

Dragonflyパートナー:「信用するな、自分で検証せよ」— デセントラル型推論におけるその応用
TechFlow厳選深潮セレクト
Dragonflyパートナー:「信用するな、自分で検証せよ」— デセントラル型推論におけるその応用
ブロックチェーンと機械学習には明らかに多くの共通点がある。
執筆:Haseeb Qureshi
翻訳:TechFlow
あなたはLlama2–70Bのような大規模言語モデルを実行したいと考えています。これほど巨大なモデルは140GB以上のメモリを必要とするため、自宅のコンピュータではオリジナルモデルを動作させることはできません。では、どのような選択肢があるでしょうか?クラウドサービスプロバイダーに頼ることも考えられますが、すべての使用データを集められるような中央集権的な企業を信用することに抵抗を感じるかもしれません。その場合に必要なのは「分散型推論」であり、特定の単一プロバイダーに依存せずに機械学習モデルを実行できる仕組みです。
信頼の問題
分散型ネットワークにおいては、単にモデルを実行してその出力を信じるだけでは不十分です。たとえば、ネットワークにLlama2–70Bを使ってガバナンス上のジレンマを分析させる場合、本当にLlama2-13Bではなく、より低品質な分析結果を提供され、差額を搾取されていないかどうか、どうやって確認すればよいでしょうか?
中央集権的な世界では、OpenAIのような企業が誠実であると信じる理由として、その企業の評判がリスクにさらされていることが挙げられます(また、ある程度はLLMの品質が自己証明的でもあります)。しかし、分散型の世界では誠実さはデフォルトではなく、検証によって保証される必要があります。
ここで登場するのが「検証可能な推論(verifiable inference)」です。クエリに対する応答だけでなく、要求されたモデル上で正しく実行されたことを証明しなければなりません。しかし、それはどのように実現できるのでしょうか?
最もシンプルな方法は、モデルをスマートコントラクトとしてオンチェーンで実行することです。これにより確かに出力の検証は保証されますが、極めて非現実的です。GPT-3は12,288次元の埋め込みベクトルで単語を表現します。このサイズの行列乗算をオンチェーンで実行すると、現在のGas価格に基づき約100億ドルの費用がかかり、計算はおよそ1か月間にわたりすべてのブロックを埋め尽くすことになります。
したがって、別のアプローチが必要です。
この分野を観察した結果、検証可能な推論を達成するための主なアプローチは3つあることが明らかになりました。ゼロ知識証明、楽観的不正行為証明(オプティミスティック・フロードプローフ)、そして暗号経済学的アプローチです。それぞれ異なる安全性とコストのトレードオフがあります。
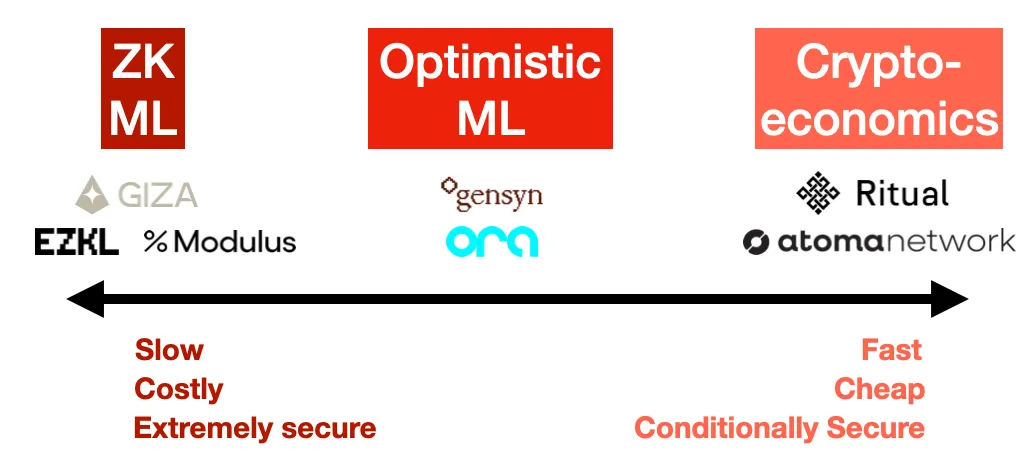
1. ゼロ知識証明(ZK ML)
モデルの大きさに関係なく、固定サイズの証明で大規模モデルを実行したことを証明できるとしたらどうでしょうか。これがZK-SNARKを通じてZK ML(機械学習)が約束するものです。
原理的には非常に洗練されていますが、ディープニューラルネットワークをゼロ知識回路にコンパイルし、さらに証明を作成することは極めて困難です。コストも非常に高く、少なくとも推論コストと遅延が1000倍になる可能性があります(証明生成にかかる時間)。加えて、実際の処理を行う前にモデル自体を回路にコンパイルする作業も必要です。最終的にこれらのコストはユーザーに転嫁されるため、エンドユーザーにとっては非常に高価なものとなります。
一方で、これは暗号学的に正しいことを保証する唯一の方法です。ZKを利用すれば、モデル提供者がいかに努力しても不正を行うことはできません。しかし、その代償は大きく、近い将来において大規模モデルには非現実的でしょう。
事例:EZKL, Modulus Labs, Giza
2. 楽観的不正行為証明(Optimistic ML)
楽観的アプローチは、「信じつつも検証する」という考え方です。推論は正しいと仮定し、反証されるまでそれを維持します。ノードが不正を行おうとした場合、「ウォッチャー(監視者)」がネットワーク内で不正を指摘し、不正行為証明によって挑戦できます。これらのウォッチャーは常にチェーンを監視し、自身でもモデルを再実行して出力の正当性を確認しなければなりません。
これらの不正行為証明は、Truebitスタイルの対話型チャレンジゲームです。モデルの実行履歴をオンチェーンで繰り返し分割しながら、誤りが見つかるまで挑戦を続けます。
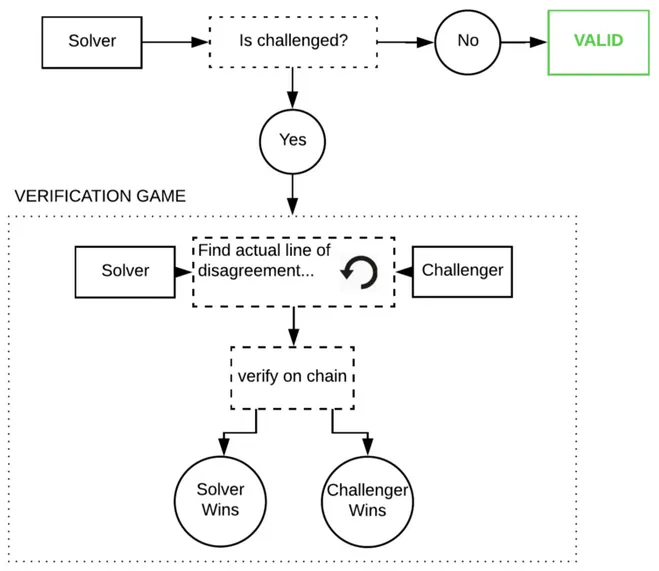
実際にこれが発生した場合、非常に高価になります。なぜなら、GPT-3の単一推論でも約1ペタフロップ(10⁵浮動小数点演算)の巨大な内部状態を持つプログラムだからです。しかし、ゲーム理論的にはそのような事態はほとんど起こらないと予想されます(実際の運用ではコードが実行されないため、不正行為証明の実装自体も非常に困難です)。
楽観的アプローチの利点は、ただ一つの正直なウォッチャーが監視していればMLが安全だということです。ZK MLよりもコストは安くなりますが、各ウォッチャーがすべてのクエリを再実行していることに注意が必要です。均衡状態では、10人のウォッチャーがいれば、セキュリティコストがユーザーに転嫁され、推論コストの10倍以上(またはウォッチャーの数に応じた倍率)を支払うことになります。
欠点としては、楽観的集約技術と同様に、応答が検証されたことを確認するためにチャレンジ期間の終了を待つ必要があることです。ただし、ネットワークのパラメータ設定次第では、数日ではなく数分で済む場合もあります。
3. 暗号経済学的アプローチ(Cryptoeconomic ML)
ここでは凝った技術を捨てて、シンプルな方法を取ります。つまり、ステークによる重み付け投票です。ユーザーがどの程度のノードにクエリを実行させるかを決定し、各ノードが出力を開示します。出力に差異があれば、外れたノードはスラッシング(ペナルティ)を受けます。これは標準的なオラクル機構であり、ユーザーがセキュリティレベルを直接指定でき、コストと信頼のバランスを調整できる直感的な方法です。もしChainlinkがMLを扱うなら、おそらくこの方法を採用するでしょう。
この方式では遅延が非常に短く、各ノードのコミットと開示だけで済みます。ブロックチェーンに記録される場合、技術的には2つのブロックで完了可能です。
ただし、安全性は最も弱くなります。大多数のノードが協力して合意すれば、合理的に共謀することが可能です。ユーザーは、ノードがどれだけステークを投入しており、不正行為がどれほどのコストを伴うかを慎重に考える必要があります。Eigenlayerのような再ステーキングや帰属可能なセキュリティを活用することで、セキュリティ失敗時に有効な保険を提供できるネットワークも構築可能です。
しかし、このシステムの利点は、ユーザーが望むセキュリティ量を指定できる点です。法定数(quorum)に3ノードか5ノード、あるいはネットワーク内の全ノードを選ぶことができます。リスクを取ってn=1を選択することさえ可能です。コスト関数は単純で、ユーザーは自分の法定数に含めるノード数に応じて料金を支払います。3ノードを選べば、推論コストの3倍を支払うことになります。
ここで難しい問題は、「n=1でも安全にできるか?」という点です。単純な実装では、孤立したノードは誰にも監視されなければ常に不正を行うはずです。しかし、クエリを暗号化し、意図に基づいて支払いを行うことで、ノードに対して自分が唯一の応答者であることを隠蔽できるかもしれません。その場合、一般ユーザーに対して推論コストの2倍未満の料金を請求できる可能性があります。
結局のところ、暗号経済学的アプローチは最もシンプルで扱いやすく、おそらく最も安価ですが、原則的には最も目立たず、最も安全性が低いと言えます。ただし、いつものように、詳細が成功の鍵を握ります。
事例:Ritual 、Atoma Network
なぜ検証可能なMLは難しいのか
こういった技術がまだすべて実現されていないのはなぜでしょうか?そもそも、MLモデルは非常に大きなコンピュータプログラムにすぎません。プログラムの正しさを証明することは、ブロックチェーンの中心的課題でした。
そのため、これら3つの検証手法は、ブロックチェーンがブロック空間を保護する方法を反映しています。ZKロールアップはZK証明を使用し、楽観的ロールアップは不正行為証明を使い、多くのL1ブロックチェーンは暗号経済学的手法を用いています。最終的に我々が導き出すソリューションは基本的に同じになるでしょう。では、MLに適用したときに何が難しくなるのでしょうか?
MLが特殊なのは、その計算が通常、GPU上で効率的に実行されるよう設計された密な計算グラフとして表現されることです。これらは「証明のために」設計されたものではありません。したがって、ZK環境や楽観的環境でML計算を証明しようとすると、実行可能な形式に再コンパイルする必要があり、それが非常に複雑かつ高価なのです。
MLにおける第二の根本的な困難は「非決定性」です。プログラム検証は、出力が決定的であることを前提としています。しかし、同じモデルを異なるGPUアーキテクチャやCUDAバージョンで実行すると、異なる出力が得られることがあります。各ノードに同じアーキテクチャを使用させても、アルゴリズム内でのランダム性(拡散モデルのノイズやLLMでのトークンサンプリング)の問題が残ります。乱数シードを固定することでこのランダム性を制御できますが、それでも最後の厄介な問題が残ります。それは浮動小数点演算に内在する非決定性です。
ほぼすべてのGPU操作は浮動小数点数で行われます。浮動小数点数は結合則が成立しないため扱いが難しいのです。つまり、(a + b) + c と a + (b + c) が常に一致するとは限りません。GPUは高度に並列化されているため、実行ごとに加算や乗算の順序が変わり、出力にわずかな差異を生じさせる可能性があります。これはLLMの出力にはあまり影響しません(単語が離散的であるため)が、画像モデルでは画素値に微妙な違いが生じ、二つの画像が完全に一致しなくなる可能性があります。
つまり、浮動小数点数の使用を避けなければならないか、出力の比較時にある程度の許容範囲を設ける必要があります。いずれにせよ、細部の処理が煩雑になり、完全に抽象化することはできません。(これが、イーサリアム仮想マシンが浮動小数点数をサポートしない理由であり、一部のブロックチェーン(NEARなど)がサポートしているのとは対照的です。)
要するに、分散型推論ネットワークは非常に難しい。なぜなら、すべての細部が重要であり、現実世界のそれらは予想外に多いからです。
まとめ
現在、ブロックチェーンと機械学習には明らかな共通点があります。一方は信頼を創造する技術であり、他方は信頼を切実に必要とする技術です。分散型推論の各アプローチにはそれぞれトレードオフがありますが、起業家たちがこれらのツールをどう活用して最適なネットワークを構築していくか、非常に興味深いことだと思います。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













