

Kernel Ventures: DA 및 역사적 데이터 계층 설계에 대한 심층 분석
작자: Kernel Ventures Jerry Luo
TL;DR
-
초기 공용 블록체인은 보안과 탈중앙화를 보장하기 위해 전망 노드들이 데이터 일관성을 유지해야 했다. 그러나 블록체인 생태계의 발전에 따라 저장 압력이 계속 증가하여 노드 운영의 중앙집중화 추세가 나타났다. 현재 단계에서 Layer1은 TPS 증가로 인한 저장 비용 문제를 시급히 해결해야 한다.
-
이 문제에 직면하여 개발자들은 보안성, 저장 비용, 데이터 읽기 속도 및 DA 계층의 범용성을 고려하면서 새로운 역사적 데이터 저장 방안을 제시해야 한다.
-
이 문제를 해결하는 과정에서 샤딩(Sharding), DAS, 베르클 트리(Verkle Tree), DA 미들웨어 컴포넌트 등 많은 신기술과 새로운 아이디어가 등장했다. 이들은 데이터 중복 감소와 데이터 검증 효율성 향상 등의 경로를 통해 DA 계층의 저장 방안을 최적화하려고 시도하고 있다.
-
현재 단계의 DA 방안은 데이터 저장 위치를 기준으로 대략 두 가지로 나뉜다. 하나는 메인 체인 DA이고 다른 하나는 제3자 DA이다. 메인 체인 DA는 정기적인 데이터 삭제와 데이터 분할 저장을 통해 노드의 저장 부담을 줄이는 것을 목표로 한다. 반면 제3자 DA는 저장 서비스를 위한 설계 요구사항을 갖고 있으며, 대량의 데이터에 대해 합리적인 해결책을 제공한다. 따라서 주로 단일 체인 호환성과 다중 체인 호환성 사이에서 균형을 맞추며 메인 체인 전용 DA, 모듈화된 DA, 저장 공용 블록체인 DA라는 세 가지 해결책을 제시했다.
-
결제 중심 공용 블록체인은 역사적 데이터 보안에 매우 높은 요구를 하므로 메인 체인을 DA 계층으로 사용하는 것이 적합하다. 그러나 오랜 시간 동안 운영되면서 많은 채굴자가 네트워크를 운영하는 공용 블록체인의 경우, 합의 계층을 포함하지 않으면서도 보안성을 고려한 제3자 DA가 더욱 적합하다. 종합적인 공용 블록체인은 데이터 용량이 크고 비용이 낮으며 보안성이 뛰어난 메인 체인 전용 DA 저장 방식을 더 선호한다. 그러나 교차 체인 수요를 고려하면 모듈화된 DA도 좋은 선택이 될 수 있다.
-
전반적으로 볼 때, 블록체인은 데이터 중복 감소 및 다중 체인 분업의 방향으로 나아가고 있다.
1. 배경
블록체인은 분산 원장로서 모든 노드에서 역사적 데이터를 저장함으로써 데이터 저장의 안전성과 충분한 탈중앙화를 보장해야 한다. 각 상태 변경의 정확성은 이전 상태(거래 출처)와 관련되기 때문에 거래의 정확성을 보장하기 위해 블록체인은 첫 번째 거래 발생부터 현재 거래까지의 모든 역사적 기록을 저장해야 한다. 예를 들어 이더리움의 경우 평균적으로 각 블록당 20KB 크기를 기준으로 삼더라도 현재 이더리움 블록의 총 크기는 이미 370GB에 달하며, 전체 노드는 블록 자체 외에도 상태와 거래 영수증 기록을 저장해야 한다. 이를 포함하면 단일 노드의 저장 총량은 이미 1TB를 초과하여 노드 운영이 소수에게 집중되는 결과를 초래한다.
이더리움 최신 블록 높이, 출처: Etherscan
2. DA 성능 지표
2.1 보안성
블록체인은 데이터베이스나 링크드리스트 구조와 비교해 불변성이라는 특징을 갖는데, 이는 역사적 데이터를 통해 새로 생성된 데이터를 검증할 수 있기 때문이다. 따라서 역사적 데이터의 보안성을 확보하는 것은 DA 계층 저장에서 가장 먼저 고려해야 할 사항이다. 블록체인 시스템의 데이터 보안성을 평가할 때는 일반적으로 데이터 중복 수량과 데이터 가용성 검증 방식을 분석한다.
-
중복 수량: 블록체인 시스템에서 데이터 중복은 다음과 같은 역할을 한다. 우선 네트워크 내 중복 수량이 많을수록 검증자가 특정 역사적 블록의 계정 상태를 조회해 현재 거래를 검증할 때 더 많은 샘플을 참고할 수 있고, 대부분의 노드가 기록한 데이터를 선택할 수 있다. 반면 전통적인 데이터베이스는 단일 노드에 키-값 형태로 데이터를 저장하기 때문에 역사적 데이터를 수정하려면 한 노드에서만 작업하면 되어 공격 비용이 매우 낮다. 이론적으로 중복 수량이 많을수록 데이터의 신뢰도가 높아진다. 또한 저장 노드가 많을수록 데이터 유실 가능성도 낮아진다. 이는 웹2 게임의 중앙화 서버와 비교할 수 있는데, 백엔드 서버가 모두 종료되면 완전히 서비스 종료된다. 하지만 이 수치가 많을수록 좋다는 것은 아니며, 각 중복은 추가 저장 공간을 필요로 하므로 과도한 데이터 중복은 시스템에 큰 저장 부담을 준다. 좋은 DA 계층은 보안성과 저장 효율 사이에서 적절한 균형을 이루는 중복 방식을 선택해야 한다.
-
데이터 가용성 검증: 중복 수량은 네트워크 내 데이터 기록 수를 보장하지만, 실제 사용할 데이터는 정확성과 무결성도 검증되어야 한다. 현재 블록체인에서 일반적으로 사용되는 검증 방식은 암호학적 커밋 알고리즘으로, 거래 데이터를 혼합해 아주 작은 암호학적 커밋을 만들어 전망에 기록하는 것이다. 특정 역사적 데이터의 진위를 검증할 때는 해당 데이터로 암호학적 커밋을 재생성하고, 이것이 전망 기록과 일치하는지 확인한다. 일치하면 검증 통과다. 일반적인 암호학적 검증 알고리즘으로는 머클 루트(Merkle Root)와 베르클 루트(Verkle Root)가 있다. 높은 보안성을 가진 데이터 가용성 검증 알고리즘은 적은 검증 데이터로도 빠르게 역사적 데이터를 검증할 수 있다.
2.2 저장 비용
기본적인 보안성을 확보한 후, DA 계층이 다음으로 달성해야 할 핵심 목표는 비용 절감과 효율 증대다. 우선 저장 비용을 낮춰야 하며, 하드웨어 성능 차이를 고려하지 않는다면 단위 데이터 저장 시 발생하는 메모리 사용량을 줄여야 한다. 현재 블록체인에서 저장 비용을 낮추는 방법은 주로 샤딩 기술을 활용하거나 보상 기반 저장 방식을 사용해 데이터 백업 수량을 줄이는 것이다. 그러나 이러한 개선 방식을 보면 저장 비용과 데이터 보안성 사이에는 상충 관계가 있음을 알 수 있다. 저장 공간 사용량을 줄이면 보안성도 저하될 가능성이 있다. 따라서 우수한 DA 계층은 저장 비용과 데이터 보안성 사이에서 균형을 이루어야 한다. 또한 DA 계층이 별도의 공용 블록체인이면 데이터 교환이 거치는 중간 과정을 최소화해 비용을 줄여야 한다. 매번 중계 과정마다 후속 조회를 위한 인덱스 데이터를 남기므로 호출 과정이 길어질수록 더 많은 인덱스 데이터가 남아 저장 비용이 증가한다. 마지막으로 데이터 저장 비용은 데이터의 지속성과 직접 연관된다. 일반적으로 데이터 저장 비용이 높을수록 공용 블록체인이 데이터를 지속적으로 저장하기 어려워진다.
2.3 데이터 읽기 속도
비용 절감을 실현한 후 다음은 효율 증대다. 즉, 데이터 사용 시 이를 DA 계층에서 빠르게 호출할 수 있어야 한다. 이 과정은 두 단계로 나뉜다. 먼저 데이터 저장 노드를 찾는 것인데, 이는 전망 노드의 데이터 일관성이 실현되지 않은 공용 블록체인에 해당한다. 공용 블록체인이 전망 노드 데이터 동기화를 실현하면 이 과정의 시간 소모를 무시할 수 있다. 둘째, 현재 주류 블록체인 시스템(BTC, 이더리움, Filecoin 등)에서는 Leveldb 데이터베이스를 노드 저장 방식으로 사용한다. Leveldb에서는 데이터가 세 가지 방식으로 저장된다. 먼저 즉시 기입되는 데이터는 Memtable 형식 파일에 저장되며, Memtable이 가득 차면 Immutable Memtable로 바뀐다. 이 두 형식 파일은 모두 메모리에 저장되지만 Immutable Memtable은 수정할 수 없고 읽기만 가능하다. IPFS 네트워크에서 사용하는 핫 스토리지는 데이터를 이 부분에 저장하여 메모리에서 빠르게 읽을 수 있게 한다. 그러나 일반 노드의 이동 메모리는 GB 단위여서 쉽게 느려지고, 노드 다운 등의 이상 상황 발생 시 메모리 데이터는 영구적으로 유실된다. 데이터를 지속적으로 저장하려면 SST 파일 형식으로 SSD에 저장해야 하지만, 데이터를 읽을 때 먼저 메모리로 읽어야 하므로 데이터 색인 속도가 크게 낮아진다. 마지막으로 분할 저장을 채택한 시스템은 데이터 복원 시 여러 노드에 데이터 요청을 보내고 복원해야 하므로 데이터 읽기 속도도 저하된다.
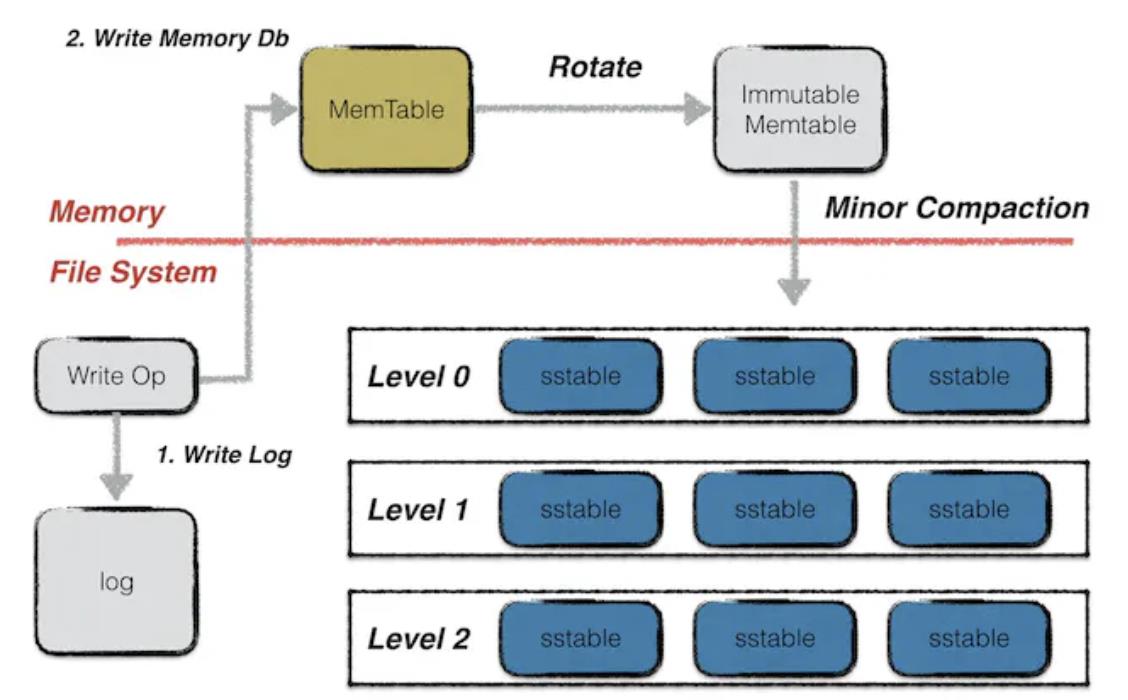
Leveldb 데이터 저장 방식, 출처: Leveldb-handbook
2.4 DA 계층 범용성
DeFi의 발전과 CEX의 다양한 문제로 인해 사용자들의 탈중앙화 자산 교차 체인 거래 요구가 지속적으로 증가하고 있다. 해시 잠금, 공증인, 리레이 체인 등의 교차 체인 메커니즘을 막론하고 두 체인의 역사적 데이터 동시 확정을 피할 수 없다. 이 문제의 핵심은 두 체인의 데이터 분리로, 서로 다른 탈중앙화 시스템 간 직접 소통이 불가능하다는 점이다. 현재 DA 계층 저장 방식을 변경해 해결책을 제시했는데, 여러 공용 블록체인의 역사적 데이터를 동일한 신뢰 가능한 공용 블록체인에 저장하면 검증 시 이 공용 블록체인에서 데이터를 호출하기만 하면 된다. 이를 위해서는 DA 계층이 다양한 유형의 공용 블록체인과 안전한 통신 방식을 수립할 수 있어야 하며, 즉 DA 계층이 뛰어난 범용성을 가져야 한다.
3. DA 관련 기술 탐색
3.1 샤딩(Sharding)
-
기존 분산 시스템에서 파일은 한 노드에 완전한 형태로 저장되지 않고 원본 데이터를 여러 Blocks로 나눈 후 각 노드에 하나의 Block씩 저장한다. 그리고 Block은 한 노드에만 저장되지 않고 다른 노드에도 적절한 백업을 둔다. 현재 주류 분산 시스템에서는 이 백업 수량을 일반적으로 2개로 설정한다. 이러한 샤딩 메커니즘은 단일 노드의 저장 부담을 줄이고 시스템의 총 용량을 각 노드 저장량의 합으로 확장할 수 있으며, 적절한 데이터 중복을 통해 저장 보안성을 확보한다. 블록체인의 샤딩 방안은 대체로 유사하지만 구체적인 세부 사항은 다르다. 우선 블록체인에서는 기본적으로 각 노드가 신뢰할 수 없다고 간주하므로 샤딩을 실현하는 과정에서 후속 데이터 진위 판단을 위해 충분한 양의 데이터 백업이 필요하므로 노드의 백업 수량이 2개보다 훨씬 많아야 한다. 이상적인 상황에서 이러한 방안을 저장하는 블록체인 시스템에서 검증 노드 총수가 T, 샤딩 수량이 N이라면 백업 수량은 T/N이어야 한다. 둘째, Block 저장 과정인데, 기존 분산 시스템은 노드 수가 적어 한 노드가 여러 데이터 블록에 대응하는 경우가 많다. 우선 일관성 있는 해시 알고리즘을 사용해 데이터를 해시링에 매핑한 후 각 노드는 특정 범위의 데이터 블록을 저장하며, 특정 저장에서 노드가 저장 작업을 할당받지 못할 수도 있다. 반면 블록체인에서는 각 노드가 Block을 할당받는 것이 더 이상 무작위 사건이 아니라 필연적인 사건이며, 각 노드는 무작위로 하나의 Block을 선택해 저장한다. 이 과정은 블록 원본 데이터와 노드 자체 정보를 포함한 데이터의 해시 결과를 샤딩 수로 나눈 나머지를 통해 완료된다. 만약 각 데이터를 N개의 Blocks로 나눈다면 각 노드의 실제 저장 크기는 원래의 1/N만 된다. 적절한 N을 설정함으로써 증가하는 TPS와 노드 저장 부담 사이의 균형을 실현할 수 있다.
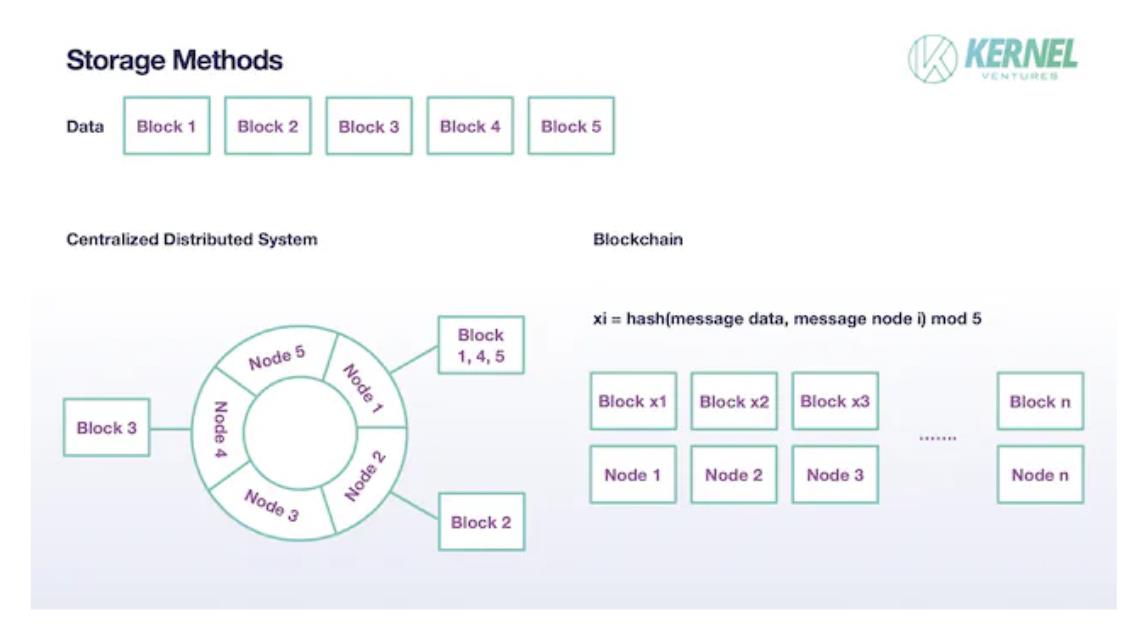
샤딩 후 데이터 저장 방식, 출처: Kernel Ventures
3.2 DAS(Data Availability Sampling)
DAS 기술은 저장 방식 측면에서 샤딩을 더욱 최적화한 것이다. 샤딩 과정에서 노드가 단순 무작위 저장을 하면 특정 Block이 유실될 수 있다. 또한 샤딩된 데이터의 복원 과정에서 데이터 진위와 무결성을 확인하는 것도 매우 중요하다. DAS는 Eraser code와 KZG 다항식 커밋을 통해 이 두 문제를 해결한다.
-
Eraser code: 이더리움의 방대한 검증 노드 수를 고려하면 어떤 Block도 저장되지 않을 확률은 거의 0이지만 이론적으로는 여전히 이런 극단적 상황이 발생할 가능성이 있다. 이러한 저장 누락 위협을 완화하기 위해 이 방안에서는 원본 데이터를 직접 Block으로 나누어 저장하지 않고, 먼저 원본 데이터를 n차 다항식 계수에 매핑한 후 다항식에서 2n개의 점을 취하고 노드가 그 중 하나를 무작위로 선택해 저장하도록 한다. 이 n차 다항식은 n+1개의 점만 있으면 복원할 수 있으므로 절반의 Block만 노드에 선택되더라도 원본 데이터를 복원할 수 있다. Eraser code를 통해 데이터 저장 보안 수준과 네트워크의 데이터 복구 능력을 향상시켰다.
-
KZG 다항식 커밋: 데이터 저장에서 중요한 요소는 데이터 진위 검증이다. Eraser code를 사용하지 않은 네트워크에서는 검증 단계에서 다양한 방법을 채택할 수 있지만, 위에서 언급한 Eraser code를 도입해 데이터 보안성을 높였다면 적절한 방법은 KZG 다항식 커밋을 사용하는 것이다. KZG 다항식 커밋은 단일 Block 내용을 다항식 형태로 직접 검증할 수 있어 이진 데이터로 복원하는 과정을 생략할 수 있다. 검증 형식은 전반적으로 머클 트리와 유사하지만 구체적인 Path 노드 데이터가 필요하지 않고 KZG 루트와 Block 데이터만으로 진위를 검증할 수 있다.
3.3 DA 계층 데이터 검증 방식
데이터 검증은 노드에서 호출한 데이터가 조작되지 않았고 유실되지 않았음을 보장한다. 검증 과정에서 필요한 데이터량과 계산 비용을 최소화하기 위해 DA 계층은 현재 트리 구조를 주류 검증 방식으로 채택하고 있다. 가장 간단한 형태는 머클 트리를 사용해 검증하는 것으로, 완전 이진 트리 형태로 기록하며 Merkle Root와 노드 경로의 다른 쪽 하위 트리 해시 값만 유지하면 검증이 가능하다. 검증 시간 복잡도는 O(logN) 수준이다(logN은 밑이 없으면 log2(N)으로 간주). 이미 검증 과정을 크게 간소화했지만 검증량은 여전히 데이터 증가에 따라 증가한다. 증가하는 검증량 문제를 해결하기 위해 현재 또 다른 검증 방식인 Verkle Tree가 제시됐다. Verkle Tree에서 각 노드는 value를 저장할 뿐만 아니라 Vector Commitment도 첨부하며, 원래 노드의 값과 이 커밋성 증명을 통해 데이터 진위를 빠르게 검증할 수 있고 다른 자매 노드의 값을 호출할 필요가 없다. 이를 통해 매번 검증의 계산 횟수는 Verkle Tree의 깊이에만 관련되어 고정된 상수이므로 검증 속도를 크게 가속화한다. 그러나 Vector Commitment 계산에는 동일 계층의 모든 자매 노드 참여가 필요하므로 데이터 기입과 변경 비용이 크게 증가한다. 하지만 역사적 데이터처럼 영구 저장되고 조작 불가능한 데이터의 경우 읽기만 필요하고 기입은 필요 없으므로 Verkle Tree가 매우 적합하다. 또한 머클 트리와 Verkle Tree 자체도 K-ary 형태의 변형이 있으며 구현 메커니즘은 유사하지만 각 노드 하위 트리 수량을 변경한 것이다. 구체적인 성능 비교는 아래 표를 참조한다.
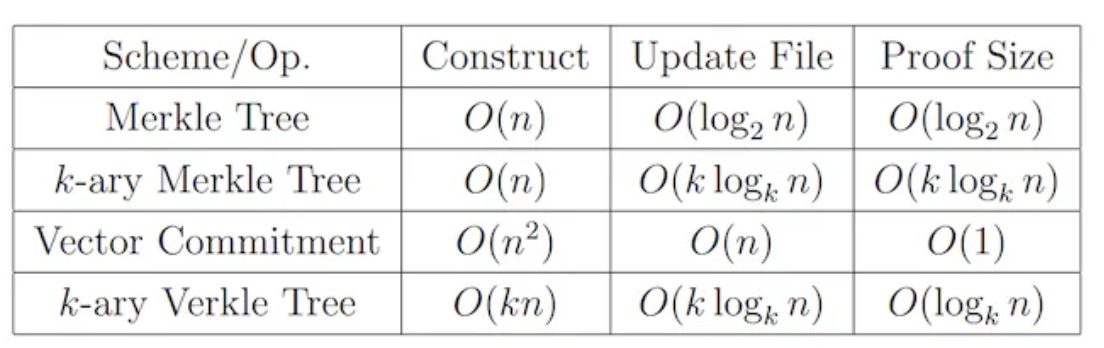
데이터 검증 방식 시간 성능 비교, 출처: Verkle Trees
3.4 범용 DA 미들웨어
블록체인 생태계의 지속적인 확장은 공용 블록체인 수량의 증가를 수반한다. 각 공용 블록체인이 각자의 분야에서 장점과 대체 불가능성을 가지고 있어 단기간 내 Layer1 공용 블록체인이 통합될 가능성은 거의 없다. 그러나 DeFi의 발전과 CEX의 다양한 문제로 인해 사용자들의 탈중앙화 교차 체인 자산 거래 요구도 계속 증가하고 있다. 따라서 교차 체인 데이터 상호 작용의 보안 문제를 제거할 수 있는 DA 계층의 다중 체인 데이터 저장 방식이 점점 더 많은 관심을 받고 있다. 그러나 서로 다른 공용 블록체인의 역사적 데이터를 수용하려면 DA 계층이 데이터 스트림 표준화 저장 및 검증을 위한 탈중앙화 프로토콜을 제공해야 한다. 예를 들어 Arweave 기반의 저장 미들웨어 kvye는 체인에서 데이터를 적극적으로 수집하는 방식을 채택해 모든 체인의 데이터를 표준 형태로 Arweave에 저장함으로써 데이터 전송 과정의 차이를 최소화한다. 반면 특정 공용 블록체인에 DA 계층 데이터 저장을 제공하는 전용 Layer2는 내부적으로 노드를 공유하는 방식으로 데이터를 교환하므로 상호 작용 비용을 낮추고 보안성을 높일 수 있지만 큰 한계가 있어 특정 공용 블록체인에만 서비스를 제공할 수 있다.
4. DA 계층 저장 방안
4.1 메인 체인 DA
4.1.1 댕크샤딩(DankSharding) 유사 방안
이 저장 방안은 아직 확정된 이름이 없으며 가장 두드러진 사례는 이더리움의 DankSharding이므로 본문에서는 이를 댕크샤딩 유사 방안이라고 칭한다. 이 방안은 앞서 언급한 두 가지 DA 저장 기술인 샤딩과 DAS를 주로 사용한다. 먼저 샤딩을 통해 데이터를 적절한 분량으로 나눈 후 각 노드가 DAS 형식으로 데이터 Block 하나를 선택해 저장한다. 전망 노드가 충분히 많은 경우 큰 샤딩 수 N을 선택할 수 있으므로 각 노드의 저장 부담은 원래의 1/N만 되어 전체 저장 공간을 N배로 확장할 수 있다. 동시에 어떤 Block도 어느 노드에 저장되지 않는 극단적 상황을 방지하기 위해 댕크샤딩은 데이터에 Eraser Code를 사용해 인코딩함으로써 데이터 절반만으로도 완전 복원이 가능하게 한다. 마지막으로 데이터 검증 과정에서는 Verkle 트리 구조와 다항식 커밋을 사용해 빠른 검증을 실현한다.
4.1.2 단기 저장
메인 체인 DA의 경우 가장 간단한 데이터 처리 방식은 역사적 데이터를 단기 저장하는 것이다. 본질적으로 블록체인은 공개 원장의 역할을 하며 전망 공동 증인 하에서 원장 내용 변경을 실현하지만 영구 저장은 필요 없다. 예를 들어 Solana의 경우 역사적 데이터가 Arweave에 동기화되었지만 메인넷 노드는 최근 2일간의 거래 데이터만 유지한다. 계정 기록 기반 공용 블록체인에서 각 시점의 역사적 데이터는 블록체인 계정의 최종 상태를 보유함으로써 다음 시점의 변경을 위한 검증 근거를 제공할 수 있다. 이 기간 이전 데이터에 특별한 요구가 있는 프로젝트팀은 다른 탈중앙화 공용 블록체인에 저장하거나 신뢰할 수 있는 제3자에 위탁할 수 있다. 즉, 추가 데이터 요구가 있는 사람은 역사적 데이터 저장 비용을 지불해야 한다.
4.2 제3자 DA
4.2.1 메인 체인 전용 DA: EthStorage
-
메인 체인 전용DA: DA 계층에서 가장 중요한 것은 데이터 전송의 보안성인데, 이 면에서 가장 보안성이 높은 것은 메인 체인 DA이다. 그러나 메인 체인 저장은 저장 공간 제약과 자원 경쟁을 받기 때문에 네트워크 데이터량이 빠르게 증가할 때 장기 저장을 실현하려면 제3자 DA가 더 나은 선택이 될 수 있다. 제3자 DA가 메인넷과 더 높은 호환성을 가지면 노드를 공유할 수 있고 데이터 상호 작용 과정에서도 더 높은 보안성을 갖는다. 따라서 보안성을 고려할 때 메인 체인 전용 DA는 큰 이점을 가진다. 예를 들어 이더리움의 경우 메인 체인 전용 DA의 기본 요구사항은 EVM과 호환되어 이더리움 데이터와 계약 간 상호 운용성을 보장하는 것이다. 대표적인 프로젝트로는 Topia, EthStorage 등이 있다. 이 중 EthStorage는 호환성 측면에서 현재 가장 완벽하게 개발된 것으로, EVM 수준의 호환성 외에도 Remix, Hardhat 등의 이더리움 개발 도구와 전용 인터페이스를 설정해 이더리움 개발 도구 수준의 호환성을 실현했다.
-
EthStorage: EthStorage는 이더리움과 독립된 공용 블록체인이지만 실행되는 노드는 이더리움 노드의 초집합으로, EthStorage 노드를 실행하면 이더리움도 동시에 실행할 수 있다. 이더리움의 오퍼코드를 통해 EthStorage를 직접 조작할 수 있다. EthStorage의 저장 모델은 이더리움 메인넷에 인덱스용 소량의 메타데이터만 유지하며 본질적으로 이더리움을 위한 탈중앙화 데이터베이스를 만든다. 현재 솔루션에서 EthStorage는 이더리움 메인넷에 EthStorage Contract를 배포해 이더리움 메인넷과 EthStorage의 상호 작용을 실현한다. 이더리움이 데이터를 저장하려면 put() 함수를 호출해야 하며 입력 매개변수는 두 바이트 변수 key, data이며 data는 저장할 데이터를 의미하고 key는 이더리움 네트워크에서의 식별자로 IPFS의 CID와 유사하다고 볼 수 있다. (key, data) 데이터 쌍이 EthStorage 네트워크에 성공적으로 저장된 후 EthStorage는 kvldx를 생성해 이더리움 메인넷에 반환하고 이더리움의 key와 연결한다. 이 값은 EthStorage 상의 데이터 저장 주소를 나타내며, 원래 대량의 데이터를 저장해야 하는 문제가 이제 단일 (key, kvldx) 쌍 저장으로 바뀌어 이더리움 메인넷의 저장 비용을 크게 줄였다. 이전에 저장된 데이터를 호출하려면 EthStorage의 get() 함수를 사용하고 key 매개변수를 입력해야 하며, 이더리움이 저장한 kvldx를 통해 EthStorage에서 데이터를 빠르게 찾을 수 있다.
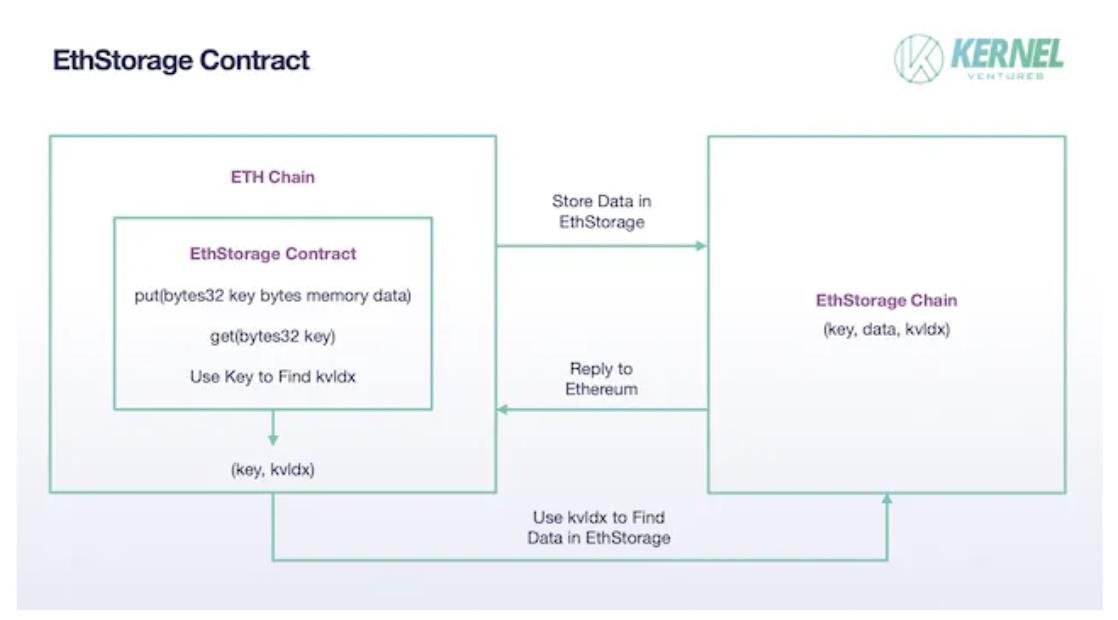
EthStorage 계약, 출처: Kernel Ventures
-
노드의 구체적인 데이터 저장 방식에서 EthStorage는 Arweave 모델을 참고했다. 우선 ETH로부터 온 대량의 (k,v) 쌍을 샤딩하고 각 샤딩은 고정 수량의 (k,v) 데이터 쌍을 포함하며 각 (k,v) 쌍의 구체적인 크기도 제한이 있다. 이를 통해 이후 채굴자 저장 보상 과정에서 작업량 크기의 공정성을 보장한다. 보상 지급은 먼저 노드가 데이터를 저장했는지 검증해야 한다. 이 과정에서 EthStorage는 하나의 샤딩(TB 규모)을 수많은 chunk로 나누고 이더리움 메인넷에 Merkle root를 유지해 검증에 사용한다. 이후 채굴자는 먼저 nonce를 제공해 EthStorage의 이전 블록 해시와 함께 랜덤 알고리즘을 통해 몇 개의 chunk 주소를 생성해야 하며, 채굴자는 이 chunk 데이터를 제공해 전체 샤딩을 실제로 저장했음을 증명해야 한다. 그러나 이 nonce는 임의로 선택할 수 없으며, 그렇지 않으면 노드가 자신이 저장한 chunk에만 해당하는 적절한 nonce를 선택해 검증을 통과할 수 있기 때문이다. 따라서 이 nonce는 생성된 chunk를 혼합하고 해시한 후 난이도 값이 네트워크 요구에 부합해야 하며, 처음으로 nonce와 랜덤 접근 증명을 제출한 노드만 보상을 받을 수 있다.
4.2.2 모듈화된 DA: Celestia
-
블록체인 모듈: 현재 단계에서 Layer1 공용 블록체인이 수행해야 하는 주요 업무는 다음과 같은 네 부분으로 나뉜다. (1) 네트워크 하부 로직 설계, 특정 방식으로 검증 노드를 선정하고 블록을 작성하며 네트워크 유지 보상자를 배분한다. (2) 거래를 패키징 처리하고 관련 업무를 발표한다. (3) 체인에 올릴 거래를 검증하고 최종 상태를 확정한다. (4) 블록체인의 역사적 데이터를 저장하고 유지 보수한다. 수행 기능에 따라 블록체인을 네 가지 모듈로 나눌 수 있다. 즉, 합의 계층, 실행 계층, 결제 계층, 데이터 가용성 계층(DA 계층).
-
모듈화된 블록체인 설계: 오랫동안 이 네 가지 모듈은 한 공용 블록체인에 통합되어 있었으며, 이를 단일체 블록체인이라고 한다. 이 형태는 더 안정적이며 유지 관리가 쉬우나 단일 공용 블록체인에 큰 부담을 준다. 실제 운영 과정에서 이 네 가지 모듈은 서로 제약하고 공용 블록체인의 제한된 계산 및 저장 자원을 경쟁한다. 예를 들어 실행 계층의 처리 속도를 높이면 DA 계층에 더 큰 저장 부담을 주며, 실행 계층의 보안성을 보장하려면 더 복잡한 검증 메커니즘이 필요하지만 거래 처리 속도가 느려진다. 따라서 공용 블록체인 개발은 종종 이 네 가지 모듈 사이의 균형을 고려해야 한다. 이 공용 블록체인 성능 향상의 병목 현상을 돌파하기 위해 개발자들은 모듈화된 블록체인 방안을 제시했다. 모듈화된 블록체인의 핵심 아이디어는 위의 네 가지 모듈 중 하나 또는 여러 개를 분리해 별도의 공용 블록체인에서 실현하는 것이다. 이렇게 하면 해당 공용 블록체인에서 거래 속도 또는 저장 능력 향상에만 집중할 수 있어 이전의 단점 효과로 인한 블록체인 전체 성능 제한을 돌파할 수 있다.
-
모듈화된 DA: DA 계층을 블록체인 업무에서 분리해 별도의 공용 블록체인에 맡기는 방법은 Layer1의 증가하는 역사적 데이터에 직면한 실현 가능한 해결책으로 여겨진다. 현재 이 분야의 탐색은 초기 단계에 있으며 가장 대표적인 프로젝트는 Celestia다. 저장 구체적인 방식에서 Celestia는 댕크샤딩 저장 방식을 참고해 데이터를 여러 Block으로 나누고 각 노드가 일부를 선택해 저장하며 동시에 KZG 다항식 커밋을 사용해 데이터 무결성을 검증한다. 동시에 Celestia는 첨단 2차원 RS 삭제 코드를 사용해 원본 데이터를 kk 행렬 형태로 재작성하며, 최종적으로 원본 데이터를 복원하기 위해 25% 부분만 필요하다. 그러나 데이터 분할 저장은 본질적으로 전망 노드의 저장 부담을 총 데이터량에 계수를 곱한 것일 뿐이며 노드의 저장 부담과 데이터량은 여전히 선형 증가한다. Layer1이 거래 속도를 지속적으로 개선함에 따라 노드의 저장 부담은 언젠가 받아들일 수 없는 임계점에 도달할 수 있다. 이 문제를 해결하기 위해 Celestia는 IPLD 구성 요소를 도입해 처리한다. kk 행렬의 데이터는 직접 Celestia에 저장되지 않고 LL-IPFS 네트워크에 저장되며 노드는 IPFS 상의 CID 코드만 유지한다. 사용자가 특정 역사적 데이터를 요청하면 노드는 IPLD 구성 요소에 해당 CID를 보내고 이 CID를 통해 IPFS에서 원본 데이터를 호출한다. IPFS에 데이터가 존재하면 IPLD 구성 요소와 노드를 통해 반환되며, 존재하지 않으면 데이터를 반환할 수 없다.
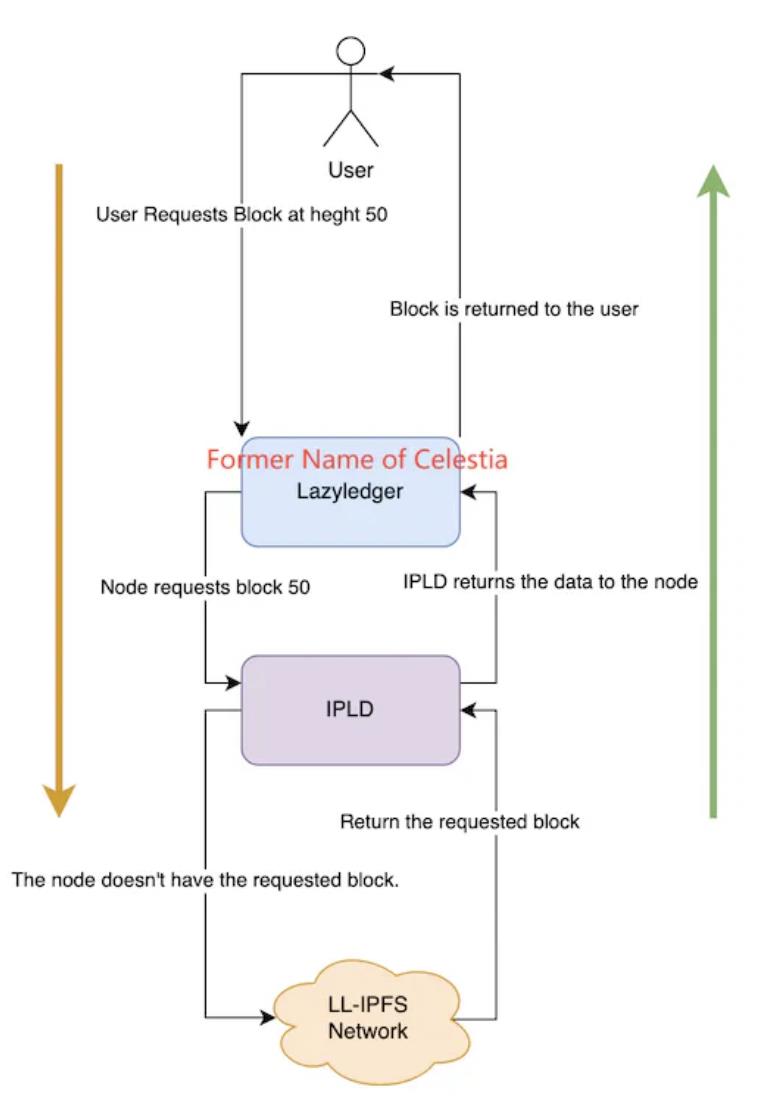
Celestia 데이터 읽기 방식, 출처: Celestia Core
-
Celestia: Celestia를 예로 들면 모듈화된 블록체인이 이더리움 저장 문제 해결에 어떻게 적용되는지를 엿볼 수 있다. Rollup 노드는 패키징 및 검증된 거래 데이터를 Celestia에 보내고 Celestia에 데이터를 저장하며, 이 과정에서 Celestia는 데이터 저장만 관리하고 과도한 인식은 하지 않는다. 마지막으로 저장 공간 크기에 따라 Rollup 노드는 tia 토큰을 저장 비용으로 Celestia에 지불한다. Celestia의 저장은 EIP4844의 DAS와 삭제 코드를 활용하지만 EIP4844의 다항식 삭제 코드를 업그레이드해 2차원 RS 삭제 코드를 사용해 저장 보안을 다시 한 번 강화하며 전체 거래 데이터를 복원하기 위해 25%의 파편만 필요하다. 본질적으로 저장 비용이 낮은 POS 공용 블록체인일 뿐이며, 이더리움의 역사적 데이터 저장 문제를 해결하려면 Celestia와 협력할 다른 많은 구체적인 모듈이 필요하다. 예를 들어 Rollup 측면에서 Celestia 공식 웹사이트는 Sovereign Rollup이라는 Rollup 모드를 적극 추천한다. 일반적인 Layer2 Rollup과 달리 거래를 계산하고 검증하는 실행 계층 작업만 수행하는 것이 아니라 실행과 결제 전체 과정을 포함한다. 이는 Celestia의 거래 처리를 최소화하며, Celestia의 전반적인 보안성이 이더리움보다 약한 상황에서 전체 거래 과정의 보안성을 최대한 높일 수 있다. 이더리움 메인넷에서 Celestia 데이터 호출의 보안성 보장 측면에서 현재 가장 주류인 방안은 Quantum Gravity Bridge 스마트 계약이다. Celestia에 저장된 데이터는 Merkle Root(데이터 가용성 증명)를 생성해 이더리움 메인넷의 Quantum Gravity Bridge 계약에 유지하며, 이더리움이 매번 Celestia의 역사적 데이터를 호출할 때 해시 결과를 Merkle Root와 비교해 일치하면 진짜 역사적 데이터임을 의미한다.
4.2.3 저장 공용 블록체인 DA
메인 체인 DA 기술 원리에서 저장 공용 블록체인은 샤딩과 유사한 많은 기술을 참고했다. 제3자 DA에서 일부는 저장 공용 블록체인을 직접 활용해 일부 저장 작업을 완료하기도 한다. 예를 들어 Celestia의 구체적인 거래 데이터는 LL-IPFS 네트워크에 저장된다. 제3자 DA 방안에서 Layer1의 저장 문제를 해결하기 위해 별도의 공용 블록체인을 구축하는 것 외에도 저장 공용 블록체인과 Layer1을 직접 연결해 Layer1의 방대한 역사적 데이터를 저장하는 더 직접적인 방법도 있다. 고성능 블록체인의 경우 역사적 데이터 규모가 더 크며, 전속력으로 운영될 경우 고성능 공용 블록체인 Solana의 데이터량은 약 4PG에 달해 일반 노드의 저장 범위를 완전히 초과한다. Solana가 선택한 해결책은 역사적 데이터를 탈중앙화 저장 네트워크 Arweave에 저장하고 메인넷 노드에는 검증용 2일치 데이터만 유지하는 것이다. 저장 과정의 보안성을 확보하기 위해 Solana는 Arweave 체인과 자체적으로 저장 브리지 프로토콜 Solar Bridge를 설계했다. Solana 노드가 검증한 데이터는 Arweave에 동기화되어 해당 tag를 반환한다. 이 tag를 통해 Solana 노드는 Solana 블록체인의 임의 시점 역사적 데이터를 조회할 수 있다. Arweave에서는 전망 노드가 데이터 일관성을 유지할 필요 없이 네트워크 운영 참여의 문턱으로 삼지 않고 보상 저장 방식을 채택한다. 우선 Arweave는 전통적인 체인 구조로 블록을 구성하지 않고 그래프 구조에 더 가깝다. Arweave에서 새 블록은 이전 블록을 가리킬 뿐만 아니라 이미 생성된 블록인 Recall Block을 무작위로 가리킨다. Recall Block의 구체적인 위치는 이전 블록과 블록 높이의 해시 결과로 결정되며 이전 블록이 채굴되기 전까지 Recall Block의 위치는 알려지지 않는다. 그러나 새 블록 생성 과정에서 POW 메커니즘을 사용해 규정된 난이도의 해시를 계산하려면 노드가 Recall Block의 데이터를 가져야 하며, 난이도에 맞는 해시를 가장 먼저 계산한 채굴자만 보상을 받을 수 있으므로 채굴자가尽可能 많은 역사적 데이터를 저장하도록 장려한다. 동시에 특정 역사적 블록을 저장하는 사람이 적을수록 노드가 난이도에 맞는 nonce를 생성할 때 경쟁자가 적어 POW 경쟁에서 선점을 할 수 없다. 마지막으로 Arweave 노드가 데이터를 영구적으로 저장하도록 하기 위해 WildFire 노드 평가 메커니즘을 도입했다. 노드 간에는 더 많은 역사적 데이터를 빠르게 제공할 수 있는 노드와 통신을 선호하며, 평가 등급이 낮은 노드는 종종 최신 블록과 거래 데이터를 즉시 얻지 못해 POW 경쟁에서 선점을 할 수 없다.
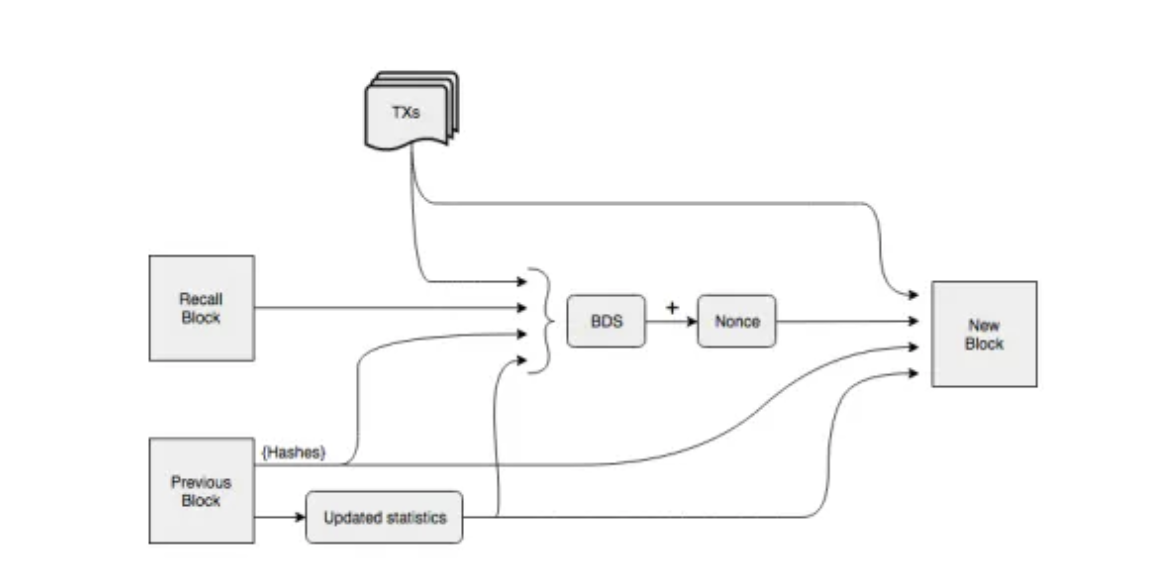
Arweave 블록 구성 방식, 출처: Arweave Yellow-Paper
5. 종합 비교
다음으로 DA 성능 지표의 네 가지 차원에서 5가지 저장 방안의 장단점을 비교하겠다.
-
보안성: 데이터 보안 문제의 가장 큰 원인은 데이터 전송 중 유실과 신뢰할 수 없는 노드의 악의적 조작이다. 교차 체인 과정에서는 두 공용 블록체인의 독립성과 상태 공유 불가로 인해 데이터 전송 보안이 가장 취약하다. 또한 현재 전용 DA 계층이 필요한 Layer1은 일반적으로 강력한 합의 그룹을 갖고 있어 자체 보안성이 일반 저장 공용 블록체인보다 훨씬 높다. 따라서 메인 체인 DA 방안은 더 높은 보안성을 갖는다. 데이터 전송 보안을 확보한 후 다음은 호출 데이터 보안을 보장하는 것이다. 거래 검증용 단기 역사적 데이터만 고려한다면 일시 저장 네트워크에서 동일한 데이터가 전망 공동 백업을 받는 반면 댕크샤딩 유사 방안에서 데이터 평균 백업 수량은 전망 노드 수의 1/N만 된다. 더 많은 데이터 중복은 데이터 유실 가능성을 낮출 뿐만 아니라 검증 시 더 많은 참고 샘플을 제공할 수 있다. 따라서 일시 저장은 상대적으로 더 높은 데이터 보안성을 갖는다. 제3자 DA 방안에서 메인 체인 전용 DA는 메인 체인과 공용 노드를 사용하므로 교차 체인 과정에서 데이터를 이러한 리레이 노드를 통해 직접 전송할 수 있어 다른 DA 방안보다 상대적으로 더
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News












