

모듈화가 간과된 영역: 실행, 결제 및 집계 레이어
글: Bridget Harris
번역: Luffy, Foresight News
관심도와 혁신성 측면에서 모듈화 스택의 각 구성 요소들이 모두 동등한 것은 아니다. 데이터 가용성(DA)과 정렬(sequencing) 계층에서 많은 프로젝트들이 혁신을 이루었지만, 실행 계층과 결제 계층은 최근에야 모듈화 스택의 일부로서 주목받기 시작했다.
공유 정렬기 분야는 경쟁이 치열하다. Espresso, Astria, Radius, Rome, Madara 등 다수의 프로젝트들이 시장 점유율을 놓고 경쟁 중이며, Caldera와 Conduit 같은 RaaS 제공자들도 롤업 구축 기반 위에서 공유 정렬기를 개발하고 있다. 이러한 RaaS 제공자들은 정렬 수익에만 전적으로 의존하지 않는 비즈니스 모델을 통해 롤업에 더 유리한 수수료를 제공할 수 있다. 반면 많은 롤업들이 정렬기에서 발생하는 수익을 확보하기 위해 자체 정렬기를 운영하기도 한다.
DA 분야와 비교했을 때 정렬기 시장은 독특하다. DA 분야는 기본적으로 Celestia, Avail, EigenDA가 형성한 과점 구조다. 이로 인해 세 거대 업체 외의 소규모 신규 진입자들이 해당 분야에서 성공적으로 시장을 뒤엎기는 어렵다. 대부분의 프로젝트들은 '기존' 선택지인 이더리움을 활용하거나, 자신의 기술 스택 유형과 일관성에 따라 성숙한 DA 계층 중 하나를 선택한다. DA 계층 사용은 상당한 비용 절감 효과를 가져오지만, 정렬기 부분을 외부에 아웃소싱하는 것은 (보안보다는 수수료 관점에서) 명백한 선택이 아니다. 특히 정렬기 수익을 포기하는 기회비용이 크기 때문이다. 또한 많은 사람들이 DA가 상품화될 것이라고 생각하지만, 암호화폐 분야에서는 초강력한 유동성 해자와 독특하면서 복제하기 어려운 핵심 기술이 결합되어 스택 내 특정 계층을 상품화하는 것을 극도로 어렵게 만든다는 점을 확인할 수 있다. 이러한 논란에도 불구하고 많은 DA 및 정렬기 제품들이 출시되고 있다. 간단히 말해, 일부 모듈화 스택에서는 "각 서비스마다 여러 경쟁자가 존재한다."
나는 실행 계층과 결제(및 집계) 계층이 아직 상대적으로 충분히 탐구되지 않았다고 생각하지만, 이제 새로운 방식으로 반복 개선되며 모듈화 스택의 나머지 부분과 보다 잘 맞춰지기 시작하고 있다고 본다.
실행 계층과 결제 계층의 관계
실행 계층과 결제 계층은 밀접하게 통합되어 있으며, 결제 계층은 상태 실행의 최종 결과를 정의하는 장소 역할을 할 수 있다. 결제 계층은 실행 계층의 결과에 강화 기능을 추가하여 실행 계층을 더욱 강력하고 안전하게 만들 수도 있다. 실무적으로 이것은 다양한 기능을 의미할 수 있는데, 예를 들어 결제 계층이 실행 계층의 사기 분쟁 해결, 증명 검증, 다른 실행 계층 연결 등의 환경을 제공할 수 있다.
주목할 점은 일부 팀들이 자체 프로토콜 내에서 맞춤형 실행 환경 개발을 직접 지원하고 있다는 것이다. Repyh Labs가 그 예다. 이들은 Delta라는 이름의 L1을 구축 중인데, 이는 본질적으로 모듈화 스택과 반대되는 설계지만, 통합된 환경 내에서 유연성을 제공하며 기술적 호환성 면에서 이점을 갖는다. 팀이 모듈화 스택의 각 부분을 수동으로 통합하는 데 시간을 들이지 않아도 되기 때문이다. 물론 단점도 존재한다. 유동성 측면에서 고립되고, 자신의 설계에 가장 적합한 모듈화 계층을 선택할 수 없으며, 비용이 너무 높다는 점이다.
다른 팀들은 특정 핵심 기능이나 애플리케이션에 특화된 L1을 구축하는 것을 선택한다. Hyperliquid는 대표적인 사례로, 자사의 주요 원생 앱인 영속계약 거래 플랫폼을 위해 전용 L1을 구축했다. 사용자들이 Arbitrum에서 크로스체인을 해야 하지만, 핵심 아키텍처는 Cosmos SDK나 기타 프레임워크에 의존하지 않기 때문에 주요 용도에 맞춰 반복적이고 맞춤화된 최적화가 가능하다.
실행 계층의 발전
지난 사이클에서 일반적인 알트-L1이 이더리움을 능가했던 유일한 기능은 더 높은 처리량이었다. 이는 프로젝트가 성능을 크게 향상시키려면 기본적으로 이더리움 자체가 아직 보유하지 않은 기술로 인해 L1을 처음부터 자체 구축해야 한다는 것을 의미했다. 역사적으로 이는 효율성 메커니즘을 일반 프로토콜에 직접 내장한다는 의미였다. 이번 사이클에서는 이러한 성능 개선이 모듈화 설계를 통해 이루어졌으며, 가장 주요한 스마트 계약 플랫폼인 이더리움 위에서 달성되었다. 이를 통해 기존 프로젝트들과 신규 프로젝트들 모두 유동성, 보안성, 커뮤니티 해자를 유지하면서 새로운 실행 계층 인프라를 활용할 수 있게 되었다.
현재 우리는 공유 네트워크의 일부로서 서로 다른 VM(실행 환경)들을 혼합·매칭하는 사례가 점점 더 많아지고 있는데, 이는 개발자들에게 유연성과 실행 계층에서의 보다 정교한 맞춤화를 제공한다. 예를 들어 Layer N은 개발자가 공유 상태 머신 위에서 범용 롤업 노드(SolanaVM, MoveVM 등을 실행 환경으로 사용) 및 애플리케이션 특화 롤업 노드(예: 영속 DEX, 오더북 DEX)를 실행할 수 있도록 한다. 또한 이들 서로 다른 VM 아키텍처 간의 완전한 구성 가능성과 공유 유동성을 실현하기 위해 노력하고 있는데, 이는 역사적으로 대규모로 구현하기 어려웠던 체인 상의 공학적 문제였다. Layer N의 각 애플리케이션은 지연 없이 비동기적으로 메시지를 전달할 수 있어 암호화폐에서 흔히 발생하는 '통신 오버헤드' 문제를 해결한다. 각 xVM은 RocksDB, LevelDB 또는 새로 구축한 사용자 정의 동기/비동기 데이터베이스 등 서로 다른 데이터베이스 아키텍처를 사용할 수 있다. 상호 운용성은 '스냅샷 시스템'(Chandy-Lamport 알고리즘과 유사한 알고리즘)을 통해 작동하며, 이 방법을 통해 체인이 시스템 정지를 하지 않고도 비동기적으로 새 블록으로 전환할 수 있다. 보안 측면에서는 상태 전환이 잘못되었을 경우 사기 증명(fraud proof)을 제출할 수 있다. 이러한 설계를 통해 실행 시간을 최소화하면서 전체 네트워크 처리량을 극대화하는 것이 목표다.
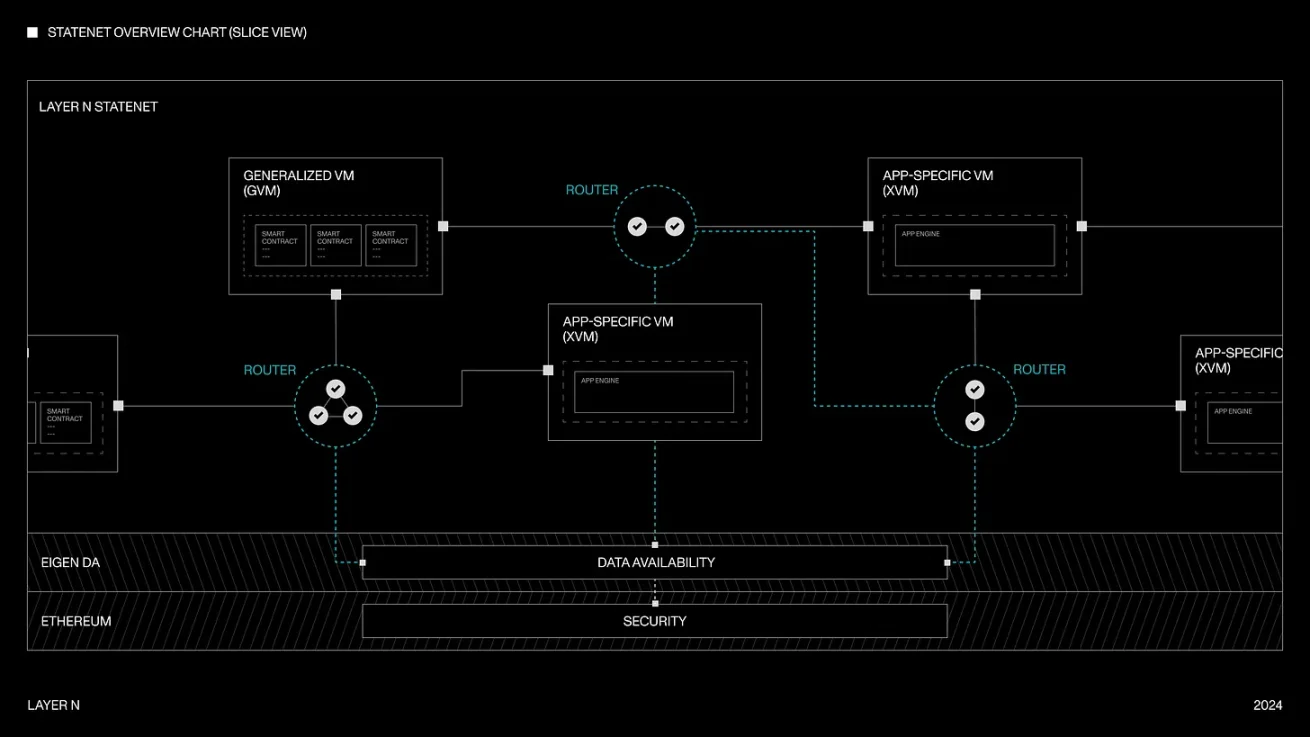
Layer N
맞춤화를 추진하기 위해 Movement Labs는 Facebook이 처음 개발하고 Aptos, Sui 등의 네트워크에서 사용한 Move 언어를 VM/실행에 활용한다. 다른 프레임워크들과 비교해 Move는 보안성과 개발자 유연성이라는 점에서 구조적 장점을 지닌다. 역사적으로 이 두 가지는 기존 기술로 체인 상 애플리케이션을 구축할 때의 주요 문제였다. 중요한 점은 개발자들이 Solidity만 작성해도 Movement에 배포할 수 있다는 것이다. 이를 위해 Movement는 Move 스택과 함께 사용 가능한 EVM 바이트코드와 완전히 호환되는 런타임을 생성했다. 이들의 롤업 M2는 BlockSTM 병렬화를 활용해 더 높은 처리량을 가능하게 하면서도 여전히 이더리움의 유동성 해자에 접근할 수 있다. (역사적으로 BlockSTM은 Aptos 등의 알트 L1에서만 사용되었고, Aptos는 명백히 EVM 호환성이 부족했다.)
MegaETH 역시 실행 계층 분야의 발전을 주도하고 있는데, 특히 병렬화 엔진과 메모리 데이터베이스를 통해 정렬기가 전체 상태를 메모리에 저장할 수 있도록 한다. 아키텍처 측면에서 그들은 다음을 활용한다:
-
네이티브 코드 컴파일을 통해 L2의 성능을 향상시킨다(스마트 계약의 연산 집약도가 높을 경우 큰 속도 향상을 얻을 수 있으며, 그렇지 않더라도 약 2배 이상의 속도 향상을 얻을 수 있음).
-
비교적 중심화된 블록 생산과 분산화된 블록 검증 및 승인.
-
효율적인 상태 동기화로, 전체 노드가 트랜잭션을 다시 실행할 필요 없이 상태 증분만 이해하면 로컬 데이터베이스에 적용할 수 있다.
-
메르클 트리 업데이트 구조(일반적으로 트리를 업데이트할 때 많은 저장 공간을 차지함). 이에 반해 MegaETH의 방법은 메모리와 디스크 모두에서 효율적인 새로운 trie 데이터 구조를 사용한다. 메모리 계산 덕분에 체인 상태를 메모리에 압축할 수 있으므로 트랜잭션 실행 시 디스크가 아닌 메모리에만 접근하면 된다.
모듈화 스택의 일부로서 최근 탐색되고 반복되는 또 다른 설계는 증명 집계(proof aggregation)다. 이는 여러 간결한 증명들을 하나의 간결한 증명으로 만드는 증명기를 의미한다. 우선 집계 계층과 그것이 암호화폐 분야에서 지닌 역사 및 현재 추세를 전체적으로 살펴보자.
집계 계층의 가치
역사적으로 비암호화폐 시장에서는 플랫폼보다 집계기(aggregator)의 시장 점유율이 작았다:
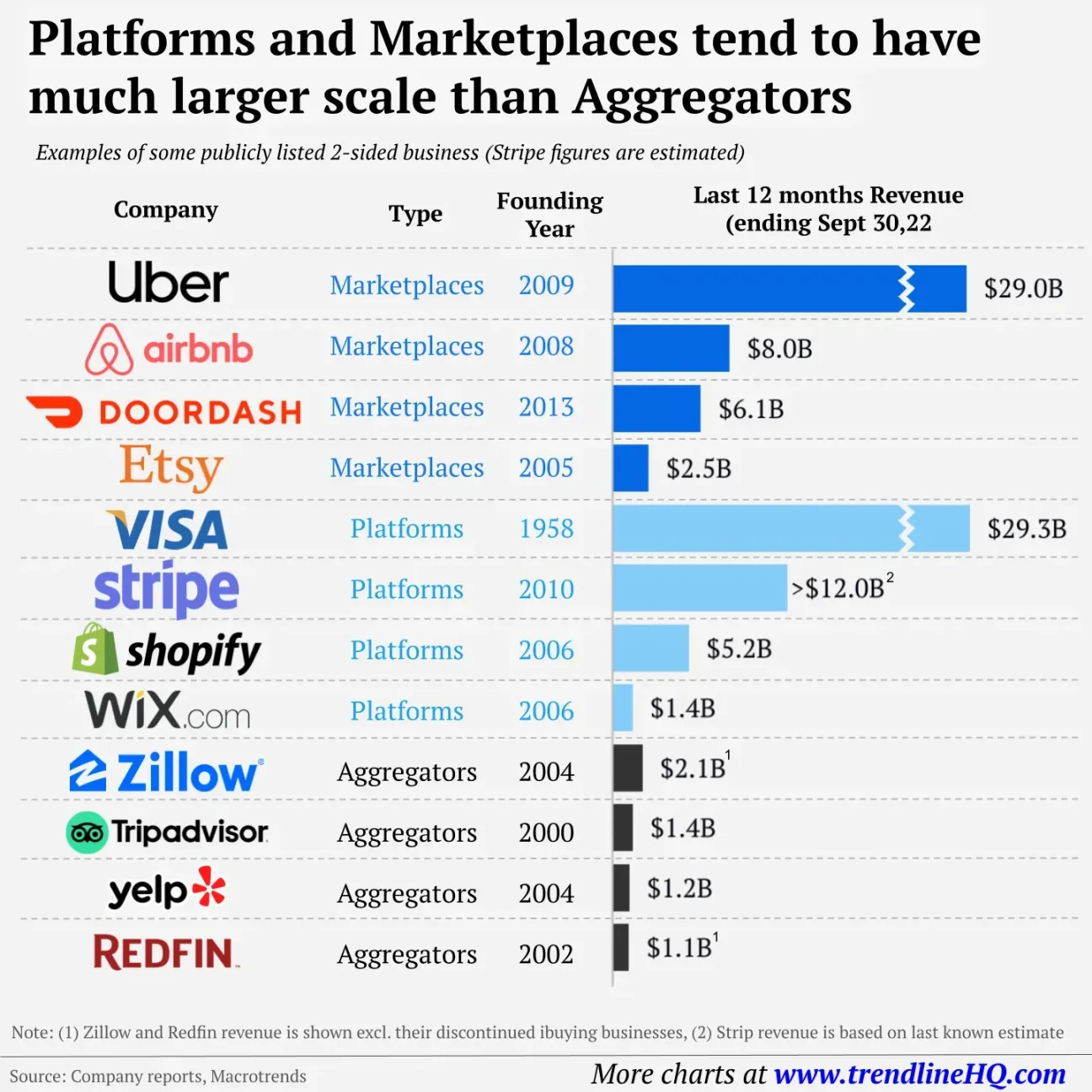
이 규칙이 모든 암호화폐 상황에 적용되는지는 확신할 수 없지만, 탈중앙화 거래소(DEX), 크로스체인 브릿지, 대출 프로토콜에는 여전히 유효하다.
예를 들어 1inch와 0x(주요 DEX 집계기 두 곳)의 시가총액은 약 10억 달러로, Uniswap의 약 76억 달러 시가총액에 비해 매우 작다. 크로스체인 브릿지도 마찬가지다. Across 같은 플랫폼과 비교할 때 Li.Fi, Socket/Bungee 등의 크로스체인 브릿지 집계기들의 시장 점유율은 더 작다. Socket은 15개의 서로 다른 크로스체인 브릿지를 지원하지만, 실제 누적 크로스체인 거래량은 Across와 유사하다(Socket—22억 달러, Across—17억 달러). 그러나 Across는 Socket/Bungee의 최근 거래량에 비해 극히 작은 부분만 차지한다.
대출 분야에서도 Yearn Finance는 최초의 탈중앙화 대출 수익 집계 프로토콜로 현재 시가총액이 약 2.5억 달러다. 반면 Aave(약 14억 달러), Compound(약 5.6억 달러) 등의 플랫폼은 더 높은 평가를 받고 있다.
전통 금융시장도 유사하다. 예를 들어 ICE(Intercontinental Exchange) US와 시카고상업거래소그룹(CME Group)의 시가총액은 각각 약 750억 달러인데, Charles Schwab, Robinhood 같은 '집계기'들은 각각 약 1320억 달러, 약 150억 달러의 시가총액을 보유하고 있다. ICE와 CME 등 다양한 거래소에 주문을 라우팅하는 Charles Schwab의 경우, 라우팅된 거래량 비율이 시가총액 비중과 비례하지 않는다. Robinhood는 매월 약 1억 1900만 건의 옵션 계약을 처리하는데, ICE는 약 3500만 건이다. 게다가 옵션 계약은 Robinhood 비즈니스 모델의 핵심조차 아니다. 그럼에도 불구하고 ICE는 공개 시장에서 Robinhood보다 약 5배 높은 평가를 받는다. 즉, Charles Schwab과 Robinhood는 애플리케이션 수준의 집계 인터페이스로서 고객 주문 흐름을 다양한 거래소로 라우팅하지만, 거래량이 크더라도 ICE와 CME만큼의 평가를 받지는 못한다.
소비자로서 우리는 집계기에 낮은 가치를 부여한다.
하지만 집계 계층이 제품/플랫폼/체인에 내장된다면 암호화폐에서는 이 규칙이 성립하지 않을 수 있다. 집계기가 체인에 직접 긴밀하게 통합된다면 분명히 다른 아키텍처가 되며, 어떻게 발전할지 매우 궁금하다. 한 예로 Polygon의 AggLayer는 개발자들이 쉽게 자신의 L1과 L2를 하나의 네트워크에 연결할 수 있게 해주며, 이 네트워크는 증명을 집계하고 CDK 기반 체인 간에 통합된 유동성 계층을 구현한다.
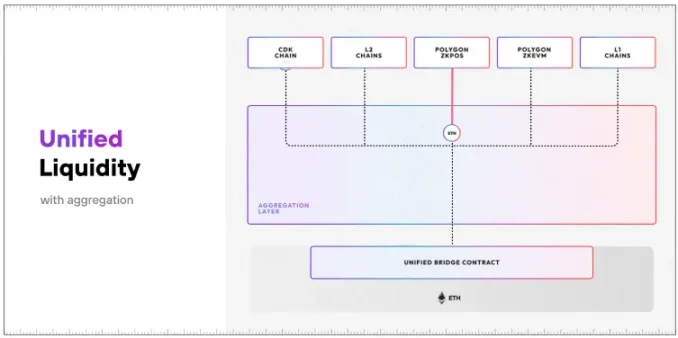
AggLayer
이 모델은 Avail의 Nexus 상호 운용성 계층과 유사하게 작동한다. Nexus는 증명 집계와 정렬 입찰 메커니즘을 포함해 DA 제품을 더욱 강력하게 만든다. Polygon의 AggLayer와 마찬가지로 Avail에 통합된 모든 체인 또는 롤업은 Avail 생태계 내에서 상호 운용이 가능하다. 또한 Avail은 이더리움, 모든 이더리움 롤업, Cosmos 체인, Avail 롤업, Celestia 롤업, Validiums, Optimiums, Polkadot 평행 체인 등 다양한 블록체인 플랫폼과 롤업에서 정렬된 트랜잭션 데이터를 풀링(pooling)한다. 어떤 생태계의 개발자라도 Avail의 DA 계층 위에서 무허가로 구축할 수 있으며, Avail Nexus를 통해 생태계 간 증명 집계와 메시지 전달이 가능하다.
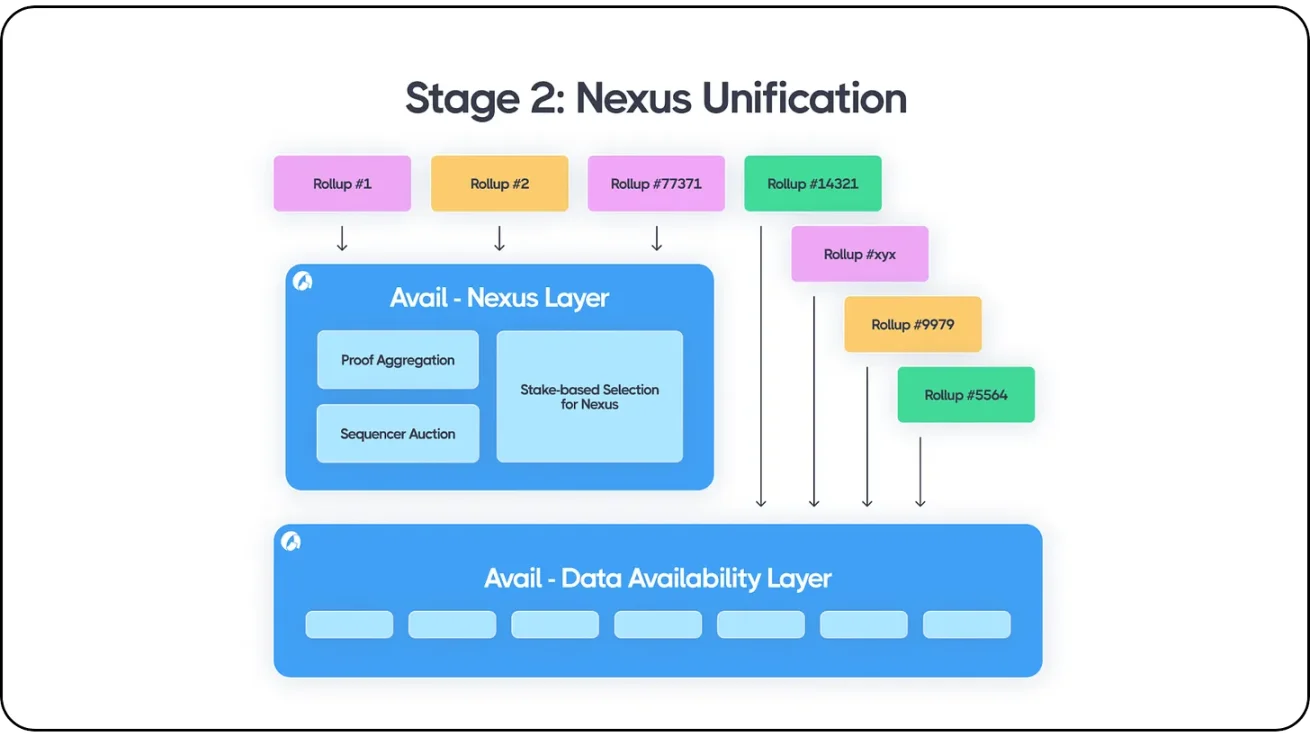
Avail Nexus
Nebra는 증명 집계와 결제에 집중하며, 서로 다른 증명 시스템 간 집계를 수행한다. 예를 들어 xyz 시스템 증명과 abc 시스템 증명을 집계하여 agg_xyzabc를 생성한다(xyz 시스템 내에서만 agg_xyz, abc 시스템 내에서만 agg_abc를 생성하는 것과 다름). 이 아키텍처는 UniPlonK를 사용해 회로 시리즈 검증자의 작업을 표준화함으로써 서로 다른 PlonK 회로 간 증명 검증을 더욱 효율적이고 실현 가능하게 한다. 본질적으로 이는 제로노울리지 증명 자체(재귀적 SNARK)를 사용해 검증 부분(이러한 시스템의 병목 지점)을 확장한다. 고객 입장에서는 '마지막 마일' 결제가 더 쉬워지는데, Nebra가 모든 배치 집계와 결제를 처리하므로 팀은 API 계약 호출만 변경하면 된다.
Astria는 공유 정렬기가 증명 집계와 어떻게 작동하는지에 관한 흥미로운 설계를 연구하고 있다. Astria는 실행 부분을 롤업 자체에 맡기며, 롤업은 공유 정렬기의 지정된 네임스페이스 위에서 실행 계층 소프트웨어를 실행한다. 이는 본질적으로 '실행 API'인데, 롤업이 정렬 계층 데이터를 수용하는 방식이다. 또한 여기에 EVM 상태 머신 규칙을 위반하지 않았음을 보장하기 위한 유효성 증명 지원을 쉽게 추가할 수 있다.
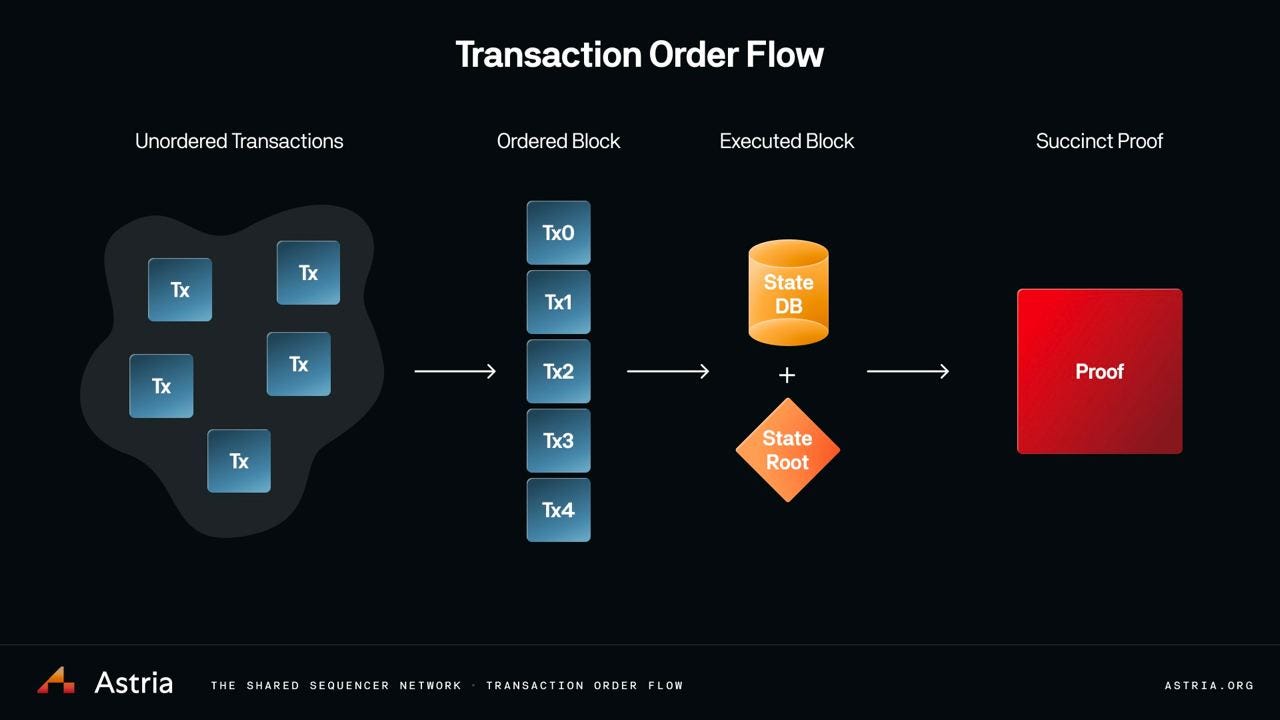
여기서 Astria 같은 제품은 #1 → #2 프로세스(정렬되지 않은 트랜잭션 → 정렬된 블록)를 담당하고, 실행 계층/롤업 노드가 #2 → #3을, Nebra 같은 프로토콜이 마지막 마일 #3 → #4(실행된 블록 → 간결한 증명)를 맡는다. Nebra는 이론적으로 증명이 집계된 후 검증되는 다섯 번째 단계가 될 수도 있다. Sovereign Labs도 마지막 단계와 유사한 개념을 연구하고 있으며, 증명 집계 기반 크로스체인 브릿지가 아키텍처의 핵심이다.
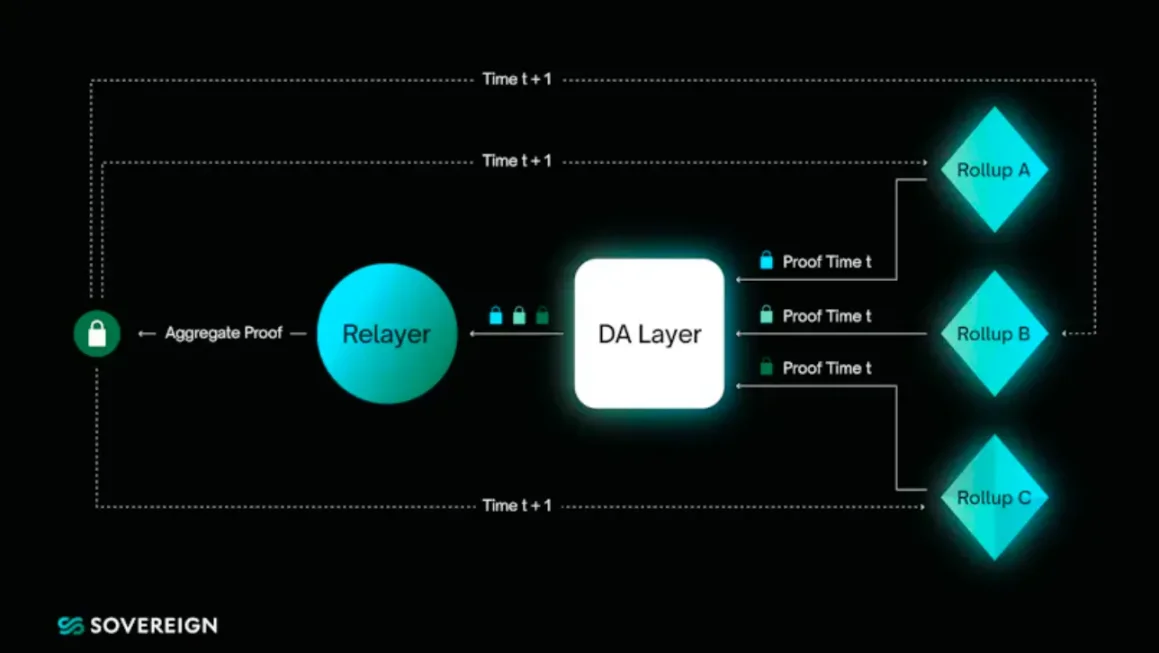
전반적으로 일부 애플리케이션 계층이 하위 인프라를 보유하게 되고 있는 이유는, 하위 스택을 통제하지 않으면 상위 애플리케이션만 유지하는 것이 인센티브 문제와 높은 사용자 채택 비용을 초래할 수 있기 때문이다. 반면 경쟁과 기술 발전으로 인해 인프라 비용이 계속 낮아지면서 애플리케이션/앱 체인이 모듈화 구성 요소와 통합하는 비용이 점점 저렴해지고 있다. 나는 이러한 역학 관계가 적어도 현재로서는 더욱 강력해질 것이라 믿는다.
이러한 모든 혁신(실행 계층, 결제 계층, 집계 계층) 덕분에 더 높은 효율성, 더 쉬운 통합, 더 강력한 상호 운용성, 더 낮은 비용이 가능해졌다. 이 모든 것이 궁극적으로 사용자에게 더 나은 애플리케이션을, 개발자에게 더 나은 개발 경험을 제공한다. 이는 더 많은 혁신과 더 빠른 혁신 속도를 만들어낼 수 있는 성공적인 조합이다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News














