月の裏側 MoBA コア開発者による告白:「新米大規模モデル訓練士」の三度の思過崖への入山
TechFlow厳選深潮セレクト
月の裏側 MoBA コア開発者による告白:「新米大規模モデル訓練士」の三度の思過崖への入山
「オープンソースの論文やオープンソースのコードから始まり、今やオープンソースの思考プロセスへと進化したのだ!」
著者:アンドリュー・ルー、晩点チーム

画像提供元:無界AI生成
2月18日、KimiとDeepSeekが同じ日にそれぞれMoBAとNSAという新たな進展を発表した。いずれも「アテンション機構」(Attention Mechanism)の改良に関するものである。
本日、MoBAの主要な開発メンバーであるアンドリュー・ルー氏が知乎に投稿し、「三度の思過崖」と称して開発過程での3回の失敗談を語った。彼の知乎プロフィールには「新米LLMトレーナー」と記されている。
この回答に対するあるコメントはこう述べている。「オープンソースの論文、オープンソースのコードから始まり、今やオープンソースの思考チェーンへと進化したのか」。
アテンション機構が重要視されるのは、現在の大規模言語モデル(LLM)における中核的メカニズムだからである。2017年6月にLLM革命の幕を開けたTransformerの8人著者による論文のタイトルは「Attention Is All You Need」(アテンションこそすべて)であり、その引用回数はすでに15.3万回に達している。
アテンション機構により、AIモデルは人間のように情報を処理する際に何に「重点的に注目」すべきか、何を「無視」すべきかを判断でき、情報の中で最も重要な部分を捉えることができる。
大規模モデルの学習フェーズおよび使用(推論)フェーズにおいて、アテンション機構は常に機能する。その基本的な動作原理は、例えば「私はリンゴが好きだ」といったデータ入力に対して、大規模モデルが文中の各単語(Token)同士の関係性を計算し、意味情報を理解することにある。
しかし、大規模モデルが扱うべきコンテキストが長くなるにつれ、標準Transformerが当初採用していたFull Attention(全アテンション)は計算リソースの消費が耐え難いものとなる。なぜなら、本来のプロセスではすべての入力トークンの重要性スコアを完全に計算し、重み付け後に最も重要な単語を特定しなければならず、計算複雑度はテキストの長さに伴って平方的に(非線形に)増加するためである。MoBA論文の「概要」に記された通り:
「従来のアテンション機構に内在する計算複雑度の二乗的増加は、到底受け入れがたい計算コストを生じる。」
一方で、研究者たちは大規模モデルがより長いコンテキストを処理できるようになることを追求している。多段階対話、複雑な推論、記憶能力など、AGIに求められるこれらの特性はすべて、非常に長いコンテキスト処理能力を必要とする。
したがって、計算資源やメモリの消費を抑えつつ、モデル性能を損なわないアテンション機構の最適化手法を見つけることが、大規模モデル研究の重要な課題となっている。
これが複数の企業が「アテンション」技術に注目を集める背景である。
DeepSeek NSAおよびKimi MoBAに加えて、今年1月中旬には中国のもう一つの大規模モデルスタートアップMiniMaxも、初のオープンソースモデルMiniMax-01において新しいアテンション機構を大規模に実装した。当時のMiniMax創業者闫俊傑氏は、これがMiniMax-01最大の革新点の一つだと語っている。
また、面壁智能の共同創業者で清華大学計算機科学部准教授の劉知遠氏のチームも2024年にInfLLMを発表しており、これも疎アテンションの改良に関わるもので、NSAの論文でも引用されている。
これらいくつかの成果のうち、NSA、MoBA、InfLLMのアテンション機構はいずれも「スパースアテンション機構」(Sparse Attention)に分類される。一方、MiniMax-01の試みは主に別の方向性である「線形アテンション機構」(Linear Attention)に位置づけられる。
SeerAttentionの著者の一人であり、マイクロソフトアジア研究所の上級研究員である曹士傑氏によると、全体として線形アテンション機構は標準アテンション機構に対してより多くの変更を加え、より急進的であり、テキスト長の増加に伴う計算量の二乗爆発(ゆえに非線形)問題を直接解決しようとする。ただし、その代償として、長コンテキスト内の複雑な依存関係の捉え損ねの可能性がある。一方、スパースアテンション機構はアテンションが持つ固有の疎性を利用し、より安定した最適化方法を探求するものである。
同時に、曹士傑氏が知乎上でアテンション機構について高評価を得た回答もおすすめする:https://www.zhihu.com/people/cao-shi-jie-67/answers
(彼は「梁文鋒氏が共著したDeepSeekの新論文NSAアテンション機構について、注目すべき点は何ですか?どのような影響を与えるでしょうか?」という質問に回答している。)
MoA(Mixture of Sparse Attention)の共著者であり、清華大学NICS-EFC研究所の博士課程学生である傅天予氏は、スパースアテンション機構の大枠の中で次のように述べている。「NSAとMoBAはどちらも動的アテンション方式を導入しており、細粒度アテンション計算が必要なKV Cacheブロックを動的に選択できる。静的アプローチを用いる他のスパースアテンション機構と比べてモデル性能を向上させることができる。さらに、両手法とも推論時ではなく、学習フェーズからすでにスパースアテンションを導入しており、これによりさらなる性能向上を実現している。」
(注:KV Cacheブロックとは、過去に計算されたKeyラベルとValue値を保存するキャッシュである。Keyラベルはアテンション計算中に、データの特徴や位置などの情報を識別するためのタグであり、アテンション重み計算時に他のデータと照合・関連付けるために用いられる。Value値はKeyラベルに対応し、通常は単語やフレーズの意味ベクトルなど、実際に処理すべきデータ内容を含んでいる。)
また、今回の月之暗面は詳細なMoBA技術論文を公開するだけでなく、GitHub上のプロジェクトページでもMoBAのエンジニアリングコードを公開している。この一連のコードは、月之暗面自社製品Kimiで1年以上オンライン運用されてきたものである。
アンドリュー・ルーによる開発秘話
章明星先生(清華大学助教)のご招待を受け、MoBA開発の波乱に満ちた道のり、つまり私が「三度の思過崖」と呼ぶ体験を共有させていただく。(アンドリュー・ルー氏が答えた質問は「Kimiがオープンソース化したスパースアテンションフレームワークMoBAをどう評価しますか?DeepSeekのNSAと比較して、それぞれの強みは何ですか?」)
MoBAの始まり
MoBAプロジェクトは非常に早く、2023年5月末、月之暗面設立直後から始まった。入社初日にTim(月之暗面共同創業者周昕宇)に小さな部屋に呼び出され、裘先生(浙江大学/之江実験室 裘捷中、MoBAアイデアの提唱者)およびDylan(月之暗面研究員)とともにLong Context Training(長コンテキスト学習)に着手した。まずTimの忍耐強く丁寧な指導に感謝したい。LLM初心者である私に大きな期待を寄せ、育ててくれたこと。さまざまなモデルおよび関連技術の開発に携わる多くの先輩たちも、私と同じようにほぼゼロからのスタートだった。
当時は業界全体の水準もそれほど高くなく、一般的には4Kの事前学習(モデルが処理可能な入出力長が約4000トークン、数千漢字程度)が主流だった。プロジェクトの初期名称は16K on 16Bで、16B(160億パラメータ)モデル上で16K長のPre-train(事前学習)を可能にするというものだった。だがその後すぐに、8月には128KでのPre-trainに対応する必要が出てきた。これがMoBA設計の最初の要求事項となった。すなわち、Continue Training(既存モデルの継続学習)なしに、128K長に対応するモデルをFrom Scratch(ゼロから)迅速に学習できるようにすることである。
ここから興味深い問題が浮かび上がる。2023年5~6月頃、業界では長文を端から端まで(エンドツーエンド)で直接学習する方が、短いモデルを学習した後で何らかの方法で延長するよりも効果が高いと考えられていた。この認識は、2023年後半にMetaが開発した長文処理対応の大規模モデル「long Llama」の登場によって初めて変わることになった。我々自身も厳密に検証した結果、短文学習+長さアクティベーションの方が、より高いtoken efficiency(各トークンあたりの有効情報量の向上、つまり少ないトークンでより高品質なタスクを達成できる)を持つことが判明した。そのため、MoBA設計の最初の機能は時代の流れに取り残されることになった。
この時期のMoBA構造は、現在の「極簡化」された結果と比べてさらに「急進的」なものだった。当初提案されたMoBAは、cross attention(異なる2つのテキストデータ間の関係を処理するアテンション機構)を備えた2層アテンション機構の直列接続方式であり、gate(各エキスパートネットワークへの入力データの重み配分を制御する構造)自体は無パラメータ構造(パラメータを持たず、学習不要)であった。しかし、過去のトークンをよりよく学習するために、各Transformer層に機械間のcross attentionと対応するパラメータを追加した(歴史的情報をよりよく記憶できるようになる)。この時点でのMoBA設計には、後に広く知られるようになるContext Parallel(完全なコンテキストシーケンスを異なるノードに分散し、計算時に集中させる)の考え方も統合されていた。すなわち、コンテキスト全体をデータ並列ノード間に平滑に配置し、各ノード内のコンテキストをMoE(Mixture of Experts、エキスパート混合システム)のexpert(エキスパート)と見なし、アテンションが必要なトークンを対応するエキスパートに送信してcross attentionを行い、結果を通信で戻すという方式である。我々は早期のMoE学習フレームワークであるfastmoeをMegatron-LM(NVIDIA由来の現在一般的な大規模モデル学習フレームワーク)に統合し、エキスパート間の通信機能をサポートした。
この考え方を我々はMoBA v0.5と呼んでいる。
(編集注:MoBAの着想は現在主流の大規模モデルMoE構造に由来する。MoEとは、大規模モデルが動作する際、すべてのエキスパートパラメータを活性化するのではなく、一部のみを活性化することで計算リソースを節約するものである。MoBAの核心的な発想は「すべてのコンテキストを見るのではなく、最も関連性の高い部分だけを見るようにすることで、計算とコストを節約する」ことにある。)
時が2023年8月初めに進むにつれ、メインモデルのPre-trainは多数のトークンをすでに学習しており、再実行には高コストがかかることになった。構造を大幅に変更し、追加パラメータを導入したMoBAは、ここで初めて「思過崖」に入った。
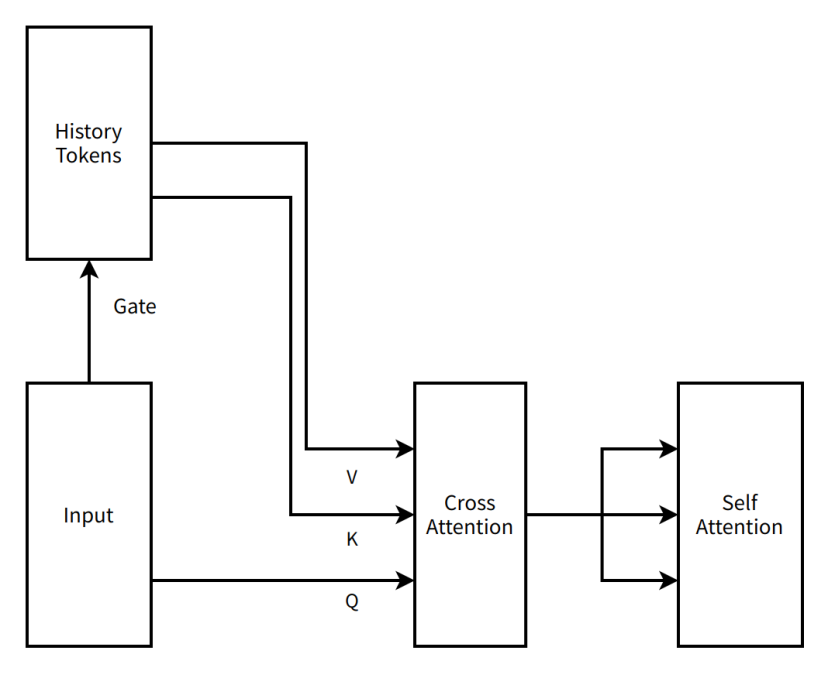
非常にシンプルなMoBA v0.5の概念図
編集注:
History Tokens(履歴トークン)――自然言語処理などの場面で、以前に処理されたテキストユニットの集合を表す。
Gate(ゲート)――ニューラルネットワーク内で情報の流れを制御する構造
Input(入力)――モデルが受信するデータまたは情報
V(Value)――アテンション機構内で、実際に処理または注目すべきデータ内容(例:意味ベクトルなど)を含む
K(Keyラベル)――アテンション機構内で、データの特徴や位置などの情報を識別するためのタグ。他のデータとの照合・関連付けに用いられる
Q(Queryクエリ)――アテンション機構内で、キー・バリューペアから関連情報を検索するためのベクトル
Cross Attention(クロスアテンション)――異なるソースからの入力を注目対象とするアテンション機構。例:入力と履歴情報の関連付け
Self Attention(セルフアテンション)――アテンション機構の一形態で、モデルが自身の入力に注目し、内部の依存関係を捉える
一回目の思過崖
「思過崖」に入るというのはもちろん冗談であり、改善案を考える時間であり、新構造を深く理解する時間でもある。初めての「悟り」は入りが早く、出も早かった。月之暗面のアイデアマンTimが新たな改善案を提示し、MoBAを2層アテンションの直列方式から単層アテンションの並列方式に変更した。MoBAは追加のモデルパラメータを増やさず、既存のアテンション機構パラメータを活用して、シーケンス内のすべての情報を同時に学習することで、現在の構造をできる限り変えずにContinue Trainingを可能にした。
この考え方はMoBA v1と呼ばれる。
MoBA v1は実質的にSparse Attention(スパースアテンション)とContext Parallelの融合産物であり、当時Context Parallelが主流ではなかった中で、MoBA v1は非常に高いエンドツーエンド加速能力を示した。3B、7Bモデルで有効性を確認した後、より大きなスケールのモデルで壁にぶつかった。学習中に非常に大きなloss spike(学習中の異常現象)が発生したのである。当初のblock attention output(アテンションモジュールがデータ処理後に生成する出力)のマージ方法が単純すぎ、単に足し合わせるだけだったため、Full Attentionとの正確なデバッグができず、ground truth(正解、ここではFull Attentionの結果)なしのデバッグは極めて困難だった。当時のあらゆる安定化手段を尽くしても解決できず、大規模モデルでの学習問題により、MoBAはここに至って二度目の「思過崖」に入った。
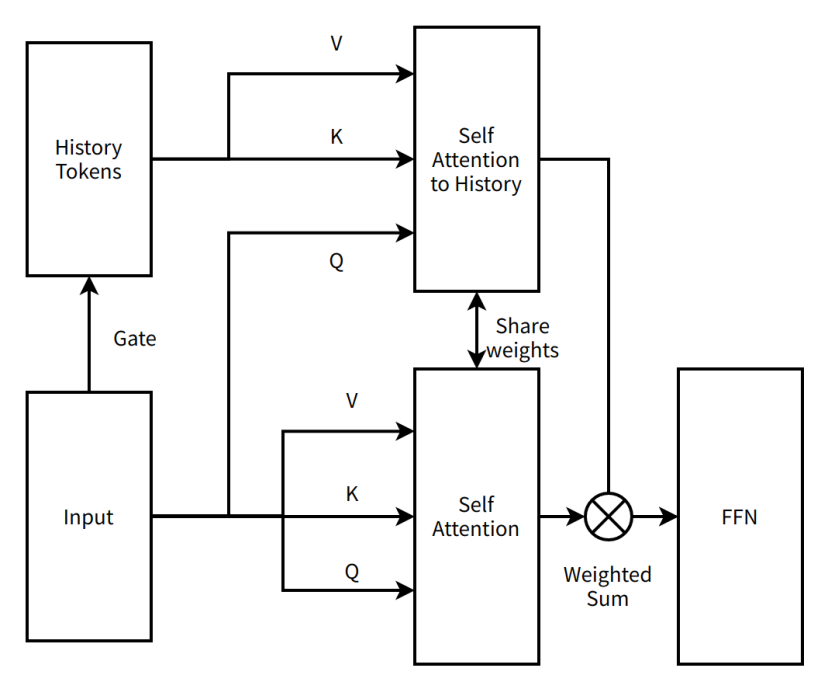
非常にシンプルなMoBA v1の概念図
編集注:
Self Attention to History(履歴へのセルフアテンション)――モデルが履歴トークンに注目し、現在の入力と履歴情報の間の依存関係を捉えるアテンション機構
Share weights(重み共有)――ニューラルネットワークの異なる部分が同じ重みパラメータを使用し、パラメータ数の削減とモデルの汎化能力向上を図る
FFN(Feed-Forward Neural Network、順伝播型ニューラルネットワーク)――データが入力層から隠れ層を経て出力層へ一方向に流れる基本的なニューラルネットワーク構造
Weighted Sum(加重和)――複数の値をそれぞれの重みに従って合計する操作
二回目の思過崖
二度目の「思過崖」滞在期間は長く、2023年9月から始まり、脱出時にはすでに2024年初頭になっていた。しかし「思過崖」にいる間も放棄されたわけではなく、月之暗面での仕事のもう一つの特徴である「飽和救援」を体感できた。
常に強力なアウトプットを出すTimと裘先生に加え、蘇神(蘇剣林、月之暗面研究員)、遠哥(Jingyuan Liu、月之暗面研究員)など多くの著名な研究者たちが激しい議論に参加し、MoBAの分解と修正を始めた。まず修正されたのは、単純なWeighted Sum(加重和)の積み重ね方であった。Gate Matrixとの乗算・加算のさまざまな組み合わせを試した後、Timが古文書の中からOnline Softmax(すべてのデータを見てから計算するのではなく、来るデータごとに逐次処理する)を取り出し、「これならうまくいくはずだ」と言った。最大の利点は、Online Softmaxを使用することで、疎度を0に下げ(すべてのブロックを選択)することで、数学的に等価なFull Attentionと厳密に比較・デバッグできるようになった点であり、これにより実装上の大部分の難題が解決された。しかし、コンテキストをデータ並列ノード間に分割する設計自体が依然として不均衡問題を引き起こした。あるデータサンプルがデータ並列に均等に分配された後、最初のデータ並列rank上の最初の数トークンが、その後の膨大なQからのattend(アテンション計算)を受けることになり、極めて悪いバランスとなり、加速効率が低下した。この現象はより広く知られており、「Attention Sink(アテンションシンク)」と呼ばれる。
このとき章先生が訪問し、私たちの考えを聞いた上で新たなアイデアを提案した。Context Parallel機能とMoBAを切り離すことである。Context ParallelはContext Parallel、MoBAはMoBAとして、MoBAを分散型スパースアテンション学習フレームワークではなく、スパースアテンションそのものに戻す。メモリに収まる限り、単一マシンで完全なコンテキストを処理し、MoBAで計算を高速化し一方で、Context Parallel方式で機械間のコンテキストを整理・伝達する。これにより、MoBA v2を再実装し、現在皆が目にしているMoBAの姿にほぼ到達した。
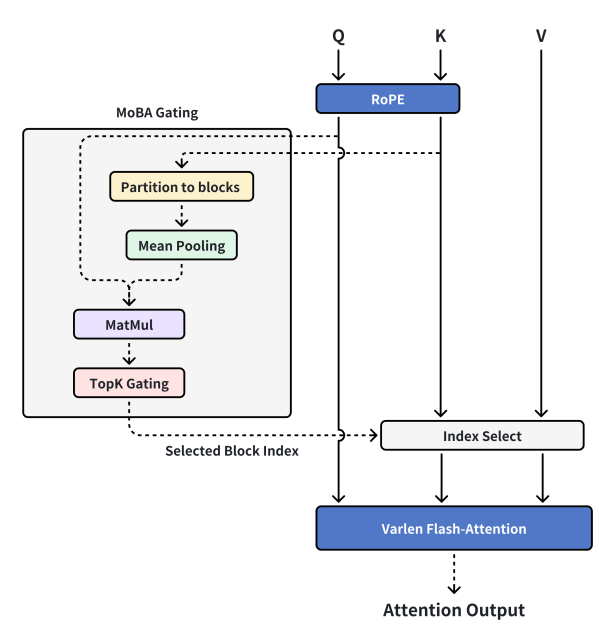
現在のMoBA設計
編集注:
MoBA Gating(MoBAゲーティング)――MoBAに特有のゲート制御機構
RoPE(Rotary Position Embedding 回転位置埋め込み)――シーケンスに位置情報を付加する技術
Partition to blocks(ブロック分割)――データを異なるブロックに分割すること
Mean Pooling(平均プーリング)――ディープラーニングでデータをダウンサンプリングする操作の一種。領域内のデータ平均値を計算
MatMul(Matrix-Multiply 行列乗算)――2つの行列の積を計算する数学演算
TopK Gating(Top-Kゲーティング)――上位K個の重要な要素を選択するゲート制御機構
Selected Block Index(選択されたブロックインデックス)――選ばれたブロックの番号を示す
Index Select(インデックス選択)――インデックスに基づいてデータから対応要素を選択
Varlen Flash-Attention(可変長フラッシュアテンション)――可変長シーケンスに適用可能で計算効率の高いアテンション機構
Attention Output(アテンション出力)――アテンション機構の計算後の出力結果
MoBA v2は安定して学習可能で、短文においてFull Attentionと完全に一致し、Scaling Lawも非常に信頼できるように見え、オンラインモデルへのスムーズな展開も可能になった。そこでさらに多くのリソースを投入し、一連のデバッグを経て、infraチームの仲間たちの髪の毛を何本も失った後、MoBAでアクティベートされたPretrainモデルが「針探しテスト」で完全に合格(大規模モデルの長文処理能力テストで基準達成)するまでに至った。この時点で非常に良好だと感じ、本番環境への展開を開始した。
しかし最も予期せぬことに、意外が起きた。SFT(監督付きファインチューニング。事前学習モデルをベースに特定タスク向けにさらに訓練し、性能を向上させる)フェーズで、一部のデータには非常に疎なloss mask(わずか1%以下しか勾配計算に使われないトークン)が含まれていた(loss maskとは、モデル予測結果と正解との誤差計算にどの部分を含めるかを指定する技術)。これによりMoBAはほとんどのSFTタスクで良好な性能を示したが、特に長文要約タイプのタスクではloss maskがますます疎になり、学習効率が著しく低下した。MoBAは本番導入プロセスで一時停止され、三度目の「思過崖」に入った。
三回目の思過崖
三度目の「思過崖」に入ったときは最も緊張した。プロジェクト全体ですでに莫大な固定費用が発生しており、会社は大量の計算資源と人的資源を投入していた。もし最終的にエンドツーエンドの長文アプリケーションで問題が起きれば、前期の研究はほとんど水の泡になる。幸運にも、MoBA自体が優れた数学的性質を持っていたため、新たな「飽和救援」による消滅実験(ablation、モデルの特定部分を除去または変更してその影響を調べる)の結果、loss maskを外すと非常に良好に動作し、逆にloss maskを付けると性能が芳しくないことが判明した。つまり、SFTフェーズで勾配(gradient、機械学習でモデルパラメータを更新する方向とステップサイズを示す値)を持つトークンが極めて疎であることが、学習効率の低下を引き起こしていると気づいた。そこで最終数層をFull Attentionに変更することで、バックプロパゲーション時の勾配トークン密度を高め、特定タスクの学習効率を改善した。その後の他の実験でも、この切り替えは切り戻されたスパースアテンションの効果に有意な影響を与えず、1M(100万)長のシーケンスにおいても同構造のFull Attentionと同等の指標を達成した。MoBAは再び「思過崖」から帰還し、ユーザーへのサービス提供に成功した。
最後に、多くの偉大な研究者たちの支援に感謝し、会社の全面的なサポートと膨大なGPUリソースに感謝する。今回公開するのは、我々が本番環境で実際に使用してきたコードであり、長期にわたって検証済みで、実際のニーズに応じて余計な設計を削ぎ落とし、極簡構造を保ちながら十分な効果を持つスパースアテンション構造である。MoBAおよびその開発過程のCoT(Chain of Thought、思考チェーン)が、皆様に少しでも役立ち、価値を提供できることを願っている。
FAQ
ついでに、ここ数日頻繁に聞かれた質問に答えておく。ここ数日、章先生と蘇神にカスタマーサポートのように質問対応をしてもらい、申し訳なく思ったので、代表的な質問をまとめて回答しておく。
1. MoBAはDecoding (モデル推論フェーズのテキスト生成プロセス)には無効ですか?
MoBAはDecodingに有効であり、MHA(Multi-Head Attention、マルチヘッドアテンション)では非常に効果的であるが、GQA(Grouped Query Attention、グループ化クエリアテンション)では効果が低下し、MQA(Multi-Query Attention、マルチクエリアテンション)では最も効果が低い。原理は単純で、MHAの場合、各Qは独自のKV cacheを持つため、MoBAのgateは理想状況下でprefill(入力初回処理フェーズ)時に各block(データブロック)の代表トークンを計算・保存でき、以降は変化しない。したがってすべてのIO(入出力操作)は基本的にindex select(インデックス選択)後のKV cacheからのみ発生する。この場合、MoBAの疎性レベルがそのままIO削減レベルとなる。
しかしGQAやMQAでは、一組のQ Headが同じKV cacheを共有するため、各Q Headが自由に興味のあるBlockを選択できる状況では、疎性によるIO最適化が相殺されてしまう可能性がある。例えばこのような状況を考えよう。16個のQ Headを持つMQAで、MoBAがちょうどシーケンスを16分割した場合、最悪ケースでは各Q headがそれぞれ1~16番目のコンテキストブロックに興味を持つと、IO削減のメリットは完全に打ち消される。KV Blockを自由に選択できるQ Headが多いほど、効果は低下する。
「KV Blockを自由に選択するQ Head」という現象が存在する以上、自然な改善策は「統合」である。全員が同じBlockを選ぶようにすれば、IO最適化の恩恵を確実に得られる。確かにそうだが、実際にテストすると、特に高コストをかけて学習済みのモデルでは、各Q headが独自の「好み」を持っており、強制的に統合するよりゼロから再学習した方が良い。
2. MoBAはデフォルトでself attention(セルフアテンション機構)を必須としていますが、selfの隣接ブロックも必須ですか?
必須ではない。これは若干混乱を招く点として知られているが、最終的にはSGD(Stochastic Gradient Descent、確率的勾配降下法)を信じることにした。現在のMoBA gateの実装は非常に直接的であり、興味のある人は簡単に改造して前のchunk(データブロック)を必ず選ぶようにできるが、我々自身のテストではそのような変更による利益はわずか(margin)であった。
3. MoBAはTriton (OpenAIが開発した高性能GPUコード作成フレームワーク)で実装されていますか?
一度バージョンを実装したが、エンドツーエンドで10%以上の性能向上があったものの、Tritonの実装を継続的にメンテナンスし本流に追随するコストが非常に高いため、何度かの反復後、さらなる最適化を一旦保留した。
* 本文冒頭で言及した研究成果のプロジェクトURL(GitHubページには技術論文リンクが含まれており、DeepSeekはまだNSAのGitHubページを公開していない):
MoBA GitHubページ:https://github.com/MoonshotAI/MoBA
NSA技術論文:https://arxiv.org/abs/2502.11089
MiniMax-01 GitHubページ:https://github.com/MiniMax-AI/MiniMax-01
InfLLM GitHubページ:https://github.com/thunlp/InfLLM?tab=readme-ov-file
SeerAttention GitHubページ:https://github.com/microsoft/SeerAttention
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News