

Bittensorは暗号資産(Crypto)業界全体の希望である
TechFlow厳選深潮セレクト
Bittensorは暗号資産(Crypto)業界全体の希望である
「Crypto にはまだ存在意義があるのか?」という総合的な議論において、Bittensor が業界全体に対して最も説得力のある答えを提示しています。
著者:0xai
本稿の作成にあたり、オープンソースAIモデル分野における@DistStateAndMeおよびそのチームの貢献、並びに本稿に対する貴重な助言と支援に対し、ここに深く感謝申し上げます。
なぜこのレポートに注目すべきか
「分散型AIトレーニング」がもはや不可能ではなくなり、現実となったとしたら、Bittensorはどれほど過小評価されているでしょうか?
2026年初頭、暗号資産(Crypto)業界全体には倦怠感が漂っていました。
前回のバブルの余韻はとっくに消え失せ、人材はAI業界へと加速的に流出しています。かつて「次の100倍」を語っていた人々は、今やClaude、CodeOpenclawといった話題に終始しています。「Cryptoは時間の無駄だ」——こうした言葉を、あなたは何度も耳にしたことがあるかもしれません。
しかし、2026年3月10日、Bittensorのサブネット「Templar」が静かに一つの発表を行いました。
世界中から集まった70名以上の独立した参加者が、中央サーバーなし、大企業による調整なし、ただ暗号資産のインセンティブメカニズムのみを用いて、720億パラメータ規模のAI大規模言語モデル(LLM)を共同で訓練しました。
このモデルおよび関連論文はすでにHuggingFaceおよびarXivにて公開されており、データは誰でも公開検証可能です。
さらに重要なのは:複数の主要なベンチマークテストにおいて、このモデルはMeta社が巨額の投資をかけて訓練した同規模モデルを上回る性能を示したことです。
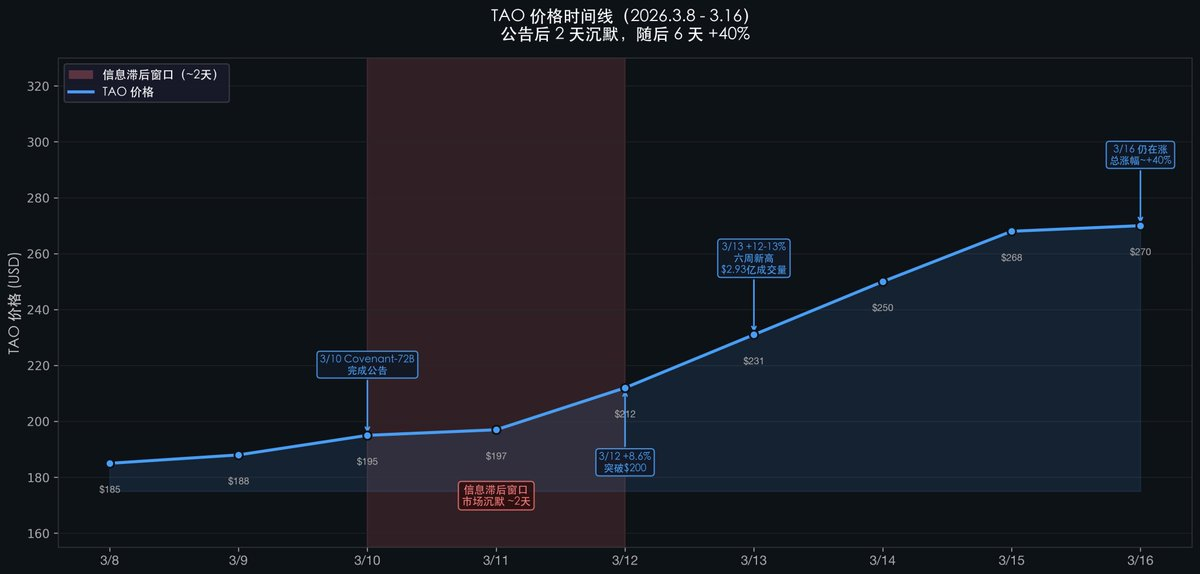
発表直後、TAOトークンの価格は約2日間沈黙を保ちました。3日目になってようやく急騰を始め、6日経ってもなお上昇は止まらず、総合的な上昇率は約+40%に達しました。では、なぜこの2日間の遅延が生じたのでしょうか?
本レポートの核心的主張は以下の通りです:暗号資産投資家はこれを単なる「また一つのオープンソースモデル」と見なし、日常的に利用しているGPTやClaudeに比べると劣ると判断しています。一方、AI研究者は暗号資産にほとんど関心を払っていません。この二つのコミュニティの間に横たわる認識のギャップこそが、まさに「認知的アービトラージ・ウィンドウ」を生み出しているのです。
読解の枠組み
本レポートは、以下の二つの論理的パートに分けられます:
Part I — 技術的ブレイクスルー:SN3 Templarが実際に何を成し遂げたのか、そしてそれがAIおよびCryptoの歴史においていかなる意義を持つのかを解説します。
Part II — 業界への影響:この出来事が、なぜBittensorエコシステムが体系的に過小評価されていることを意味するのか、またなぜBittensorがCrypto業界全体の希望であると言えるのかを解説します。
Part I:分散型AIトレーニングのブレイクスルー
1. SN3とは何か?
大規模言語モデル(LLM)の訓練には何が必要でしょうか?
従来の回答:巨大なデータセンターを建設し、数万枚の最上位GPUを購入し、数億ドルの資金を投じ、単一企業のエンジニアチームが一元的に調整する——これがMeta、Google、OpenAIのやり方です。
SN3 Templarのアプローチ:世界中に散らばった個人が、各自が所有する1台または数台のGPUサーバーを提供し、それをパズルのように組み合わせ、協力して1つの完全な大規模モデルを訓練する。
ただし、ここには根本的な課題があります。参加者が世界中に散在し、相互に信頼関係がなく、ネットワーク遅延も不安定な状況下で、どうすれば訓練結果が有効であることを保証できるでしょうか?サボりや不正行為をどう防ぐのでしょうか?また、継続的な貢献をどう促すのでしょうか?
Bittensorが提示した解決策:TAOトークンをインセンティブとして活用する。誰がより効果的な勾配(=「モデルの改善への貢献度」)を提供したかによって、獲得するTAOの量が決まります。システムが自動的に評価・支払いを行い、一切の中央集権的機関による調整は不要です。
これがBittensorのSN3(第3号サブネット)、コードネームTemplarです。
Bitcoinが「分散型の貨幣」の実現可能性を証明したなら、SN3は「分散型のAIトレーニング」の実現可能性を証明しようとしています。
2. SN3が達成した成果とは?
2026年3月10日、SN3 TemplarはCovenant-72Bという大規模言語モデルの訓練完了を発表しました。
「72B」とは?:720億個のパラメータ。パラメータはAIモデルの「知識保存単位」であり、その数が多いほど、通常はモデルの能力が高まります。GPT-3は1750億、Metaのオープンソース旗艦モデルLLaMA-2は700億です。Covenant-72BはLLaMA-2と同規模のモデルです。
訓練規模はどれほどか?:約1.1兆トークン(≈20万字の書籍550万冊分)。
誰が訓練に参加したか?:70名以上の独立した参加者(マイナー)が、各ラウンド最大約20ノードの同期制限のもとで順次計算リソースを提供。訓練は2025年9月12日に開始され、約6ヶ月かけて完了しました。中央サーバーも、統一された調整機関も存在しません。
モデルの性能は?:主流のAIベンチマーク試験を例に挙げると以下の通りです:
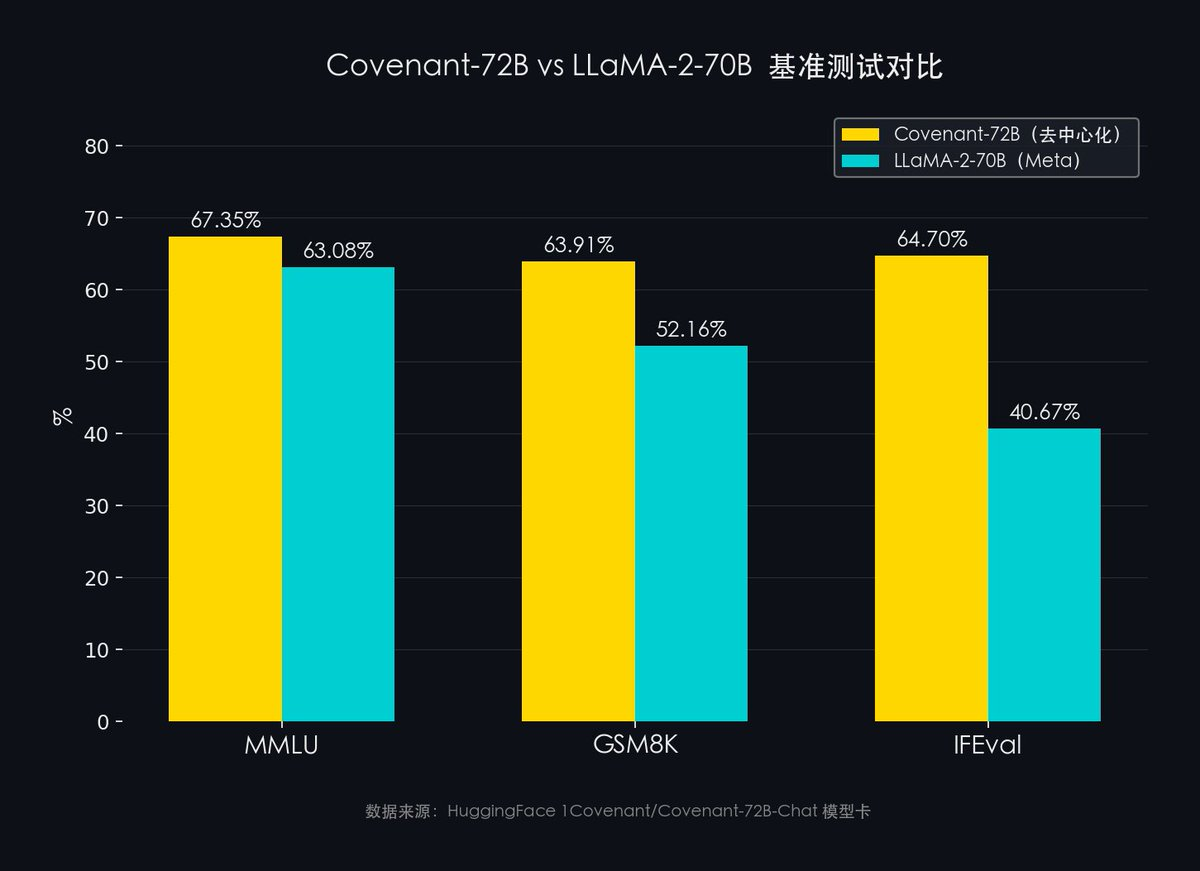
出典:HuggingFace 1Covenant/Covenant-72B-Chat モデルカード
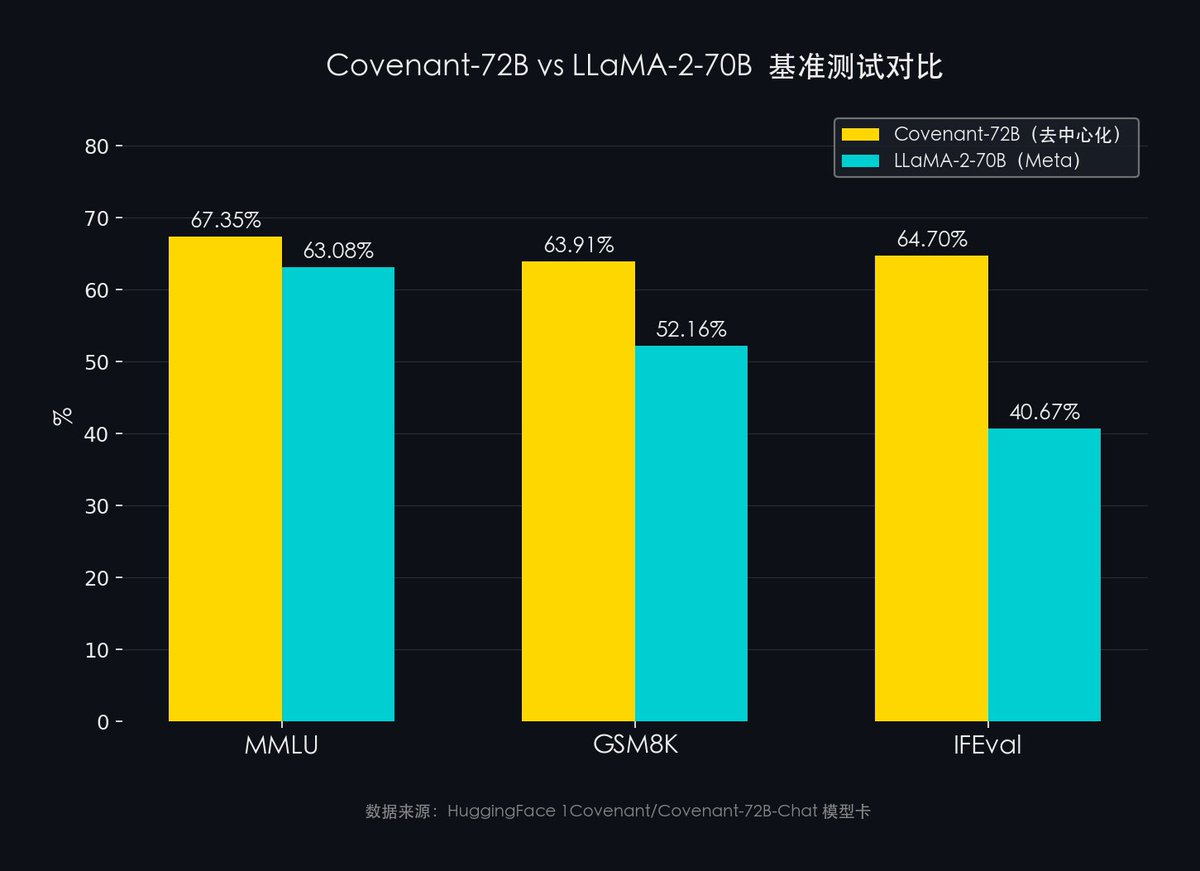
- MMLU(57分野の総合的知識):Covenant-72B 67.35% vs Meta LLaMA-2 63.08%
- GSM8K(数学的推論):Covenant-72B 63.91% vs Meta LLaMA-2 52.16%
- IFEval(指示遂行能力):Covenant-72B 64.70% vs Meta LLaMA-2 40.67%
完全オープンソース:Apache 2.0ライセンス。誰でも無料でダウンロード・利用・商用利用可能、制限なし。
学術的裏付けあり:論文はarXiv 2603.08163に投稿済み。核となる技術(SparseLoCoオプティマイザおよびGauntlet不正防止メカニズム)はNeurIPS Optimization Workshopにて発表済みです。
3. この成果が意味するものとは?
オープンソースAIコミュニティにとって:これまで、資金・計算資源のハードルの高さゆえに、70Bクラスの大規模モデルの訓練はごく少数の大企業だけの特権でした。Covenant-72Bは、初めて「中央資金支援なしで、コミュニティ自体が同等規模のモデルを訓練できること」を実証しました。これは、AI基盤モデル開発への参画資格の境界を根本的に変えるものです。
AIの権力構造にとって:現在のAI基盤モデルの市場は極めて集中しており、OpenAI、Google、Meta、Anthropicといった数社が最も強力な基盤モデルを支配しています。分散型トレーニングの成立は、この「護城河」が必ずしも越えられないものではないことを示唆します。「基盤モデルの開発は大企業にしかできない」という前提が、初めて揺らぎ始めたのです。
暗号資産業界にとって:これは、CryptoプロジェクトがAI分野において、単なる「トレンド乗っ取り」ではなく、**実質的な技術貢献**を初めて実現したケースです。Covenant-72BはHuggingFace上のモデル、arXiv掲載論文、公開ベンチマークデータという三つの確固たる実績を持っています。これにより、「Cryptoのインセンティブメカニズムが、真剣なAI研究のためのインフラストラクチャとなり得る」という先例が築かれました。
Bittensor自身にとって:SN3の成功は、Bittensorを単なる「理論的には可能と思われる分散型AIプロトコル」から、「実践によって検証済みの分散型AIインフラストラクチャ」へと進化させました。これは0から1への質的飛躍です。
4. SN3の歴史的地位
分散型AIトレーニングという道を歩んだのは、SN3が初めてではありません。しかし、SN3は先行者たちが到達できなかった地点まで到達しました。
分散型トレーニングの進化史:
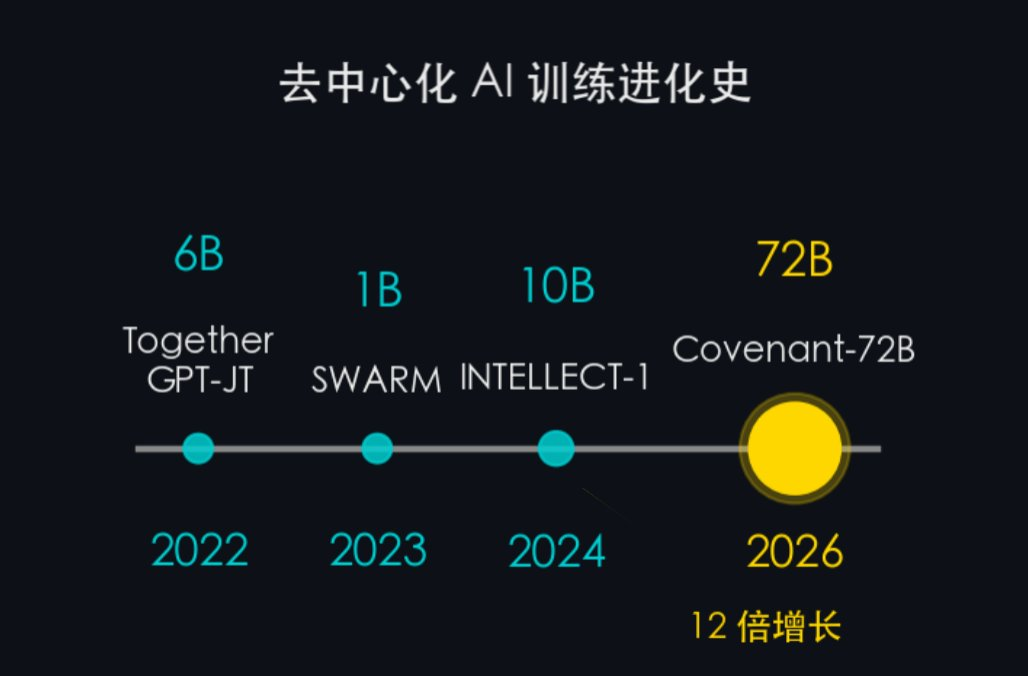
- 2022 — Together GPT-JT(6B):初期の探求。マルチマシン協調の実現可能性を証明
- 2023 — SWARM Intelligence(~1B):異種ノード間協調トレーニングフレームワークを提案
- 2024 — INTELLECT-1(10B):組織を超えた分散型トレーニング
- 2026 — Covenant-72B / SN3(72B):主流ベンチマークで集中型トレーニングモデルを上回った、初の72B規模分散型大規模モデル
4年間で、6Bから72Bへとパラメータ数は12倍に増加しました。しかし、より重要であるのはパラメータ数ではなく「品質」です。それ以前の世代のプロジェクトは主に「動くこと」を目的としていたのに対し、Covenant-72Bは、主流ベンチマークで集中型トレーニングモデルを上回る性能を示した、初の分散型大規模モデルなのです。
主要な技術的ブレイクスルー:
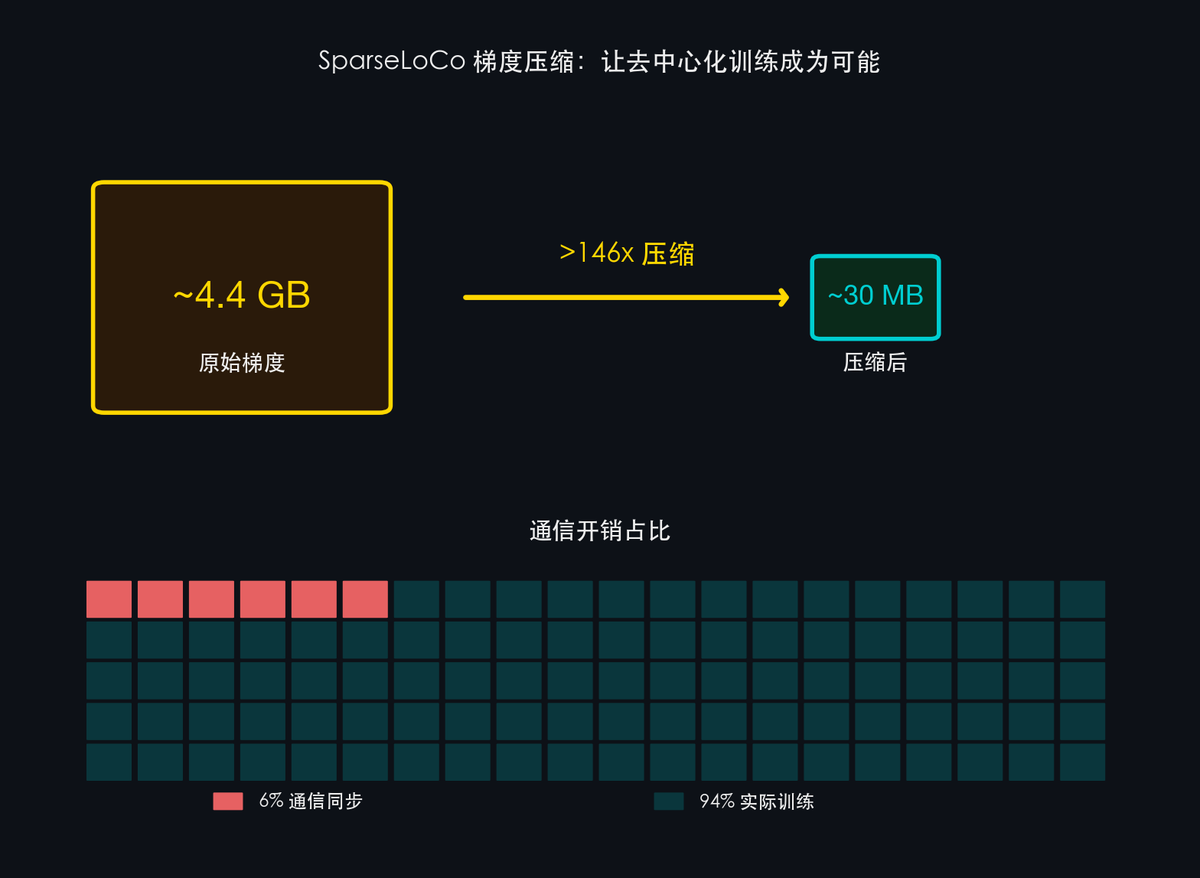
- >99%の圧縮率(>146倍):参加者がトレーニング結果(勾配)をアップロードする際、本来GB単位のデータ転送が必要なところを、SparseLoCoが全工程で146倍以上圧縮。まるで1シーズン分のドラマを1枚の画像に圧縮し、かつ情報損失を極小化するようなものです。
- 通信負荷わずか6%:100人が協働する場合、そのうち「調整・連絡」に費やす時間はわずか6%、残り94%は実際のトレーニングに専念できます。これは分散型トレーニングの最大のボトルネックの一つを解決しました。
5. 分散型トレーニングは過小評価されているか?
まずデータを見て、その後で判断しましょう。
過小評価の証拠
- MMLU:Covenant-72B 67.35% vs LLaMA-2 63.08%
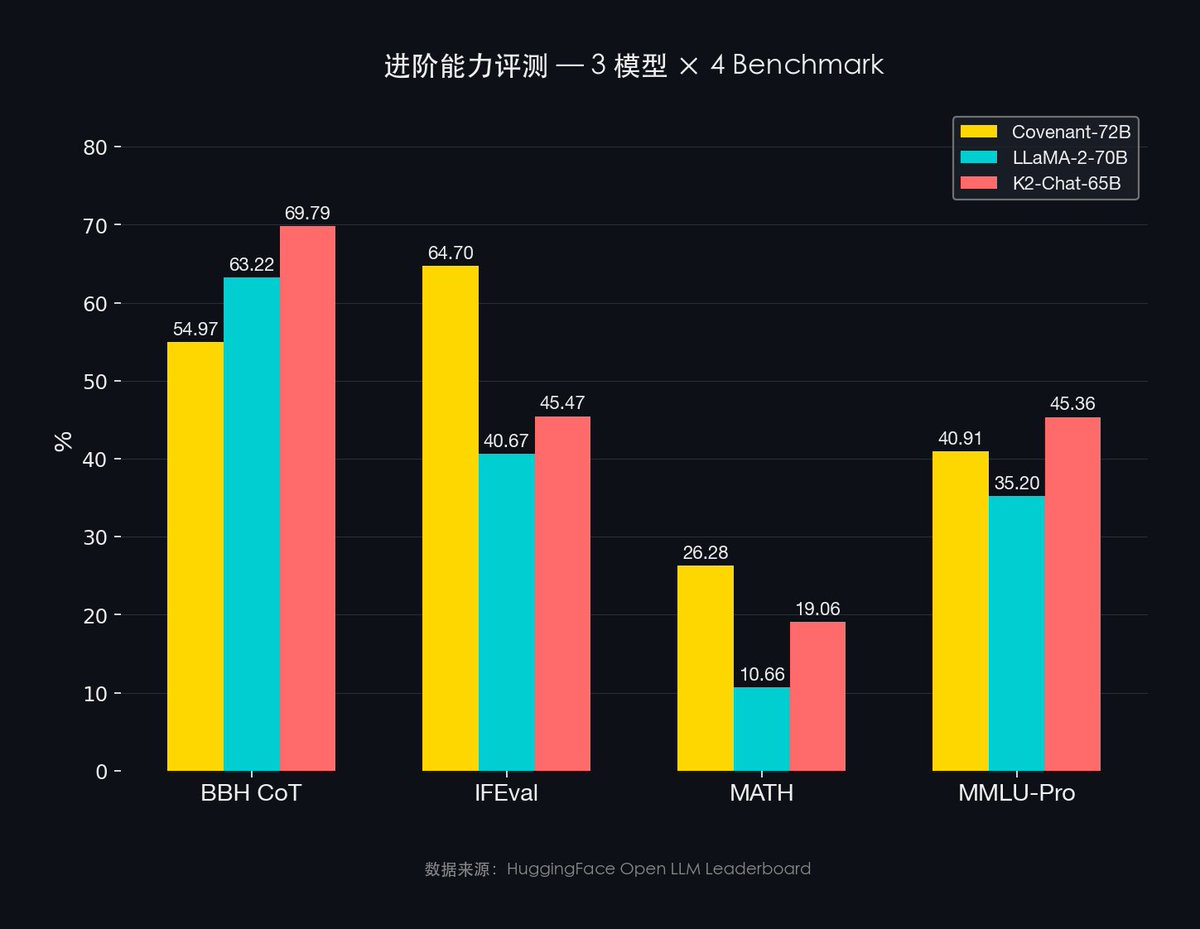
- MMLU-Pro:Covenant-72B 40.91% vs LLaMA-2 35.20%
- IFEval:Covenant-72B 64.70% vs LLaMA-2 40.67%
分散型トレーニングで作られたモデルが、Metaが巨額の費用をかけて訓練したLLaMA-2-70Bを上回りました。
現行トップクラスのオープンソースモデルとの差(率直に向き合うべき点):
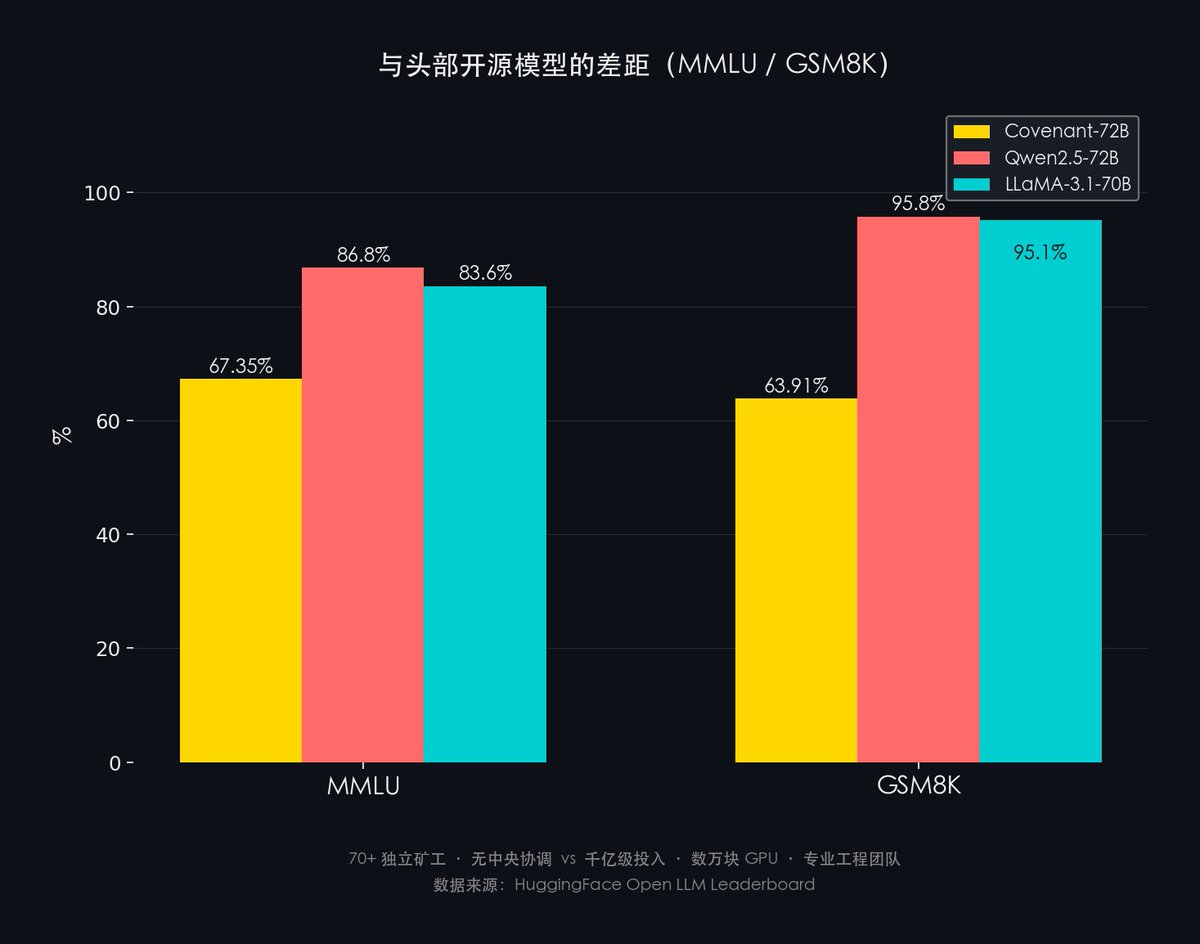
- MMLU:Covenant-72B 67.35% vs Qwen2.5-72B 86.8% vs LLaMA-3.1-70B 83.6%
- GSM8K:Covenant-72B 63.91% vs Qwen2.5-72B 95.8% vs LLaMA-3.1-70B 95.1%
差は約20〜30ポイントです。
ただし、比較の枠組みが重要です。Covenant-72Bの意義はSOTA(State-of-the-Art)を打ち破ることではなく、「分散型トレーニングの実現可能性」を証明することにあります。Qwen2.5/LLaMA-3.1は、数千億円規模の投資+数万枚のGPU+専門のエンジニアリングチームを背景にしています。一方、Covenant-72Bは70名以上の独立したマイナー+中央調整なしという環境で生まれました。
スナップショットよりもトレンドが重要:
- 2022年:最高水準の分散型モデルは6Bパラメータで、MMLUすら個別に測定されていなかった。
- 2026年:72BモデルでMMLU 67.35%を記録し、Metaの同規模モデルを上回った。
わずか4年間で、分散型トレーニングは「概念実験」から「集中型トレーニングと比肩する性能」へと進化しました。この曲線の傾きこそが、単一のベンチマーク数値よりも遥かに注目に値する指標です。
加えて、Covenant-72Bが深度推論において見せる差は、既に解消の道筋が描かれています——SN81 Grailが後続の強化学習(RLHF)によるファインチューニングを担当し、モデルのアライメントおよび能力向上を図ります。これはまさに、GPT-4がGPT-3に対して実現した最も重要な進化ステップです。
次なるマイルストーンは「Heterogeneous SparseLoCo」:現行のSN3では、すべてのマイナーが同一モデルのGPUを使用することが必須です。次なる重大な技術的飛躍はHeterogeneous SparseLoCoであり、これは混合ハードウェア(B200+A100+コンシューマー向けGPU)を同一トレーニングタスクに参加させることを可能にします。実現すれば、次期トレーニングの計算資源プールは劇的に拡大します。
分散型トレーニングは、すでに「実現可能性」の閾値を越えました。現在のベンチマークでの差は、引き続き最適化すべき工学的課題であり、根本的な理論的障壁ではありません。
Part II:市場はまだこの事象を理解していない
TAO価格のタイムライン
SN3の発表直後の$TAO価格の動きは、まさにこの認識の遅れを如実に示しています:
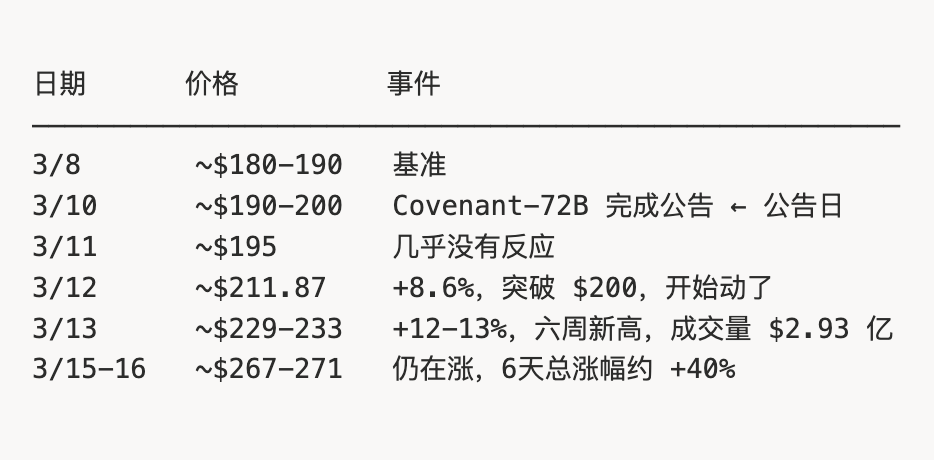
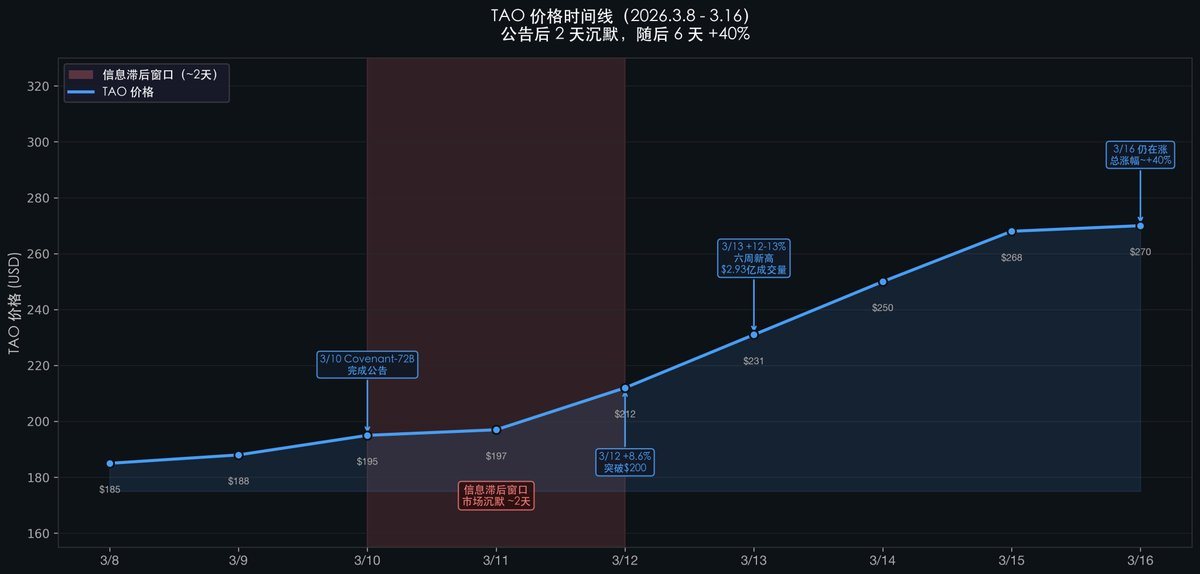
この2日間の沈黙(3月10日→3月12日)に注目してください:発表直後、価格はほとんど変動しませんでした。
なぜ遅れが生じたのか?
暗号資産投資家が受け取ったニュースは「BittensorのSN3がAIモデルのトレーニングを完了した」——しかし、彼らが必ずしも理解しているのは、「72B規模の分散型トレーニングがMMLUでMetaを上回る」という技術的意義ではありません。
AI研究者はこの技術的意義を理解できますが、彼らは暗号資産にほとんど関心を払っていません。
この二つのコミュニティの認識のギャップが、約2〜3日の価格遅延というウィンドウを生み出しています。
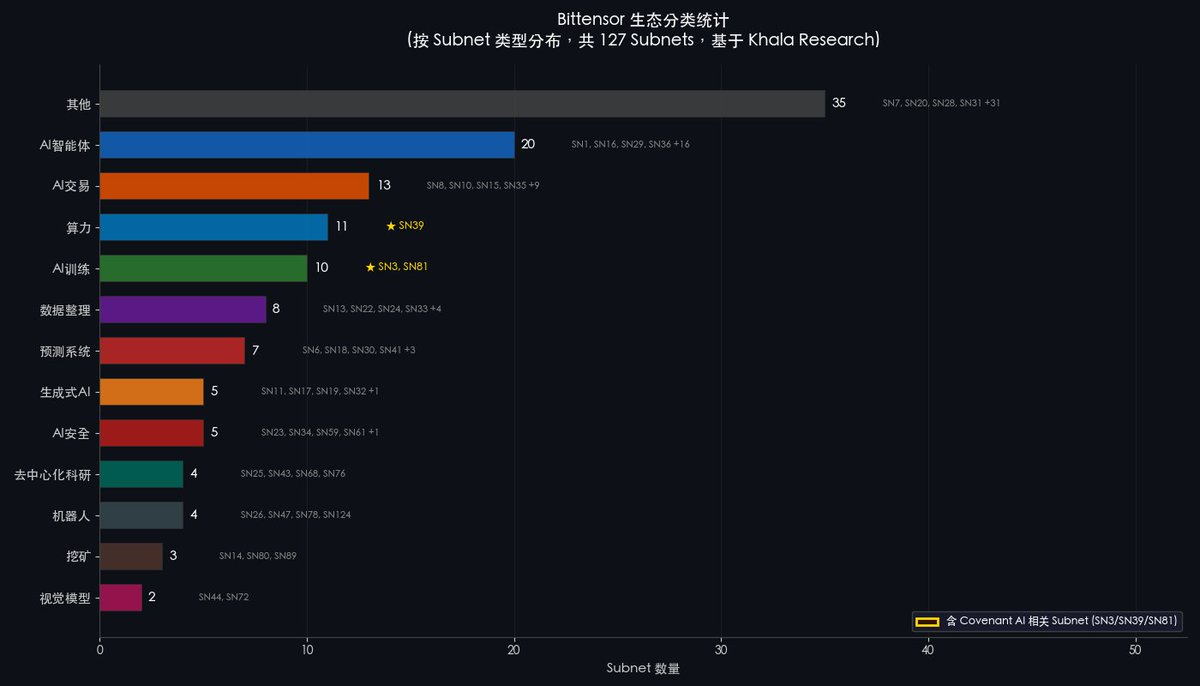
さらに、大多数の暗号資産投資家は、Bittensorに対する認識を前回のサイクルに留めています。現在、Bittensor上でアクティブなサブネットは79個を超え、AI Agent、計算資源、AIトレーニング、AI取引、ロボティクスなど、まったく異なる領域をカバーしています。市場がBittensorのエコシステムの広範性を再評価する際、この認識のギャップは是正されます——そして、その是正プロセスは通常、価格の急騰という形で現れます。
Bittensorの評価のずれ
Bittensorをより大きな産業的文脈に位置付けると:
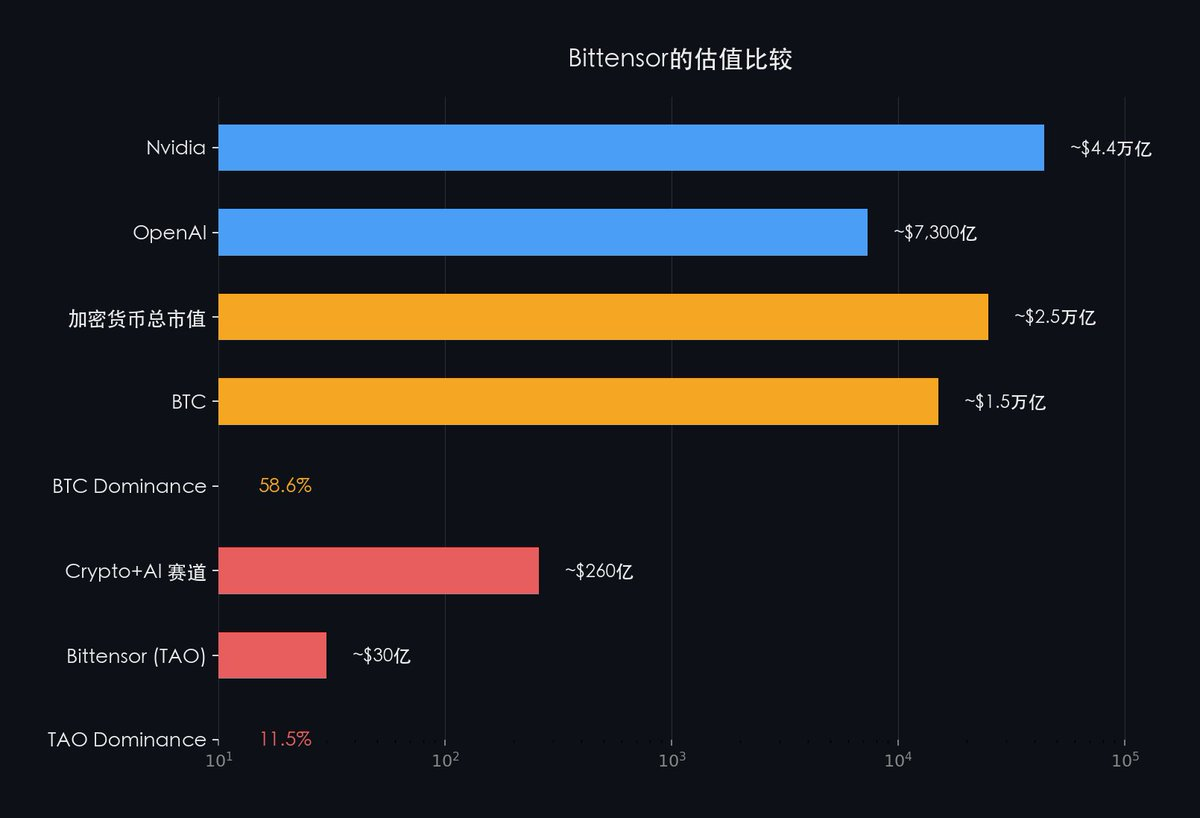
SN3はすでに、Bittensorが分散型の大規模モデルトレーニングを実行可能であることを証明しました。
もし将来のAIが、オープンで許諾不要のトレーニングネットワークを必要とするなら、現時点で唯一実践によって検証済みの候補インフラストラクチャは、Bittensor以外にありません。
市場は、アプリケーション層のプロジェクトを評価するロジックで、AIインフラストラクチャレベルのネットワークを評価しています。
暗号資産業界内部での比較でさえ:Bitcoinは暗号資産市場全体における時価総額シェアを長期的に50〜60%維持していますが、BittensorはCrypto AI分野におけるシェアはわずか約11.5%に過ぎません。
市場がBittensorのAIインフラストラクチャとしての位置づけを再認識するとき、この評価のずれは必然的に修正されます。
結論:BittensorはCrypto業界全体の希望である
SN3 TemplarのCovenant-72Bが一つだけ証明したとすれば、それは以下の一点です:
分散型ネットワークは、資本の調整だけでなく、計算資源および最先端AI研究の調整も可能である。
過去数年間、CryptoはAIに関する物語の中で、多くが周辺的な役割を果たしてきました。多数のプロジェクトが、概念的な包装・感情的な煽り・資本の物語に依存し、検証可能な技術的成果を欠いていました。SN3は、明らかに異なるケースです。
それは新たなトークン物語を打ち出したり、あるいは「AI+Web3」を謳うアプリケーション層の製品を包装したりはしていません。代わりに、より基盤的で、より困難なことを成し遂げました:
中央集権的な調整なしで、72B規模の大規模モデルを訓練したのです。
参加者は世界中から集まり、互いに信頼関係を築く必要はありません。システムはブロックチェーン上のインセンティブおよび検証メカニズムによって、トレーニングへの貢献と報酬の分配を自動的に調整します。
Cryptoのメカニズムが、AI分野において初めて実質的な生産力を組織化したのです。
多くの人々は、SN3の歴史的意義をまだ理解していません。かつて、多くの人々がBitcoinが証明したのは「より優れた支払い手段」ではなく、「中央信用を必要としない価値の合意形成」であることに気づかなかったのと同じです。
今日、多くの人々がまだ見ているのは、単なるベンチマークの数値、モデルのリリース、あるいは価格の一時的な上昇にすぎません。
しかし、実際に起きている変化は、Bittensorが以下を証明しつつあるということです:
- Cryptoは資産の発行だけではなく、生産の組織化も可能である
- Cryptoは注目の取引だけではなく、知能の生産も可能である
オープンソースコミュニティはコードを提供でき、学術界は論文を提供できます。しかし、問題が超大規模トレーニング、長期的協働、地域横断的なスケジューリング、不正防止および報酬分配という領域に至ると、善意や評判システムだけでは到底十分ではありません:
- 経済的インセンティブがなければ、安定した供給は得られない
- 検証可能な報償・罰則がなければ、長期的な協働は成立しない
- トークン化された調整メカニズムがなければ、真正のグローバルかつ許諾不要のAI生産ネットワークは形成されない
だからこそ、Bittensorは過小評価されているのか?その答えは「おそらく」ではなく、「明確に、体系的に過小評価されている」です。
「Cryptoにはまだ存在意義があるのか?」という業界全体の根本的議論において、Bittensorは、全業界に向けた最も力強い回答を提示しています。
そうであるがゆえに:BittensorはCrypto業界全体の希望なのです。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














