

크립토는 수익 창출과 스토리텔링 외에 AI를 위해 무엇을 더 할 수 있을까?
저자: Pavel Paramonov
번역: TechFlow
Cuve Finance 창립자 @newmichwill는 최근 트위터에서 암호화폐의 주된 목적은 DeFi(탈중앙 금융)이며, AI(인공지능)는 본질적으로 암호화폐가 필요하지 않다고 언급했다. 나는 DeFi가 암호화 생태계의 중요한 부분이라는 데에는 동의하지만, AI에 암호화폐가 불필요하다는 주장에는 동의할 수 없다.
AI 에이전트(AI agents)의 부상과 함께 많은 에이전트가 토큰을 동반하고 있어, 사람들은 암호화폐와 AI의 교차점이 단순히 이러한 AI 에이전트에 국한된다고 오해하기 쉽다. 그러나 또 다른 중요한 주제인 "탈중앙 AI"는 AI 모델 자체의 학습 과정과 깊게 관련되어 있으며, 이는 상대적으로 간과되고 있다.
내가 특정 내러티브에 대해 불만족스러운 점은, 대부분의 사용자들이 어떤 것이 유행하면 그것이 중요하고 유용하다고 맹목적으로 생각하며, 더 나아가 그러한 내러티브의 유일한 목적이 가능한 한 가치를 추출하는 것(즉, 돈을 버는 것)이라고 여기는 경향이다.
탈중앙 AI를 논의할 때 우리가 먼저 스스로에게 질문해야 할 것은 바로 "왜 AI에 탈중앙화가 필요한가?" 그리고 그로 인해 어떤 결과가 발생하는가?"이다.
사실, 탈중앙화 개념은 거의 언제나 "인센티브 정렬(incentive alignment)"이라는 아이디어와 불가분하게 연결된다.
AI 분야에는 암호 기술로 해결할 수 있는 근본적인 문제들이 많이 있으며, 일부 메커니즘은 기존 문제를 해결할 뿐 아니라 AI 시스템에 더 큰 신뢰성을 제공할 수도 있다.
그렇다면 왜 AI는 암호화폐를 필요로 하는가?
1. 높은 컴퓨팅 비용이 참여와 혁신을 제한한다
운이 좋든 나쁘든, 대규모 AI 모델은 방대한 컴퓨팅 자원을 필요로 하며, 이는 자연스럽게 잠재적 사용자의 참여를 제한한다. 일반적으로 AI 모델은 거대한 양의 데이터와 실질적인 계산 능력이 필요하므로 개인이 감당하기는 거의 불가능하다.
이 문제는 오픈소스 개발에서 특히 두드러진다. 기여자는 시간뿐 아니라 컴퓨팅 리소스도 투입해야 하므로, 오픈소스 개발의 효율성이 낮아진다.
물론 개인이 블록체인 노드를 운영하듯 자신의 AI 모델을 실행하기 위해 많은 자원을 투입할 수는 있다.
그러나 이는 근본적인 해결책이 되지 못한다. 왜냐하면 컴퓨팅 파워가 해당 작업을 수행하기에 여전히 부족하기 때문이다.
LLaMA 같은 대규모 AI 모델 개발에 독립형 개발자나 연구자가 참여할 수 없는 이유는 단순히 모델 학습에 드는 컴퓨팅 비용을 감당할 수 없기 때문이다. 수만 개의 GPU와 데이터센터, 추가 인프라가 필요하기 때문이다.
몇 가지 규모를 가늠할 수 있는 데이터가 있다:
→ 일론 머스크(Elon Musk)는 최신 Grok 3 모델이 10만 개의 Nvidia H100 GPU를 사용하여 훈련되었다고 밝혔다.
→ 각 칩의 가격은 약 3만 달러이다.
→ Grok 3 훈련에 사용된 AI 칩의 총비용은 약 30억 달러에 달한다.
이 문제는 스타트업 설립 과정과 어느 정도 유사하다. 개인은 시간, 기술 역량, 실행 계획을 보유하고 있을지라도, 초창기에 비전을 실현할 충분한 자원이 부족할 수 있다.
@dbarabander가 지적했듯이, 전통적인 오픈소스 소프트웨어 프로젝트는 기여자가 시간만 기부하면 되지만, 오픈소스 AI 프로젝트는 시간과 함께 컴퓨팅 파워 및 데이터와 같은 방대한 자원이 필요하다.
선의와 자원봉사자들의 노력만으로는 이러한 고비용 자원을 제공할 충분한 개인이나 집단을 유인하기에 부족하다. 추가적인 인센티브 메커니즘이 참여를 촉진하는 데 필수적이다.
2. 암호 기술은 인센티브 정렬을 위한 최적의 도구다
인센티브 정렬(incentive alignment)이란 시스템에 기여하면서 동시에 자신의 이익도 얻도록 유도하는 규칙을 설정하는 것을 의미한다.
암호 기술은 다양한 시스템에서 인센티브 정렬을 성공적으로 구현한 사례가 무수히 많으며, 그 중에서도 가장 두드러진 예시는 탈중앙 물리 인프라 네트워크(DePIN) 산업인데, 이는 위 개념과 완벽하게 부합한다.
예를 들어, @helium과 @rendernetwork는 분산된 노드 및 GPU 네트워크를 통해 인센티브 정렬을 실현한 모범 사례다.
그렇다면 왜 이러한 패턴을 AI 분야에 적용하여 생태계를 더욱 개방적이고 접근 가능하게 만들 수 없는가?
사실 우리는 그렇게 할 수 있다.
Web3와 암호화 기술 발전의 핵심은 "소유권(ownership)"이다.
당신은 자신의 데이터를 소유하고, 자신의 인센티브를 소유하며, 특정 토큰을 보유함으로써 네트워크의 일부를 소유할 수도 있다. 리소스 제공자에게 소유권을 부여하면, 그들은 자신의 자산을 프로젝트에 제공하고 네트워크의 성공으로부터 보상을 받기를 기대하게 된다.
AI를 더욱 보편화하기 위해서는 암호 기술이 최선의 해법이다. 개발자들은 프로젝트 간 자유롭게 모델 설계를 공유할 수 있으며, 컴퓨팅 및 데이터 제공자는 리소스 제공에 대한 보상으로 소유권 지분을 얻을 수 있다.
3. 인센티브 정렬은 검증 가능성과 밀접하게 연결된다
적절한 인센티브 정렬이 이루어진 탈중앙 AI 시스템을 상상한다면, 그것은 전통적인 블록체인 메커니즘의 몇 가지 특성을 계승해야 한다:
-
네트워크 효과(Network Effects).
-
낮은 초기 진입 장벽. 노드는 미래 수익을 통해 보상받을 수 있다.
-
벌칙 메커니즘(Slashing Mechanisms). 악의적인 행위자에게 처벌을 가한다.
특히 벌칙 메커니즘의 경우, 검증 가능성(Verifiability)이 반드시 필요하다. 누가 악의적인 행위자인지 확인할 수 없다면 처벌도 불가능하며, 이는 특히 다수 팀이 협력하는 환경에서 시스템이 사기꾼에게 쉽게 악용될 위험을 초래한다.
탈중앙 AI 시스템에서는 중심적인 신뢰 지점이 없으므로, 검증 가능성은 매우 중요하다. 대신 우리는 신뢰 없이도 검증 가능한 시스템을 추구한다. 다음은 검증성이 요구될 수 있는 주요 구성 요소들이다:
-
벤치마킹 단계(Benchmark Phase): 특정 지표(x, y, z 등)에서 다른 시스템보다 우수함을 입증.
-
추론 단계(Inference Phase): 시스템이 올바르게 작동했는지, 즉 AI의 '사고' 과정이 정확했는지.
-
학습 단계(Training Phase): 시스템이 올바르게 훈련되었거나 미세 조정되었는지.
-
데이터 단계(Data Phase): 시스템이 데이터를 올바르게 수집했는지.
현재 수백 개의 팀이 @eigenlayer 위에서 프로젝트를 구축하고 있지만, 최근 AI에 대한 관심이 이전보다 훨씬 커졌음을 느꼈다. 이것이 EigenLayer의 원래 재스테이킹(Restaking) 비전과 얼마나 부합하는지도 궁금해졌다.
인센티브 정렬을 추구하는 모든 AI 시스템은 반드시 검증 가능해야 한다.
이러한 맥락에서, 벌칙 메커니즘은 곧 검증 가능성과 동일시될 수 있다. 탈중앙 시스템이 악의적인 행위자를 처벌할 수 있다는 것은, 그러한 악의적 행동을 식별하고 검증할 수 있음을 의미한다.
시스템이 검증 가능하다면, AI는 암호 기술을 활용해 전 세계의 컴퓨팅 및 데이터 자원에 접근하여 더 크고 강력한 모델을 구축할 수 있다. 왜냐하면 더 많은 자원(컴퓨팅 + 데이터)은 일반적으로 더 나은 모델을 만드는 데 기여하기 때문이다(현재 기술 체계 하에서는 적어도 그렇다).
@hyperbolic_labs는 협업형 컴퓨팅 자원의 가능성을 이미 보여주었다. 누구나 집에서 실행할 수 있는 것보다 훨씬 복잡한 AI 모델을 저렴한 비용으로 GPU를 임대해 훈련시킬 수 있다.
AI 검증을 효율적이고 검증 가능하게 만드는 방법은?
누군가는 현재 AWS나 Google Cloud와 같은 클라우드 솔루션을 통해 GPU를 임대할 수 있으므로, 컴퓨팅 자원 문제는 이미 해결되었다고 말할 수 있다.
그러나 AWS나 Google Cloud와 같은 클라우드 솔루션은 고도로 중앙집중화되어 있으며, 소위 '대기자 명단 전략(Waitlist Strategy)'을 사용해 인위적으로 수요를 높게 보이게 하고 가격을 인상한다. 이 현상은 해당 분야의 과점 구조에서 흔히 나타난다.
사실, 데이터센터, 광산, 심지어 개인 소유의 GPU 자원들이 대량으로 유휴 상태로 남아 있으며, 이러한 자원은 AI 모델 훈련에 기여할 수 있음에도 불구하고 낭비되고 있다.
@getgrass_io를 들어봤을지도 모르는데, 이 서비스는 사용자가 미사용 대역폭을 기업에 판매함으로써 자원 낭비를 방지하고 보상을 받을 수 있도록 한다.
나는 컴퓨팅 자원이 무한하다고 주장하는 것이 아니다. 하지만 어떤 시스템이라도 최적화를 통해 윈윈을 달성할 수 있다. 즉, AI 모델 훈련에 더 많은 자원이 필요한 사람들에게는 더 개방된 시장을 제공하고, 리소스를 기여하는 사람들에게는 공정한 보상을 제공하는 것이다.
Hyperbolic 팀은 개방형 GPU 시장을 개발했다. 여기서 사용자는 AI 모델 훈련을 위해 GPU를 임대해 최대 75%의 비용을 절감할 수 있으며, GPU 제공자는 유휴 자원을 수익화할 수 있다.
다음은 그 작동 방식의 개요이다:
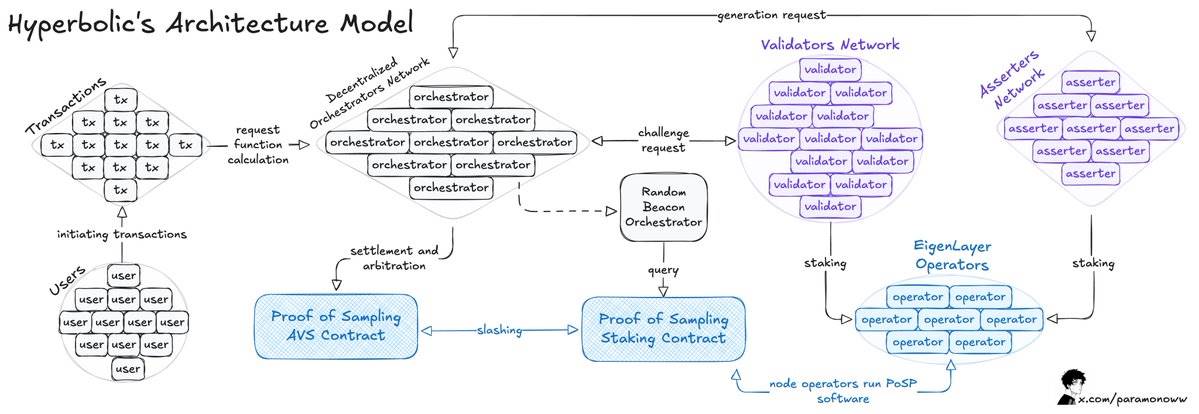
Hyperbolic은 연결된 GPU들을 클러스터와 노드로 조직하여, 필요에 따라 컴퓨팅 능력을 확장할 수 있게 한다.
이 아키텍처의 핵심은 '샘플링 증명(Proof of Sampling)' 모델인데, 거래를 샘플링 처리함으로써 워크로드와 컴퓨팅 요구를 줄이는 특징을 가진다.
주요 문제는 AI 추론(Inference) 과정에서 발생한다. 네트워크에서 실행되는 모든 추론은 검증되어야 하며, 다른 메커니즘으로 인한 상당한 컴퓨팅 오버헤드를 피하는 것이 이상적이다.
앞서 언급했듯이, 어떤 일이 검증 가능하다면, 그 검증 결과가 규칙 위반이라고 판단되면 반드시 처벌(Slashing)되어야 한다.
Hyperbolic이 AVS(Adaptive Verification System, 적응형 검증 시스템) 모델을 채택함으로써 시스템에 더 높은 검증 가능성을 추가했다. 이 모델에서 검증자는 무작위로 선택되어 출력 결과를 검증하며, 이를 통해 시스템은 인센티브 정렬을 달성한다. 이 메커니즘 하에서는 부정직한 행동이 수익성이 없게 된다.
AI 모델을 훈련하고 개선하기 위해 필요한 주요 두 가지 자원은 컴퓨팅 능력과 데이터이다. 컴퓨팅 능력을 임대하는 것은 하나의 해결책이지만, 여전히 어디선가 데이터를 확보해야 하며, 모델의 편향을 피하기 위해 다양한 데이터가 필요하다.
다양한 출처의 데이터를 AI 검증하기
데이터가 많을수록 모델은 더 좋아진다. 그러나 문제는 일반적으로 다양한 데이터가 필요하다는 점이다. 이는 AI 모델이 직면하는 주요 과제 중 하나다.
데이터 프로토콜은 수십 년 전부터 존재해왔다. 데이터가 공개이든 비공개이든, 데이터 브로커들은 어떤 식으로든 데이터를 수집하며, 유료일 수도 있고 무료일 수도 있고, 이를 이윤을 위해 판매한다.
AI 모델에 적합한 데이터를 확보하는 데 직면하는 문제는 단일 실패 지점, 검열, 그리고 AI 모델에 '먹이'를 주기 위한 신뢰할 수 있고 사실적인 데이터를 제공하는 신뢰 없이도 가능한 방법의 부재이다.
그렇다면 누구에게 이러한 데이터가 필요한가?
첫째, AI 연구자와 개발자들로서, 실제적이고 적절한 입력을 통해 모델을 훈련하고 추론하려는 사람들이 있다.
예를 들어, OpenLayer는 누구나 허가 없이 시스템이나 AI 모델에 데이터 스트림을 추가할 수 있게 하며, 시스템은 각각의 이용 가능한 데이터를 검증 가능한 방식으로 기록한다.
OpenLayer는 또한 zkTLS(제로지식 전송층 보안 프로토콜)를 사용하는데, 이는 내가 이전 글에서 자세히 설명한 바 있다. 이 프로토콜은 운영자가 보고하는 데이터가 실제로 출처로부터 얻은 것임을 보장한다(검증 가능성).
다음은 OpenLayer의 작동 원리이다:
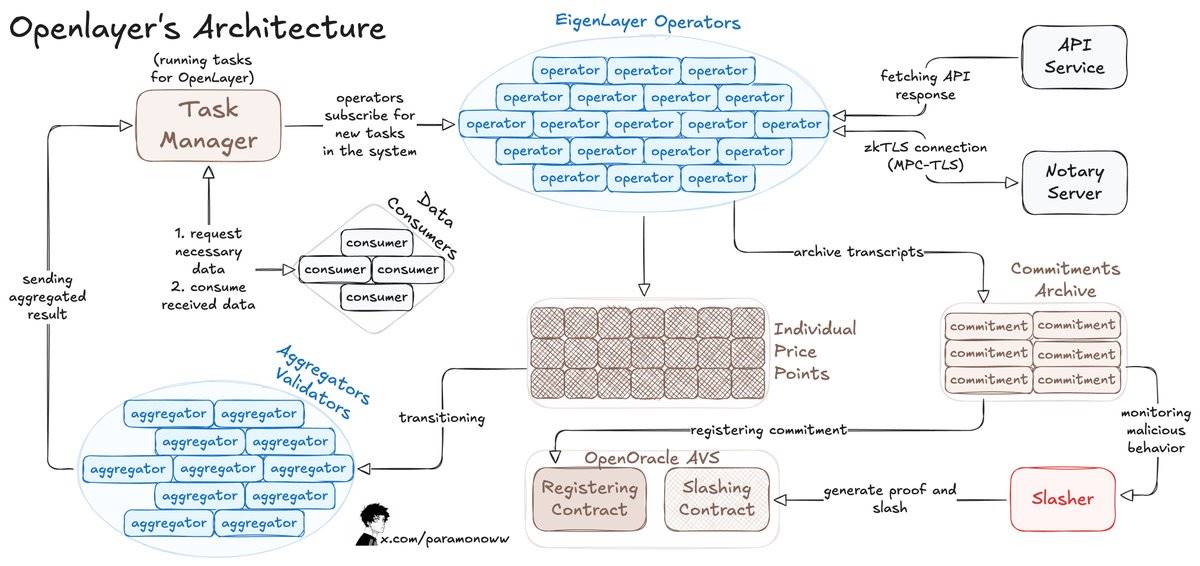
-
데이터 소비자는 OpenLayer의 스마트 계약에 데이터 요청을 게시하고, 주요 데이터 오라클과 유사한 API를 통해 계약(체인 내 또는 체인 외)에서 결과를 검색한다.
-
운영자는 EigenLayer에 등록하여 OpenLayer AVS의 스테이킹 자산을 보호하고 AVS 소프트웨어를 실행한다.
-
운영자는 작업을 구독하고 데이터를 OpenLayer에 제출하며, 원본 응답과 증명을 탈중앙 저장소에 저장한다.
-
가변 결과의 경우, 집계기(aggregator, 특수한 운영자)가 출력을 표준화 처리한다.
개발자는 어떤 웹사이트든 최신 데이터를 요청해 네트워크에 통합할 수 있다. AI 관련 프로젝트를 개발 중이라면 신뢰할 수 있는 실시간 데이터를 얻을 수 있다.
AI 컴퓨팅 과정과 검증 가능한 데이터 획득 방법을 살펴본 후, 이제 AI 모델의 핵심 두 요소에 주목해야 한다: 컴퓨팅 자체와 그 검증이다.
AI 컴퓨팅은 정확성을 보장하기 위해 검증되어야 한다
이상적인 상황에서, 노드는 시스템이 정상적으로 작동하도록 자신의 컴퓨팅 기여를 증명해야 한다.
최악의 경우, 노드는 컴퓨팅 능력을 제공했다고 허위로 주장하지만 실제로는 아무 작업도 하지 않을 수 있다.
노드가 자신의 기여를 증명하도록 요구하면 합법적인 참여자만 인정받도록 보장할 수 있으며, 악의적 행위를 방지할 수 있다. 이 메커니즘은 전통적인 작업 증명(PoW, Proof of Work)과 매우 유사하며, 차이점은 수행되는 작업의 유형뿐이다.
시스템에 적절한 인센티브 정렬 메커니즘을 도입하더라도, 노드가 특정 작업을 완료했음을 허가 없이 증명할 수 없다면 실제 기여와 맞지 않는 보상을 받을 수 있으며, 보상 배분의 불공정이 발생할 수 있다.
네트워크가 컴퓨팅 기여를 평가할 수 없다면, 일부 노드에 자신의 능력을 초과하는 작업이 할당되거나 다른 노드는 유휴 상태에 머무르게 되어 결국 효율 저하나 시스템 장애를 초래할 수 있다.
컴퓨팅 기여를 증명함으로써, 네트워크는 FLOPS(초당 부동소수점 연산 횟수)와 같은 표준 지표를 사용해 각 노드의 노력을 정량화할 수 있다. 이렇게 하면 노드가 네트워크에 존재하는지 여부가 아니라 실제로 수행한 작업에 따라 보상을 분배할 수 있다.
@HyperspaceAI 팀은 "FLOPS 증명(Proof-of-FLOPS)" 시스템을 개발했는데, 이는 사용자가 미사용 컴퓨팅 능력을 임대할 수 있게 한다. 그 대가로 'flops' 포인트를 받으며, 이는 네트워크의 통용 화폐 역할을 한다.
이 아키텍처의 작동 방식은 다음과 같다:
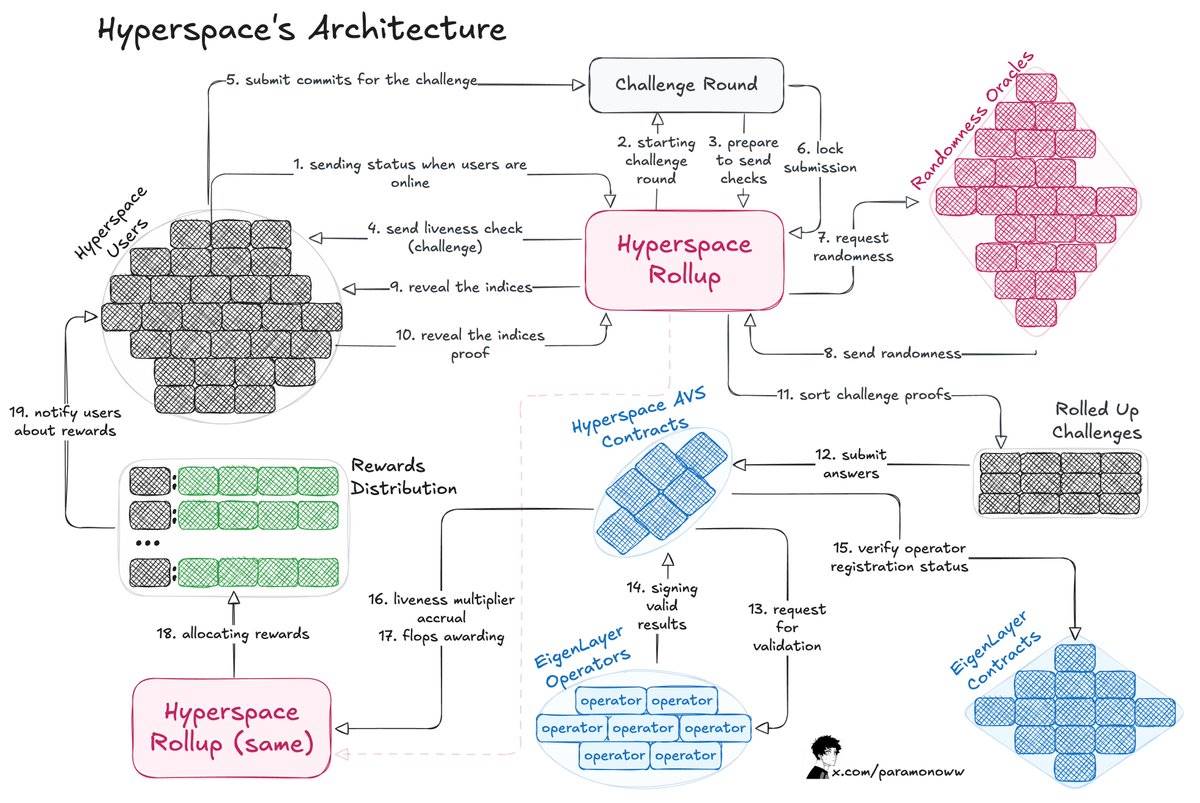
-
프로세스는 사용자에게 챌린지를 보내는 것으로 시작되며, 사용자는 챌린지에 대한 커밋을 제출하여 응답한다.
-
Hyperspace Rollup이 프로세스를 관리하여 제출의 보안을 보장하고 오라클로부터 난수를 가져온다.
-
사용자가 인덱스를 공개하면 챌린지 프로세스가 완료된다.
-
운영자가 응답을 확인하고 유효한 결과를 Hyperspace AVS 계약에 알리며, 이후 EigenLayer 계약을 통해 결과를 확인한다.
-
활동성 승수(Liveness Multipliers)를 계산하고 사용자에게 flops 포인트를 부여한다.
컴퓨팅 기여를 증명함으로써 각 노드의 능력을 명확히 파악할 수 있으므로, 시스템은 작업을 지능적으로 분배할 수 있다. 즉, 복잡한 AI 컴퓨팅 작업은 고성능 노드에, 덜 복잡한 작업은 능력이 낮은 노드에 할당할 수 있다.
가장 흥미로운 부분은 어떻게 이 시스템을 검증 가능하게 만들어 누구나 작업 완료의 정확성을 입증할 수 있게 하는가이다. Hyperspace의 AVS 시스템은 위 아키텍처 다이어그램에서 설명한 바와 같이, 지속적으로 챌린지와 난수 요청을 보내고 다층 검증 프로세스를 실행한다.
결과가 검증되고 보상이 공정하게 분배되므로 운영자는 안심하고 시스템에 참여할 수 있다. 결과가 잘못된 경우, 악의적 행위자는 의심의 여지 없이 처벌(Slashing)을 받는다.
AI 컴퓨팅 결과를 검증하는 데는 여러 가지 중요한 이유가 있다:
-
노드가 참여하고 리소스를 기여하도록 유도한다.
-
노력 정도에 따라 보상을 공정하게 분배한다.
-
기여가 특정 AI 모델을 직접 지원함을 보장한다.
-
노드의 검증 능력에 따라 작업을 효과적으로 분배한다.
AI의 탈중앙화와 검증 가능성
@yb_effect가 지적했듯이, "탈중앙화(Decentralized)"와 "분산(Distributed)"는 완전히 다른 개념이다. 분산은 단지 하드웨어가 서로 다른 위치에 분포되어 있다는 의미일 뿐, 여전히 중심화된 연결 지점이 존재할 수 있다.
반면 탈중앙화란 단일 주 노드가 없으며, 학습 과정이 장애를 처리할 수 있다는 의미로, 오늘날 대부분의 블록체인이 작동하는 방식과 유사하다.
AI 네트워크가 진정한 탈중앙화를 이루기 위해서는 다양한 솔루션이 필요하겠지만, 확실한 것은 거의 모든 것을 검증해야 한다는 점이다.
AI 모델이나 에이전트를 구축하려는 경우, 각 구성 요소와 모든 종속 항목이 검증되었는지 확인해야 한다.
추론, 학습, 데이터, 오라클—이 모든 것은 검증 가능하며, 이는 AI 시스템에 인센티브와 호환되는 암호 보상을 도입할 뿐 아니라 시스템을 더욱 공정하고 효율적으로 만들 수 있다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News









