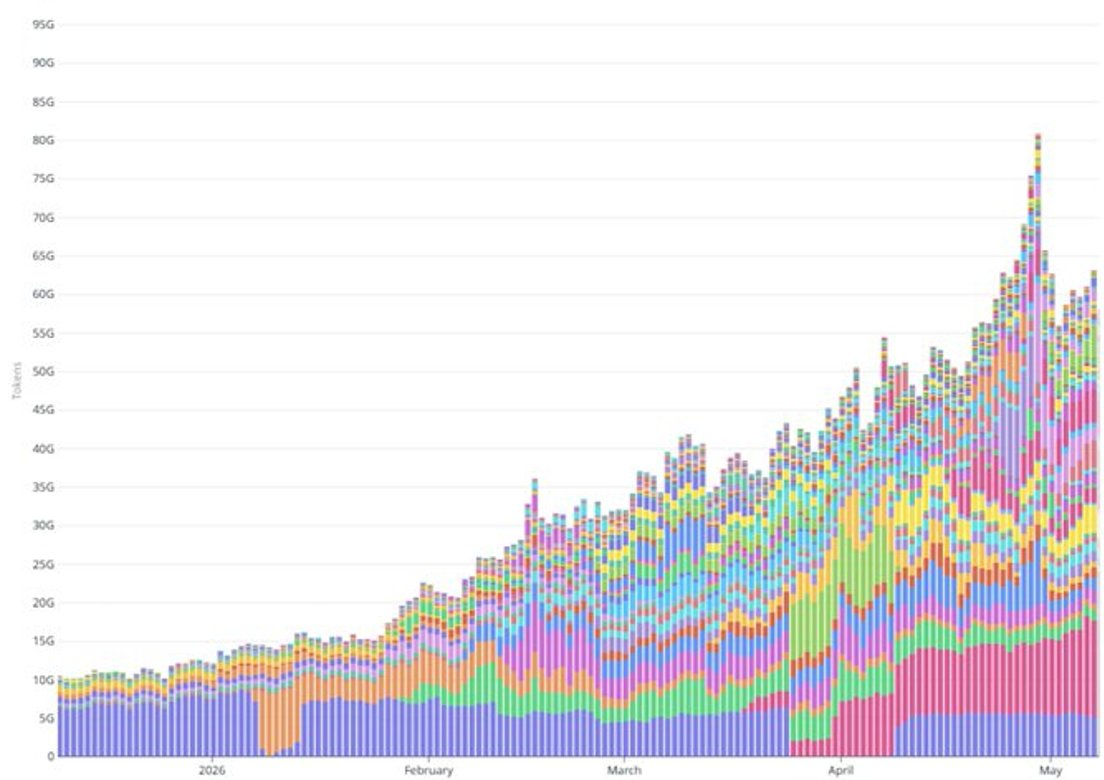
둘째, 최근 토큰 처리량의 급증은 구독 증가만으로는 설명할 수 없습니다. 일일 토큰 처리량은 2월 초 200억 개에서 5월 초 600억 개 이상으로, 3개월 만에 약 3배 증가했습니다. 같은 기간 동안 유료 구독 기반은 약 50% 증가했습니다(약 10만 명에서 약 15만 명으로). 4月中旬 Pro+/Max 요금제 확장은 일부 신규 등록자만 더 높은 ARPPU 요금제로 전환시켰고, 이들 요금제의 단일 사용자 토큰 소비량을 관대하게 가정해도 이 격차를 메울 수 없습니다. 토큰 처리량 증가의 대부분은 사용량 기반 요금제(API) 작업 부하에서 비롯된 것으로 보입니다: 에이전트 배포, 통합 파트너의 생산 트래픽 확대, 기타 고용량 사용 사례 등입니다.
현재 API ARR을 구독 ARR보다 추정하기 더 어렵습니다. 왜냐하면 1:1 비율은 최근에야 나타났기 때문입니다. 4월 중순 이전에는 API 비중이 더 작았을 수 있습니다. 중간값 가정으로, API는 역사적으로 구독의 70~80% 수준이었고 최근에야 1:1에 도달했다고 보면, 현재 API ARR은 약 2500~3000만 달러입니다. 현재 총 ARR 추정치는 약 5500~6500만 달러, 중간값은 약 6000만 달러입니다.
API 부분에 대해 간략히 설명하자면: 이는 현재 사용 기반 운영 수익의 연간 환산치이며, 반복적인 구독 약정이 아닙니다. 따라서 구독 부문보다 내재적 변동성이 더 큽니다. 대규모 API 고객이 사용을 줄이면 API 운영 수익이 크게 감소할 수 있지만, 구독 기반에서는 이와 유사한 이탈이 발생하지 않습니다.
연초 대비 수익 교차 검증: 토큰 처리량이 2월 초 일일 200억 개에서 5월 초 일일 600억 개 이상으로 증가한 것을 바탕으로, Venice는 2026년에 이미 최소 3000만 달러의 누적 수익을 창출했습니다. 이 수치는 현재 ARR이 5500~6500만 달러 구간에 있다는 점과 일치하며, 이 기반은 연간 2억 달러 신규 증가 속도로 급속히 성장하고 있습니다.
중요한 점은, 연간 신규 증가 속도는 향후 12개월 동안 창출될 수익과 동일하지 않다는 것입니다. 신규 ARR은 1년 동안 선형적으로 증가하므로, 2026년 내내 지속되는 2억 달러 연간 신규 증가 속도는 약 1억 달러의 신규 수익 창출로 이어지고, 현재 ARR 기반은 추가로 약 6000만 달러를 기여합니다. 향후 12개월 동안 창출될 총 수익은 1.5~2억 달러 구간에 속하며, 이 12개월 창구 종료 시점의 ARR은 이탈을 고려하지 않았을 때 약 2.6억 달러입니다(현재 6000만 달러 + 신규 2억 달러 ARR).
과거를 돌아보는 것은 주로 각주에 해당합니다. Venice의 현재 ARR 연간 신규 증가 속도는 약 2억 달러이며, 진정한 질문은 오늘의 속도가 바닥인지 아니면 출발점인지입니다. 중요한 변수는 다음과 같습니다: 구독 성장이 지속될 것인지, API 사용이 구독 확장보다 더 빠르게 계속될 것인지, 대기열이 성숙함에 따라 얼마나 많은 이탈이 발생할 것인지, 그리고 접근 가능한 시장이 이 속도의 지속적 성장을 뒷받침할 수 있을지 여부입니다.
시장 규모 문제는 Venice가 실제로 무엇을 하는지 이해한 후에야 더 쉽게 답할 수 있습니다. 가장 명확한 기초는 LLM 상호작용을 위한 프라이버시 계단식 구조이며, 각 계단은 서로 다른 프라이버시 가정을 나타내고, Venice의 모드는 특정 계단에 내재되어 있습니다.
프라이버시 계단식 구조
다음 계단식 구조는 클라우드 기반 AI 사용을 좁지만 중요한 축—누가 평문 프롬프트를 사용자 신원과 연결할 수 있는가—에 따라 순위를 매깁니다. 이는 모든 프라이버시 문제를 해결하지는 않습니다. 디바이스 침해, 결제 흔적, 계정 메타데이터, 소환 위험, 엔드포인트 보안은 여전히 독립적인 문제입니다. 그러나 이는 사용자가 기본 챗봇에서 Venice의 고급 프라이버시 모드로 전환할 때 실제로 무엇이 바뀌는지를 명확히 합니다. 계단 번호(0~7)는 Venice를 더 광범위한 맥락에 배치하기 위해 제가 부여한 것입니다. Venice 자체의 분류법은 Anonymous, Private, TEE, E2EE라는 네 가지 명명된 모드만 사용하며, 이는 아래 Level 3, 4, 6, 7에 각각 대응합니다.
가장 강력한 프라이버시 옵션은 계단식 구조에 포함되지 않습니다. 사용자가 소유한 하드웨어에서 오픈소스 모델을 실행하고 클라우드를 전혀 사용하지 않는 경우가 이에 해당합니다. 강력한 Mac 또는 워크스테이션에서 GLM 5.1 또는 Qwen 3.6을 실행하고, 네트워크 호출 없이, 제3자 개입 없이 실행합니다. ‘프롬프트가 내 기기에서 한 번도 벗어나지 않는다’는 것보다 더 강력한 프라이버시는 없습니다—단, 기기가 적절히 강화되었다는 전제하에 말입니다. 그러나 이는 대부분의 사람들이 선택하지 않을 경로입니다. 하드웨어 비용이 비쌉니다. 로컬에서 실행 가능한 오픈소스 모델은 가장 어려운 작업에서 여전히 폐쇄형 실험실의 최첨단 수준보다 뒤처집니다. 통합 및 24/7 클라우드 실행 기능을 잃게 되며, 전체 스택을 관리해야 하는 책임도 떠안게 됩니다. 로컬 배포를 제외하고, 다음 계단식 구조는 클라우드 기반 추론의 현실적인 옵션을 다룹니다.
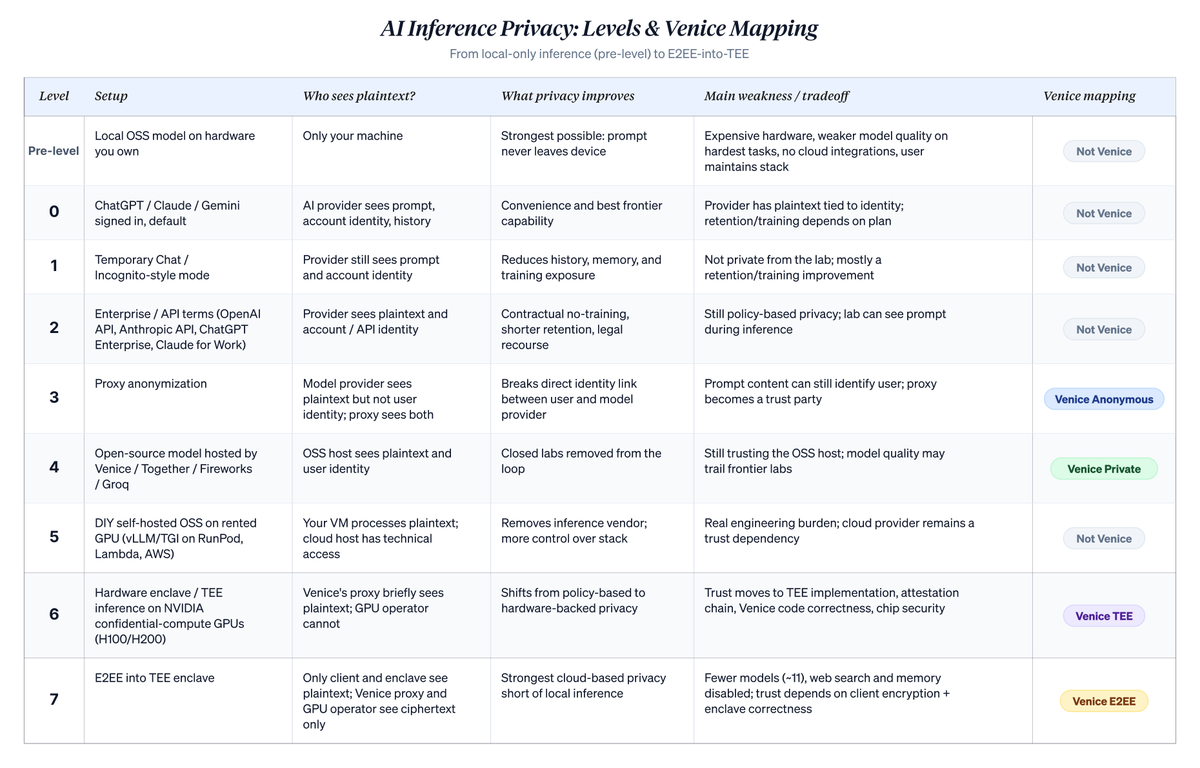
자세한 계단별 분석은 각 레벨을 설명하는 은유와 함께 아래와 같습니다:
Level 0: “로그인된 상태의 ChatGPT, Claude 또는 Gemini, 기본 설정.” 프롬프트는 귀하의 계정과 연결된 실험실로 전송됩니다. 실험실은 귀하가 누구이며 무엇을 물어보았는지 알고 있습니다. 소비자 요금제에서는, 귀하가 선택적으로 탈퇴하지 않는 한 대화가 향후 모델 개선을 위해 사용될 수 있으며, 귀하의 서버측 채팅 기록에 저장됩니다. 여기에는 실제 약속(데이터 판매 금지, 보관 기간, 삭제 제어)이 있지만, 귀하는 식별 가능하고 보관되며, 소비자 요금제에서는 훈련 프로세스에 포함될 수도 있습니다. 대부분의 사람들이 이 계단에 있습니다. 아키텍처적으로, 공급업체가 어디에 있든, 모든 호스팅 API 소비 서비스는 동일한 자세를 취합니다. 중국 공급업체의 호스팅 계획(DeepSeek 호스팅 버전, GLM/지푸, MiniMax, Qwen 직결)은 동일한 아키텍처 계단에 있습니다: 공급업체는 평문을 보고 신원을 계정과 연결하며, 보관 및 훈련 정책은 공급업체마다 다릅니다. 사용자는 일반적으로 가격 때문에 이러한 서비스를 선택하는데, 이는 Anthropic 또는 OpenAI보다 훨씬 저렴하기 때문입니다. 귀하의 데이터가 궁극적으로 어느 사법 관할권에 의해 관리되는지는 구체적인 공급업체, 귀하가 접속하는 엔드포인트, 지역 및 계약에 따라 달라집니다. 단순히 모델이 저렴하다고 해서 미국 또는 EU식 데이터 처리를 받는다고 가정해서는 안 됩니다.
은유: 귀하는 대기업(AI 공급업체)으로 직접 찾아가서 컨설턴트(모델)를 만나는 것입니다. 그들은 귀하의 메모를 읽고 질문에 답변한 후, 귀하의 이름으로 사본을 보관합니다. 그들은 과거 메모의 익명 버전을 사용하여 다른 컨설턴트를 훈련하거나 서비스를 개선할 수도 있습니다.
Level 1: “ChatGPT 임시 채팅 / Claude 익명 채팅.” 동일한 공급업체, 동일한 신원, 동일한 평문이 그들의 서버에 전송됩니다. 대화는 귀하의 기록에 표시되지 않으며, 모델은 이를 계속 전달하지 않으며, 정책상 훈련에도 사용되지 않습니다. 귀하의 계정에 영향을 주고 싶지 않은 민감한 단일 대화에 유용합니다. 공급업체는 여전히 귀하가 누구인지, 완전한 프롬프트를 보고 있습니다. 다만 장기 보관이나 훈련 용도로 사용하지는 못합니다. 귀하의 기록에서는 숨겨지지만, 실험실에서는 숨겨지지 않습니다.
은유: 컨설턴트(모델)와의 직접 상호작용은 동일하지만, 귀하는 이 특정 메모를 귀하의 주 파일에서 제외해 달라고 요청합니다. 그들은 그것을 읽고 답변한 후, 임시 서랍(익명 채팅)에 넣고, 일정 기간 후 삭제합니다. 그들은 여전히 귀하가 누구인지 알고, 귀하가 보낸 내용도 보고 있습니다.
Level 2: “Anthropic API, Claude for Work, ChatGPT Enterprise, OpenAI API.” 소비자 채팅에서 상업적 조건으로 전환합니다. 계약서는 귀하의 데이터를 훈련에 사용하지 않도록 배제합니다. 보관 기간은 짧으며, 일반적으로 보안 검토를 위해 약 30일이며, 기업 수준에서는 0일일 수도 있습니다. 정책 위반 시 법적 구제 수단이 있습니다. 실험실은 추론 과정에서 여전히 평문을 보고, 트래픽을 귀하의 API 키와 연결하지만, 보장은 더 강력하며 계약서상 시행 가능합니다. 이는 대부분의 기업이 실제로 사용하는 프라이버시 자세이며, 소비자 채팅에 대한 진정한 업그레이드입니다. 그러나 이는 여전히 정책 기반이며, 아키텍처 기반은 아닙니다. 더 높이 오를 이유는 현실적입니다: 미래의 정책 변경, 강제 공개, 데이터 유출 또는 실험실 자체의 악화.
은유: 귀하는 컨설팅 회사(기업/API 조건)와 계약을 체결하며, 계약서에는 복제 금지, 고객 간 공유 금지, 짧은 보관 기간, 위반 시 법적 구제 수단 등이 포함됩니다. 컨설턴트(모델)와의 직접 상호작용은 동일하며, 그들은 귀하의 메모를 읽고 귀하가 보낸 것임을 알고 있지만, 메모 이후에 무슨 일이 일어날지에 대한 규칙이 더 엄격합니다.
Level 3: “Venice 익명 모드.” 프록시가 귀하와 실험실 사이에 위치하며, 전달 전에 귀하의 신원을 제거합니다. 실험실은 평문으로 프롬프트 내용을 보지만, 그것이 귀하라는 사실은 모릅니다. 그들은 ‘Venice에서 온 요청’으로만 봅니다. 프롬프트 내용이 귀하를 식별하지 않는 경우, 이는 귀하의 쿼리와 귀하의 이름 사이의 연결을 끊어주며, 실험실의 장기 프로필 구축을 훨씬 어렵게 만듭니다. 그러나 프롬프트 내용이 실제로 귀하를 식별하는 경우(귀하의 회사, 거래, 이름 등), 이는 대부분 피상적입니다. 내용 자체가 귀하를 노출하기 때문입니다. 또한 귀하는 Venice를 신뢰 당사자로 추가합니다. 이를 직접 수행하는 것은 현실적이지 않습니다. 귀하는 귀하만의 프록시의 유일한 사용자이며, 단일 사용자 익명성은 익명성이 아닙니다.
은유: 택배 서비스(Venice)가 배달을 처리합니다. 택배는 메모를 컨설턴트(모델)에게 전달하기 전에 귀하의 이름을 제거합니다. 컨설턴트는 내용을 읽지만 누가 보냈는지는 모릅니다. 택배 서비스는 양측을 모두 알고 있습니다.
Level 4: “Together AI / Fireworks / Groq 상의 오픈소스 모델, 또는 Venice 프라이버시 모드.” 폐쇄형 실험실에서 벗어나 오픈소스 모델로 전환합니다. 이 트래픽에서 폐쇄형 실험실은 루프에서 완전히 제외됩니다. 귀하는 그들의 모델을 사용하지 않기 때문입니다. 신뢰는 오픈소스 모델을 호스팅하는 사람에게 이동합니다. 다양한 공급업체, 유사한 계약 보장, 일반적으로 프라이버시를 더 중시하는 문화(특히 Venice 프라이버시 모드)입니다. 귀하는 능력 일부를 포기하지만, 격차는 좁혀지고 있습니다. GLM 5.1, Qwen 3.6, Minimax M2.7 및 DeepSeek V4는 일상적인 코딩, 글쓰기 및 분석에서 괜찮은 성능을 보입니다. 그들이 최고 수준의 폐쇄형 모델에 도달했는지는 벤치마크에 따라 크게 달라지며, 폐쇄형 실험실은 긴 컨텍스트 작업, 멀티모달 작업 및 복잡한 에이전트 워크플로우에서 여전히 우위를 점하고 있습니다. 또한 집중 리스크를 줄이고, 신뢰해야 할 당사자도 줄입니다. 이것이 Level 3보다 엄격하게 더 프라이버시한가? 귀하가 무엇을 걱정하느냐에 따라 다릅니다. Level 3은 최첨단 실험실에 귀하의 신원을 숨깁니다. Level 4는 작은 플레이어에게 귀하의 신원을 공개하지만, 실험실과의 연결을 완전히 끊습니다. 다른 우선순위, 다른 순위입니다. 이것은 귀하가 실제로 오픈소스 라우팅을 통해 전송하는 트래픽에만 적용됩니다. 혼합 사용은 실험실이 귀하가 그들에게 보낸 모든 내용을 여전히 볼 수 있음을 의미합니다. Level 4 내부에서도, 공급업체는 GPU 작업이 발생하는 위치에서 차이가 있습니다: Together, Fireworks 및 Venice 프라이버시 모드는 자신의 데이터센터를 지정하지만, OpenRouter와 같은 어그리게이터는 가장 저렴한 하위 공급업체로 라우팅하며, 이는 귀하가 선택하지 않은 사법 관할권에서 운영되는 공급업체를 포함할 수 있습니다. 이 점을 걱정하는 사용자(특정 국가로의 API 호출 라우팅을 피하기 위해)에게는, 가장 저렴한 어그리게이터로 라우팅하는 것과 달리, 호스트를 지정하는 옵션은 본질적으로 다르며, 이는 추가 신뢰 점프를 의미합니다.
은유: 귀하는 다른 컨설팅 회사(오픈소스 모델 호스팅 업체, 예: Together AI, Fireworks 또는 Venice 프라이버시 모드)로 직접 메모를 가져갑니다. 원래 회사는 아무것도 보지 못합니다. 왜냐하면 귀하가 이미 그들을 사용하지 않기 때문입니다. 새로운 컨설턴트(다른 모델)는 귀하의 메모를 읽고 귀하가 보낸 것임을 알고, 이전과 동일한 직접 상호작용 구조이지만, 회사만 다릅니다.
Level 5: “DIY: RunPod / Lambda Labs / AWS 상의 vLLM.” 추론 서비스 계층을 완전히 건너뜁니다. 원시 GPU를 임대하고, vLLM 또는 TGI를 직접 설치하고, 가중치를 로드하며, 자신만의 엔드포인트를 노출합니다. 추론 공급업체는 귀하의 트래픽을 보지 못하며, 귀하의 가상 머신이 실행되는 클라우드 호스팅 업체의 하드웨어만 볼 수 있습니다. 동기 또는 강제 요구에 따라, 클라우드 호스팅 업체는 기술적으로 귀하의 가상 머신을 검사할 수 있습니다. 그러나 그들은 소규모 추론 공급업체보다 더 강력한 규정 준수 자세, 계약 보호 및 감사 추적을 갖추고 있습니다. 타협은: 귀하는 소규모 공급업체의 정책에서 초대규모 클라우드 공급업체의 정책으로 이동하며, 대가로 진정한 엔지니어링 및 운영 작업을 감당해야 합니다.
은유: 귀하는 자신만의 컨설턴트(자체 호스팅 모델)를 고용하며, 이 컨설턴트는 귀하가 RunPod, Lambda Labs 또는 AWS 등 클라우드 호스팅 업체에서 임대한 가상 머신(사적 사무실)에서 전담으로 귀하를 위해 일합니다. 중간에 컨설팅 회사는 없고, 귀하와 귀하가 직접 고용한 컨설턴트만 있습니다. 건물 소유자(클라우드 호스팅 업체)는 동기 부여 시 기술적 접근이 가능하지만, 일반적으로 초기 계단의 소규모 회사보다 더 강력한 규정 준수 자세를 갖추고 있습니다.
Level 6: “Venice TEE 모드.” 여기서 프라이버시 보장의 성격이 바뀝니다. TEE 및 E2EE는 유료 Pro 구독자 모두에게 사용 가능하며, 선택은 요금제가 아닌 요청 단위로 이루어집니다. TEE 추론의 경우, Venice는 NEAR AI Cloud 및 Phala Network의 기밀 컴퓨팅 기술이 구동되는 NVIDIA H100 및 H200 하드웨어의 GPU 호스트로 라우팅합니다. NEAR 및 Phala는 프로토콜 및 도구를 제공하며, GPU 자체는 해당 기술을 사용하는 제3자 호스팅 업체가 운영합니다. GPU 상의 기밀 컴퓨팅 기능은 운영자가 실행 중인 플라이트 내의 콘텐츠를 읽는 것을 방지합니다. 원격 증명은 클라이언트가 콘텐츠를 보내기 전에 암호화 방식으로 플라이트 내에서 실행되는 코드를 검증할 수 있게 해주므로, “이것이 정말 Venice가 게시한 코드인가?”라는 질문은 해결된 문제입니다. 아직 해결되지 않은 것은 해당 코드의 정확성에 대한 공식적인 제3자 감사입니다. GPU 운영자는 더 이상 들여다볼 수 있는 당사자가 아닙니다. Venice의 프록시는 여전히 잠시 동안 평문을 보지만, GPU 호스터는 보지 못합니다. 여기서의 전환은 정책에서 하드웨어로의 전환입니다. 신뢰는 사라지지 않지만, 그 대상이 바뀝니다. 이제 귀하는 NVIDIA의 기밀 컴퓨팅 설계, 증명 서명 체인 및 Venice의 구현을 신뢰합니다. 실제 위협에 대해 견고하지만, 완벽하지는 않습니다: TEE 설계(Intel SGX, AMD SEV)는 반복적으로 측면 채널 취약점이 발견되었으며, 현재 설계도 면역이 아닙니다. 이 취약점 연구를 밀접하게 추적하는 사용자의 경우, Level 4(신뢰할 수 있는 운영자 데이터센터 상의 Venice 프라이버시 모드)가 Level 6보다 합리적인 정착점일 수 있습니다. 왜냐하면 Venice의 운영 위생을 신뢰하는 것이 칩 공급업체의 증명 체인을 신뢰하는 것보다 더 편안할 수 있기 때문입니다. 애플의 Private Cloud Compute는 거의 동일한 아키텍처 계열에 속합니다: 하드웨어 지원 프라이버시 및 검증 가능한 사적 클라우드 추론. 그러나 Venice와의 차이는 현실적입니다. 애플은 자신이 통제하는 Apple Silicon을 사용하고, Apple Intelligence만 실행하며, 모델 선택을 노출하지 않습니다. Venice는 외부 TEE 파트너를 사용하며, 오픈소스 모델을 지원하고, 사용자가 요청 단위로 프라이버시 계층을 선택할 수 있습니다.
은유: 택배 서비스(Venice)는 귀하의 메모를 밀폐된 방음실(NVIDIA 기밀 컴퓨팅 GPU 상의 TEE/하드웨어 플라이트, Venice의 파트너 NEAR AI Cloud 및 Phala Network가 운영) 내에서 일하는 컨설턴트(모델)에게 전달합니다. 택배는 이동 중에 메모를 읽지만, 방 안의 컨설턴트는 누구도 관찰할 수 없으며, 건물 소유자(GPU 운영자)도 예외입니다. 방은 각 세션 후에 비워집니다.
Level 7: “Venice E2EE 모드.” TEE에 클라이언트 암호화가 추가된 형태입니다. 암호화 설정은 클라이언트와 실리콘 플라이트 사이에서 직접 발생합니다. 중간 Venice 프록시는 결코 키를 소유하지 않으므로, 이를 통해 전달되는 모든 콘텐츠는 귀하의 기기에서 암호문으로 발신되어, 실리콘 내에서 처리되는 순간까지 해독되지 않습니다. GPU 운영자 및 Venice 자체도 더 이상 들여다볼 수 있는 당사자가 제거됩니다. 유일하게 평문을 처리하는 것은 플라이트 내에서 실행되는 모델이며, 그 또한 일시적입니다. 이는 타인의 하드웨어 상에서 사용 가능한 가장 강력한 프라이버시 보장이며, 현재는 실용적인 속도로 LLM에 적용할 수 없는 완전 동형 암호화보다는 한 단계 아래입니다. Level 6의 모든 신뢰 의존성은 그대로 유지되며, 여기에 새로운 의존성이 추가됩니다: 클라이언트 암호화 자체가 올바르게 구현되어야 합니다. 이 계층에서 고유한 두 가지 기능 타협이 있습니다. 네트워크 검색 및 지속적 메모리와 같이 Venice 인프라가 평문을 읽어야 하는 기능은 비활성화됩니다. 모델 선택도 좁아집니다: 현재 TEE/E2EE 인프라 내부에 정확히 11개의 모델이 배포되어 있습니다: Venice Uncensored 1.2, GLM 5.1, GLM 4.7, GLM 4.7 Flash, Qwen3.5 122B A10B, Qwen 2.5 7B, Qwen3 30B A3B, Qwen3 VL 30B A3B, Gemma 3 27B, GPT OSS 20B 및 GPT OSS 120B.
은유: Level 6의 모든 내용은 여전히 유효합니다: 컨설턴트(모델)는 밀폐된 방음실에서 일하며, 외부에서 관찰할 수 없고, 각 세션 후에 방은 비워집니다. 새로 추가된 것은, 귀하가 택배(Venice)에게 메모를 넘기기 전에 스스로 메모를 자물쇠 상자(클라이언트 암호화)에 넣는 것입니다. 이제 택배는 불투명한 상자를 운반하며, 안을 볼 수 없으므로, 귀하의 메시지를 볼 수 있는 유일한 사람은 밀폐된 방 안의 컨설턴트입니다.
핵심 포인트: Level 0~2는 주로 정책 및 계약 업그레이드입니다. Level 3~4는 라우팅 및 모델/공급업체 노출을 변경합니다. Level 6~7은 하드웨어 지원 및 암호화 추론으로 신뢰 모델을 근본적으로 변경합니다. Venice의 차별화는 단일 제품 내에서 Level 3, 4, 6, 7을 모두 아우르는 데 있습니다.
특정 사용자에게 적절한 계층은 그들의 위협 모델에서 나옵니다. 기술적으로 가장 인상 깊어 보이는 메커니즘을 선택하는 것은 핵심을 놓치는 것입니다. Level 6 및 7은 일부 최첨단 기능을 희생하고 새로운 신뢰 의존성을 추가합니다. 이러한 비용에도 불구하고, 이는 오늘날 클라우드 추론에서 사용 가능한 가장 의미 있는 프라이버시 업그레이드입니다.
이것이 아키텍처가 작동하는 방식입니다. 더 어려운 질문은 누구에게 어느 계층이 진정으로 필요한지, 그리고 그 대상이 얼마나 큰지입니다. 서로 다른 위협 모델은 다른 사용자를 계단의 다른 부분으로 몰아가며, 일반적으로 선호가 아닌 강제에 의해 그렇게 됩니다. 따라서 형성되는 시장은 기술 마케팅이 암시하는 것보다 훨씬 큽니다. 아래에 분해합니다.
사용자 분류
프라이버시 입장은 추상적인 선호가 아닙니다. Venice의 상당 부분의 청중은 콘텐츠 정책, 규정 준수 팀, 위협 모델 또는 원칙에 의해 기본 옵션에서 밀려난 후 여기에 도달했습니다. 사용자가 더 이상 사용할 수 없는 대안을 적극적으로 찾을 때, 마케팅 작업은 훨씬 쉬워집니다. 분석할 가치가 있는 여섯 개의 세분화된 집단은 다음과 같습니다:
규제 및 규정 준수 중심의 업무. 중대한 비공개 정보를 다루는 금융 팀, HIPAA 규제를 받는 의료 종사자, 특권 통신을 다루는 변호사, 인수합병 및 거래 프로세스 전문가. 규정 준수 팀은 일반적으로 Level 0을 허용하지 않습니다. 많은 이들이 Level 2에 머물러 있는데, 이는 Anthropic 및 OpenAI의 기업 조건(훈련 금지, 단기 보관, 계약상 구제 수단)이 일반적인 규정 준수 기준을 통과하기 때문입니다. 일부는 Level 6으로 진전되는데, 이는 다른 곳에서 정책 변경으로 피해를 입었거나, 강제 공개 시 실제 손실을 초래할 수 있는 데이터를 다루기 때문입니다. Anthropic은 이 세그먼트 시장에서 상당한 기업 비즈니스를 구축한 것으로 보이며, 의료 및 금융 분야의 규제 방향은 더 엄격한 프라이버시 보호 컴퓨팅 요구로 향하고 있습니다. Venice가 현재 이곳에서 가장 명확한 적합성은 기업 구매가 아닌, 개인적 신중함으로 Pro를 구매하는 독립 전문가입니다. 기업 구매는 프라이버시 아키텍처만 보지 않습니다. 규정 준수 팀은 서명 전에 관리 통제, 감사 로그, SOC2 보고서, 서명된 DPA, 실제 SLA 및 통합 지원이 필요합니다. 암호화 이야기는 중요하지만 충분하지 않습니다. 구매 주도의 기업 시장은 Apple PCC, Microsoft Azure Confidential Computing, Phala 또는 NEAR에 의해 직접 경쟁되고 있습니다.
Venice API를 기반으로 구축하는 개발자. Venice의 API는 OpenRouter, Cursor, VSCode, Brave Leo 및 Fleek과 같은 개발자 통합에서 주목을 받았습니다. 여기서 가장 명확한 사용 사례는 개발자가 자신의 제품에 프라이버시를 존중하는 AI 기능을 구축하고, 최종 사용자에게 “귀하의 데이터는 비밀로 유지됩니다”라고 보장하려는 경우입니다. 계층 매핑은 개발자가 구축하는 내용에 따라 달라질 수 있습니다: 비용 민감한 소비자 기능은 익명 모드(Level 3), 기본 OSS 라우팅은 프라이버시 모드(Level 4), 아키텍처 프라이버시를 주요 판매 포인트로 삼는 제품은 TEE 또는 E2EE(Level 6~7)를 사용할 수 있습니다. Venice API를 사용하는 개발자는 최종 사용자 각각이 Venice 구독을 구매하지 않고도 수많은 최종 사용자를 서비스할 수 있으므로, 단위 경제 효율은 직접 소비자 구독과 크게 다를 수 있습니다.
고위험 개인 사용. 심리 건강 및 치료 관련 문의가 계정 기록에 남는 것을 원하지 않을 수 있습니다. 성 정체성 또는 성별에 관한 정체성 탐색은 아직 공개할 준비가 되지 않았을 수 있습니다. 결혼, 이혼, 고용 또는 가족 역학에 관한 논의는 이러한 문의 자체가 노출되면 피해를 초래할 수 있습니다. 이러한 사용자 중 다수는 Level 1에 머물러 있으며, 익명 채팅이 그들을 숨긴다고 생각합니다. 프라이버시 의식이 강한 하위 집단은 일반적으로 실험실에 완전히 숨길 수 없다는 것을 이해한 후 Level 6으로 전환합니다. AI 심리 건강은 성장 중인 카테고리로 보이지만, 임상 및 소비자 제품의 규모와 품질은 다양합니다. Venice의 관점에서 규모를 추정하기는 어렵습니다. 왜냐하면 이 세그먼트의 많은 사용자가 실수로 자신이나 그들이 아는 사람이 당할 때까지 하드웨어 인증 프라이버시를 찾아야 한다는 것을 알지 못하기 때문입니다.
대립적 환경. 정보 출처를 보호하는 기자, AI 사용을 감시하는 사법 관할권에 있는 활동가, 이견자 및 정치 조직가, 위협 행위자를 연구하는 보안 연구원, 신고자를 대리하는 변호사. 이러한 사용자는 일반적으로 Level 6 및 7이 필요합니다. 낮은 계층은 그들의 위협 모델 하에서는 생존할 수 없습니다. Proton을 살펴보면: 프라이버시 우선의 평판과 스위스 법률 관할권을 가지고 있음에도 불구하고, 대부분의 법적 요청을 준수하며, 이는 종종 스위스 법률이 그렇게 요구하기 때문입니다. 이것은 대규모에서 정책 기반 프라이버시가 마주칠 수 있는 실패 모드입니다. Venice의 TEE 및 E2EE 아키텍처는 클라우드 설정에서 제공업체가 평문을 보유하도록 설계되지 않은 유형에 속합니다. 평문은 이러한 강제 요청을 준수하는 데 필수적입니다. 그러나 아키텍처는 한계가 있습니다. Level 6 및 7은 평문 노출을 줄이지만, 전체 그림을 수정할 수는 없습니다. 계정 메타데이터, 결제 경로, Venice가 기록한 사용 정보, 귀하의 노트북이 수행하는 작업, 법원이 귀하로부터 강제로 확보할 수 있는 것 등은 모두 사용자에게 남아 있습니다. 진정한 대립적 위협 모델을 가진 사람에게는 이는 더 광범위한 도구 킷의 일부일 뿐입니다. 이 세그먼트의 수치적 규모는 작습니다. 소환에 견딜 수 있는 도구에 지불할 의향은 일반적으로 매우 높습니다.
암호화 원생 및 프라이버시 문화 사용자. Web3 개발자, 주권을 중시하는 기술 전문가, 자신만의 노드를 운영하고 하드웨어 인증 보장을 원칙으로 삼는 사람. 이 세그먼트는 개인 위협 모델에 따라 Level 3~7을 가로질 수 있으며, 원칙 기반의 하위 집단은 민감한 쿼리에서 기본적으로 6 또는 7을 사용합니다. AI x crypto는 더 광범위한 암호화 생태계 내에서 의미 있는 카테고리가 되었으며, Bittensor와 같은 인프라 참여자들이 중요한 입지를 확보했습니다. 업계 조사에서는 중앙 집중형 결제 감시가 우려되는 신흥 시장에서 자기 호스팅 관심도가 더 높다고 자주 보고합니다. Venice의 입장은 폐쇄형 실험실 경쟁사가 따라잡지 못한 방식으로 이 세그먼트와 잘 맞습니다: VVV 기반 가격 책정, KYC 없음, Erik Voorhees의 평판, VVV 및 MOR 보유자에게 제공된 역사적 무료 Pro 레벨이 이 집단을 육성했습니다. Venice의 자연스러운 문화적 기반 및 최초 유료 사용자 중 중요한 부분일 수 있습니다.
성인 콘텐츠 및 폐쇄형 실험실이 직접 거부하는 기타 카테고리. OpenAI, Anthropic 및 Google은 일반적으로 NSFW 성 콘텐츠를 거부합니다. Level 0에서 막히는 다른 카테고리는 성숙한 창작 글쓰기, 약물 감소 피해 문제, 그리고 낙인이 찍혔지만 합법적인 주제의 긴 목록 등이며, 공급업체마다 다르게 처리되며, 때때로 관대함을 보입니다. 이러한 카테고리의 사용자는 일반적으로 Level 0에서 시작할 수 없습니다. 모델이 일반적으로 거부합니다. 단순한 모델 선택만으로도 그들은 일반적으로 무검열 오픈소스 변형이 사용 가능한 Level 4~7로 밀려납니다. 대부분의 유료 사용자는 일상적인 사용에서 Level 4에 머물러 있을 가능성이 높으며, 프라이버시에 민감한 하위 집단은 6 또는 7로 나아갑니다. 이 카테고리는 크다고 보입니다: Character.AI 및 Replika는 모두 유의미한 소비자 규모로 운영되고 있으며, AI 동반 애플리케이션은 소비자 AI의 눈에 띄는 하위 집단으로 성장했습니다. 이러한 사용자는 일반 챗봇 사용자보다 프라이버시를 더 걱정할 가능성이 높은데, 그 이유는 노출 비용 때문입니다: 선호도 프로필 유출은 결혼, 직장 또는 양육권 사건을 망칠 수 있습니다. Venice의 현재 계량 기준에서 가장 큰 청중일 수 있습니다.
이 집단들에서 두드러지는 점은, 그들 중 거의 누구도 편안한 경로에서 밀려나는 것이 아니라, 콘텐츠 정책, 규정 준수 팀, 위협 모델 또는 원칙에 의해 강제되거나 밀려난다는 점입니다. 프라이버시 우선 AI는 일반적으로 사람들이 처음 들어서는 카테고리가 아닙니다. 그들은 원래 있던 곳에 머물 수 없다는 것을 깨닫고 도달하는 경우가 많습니다. 동일한 논리는 두 인접한 세그먼트를 설명할 수 있습니다. 규모를 추정하지는 않지만 표시할 가치가 있는 것은, 사법 관할권 때문에 중앙 집중형 결제 및 AI 감시에서 벗어나려는 국제 사용자와, 조정 데이터가 프라이버시를 존중하는 백엔드에서 이득을 볼 수 있는 초기 개인 AI 에이전트 그룹입니다.
시장 규모
Venice의 최종 상한선은 현재 실행 상황이 아니라 접근 가능한 시장 규모에 달려 있습니다. 올바른 프레임워크는 추론 점유율입니다: Venice는 AI 추론 서비스를 판매하며, 관련 시장은 전 세계 추론 지출이며, Venice의 수익은 그 풀의 일부입니다.
2027년 추론 시장에 대한 독립적인 추정치는 전 세계적으로 1400~1600억 달러로 수렴하고 있으며, 베인, IDC 및 맥킨토시의 예측도 이 범위에 대체로 부합합니다. Venice가 예상하는(본 평가 섹션에서 전개할 제 예측) 2027년 말 4억 달러 연간 실행 속도를 기준으로 해도, Venice는 이 풀의 0.3% 미만을 차지하며, 합리적인 시장 정의 하에서는 사소한 점유율입니다. 참고로, OpenAI의 API 사업만 해도 오늘날 추론 지출의 한 자릿수 퍼센트를 차지한다고 추정되며, Anthropic의 API도 유사한 범위입니다. Venice의 현재 위치는 중형 추론 플랫폼이 차지하는 점유율보다 훨씬 낮습니다.
하지만 Venice는 전체 풀을 차지하려 하지 않습니다. Venice의 목표은 익명성, 하드웨어 인증 프라이버시, 무검열 접근 또는 추론 과정에서의 사법 관할권 선택이 필요한 사용자 및 기업을 위한 프라이버시 세그먼트입니다. 이 하위 집단의 규모를 정확히 계산하는 것은 어렵지만, 방향성 신호는 매우 강합니다.
추론의 프라이버시 세그먼트를 확대하는 여러 힘이 있습니다: 유럽 및 아시아 일부 지역에서 점점 더 엄격해지는 데이터 거주 규정, 기업과 기본 폐쇄형 실험실 제품 간 점점 더 커지는 규정 준수 마찰, TEE 기반 프라이버시 인프라의 성숙. 기업 조사는 AI 기반 데이터 노출에 대한 점점 더 커지는 우려를 지속적으로 표시하고 있습니다. 이 힘들은 개별적으로는 느리지만, 중첩됩니다.
프라이버시 세그먼트 클라우드 추론 시장이 2027년 추론 시장의 1400~1600억 달러 중 5~15%만 차지하더라도, 이는 70~230억 달러 규모의 세그먼트입니다. 한 자릿수 점유율만으로도 Venice는 수억 달러의 수익에 도달할 수 있으며, 현재 실행 속도보다 훨씬 높고, 여전히 큰 성장 여지가 있습니다. 중간 한 자릿수 점유율은 Venice를 10억 달러 이상 수익 범위로 끌어올립니다.
비관적인 시나리오는 세 가지 차원에서 존재합니다. 첫째, 초대규모 클라우드 서비스 제공업체가 기존 플랫폼 내에서 충분한 프라이버시 옵션을 제공함으로써 프라이버시 세그먼트 클라우드 추론 시장이 의미 있는 규모에 도달하지 못할 수 있습니다. Apple PCC, Azure Confidential Computing 및 AWS Bedrock 비밀 추론이 모두 이 방향으로 나아가고 있습니다. 이 경우 프라이버시는 여전히 중요하지만, 기존 클라우드 및 소비자 플랫폼에 통합되어 독립적인 프라이버시 우선 시장은 독립적인 플레이어를 지원할 만큼 규모가 커지지 않을 수 있습니다.
둘째, 로컬 추론이 주류 사용자에게 실현 가능해질 수 있습니다. 오픈소스 모델 품질은 대부분의 일상적인 작업 부하에 대해 이미 충분히 강력합니다. 병목은 로컬 모델을 실행하는 데 필요한 설정 마찰 및 기술 능력입니다. 이 병목이 더 정교한 개봉 즉시 사용 가능한 솔루션, 더 간단한 설치 프로그램 및 운영 부담을 처리하는 통합을 통해 완화됨에 따라, 프라이버시를 중시하는 상당한 부분의 사용자가 클라우드 서비스에 비용을 지불하기보다는 로컬에서 추론을 실행할 가능성이 있습니다. 이는 그들을 완전히 Venice의 접근 가능한 시장에서 제거합니다. 이 우려의 시점은 소비자 친화적인 로컬 스택의 성숙 속도에 달려 있습니다.
셋째, 프라이버시 시장이 의미 있는 규모로 실현되더라도, Venice는 Brave Leo, DuckDuckGo, Proton의 Lumo, Maple 및 Tinfoil과 같은 다른 프라이버시 원생 경쟁자들과의 경쟁에서 점유율을 확보해야 합니다. 이들 각각은 Venice의 번들 패키지의 여러 부분을 다른 각도에서 겨냥합니다. 경쟁 구도 섹션에서는 Venice의 프라이버시 심도, 무검열 접근, 암호화 원생 유통 조합과 이러한 특정 위협을 비교합니다.
경쟁 구도
Venice의 경쟁군은 “다른 프라이버시 AI 애플리케이션”보다 더 광범위합니다. 다양한 플랫폼이 동일한 수요를 경쟁합니다: 프라이버시를 중시하는 소비자, 모델 선택을 원하는 개발자, 무검열 콘텐츠를 추구하는 사람, 암호화 원생 구매자. 다음 섹션은 다섯 가지 카테고리를 다룹니다.
이 구도는 부분적인 대체품들이 Venice의楔子를 다양한 각도에서 끌어당기는 모습입니다. Brave와 DuckDuckGo는 유통을 놓고 경쟁합니다. OpenRouter는 개발자 API를 놓고 경쟁합니다. Tinfoil, NEAR, Phala 및 Maple은 프라이버시 아키텍처 자체를 놓고 경쟁합니다. 최첨단 실험실은 기업 측면에서 더 나은 모델에 충분히 좋은 프라이버시를 내장합니다. 현재 이 제품들은 Venice의 완전한 번들 패키지—기본 프라이버시 소비자 AI, 무검열 접근, 다중 모델 선택, 암호화 원생 결제 및 토큰화된 사용 경제학—을 모두 포장하지 못합니다.
가장 약한 것부터 가장 강한 것까지 구분되는 프라이버시 수준은 다음과 같습니다:
훈련 금지: 공급업체가 귀하의 데이터를 훈련에 사용하지 않겠다고 약속함(표준 Anthropic 및 OpenAI API 조항)
제한적 또는 제로 보관: 공급업체가 남용 모니터링을 위해 프롬프트를 잠시 보관하거나, 프롬프트 및 응답 콘텐츠가 처리 후 저장되지 않는 ZDR 구성(OpenAI ZDR, OpenRouter ZDR)을 제공함
익명 프록시: 공급업체는 프롬프트를 보지만 신원은 보지 않음(Venice Anonymous, Brave Leo, DuckDuckGo AI Chat)
TEE/하드웨어 인증: 프롬프트가 운영자가 읽을 수 없는 플라이트에서 실행됨(Venice TEE, Tinfoil, NEAR Private Chat, Apple PCC)
E2EE 진입 TEE: 공급업체는 암호문만 봄(Venice E2EE, Maple AI)
로컬: 모델이 귀하의 하드웨어에서 실행됨(Ollama, LM Studio)
Venice는 익명 프록시, 프라이버시 채팅, TEE 및 E2EE 모드를 단일 사용자 경험에서 모두 아우르는 소비자 제품 중 소수에 불과하며, 사용자는 요청 단위로 모드를 선택할 수 있습니다.
기본 AI 플랫폼(OpenAI, Anthropic, Google, xAI)
최첨단 실험실은 기업 고객에게 진정한 프라이버시를 제공하고 있습니다. OpenAI는 기본적으로 API 또는 기업 데이터를 훈련에 사용하지 않으며, 자격이 있는 고객을 위해 ZDR 구성도 제공합니다. Anthropic는 기업 제품 입력 또는 출력을 훈련에 사용하지 않습니다. Google Vertex AI는 기업 수준 훈련 제한을 제공합니다. xAI는 또한 사용자 프라이버시 제어를 홍보하지만, 그 자세는 OpenAI, Anthropic 및 Google의 더 성숙한 기업 약속과 별도로 취급되어야 합니다. Venice는 최첨단 실험실이 하지 않는 일을 추구합니다: 익명 접근, 무검열 모델, 암호화 원생 결제. 이 시장은 주류 AI보다 작지만, 현실적입니다. 최첨단 실험실은 대부분의 일반 사용자를 서비스합니다. Venice는 기본 옵션에서 벗어나고 싶은 일부를 서비스합니다.
세그먼트별로 살펴보면:
소비자 채팅: Venice는 익명성, 더 적은 보호주의 콘텐츠, 암호화 결제를 제공합니다. 실험실은 능력 및 브랜드 측면에서 승리합니다.
전문 소비자: Venice는 모델 선택 및 더 적은 잠금을 제공합니다. 실험실은 코딩 통합, 메모리 및 도구 측면에서 승리합니다.
기업: 현재 SOC2, DPA, 관리 통제, 감사 로그가 없는 Venice의 이야기입니다. 실험실 및 초대규모 클라우드 서비스 제공업체가 이 시장을 장악하고 있습니다.
API: Venice는 프라이버시 심도 및 무검열 접근을 제공합니다. 실험실은 모델 품질 및 생태계를 제공합니다.
프라이버시 원생 유통 측면(Brave, DuckDuckGo)
Brave는 프라이버시 분야에서 가장 강력한 소비자 유통 전략입니다. Brave는 2026년 4월 기준 1.15억 명 이상의 월 활성 사용자와 4700만 명의 일일 활성 사용자를 보고하고 있으며, Leo Premium은 14.99달러/월 가격과 무료 레벨을 제공합니다. Leo는 계정 선택 가능하며, 로컬에 기록을 저장하고, Brave의 공식 정책에 따르면 Brave 서버에 프롬프트를 보관하지 않습니다. Brave는 NEAR AI의 NVIDIA 지원 TEE를 통해 프록시 프라이버시에서 검증 가능한 프라이버시로 전환하고 있으며, 이는 하드웨어 지원 AI 프라이버시가 주류 제품 기능이 되고 있음을 강화합니다.
DuckDuckGo AI Chat은 자세 면에서 유사합니다: 무료, 계정 없음, OpenAI, Anthropic, Meta 등 다양한 제3자 모델로 순환되는 익명 프록시. DuckDuckGo는 채팅이 저장되거나 훈련에 사용되지 않는다고 말합니다. Duck.ai는 이제 더 진보된 모델을 제공하는 유료 레벨도 있습니다.
Proton의 Lumo는 이 분야에서 세 번째 의미 있는 참가자입니다. Lumo는 2025년 7월에 출시되었으며, 2026년 1월에 기반 프로젝트 암호화 작업 공간을 통해 확장되었습니다. 이는 서버측 로그 없이, 사용자 데이터를 훈련에 사용하지 않는 제로 액세스 암호화 AI 보조 기능을 제공합니다. Lumo는 Proton의 유럽 기반에서 운영되며, 미국 관할권 밖에 있으며, 이메일, VPN 및 클라우드 드라이브 제품을 포함한 Proton의 기존 프라이버시 중심 사용자 기반을 대상으로 합니다. Venice와 비교할 때, Lumo의 모델 선택은 더 제한적이며, 최첨단 폐쇄형 실험실, 무검열 콘텐츠, 암호화 원생 유통이 없습니다. 그러나 Proton은 프라이버시 중심 사용자 사이에서 확립된 브랜드를 가지고 있는 반면, Venice의 브랜드는 현재 세그먼트 외부에서 인정을 받아야 합니다.
Brave, DuckDuckGo 및 Lumo가 위험한 이유는 전환 경로를 단축시키기 때문입니다. 이들은 사용자가 프라이버시 AI를 찾아야 한다고 설득할 필요가 없습니다. 이들은 사용자가 이미 사용 중인 브라우저, 검색 프로세스 또는 이메일/VPN 생태계 내에서 바로 프라이버시 중심 사용자에게 도달합니다. 일반 사용자에게는 이들이 제공하는 프라이버시와 익숙한 브랜드가 충분할 수 있습니다. Venice는 다른 경쟁사에 따라 다른 차원에서 차별화됩니다: Brave 및 DuckDuckGo와의 경쟁에서는, 프록시보다 훨씬 깊은 프라이버시 스택과 더 광범위한 모델 카탈로그를 제공하며, Lumo와의 경쟁에서는, Anonymous 모드를 통한 최첨단 폐쇄형 실험실 접근, 무검열 콘텐츠, 암호화 원생 경제학이 차별화 요소이며, 프라이버시 심도 자체가 아닙니다.
API 라우팅 및 어그리게이션(OpenRouter, Together AI, Fireworks, Replicate)
OpenRouter는 이미 많은 개발자에게 기본 라우팅 계층이 되었습니다. 그들은 2025년 a16z, Menlo 및 시퀀스 캐피털에서 4000만 달러의 시드 및 A라운드 자금을 조달했으며, 약 5.5억 달러의 기업 가치를 기록했습니다. 2026년 4월 기준, CapitalG 주도의 1.2억 달러 자금 조달을 논의 중이며, 약 5000만 달러의 ARR 및 15만 명 이상의 월 활성 개발자를 기반으로 한 기업 가치는 13억 달러입니다. 이 제품은 올바른 인터페이스, 글로벌 및 요청 단위로 사용 가능한 ZDR 제어, 그리고 이미 통합된 개발 팀의 개발자 마인드쉐어를 갖추고 있습니다. OpenRouter는 Venice Uncensored를 포함한 Venice 모델도 유통하며, 이는 Venice API 사업의 경쟁사이자 유통 채널이기도 합니다.
Venice의 API 차별화는 더 좁지만 더 명확합니다: 프라이버시 우선 포장, Venice 원생 무검열 모델, 암호화 원생 결제 프로세스, VVV 및 DIEM 경제학과의 직접 연계. Together AI, Fireworks 및 Replicate는 프라이버시를 특별히 중시하지 않는 개발자에게 저렴한 OSS 추론을 제공하는 다양한 차원에서 경쟁합니다. 이들은 인접한 경쟁사일 뿐, 직접적인 경쟁사는 아닙니다.
Venice의 API 로드맵은 프라이버시 및 무검열 접근을 중심으로 합니다. 라우팅 유연성 및 개발자 경험에 대한 지속적인 투자는 Venice가 소비자 구독 사업 성장 속도보다 얼마나 많은 API 점유율을 확보할 수 있을지를 결정할 것입니다.
기밀 추론 인프라(Tinfoil, NEAR AI Cloud, Phala Network, Maple)
현재 Venice 아키텍처의 일부와 중복되는 여러 제품이 있습니다. Tinfoil은 기밀 컴퓨팅 GPU에서 TEE 인증 추론을 제공하며, OpenAI와 호환되는 API를 채택하여 개발자 및 인프라 사용 사례를 대상으로 합니다. NEAR AI Cloud는 Venice의 TEE 모드를 지원하며, 동시에 자체 소비자 제품인 NEAR Private Chat을 출시했습니다. Phala Network는 Venice의 E2EE 인프라 및 OpenRouter의 기밀 라우팅을 지원합니다. Maple은 소비자 중심이며 프라이버시를 중시하며, 보안 격리된 영역에서 E2EE 채팅을 제공합니다.
Venice는 의식적으로 전문 기밀 컴퓨팅 파트너 위에 구축하면서, 애플리케이션 계층, 사용자 관계, 브랜드, 결제 및 모델 패키징을 모두 갖추고 있습니다. 계약 기반 프라이버시는 이제 기본 요구사항이 되고 있으며, 검증 가능한 프라이버시가 다음 프런티어가 되고 있습니다. Venice의 차별화는 다른 누군가가 TEE 또는 E2EE를 갖추지 못한다는 데 있지 않습니다. Venice는 여러 프라이버시 모드, 무검열 콘텐츠, 모델 접근, 암호화 결제 및 토큰화된 사용을 단일 소비자 및 API 제품에 모두 포장한다는 데 있습니다.
로컬 및 운영체제 수준 AI(Ollama, LM Studio, Apple Private Cloud Compute)
로컬 AI는 진정한 잠재적 경쟁자입니다. Ollama 및 LM Studio는 기술 사용자에게 이미 우수한 서비스를 제공해 왔으며, 소비자용 하드웨어의 가속화와 함께 이 청중은 계속 확대되고 있습니다. 오픈소스 모델 품질은 현재 대부분의 일상적인 작업 부하에 대해 이미 충분히 강력합니다. 오늘날 일반 사용자가 클라우드 서비스를 계속 사용하는 이유는 로컬 모델 실행의 설정 마찰 및 운영 부담입니다. 이 격차가 더 정교한 개봉 즉시 사용 가능한 솔루션, 더 간단한 설치 프로그램 및 운영 부담을 처리하는 통합을 통해 좁혀짐에 따라, 프라이버시를 중시하는 사용자 중 로컬을 선택하고 클라우드 서비스에 비용을 지불하지 않는 비율은 증가할 것입니다. 시점은 불확실하지만, 일반적인 장기 프레임워크가 암시하는 것보다 더 빠르게 압축될 수 있습니다.
Apple Private Cloud Compute는 전략적으로 관련성이 있습니다. PCC는 Apple Silicon에서 Apple Intelligence를 실행하며, 하드웨어 지원 프라이버시를 통해 프라이버시 AI를 플랫폼 기능으로 정상화합니다. PCC는 Apple 기기상의 Apple Intelligence에 제한되어 있으므로, Venice와 직접 경쟁하지는 않습니다. 그러나 프라이버시 AI가 어떤 모습이어야 하는지에 대한 소비자 인식을 교육함으로써 Venice가 속한 카테고리에 유리합니다.
Venice의 진정한 차별화 요소
현재 시장에서 Venice만이 제공하는 세 가지 유일한 조합입니다:
단일 소비자 제품 내에서 요청 단위로 선택 가능한 여러 프라이버시 모드. Anonymous, Private, TEE 및 E2EE가 하나의 애플리케이션에 모두 있으며, 사용자는 프롬프트 수준에서 모드를 선택합니다. 몇몇 경쟁사는 이 기능 중 일부를 제공하지만, Venice는 완전한 기능 세트를 소비자 경험 계층과 함께 제공합니다.
강력한 프라이버시와 무검열 콘텐츠 접근의 결합. 폐쇄형 실험실은 기업 포지셔닝을 포기해야만 이를 따라잡을 수 있습니다. 어느 누구도 이를 수행하려는 의지를 보이지 않았습니다. 기업을 대상으로 하는 프라이버시 플레이어도 동일한 문제를 겪으며, 규정 준수 요구에 의해 더욱 악화됩니다. Venice는 Venice Uncensored 1.2를 최첨단 폐쇄형 실험실 옆에 호스팅합니다. Venice는 폐쇄형 실험실보다 콘텐
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News









