

エージェント工学の8段階
TechFlow厳選深潮セレクト
エージェント工学の8段階
レベルが1つ上がるごとに、生産性は飛躍的に向上し、モデルの能力が向上するたびに、こうした利益はさらに拡大します。
翻訳:宝玉
AI のプログラミング能力は、私たちがそれを活用する能力をすでに上回りつつあります。そのため、SWE-bench のスコアを必死に上げようとする試みの数々は、エンジニアリングリーダーが真に重視している生産性指標と連動していません。Anthropic のチームはわずか10日間で Cowork を本番リリースしましたが、別のチームは同じモデルを使いながらも、POC(概念実証)すら完成できていません——その差は、一方のチームが「能力」と「実践」のギャップをすでに埋めているのに対し、もう一方はまだ埋めていないことに起因します。
このギャップは一夜にして解消されるものではなく、段階的に徐々に縮小されていきます。全部で8段階です。この記事をお読みになっている多くの方は、おそらくすでに最初の数段階を通過済みでしょう。そして、次の段階に到達することを今か今かと待ち望んでいるはずです——なぜなら、段階を1つ昇るごとに、生産性が飛躍的に向上し、さらに各モデルの能力向上によって、その恩恵はさらに拡大されるからです。
もう一つ注目すべき理由は、多人数協働効果です。あなたの生産性は、あなた自身が思っている以上に、チームメイトの段階に依存しています。仮にあなたが7段階のエキスパートだとしましょう。夜寝ている間に、バックグラウンドのエージェントがあなたの代わりに複数のPRを提案してくれます。しかし、あなたのコードリポジトリでは、他の同僚による承認がマージの前提条件となっており、その同僚がまだ2段階にとどまっていて、手動でPRをレビューしているとしたら、あなたのスループットはそこで完全に止まってしまいます。つまり、チームメイトのレベルアップを支援することは、結果として自分自身の利益にもなるのです。
多くのチームおよび個人と、彼らがAIを活用したプログラミングをどのように実践しているかについて対話を重ねた結果、以下のような段階的進化の道筋(順序は絶対的ではありません)を観測しました:
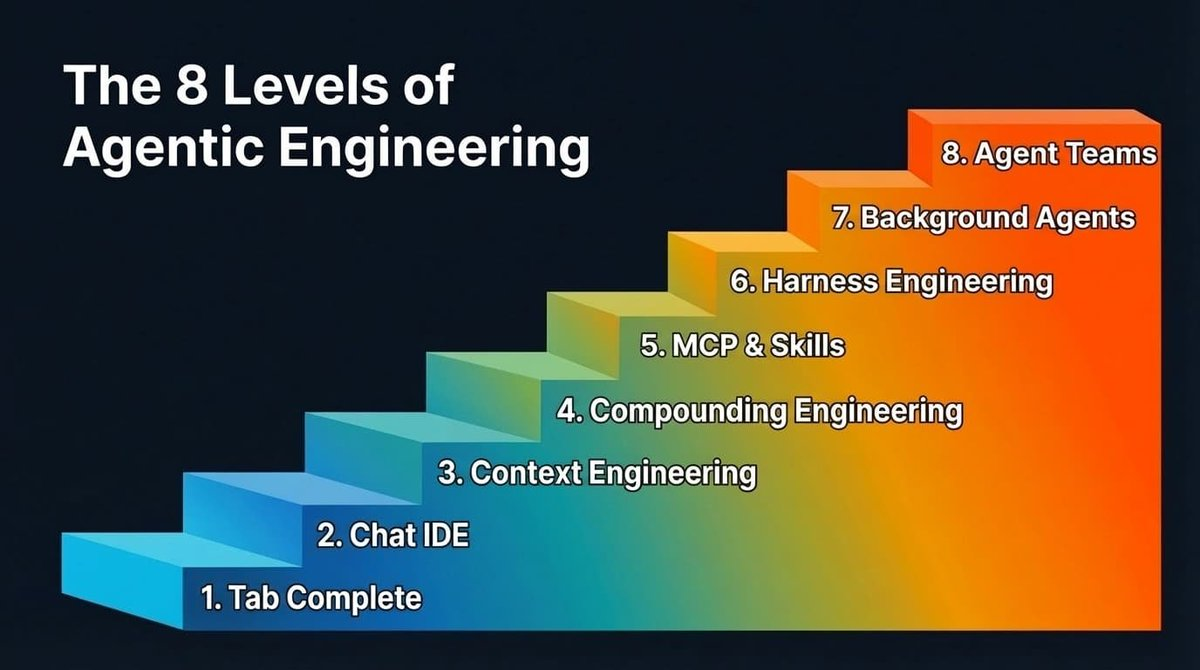
エージェントエンジニアリングの8段階
第1段階および第2段階:Tab補完とエージェント専用IDE
これら2つの段階については、網羅性のためだけに簡単に触れます。必要に応じて読み飛ばして構いません。
Tab補完はすべての出発点です。GitHub Copilotがこの動きの幕開けを告げました——Tabキーを1回押すだけで、コードが自動補完されます。この段階を覚えている人はすでに少なく、新しく業界に入った人の中には、そもそもこの段階を経ずに飛び越えた人もいるかもしれません。これは、コードの骨格をまず自ら構築し、その後AIに細部を埋め込ませるというスタイルに向いており、経験豊富な開発者に最も適しています。
Cursorなど、AIに特化したIDEは状況を一変させました。これらのツールはチャット機能とコードベースを統合し、複数ファイルにまたがる編集をはるかに容易にします。ただし、限界は常にコンテキストにあります。モデルは、自分が「見える」範囲の内容しか処理できません。厄介なのは、正しいコンテキストが見えない場合もあれば、逆に不必要な情報が多すぎて混乱してしまう場合もあることです。
この段階にいる多くの人は、選択したプログラミングエージェントの「プランニングモード」(計画立案モード)も試しています。つまり、ざっくりとしたアイデアを、LLMが理解可能な構造化されたステップごとの計画に変換し、その計画を反復的に改善した後、実行を開始するというやり方です。この段階では十分に有効であり、かつ制御を維持する合理的な方法でもあります。ただし、後の段階で見ていくように、プランニングモードへの依存度は次第に低下していくことになります。
第3段階:コンテキストエンジニアリング
ここからが興味深い部分です。コンテキストエンジニアリング(Context Engineering)は2025年のキーワードとなりました。この概念が登場した背景には、モデルが「ある程度の指示数」を信頼性高く遂行できるようになり、かつ「適切な量のコンテキスト」を伴えるようになったという事実があります。雑然としたコンテキストも、不十分なコンテキストと同じくらい有害です。そのため、核心となる作業は、1トークンあたりの情報密度を高めることにあります。「提示文における各トークンは、自分の位置を正当化するために戦わなければならない」——これが当時の合言葉でした。
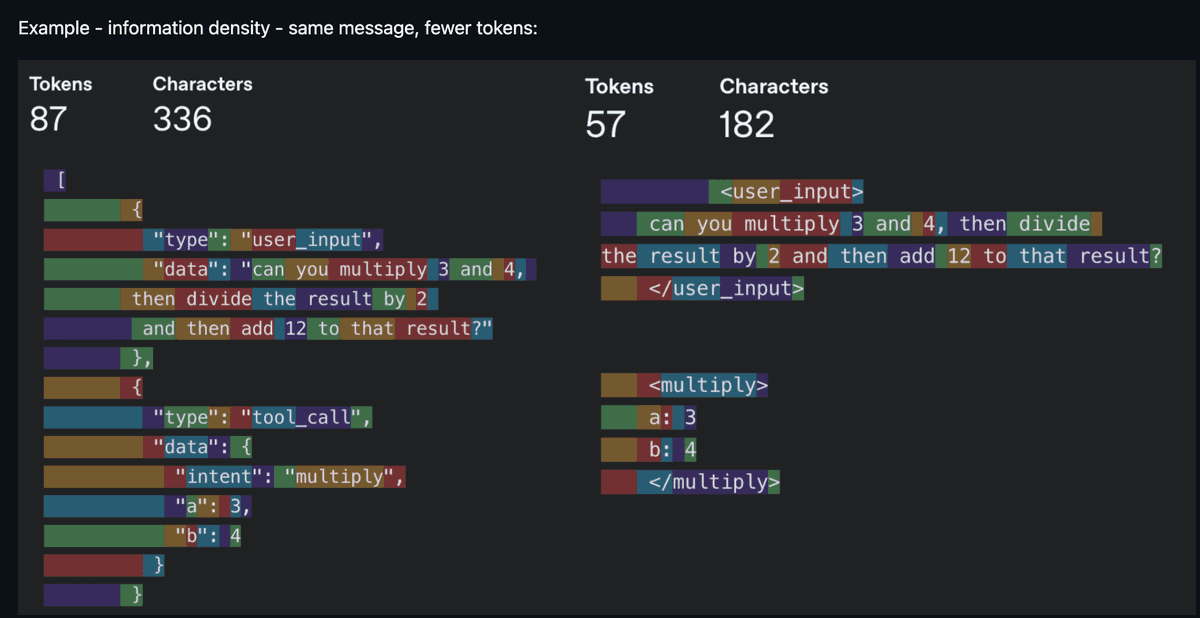
同じ情報を、より少ないトークンで——情報密度こそが王道(出典:humanlayer/12-factor-agents)
実際には、コンテキストエンジニアリングの範囲は、多くの人が認識しているよりも広範に及びます。それは、システムプロンプトやルールファイル(.cursorrules、CLAUDE.mdなど)の設計を含みます。また、ツールの説明文の記述方法も重要です。なぜなら、モデルはそれらの説明を読んで、どのツールを呼び出すべきかを判断するからです。さらに、会話履歴の管理も含まれます。長時間稼働するエージェントが、10ラウンド目の会話で方向を見失わないよう配慮する必要があります。また、各ラウンドでどのツールを提示するかを決定することも重要です。選択肢が多すぎると、モデルは混乱してしまいます——人間と同じです。
現在では、この「コンテキストエンジニアリング」という用語を耳にする機会は減りました。バランスは、より雑然としたコンテキストにも耐え、より混沌とした状況下でも推論できるモデルへと傾き始めています(大きなコンテキストウィンドウも助けになります)。ただし、コンテキストの消費量への注意は依然として重要です。以下のシナリオでは、今でもボトルネックになる可能性があります:
- 小規模モデルはコンテキストに敏感です。音声アプリケーションでは通常小規模モデルが使われ、またコンテキストサイズは初回トークン遅延にも影響し、レスポンスタイムを悪化させます。
- トークン消費量が極端に多いケース。PlaywrightなどのMCP(Model Context Protocol:モデルコンテキストプロトコル)や画像入力は、トークンを急速に消費し、Claude Codeにおいて予期せず早く「圧縮セッション」状態に陥らせます。
- 数十個のツールを接続したエージェントの場合、モデルがツール定義の解析に費やすトークン数が、実際の作業に使うトークン数を上回ってしまうことがあります。
より大局的なポイントは:コンテキストエンジニアリングは消滅したわけではなく、進化しているということです。焦点は、「悪いコンテキストをフィルタリングする」ことから、「正しいコンテキストを正しいタイミングで提供する」ことに移っています。まさにこの転換が、第4段階への道を切り開いたのです。
第4段階:コンパウンディングエンジニアリング
コンテキストエンジニアリングは、現時点での1回の会話の質を改善します。コンパウンディングエンジニアリング(Compounding Engineering、Kieran Klaassen氏が提唱)は、その後のすべての会話の質を改善します。この考え方は、私を含む多くの人にとって転機となりました——「感覚的にプログラミングする」ことが、単なるプロトタイピング以上の意味を持つことを、私たちに気づかせてくれたのです。
これは「計画→委任→評価→定着化」のサイクルです。まずタスクを計画し、LLMが成功するために十分なコンテキストを与えます。次にタスクを委任します。そして、出力結果を評価します。そして最も重要なステップ——得られた知見を「定着化」します:何が有効だったか、どこで問題が起きたか、次回はどのようなパターンに従うべきか、といったことを体系化します。
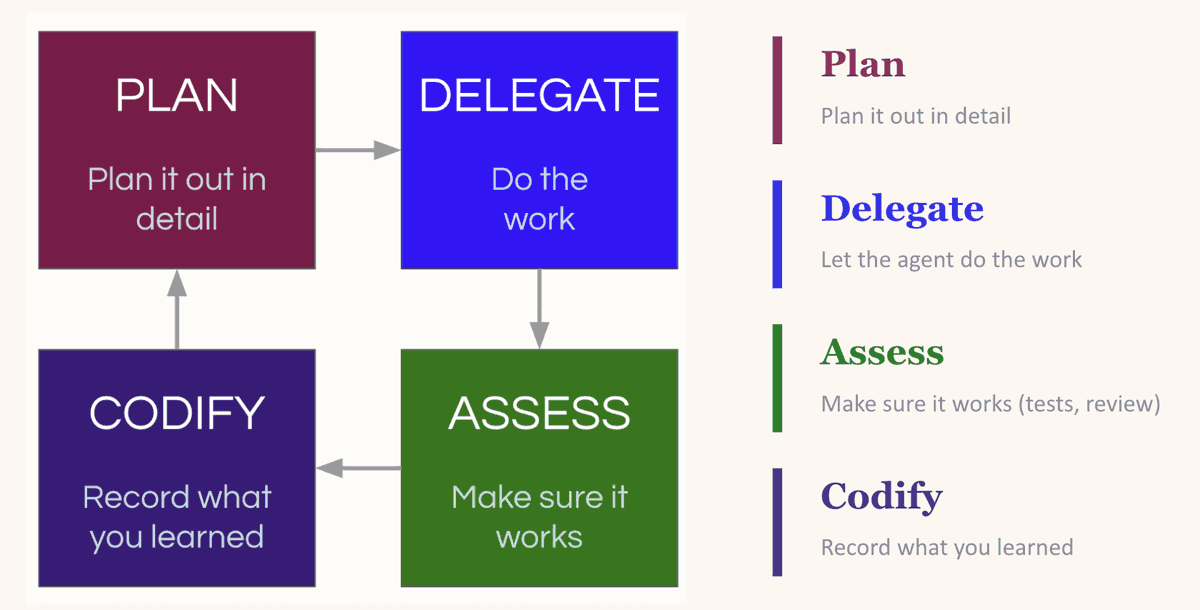
コンパウンディングサイクル:計画・委任・評価・定着化——各ラウンドが次のラウンドをより良くする
その「魔力」はまさに「定着化」にあります。LLMはステートレスです。もし昨日、明確に削除した依存関係を再び導入してしまったなら、明日も同じ間違いを繰り返します——あなたがそれを禁じないとすれば。最も一般的な解決策は、CLAUDE.md(または同等のルールファイル)を更新し、得た教訓を今後のすべての会話に固定化することです。ただし注意が必要です。「なんでもルールファイルに追加しよう」という衝動は、逆効果になる可能性があります(指示が多すぎる=指示がないのと同じ)。より良いアプローチは、LLMが自ら有用なコンテキストを容易に発見できる環境を作ることです——例えば、常に最新の状態を保つdocs/フォルダを整備すること(第7段階で詳しく説明します)。
コンパウンディングエンジニアリングを実践する人々は、LLMに与えるコンテキストに対して非常に敏感です。LLMが誤った出力をしたとき、彼らの直感的な反応は「モデルが悪い」と責めるのではなく、「コンテキストが不足していたのではないか?」と考えることです。こうした直感こそが、第5~第8段階を可能にする基盤となります。
第5段階:MCPとスキル
第3段階と第4段階はコンテキストの課題を解決します。第5段階は「能力」の課題を解決します。MCPおよびカスタムスキルにより、LLMはデータベース、API、CIパイプライン、デザインシステム、ブラウザテスト用Playwright、Slack通知などにアクセスできるようになります。モデルはもはや単にあなたのコードベースを「考える」だけではなく、今やそれを直接「操作」できるようになりました。
MCPおよびスキルに関する優れた資料はすでに多数存在しており、ここではその定義については詳述しません。ただし、私が実際に使用している例をいくつか挙げます。私たちのチームでは、PRレビュー用のスキルを共有し、全員で反復的に改善しています(現在も継続中)。このスキルは、PRの性質に応じて条件付きでサブエージェントを起動します。1つはデータベース統合のセキュリティをチェックし、1つは複雑さ分析を行い冗長性や過剰設計を検出し、もう1つはプロンプトの健康度をチェックして、チームの標準フォーマットに準拠しているかを確認します。また、linterおよびRuffも実行します。
なぜPRレビュー用スキルにこれほど投資するのでしょうか? それは、エージェントがPRを大量に生成し始める際に、人手によるレビューが品質ゲートではなく、むしろボトルネックになってしまうからです。Latent Spaceは、説得力のある主張を展開しています:私たちが知っている従来のコードレビューはすでに死んでいます。その代わりに、自動化され、一貫性を持ち、スキル駆動型のレビューが登場しています。
MCPに関しては、Braintrust MCPを使ってLLMが評価ログを照会し、即座に修正を加えるようにしています。DeepWiki MCPを使えば、オープンソースリポジトリのドキュメントを手動でコンテキストに取り込むことなく、エージェントがいつでもアクセスできます。
チーム内で複数の人が似たようなスキルをそれぞれ独立して作成し始めたら、それらを統合して共用レジストリを作成する価値があります。Block(心よりお悔やみ申し上げます)は、とても優れた記事を公開しています。彼らは内部スキル市場を構築し、100を超えるスキルを提供し、特定の役割やチーム向けにスキルパッケージをキュレーションしています。スキルはコードと同様に扱われ、pull request、レビュー、バージョン履歴が適用されています。
もう1つの注目すべきトレンドは、LLMがMCPではなくCLIツールをますます利用するようになってきていることです(しかも、各社がこぞって独自のものを発表しています:Google Workspace CLI、Braintrustも間もなくリリース予定)。その理由はトークン効率です。MCPサーバーは、各ラウンドで、エージェントが実際に使用するかどうかに関わらず、すべてのツール定義を完全にコンテキストに注入します。一方、CLIは逆に動作します:エージェントが目的に特化したコマンドを実行すると、そのコマンドの関連出力のみがコンテキストウィンドウに入ります。私は、この理由から、Playwright MCPではなくagent-browserを多用しています。
ここで一旦立ち止まりましょう。第3~第5段階は、その後のすべての段階の基礎です。LLMはある種のタスクには驚くほど優れていますが、他のタスクには驚くほど苦手です。これらの境界線に対する直感を養い、その上でさらに自動化を重ねていく必要があります。もしコンテキストが雑然としていたり、プロンプトが不十分・不正確であったり、ツールの説明が曖昧であれば、第6~第8段階はそうした問題をさらに拡大させるだけです。
第6段階:ハーネスエンジニアリング
ロケットが本格的に離陸を始めます。
コンテキストエンジニアリングは「モデルが何を見るか」に焦点を当てます。ハーネスエンジニアリング(Harness Engineering)は、エージェントが人間の介入なしに信頼性高く動作できるよう、ツール、インフラストラクチャ、フィードバックループを含めた「全体の環境」を構築することに焦点を当てます。エージェントに与えるのは単なるエディタではなく、完全なフィードバックループです。
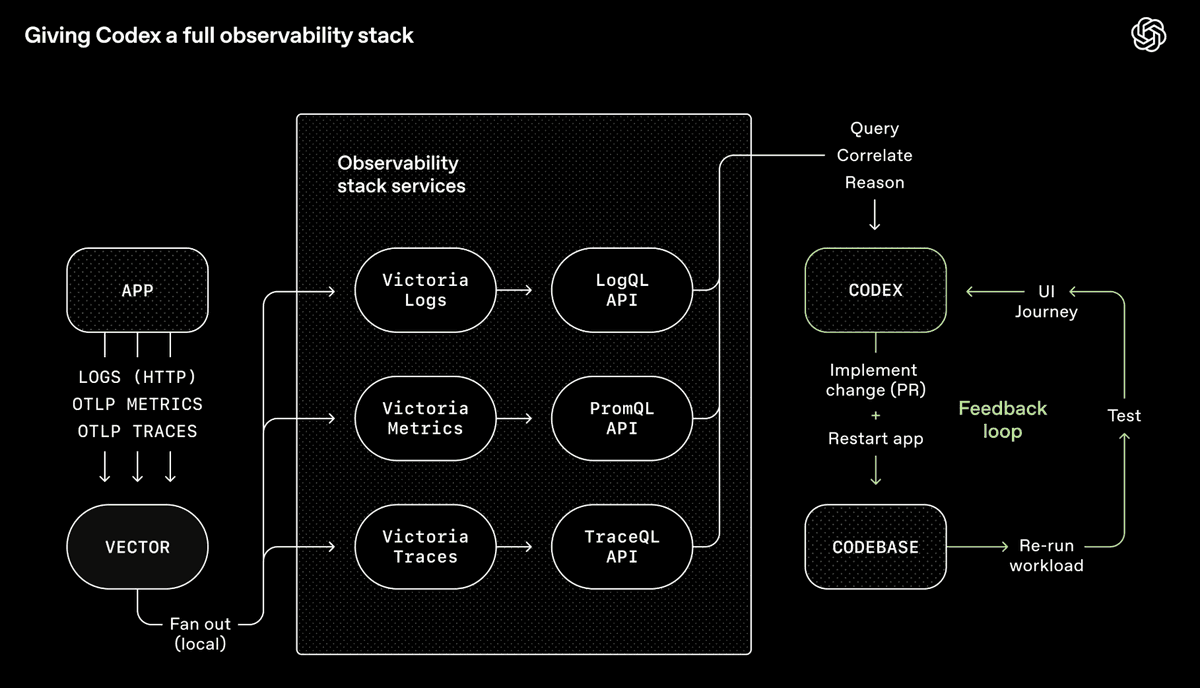
OpenAIのCodexツールチェーン——エージェントが自身の出力を照会・関連付け・推論できる完全な観測性システム(出典:OpenAI)
OpenAIのCodexチームは、Chrome DevTools、観測性ツール、ブラウザナビゲーションをエージェントのランタイムに統合し、スクリーンショット撮影、UIフローの自動操作、ログ照会、修正の検証などが可能にしました。単一のプロンプトを与えるだけで、エージェントはバグを再現し、ビデオを録画し、修正を実装できます。さらに、アプリケーションを操作して修正を検証し、PRを送信し、レビューのフィードバックに応答し、最終的にマージまで行います——判断が必要な場合のみ、人間へ報告します。エージェントは単にコードを書くだけでなく、そのコードがどのような結果を生むかを「見る」ことができ、人間のように反復的に改善を進めます。
私のチームは技術障害のトラブルシューティングを行う音声およびチャットエージェントを開発しています。そこで、任意のLLMがバックエンドAPIと対話し、ラウンド単位で会話できるCLIツール「converse」を作成しました。LLMがコードを修正した後、converseを使ってオンラインシステム上で会話テストを行い、反復的に改善します。このような自己改善ループが数時間にわたって連続して実行されることもあります。結果が検証可能である場合は特に強力です:会話はこのフローに従う必要があり、あるいは特定の状況で特定のツール(例:人間のカスタマーサポートへの転送)を呼び出す必要があります。
これを支える中心的概念はバックプレッシャー(Backpressure)——タイプシステム、テスト、linter、pre-commitフックといった自動化されたフィードバック機構です。これにより、エージェントは人間の介入なしにエラーを検出し、自ら修正することが可能になります。自律性を実現したいなら、バックプレッシャーは必須です。そうでなければ、ただの「ゴミ製造機」になってしまいます。この考え方はセキュリティ分野にも及んでいます。VercelのCTOは指摘しています:エージェント、それらが生成するコード、およびあなたのシークレットは、それぞれ異なる信頼ドメインに配置されるべきです。なぜなら、ログファイルに埋もれた1行のプロンプトインジェクション攻撃が、エージェントにあなたの認証情報を盗むよう誘導してしまう可能性があるからです——もしすべてが同一のセキュリティコンテキストを共有しているならば。セキュリティ境界こそがバックプレッシャーです:それは、エージェントが暴走したときに「何ができるか」を制約するものであり、単に「何をすべきか」を指示するものではありません。
この考え方をさらに明確にする2つの原則があります:
- 完璧さではなくスループットを最適化する。各コミットを完璧にしようとすると、エージェントは同じバグに何度も執着し、互いの修正を上書きしてしまうことがあります。より良いアプローチは、小さな非ブロッキングエラーを許容し、リリース前に最終的な品質チェックを行うことです。人間の同僚に対しても、私たちはそうしています。
- 指示よりも制約を優先する。「まずAを行い、次にBを行い、その後Cを行う」といったステップバイステップの指示は、次第に時代遅れになりつつあります。私の経験では、リスト形式の指示よりも、境界を明確に定義する方が効果的です。なぜなら、エージェントはリストに固執し、リスト外の要素を無視してしまうからです。より良いプロンプトは「これが望む結果であり、すべてのテストに合格するまで繰り返しなさい」です。
ハーネスエンジニアリングのもう半分は、エージェントがコードリポジトリ内で、あなたなしで自由にナビゲートできるようにすることです。OpenAIのアプローチは、AGENTS.mdを約100行以内に収め、他の構造化ドキュメントへの目次として機能させ、ドキュメントの最新性をCIプロセスに組み込むことです。一時的な更新に依存するのではなく、常に最新の状態を保つようにしています。
こうしたすべての仕組みを整えた後、自然と浮かぶ疑問があります:もしエージェントが自身の作業を検証し、リポジトリ内を自在にナビゲートし、あなたを介さずにエラーを修正できるのなら、なぜあなたは椅子に座っている必要があるのでしょう?
ここでひとつ注意:まだ前段階にいる方々にとっては、以降の内容はSF映画のように聞こえるかもしれません(でも大丈夫、まずはブックマークして、後で読み返してください)。
第7段階:バックグラウンドエージェント
辛辣な評価:プランニングモードは衰退しつつあります。
Claude Codeの創設者であるBoris Cherny氏は、現在でも80%のタスクをプランニングモードで開始しています。しかし、各世代の新しいモデルがリリースされるにつれ、プランニング後の1回成功率は継続的に上昇しています。私は、プランニングモードが独立した人間の介入ステップとして、次第に姿を消していくという臨界点に近づいていると見ています。プランニングそのものが不要になるわけではなく、モデルが自分で計画を立てられるほど賢くなったということです。ただし、これは第3~第6段階の作業がきちんと完了しているという前提の上での話です。もしコンテキストがクリーンで、制約が明確で、ツールの説明が充実し、フィードバックループが閉じているなら、モデルはあなたによるレビューなしで信頼性高く計画を立てることができます。これらの準備が整っていなければ、やはりプランニングを監視し続ける必要があります。
明確に述べますが、プランニングという一般概念は消滅しないものの、形態は変化しています。初心者にとっては、プランニングモードは依然として正しい入り口です(第1・第2段階で述べた通り)。しかし、第7段階の複雑な機能においては、「プランニング」とは、ステップごとの概要を書くことではなく、むしろ探査行為になります:コードベースを調査し、worktreeでプロトタイピング実験を行い、解決策の空間を把握することです。そして、こうした探査の多くは、今やバックグラウンドエージェントが代わりに行っています。
これは極めて重要です。なぜなら、それがバックグラウンドエージェントの実現を可能にするからです。もしエージェントが信頼性の高い計画を立て、あなたの承認なしに実行できるなら、あなたが他のことに集中している間にも、非同期で作業を進めることができます。これは決定的な転換です——「私は複数のタブを同時に切り替えている」状態から、「私の関与なしに作業が進行している」状態へと変わります。
Ralphループは人気の入門手法です:自主的なエージェントループで、PRD(製品要件定義書)に記載されたすべての項目が完了するまで、プログラミング用CLIを繰り返し実行します。各反復は、新たなコンテキストを持つ新規インスタンスを起動します。私の経験では、Ralphループをうまく運用するのは容易ではなく、PRD内のいかなる不十分・不正確な記述も、最終的に跳ね返ってきます。ある意味で「投げ出して放置」型のアプローチと言えます。
複数のRalphループを並列実行することもできますが、エージェントの起動数が増えれば増えるほど、あなたの時間の大半がどこに使われているかが明らかになります:それらの調整、作業順序のスケジューリング、出力の確認、進捗の促進です。あなたはもはやコードを書いていません——中間管理職になっています。あなたが意図に集中できるよう、スケジューリングを担当するオーケストレーションエージェントが必要です。
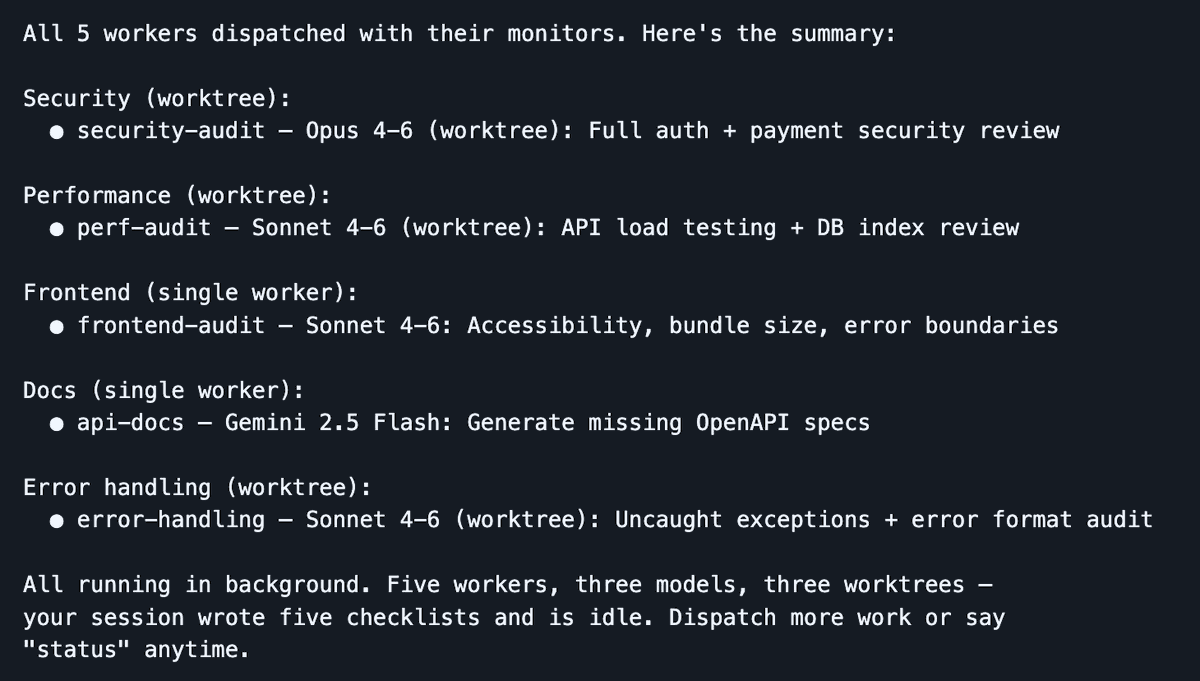
Dispatchは3つのモデルを横断して5つのワーカーを並列起動——あなたの会話はシンプルに保たれ、エージェントが作業を行います
私が最近多用しているツールは、Dispatchです。これは私が開発したClaude Codeスキルで、あなたの会話を指揮センターに変えるものです。あなたはクリーンな1つの会話に留まり、ワーカーが隔離されたコンテキストで重労働をこなします。スケジューラが計画・委任・追跡を担い、あなたのメインコンテキストウィンドウはオーケストレーション専用に確保されます。ワーカーが行き詰まった場合、黙って失敗するのではなく、明確化のための質問を投げかけます。
Dispatchはローカルで実行されるため、開発者が作業と密接に連携したい迅速な開発シーンに最適です:フィードバックが速く、デバッグが容易で、インフラストラクチャのオーバーヘッドがありません。RampのInspectは、より長時間・より自律的な作業に適した補完的ソリューションです:各エージェント会話は、クラウド上のサンドボックスVM内で、完全な開発環境とともに起動されます。PMがUIのバグを発見し、Slackで指摘すると、Inspectがノートパソコンを閉じた瞬間に引き継いで処理を始めます。その代償は運用の複雑さ(インフラ、スナップショット、セキュリティ)ですが、得られるのはローカルエージェントでは実現できないスケールと再現性です。私は両方(ローカルおよびクラウドベースのバックグラウンドエージェント)を併用することを推奨します。
この段階で意外に強力なパターンの1つは、異なるタスクに異なるモデルを割り当てることです。最高のエンジニアリングチームは、クローン人間の集まりではありません。チームメンバーはそれぞれ異なる思考スタイル、異なる訓練背景、異なる強みを持っています。同じ論理がLLMにも適用されます。これらのモデルは異なる後学習を経ており、明確に異なる性格的特徴を持っています。私はよく、Opusを実装作業に、Geminiを探索的研究に、Codexをレビューに割り当て、その総合的な成果を、単一モデルが単独で行う場合よりも高めています。これは「集合知」のコード版と理解できます。
極めて重要なのは、実装者とレビュアーを分離することです。この教訓を私は何度も痛感しました:同じモデルインスタンスが実装と自己評価の両方を担当すると、バイアスが生じます。問題を見落とし、「すべて完了しました」と報告してきます——実際にはそうではありません。これは悪意によるものではなく、あなた自身の試験の採点を自分で行わないのと同じ理由です。レビューは別のモデル(あるいはレビュー専用のプロンプトを備えた別インスタンス)に任せましょう。そうすれば、あなたの信号品質は劇的に向上します。
バックグラウンドエージェントは、CIとAIの融合にも扉を開きます。エージェントが誰の監視もなしに実行可能になった時点で、既存のインフラストラクチャからそれらをトリガーできるようになります。ドキュメンテーションロボットは、毎回のマージ後にドキュメントを再生成し、CLAUDE.mdの更新PRを送信します(実際にこれを運用しており、膨大な時間を節約しています)。セキュリティレビュー用ロボットはPRをスキャンし、修正PRを送信します。依存関係管理ロボットは問題を指摘するだけでなく、実際のパッケージアップグレードとテストスイートの実行も行います。優れたコンテキスト、継続的に定着化されるルール、強力なツール、自動化されたフィードバックループ——これらすべてが今や自律的に稼働しています。
第8段階:自律型エージェントチーム
現時点では、誰もこの段階を完全に掌握していませんが、少数の人々がすでにこの領域に挑戦し始めています。これが現在の最前線です。
第7段階では、オーケストレーション用LLMがハブ・アンド・スポーク(中心放射型)の構造で、作業用LLMにタスクを分散します。第8段階では、このボトルネックが排除されます。エージェント同士が直接協調し、タスクを自ら引き受け、発見を共有し、依存関係を明示し、競合を解決します——すべて単一のオーケストレーターを介さずに行われます。
Claude Codeの実験的機能Agent Teamsは、この初期実装の一例です:複数のインスタンスが共有コードベース上で並列に作業し、チームメイトはそれぞれのコンテキストウィンドウで実行され、直接相互に通信します。Anthropicは、16個の並列エージェントを用いて、ゼロからLinuxをコンパイル可能なCコンパイラを構築しました。Cursorは、数週間にわたり数百の同時実行エージェントを稼働させ、ゼロからブラウザを構築し、自社のコードベースをSolidからReactへと移行させました。
しかし、よく見てみると問題が見えてきます。Cursorは、階層構造がないと、エージェントが臆病になり、原地踏みをしてまったく進展しないことを発見しました。Anthropicのエージェントは、既存機能を繰り返し破壊し続け、リグレッションを防ぐCIパイプラインを追加するまで改善しませんでした。この段階で実験を行っているすべての人は、同じことを言っています:マルチエージェント協調は極めて困難な課題であり、最適解はまだ見つかっていません。
正直に言うと、私は、ほとんどのタスクに対してモデルがこのレベルの自律性を備えているとは思いません。たとえ十分に賢いとしても、コンパイラやブラウザ構築以外の「月面着陸級」プロジェクトでは、依然として遅く、トークン消費が多く、コスト面で非現実的です(印象的ではありますが、決して成熟しているとは言えません)。私たちの日常業務のほとんどにとっては、第7段階こそが真のレバレッジポイントです。第8段階が最終的に主流になることは予想されますが、現時点では、私は第7段階に集中することをおすすめします(Cursorのように、突破そのものが事業の核である場合を除く)。
第?段階
避けられない問い、「次に何が来るのか?」です。
あなたがエージェントチームのオーケストレーションを摩擦なく熟練して行えるようになったとき、インタラクションインターフェースがテキストに限定される理由はなくなります。音声対音声(あるいは思考対思考?)でプログラミングエージェントと対話する——単なる音声認識入力ではなく、会話型のClaude Code——が自然な次のステップです。あなたのアプリケーションを見つめながら、一連の変更を大声で説明し、それらが眼前で実行されるのを見るのです。
完璧なワンショット生成を追求する人々がいます:「欲しいものを伝えれば、AIが一発で完璧に実現してくれる」。しかし、この前提には重大な問題があります。それは、私たち人間が本当に何を望んでいるかを正確に把握しているという仮定です。しかし、実際にはそうではありません。これまで一度も、そうではなかったのです。ソフトウェア開発は常に反復的であり、これからもそうであり続けるでしょう。ただ、それは純粋なテキストインタラクションをはるかに超えて、はるかに簡単で、はるかに高速になるでしょう。
では、あなたはどの段階にいますか? 次の段階に到達するために、何をしていますか?
あなたはどの段階にいますか?
プログラミングタスクを始める際に、普段どのようにAIを活用していますか?
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













