

最適化の最良レベル:機械学習から目標最大化の経験を学ぶ
TechFlow厳選深潮セレクト
最適化の最良レベル:機械学習から目標最大化の経験を学ぶ
効率が低いのはダメだが、高いほど必ずしも良いのか?
執筆:DAN SHIPPER
翻訳:Ines
Midjourneyプロンプト:「橋を渡ろうとしている人の視点から、巨大で危険な断崖を横切るロープブリッジを想像する。水彩画風。」
どこまで最適化すべきか? これは私がよく自問する問いであり、あなたもきっと考えたことがあるはずだ。世代にわたる企業の創設、完璧な人生の伴侶探し、あるいは理想的な運動プログラムの設計など、ある目標に向かって最適化しようとするとき、私たちはつい完全を追い求めがちになる。
最適化とは完璧さへの追求である。妥協したくないからこそ、私たちは最適化するのだ。しかし、本当に完璧を目指すことが常に最善なのだろうか? 言い換えると、「最適化しすぎ」というのは存在するのか?
最適化の難しさについては、長年にわたり人々が考察してきた。彼らの立場は一つの連続体上に並べることができる。
一端にはジョン・メイヤー(John Mayer)がいる。「少ないことは、より多いことだ」と彼は考える。代表曲『Gravity』の中でこう歌っている。
「ああ、2倍良いというのは本当に2倍良いわけじゃない / 2倍長く続くわけでもない / もっと欲しいと思う気持ちが、私を屈服させるのだ」
一方、ドリー・パートン(Dolly Parton)は正反対の立場を取る。「少ないことは多くない。多いことが、そのまま“多い”なのだ。」
アリストテレスはこのどちらにも同意しない。2000年も前から、彼は「中庸」の概念を提唱していた。ある目標に向かって最適化する際には、「多すぎる」ことと「少なすぎる」ことの中間点が望ましいと。
では、いったいどれを選べばいいのか? 今や2023年だ。私たちはこの問いに対して、漠然とした議論ではなく、もう少し定量的な答えを求めたい。理想を言えば、ある目標に向かう最適化の効果を、何らかの方法で測定できるようにしたい。
今日では、その手がかりを機械に求めることができる。目的の最適化は、機械学習や人工知能の研究者が長年取り組んできたテーマの一つだ。ニューラルネットワークに何か有用なことをさせようと思えば、まず目的を与え、その達成に向けて努力させる必要がある。コンピュータ科学者がニューラルネットワークのために見出した答えは、最適化全般について多くの教訓を与えてくれる。
最近、機械学習研究者のヤシャ・ゾールディクシュタイン(Jascha Sohl-Dickstein)が発表した記事に私は特に心を動かされた。そこには次のような主張がある。
機械学習が示しているのは、「目的に対してあまりに強く最適化すると、物事はひどく狂ってしまう」ということだ。これは量的にも確認できる。機械学習アルゴリズムが目的を過剰に最適化すると、全体像を見失いがちになり、研究者たちが言うところの「過学習(overfitting)」という現象が起きる。実際、私たちが特定のプロセスやタスクの完璧化にあまりに集中しすぎると、そのタスクにだけ過度に適応してしまい、変化や新たな課題に対応できなくなるのだ。
つまり最適化の問題において――「多い」ことは、決して「多い」ことではない。受け取れ、ドリー・パートン。
以下は、私はヤシャ(Jascha)の記事を要約し、平易な言葉でその考え方を説明しようとする試みだ。それを理解するために、まずは機械学習モデルの訓練がどのように行われるかを見てみよう。
Mindseraは人工知能を活用して、あなたの隠れた思考パターンを明らかにし、盲点に気づかせ、自分自身をより深く理解するのを支援します。
日記テンプレートを使って、役立つフレームワークやマインドセットに基づいて思考を構築することで、よりよい意思決定をし、健康状態を改善し、生産性を高めることができます。
MindseraのAIメンターは、マルクス・アウレリウス(Marcus Aurelius)やソクラテス(Socrates)といった思想的巨人の思考を模倣し、新しい洞察の道を開きます。
インテリジェントな分析が、あなたの書き込みから独自の作品を生成し、感情状態を測定し、個性を反映し、成長に向けたパーソナライズされたアドバイスを提供します。
自己認識を高め、思考を整理し、ますます不確実な世界で成功を収めましょう。
さあ、始めましょう。
ボランティアになりたいですか?こちらをご覧ください。
👉https://www.passionfroot.me/every
あまりに効率的になることで、すべてが悪化する
ここで、犬の画像分類に優れた性能を発揮する機械学習モデルを作りたいとしよう。写真を入力すれば、その犬の品種が正確に返ってくるようなものだ。ただの普通の分類器ではなく、代償を惜しまず、延々とプログラミングを続け、無数のコーヒーを飲み干してでも達成したい、比類なき機械学習分類器を求める。(畢竟、我々は最適化しているのだ。)
では、どうやってそれを実現するか? いくつかの戦略があるが、おそらくあなたは「教師あり学習」を選ぶだろう。教師あり学習とは、機械学習モデルに導師をつけるようなものだ。モデルに繰り返し質問を投げかけ、誤ったときは修正を加えることで、徐々に正解への道を学ばせていく。この訓練を通じて、モデルは回答の正確性を高めていく。
まず、モデルの訓練用に画像データセットを準備する必要がある。各画像には「プードル」「コカプー」「ダンディ・ディーンモン・テリア」などのラベルを事前に付けておく。そして、それらの画像とラベルをモデルに入力し、学習を開始させる。
モデルの学習方法はまさに「試行錯誤」だ。画像を見せ、モデルにラベルを推測させ、間違えたら微調整を行う。これを繰り返すことで、時間とともに、モデルは訓練データ内の画像のラベル予測精度を高めていく。
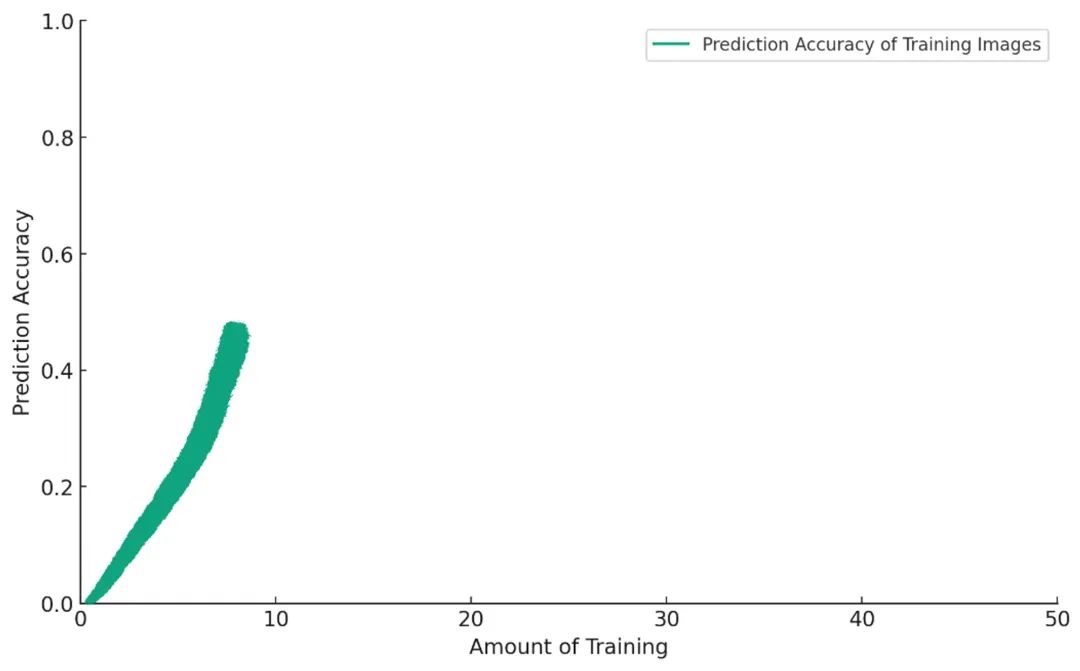
さて、モデルは訓練データ内の画像ラベル予測に関して、どんどん上手くなってきた。そこで、新たなテストを与える。訓練中に一度も見せたことのない犬の画像に対して、ラベル付けをしてもらうのだ。
これは重要なテストだ。以前見たことのある画像だけを尋ねるのは、まるでテストでカンニングを許すようなものだからだ。そこで、モデルが確実に見たことがないであろう別の犬の画像を集めてくる。
最初のうちは順調だ。訓練を重ねるほど、モデルの成績は向上していく。
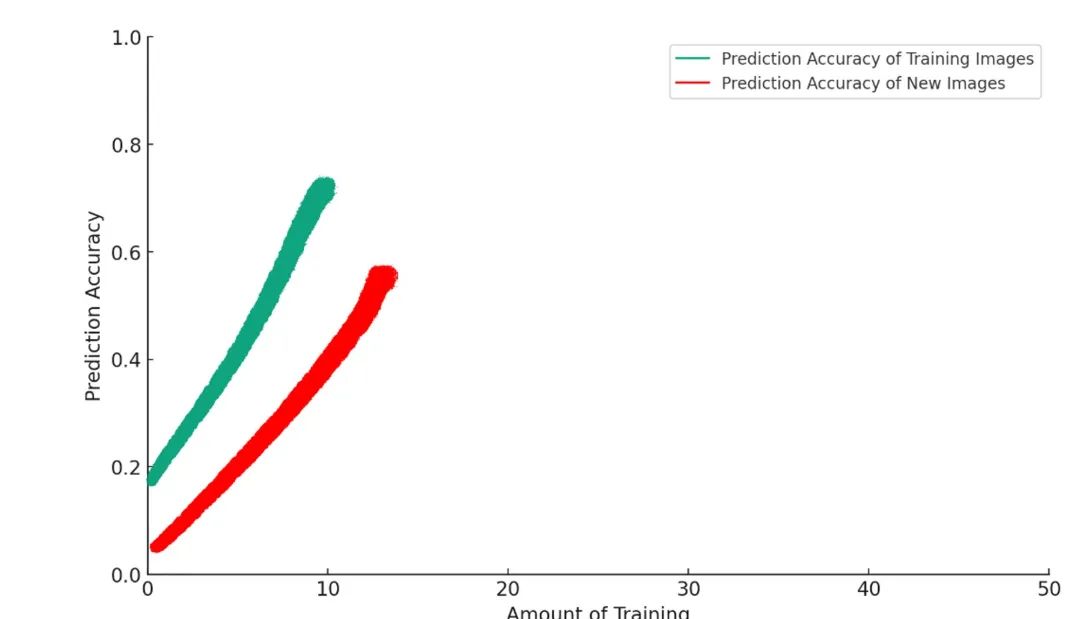
だが、訓練をさらに続けると、モデルはAI版の「絨毯の上で排泄する」ような挙動を始める。一体何が起きたのか?
ここに何が起こっているのか?
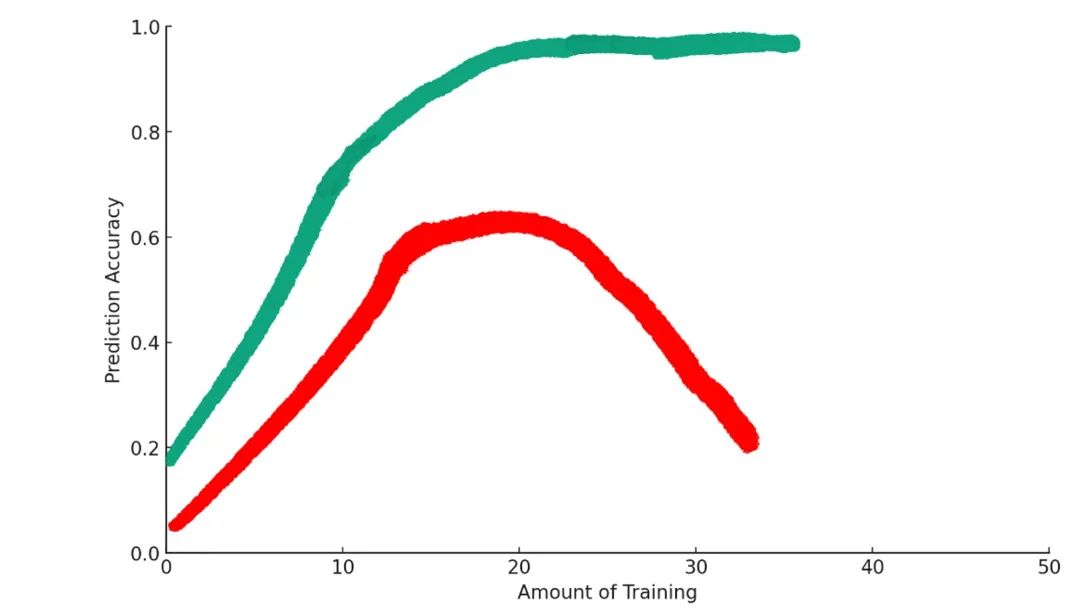
ある程度の訓練は、モデルを目標達成に向けて最適化する。しかし、あるポイントを過ぎて過剰に訓練すると、かえって状況が悪化してしまう。これが機械学習における「過学習(overfitting)」という現象だ。
なぜ過学習は事態を悪化させるのか
モデルの訓練には、実は巧妙な操作が含まれている。
本当の目標は、任意の犬の画像を正確に分類することだ。しかし、ありとあらゆる犬の画像を取得することは不可能なので、直接その目標を最適化できない。代わりに、代理の目標を設定する。つまり、真の目標を代表すると期待される、犬の画像の小さなサブセットだ。
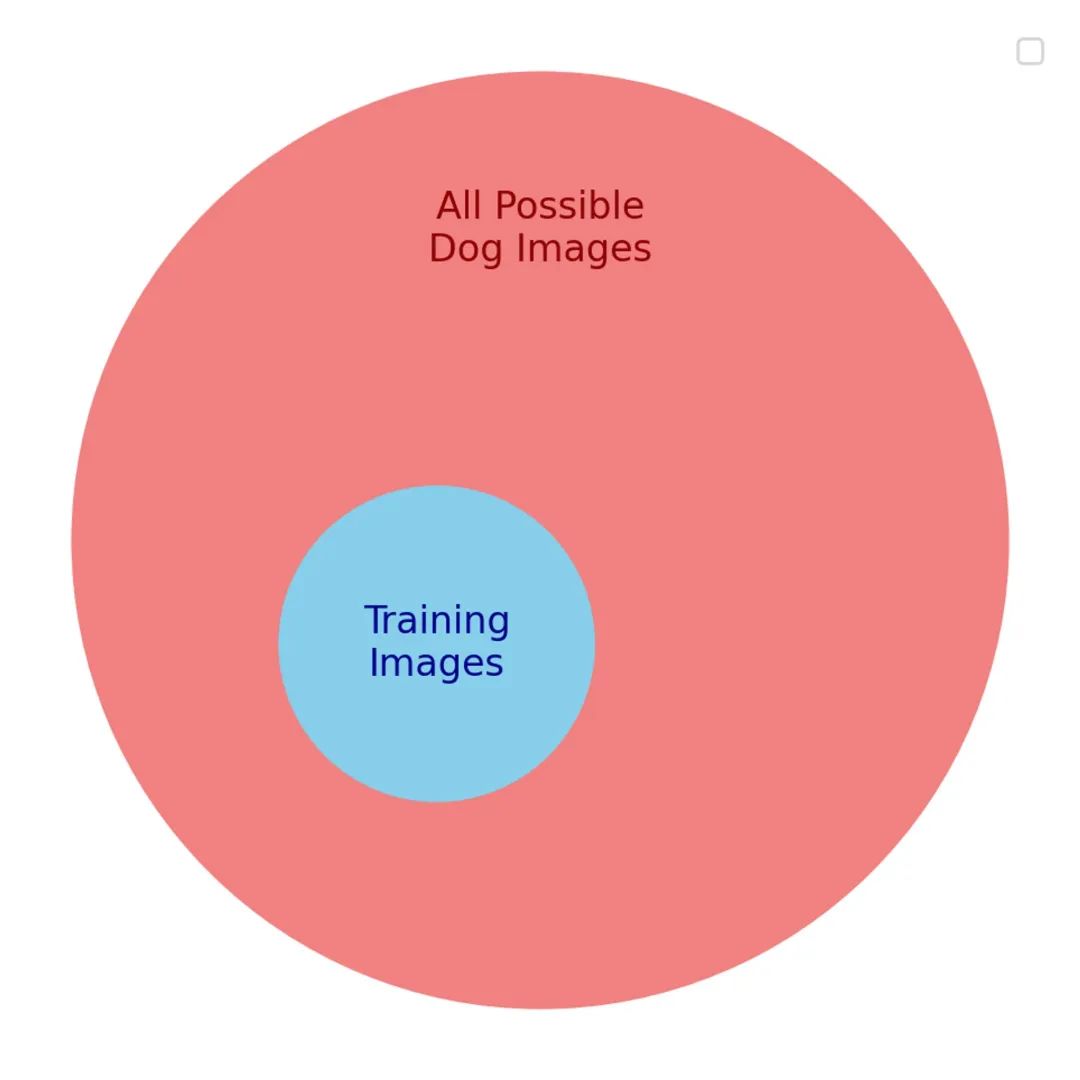
代理目標と真の目標の間には多くの共通点があるため、初期段階では、モデルは両方の目標において進歩を遂げる。しかし、訓練が深まるにつれて、これらの有用な類似性は薄れていき、やがてモデルは訓練データ内に特化した知識しか持たなくなり、それ以外の画像にはうまく対応できなくなる。
訓練を続けるほど、モデルは訓練データの細部に過剰に依存するようになる。例えば、訓練データに黄色のラブラドゥードルの画像が異常に多かったとしよう。過学習したモデルは、黄色い犬=すべてラブラドゥードルだと誤って学んでしまうかもしれない。
このような過学習モデルは、訓練データとは異なる特徴を持つ新しい画像に対して、ひどく失敗する。
過学習は、私たちが目標最適化を探求する上で重要な洞察を提示している。
第一に、何かを最適化しようとするとき、ほとんど常に直接その対象を最適化しているわけではない。代わりに、それに似ているがわずかに異なる「代理」を最適化しているのだ。犬の分類問題では、あり得るすべての犬の画像で訓練できないため、その一部のサブセットで最適化し、それが一般化されることを期待する。それは確かに機能する――ただし、過剰に最適化するまでは。
第二の洞察はこれだ。代理関数を過剰に最適化すると、本来の目標から遠ざかってしまう。
この機械学習のメカニズムを理解すれば、至る所で同じ現象を観察できるようになる。
過学習を現実世界にどう適用するか
学校を例に取ろう。
学校では、学んだ科目に関する知識を深めることを最適化したい。しかし、ある知識をどの程度深く理解しているかを測るのは難しいため、標準化テストを利用する。標準化テストはある程度、その科目を理解しているかどうかを代表する指標となる。
しかし、生徒や学校がテストの成績に過剰な圧力をかけると、テスト結果の最適化が本物の学びを損なってしまう。生徒はテストの点数を上げるプロセスに過剰に適応するようになる。知識を学ぶのではなく、テストの受け方(あるいはカンニング)を学んで点数を最適化してしまうのだ。
ビジネスの世界にも過学習は存在する。『乱世中の法則(Fooled by Randomness)』の著者ナシーム・タレブ(Nassim Taleb)は、新興市場債券の洗練されたトレーダー、カルロスという銀行員の話を紹介している。彼の戦略は「安値買い」だった。1995年のメキシコ通貨下落時、彼は底値で買いを入れ、危機解除後に価格が回復した際に利益を得た。
この安値買い戦略は、会社に8000万ドルの純利益をもたらした。しかし、カルロスは自分が経験した市場に「過剰に適応」してしまい、リターンの最適化が最終的に彼を破滅に導いた。
1998年の夏、彼は再び底値でロシア国債を購入した。夏が進むにつれ、下落はさらに激しくなり――カルロスは買い増しを続ける。彼は賭け金を倍々にしていった。結局、債券価格が極端に低下し、3億ドルの損失を被った。これは、それまでのキャリアで稼いだ額の3倍に相当する。
タレブが本書で指摘するように、「市場において最も成功するトレーダーは、最新のサイクルに最も適応した人物である可能性がある」。
言い換えれば、リターンの過剰最適化とは、現在の市場サイクルへの過剰適応を意味する。短期的には業績が劇的に向上するだろう。しかし、現在の市場サイクルは、市場行動全体のごく一部にすぎない。サイクルが変われば、それまで成功した戦略が突然、破産の原因になる。
私のビジネスにも同じ教訓が当てはまる。Everyはサブスクリプションメディア事業を行っており、MRR(月間継続収益)を増やしたい。そのためには、ページビューを増やすことで記事の流入を高め、その成果を報酬として作者に還元する方法が考えられる。
これはおそらく有効だろう! 流入が増えることで、実際に有料購読者も増えるはずだ――ある時点までは。だが、その地点を越えると、作者たちはクリックベイトやセンセーショナルな記事でページビューを稼ぎ始めるだろう。そうした記事は、支払い意愿があり、参加意欲の高い読者を惹きつけない。結局、Everyをクリックベイト工場にしてしまえば、有料購読者は増えず、むしろ減ってしまうかもしれない。
自分の生活や仕事に目を向ければ、きっと同じパターンをいくつも見つけることができるだろう。問題は、どうすればいいのかということだ。
では、どうすればいいのか?
機械学習研究者は、過学習を防ぐために多くの技術を用いている。ヤシャの記事によれば、私たちが採れる対策は主に三つある:早期停止、ノイズの導入、正則化だ。
早期停止(Early Stopping)
これは、モデルが真の目標においてどのように振る舞っているかを常にチェックし、性能が低下し始めた時点で訓練を中断するという手法だ。
カルロスの場合、債券価格の下落局面で全資金を失ったトレーダーだったが、これは一定額の損失が積み上がった時点で強制的にポジションを解消する厳格な損切りルールがあれば防げたかもしれない。
ノイズの導入(Introducing Random Noise)
機械学習モデルの入力やパラメータにノイズを加えることで、過学習を防ぐことができる。この原理は他のシステムにも応用可能だ。
生徒や学校にとっては、テストの日程をランダムにするなど、詰め込み勉強の難易度を上げる手段が考えられる。
正則化(Regularization)
機械学習では、モデルが複雑になりすぎないようにペナルティを課す「正則化」が使われる。モデルが複雑になればなるほど、データに過剰適合しやすくなる。技術的詳細はともかく、この概念は他のシステムにも応用できる。つまり、システム内部にあえて摩擦を加えるのだ。
もし私がEveryの全作者に対して、ページビューの向上によってMRRを増やすことを促したいなら、報酬計算の仕組みを変更し、一定の閾値を超えたページビューについては、徐々に報酬カウントを減らしていくようにできる。
これらはすべて過学習に対処する潜在的な解決策であり、再び私たちの最初の問いに戻る:最適化の「最適なレベル」とは何か?
最適な最適化レベル
私たちが学んだ最大の教訓は、ほぼ常に、目標そのものを直接最適化することはできないということだ。代わりに、目標に似ているがわずかに異なる「代理」を最適化している。それが「代理変数」なのである。
代理変数を最適化せざるを得ない以上、あまりに強く最適化すれば、その代理目標の最大化に過剰に適応してしまう。そしてそれは、往々にして真の目標から遠ざかることにつながる。
したがって、肝に銘じるべきはこれだ。自分が今、何を最適化しているのかを知ること。代理目標は、目標そのものではない。最適化の過程では柔軟性を持ち、代理目標と真の目標との間に有用な類似性が尽きたと感じたら、戦略の停止や転換の準備をすること。
ジョン・メイヤー、ドリー・パートン、アリストテレス――この三人の最適化に関する知恵を考えるならば、やはり賞はアリストテレスの中庸の道にある「黄金分割点」に与えるべきだろう。
ある目標に向かって最適化するとき、最適なレベルは「多すぎる」と「少なすぎる」の間にある。それは「ちょうどよい」点なのだ。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News










