

채팅GPT 헬스 출시 6일 만에 OpenAI, 자체 의료 건강 벤치마크에서 역전당해
저자: Li Yuan
AI 어시스턴트에게 건강 문제를 물어본 적이 있나요?
제가 AI의 심도 있는 사용자라면 아마 여러분도 한 번쯤은 해봤을 겁니다.
OpenAI가 공개한 데이터에 따르면 건강 분야는 이미 ChatGPT의 가장 일반적인 사용 사례 중 하나로 자리 잡았으며 전 세계적으로 매주 2.3억 명 이상이 건강 및 보건 관련 질문을 하고 있습니다.
이러한 이유로 인해 2026년에는 헬스케어 분야가 AI 산업에서 필수적으로 확보해야 할 영역으로 부상할 조짐을 보이고 있습니다.
1월 7일 OpenAI는 사용자가 전자의무기록(EMR)과 다양한 헬스 앱을 연결해 더욱 맞춤화된 의료 응답을 받을 수 있도록 하는 ChatGPT Health를 발표했고, 이어서 1월 12일 Anthropic도 새로운 모델의 의학적 활용 능력을 강조하며 Claude for Healthcare를 출시했습니다.
흥미롭게도 이번에는 중국 기업들이 뒤처지지 않았을 뿐 아니라 오히려 앞서 나가는 모습마저 보였습니다.
1월 13일 백천지능(Baichuan AI)은 OpenAI가 개발한 헬스케어 분야 평가 벤치마크인 HealthBench에서 GPT-5.2 High를 넘어 SOTA(SOTA: 최고 성능)를 달성한 백천 M3 모델을 발표했습니다.
'올인 메디컬' 선언 이후 여러 의문을 받아왔던 백천지능은 마침내 그 실력을 입증하는 듯했습니다. GeekPark는 이번 M3 모델의 능력과 AI 의료의 궁극적 미래에 대해 왕샤오촨(Wang Xiaochuan) 대표와 특별히 인터뷰를 진행했습니다.
01 건강 분야 평가에서 처음으로 OpenAI를 앞서다
이번에 발표된 M3 모델의 가장 두드러진 성과는 바로 OpenAI가 발표한 의료·헬스케어 분야 평가 세트 HealthBench에서 처음으로 OpenAI의 GPT-5.2 High를 제치고 SOTA를 달성했다는 점입니다.
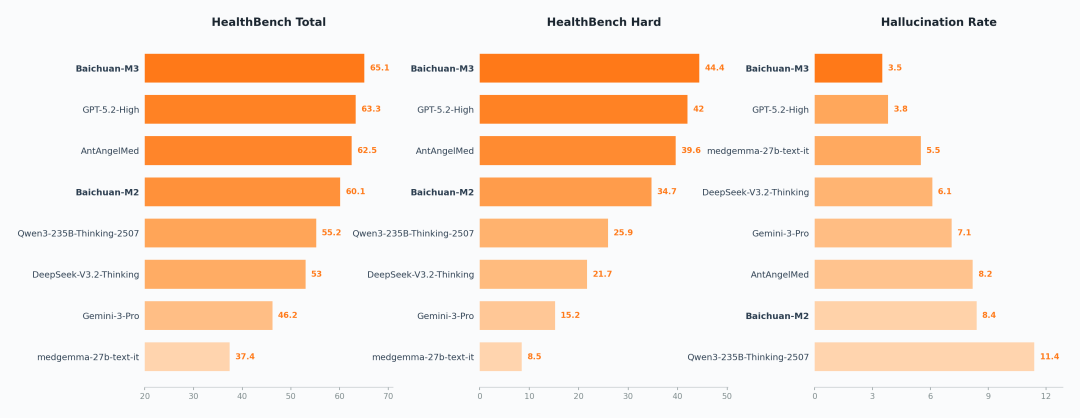
SOTA On Healthbench, Healthbench Hard 및 환각 평가 결과
Healthbench는 2025년 5월 OpenAI가 발표한 것으로, 60개국 출신 262명의 의사들이 공동으로 구축한 의료 평가 세트입니다. 총 5,000개의 고도로 현실감 있는 다중 회전 진료 대화를 포함하고 있으며 현재 전 세계에서 가장 권위 있고 실제 임상 상황에 가장 근접한 의료 평가 도구 중 하나입니다.
출시 이후 OpenAI 모델이 줄곧 1위를 지켜왔지만, 이번 백천지능의 차세대 오픈소스 의료 대규모 모델 Baichuan-M3는 종합 점수 65.1점을 기록하며 세계 1위를 차지했습니다. 특히 복잡한 의사결정 능력을 시험하는 HealthBench Hard에서도 최고 점수를 갱신하며 우승했습니다.
백천지능은 동시에 환각률(hallucination rate) 테스트 결과도 공개했는데, M3 모델의 환각률은 3.5%로 세계 최저 수준입니다.
특히 주목할 점은 이 환각률이 외부 검색 도구 없이 순수 모델 설정 하에서 측정된 의료 환각률이라는 점입니다.
백천지능은 이러한 성과를 달성한 핵심 요인으로 의료 분야에 적합한 강화학습 알고리즘 도입을 꼽습니다.
M3 모델에서는 '팩트 인식 강화학습(Fact Aware RL)' 기술을 처음 적용하여 모델이 막연한 말만 반복하지 않도록 하면서 동시에 무책임한 답변을 내놓는 것도 방지했습니다.
이는 의료 분야에서 매우 중요한 의미를 가집니다.
최적화되지 않은 모델에 의료 질문을 할 경우 가장 자주 발생하는 문제는 크게 두 가지입니다. 첫째는 증상을 거짓으로 만들어내며 가상의 질병을 진단하는 것이고, 둘째는 모호한 표현을 사용한 끝에 결국 "의사에게 가보라"고 조언하는 것입니다. 이런 응답은 환자든 의사든 모두에게 큰 도움이 되지 않습니다.
이는 많은 모델들이 단순히 환각률만을 최적화 목표로 삼아, 올바른 사실들을 나열함으로써 전체 환각률을 낮추려 하기 때문입니다. 백천지능은 의미 클러스터링과 중요도 가중치 메커니즘을 도입하여 중복된 설명의 방해를 제거하고 핵심 의학 판단에 더 높은 가중치를 부여하도록 했습니다.
또한 단순히 환각에 대한 패널티를 강화하면 모델이 '말을 덜 하면 실수도 적다'는 보수적인 전략으로 기울기 쉬운데, Fact Aware RL 알고리즘은 동적 가중치 조절 메커니즘을 설계하여 모델의 능력 수준에 따라 두 목표를 자동으로 균형 있게 조절합니다. 즉 능력 형성 초기에는 의학 지식 습득과 표현에 초점을 맞추고(높은 Task Weight), 능력이 성숙되면 점차 사실성 제약을 강화하여(Hallucination Weight 증가) 정확성을 높입니다.
온라인 검색이 가능한 경우 백천지능은 다중 검색 기반 온라인 검증 모듈과 함께 대규모 의료 지식 정렬을 위한 고효율 캐시 시스템도 추가했습니다.
02 인간 의사 수준을 넘어선 진료 능력, 실용 단계 진입
그러나 HealthBench에서 OpenAI를 앞선 것만이 이번 성과의 유일한亮点(하이라이트)는 아닙니다.
더 흥미로운 점은 백천지능이 OpenAI의 벤치마크를 따라가기보다 스스로 SCAN-bench라는 평가 세트를 창안했다는 점입니다. 이 자체 평가 세트는 백천지능이 의료 분야에서 어떤 방향으로 최적화를 추구하고 있는지를 더 잘 보여줍니다.
SCAN-bench의 핵심은 '엔드투엔드(end-to-end) 진료 능력'을 개선하는 데 있습니다. 이는 백천지능이 자체 실험을 통해 얻은 통찰에서 비롯됐는데, '질병 문진 정확도가 2% 향상되면 진단 정확도가 1% 증가한다'는 결론을 도출한 것입니다.
즉 OpenAI의 HealthBench가 여전히 'AI가 질문에 답할 수 있는가'에 집중한다면, 백천의 SCAN-bench는 AI가 일련의 질문과 답변을 통해 효과적으로 정보를 수집하고 정확한 진단 및 의학적 조언을 제공할 수 있는지를 평가하려는 목적을 가지고 있습니다.
일반적으로 AI 어시스턴트에게 '당신은 경험이 풍부한 의사입니다'라고 지시하더라도 좋은 결과를 기대하기 어렵습니다. 실제 의사들의 문진 프로세스는 매우 체계적이기 때문인데, 백천지능은 이를 네 가지 영역으로 정리한 SCAN 원칙으로 요약합니다. Safety Stratification(안전 분류), Clarity Matters(정보 명확화), Association & Inquiry(관련 질문), Normative Protocol(표준화 출력).
이 SCAN 원칙을 바탕으로 백천지능은 오랫동안 의학 교육에서 사용되어 온 OSCE(Objective Structured Clinical Examination) 방법을 참고하여 150명 이상의 현직 전문의들과 협력해 SCAN-bench 평가 체계를 구축했습니다. 이 체계는 진료 과정을 병력 수집, 보조 검사, 정밀 진단의 세 단계로 나누고 동적·다중 회전 방식으로 평가함으로써 실제 의사가 접수부터 확진까지 거치는 전 과정을 완벽히 시뮬레이션합니다. 그리고 각 단계에서 더 나은 성과를 거두도록 모델을 최적화합니다.
백천지능은 또한 M3 모델이 SCAN-bench에서의 평가 결과를 공개했습니다.
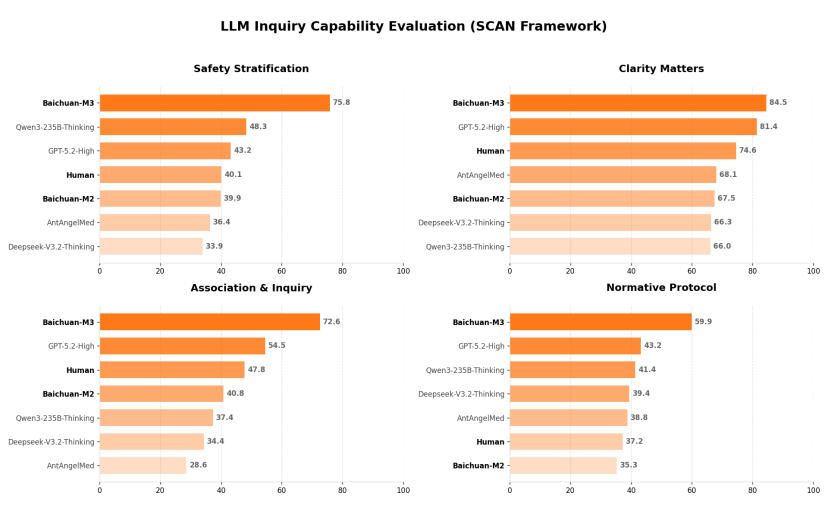
결과는 매우 흥미롭습니다. 백천지능은 단순히 다른 모델들과 비교하는 것을 넘어서 실제 인간 의사들과도 직접 비교를 수행했습니다. 네 가지 영역 전반에서 인간 전문의들은 이미 모델이 달성한 수준에 미치지 못했습니다.
GeekPark은 이에 대해 백천팀에 직접 질문했고, 답변은 다음과 같습니다. 이번 평가는 모두 해당 전공 분야의 실제 전문의들이 전공 진료 사례를 대상으로 모델과 비교한 것입니다. 모델이 승리한 이유는 우선 모델이 더 인내심 있게 반응한다는 점이며, 무엇보다도 모델이 더 뛰어난 다학제적 지식 통합 능력을 갖추고 있기 때문입니다.
예를 들어 10세 어린이가 반복적으로 발열하는 사례를 들 수 있습니다. 발열은 매우 복합적인 의학적 현상인데, 기침 등 폐부위 증상만 묻는다면 관절이나 비뇨계의 심각한 문제를 간과하고 단순 감염으로 잘못 판단하기 쉽습니다.
인간 의사는 일반적으로 자신이 전공한 분야에 대해서만 능숙하기 때문에 복잡한 증상은 종종 다과회의진을 필요로 하거나, 난치병 전문의조차 책을 찾아보는 일이 많습니다.
훈련되지 않은 일반 모델이 의사 역할을 한다고 해도 이런 문제에 제대로 답하기는 어렵습니다.
03 다음 단계: C단 제품 개발 시작, 보다 엄격한 의료 실현으로 나아가다
백천지능에게 인간 의사 수준을 넘어선다는 것은 매우 중요한 전환점입니다. 이는 AI가 이제 실용성의 문턱을 넘어서 실제 사용 환경에 배치될 수 있는 가능성을 의미합니다.
1월 13일부터 사용자는 백소응(백천지능의 AI 서비스 플랫폼) 웹사이트 및 앱을 통해 M3 모델의 답변을 체험할 수 있게 되었습니다.
현재 사이트 디자인은 흥미롭습니다. M3 모델이 답변을 생성하지만, '의사용 버전'과 '환자용 버전'을 구분합니다. 의사용 버전은 답변이 더 간결하며 참고 문헌을 많이 인용하고, '사람 말투'보다는 전문적인 표현을 사용합니다. 반면 일반 환자용 버전에서는 모델이 한 번에 답변을 주기보다는 추가적인 질문을 통해 더 정확한 진단을 내리려 합니다.

백천지능은 백그라운드에서 모델이 사고하는 방식이 매우 흥미롭다고 설명합니다. "우리는 자주 모델의 사고 연쇄(chain-of-thought)에서 '이 환자는 제가 묻는 질문에 답하지 않았지만, 반드시 물어봐야 하는 질문이다'라고 언급하는 것을 발견합니다. 극단적인 경우에는 '이미 환자에게 20라운드 질문을 했고, 이는 설정된 최대 라운드 수를 초과했지만 그래도 이 질문은 반드시 해야 한다'고 말하기도 합니다. 이는 훈련 과정에서 말을 교묘하게 꾸며도 보상을 받지 못하고, 반드시 충분한 핵심 정보를 획득해 정확한 진단을 내릴 때만 보상을 받도록 설계했기 때문입니다. 이것이 우리가 타사와 모델 훈련 방식에서 가장 뚜렷하게 다른 점입니다."
최근 많은 AI 기업들이 의료 분야에 진출하고 있습니다. 그러나 백천지능은 자신들의 가장 큰 차별점은 '더 엄격한 의료(strict medical)'를 실현하는 데 있다고 강조합니다.
"이것은 백천지능이 사용 사례를 선택할 때 가장 쉬운 일을 먼저 하겠다는 식이 아니라, 기술 능력을 지속적으로 향상시키며 더 어려운 문제에 도전하겠다는 의미입니다." 왕샤오촨 대표가 말합니다.
전형적인 예로, 백천지능은 향후 우선적으로 종양 전문 분야의 솔루션을 개발할 계획이며, 심리 치유는 비교적 낮은 우선순위에 둡니다.
일반적인 견해로는 AI가 심리 치유를 제공하는 것이 더 쉬우며 쉽게 상용화될 수 있는 분야라고 생각하지만, 백천지능의 판단은 다릅니다. 그들은 종양 분야가 더 엄격한 과학적 근거를 가지고 있어 AI가 진정한 엄격한 의료 효과를 낼 수 있고, 인간 의사 수준에 도달하거나 초월할 가능성이 크다고 봅니다. 반면 심리학 분야는 그러한 과학적 기준점이 부족하다고 판단합니다.
또 일부 기업들이 의사의 디지털 분신을 만드는 방향을 선택하는 데 대해 왕샤오촨은 그런 방향은 백천지능이 추구하지 않는 길이라고 말합니다. 의사의 디지털 분신은 본래 의사의 수준을 완전히 재현할 수도 없고, 더군다나 그것을 뛰어넘을 수도 없습니다. 이런 형태의 AI는 결국 껍데기뿐인 도구나 고객 유치 수단에 그칠 뿐, 진정한 의미의 엄격한 의료를 추진할 수 없다는 것입니다.
엄격성에 대한 이러한 고집은 백천지능의 많은 비즈니스 결정에 깊은 영향을 미칩니다.
이는 왕샤오촨이 AI 의료의 다음 단계를 어떻게 바라보는지도 직결됩니다. 그는 현재 가장 중요한 과제는 AI 능력을 강화하는 동시에 점차 더 많은 의료 공급을 제공하는 것이라고 생각합니다.
중국은 오랫동안 분급진료와 전문의 제도를 시행하려 노력해왔습니다. 기본 취지는 국민들이 먼저 기초 의료기관에서 진료를 받도록 하여 대형 병원의 예약 난항, 장시간 대기, 혼잡 등을 해결하려는 것입니다.
그러나 이 제도가 시행되기 어려운 근본 원인은 의료 공급의 부족, 즉 기초 의료기관에 우수한 의사가 부족하기 때문입니다. 감기처럼 가벼운 질병조차도 사람들은 3급 병원에 줄 서서라도 가려는 이유는 기초 의료기관의 진료 수준에 신뢰를 두지 못하기 때문입니다.
이正是大模型可以发挥关键作用之处。大模型能够将顶尖的医学知识实现规模化分发,填补基层医疗的供给缺口,让每一个社区、每一个家庭都能拥有三甲医院专家级的诊疗能力。
장기적으로 보면 이는 더 광범위한 영향을 미칠 수 있습니다. 즉 의료 결정권이 의사에서 환자로 점차 이동할 가능성입니다. 전통적인 의료 환경에서 환자는 이해 당사자이지만 대부분 의사에게 결정권이 집중되어 있습니다. 이러한 권력 불균형은 의사소통 비용과 치료 과정에서의 고통을 초래하기도 합니다.
백천지능은 AI를 통해 환자가 더 쉽게 고품질 의료 자원을 이용할 수 있기를 바랍니다. "많은 사람들이 의료는 너무 복잡해서 환자는 절대 이해할 수 없다고 생각합니다. 하지만 저는 미국 사법제도의 배심원 제도를 떠올립니다. 법률 역시 매우 전문적인 분야지만, 배심원을 구성하는 일반인들은 법리를 알지 못합니다. 그래서 판사, 변호사, 검사가 충분한 토론을 통해 사건을 명확히 설명하고, 일반인이 유죄인지 무죄인지 판단할 수 있을 정도로 논리를 정리해주면 됩니다. 그렇게 하면 일반인도 논리적으로 정상적인 판단을 할 수 있는 것이죠." 왕샤오촨이 말합니다.
이것이 백천지능이 단순한 사용 사례에 머무르지 않고, 계속해서 고난도의 엄격한 진료 분야로 나아가려는 이유 중 하나입니다.
고난도 문제 해결이 상업적으로 가장 큰 수익을 가져오는가라는 질문에 왕샤오촨은 깊이 있는 답변을 내놓습니다.
그는 감기, 열 등의 간단한 문제를 해결하는 것으로는 사용자 마음속에 충분한 신뢰를 쌓기 어렵다고 봅니다. 의료는 신뢰에 매우 의존하는 산업이기 때문입니다. 오직 AI가 중증 질환 같은 고난도 문제를 해결할 수 있을 때 비로소 신뢰의 기반을 마련할 수 있다는 것입니다.
상업 논리 측면에서도 환자는 심각한 건강 문제를 겪을 때 더 고품질의 AI 의료 서비스에 지불意愿(지불 의지)가 강합니다. 이러한 신뢰는 단순한 수익의 전제일 뿐 아니라, AI 의료가 규모화되어 확산되는 핵심 요소이기도 합니다.
더 근본적인 의미에서, 의료는 백천지능과 왕샤오촨 개인에게 여전히 AGI(범용 인공지능)에 접근하는 하나의 경로를 의미합니다.
왕샤오촨은 현재 AI는 문학, 이공학, 예술 분야 등에서 이미 실질적인 해법을 찾았지만, 의료는 매우 독특한 영역이라고 말합니다. 인간의 의학 탐구가 아직 완성되지 않았고, AI 역시 이 분야에서는 여전히 탐색 단계에 있다고 봅니다.
백천지능의 로드맵은 매우 명확합니다. 우선 AI를 통해 진료 효율을 높여 현재 의료 공급 부족 문제를 해결합니다. 이를 기반으로 환자와의 깊은 신뢰를 구축합니다. 환자가 AI 도구를 사용해 장기간 의료 상담을 하게 되면, AI는 장기적인 동행을 통해 실제적이며 고품질의 의료 데이터를 축적할 수 있습니다.
이 데이터의 궁극적 목표는 생명의 수학적 모델을 구축하는 것입니다. 이는 인간 의사들이 아직 완전히 닦지 못한 길이며, 미래에 AI가 처음으로 실현할 가능성이 큽니다. 만약 생명의 본질을 모델링하는 데 성공한다면, 이는 AGI가 더 높은 단계로 나아가는 데 핵심적인 한 걸음이 될 것입니다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News










