

DataFi:分散型データサービスがデータ経済をどう改革するか?
TechFlow厳選深潮セレクト
DataFi:分散型データサービスがデータ経済をどう改革するか?
世界には膨大な量のデータが存在しており、その量は驚異的なスピードで増加している。
執筆:Risk Taker88
編集・翻訳:TechFlow
世界には膨大な量のデータが存在しており、その規模は驚異的なスピードで拡大している。市場調査会社IDCの推計によると、2025年までにデータ量は33ZBから175ZBへと増加する見込みだ。
データ量が膨大であるにもかかわらず、複数の企業や業界、経済圏の間では効果的に活用されていない。主な課題は「データサイロ」にある。データサイロとは、ある部門や単位が収集したデータが、組織内の他の部門で利用できない状態を指す。より広いレベルでも同様であり、ある企業が収集したデータは通常、他の企業が利用できない。
こうした状況を変えるのが「データ経済」である。
データ経済とは、生産者と消費者がデータを収集・整理・共有し、インサイトを得てそれをマネタイズするグローバルなデジタルエコシステムである。重要なのは、関係者がそこから利益を得られることだ。この経済圏において、データは多様な形態を持ち、さまざまなソースから生成される。検索エンジン、ソーシャルメディアプラットフォーム、オンラインデータ供給業者、IoTデバイスを導入した企業など、ありとあらゆる場所がデータの源泉となりうる。
データ経済への参加には多くのメリットがある。他者とのデータ交換を通じて、企業は新たなビジネスラインを展開できる。たとえば、医療機器メーカーはユーザーの健康情報(心拍数やインスリン値など)を大量に保有している。医療機器販売による収益に加え、倫理的かつ安全な方法で医療機関に患者追跡データを提供することで協業することも可能になる。すべての関係者がデータ交換の恩恵を受け、医療機器メーカーは新たな収益源を創出できるのだ。
Streamr
予測によれば、世界中で生成されるデータの約30%がリアルタイムであり、そのうち95%はIoTデバイスによって得られるという。これが正しければ、Streamrはまさに未来を築いていると言えるだろう。Streamrは、ユーザーがリアルタイムデータ(IoTデバイスが生成するデータを含む)を交換・マネタイズできる分散型プラットフォームである。その中心となるのはStreamrネットワークであり、リアルタイムデータを生産者から消費者へと転送する役割を担っている。
Streamrネットワーク内のすべてのデータは「データストリーム」という形式で存在する。データストリームとは、任意の種類のデータが任意のソースから生成される一連のデータポイントのことである。スマートホーム内のセンサーや商業データ供給業者、データベースシステムなどがそのソースとして挙げられる。データストリームの具体例を見てみよう。

これらの数字は高性能エンジンからのもので、RPMの上昇とともに温度も上昇している。これは明らかに機械エンジニアにとって非常に有用であり、再設計時に現場のデータを活用できるようになる。
Streamrでは、ユーザーがデータストリームを収集し、「データアライアンス」としてパッケージ化する。合意のもと、異なるユーザーのリアルタイムデータを一つのデータアライアンスにまとめることが可能だ。データアライアンスは、Streamrマーケットプレイスで販売可能なコンテンツである。これがユーザーがリアルタイムデータをマネタイズする方法だ。購入者が(Streamrの用語では「購読」が適切だが)データアライアンスを購入すると、DATAトークンがすべてのデータストリーム生産者に分配される。すべてのデータアライアンスが同じというわけではない。メンバー構成、ユースケース、収益モデル、その他の特徴によって異なる。
私は、Streamrプラットフォームおよびデータアライアンスがデータ経済において重要な役割を果たすと信じている。これは許可不要で分散型のP2Pプロダクトであり、個人データ生産者もリアルタイムデータのマネタイズが可能にする。
Ocean Protocol
DataFi分野において、主要なプレイヤーの一つがOcean Protocolである。DataFiとは、データおよびデータサービスが新興資産クラスとして扱われる、DeFiの一分野として定義できる。Ocean Protocolはこの分野の先駆者であり、データ生産者が直接消費者に製品を販売できる分散型データ共有プロトコルである。

このプロトコルにより、データ提供者は所有権を完全に買い手に渡すことなく、データを安全にマネタイズできる。政策立案者やAI・機械学習エンジニアなどのデータ消費者は、本来アクセスが困難または不可能なプライベートデータセットを入手できるため、恩恵を受ける。
Ocean Protocolにおける最も重要な概念の一つが「データトークン(datatokens)」であり、特定のデータセットやデータサービスへのアクセスを可能にする。プロトコル上のすべてのデータセットやデータサービスには、それぞれ独自のデータトークンが付随している。データセットへのアクセスを得るには、データ生産者に1.0のデータトークンを送信すればよい。さらに、自分の持つ1.0のデータトークンを他人に送ることで、アクセス権を譲渡することもできる。ここで注意すべきは、データ自体を購入しているわけではなく、あくまで「アクセス権」を購入しているということだ。
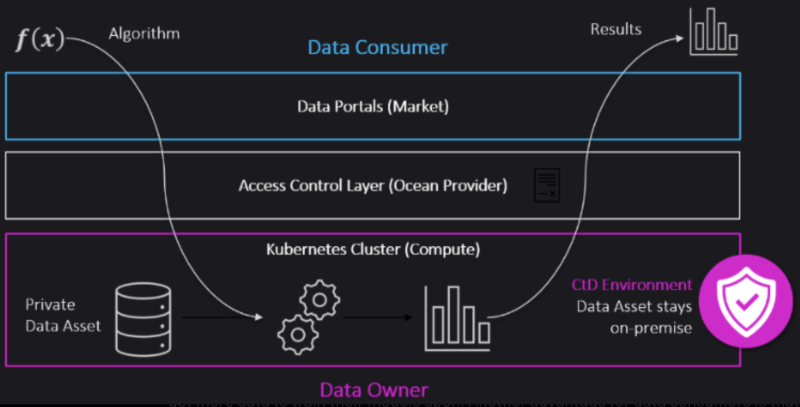
「コンピュート・トゥ・データ(Compute-to-Data, CtD)」は、プライバシーを保護しながらデータを共有できる賢い技術的解決策である。仮に自分が所有するデータセットを「貸し出し」たいが、セキュリティ上の理由から躊躇しているとする。一方、データサイエンティストがそのデータを使いたいと考えている。CtDはこうした問題を解決するツールだ。データ消費者は、データが所在する場所(あなたのハードウェア、Googleスプレッドシートファイルなど何でもよい)からデータを移動させることなく、その上でモデルを実行できる。CtDは、データ所有者とデータ消費者の間に設けられた保護層と捉えることができる。
仕組みとしては、データ上でアルゴリズムを実行した際に、データセット自体ではなく結果のみがデータ消費者に送信される。これにより、データ所有者はプライバシーを守りつつデータをマネタイズできる。データは直接消費者に販売しても、マーケットプレイスで販売してもよい。データ消費者はモデル訓練用のより多くのデータを入手でき、また計算インフラを自前で用意する必要がないという利点もある。なぜなら、すべての計算処理はデータ所有者のハードウェア上で行われるからだ。
Ocean Protocolでは、データだけでなくアルゴリズムも一種の資産として扱われる。研究者は自身のアルゴリズムをマネタイズできる。他のデータ資産と同様に、提供者はアルゴリズム自体を販売したり、アクセス権だけを販売したりできる。アルゴリズム開発者は、アクセス権のみを販売することを選択でき、これはアルゴリズムが公開されることを意味する。一方で、アルゴリズム自体ではなく計算サービスのみを販売する場合は、それは非公開(プライベート)となる。
Chainlink
最後に、老舗プロジェクトの一つであるChainlinkについて見てみよう。
多くのDeFiアプリケーションは外部データを必要としている。例えば、ブロックチェーン上の賭け市場は複数のブックメーカーからのリアルタイムオッズを必要とする。また、ETH先物価格に関連する証券を取引できる分散型取引アプリは、シカゴ・マーカンタイル取引所(CME)などの外部取引所からETH先物価格を取得できる必要がある。そのため、ほとんどの場合、スマートコントラクトを現実世界の情報と接続する仕組みが必要となる。
ここで登場するのが「ブロックチェーンオラクル」である。オラクルとは、DeFiを支えるスマートコントラクトに現実世界のデータを提供する第三者サービスのことだ。分散型オラクルはさらに一歩進んでおり、複数のオラクルを一つのシステムに統合する。複数のデータソースを照会し、その情報をブロックチェーンに返却する。目的は、単一障害点(SPOF)のリスクを低減することにある。
Chainlinkは、代表的な分散型オラクルネットワークである。そのアーキテクチャは3つの要素から構成されている:基本リクエストモデル、分散型データモデル、オフチェーンレポート。基本リクエストモデルは名前の通り、スマートコントラクトがBinance上のSOLの取引価格を知りたい場合、このモデルがそのタスクを遂行する。この部分は単一のデータソースからデータを照会する責任を負っている。
分散型データモデルは、オンチェーンでの集約(aggregation)の概念を導入している。複数の独立したオラクルノードからデータを集約することで、回答の信頼性と正確性が高まる。Chainlinkのデータ提供機能は、この分散型データモデルに基づいている。データ提供とは、天候イベント、企業財務情報、スポーツイベントの結果、資産価格といった、オフチェーンのデータソースのことだ。データはオンチェーンで集約され、消費者は常に最終的な答えを取得できる。
最後に、オフチェーンレポートは、Chainlinkを分散型環境下で真にユニークなものにしている。処理の大部分はオフチェーンで行われる。オラクル運営者(ノード)はピアツーピアネットワーク上で互いに通信し、各ノードが定期的にデータを報告し、署名で承認する。すべての報告は一つのトランザクションに集約され、それが当該ラウンドの最終的な答えとして転送される。複数のトランザクションではなく一つのトランザクションに集約することで、オラクルノードが支払う手数料が大幅に削減され、Chainlinkブロックチェーン上の混雑も緩和される。
まとめ
誇張抜きに、データは今や独立した資産クラスとなった。データおよびデータサービスは、経済全体においてますます重要性を増しており、ヘルスケアからEコマースに至るまで、あらゆる分野・業界に影響を与える「データ経済」というグローバルなデジタルエコシステムが形成されつつある。
しかし、グローバル経済の中で「データの流れ」にはいくつかの問題がある。現在の状況における最も深刻な問題の一つは、データがデータサイロ内に生成・保存されていることだ。データが他の関係者に届かないことで、その価値が低下している。二つ目の問題は所有権の欠如である。私たちのデータは、大手ソーシャルメディアプラットフォームや医療機器メーカーなどによって急速に記録・蓄積されているが、私たちは通常、そのデータの所有者ではない。私たちの同意なしに、データが使用されたり販売されたりしているのだ。
データDeFi(DataFi)は、データの収集と共有のあり方を変える。現時点ですでにDataFiは初期段階にあるとはいえ、データサービスを分散化しようとするプロジェクトが次々と登場している。Ocean ProtocolやStreamrのようなサービスは、データ生産者がマーケットプレイスで製品やサービスをマネタイズできるようにしている。ユーザーに新たな収益源を提供するだけでなく、これらのプラットフォームはデータの所有権を生産者に還元する。データ消費者にとっては、本来アクセスが困難または不可能だったデータを、安全かつ倫理的な方法で利用できるというメリットがある。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














