

同質化AIインフラの出口はどこにあるのか?
TechFlow厳選深潮セレクト
同質化AIインフラの出口はどこにあるのか?
本研究は、開発者にとってどの人工知能分野が最も重要であるか、およびWeb3と人工知能の分野において次にブレークする可能性のある機会が何であるかを考察することを目的としている。
執筆:IOSG Ventures
Zhenyang@Upshot、Fran@Giza、Ashely@Neuronets、Matt@Valence、Dylan@Pond のフィードバックに感謝します。
本研究は、開発者にとって最も重要なAI分野と、Web3およびAI分野における次なる爆発的機会の可能性を探ることを目的としています。
新たな調査結果を共有する前に、まず私たちがRedPillの総額500万ドルの初回資金調達に参加できたことを嬉しく思います。今後、RedPillとともに成長していけることに非常に期待しています!

TL;DR
Web3とAIの融合が暗号資産界隈で注目を集める中、暗号世界におけるAIインフラの構築が盛んになっていますが、実際にAIを利用またはAI向けのアプリケーションはそれほど多くありません。また、AIインフラの同質化問題も徐々に顕在化しています。最近私たちが参加したRedPillの初回資金調達を通じて、より深い理解を得ることができました。
-
AI Dapp構築の主なツールには、分散型OpenAIアクセス、GPUネットワーク、推論ネットワーク、エージェントネットワークがあります。
-
「ビットコイン採掘時代」よりもGPUネットワークが人気な理由は、AI市場がより大きく、急速かつ安定的に成長していること。毎日数百万ものアプリケーションを支えていること。多様なGPUモデルとサーバー所在地が必要であること。技術が以前より成熟していること。対象となる顧客層が広いことです。
-
推論ネットワークとエージェントネットワークは似たインフラを持ちますが、焦点は異なります。推論ネットワークは経験豊富な開発者が独自モデルを展開することを主に対象としており、LLM以外のモデルを実行する場合、必ずしもGPUが必要ではありません。一方、エージェントネットワークはLLMに特化しており、開発者は自前のモデルを持たず、プロンプトエンジニアリングや複数エージェントの連携に重点を置きます。エージェントネットワークでは常に高性能GPUが必要です。
-
AIインフラプロジェクトは大きな可能性を秘めており、継続的に新機能をリリースしています。
-
多くのネイティブ暗号プロジェクトはまだテストネット段階にあり、安定性に欠け、設定が複雑で機能制限があり、安全性とプライバシーの証明にはまだ時間がかかります。
-
もしAI Dappが大きなトレンドになるなら、監視、RAG関連インフラ、Web3ネイティブモデル、組み込み暗号ネイティブAPIおよびデータを持つ分散型エージェント、評価ネットワークなど、未開拓の領域が多数存在します。
-
垂直統合は顕著な傾向です。インフラプロジェクトは一括サービスを提供し、AI Dapp開発者の作業を簡素化しようとしています。
-
将来はハイブリッド型になります。一部の推論はフロントエンドで、一部はオンチェーンで計算されます。これによりコストと検証可能性の両方を考慮できます。
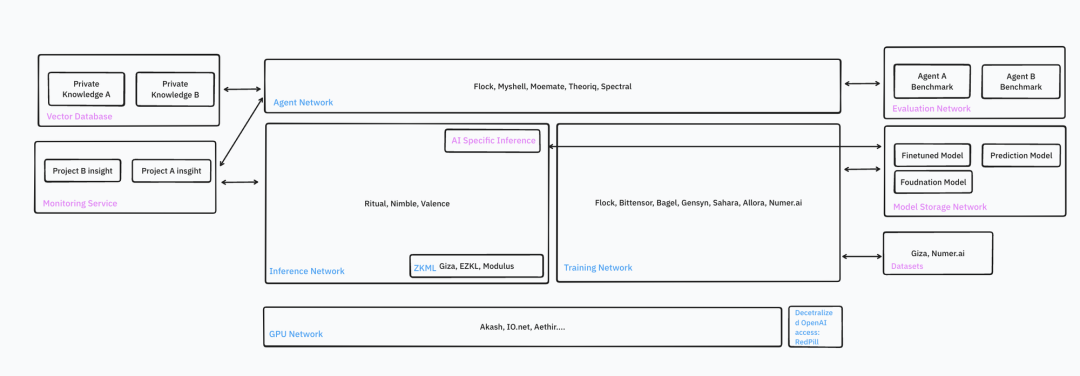
出典: IOSG
はじめに
-
Web3とAIの融合は、現在の暗号分野で最も注目されている話題の一つです。優れた開発者たちが暗号世界にAIインフラを構築し、スマートコントラクトに知能をもたらそうとしています。AI dAppの構築は極めて複雑なタスクであり、開発者はデータ、モデル、計算力、運用、展開、ブロックチェーンとの統合など幅広い範囲を扱う必要があります。これらのニーズに対応して、Web3起業家たちはGPUネットワーク、コミュニティによるデータアノテーション、コミュニティで訓練されたモデル、検証可能なAI推論と訓練、エージェントストアなどの初期ソリューションを開発してきました。
-
しかし、この活発なインフラ整備の裏で、実際にAIを利用またはAI向けのアプリケーションはあまり多くありません。開発者がAI dApp開発のチュートリアルを探す際、ネイティブ暗号AIインフラに関連するものは少なく、ほとんどのチュートリアルはフロントエンドからOpenAI APIを呼び出すことに留まっています。
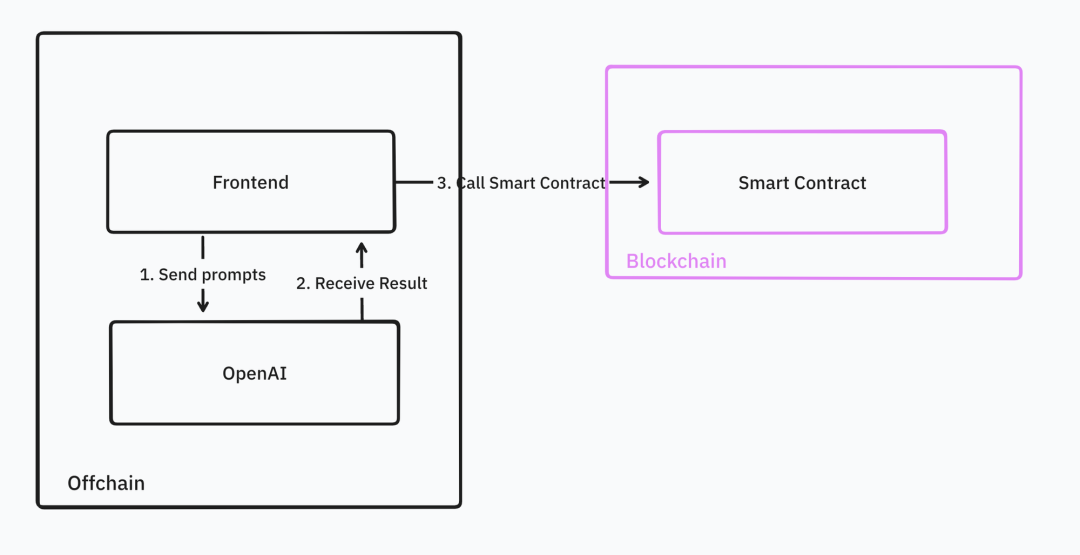
出典: IOSG Ventures
-
現時点でのアプリケーションはブロックチェーンの分散性と検証可能機能を十分に発揮できていませんが、この状況はすぐに変わります。現在、暗号分野に特化した多くのAIインフラがテストネットを開始しており、今後6か月以内に本格稼働を予定しています。
-
本研究では、暗号分野のAIインフラで利用可能な主要ツールについて詳しく紹介します。暗号世界のGPT-3.5的瞬間を迎えましょう!
1. RedPill:OpenAIへの分散型アクセラレーター
前述のRedPillへの投資は、良い導入例となります。
OpenAIはGPT-4-vision、GPT-4-turbo、GPT-4oといった世界的に強力なモデルを持っており、高度なAI Dapp構築に最適です。
開発者はオラクルまたはフロントエンドインターフェースを通じてOpenAI APIを呼び出し、dAppに統合できます。
RedPillは、複数の開発者のOpenAI APIを単一のインターフェースに統合し、グローバルユーザーに高速かつ安価で検証可能なAIサービスを提供することで、最先端AIモデルリソースの民主化を実現しています。RedPillのルーティングアルゴリズムは、開発者のリクエストを個々の貢献者に振り分けます。APIリクエストはその配信ネットワークを通じて実行され、OpenAIからの制限を回避し、暗号開発者が直面する以下の一般的な問題を解決します:
-
TPM(毎分トークン)制限:新規アカウントはトークン使用量に制限があり、人気でAI依存度の高いdAppの需要を満たせません。
-
アクセス制限:一部のモデルは新規アカウントまたは特定国へのアクセスを制限しています。
リクエストコードは同じままホスト名を変更するだけで、開発者は低コスト、高スケーラビリティ、無制限でOpenAIモデルにアクセスできます。

2. GPUネットワーク
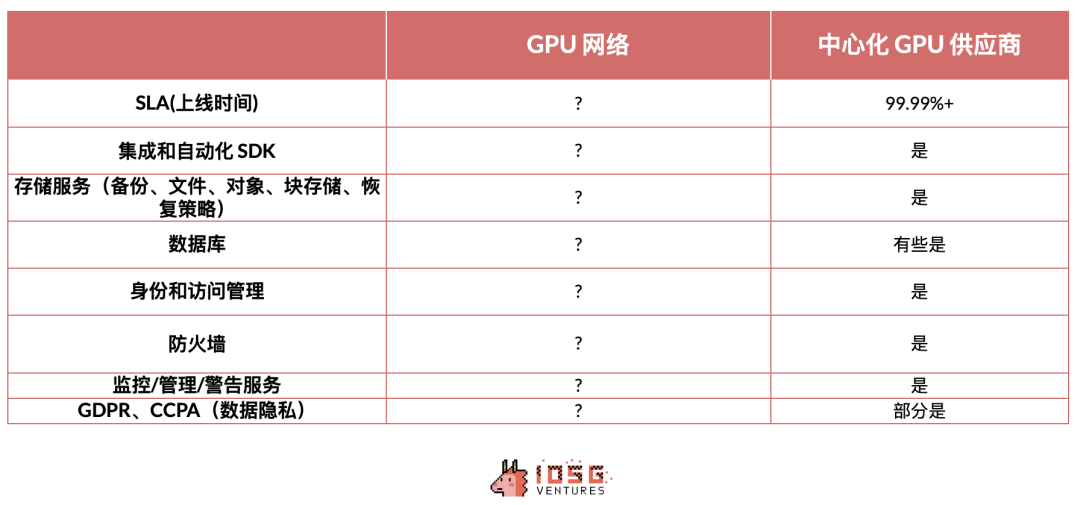
OpenAIのAPIを使用するほか、多くの開発者は自宅でモデルをホストすることを選択します。io.net、Aethir、Akashなどの普及したネットワークを利用して、分散型GPUネットワーク上でGPUクラスタを構築し、さまざまな強力な内部またはオープンソースモデルを展開・実行できます。
このような分散型GPUネットワークは、個人または小規模データセンターの計算力を活用し、柔軟な構成、多様なサーバー位置選択、低コストを提供することで、限られた予算内で開発者が簡単にAI関連の実験を行うことを可能にします。ただし、分散化の性質上、こうしたGPUネットワークには機能性、可用性、データプライバシーの面で一定の制約があります。
ここ数ヶ月、GPUの需要は過去のビットコイン採掘ブームを上回るほど熱狂的でした。その理由は以下の通りです:
-
ターゲット顧客が増え、GPUネットワークはAI開発者にサービスを提供しており、その数は膨大で忠誠心も高く、暗号資産価格の変動に左右されません。
-
採掘専用機器と比べ、分散型GPUはより多様なモデルと仕様を提供し、さまざまな要件に対応できます。特に大規模モデル処理には高VRAMが必要ですが、小規模タスクには適したGPUが選べます。また、分散型GPUはエンドユーザーに近い場所でサービスを提供できるため、遅延を低減できます。
-
技術がますます成熟しており、GPUネットワークはSolanaのような高速ブロックチェーンでの決済、Docker仮想化技術、Ray計算クラスタなどを活用しています。
-
リターン面では、AI市場が拡大しており、新アプリやモデル開発の機会が多く、H100モデルの期待リターンは60〜70%です。一方、ビットコイン採掘はより複雑で、勝者がすべてを取る構造であり、生産量も限定的です。
-
Iris Energy、Core Scientific、Bitdeerといったビットコイン採掘企業もGPUネットワークをサポートし、AIサービスを提供し、H100などAI向けに設計されたGPUの購入を積極的に行っています。
おすすめ:SLAをあまり重視しないWeb2開発者には、io.netが使いやすくシンプルな体験を提供し、コストパフォーマンスの高い選択肢です。
3. 推論ネットワーク
これは暗号ネイティブAIインフラの中核です。将来的には数十億回のAI推論操作を支えることになります。多くのAI layer1またはlayer2は、開発者がオンチェーンでネイティブにAI推論を呼び出せるようにしています。市場のリーダーにはRitual、Valence、Fetch.aiがあります。
これらのネットワークは以下の点で差異があります:
-
パフォーマンス(遅延、計算時間)
-
サポートされるモデル
-
検証可能性
-
価格(オンチェーンコスト、推論コスト)
-
開発体験
3.1 目的
理想は、開発者がどこでも、あらゆる形式の証明を通じて、カスタマイズされたAI推論サービスに容易にアクセスでき、統合にほとんど障壁がないことです。
推論ネットワークは、必要に応じた証明の生成と検証、推論計算、推論データの中継と検証、Web2およびWeb3インターフェースの提供、ワンクリックでのモデル展開、システム監視、クロスチェーン操作、同期統合、定期実行など、開発者に必要なすべての基盤サポートを提供します。
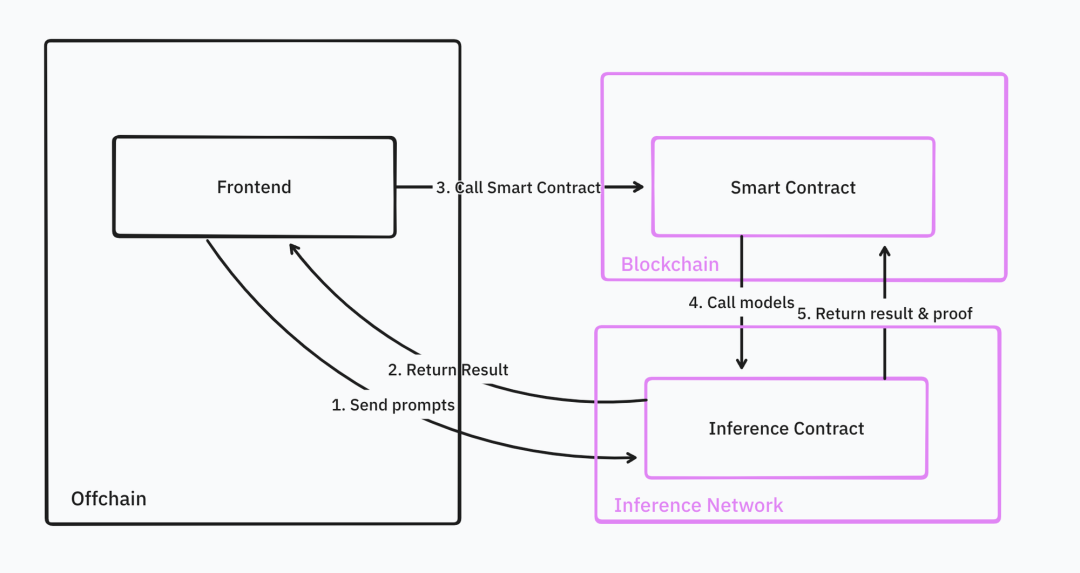
出典: IOSG Ventures
これらの機能により、開発者は推論サービスを既存のスマートコントラクトにシームレスに統合できます。例えば、DeFi取引ロボットを構築する際、これらのロボットは機械学習モデルを使って特定の取引ペアの売買タイミングを見つけ、基本取引プラットフォームで対応する取引戦略を実行します。
完全に理想的な状態では、すべての基盤構造がクラウドホスティングされています。開発者は取引戦略モデルをtorchのような汎用形式でアップロードするだけでよく、推論ネットワークがモデルを保存し、Web2およびWeb3の照会に対応します。
すべてのモデル展開ステップが完了すると、開発者は直接Web3 APIまたはスマートコントラクトを通じてモデル推論を呼び出せます。推論ネットワークはこれらの取引戦略を継続的に実行し、結果を基本スマートコントラクトにフィードバックします。開発者が管理するコミュニティ資金が大きい場合は、推論結果の検証も必要です。推論結果を受け取ると、スマートコントラクトはその結果に基づいて取引を行います。
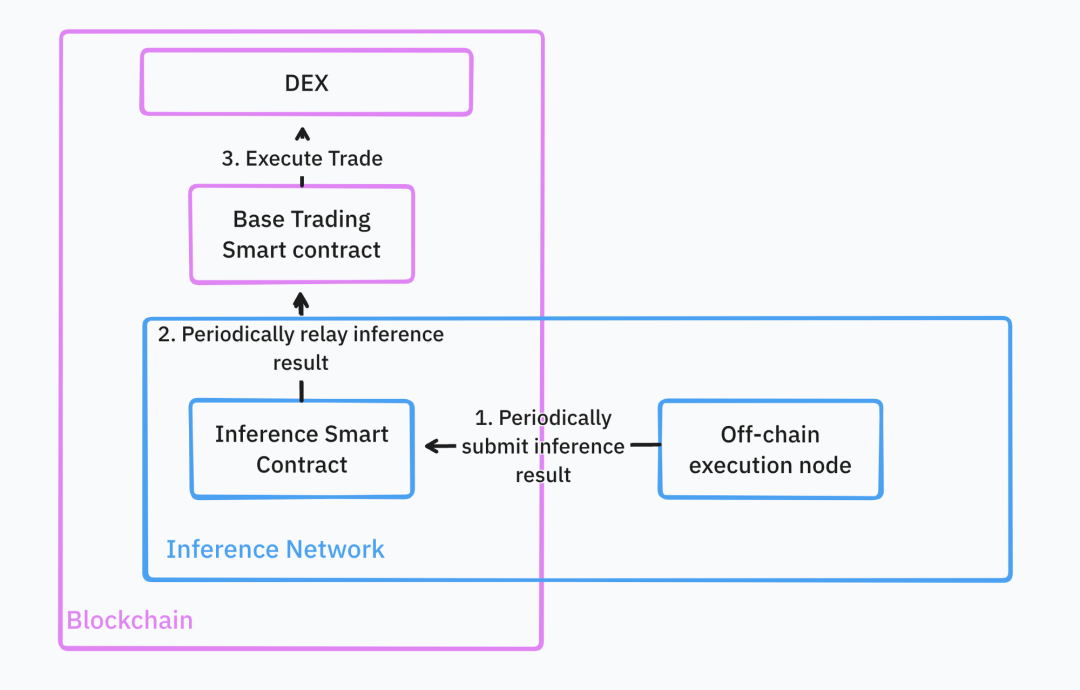
出典: IOSG Ventures
3.1.1 非同期と同期
理論的には、非同期実行の推論操作はより良いパフォーマンスを発揮できます。しかし、開発体験としては不便に感じられることがあります。
非同期方式では、開発者はまずタスクを推論ネットワークのスマートコントラクトに提出します。推論タスクが完了すると、推論ネットワークのスマートコントラクトが結果を返します。このプログラミングパターンでは、ロジックが推論呼び出しと推論結果処理の二つに分かれます。
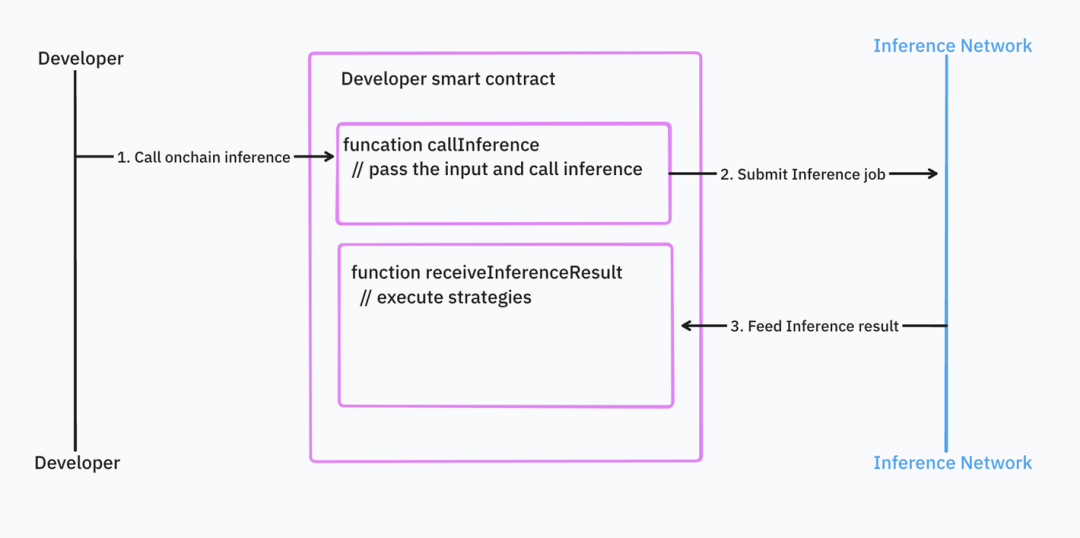
出典: IOSG Ventures
開発者が入れ子の推論呼び出しや大量の制御ロジックを持っている場合、状況はさらに悪化します。
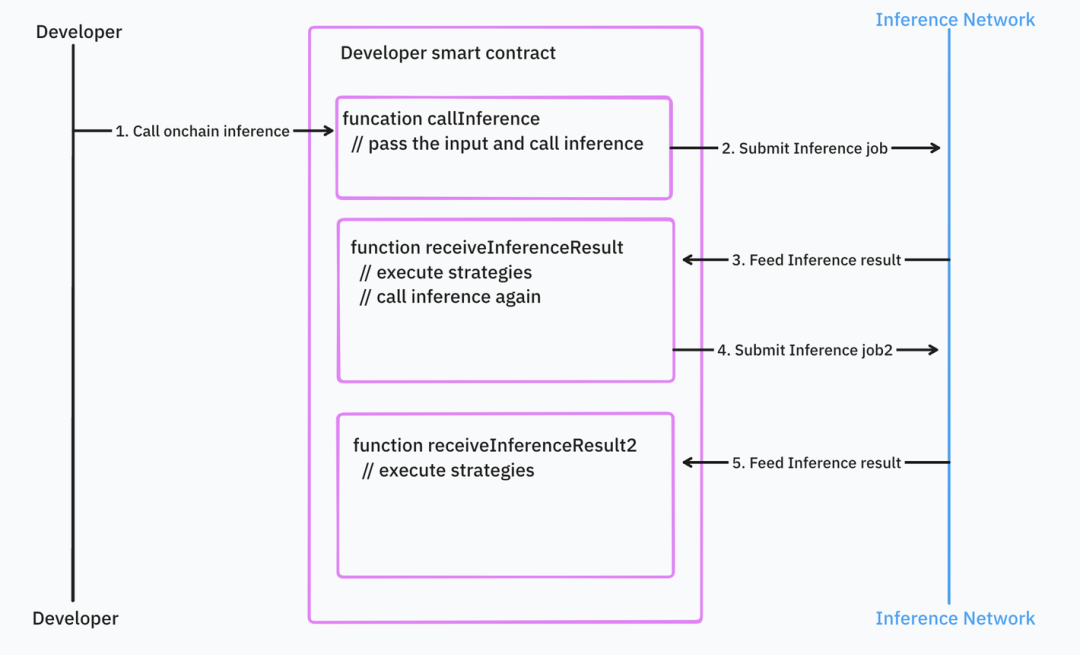
出典: IOSG Ventures
非同期プログラミングパターンは、既存のスマートコントラクトとの統合が難しく、開発者が大量の追加コードを書く必要があり、エラー処理や依存関係の管理も必要です。
一方、同期プログラミングは開発者にとってより直感的ですが、レスポンスタイムとブロックチェーン設計に課題をもたらします。例えば、入力データがブロックタイムや価格など急速に変化するデータの場合、推論完了時にはデータが古くなり、特定の状況下でスマートコントラクトの実行をロールバックする必要があるかもしれません。古くなった価格を使って取引するようなものです。
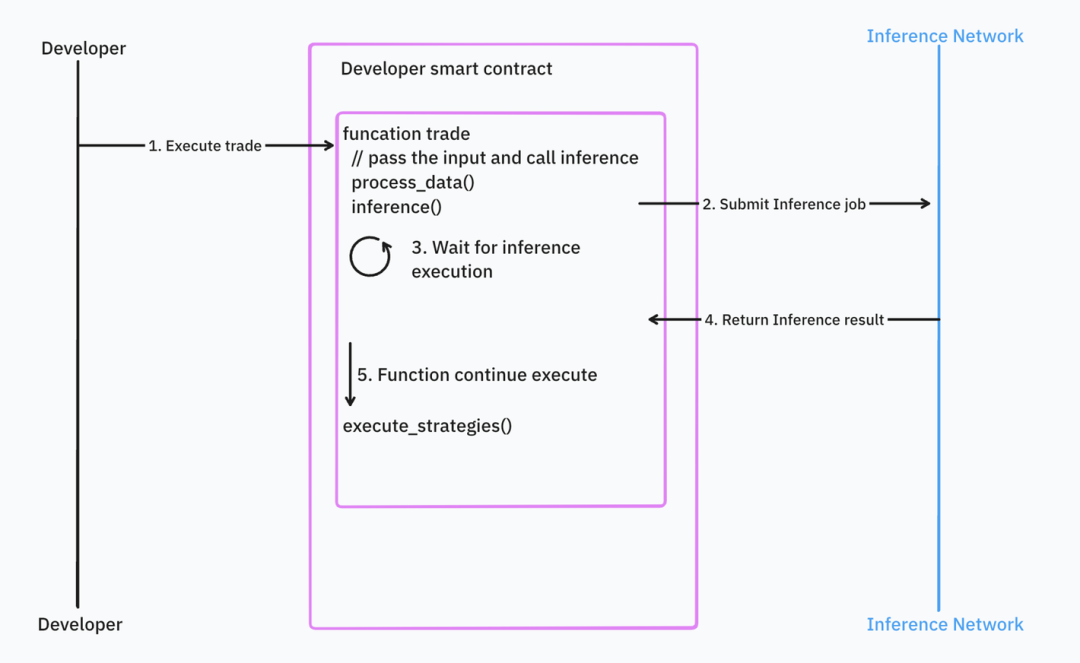
出典: IOSG Ventures
多くのAIインフラは非同期処理を採用していますが、Valenceはこれらの問題の解決に取り組んでいます。
3.2 現実
実際、多くの新しい推論ネットワークはまだテスト段階にあります。Ritualネットワークなどが該当します。公開資料によると、これらのネットワークの現時点での機能は限定的で(検証、証明機能などはまだ未実装)、オンチェーンAI計算を支えるクラウドインフラを提供しているわけではなく、AI計算をセルフホスティングし、その結果をオンチェーンに伝えるためのフレームワークを提供しています。
これはAIGC NFTを運営するアーキテクチャです。ディフュージョンモデルがNFTを生成し、Arweaveにアップロードします。推論ネットワークはこのArweaveアドレスを使ってオンチェーンでNFTを鋳造します。
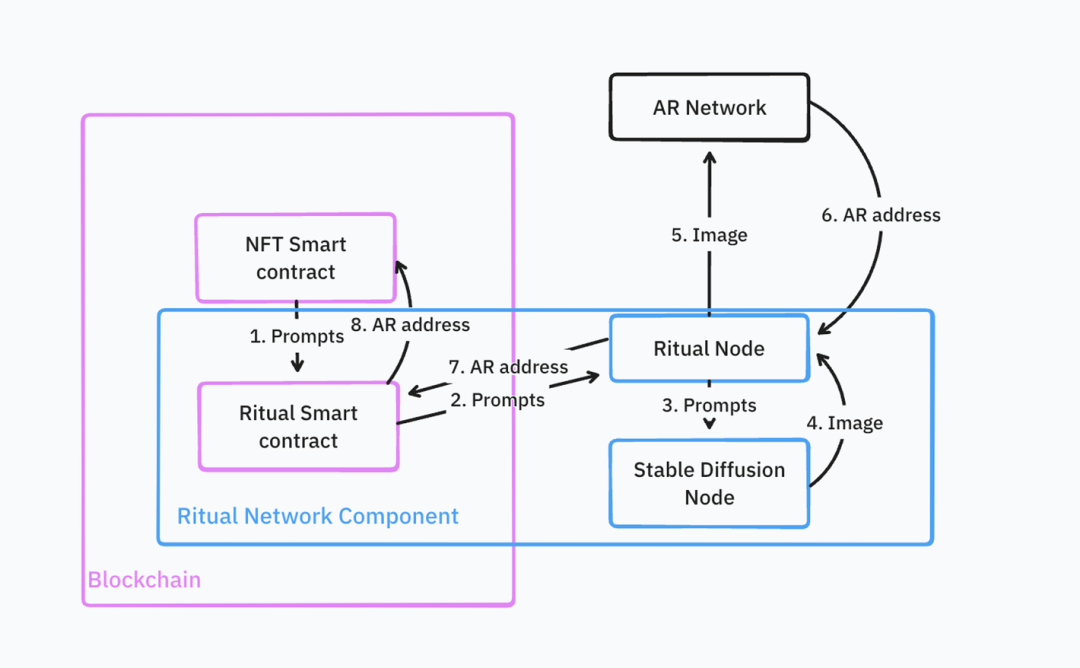
出典: IOSG Ventures
このプロセスは非常に複雑で、開発者はRitualノード(カスタムサービスロジック付き)、Stable Diffusionノード、NFTスマートコントラクトなど、大部分のインフラを自分で展開・維持する必要があります。
おすすめ:現時点の推論ネットワークは、カスタムモデルの統合と展開が非常に複雑であり、この段階ではほとんどのネットワークが検証機能をサポートしていません。AI技術をフロントエンドに適用することは、開発者にとって比較的簡単な選択肢です。検証機能がどうしても必要な場合は、ZKMLプロバイダーのGizaが良い選択です。
4. エージェントネットワーク
エージェントネットワークは、ユーザーが簡単にエージェントをカスタマイズできるようにします。このようなネットワークは、自律的にタスクを実行し、相互に通信し、ブロックチェーンネットワークとやり取りする実体またはスマートコントラクトから成り、すべて人間の直接介入なしに動作します。主にLLM技術を対象としています。例えば、イーサリアムに精通したGPTチャットボットを提供できます。現在、こうしたチャットボットのツールは限定的で、開発者はその上に複雑なアプリケーションを構築できません。
出典: IOSG Ventures
しかし将来、エージェントネットワークはエージェントに知識だけでなく、外部APIの呼び出し、特定タスクの実行能力など、より多くのツールを提供するようになります。開発者は複数のエージェントをつなげてワークフローを構築できるようになります。例えば、Solidityスマートコントラクトの作成には、プロトコル設計エージェント、Solidity開発エージェント、コードセキュリティレビューエージェント、Solidity展開エージェントなど、複数の専門エージェントが関与します。
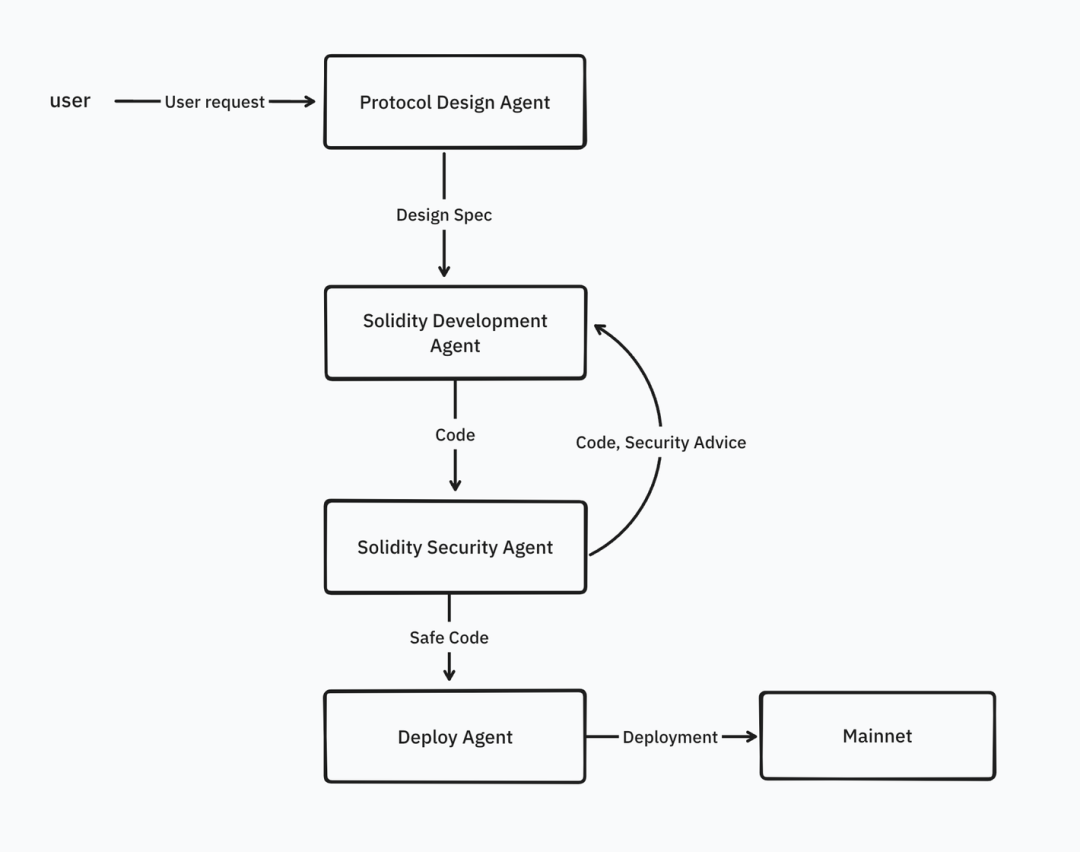
出典: IOSG Ventures
私たちはプロンプトとシナリオを使って、これらのエージェントの協力を調整します。
Flock.ai、Myshell、Theoriqなどがエージェントネットワークの例です。
おすすめ:現在の大多数のエージェントの機能は限定的です。特定のユースケースでは、Web2エージェントの方がサービスが充実しており、Langchain、Llamaindexなど成熟したオーケストレーションツールがあります。
5. エージェントネットワークと推論ネットワークの違い
エージェントネットワークはLLMに重点を置いており、Langchainのようなツールで複数のエージェントを統合します。通常、開発者は機械学習モデルを自ら開発する必要はなく、エージェントネットワークがモデル開発と展開のプロセスを簡素化しています。必要なエージェントとツールをリンクするだけで済みます。多くの場合、最終ユーザーが直接これらのエージェントを使用します。
推論ネットワークはエージェントネットワークの基盤インフラです。開発者に低レベルのアクセス権を提供します。通常、エンドユーザーは直接推論ネットワークを使用しません。開発者は独自のモデルを展開する必要があり、これはLLMに限定されず、オフチェーンまたはオンチェーンのエンドポイントを通じて使用できます。
エージェントネットワークと推論ネットワークは完全に独立した製品ではありません。すでに縦方向に統合された製品が見られ始めています。これら二つの機能は類似のインフラに依存しているため、エージェントと推論の両方の機能を同時に提供しています。

6. 新たな機会の地
モデル推論、訓練、エージェントネットワークに加え、web3分野には他にも探求すべき新たな分野があります:
-
データセット:ブロックチェーンデータを機械学習で使えるデータセットに変換するには? 機械学習開発者はより具体的でテーマに沿ったデータを必要としています。例えば、GizaはDeFiに関する高品質なデータセットをいくつか提供しており、機械学習訓練専用です。理想的なデータは単なる表形式ではなく、ブロックチェーン世界のインタラクションを記述するグラフデータを含むべきです。現状、この点は不十分です。BagelやSaharaなどのプロジェクトは、個人が新しいデータセットを作成する報酬を提供することでこの問題に取り組んでおり、個人データのプライバシー保護を約束しています。
-
モデルストレージ:一部のモデルは巨大なサイズであるため、それらの保存、配布、バージョン管理が鍵となり、オンチェーン機械学習のパフォーマンスとコストに影響します。この分野ではFilecoin、AR、0gなどの先駆的プロジェクトが進展を見せています。
-
モデル訓練:分散かつ検証可能なモデル訓練は難題です。Gensyn、Bittensor、Flock、Alloraなどが顕著な進展を遂げています。
-
モニタリング:モデル推論はオンチェーンとオフチェーンの両方で発生するため、web3開発者がモデルの使用状況を追跡し、潜在的な問題やバイアスを早期に発見できる新しいインフラが必要です。適切なモニタリングツールがあれば、web3の機械学習開発者は迅速に調整し、モデル精度を継続的に最適化できます。
-
RAGインフラ:分散型RAGには、ストレージ、埋め込み計算、ベクトルデータベースに対する高い要求があり、データのプライバシーとセキュリティを確保する必要があります。これは現在のWeb3 AIインフラとは大きく異なり、後者はFirstbatchやBagelなど第三者にRAGを依存していることがほとんどです。
-
Web3向けに特化したモデル:すべてのモデルがWeb3の状況に適しているわけではありません。多くの場合、価格予測、推薦などの特定用途に合わせて再訓練が必要です。AIインフラが繁栄するにつれ、将来的にはAIアプリケーションを支援するためのより多くのWeb3ネイティブモデルが登場することを期待しています。例えば、PondはブロックチェーンGNNを開発しており、価格予測、推薦、詐欺検知、マネーロンダリング防止など多様なシナリオに利用されます。
-
評価ネットワーク:人間のフィードバックがない状況でエージェントを評価するのは簡単ではありません。エージェント作成ツールが普及すれば、市場には無数のエージェントが現れます。そのため、各エージェントの能力を示し、特定の状況でどのエージェントが最も優れているかを判断するためのシステムが必要です。Neuronetsはこの分野のプレイヤーの一つです。
-
コンセンサスメカニズム:AIタスクに対してPoSが最適とは限りません。計算の複雑さ、検証の困難さ、決定性の欠如がPoSが直面する主な課題です。Bittensorは、機械学習モデルと出力に貢献するノードに報酬を与える新しい知的コンセンサスメカニズムを創造しました。
7. 今後の展望
現在、垂直統合の傾向が観察されています。基本的な計算層を構築することで、ネットワークは訓練、推論、エージェントネットワークサービスなど多様な機械学習タスクをサポートでき、Web3の機械学習開発者に包括的なワンストップソリューションを提供することを目指しています。
現在、オンチェーン推論はコストが高く速度も遅いものの、優れた検証可能性とバックエンドシステム(例:スマートコントラクト)とのシームレスな統合を提供しています。私は将来はハイブリッド型のアプリケーションになると予想しています。一部の推論処理はフロントエンドまたはオフチェーンで行われ、重要な意思決定的な推論のみがオンチェーンで実行されます。このパターンはすでにモバイルデバイスで応用されています。モバイルデバイスの特性を活かし、ローカルで小型モデルを高速に実行し、より複雑なタスクはクラウドに移行して大型LLMで処理します。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













