

LLMがブロックチェーンに力を与え、オンチェーン体験の新時代を切り開く
TechFlow厳選深潮セレクト
LLMがブロックチェーンに力を与え、オンチェーン体験の新時代を切り開く
LLMの強みには、大量のデータを理解する能力、複数の言語関連タスクを実行できる能力、およびユーザーのニーズに応じて結果をカスタマイズする可能性が含まれる。
著者:Yiping, IOSG Ventures
はじめに
-
大規模言語モデル(LLM)の発展に伴い、人工知能(AI)とブロックチェーンを統合するプロジェクトが数多く登場している。LLMとブロックチェーンの融合が進む中で、AIが再びブロックチェーンと結びつく可能性も見えてきた。とりわけ注目すべきは、ゼロナレッジ機械学習(ZKML)である。
-
AIとブロックチェーンは、根本的に異なる特徴を持つ変革的技術である。AIは強力な計算能力を必要とし、通常は中央集権的なデータセンターによって提供される。一方、ブロックチェーンは分散型の計算とプライバシー保護を提供するが、大規模な計算やストレージタスクには向いていない。AIとブロックチェーンの統合における最適な実践方法についてはまだ探求・研究の段階であり、今後いくつかの「AI+ブロックチェーン」プロジェクトの事例を紹介していく予定である。
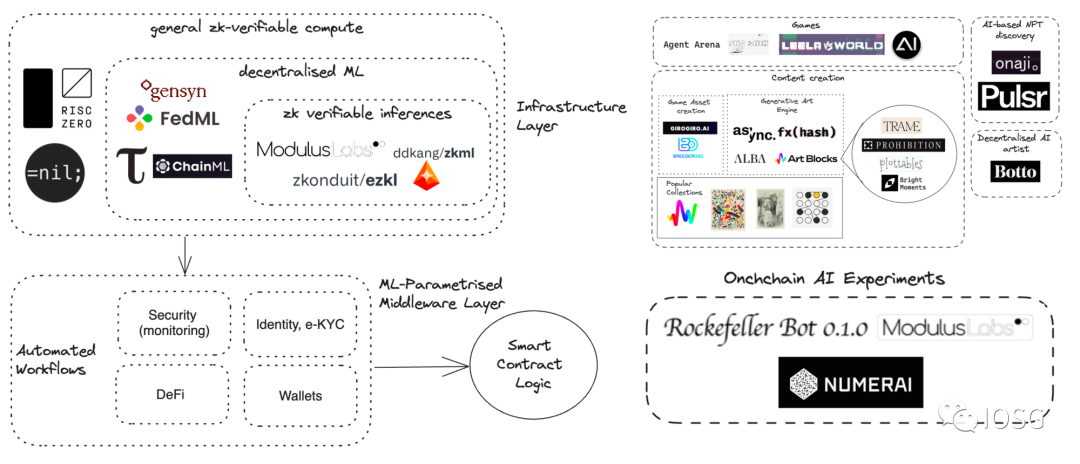
出典: IOSG Ventures
本レポートは上下2部構成となっており、こちらはその上巻である。ここでは、暗号資産(Crypto)分野におけるLLMの応用に焦点を当て、実装戦略について考察する。
LLMとは何か?
LLM(大規模言語モデル)とは、多数のパラメータ(通常は数十億)を持つ人工ニューラルネットワークで構成されるコンピュータ化された言語モデルである。これらのモデルは大量のラベルなしテキストで学習される。
2018年頃に登場したLLMは、自然言語処理(NLP)研究のあり方を一変させた。従来のように特定のタスクごとに専用の教師ありモデルを訓練する方法とは異なり、LLMは汎用モデルとしてさまざまなタスクで優れた性能を発揮する。その能力と応用範囲には以下のようなものがある:
-
テキストの理解と要約:LLMは膨大な人間の言語およびテキストデータを理解・要約できる。重要な情報を抽出し、簡潔な要約を生成することが可能である。
-
新規コンテンツの生成:LLMはテキストベースのコンテンツを生成する能力を持つ。プロンプトをモデルに入力することで、質問への回答、新たな文章、要約、感情分析などを生成できる。
-
翻訳:LLMは異なる言語間の翻訳に使用できる。深層学習アルゴリズムとニューラルネットワークを活用して、語彙間の文脈や関係性を理解する。
-
テキストの予測と生成:LLMは文脈に基づいてテキストを予測・生成でき、人間が作成したような内容(楽曲、詩、物語、マーケティング資料など)を生成可能である。
-
さまざまな分野での応用:大規模言語モデルは自然言語処理タスクにおいて広範な適用性を持つ。対話型AI、チャットボット、医療、ソフトウェア開発、検索エンジン、教育支援、執筆ツールなど、多くの分野で利用されている。
LLMの利点には、大量データの理解力、多様な言語関連タスクの遂行能力、ユーザーのニーズに応じたカスタマイズの可能性などが含まれる。
一般的な大規模言語モデルの応用
卓越した自然言語理解能力により、LLMには大きな可能性がある。開発者の関心は主に以下の2点に集中している:
-
大量のコンテキストデータとコンテンツに基づき、正確かつ最新の回答をユーザーに提供すること
-
異なるエージェントやツールを活用して、ユーザーが指示した特定のタスクを遂行すること
この2つの方向性により、「XXと会話する」タイプのLLMアプリケーションが急速に増加している。例えば、「PDFと会話する」「ドキュメントと会話する」「学術論文と会話する」といったものがある。
その後、人々はLLMとさまざまなデータソースを統合しようと試みた。開発者はすでにGitHub、Notion、ノートアプリなどのプラットフォームをLLMと統合することに成功している。
LLM固有の制限を克服するために、さまざまなツールがシステムに組み込まれている。最初に導入されたのは検索エンジンであり、これによりLLMは最新の知識にアクセスできるようになった。さらに進んで、WolframAlpha、Google Suite、Etherscanなどのツールが大規模言語モデルと統合されていく。
LLMアプリのアーキテクチャ
下図は、LLMアプリがユーザーの問い合わせに応答する際の処理フローを概説している。まず、関連するデータソースが埋め込みベクトルに変換され、ベクトルデータベースに保存される。LLMアダプターはユーザーのクエリと類似性検索を用いて、ベクトルデータベースから関連するコンテキストを取得する。その関連コンテキストはプロンプトに挿入され、LLMに送信される。LLMはそのプロンプトを実行し、ツールを利用して回答を生成する。場合によっては、特定のデータセット上でファインチューニングを行うことで、精度の向上とコスト削減を図ることもできる。
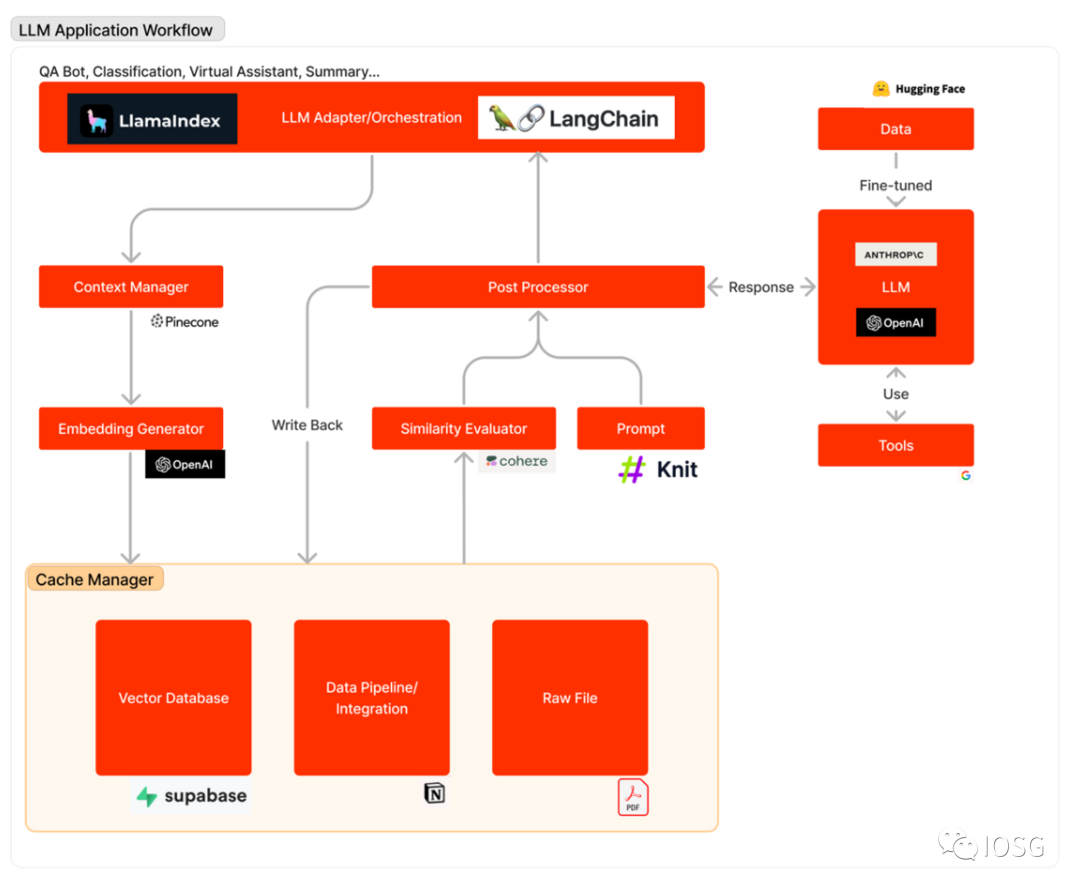
LLMアプリのワークフローは、おおむね以下の3つの主要な段階に分けられる:
-
データ準備と埋め込み(Embedding):この段階では、将来の参照のために機密情報(プロジェクトメモなど)を保持する。通常、ファイルは分割され、埋め込みモデルを通じて処理され、ベクトルデータベースと呼ばれる特殊なデータベースに保存される。
-
プロンプトの構築(Formulation)と抽出(Extraction):ユーザーが検索リクエスト(この例ではプロジェクト情報の検索)を送信すると、ソフトウェアは一連のプロンプトを作成し、言語モデルに入力する。最終的なプロンプトには、開発者がハードコードしたヒントテンプレート、few-shotの有効な出力例、外部APIから取得した必要なデータ、およびベクトルデータベースから抽出された関連ファイルが含まれる。
-
プロンプトの実行と推論:プロンプトの作成が完了したら、それらは既存の言語モデルに渡され、推論が行われる。これは、独自のモデルAPI、オープンソースモデル、または個別にファインチューニングされたモデルを含む。この段階で、一部の開発者はログ記録、キャッシュ、検証などのオペレーションシステムをシステムに統合することもある。
LLMを暗号資産(Crypto)分野に導入する
暗号資産(Web3)分野にはWeb2と類似したアプリケーションがいくつか存在するが、優れたLLMアプリを開発するには特に慎重な配慮が必要である。
暗号エコシステムは独自の文化、データ、統合性を持っており、特有の性格を持つ。このような暗号特有のデータセット上でファインチューニングされたLLMは、比較的低いコストで優れた結果を提供できる。データ自体は豊富にあるものの、HuggingFaceなどのプラットフォームでは公開データセットが明らかに不足している。現時点でスマートコントラクト関連のデータセットは1つしかなく、11.3万件のスマートコントラクトを含んでいる。
開発者はまた、さまざまなツールをLLMに統合する上での課題にも直面している。これらのツールはWeb2で使われるものとは異なり、LLMに取引関連データへのアクセス、デセントラライズドアプリ(Dapp)とのインタラクション、取引の実行といった能力を与えるものである。現時点では、Langchain内にDappの統合は見つかっていない。
高品質な暗号LLMアプリの開発には追加の投資が必要かもしれないが、LLMは暗号分野に天然的に適しているとも言える。この分野は豊かで、きれいで、構造化されたデータを提供しており、Solidityコードは通常簡潔で明快であるため、LLMによる機能的コードの生成が容易になる。
下巻では、LLMがブロックチェーン分野に貢献できる8つの潜在的分野について議論する。例えば:
-
ブロックチェーンに内蔵されたAI/LLM機能の統合
-
LLMを用いた取引履歴の分析
-
LLMを用いた潜在的ボットの識別
-
LLMを用いたコードの作成
-
LLMを用いたコードの読解
-
LLMを用いたコミュニティ支援
-
LLMを用いた市場動向の追跡
-
LLMを用いたプロジェクト分析
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














