ジェンスン・ファン氏のGTC基調講演全文:推論時代の到来、2027年には売上が最低でも1兆ドルに達する、ロブスターが新しいオペレーティングシステムとなる
TechFlow厳選深潮セレクト
ジェンスン・ファン氏のGTC基調講演全文:推論時代の到来、2027年には売上が最低でも1兆ドルに達する、ロブスターが新しいオペレーティングシステムとなる
NVIDIAは、宇宙空間に展開するデータセンター向けコンピューター「Vera Rubin Space-1」の開発を進めている。これにより、AIの演算能力が地球の外へと拡張されるという想像の余地が一気に広がった。
出典:Wall Street Insights
2026年3月16日、NVIDIA GTC 2026カンファレンスが正式に開幕し、NVIDIA創設者兼CEOのジェンソン・フアン(黄仁勲)氏が基調講演を行った。
「AI業界の年次巡礼」とも称される本カンファレンスにおいて、フアン氏は、NVIDIAが単なる「半導体企業」から「AIインフラおよび工場企業」へと進化したことを強調した。市場が最も関心を持つ業績の持続性および成長余地について、フアン氏は今後の成長を牽引する根本的なビジネスロジック——「トークン工場経済学(Token Factory Economics)」——を詳細に解説した。

業績見通しは極めて楽観的、「2027年には少なくとも1兆ドルの需要」
過去2年間、世界中のAIコンピューティング需要は指数関数的に爆発した。大規模言語モデル(LLM)が「知覚」「生成」から「推論」および「実行(タスク遂行)」へと進化するにつれ、計算リソースの消費量は急激に増加している。市場が特に注目する注文数および売上高の上限について、フアン氏は非常に強気な予測を提示した。
フアン氏は講演で明言した:
「昨年のこの時期、私はBlackwellおよびRubinアーキテクチャ向けに、2026年までに500億ドル規模の高確度需要を見込んでいると述べました。そして、まさに今、ここに立って申し上げますが、2027年までに少なくとも1兆ドル(at least $1 trillion)の需要が見込まれます。」

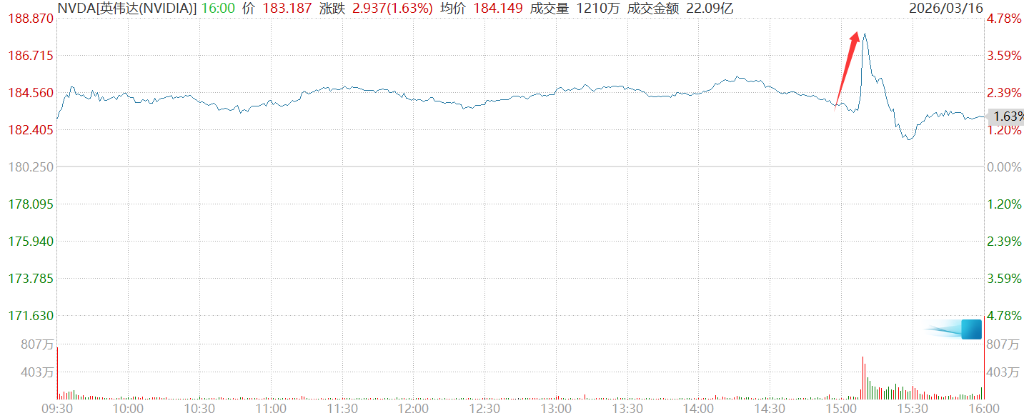
フアン氏の「1兆ドル」予測は、NVIDIA株価を一時4.3%以上押し上げた。
さらに、フアン氏はこの数字について補足説明を行った:
「これは妥当でしょうか?それが次に私がお話しする内容です。実際には、供給が需要に追いつかない状況になるでしょう。私は確信していますが、実際のコンピューティング需要は、これよりもはるかに高くなるでしょう。」
フアン氏は、現在のNVIDIAシステムが世界で「コスト最低のインフラ」として実証済みであると指摘した。NVIDIA製品はあらゆる分野のAIモデルを実行可能であり、この汎用性により、顧客が投入する1兆ドルの投資は十分に活用され、長期にわたって有効に活用できるという。
現時点では、NVIDIAの売上の60%がトップ5の超大手クラウドサービスプロバイダーから生じており、残りの40%は主権クラウド、企業、産業、ロボティクス、エッジコンピューティングなど多様な分野に広がっている。
トークン工場経済学:1ワットあたりのパフォーマンスがビジネスの命運を左右する
この1兆ドル需要の妥当性を説明するため、フアン氏はグローバルな企業CEOたちに対し、全く新しいビジネス思考法を提示した。彼は、将来のデータセンターは単なるファイル保管庫ではなく、AIが生成する基本単位「トークン(Token)」を生産する「工場」であると強調した。

フアン氏は次のように強調した:
「すべてのデータセンター、すべての工場は、定義上、電力供給に制約されます。1GW(ギガワット)の工場が2GWになることは決してありません。これは物理的・原子レベルの法則です。固定された電力制約のもとで、1ワットあたりのトークンスループット(処理能力)が最も高い企業こそが、生産コストを最も低く抑えられるのです。」
フアン氏は、将来のAIサービスを以下の5つの商業レイヤーに分類した:
- 無料層(高スループット、低速度)
- 中級層(約100万トークンあたり3米ドル)
- 上級層(約100万トークンあたり6米ドル)
- 高速層(約100万トークンあたり45米ドル)
- 超高速度層(約100万トークンあたり150米ドル)
彼は、モデルが大型化し、コンテキスト長が延長されるにつれて、AIはより賢くなる一方で、トークン生成速度は低下すると指摘した。フアン氏はこう述べた:
「このトークン工場において、あなたのスループットおよびトークン生成速度は、来年の正確な収益に直結します。」
フアン氏は、NVIDIAのアーキテクチャが、顧客に対して無料層で極めて高いスループットを実現するとともに、最も価値の高い推論レイヤーでは驚異的な35倍のパフォーマンス向上を達成することを強調した。

Vera Rubinで2年間で350倍の加速、Groqで即時推論を実現
このような物理的限界の下、NVIDIAは史上最大規模かつ最も複雑なAIコンピューティングシステム「Vera Rubin」を紹介した。フアン氏は次のように述べた:
「Hopperを紹介する際には、私は一枚のチップを手に取り、『かわいいですね』と言いました。しかしVera Rubinについては、皆さんは『システム全体』を思い浮かべるでしょう。この100%液体冷却で、従来のケーブルを完全に排除したシステムでは、かつて2日かかっていたラックの設置が、わずか2時間で完了します。」
フアン氏によると、究極のエンドツーエンドソフトウェア/ハードウェア連携設計によって、Vera Rubinは同一の1GWデータセンター内で驚異的な性能飛躍を実現したという:
「わずか2年間で、トークン生成速度を2,200万トークン/秒から7億トークン/秒へと、350倍の向上を達成しました。同期間にモアの法則がもたらすのは約1.5倍の改善にすぎません。」
また、即時推論(例:1,000トークン/秒)における帯域幅ボトルネックを解決するため、NVIDIAは買収先のGroq社技術統合の最終的なソリューションとして、「非対称型分離推論(Asymmetric Disaggregated Inference)」を提示した。フアン氏は次のように説明した:
「両プロセッサの特性はまったく異なります。Groqチップには500MBのSRAMが搭載されていますが、Rubinチップには288GBのメモリが備わっています。」

フアン氏は、Dynamoソフトウェアシステムを活用し、「プリフィル(Pre-fill)」段階(膨大な計算およびGPUメモリを要する)をVera Rubinに、遅延に極めて敏感な「デコード(Decode)」段階をGroqに割り当てることで最適化を図っていると指摘した。さらに、企業の計算リソース構成についても提言を行った:
「業務が主に高スループット重視の場合、100%Vera Rubinを採用してください。一方、プログラミングレベルの高価値トークン生成ニーズが大量にある場合、データセンターの25%規模をGroqに割り当てることをお勧めします。」
サムスン社が代工するGroq LP30チップはすでに量産体制に入り、第3四半期からの出荷が予定されている。また、初のVera Rubinラックは既にマイクロソフトAzureクラウド上で稼働を開始している。
さらに、光インターコネクト技術に関しては、フアン氏が世界初の量産型コパッケージド・オプティクス(CPO)スイッチ「Spectrum X」を披露し、「銅線退却・光進出」を巡る路線論争に終止符を打った:
「我々には、より多くの銅線ケーブル生産能力、より多くの光チップ生産能力、より多くのCPO生産能力が必要です。」
Agentが従来型SaaSを終焉へ、シリコンバレーでは「年俸+トークン」が標準に
ハードウェアの壁に加え、フアン氏はAIソフトウェアおよびエコシステムの革命、特にAgent(エージェント)の爆発的普及に大きく焦点を当てた。
彼は、オープンソースプロジェクト「OpenClaw」を「人類史上で最も人気のあるオープンソースプロジェクト」と称し、「Linuxが30年かけて築いた成果を、わずか数週間で上回った」と述べた。フアン氏は、OpenClawが本質的に「エージェントコンピューターのオペレーティングシステム(OS)」であると断言した。
フアン氏はさらにこう断言した:
「すべてのSaaS(Software-as-a-Service)企業は、やがてAaaS(Agent-as-a-Service、エージェント・アズ・ア・サービス)企業へと変貌します。当然のことながら、機密データへのアクセスおよびコード実行機能を備えたエージェントを安全に展開するため、NVIDIAはエンタープライズ向けのNeMo Clawリファレンスデザインを発表し、ポリシーエンジンおよびプライバシールーティング機能を追加した。」
一般の職場人にとっても、この変革はすぐそこまで迫っている。フアン氏は将来の職場の新形態を次のように描いた:
「将来、弊社のすべてのエンジニアには、年間トークン予算が与えられます。基礎となる年俸は数十万ドルですが、それに加えて、その約半額相当の金額をトークン枠として付与し、生産性を10倍に引き上げることが可能になります。すでにこれはシリコンバレーにおける新たな採用戦略となっており、『あなたのオファーにはどれだけのトークンが含まれていますか?』が新たな話題になっています。」
講演の最後に、フアン氏は次世代コンピューティングアーキテクチャ「Feynman」の開発を明らかにした。これは、銅線およびCPOを並列的にスケールアウト可能な初のアーキテクチャとなる。さらに興味深いことに、NVIDIAは宇宙空間に展開するデータセンター用コンピューター「Vera Rubin Space-1」の開発にも着手しており、AIコンピューティング能力を地球外へと拡張するという壮大な構想を示唆した。
フアン氏によるGTC 2026基調講演全文(AIツール補助による翻訳):
司会者:NVIDIA創設者兼CEOのジェンソン・フアン氏の登壇を歓迎いたします。
ジェンソン・フアン氏(創設者兼CEO):
GTCへようこそ。本カンファレンスは技術系イベントであることを、改めてお伝えしたいと思います。朝早くから会場に並ぶ多くの皆様、そしてここにお集まりの皆様にお会いでき、大変嬉しく思います。
GTCでは、技術・プラットフォーム・エコシステムの3つのテーマに焦点を当てます。NVIDIAは現在、CUDA-Xプラットフォーム、システムプラットフォーム、そして最新のAI工場プラットフォームという3つの主要プラットフォームを保有しています。
本講演を始める前に、オープニングセッションの司会者であるConviction社のサラ・グオ氏、シーケンシャル・キャピタルのアルフレッド・リン氏(NVIDIA初のベンチャーキャピタリスト)、そしてNVIDIA初の主要機関投資家であるゲイヴィン・ベイカー氏に感謝申し上げます。この3名の方々は、技術に関する深い洞察を持ち、技術エコシステム全体において極めて広範な影響力をお持ちです。もちろん、本日私自身が招待したすべての特別ゲストの皆様にも、心より感謝申し上げます。このオールスターチームに深謝いたします。
また、本日ご出席いただいたすべての企業の皆様にも感謝申し上げます。NVIDIAはプラットフォーム企業であり、技術・プラットフォーム・豊かなエコシステムを有しています。本日ご出席の企業は、総額100兆ドル規模の産業におけるほぼすべての関係者を代表しており、本カンファレンスには450社がスポンサーとして参加しています。心より御礼申し上げます。
本カンファレンスでは、1,000件の技術セッション、2,000名のスピーカーが登壇し、AIの「5層ケーキ構造」——土地・電力・データセンターなどのインフラから、チップ・プラットフォーム・モデル、そして業界を牽引するアプリケーションに至るまで——のすべてのレイヤーを網羅します。
CUDA:20年にわたる技術蓄積
すべての出発点は、ここにあります。今年はCUDA誕生20周年です。
20年間にわたり、私たちはこのアーキテクチャの開発に一貫して注力してきました。CUDAは革命的な発明であり、SIMT(Single Instruction Multiple Thread)技術により、開発者はスカラー形式のコードを記述し、それをマルチスレッドアプリケーションへと容易に拡張できます。これは、従来のSIMDアーキテクチャと比べてはるかに簡単なプログラミングを可能にします。最近では、テンソルコア(Tensor Core)および現代AIが依存するさまざまな数学演算構造をより簡単にプログラミングできるようにする「Tiles」機能も追加しました。現在、CUDAには数千種類のツール・コンパイラ・フレームワーク・ライブラリが存在し、オープンソースコミュニティには数十万件の公開プロジェクトがあり、すべての技術エコシステムに深く統合されています。
このグラフは、NVIDIAの100%戦略ロジックを示しており、私は当初からこのスライドを用いて説明しています。その中で最も困難かつ最も重要な要素は、グラフの底辺にある「インストールベース(装機量)」です。20年間にわたり、私たちは世界中で数億台のCUDA対応GPUおよびコンピューティングシステムを展開してきました。
当社のGPUはすべてのクラウドプラットフォームをカバーし、ほぼすべてのPCメーカーおよび業界に提供されています。CUDAの巨大なインストールベースこそが、この「フライホイール(飛輪)」を加速させる根本的な原動力です。インストールベースが開発者を惹きつけ、開発者が新たなアルゴリズムを開発・突破し、それによって新市場が生まれ、新市場が新たなエコシステムを形成してさらに多くの企業を引き込み、結果としてインストールベースが拡大する——このフライホイールは今も加速し続けています。
NVIDIAライブラリのダウンロード数は驚異的なスピードで増加しており、その規模と成長率はいずれも急速に拡大しています。このフライホイールにより、当社のコンピューティングプラットフォームは膨大なアプリケーションおよび次々と登場する新たな技術革新を支えることが可能となっています。
さらに重要なのは、これらのインフラストラクチャが極めて長い寿命を持つことです。理由は明白です:NVIDIA CUDA上で動作するアプリケーションは極めて多岐にわたり、AIライフサイクルのすべての段階、あらゆるデータ処理プラットフォーム、そして科学的原理に基づくソルバーに至るまでをカバーしています。そのため、NVIDIA GPUを一度導入すれば、その実用的価値は極めて高いのです。これが、6年前にリリースされたAmpereアーキテクチャのGPUが、クラウド上でむしろ価格が上昇している理由です。
これらすべての根本的な理由は、巨大なインストールベース、強力なフライホイール、広範な開発者エコシステムにあります。これらの要素が相互に作用し、私たちがソフトウェアを継続的に更新することで、コンピューティングコストは不断に低下しています。アクセラレーテッド・コンピューティングはアプリケーションのパフォーマンスを大幅に向上させるとともに、長期的なソフトウェア保守および反復的アップデートにより、ユーザーは初期のパフォーマンス向上に加えて、継続的なコンピューティングコスト削減の恩恵を享受できます。当社は世界中のすべてのGPUに対して長期サポートを提供することを約束します。なぜなら、それらはアーキテクチャ上完全に互換性があるからです。
このような姿勢を取れるのは、インストールベースがこれほど巨大だからです。新しい最適化を1回リリースするだけで、何百万ものユーザーに恩恵が及びます。このようなダイナミックな組み合わせにより、NVIDIAアーキテクチャはカバレッジを拡大し、自らの成長を加速させながら、同時にコンピューティングコストを圧縮し、新たな成長を刺激しています。CUDAは、すべての基盤です。
GeForceからCUDAへ:25年にわたる進化の道のり
そして、私たちのCUDAとの旅は、実は25年前から始まっています。
GeForce——おそらくここにいらっしゃる多くの方々は、GeForceとともに育ってきたことでしょう。GeForceはNVIDIA史上最も成功したマーケティングプロジェクトです。当社は、まだ皆さんが製品を購入できない時代から、将来の顧客を育て始めました。つまり、皆さんの親御さんたちが、NVIDIAの最初のユーザーとなり、毎年製品を購入し続け、ついには皆さんが優秀なコンピューターサイエンティストとして成長し、真の意味での顧客および開発者となったのです。
これが25年前のGeForceが築いた基盤です。25年前、当社はプログラマブルシェーダーを発明しました。これは、アクセラレーターをプログラマブル化するという、一見シンプルながらも画期的な発明であり、世界初のプログラマブルアクセラレーター、すなわちピクセルシェーダーでした。それから5年後、当社はCUDAを創造しました。これは、当社史上で最も重要な投資の一つです。当時は資金に限りがあったにもかかわらず、当社は利益のほとんどをこのプロジェクトに賭け、CUDAをGeForceからあらゆるコンピューターへと拡張することを決意しました。そのような強い信念を持てたのは、その可能性を深く信じていたからです。初期には苦難もありましたが、当社は13世代、つまり20年間この信念を貫き、今やCUDAはどこにでも存在しています。
ピクセルシェーダーこそがGeForceの革命を推進しました。そして約8年前、当社はRTXを発表しました。これは、現代コンピューターグラフィックス時代に向けたアーキテクチャの大規模な刷新です。GeForceはCUDAを世界中に広め、そのおかげでAlex Krizhevsky氏、Ilya Sutskever氏、Geoffrey Hinton氏、Andrew Ng氏といった多くの研究者が、GPUがディープラーニングを加速するための強力なツールであることに気づき、10年前のAI大爆発を引き起こしました。
10年前、当社はプログラマブルシェーディングに2つの新たな概念を融合させることを決めました。1つはハードウェア・レイ・トレーシング(Ray Tracing)で、これは技術的に極めて困難な課題でした。もう1つは、当時としては非常に先見性の高い考え——約10年前から、AIがコンピューターグラフィックスを完全に変革することを予見していたのです。GeForceがAIを世界中に広めたのと同様に、AIは今やコンピューターグラフィックスの実現方法を逆に再構築しようとしています。
今日は、未来をお見せしましょう。これは当社の次世代グラフィック技術であり、「ニューラルレンダリング(Neural Rendering)」と呼ばれます——3DグラフィックスとAIの深度融合です。これがDLSS 5です。ご覧ください。
ニューラルレンダリング:構造化データと生成AIの融合
これは驚嘆すべきものではありませんか?コンピューターグラフィックスは、まさに息を吹き返しました。
我々は何をしたのか?我々は、制御可能な3Dグラフィックス(仮想世界の真の基盤)とその構造化データを結合し、さらに生成AIおよび確率的計算を取り入れました。一方は完全に決定論的であり、他方は確率的ではあるものの極めてリアルです。我々はこの2つの概念を融合し、構造化データによって正確かつ制御可能な表現を実現しながら、リアルタイムでの生成を可能にしました。その結果、コンテンツは美しく驚くべきものでありながら、完全に制御可能です。
構造化情報と生成AIの融合という考え方は、次々と異なる業界で再現されていくでしょう。構造化データは、信頼性の高いAIの基盤です。
構造化データと非構造化データのアクセラレーション・プラットフォーム
次に、技術アーキテクチャ図をご覧いただきます。
構造化データ——SQL、Spark、Pandas、Velox、Snowflake、Databricks、Amazon EMR、Azure Fabric、Google BigQueryなど、皆様がよくご存知の主要プラットフォームは、すべて「データフレーム(Data Frame)」を処理しています。これらのデータフレームは、巨大な電子スプレッドシートのようなもので、ビジネス世界のすべての情報を担っており、企業コンピューティングの基本的事実(Ground Truth)です。
AI時代には、AIが構造化データを活用し、それを極限まで高速化する必要があります。これまで、構造化データ処理の高速化は、企業の運用効率向上を目的としていました。しかし将来、AIは人間をはるかに凌ぐスピードでこれらのデータ構造を活用し、AIエージェントも大量に構造化データベースを呼び出すことになります。
非構造化データに関しては、ベクトルデータベース、PDF、動画、音声などが世界のデータの大多数を占めています——年間生成されるデータの約90%が非構造化データです。過去には、これらのデータはほとんど利用されていませんでした。我々はそれらを読み込み、ファイルシステムに保存するだけでした。検索も困難であり、非構造化データには単純なインデックス方式がなく、その意味と文脈を理解しなければならないためです。しかし今、AIがこれを可能にしています——マルチモーダルな感覚および理解技術により、AIはPDFドキュメントを読み取り、その意味を理解し、クエリ可能なより大きな構造に埋め込むことができるのです。
NVIDIAは、このために2つの基盤ライブラリを構築しました:
- cuDF:データフレームおよび構造化データの高速化処理用
- cuVS:ベクトルストレージ、意味的データおよび非構造化AIデータの処理用
この2つのプラットフォームは、将来最も重要な基盤プラットフォームの一つとなるでしょう。
本日、当社は複数の企業との提携を発表します。IBM——SQL言語の発明者——は、WatsonX Dataプラットフォームの高速化にcuDFを採用します。Dell社とは共同でDell AIデータプラットフォームを構築し、cuDFおよびcuVSを統合、NTT Dataの実際のプロジェクトで大幅なパフォーマンス向上を実現しました。Google Cloudでは、Vertex AIだけでなくBigQueryの高速化も行い、Snapchatとの協業により、計算コストを約80%削減しました。
アクセラレーテッド・コンピューティングがもたらすメリットは三位一体です:速度・スケール・コスト。これはモアの法則と一脈相通じるものであり——アクセラレーテッド・コンピューティングによって性能を飛躍的に向上させ、同時にアルゴリズムを継続的に最適化することで、誰もが継続的に低下するコンピューティングコストの恩恵を享受できるのです。
NVIDIAはアクセラレーテッド・コンピューティング・プラットフォームを構築し、その上にはRTX、cuDF、cuVSなど多数のライブラリが集積されています。これらのライブラリは、世界中のクラウドサービスおよびOEM体系に統合され、全世界のユーザーに届けられています。
クラウドサービスプロバイダーとの深層連携
主要クラウドサービスプロバイダーとの連携
Google Cloud:Vertex AIおよびBigQueryの高速化を実施、JAX/XLAと深く統合、PyTorch上でも卓越したパフォーマンスを発揮——NVIDIAは、PyTorchおよびJAX/XLAの両方で優れたパフォーマンスを発揮する唯一のアクセラレーターです。Base10、CrowdStrike、Puma、Salesforceなどの顧客をGoogle Cloudエコシステムに導入しています。
AWS:EMR、SageMaker、Bedrockの高速化を実施、AWSと深く統合。今年特に楽しみにしているのは、OpenAIをAWSに導入することです。これにより、AWSのクラウドコンピューティング消費量が大幅に増加し、OpenAIの地域展開およびコンピューティング規模の拡大を支援します。
Microsoft Azure:NVIDIAの100 PFLOPSスーパーコンピューターは、当社が構築した初のスーパーコンピューターであり、Azure上に最初に展開されたスーパーコンピューターでもあります。これは、OpenAIとの協業の重要な基盤を築きました。AzureクラウドサービスおよびAI Foundryの高速化を実施、Azure地域展開の協力を進め、Bing検索でも深く協業しています。特に注目に値するのは、**秘匿コンピューティング(Confidential Computing)**機能です——事業者がユーザーのデータおよびモデルを一切閲覧できないことを保証する機能——NVIDIA GPUは、世界で初めてこの秘匿コンピューティングをサポートするGPUであり、OpenAIおよびAnthropicのモデルを世界中の各クラウド環境で秘匿的に展開することが可能です。Synopsys社の例では、当社はそのすべてのEDAおよびCADワークロードを高速化し、Microsoft Azure上に展開しています。
Oracle:当社はOracleの最初のAI顧客であり、私がOracleに初めてAIクラウドの概念を説明できたことを誇りに思います。その後、Oracleは急速に成長し、当社はCohere、Fireworks、OpenAIなど多数のパートナーを導入しました。
CoreWeave:世界初のAIネイティブクラウドで、GPUホスティングおよびAIクラウドサービスに特化し、優れた顧客基盤と強力な成長勢力を有しています。
Palantir+Dell:三者が共同で、PalantirのオントロジープラットフォームおよびAIプラットフォームを基盤とする新たなAIプラットフォームを構築しました。これは、あらゆる国・あらゆるエアギャップ隔離環境下で、完全にローカライズされたAIを——データ処理(ベクトル化または構造化)からAIに至る全アクセラレーテッド・コンピューティング・スタックまで——包括的に展開することが可能です。
NVIDIAは、世界中のクラウドサービスプロバイダーとこのような特別な協業関係を築いています——当社は顧客をクラウドへと導入し、これは双方に利益をもたらす共生的エコシステムです。
縦横一体:NVIDIAの核心戦略
NVIDIAは、世界で初めて「縦横一体(Vertical Integration & Horizontal Openness)」を実現した企業です。
このモデルの必要性は極めて単純です:アクセラレーテッド・コンピューティングは、単なるチップの問題でもなければ、単なるシステムの問題でもありません。その完全な表現は「アプリケーションのアクセラレーション」です。CPUはコンピューター全体の動作を高速化できますが、この道はすでに限界に達しています。将来は、アプリケーションあるいは特定ドメインに特化したアクセラレーションのみが、持続的な性能向上およびコスト削減をもたらすのです。
これが、NVIDIAが1つ1つのライブラリ、1つ1つのドメイン、1つ1つの垂直産業に深く掘り下げていく必然性です。当社は縦横一体のコンピューティング企業であり、他に選択肢はありません。当社はアプリケーションを理解し、ドメインを理解し、アルゴリズムを深く理解し、データセンター・クラウド・オンプレミス・エッジ・ロボットシステムなどあらゆる環境にそれを展開できる必要があります。
同時に、NVIDIAは横の開放性を維持し、自社技術をあらゆるパートナーのプラットフォームに統合することを歓迎し、世界中の誰もがアクセラレーテッド・コンピューティングの恩恵を享受できるようにしています。
本GTCの参加者構成は、これを如実に示しています。今回の参加者の中で最も比率が高いのは金融サービス業界です——開発者の方々が来られることを願っています、トレーダーの方々ではありません。当社のエコシステムはサプライチェーンの上流および下流をカバーしています。設立50年、70年、150年を迎える企業が、昨年はいずれも歴史最高の年となりました。我々は、非常に非常に大きな何かの始まりに立っているのです。
CUDA-X:各業界のアクセラレーテッド・コンピューティング・エンジン
NVIDIAは、あらゆる垂直産業においてすでに深く浸透しています:
- 自動運転:広範かつ深い影響
- 金融サービス:定量投資が、従来の人為的特徴量エンジニアリングから、スーパーコンピューター駆動のディープラーニングへと移行し、その「Transformerの瞬間」を迎えている
- ヘルスケア:独自の「ChatGPTの瞬間」を迎えつつあり、AI支援薬剤発見、AIエージェントによる診断支援、医療カスタマーサポートなど多方面で展開
- 産業:世界最大規模の建設ブームが進行中であり、AI工場、半導体工場、データセンター工場が次々と建設されている
- エンターテインメントおよびゲーム:リアルタイムAIプラットフォームが翻訳、ライブ配信、ゲームインタラクション、スマートショッピングエージェントなどをサポート
- ロボティクス:10年以上にわたる深耕により、訓練コンピューター、シミュレーションコンピューター、搭載コンピューターという3つのコンピューター・アーキテクチャを完備。本展示会には110台のロボットが登場
- 通信:約2兆ドル規模の産業であり、基地局は単なる通信機能からAIインフラプラットフォームへと進化しており、そのプラットフォーム名は「Aerial」。ノキア、T-Mobileなどとの深層連携が進行中
以上のすべての分野の核となるのが、当社のCUDA-Xライブラリ——これはNVIDIAがアルゴリズム企業としての本質を示すものです。これらのライブラリは、当社の最も重要な資産であり、コンピューティングプラットフォームが各業界で実際の価値を発揮するための鍵となります。
その中でも最も重要なライブラリの1つが、cuDNN(CUDA Deep Neural Network Library)であり、これはAIを完全に革新し、現代AIの大爆発を引き起こしました。
(CUDA-Xデモンストレーション動画再生)
さきほどご覧いただいたすべてのものは、シミュレーションです——物理原理に基づくソルバー、AIエージェント物理モデル、物理AIロボットモデルなど、すべてがシミュレーションです。手作業によるアニメーションやジョイントバインディングは一切使用していません。これがNVIDIAの核心的能力です:アルゴリズムに対する深い理解とコンピューティングプラットフォームの緊密な融合により、これらの機会を解き放つのです。
AIネイティブ企業と新計算時代
さきほど、ウォルマート、ロレアル、JPモルガン、ロシュ、トヨタなど、現代社会を定義する業界の巨人たち、そして皆さんが聞いたことのない企業——当社が「AIネイティブ企業」と呼ぶ企業——をご覧いただきました。このリストは非常に大きく、OpenAI、Anthropic、そしてさまざまな垂直産業に特化した新興企業が含まれています。
過去2年間、この業界は驚くべき飛躍を遂げました。スタートアップ企業へのベンチャーキャピタル投資額は1,500億ドルに達し、人類史上最高を記録しました。さらに重要なのは、単一投資額が、これまでの数百万ドルから、数億ドル乃至数十億ドルへと一気に跳躍したことです。その理由はただ1つ:これは史上初めて、こうした企業すべてが大量のコンピューティングリソースおよび大量のトークンを必要とするからです。この業界はトークンを創出し・生成するか、あるいはAnthropic、OpenAIなどから供給されるトークンの価値を高めているのです。
PC革命、インターネット革命、モバイル・クラウド革命がそれぞれ時代を画する企業を生み出したのと同様に、この世代のコンピューティングプラットフォームの変革も、将来の世界を形作る極めて影響力のある企業を生み出すでしょう。
これらを推進する3つの歴史的ブレイクスルー
過去2年間、一体何が起きたのでしょうか?3つの出来事があります。
第一に:ChatGPT——生成AI時代の幕開け(2022年末~2023年)
これは、単に知覚・理解するだけでなく、独自のコンテンツを生成できるようになりました。私は、生成AIとコンピューターグラフィックスの融合をご紹介しました。生成AIは、計算の本質を根本的に変えました——計算は検索中心から生成中心へと移行し、これはコンピューターアーキテクチャ、展開方法、そしてその全体的な意味に深く影響を与えています。
第二に:推論AI(Reasoning AI)——o1を代表例として
推論能力により、AIは自己反省・計画立案・問題分解ができるようになりました——直接理解できない問題を、処理可能なステップに分解します。o1は、生成AIを信頼できるものにし、現実の情報をもとに推論を行うことを可能にしました。そのため、入力コンテキストのトークン数および思考に使う出力トークン数が大幅に増加し、計算量も著しく増大しました。
第三に:Claude Code——初のエージェントモデル
これは、ファイルを読み取り、コードを書き、コンパイルし、テストし、評価し、反復する能力を持っています。Claude Codeはソフトウェアエンジニアリングを完全に革新しました——NVIDIAのエンジニア100%が、Claude Code、Codex、Cursorのいずれか、あるいは複数を活用しています。AIの助けなしに仕事をするソフトウェアエンジニアは、一人もいません。
これはまったく新しい転換点です——あなたはもはやAIに「何であるか、どこにあるか、どうするか」を尋ねるのではなく、「作成し、実行し、構築する」ことを求め、AIにツールの利用、ファイルの読み取り、問題の分解、行動の実行を積極的にさせるのです。AIは、知覚から生成へ、さらに推論へ、そして今や本当に仕事を遂行できる段階へと進化しました。
過去2年間で、推論に必要な計算量は約10,000倍、使用量は約100倍増加しました。私は常に、過去2年間の計算需要は100万倍増加したと考えています——これはすべての人の共通認識であり、OpenAIの認識であり、Anthropicの認識でもあります。より多くの計算リソースを得れば、より多くのトークンを生成でき、収益が上がり、AIはさらに賢くなります。推論の転換点はすでに到来しています。
1兆ドル規模のAIインフラ時代
昨年のこの時期、私はここで、BlackwellおよびRubinアーキテクチャに対する2026年までの需要および受注について、約500億ドル規模の高確度見通しを示しました。そして、GTCから1年後の今日、私はここでこう申します:2027年までの需要は、少なくとも1兆ドルです。そして私は確信していますが、実際の計算需要は、これよりもはるかに大きくなるでしょう。
2025年:NVIDIAの推論元年
2025年はNVIDIAの「推論元年(Year of Inference)」です。当社は、トレーニングおよびポストトレーニングに加えて、AIライフサイクルのすべての段階において卓越したパフォーマンスを確保することを目指しています。これにより、既に投資されたインフラストラクチャが継続的に効率的に稼働し、有効寿命が長くなればなるほど、単位コストは低下します。
同時に、AnthropicおよびMetaが正式にNVIDIAプラットフォームに加入し、これらは世界のAI計算需要の約3分の1を代表しています。オープンソースモデルは最先端水準に近く、どこにでも存在しています。
NVIDIAは、現在、世界で唯一、言語・生物学・コンピューターグラフィックス・コンピュータービジョン・音声・タンパク質・化学・ロボティクスなど、あらゆるAI分野のすべてのAIモデルを実行可能なプラットフォームです。エッジでもクラウドでも、どの言語でも実行可能です。NVIDIAアーキテクチャは、これらすべてのシナリオに対して汎用性を持ち、これが当社をコスト最低・信頼度最高のプラットフォームにしています。
現在、NVIDIAの売上の60%は世界のトップ5の超大手クラウドサービスプロバイダーから生じており、残りの40%は地域クラウド、主権クラウド、企業、産業、ロボティクス、エッジコンピューティングなど多様な分野に広がっています。AIの広範なカバレッジこそが、そのレジリエンス(耐障害性)の源です——これは、間違いなく新たなコンピューティングプラットフォームの変革です。
Grace BlackwellおよびNVLink 72:大胆なアーキテクチャ革新
Hopperアーキテクチャが絶頂期にあったとき、当社はシステムを完全に再設計し、NVLinkを8リンクからNVLink 72へと拡張し、コンピューティングシステムを全面的に再構築することを決断しました。Grace Blackwell NVLink 72は、大きな技術的賭けであり、すべてのパートナーにとって容易ではない挑戦でしたが、ここに心から感謝申し上げます。
同時に、当社はNVFP4——単なるFP4ではなく、まったく新しいタイプのテンソルコアおよび計算ユニット——を発表しました。当社は、NVFP4が精度損失なしに推論を実行できることを実証し、巨大なパフォーマンス向上およびエネルギー効率向上を実現したばかりか、トレーニングにも適用可能であることを確認しました。さらに、DynamoおよびTensorRT-LLMなど一連の新アルゴリズムが登場し、最適化カーネルのために数十億ドルを投じてDGX Cloudと呼ばれるスーパーコンピューターを専用に構築しました。
その結果、当社の推論パフォーマンスは目を見張るものとなりました。Semi Analysis社のデータ——これは、これまでで最も包括的なAI推論パフォーマンス評価——によると、NVIDIAは1ワットあたりトークン数および1トークンあたりコストの2つの次元で、圧倒的なリードを保っています。モアの法則がH200に与える可能性のある1.5倍の性能向上に対し、当社は35倍を達成しました。Semi Analysisのディラン・パテル氏は、「ジェンソンは控えめに発表した。実際は50倍だ」とさえ述べました。その通りです。
私はここで引用します:「Jensen sandbagged(ジェンソンは控えめに発表した)。」
NVIDIAの1トークンあたりコストは、世界で最も低く、現在誰もが追随できません。その理由は、究極の協調設計(Extreme Co-design)にあります。
Fireworks社の例では、NVIDIAがソフトウェアおよびアルゴリズムを全面的に更新する前は、平均トークン速度は約700トークン/秒でしたが、更新後は約5,000トークン/秒に近づき、約7倍の向上を実現しました。これが究極の協調設計の力です。
AI工場:データセンターからトークン工場へ
データセンターは、かつてファイルを保存する場所でしたが、今やトークンを生産する工場です。すべてのクラウドサービスプロバイダー、すべてのAI企業は、将来「トークン工場効率」をコアの経営指標として採用します。
これが私の核心論点です:
- 縦軸:スループット(Throughput)——固定電力下での1秒あたりトークン生成数
- 横軸:インタラクション速度(Token Speed)——各推論のレスポンス速度。速度が速いほど、使用可能なモデルは大型化し、コンテキストは長くなり、AIはより賢くなります
トークンは新たなコモディティであり、成熟すれば、階層別に価格設定されます:
- 無料層(高スループット、低速度)
- 中級層(約100万トークンあたり3米ドル)
- 上級層(約100万トークンあたり6米ドル)
- 高速層(約100万トークンあたり45米ドル)
- 超高速度層(約100万トークンあたり150米ドル)
Hopperと比較して、Grace Blackwellは最も価値の高い層で35倍のスループット向上を実現し、まったく新しい層を導入しました。簡略化したモデルで試算すると、4つの層にそれぞれ25%の電力を割り当てた場合、Grace BlackwellはHopperよりも5倍の収益を生み出すことができます。
Vera Rubin:次世代AIコンピューティング・システム
(Vera Rubinシステム紹介動画再生)
Vera Rubinは、エージェント(Agentic)ワークロード専用に設計された、完全にエンドツーエンド最適化されたシステムです:
- 大規模言語モデル計算コア:NVLink 72 GPUクラスターで、プリフィル(Prefill)およびKVキャッシュを処理
- 全新Vera CPU:極めて高い単一スレッド性能を追求し、LPDDR5メモリを採用、卓越したエネルギー効率を実現。世界で唯一LPDDR5を採用するデータセンターCPUであり、AIエージェントのツール呼び出しに最適
- ストレージシステム:BlueField 4+CX 9、AI時代のための全新ストレージプラットフォーム。世界のストレージ業界が100%参画
- CPO Spectrum Xスイッチ:世界初のコパッケージド・オプティクスイーサネットスイッチで、すでに全面量産中
- Kyberラック:全新ラックシステムで、144個のGPUを単一NVLinkドメインに統合可能。フロントエンドで計算、バックエンドでNVLinkスイッチングを行い、1台の巨大コンピューターを構成
- Rubin Ultra:次世代スーパーコンピューターノードで、縦挿式設計。Kyberラックと組み合わせることで、さらに大規模なNVLink相互接続を可能に
Vera Rubinは100%液体冷却を採用し、設置時間が2日から2時間へと短縮され、45℃の温水冷却を採用することで、データセンターの冷却負荷を大幅に低減します。この点について、サティア(ナデラ)氏が既に投稿を発表しており、初のVera RubinラックがマイクロソフトAzure上で稼働を開始したことが確認されています。これには、私は非常に興奮しています。
Groqの統合:推論パフォーマンスの究極の延長
当社はGroqチームを買収し、その技術ライセンスを取得しました。Groqは、決定論的データフロー・プロセッサ(Deterministic Dataflow Processor)であり、静的コンパイルおよびコンパイラスケジューリングを採用し、大量のSRAMを搭載、単一の推論ワークロードに最適化された、極めて低い遅延と極めて高いトークン生成速度を実現します。
しかし、Groqのメモリ容量は限定的であり(500MBのオンチップSRAM)、大規模モデルのパラメーターおよびKVキャッシュを独立して処理するには不十分であり、大規模展開に制約がありました。
その解決策が、Dynamo——推論スケジューリングソフトウェア——です。当社はDynamoを用いて、推論パイプラインを分解(Disaggregate)します:
- **プリフィル(Prefill)およびアテンション機構のデコード(Decode)**はVera Rubin上で実行(大量の計算リソースおよびKVキャッシュ記憶域を必要)
- **フィードフォワードネットワークデコード(Feed-Forward Network Decode)**、すなわちトークン生成部分はGroq上で実行(極めて高い帯域幅および極めて低い遅延を必要)
両者はイーサネットで緊密に結合され、特殊なモードにより遅延を約半分に削減します。Dynamoという「AI工場のオペレーティングシステム」の統一スケジューリングの下で、全体のパフォーマンスは35倍向上し、NVLink 72では到達できなかった新たな推論パフォーマンスレベルを開拓しました。
GroqとVera Rubinの組み合わせに関する推奨事項:
- ワークロードが主に高スループット重視の場合、100%Vera Rubinを使用
- コード生成など高価値トークン生成のワークロードが大量にある場合、Groqを導入することを推奨。推奨比率は、約25%Groq+75%Vera Rubin
Groq LP30はサムスン社が代工し、すでに量産体制に入り、Q3からの出荷が予定されています。サムスン社の全面的な協力に感謝します。
推論パフォーマンスの歴史的飛躍
これまでの技術進歩を数値化すると:2年間で、1ギガワットAI工場のトークン生成速度は、2,200万トークン/秒から7億トークン/秒へと、350倍の向上を達成しました。これが究極の協調設計の力です。
技術ロードマップ
- Blackwell:現在量産中。Oberon標準ラックシステム。銅線によるNVLink 72拡張、およびオプションの光拡張によるNVLink 576拡張
- Vera Rubin(現在):Kyberラック、NVLink 144(銅線);Oberonラック、NVLink 72+光拡張、NVLink 576まで拡張可能;Spectrum 6、世界初のCPOスイッチ
- Vera Rubin Ultra(近日発表予定):新世代Rubin Ultra GPU、LP35チップ(NVFP4を初搭載)、さらに数倍のパフォーマンス向上
- Feynman(次世代):全新GPU、LP40チップ(NVIDIAとGroqチームが共同開発、NVFP4搭載);全新CPU——Rosa(ロザリン);BlueField 5;CX 10;Kyberラック(銅線およびCPOの両方をサポートするスケールアップ/スケールアウト方式)
ロードマップは明確です:銅線拡張、光拡張(スケールアップ)、光拡張(スケールアウト)の3つのルートを並行して推進します。我々には、すべてのパートナーが銅線、光ファイバー、CPOの生産能力を継続的に拡大することが求められています。
NVIDIA DSX:AI工場のデジタルツイン・プラットフォーム
AI工場はますます複雑化していますが、それを構成するさまざまな技術サプライヤーは、これまで設計段階で協業したことがなく、データセンターで初めて「出会う」のが常でした——これは明らかに不十分です。
このため、当社はOmniverseおよびその上に構築されたNVIDIA DSXプラットフォームを作成しました——これは、すべてのパートナーが仮想世界で共同でギガワット規模のAI工場を設計・運用できるプラットフォームです。DSXは以下を提供します:
- ラックレベルの機械・熱・電気・ネットワークシミュレーションシステム
- 電力網との接続による協調省エネスケジューリング
- Max-Qに基づくデータセンター内での動的電力および冷却最適化
保守的な見積もりでは、このシステムによりエネルギー利用効率が約2倍向上し、当社が議論している規模において、これは非常に大きな利益となります。Omniverseはデジタルアースから始まり、あらゆる規模のデジタルツインを支えることになります。当社は世界中のパートナーとともに、人類史上最大のコンピューターを構築しています。
さらに、NVIDIAは宇宙分野へ進出しています。Thorチップは放射線認証を通過し、衛星上で稼働しています。当社はパートナーとともに、宇宙データセンターの構築を目的とした「Vera Rubin Space-1」の開発を進めています。宇宙では放射線による放熱しかできないため、熱管理が核心的な課題であり、当社は世界トップクラスのエンジニアを集結させて取り組んでいます。
OpenClaw:エージェント時代のオペレーティングシステム
ペーター・シュタインベルガー氏が「OpenClaw」というソフトウェアを開発しました。これは人類史上で最も人気のあるオープンソースプロジェクトであり、わずか数週間でLinuxが30年かけて築いた成果を上回りました。
OpenClawは本質的にエージェントシステム(Agentic System)であり、以下の機能を備えています:
- リソース管理、ツール・ファイルシステム・大規模言語モデルへのアクセス
- スケジューリングおよびタイマー・タスクの実行
- 問題の段階的分解およびサブエージェントの呼び出し
- 任意のモダリティ(音声・動画・テキスト・メールなど)の入出力サポート
オペレーティングシステムの文法で言えば、これはまさにオペレーティングシステム——エージェントコンピューターのOSです。Windowsがパーソナルコンピューターを可能にしたのと同様に、OpenClawはパーソナルエージェントを可能にします。
すべての企業は、自社のOpenClaw戦略を策定する必要があります。それは、Linux戦略、HTML戦略、Kubernetes戦略を策
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News