

DeepSeekがOpenAIを「盗用」?むしろ泥棒が泥棒を呼んでいるようだ
TechFlow厳選深潮セレクト
DeepSeekがOpenAIを「盗用」?むしろ泥棒が泥棒を呼んでいるようだ
蒸留は盗用ではなく、技術進化に必要な手段である。
筆者:鄧詠儀、インテリジェント・エマージェンス

画像出典:無界AI生成
2025年の春節期間中、最も話題になったのは『哪吒2』だけでなく、DeepSeekというアプリも爆発的人気を博した。その物語はすでに何度も語られている――1月20日、杭州に拠点を置くAIスタートアップ企業DeepSeek(深度求索)が新モデルR1を発表し、OpenAIの現在最強の推論モデルo1と同等の性能を達成、真に世界中を震撼させたのである。
公開からわずか一週間で、DeepSeekアプリのダウンロード数は2000万件を超え、140カ国以上で首位を記録した。その成長速度は2022年に登場したChatGPTを上回り、現在ではその約20%にまで達している。
どの程度人気なのか?2月8日時点で、DeepSeekのユーザー数はすでに1億人を超えており、AIオタクに限らず、中国から世界へと広く普及している。高齢者から子供、コメディアンから政治家まで、誰もがDeepSeekについて語っている。
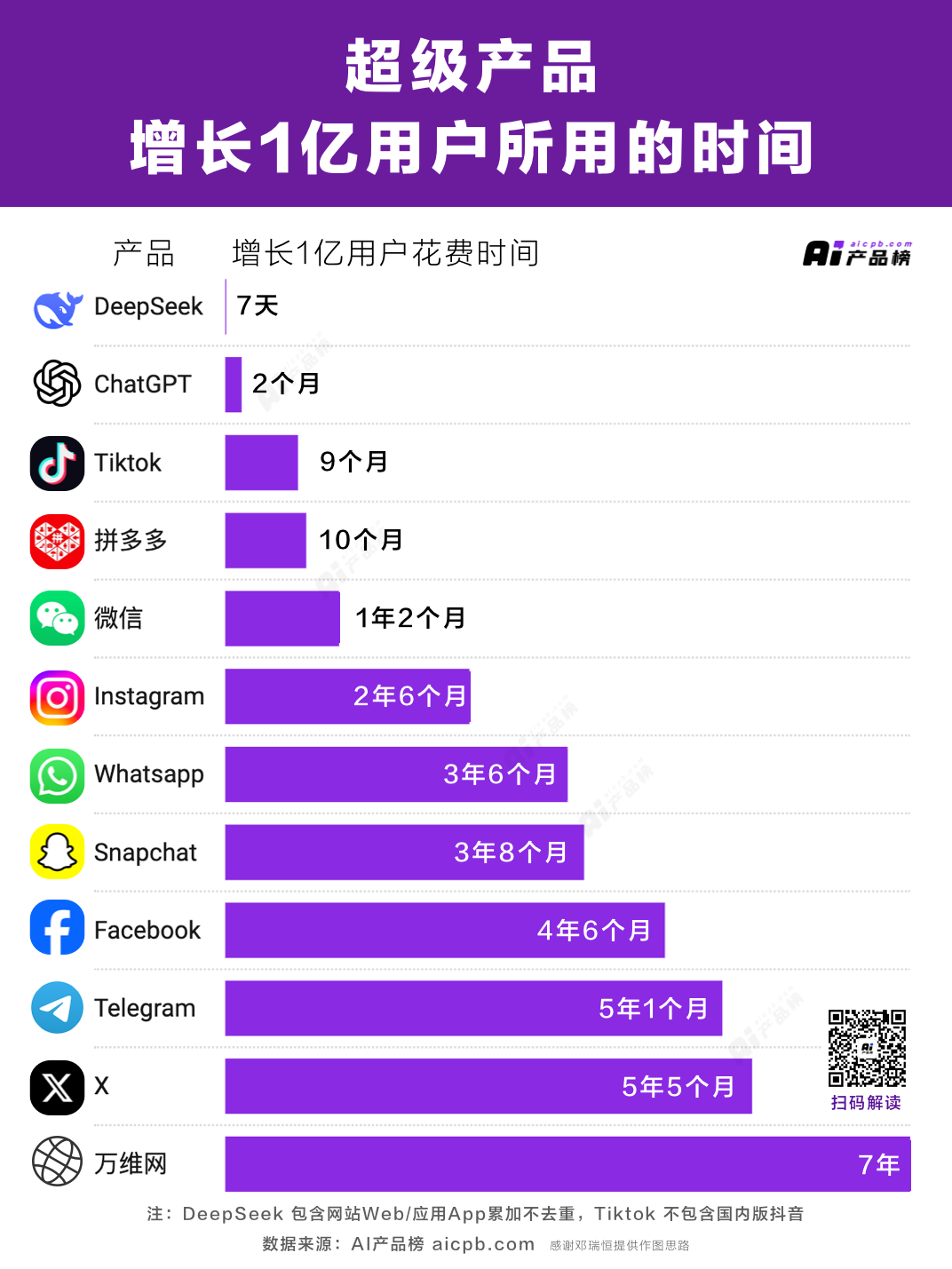
今なお、DeepSeekによる衝撃は続いている。ここ二週間で、DeepSeekはTikTokが歩んだ劇的な脚本をなぞった――爆発的成長と急激な普及により、米国の多くの競合を打ち破り、さらに地政学的な崖っぷちにまで立たされる事態となった。米国や欧州では「国家安全保障への影響」が議論され、多くの地域でダウンロードやインストールの禁止命令が迅速に発令された。
A16ZのパートナーであるMarc Andreessenは、「DeepSeekの出現は、新たな“スプートニク・モーメント”だ」と驚嘆した。
(冷戦時代の出来事に由来する表現。1957年にソ連が世界初の人工衛星「スプートニク1号」を成功裏に打ち上げ、米国社会に衝撃を与え、自国の技術的優位性が脅かされていることに気づいた瞬間を指す)
しかし、注目されればされるほど批判も増える。技術コミュニティ内でも、DeepSeekは「蒸留(蒸馏)」や「データ窃取」などの論争に巻き込まれている。
現時点において、DeepSeek側は一切公式な反応を示しておらず、この議論は極端な二極化を見せている。熱狂的な支持者はDeepSeek-R1を「国家運命レベル」の革新と称賛する一方、一部のテック業界関係者は、異常に低い訓練コストや蒸留方式に対して疑問を呈し、これらの革新が過大評価されていると指摘している。
DeepseekがOpenAIを「盗んだ」?むしろ泥棒が泥棒を非難しているようなもの
DeepSeekが注目を集めた直後から、OpenAIやマイクロソフトなどシリコンバレーの大手AI企業が次々と公に声を上げ、主にDeepSeekのデータに関する非難が集中した。米国政府のAI・暗号担当官デイビッド・サックスも公に、「DeepSeekは“蒸留”という技術を通じて、ChatGPTの知識を“吸収”している」と述べた。
英国『フィナンシャル・タイムズ』の報道によると、OpenAIはDeepSeekがChatGPTを「蒸留」している兆候を発見したとしており、これは同社のモデル利用規約に違反すると主張している。ただし、OpenAIは具体的な証拠を提示していない。
実際、この非難は根拠に欠けるものだ。
蒸留は通常の大規模モデル訓練手法の一つである。これは訓練段階でよく行われるもので、より大きく高性能なモデル(教師モデル)の出力を用いて、小型モデル(学生モデル)がより高い性能を学ぶことを可能にする。特定のタスクにおいて、小規模モデルでも低コストで類似の結果を得られるようになる。
蒸留は剽窃ではない。わかりやすく言えば、蒸留とはまるで優秀な先生がすべての難問を解き、完璧な解法ノートを作成するようなものだ。そのノートには答えだけでなく、最適な解法プロセスが詳細に記されている。普通の生徒(小規模モデル)はこのノートを直接学び、自分の解答を導き出し、先生の思考プロセスと照らし合わせて確認するのである。
DeepSeekの最大の貢献は、この過程でより多くの無監督学習を活用したことにある。つまり、人間のフィードバック(RLHF)を減らし、機械自身による自己フィードバックを促進したのだ。これにより、モデルの訓練コストが大幅に削減された――これが多くの疑念の原因ともなっている。
DeepSeek-V3の論文では、V3モデルの具体的な訓練クラスタ規模(2048枚のH800チップ)が明記されている。多くの人々が市場価格に基づき試算したところ、その費用は約550万ドル程度であり、MetaやGoogleなどのモデル訓練コストの数十分の1に過ぎない。
ただし注意すべきは、DeepSeekが論文で明言している通り、これは最終訓練ステップにおける単一実行コストにすぎず、それ以前の設備投資、人件費、訓練中の損耗などは含まれていないということだ。
AI分野において、蒸留は新しい技術ではない。多くのモデルベンダーが自社の蒸留作業を公表している。例えば、Metaは自社モデルがどのように蒸留されたかを明らかにしており、Llama 2ではより大規模で賢いモデルを用いて、思考プロセスや方法を含むデータを生成し、それを自社の小規模推論モデルに微調整として適用している。
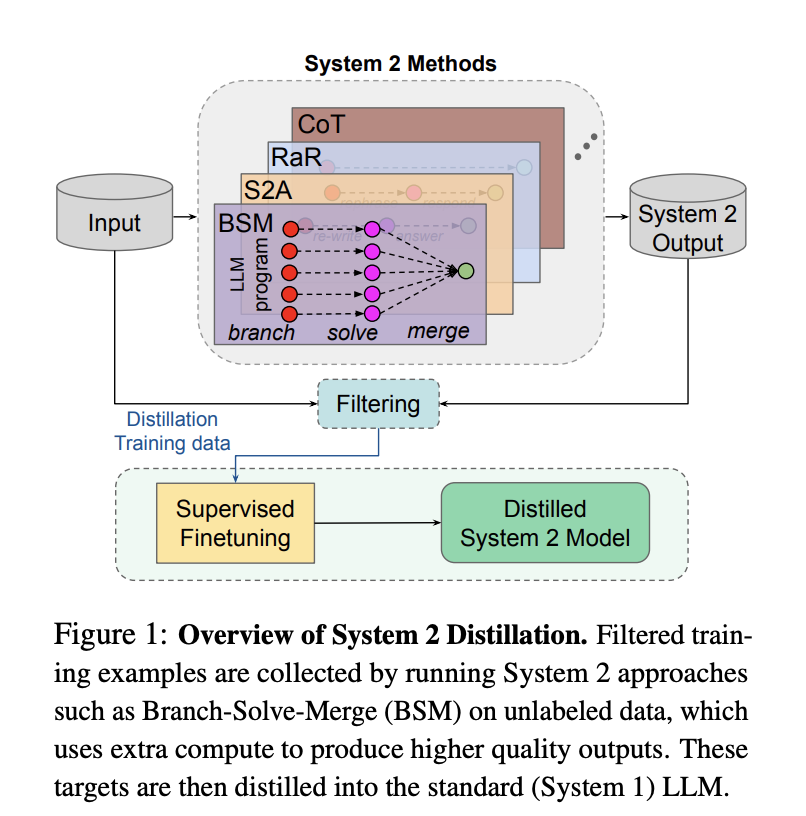
△出典:Meta FAIR
しかし、蒸留にも欠点はある。
ある大手企業のAI応用担当者は『インテリジェント・エマージェンス』に対し、蒸留によってモデルの能力は短期間で向上するが、問題は「教師モデル」が生成するデータが非常にきれいすぎて多様性に欠けることだと語った。このようなデータを学習すると、モデルはまるで画一的な「レトルト食品」のように中庸になり、その能力は決して教師モデルを上回ることはできない。
データの質はモデル訓練の成果を大きく左右する。もし大部分の訓練を蒸留に頼ってしまうと、モデルは均質化してしまう。現在、世界中の大規模モデルはすでに多数存在し、各社が自社モデルの「精鋭版」を提供している状況下で、まったく同じモデルを蒸留しても大きな意味はない。
さらに深刻な問題は、幻覚(ハルシネーション)問題が悪化する可能性があることだ。小規模モデルは大規模モデルの「表面」だけを模倣しており、背後の論理を深く理解できていないため、新しいタスクでのパフォーマンスが低下しやすい。
そのため、モデルに独自性を持たせるには、AIエンジニアがデータ段階から介入する必要がある。どのようなデータを選ぶか、データの比率、訓練方法などが、最終的に完成するモデルの性質を大きく変える。
典型的な例が現在のOpenAIとAnthropicである。OpenAIとAnthropicはシリコンバレーで最初期に大規模モデル開発に取り組んだ企業だが、双方とも蒸留可能な既存モデルがなかったため、公開ネットやデータセットから直接データを収集・学習した。
異なる学習経路により、両モデルのスタイルには明確な違いが生まれている――現在のChatGPTは堅実な理系学生のような存在で、生活や仕事のさまざまな課題解決に長けている。一方Claudeは文系分野に強く、文章作成タスクでは定評があり、コード処理も劣らない。
OpenAIの非難の皮肉な点は、境界があいまいな条項でDeepSeekを責めていることにある。なぜなら彼ら自身も同様のことをしているからだ。
設立当初、OpenAIはオープンソース志向の組織だったが、GPT-4以降はクローズドソースに転換した。OpenAIの訓練データはほぼ全世界の公開インターネットから収集されている。このため、クローズドソース化後に新聞メディアや出版社との著作権訴訟に長年悩まされている。
OpenAIがDeepSeekの「蒸留」を非難することに対する風刺は、「泥棒が泥棒を非難している」という点にある。OpenAIのo1もDeepSeekのR1も、いずれの論文においてもデータ準備の詳細を明かしておらず、この問題は依然として「羅生門」状態なのである。
ましてや、DeepSeek-R1は発表時にMITライセンスを採用している――ほぼ最も緩やかなオープンソースライセンスである。DeepSeek-R1は商用利用を許可し、蒸留も認め、さらに一般向けに6つの蒸留済み小型モデルを提供しており、スマートフォンやPCに直接展開できるよう配慮している。これはオープンソースコミュニティへの誠意ある還元と言える。
2月5日、元Stability AI研究責任者のTanishq Mathew Abraham氏も専門記事を執筆し、この非難はグレーゾーンにあると指摘した。まず、OpenAIはDeepSeekが直接GPTを用いて蒸留したという証拠を出していない。彼が推測する可能性の一つは、DeepSeekが市販されているChatGPT生成データセットを利用したというものだが、これはOpenAIが明確に禁止しているわけではない。
蒸留はAGIをやるかどうかの判断基準なのか?
世論では、最近「蒸留を行うかどうか」をもって、コピーかどうか、AGI開発をしているかどうかを判断しようとする傾向があるが、それはあまりに短絡的だ。
DeepSeekの活動は「蒸留」という概念を再び注目させたが、実はこれは約10年前から存在する技術である。
2015年、AIの重鎮であるHinton、Oriol Vinyals、Jeff Deanらが共同で発表した論文『Distilling the Knowledge in a Neural Network』にて、大規模モデルにおける「知識蒸留」技術が正式に提唱され、その後の大規模モデル分野の標準的手法となった。
特定の領域やタスクに特化したモデルベンダーにとって、蒸留はより現実的なアプローチである。
あるAI関係者が『インテリジェント・エマージェンス』に語ったところによると、中国国内の大規模モデルベンダーで蒸留を行っていない企業はほとんどなく、これは公開の秘密に近い。「現在、公開ネット上のデータはほぼ枯渇しており、ゼロからプリトレーニングを行い、データにラベル付けするコストは、大手企業であっても簡単に負担できるものではない」。
例外は字節跳動(バイテッド)である。最近リリースされたDouBao 1.5 Proバージョンにおいて、同社は「訓練中に他のモデルが生成したデータは一切使用せず、決して蒸留という近道を選ばない」と明言し、AGI達成への決意を示した。
大手企業が蒸留を避けるのには現実的な理由がある。たとえば、将来的なコンプライアンス紛争を回避できることや、クローズドソースの前提でモデル能力に一定の壁を築けることなどだ。『インテリジェント・エマージェンス』が把握するところ、字節跳動の現在のデータラベリングコストはシリコンバレー並み――最高で1件あたり200ドルに達している。このような高品質データには、修士や博士以上の専門家レベルの人材が、それぞれの専門分野でラベリング作業を行う必要がある。
AI分野の多くの参加者にとって、蒸留を使うか他の工学的手法を使うかは、本質的にScaling Law(規模効果則)の限界を探ることに他ならない。これはAGI探索の必要条件ではあるが、十分条件ではない。
大規模モデルがブームになった初期2年間、Scaling Lawは単純に「計算力投入=奇跡の発生」と解釈されていた。つまり、計算リソースとパラメータを積み上げれば知能が出現するという考えで、これは主にプリトレーニング段階にあたる。
現在「蒸留」が注目される背景には、大規模モデルの発展パラダイムが変化しているという隠れた流れがある。つまり、Scaling Lawは依然有効だが、その重心がプリトレーニング段階から、ポストトレーニングおよび推論段階へと移行しているのである。
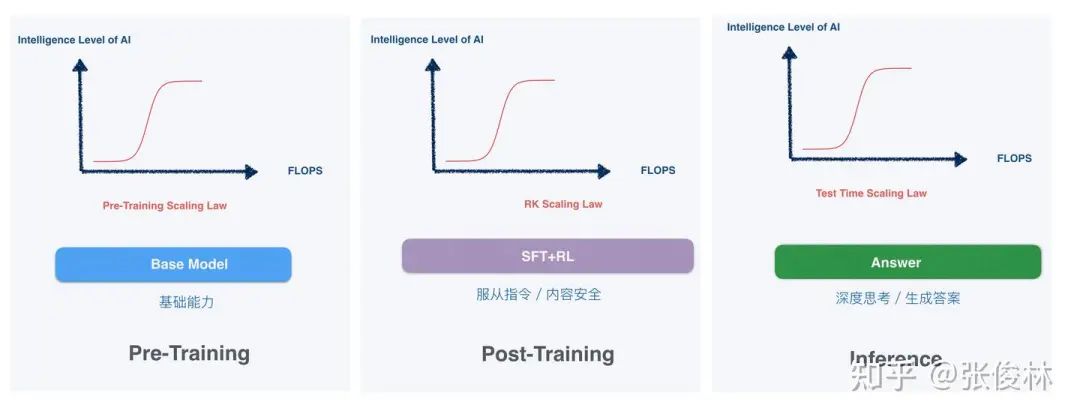
△出典:中国科学院ソフトウェア研究所 張俊林博士のコラム記事
OpenAIのo1は2024年9月に発表され、Scaling Lawがポストトレーニングおよび推論段階へ移行した象徴とされており、現在も世界最高峰の推論モデルと見なされている。しかし問題は、OpenAIが訓練方法や詳細を一切公開しておらず、利用コストも依然高いままであることだ。o1 proの月額コストは200ドルに達し、推論速度も遅く、AIアプリケーション開発の大きな障壁とされている。
最近のAIコミュニティの研究の多くは、o1の効果を再現しつつ、推論コストを下げることに集中している。これにより、より多くのシーンへの応用が可能になる。DeepSeekの画期的な意義は、オープンソースモデルが最先端のクローズドソースモデルに追いつくまでの時間を大きく短縮しただけでなく(わずか3ヶ月程度でo1の複数指標をほぼ達成)、o1の能力飛躍の鍵となる技術を発見し、それをオープンソース化した点にある。
見逃せない大きな前提は、DeepSeekの革新は巨人の肩の上に立って成し遂げられたということだ。単に「蒸留」などの工学的手法を近道と見なすのは狭隘すぎる。これはむしろ、オープンソース文化の勝利である。
DeepSeekがもたらしたエコシステムの共栄とオープンソース効果は、すでに急速に現れている。話題になってすぐ後、いわゆる「AIの母」李飛飛の新たな研究が瞬く間に話題となった。Google傘下のGeminiを「教師モデル」とし、微調整されたアリババのQwen2.5を「学生モデル」として、蒸留などの手法を用い、50ドル未満の費用で推論モデルs1を訓練し、DeepSeek-R1およびOpenAI-o1のモデル能力を再現したのである。
NVIDIAも典型的な例だ。DeepSeek-R1発表後、同社の時価総額は一夜にして約6000億ドルも暴落し、史上最大の単日減少額を記録した。しかし翌日にはすぐに反発し、約9%上昇した――市場はR1がもたらす強力な推論需要に依然として期待を寄せている。
予想されるのは、大規模モデル各社がR1の能力を取り込んだ後、AIアプリケーションの革新の波が到来することだろう。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













