

DeepSeek이 OpenAI를 '도둑질'했다고? 오히려 도둑이 제 발 저리다고 하는 꼴
작자: 등영의, 지능융기

이미지 출처: 무계AI 생성
2025년 춘절 기간 동안 가장 인기를 끈 것은 단순히 '나찰 2'만이 아니라 DeepSeek라는 앱도 있었다. 이는 이미 여러 차례 전해진 유명한 이야기다. 1월 20일 항저우에 위치한 AI 스타트업 DeepSeek(심도구색)이 OpenAI의 최강 추론 모델 o1과 견줄 수 있는 새로운 모델 R1을 발표했고, 진정한 의미에서 전 세계를 강타했다.
출시 일주일 만에 DeepSeek 앱은 다운로드 수 2000만 건을 돌파하며 140개 이상 국가에서 1위를 기록했다. 성장 속도는 2022년 출시된 ChatGPT를 능가했으며 현재 그 약 20% 수준에 달한다.
얼마나 인기가 있었냐면, 2월 8일 기준 DeepSeek 사용자 수는 이미 1억 명을 넘겼고 대상은 AI 마니아에 국한되지 않고 중국을 넘어 전 세계로 확산되었다. 노인과 어린이부터 코미디언, 정치인까지 모두가 DeepSeek를 이야기하고 있다.
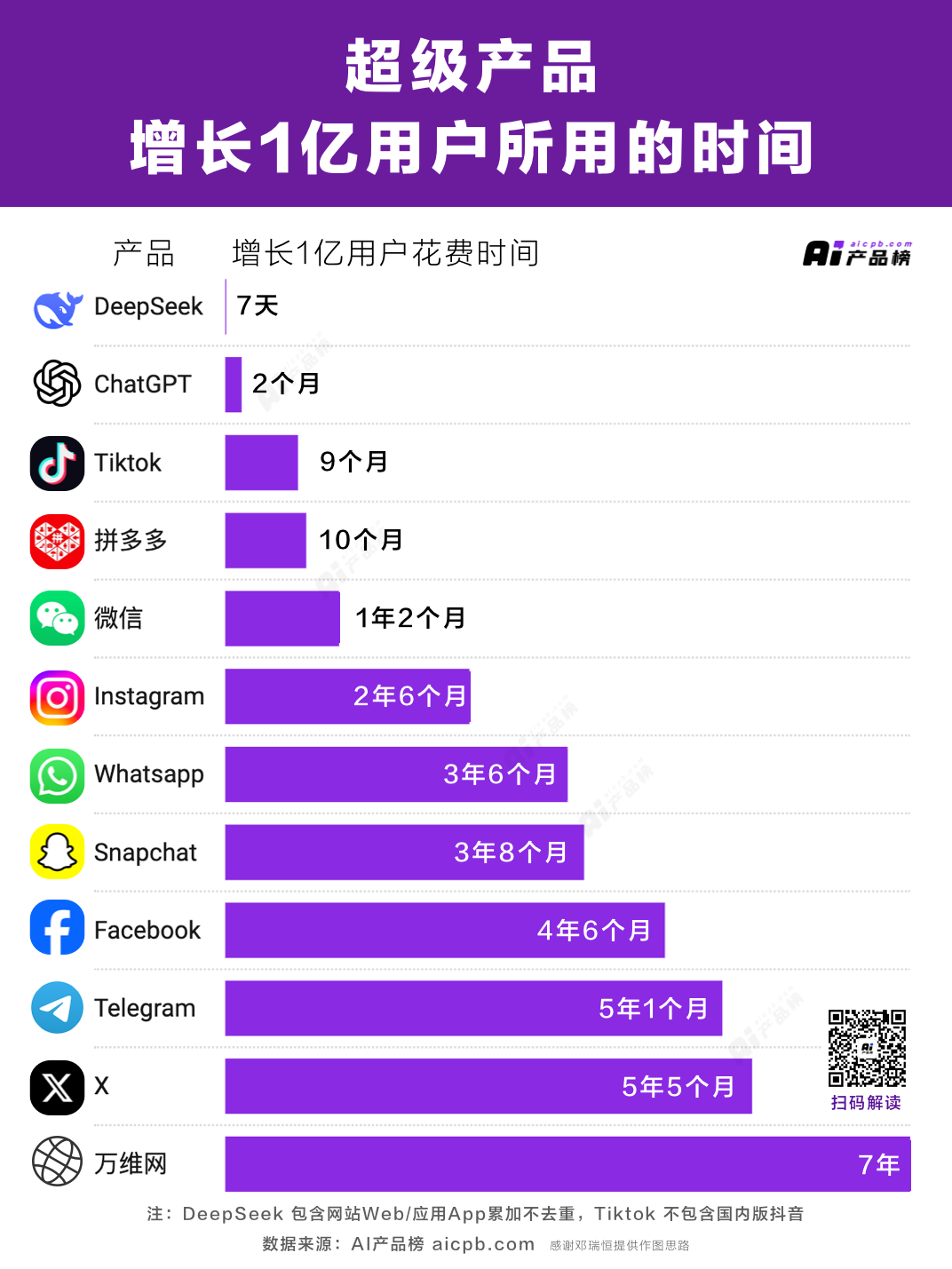
지금까지도 DeepSeek가 가져온 충격은 계속되고 있다. 지난 2주간 DeepSeek는 마치 TikTok의 성장 드라마를 보는 듯했다—폭발적 인기와 급속한 성장을 통해 미국의 다수 경쟁사들을 제압했고, 심지어 DeepSeek를 지정학적 위기에 직면하게 만들었다. 미국과 유럽에서는 '국가 안보에 영향을 미친다'며 논의하기 시작했고, 많은 지역에서 다운로드 및 설치 금지를 신속히 명령했다.
A16Z 파트너 마크 앤드리슨은 감탄하며 말했다. "DeepSeek의 등장은 또 하나의 '스푸트니크 순간(Sputnik Moment)'이다."
(냉전 시대의 용어로, 소련이 1957년 세계 최초의 인공위성 '스푸트니크 1호'를 성공적으로 발사하자 미국 사회가 공포를 느끼고 자신의 지위가 도전받고 있음을 인식하며 기술 우위가 무너질 수 있음을 깨달았던 사건)
하지만 인기 많으면 흑심도 많다는 말처럼, 기술 커뮤니티 내에서도 DeepSeek는 여전히 '증류', '데이터 절도' 등의 논란 속에 갇혀 있다.
현재까지 DeepSeek는 어떠한 공식 입장도 밝히지 않았으며, 이 논쟁은 두 극단으로 나뉘고 있다. 열광적인 지지자들은 DeepSeek-R1을 '국운급' 혁신으로까지 높이 평가하는 반면, 일부 기술 종사자들은 초저렴한 학습 비용과 증류 방식 등을 문제 삼으며 이러한 혁신이 과도하게 찬양되고 있다고 지적한다.
Deepseek이 OpenAI를 '절도'했는가? 오히려 도둑이 도적을 잡는 꼴
거의 DeepSeek의 인기가 치솟기 시작하면서 OpenAI, 마이크로소프트 등 실리콘밸리 주요 AI 기업들이 연이어 공개적으로 목소리를 냈다. 핵심 주장은 모두 DeepSeek의 데이터 문제에 집중됐다. 미국 정부의 AI 및 암호화 담당 책임자 데이비드 색스(David Sacks)는 공개적으로 DeepSeek가 '증류'라는 기술을 통해 ChatGPT의 지식을 '흡수'했다고 밝혔다.
OpenAI는 영국 <파이낸셜 타임스> 보도를 통해 DeepSeek가 ChatGPT를 '증류'한 징후를 발견했다고 전하며, 이는 OpenAI 모델 사용 조항을 위반한 것이라고 주장했다. 그러나 OpenAI는 구체적인 증거를 제시하지 않았다.
사실 이 주장은 설득력이 부족하다.
증류는 정상적인 대규모 모델 학습 기술 수단이다. 이는 일반적으로 모델 학습 단계에서 발생하는데, 더 크고 강력한 모델('선생님 모델')의 출력 결과를 이용해 작은 모델('학생 모델')이 더 나은 성능을 배우도록 하는 것이다. 특정 작업에서 작은 모델은 낮은 비용으로도 유사한 결과를 얻을 수 있다.
증류는 복제가 아니다. 쉽게 설명하면, 증류란 선생님이 모든 난제를 풀고 완벽한 해답 노트를 정리하는 것과 같다. 이 노트에는 답만 있는 것이 아니라 다양한 최적의 풀이 방법이 적혀 있다. 일반 학생(소형 모델)은 단지 이 노트를 학습하여 자기 답을 만들어내고, 선생님의 계단식 사고 흐름을 따르는지 노트와 비교해 확인하는 것이다.
DeepSeek의 가장 큰 기여는 바로 이 과정에서 비지도 학습(Unsupervised Learning)을 더 많이 활용했다는 점이다. 즉, 인간의 피드백(RLHF)을 줄이고 기계가 스스로 피드백을 받는 방식이다. 가장 직접적인 결과는 모델 학습 비용이 크게 줄어들었다는 것으로, 이것이 바로 많은 의문이 제기되는 이유이기도 하다.
DeepSeek-V3 논문은 V3 모델의 구체적인 학습 클러스터 규모(2048개 H800 칩)를 언급한 바 있다. 많은 사람들이 시장 가격을 기준으로 이를 약 550만 달러 정도로 추정했는데, 메타(Meta), 구글(Google) 등의 모델 학습 비용의 수십 분의 일에 불과하다.
그러나 주목할 점은 DeepSeek가 이미 논문에서 이 금액은 최종 학습의 단일 실행 비용에 불과하며 초기 장비, 인력, 학습 손실 비용은 포함하지 않았다고 밝혔다는 사실이다.
AI 분야에서 증류는 새로운 일이 아니며, 많은 모델 제조사들이 자사의 증류 작업을 공개한 바 있다. 예를 들어, 메타는 자사 모델이 어떻게 증류되었는지를 공개한 바 있는데, Llama 2는 더 크고 똑똑한 모델이 사고 과정과 방법을 포함한 데이터를 생성하고, 이를 자체의 더 작은 규모의 추론 모델에 적용해 미세 조정(Fine-tuning)하는 방식이다.
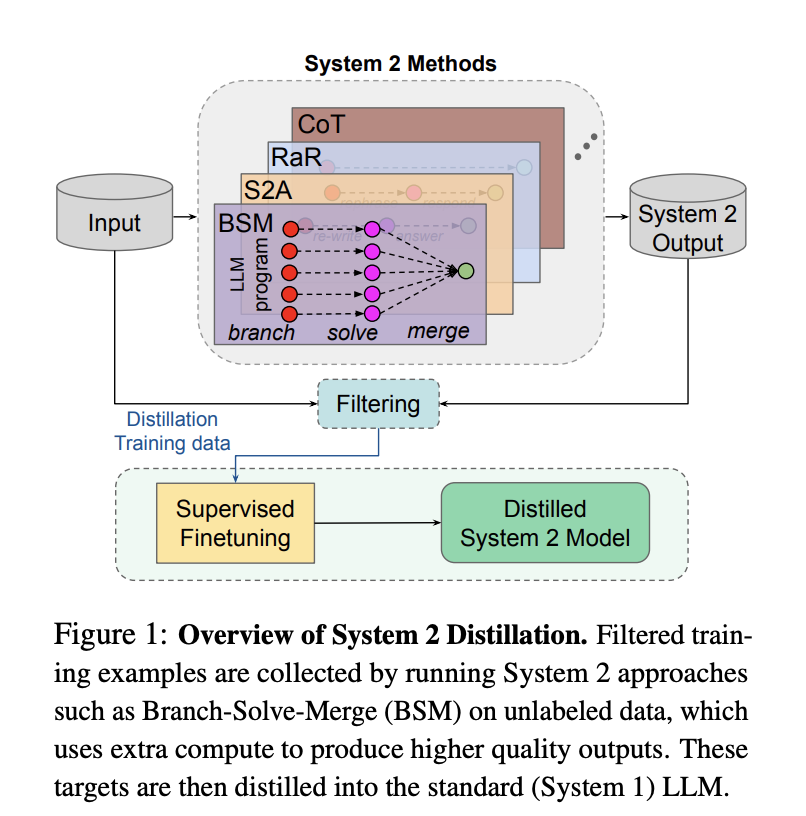
△ 출처: Meta FAIR
하지만 증류에도 단점이 있다.
한 대기업 AI 응용 분야 종사자는 <지능융기>에게 증류는 모델의 능력을 빠르게 향상시킬 수 있지만, 그 단점은 '선생님 모델'이 생성한 데이터가 너무 깨끗해서 다양성이 부족하다는 점이라고 말했다. 이러한 데이터를 학습하면 모델은 마치 형식화된 '즉석식품' 같아지고, 그 능력 또한 선생님 모델을 넘어서기 어렵다.
데이터 품질은 대부분 모델 학습 효과를 결정한다. 만약 대부분의 모델 학습을 증류로 수행한다면, 오히려 모델이 과도하게 동질화될 수 있다. 지금 전 세계의 대규모 모델은 이미 다양하게 존재하며, 각사는 자신만의 '핵심 버전' 모델을 제공하고 있으며, 완전히 동일한 모델을 증류하는 것은 큰 의미가 없다.
더 심각한 문제는 환각(hallucination) 문제가 더욱 악화될 수 있다는 점이다. 작은 모델은 어느 정도에서 큰 모델의 '겉모습'만을 모방할 뿐, 그 이면의 논리를 깊이 이해하지 못해 새 작업에서 성능 저하를 유발하기 쉽다.
따라서 모델이 고유한 특성을 가지려면 AI 엔지니어는 데이터 단계부터 개입해야 한다. 어떤 데이터를 선택하고, 데이터 구성 비율은 어떻게 하며, 학습 방법은 무엇인지에 따라 결국 만들어지는 모델은 매우 다르게 나타난다.
대표적인 예가 현재의 OpenAI와 Anthropic이다. OpenAI와 Anthropic은 실리콘밸리에서 가장 먼저 대규모 모델을 개발한 회사들로, 양측 모두 증류할 수 있는 기존 모델이 없었기 때문에 공개 인터넷과 데이터셋에서 직접 크롤링하고 학습했다.
서로 다른 학습 경로는 두 모델의 스타일이 현저히 다르게 나타나게 했다. 오늘날 ChatGPT는 생활과 업무 문제 해결에 능한 엄격한 이과생 같은 느낌이며, Claude는 문과에 더 능해 글쓰기 작업에서 입소문을 탄 왕으로 인정받고 있지만 코드 작업에서도 결코 뒤지지 않는다.
OpenAI의 또 다른 아이러니한 점은 경계가 모호한 조항으로 DeepSeek를 고발하면서 자신들도 유사한 일을 해왔다는 사실이다.
창립 초기 OpenAI는 오픈소스 중심 조직이었지만 GPT-4 이후 폐쇄소스로 전환했다. OpenAI의 학습은 거의 전 세계 공개 인터넷 데이터를 모두 크롤링했다. 따라서 폐쇄소스 전환 후 OpenAI는 언론 매체와 출판사들과의 저작권 분쟁에 끊임없이 휘말리고 있다.
OpenAI의 '증류' 고발은 '도둑이 도적을 잡는다'는 비판을 받는 이유가 바로 OpenAI o1과 DeepSeek R1 모두 논문에서 데이터 준비 세부사항을 공개하지 않았기 때문이다. 이 문제는 여전히 베일에 싸인 상태다.
더욱이 DeepSeek-R1은 출시 당시 MIT 오픈소스 라이선스를 선택했다. 이는 거의 가장 관대한 오픈소스 라이선스다. DeepSeek-R1은 상업적 이용을 허용하고 증류도 허용하며, 공개용으로 증류된 6개의 소형 모델도 제공해 사용자가 스마트폰이나 PC에 직접 배포할 수 있도록 했다. 이는 오픈소스 커뮤니티에 대한 진정성 있는 환원 행위다.
2월 5일, 전 Stability AI 연구 책임자인 타니슈크 매튜 아브라함(Tanishq Mathew Abraham)은 특별히 글을 써서 이 고발이 회색 지대에 서 있음을 지적했다. 우선 OpenAI는 DeepSeek가 직접 GPT를 이용해 증류했다는 증거를 제시하지 않았다. 그가 추측한 가능성 중 하나는 DeepSeek가 이미 시장에 널리 퍼져 있는 ChatGPT 생성 데이터셋을 활용했을 수 있다는 점인데, 이런 경우는 OpenAI가 명확히 금지하지 않았다.
증류 여부가 AGI 개발 여부를 판단하는 기준인가?
여론 공간에서 현재 많은 사람들은 '증류 여부'를 기준으로 모방인지, AGI 개발인지 판단하는데, 이는 다소 독단적이다.
DeepSeek의 활동은 '증류'라는 개념을 다시 한 번 유행시켰지만, 사실 이는 거의 10년 전부터 존재했던 기술이다.
2015년, AI 거물 힌튼(Hinton), 오리올 비냐스(Oriol Vinyals), 제프 딘(Jeff Dean) 등이 공동 발표한 논문 《Neural Network의 지식 증류(Distilling the Knowledge in a Neural Network)》에서 대규모 모델의 '지식 증류' 기술을 공식적으로 제안했으며, 이후 대규모 모델 분야의 표준이 되었다.
특정 분야와 작업에 집중하는 모델 제조업체들에게 증류는 더 현실적인 접근 방식이다.
한 AI 종사자는 지능융기(智能涌现)에 국내 대규모 모델 제조업체 중 증류를 하지 않는 곳은 거의 없으며, 이는 거의 공공연한 비밀이라고 말했다. "현재 공개 인터넷 데이터는 거의 고갈되었고, 처음부터 사전 학습과 데이터 주석 작업을 수행하는 비용은 대기업이라도 쉽게 감당하기 어려운 수준이다."
예외 중 하나는 바이트댄스(ByteDance)다. 최근 출시된 두바오 1.5 프로 버전에서 바이트댄스는 "학습 과정에서 다른 모델이 생성한 데이터를 전혀 사용하지 않았으며, 증류라는 편법을 절대 선택하지 않는다"고 명확히 밝히며 AGI 달성에 대한 결의를 표현했다.
대기업이 증류를 선택하지 않는 데는 현실적인 고려가 있다. 예를 들어, 이후의 규제 관련 분쟁을 회피할 수 있다. 폐쇄소스 전략 하에서는 모델 능력에 일정한 장벽을 구축할 수도 있다. 지능융기(智能涌现)가 파악한 바에 따르면, 바이트댄스의 현재 데이터 주석 비용은 실리콘밸리 수준을 따라잡았으며, 최대 200달러/건에 달한다. 이러한 고품질 데이터는 석사, 박사 이상의 해당 분야 전문가들이 주석을 달아야 한다.
AI 분야의 더 많은 참여자들에게 증류든 다른 공학적 수단이든 본질적으로 모두 스케일링 법칙(Scaling Law)의 경계를 탐색하는 것이다. 이는 AGI 탐색의 필요조건이지 충분조건은 아니다.
대규모 모델이 유행하기 시작한 초기 2년간 스케일링 법칙은 일반적으로 '힘으로 기적을 만든다'고 단순하게 이해됐다. 즉, 컴퓨팅 파워와 파라미터를 늘리기만 하면 지능이 자연스럽게 나타난다는 것으로, 주로 사전 학습 단계에서 이루어졌다.
지금 '증류'가 뜨겁게 논의되는 이면에는 사실 대규모 모델 발전 패러다임의 변화가 숨어 있다. 스케일링 법칙은 여전히 존재하지만, 사전 학습 단계에서 진정한 의미로 후기 학습과 추론 단계로 이동한 것이다.
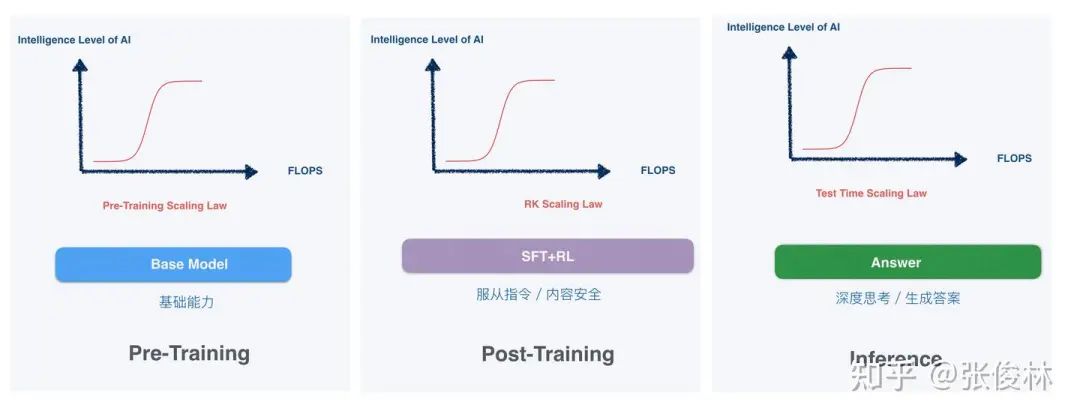
△ 출처: 중국과학원 소프트웨어연구소 장준림 박사 칼럼
OpenAI의 o1은 2024년 9월 출시되며 후기 학습과 추론으로의 스케일링 법칙 전환의 상징으로 여겨졌고, 현재까지도 세계 최고 수준의 추론 모델이다. 그러나 문제는 OpenAI가 학습 방법과 세부사항을 공개하지 않았으며, 응용 비용도 여전히 높은 수준에 머물러 있다는 점이다. o1 pro의 월비용은 200달러에 달하고, 추론 속도도 느려 AI 응용 개발의 주요 걸림돌로 여겨진다.
최근 AI 업계의 대부분 작업은 o1의 효과를 재현하면서 동시에 추론 비용을 낮추는 데 초점을 맞추고 있다. DeepSeek의 이정표적 의미는 단지 오픈소스 모델이 최정상 폐쇄소스 모델을 따라잡는 시간을 크게 단축시켰다는 것뿐 아니라(약 3개월 만에 o1의 여러 지표를 거의 따라잡음), o1의 능력 도약 핵심 요령을 찾아내고 이를 오픈소스로 공개했다는 데 있다.
무시할 수 없는 큰 전제는 DeepSeek가 거인의 어깨 위에서 이 혁신을 완성했다는 사실이다. 단지 '증류'와 같은 공학적 수단을 단순히 편법으로 보는 것은 지나치게 좁은 시각이며, 이는 오히려 오픈소스 문화의 승리다.
DeepSeek가 가져온 생태계 공동번영과 오픈소스 효과는 이미 빠르게 나타나고 있다. DeepSeek의 인기 이후 곧바로 'AI 교모' 리페이페이(Li Feifei)의 새로운 연구도 급속도로 확산됐다. 구글 산하 Gemini를 '선생님 모델'로, 미세 조정된 알리바바 Qwen2.5를 '학생 모델'로 하여 증류 등의 방식을 통해 50달러 미만의 비용으로 추론 모델 s1을 학습해 DeepSeek-R1과 OpenAI-o1의 모델 능력을 재현한 것이다.
엔비디아(NVIDIA)도 대표적인 사례다. DeepSeek-R1 출시 후 엔비디아 시가총액은 하루 만에 약 6000억 달러가 폭락하며 역사상 최대 단일일 날蒸发 기록을 세웠지만, 다음 날 곧바로 강세 반등하며 약 9% 상승했다. 시장은 R1이 가져오는 강력한 추론 수요에 여전히 기대감을 갖고 있기 때문이다.
예상할 수 있듯, 대규모 모델 분야의 각 참여자들이 R1의 능력을 흡수한 후에는 새로운 AI 응용 혁신 열풍이 이어질 것이다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News













