

Qwen3 d'Alibaba domine le classement mondial des logiciels open source, surpassant DeepSeek-R1 avec 17 000 étoiles en 2 heures
TechFlow SélectionTechFlow Sélection
Qwen3 d'Alibaba domine le classement mondial des logiciels open source, surpassant DeepSeek-R1 avec 17 000 étoiles en 2 heures
Qwen3 est plus conforme aux préférences humaines, excellant dans l'écriture créative, le jeu de rôle, les dialogues multipasses et le respect des instructions, offrant ainsi une expérience conversationnelle plus naturelle, captivante et réaliste.
Auteur : Xin Zhiyuan

【Introduction de TechFlow】Dans la nuit, Alibaba a officiellement publié Qwen3 en open source, couronnant ainsi le meilleur modèle ouvert mondial ! Ses performances dépassent largement DeepSeek-R1 et OpenAI o1. Basé sur une architecture MoE avec 235 milliards de paramètres au total, il domine tous les benchmarks clés. La famille entière Qwen3, composée de 8 modèles hybrides à raisonnement mixte, est désormais entièrement open source et librement utilisable commercialement.
Cette nuit même, le nouveau modèle Qwen3 d'Alibaba, très attendu mondialement, a été publié en open source !
Dès sa sortie, il devient immédiatement le meilleur modèle open source au monde.
Avec seulement un tiers des paramètres de DeepSeek-R1, Qwen3 réduit considérablement les coûts tout en surpassant largement des modèles de pointe comme R1 et OpenAI-o1.
Qwen3 est le premier « modèle hybride à raisonnement » en Chine, intégrant dans un seul modèle les modes « pensée rapide » et « pensée lente ». Il répond instantanément avec peu de puissance de calcul pour les requêtes simples, et effectue un « raisonnement profond » en plusieurs étapes pour les problèmes complexes, économisant ainsi énormément les ressources de calcul.
Il adopte une architecture Mixture of Experts (MoE), avec 235 milliards de paramètres au total, dont seulement 22 milliards activés à chaque inférence.
Son volume de données d'apprentissage atteint 36 téra-tokens, enrichi par plusieurs tours d'apprentissage par renforcement en phase post-entraînement, intégrant parfaitement le mode non réflexif au sein du modèle réflexif.
Dès son apparition, Qwen3 s'impose haut la main dans tous les benchmarks majeurs.
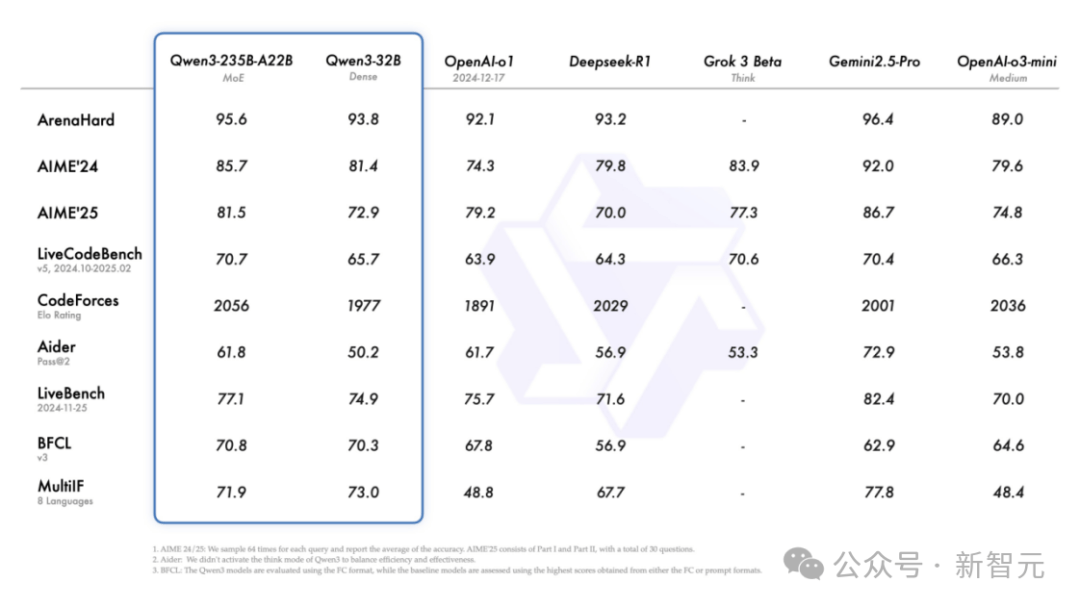
En outre, malgré des performances nettement améliorées, son coût de déploiement diminue fortement : seule une configuration de 4 cartes H20 suffit pour déployer la version complète de Qwen3, avec une occupation mémoire réduite à seulement un tiers de celle des modèles comparables !
Résumé des points forts :
· Une gamme complète de modèles denses et de modèles MoE disponibles dans diverses tailles, incluant 0,6B, 1,7B, 4B, 8B, 14B, 32B, ainsi que 30B-A3B et 235B-A22B.
· Capacité de basculer sans interruption entre un mode réflexif (pour raisonnement logique, mathématiques et codage complexes) et un mode non réflexif (pour conversations générales efficaces), garantissant des performances optimales dans tous les scénarios.
· Capacités de raisonnement nettement améliorées, surpassant les précédents modèles QwQ (en mode réflexion) et Qwen2.5 instruct (en mode non réflexif) en mathématiques, génération de code et raisonnement logique courant.
· Meilleure adéquation aux préférences humaines, excellant en écriture créative, jeu de rôle, dialogue multi-tours et suivi d'instructions, offrant une expérience conversationnelle plus naturelle, engageante et réaliste.
· Compétences avancées en agent IA : prise en charge précise de l'intégration avec des outils externes en mode réflexif et non réflexif, réalisant des performances leaders parmi les modèles open source sur des tâches complexes basées sur des agents.
· Prise en charge inédite de 119 langues et dialectes, dotée de solides capacités multilingues de suivi d'instructions et de traduction.
Actuellement, Qwen3 est disponible simultanément sur ModelScope, Hugging Face, GitHub, et peut être testé en ligne.
Tous les développeurs, institutions de recherche et entreprises du monde entier peuvent télécharger gratuitement les modèles et les utiliser à des fins commerciales. Ils peuvent aussi accéder via l'API Qwen3 sur Alibaba Cloud BaiLian. Les utilisateurs individuels peuvent dès maintenant expérimenter Qwen3 via l'application Tongyi, tandis que Kuai se prépare à intégrer complètement Qwen3.
Test en ligne :
Communauté ModelScope :
https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Hugging Face :
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
GitHub :
https://github.com/QwenLM/Qwen3
Jusqu’ici, Alibaba Tongyi a publié plus de 200 modèles en open source, avec plus de 300 millions de téléchargements dans le monde, et plus de 100 000 modèles dérivés de Qwen, dépassant définitivement Llama américain pour devenir le leader mondial des modèles open source !
La famille Qwen3 fait son entrée
8 modèles « à raisonnement hybride » entièrement open source
Cette fois, Alibaba publie d’un coup 8 modèles à raisonnement hybride, dont deux modèles MoE de 30B et 235B, ainsi que six modèles denses de 0,6B, 1,7B, 4B, 8B, 14B et 32B, tous sous licence Apache 2.0.
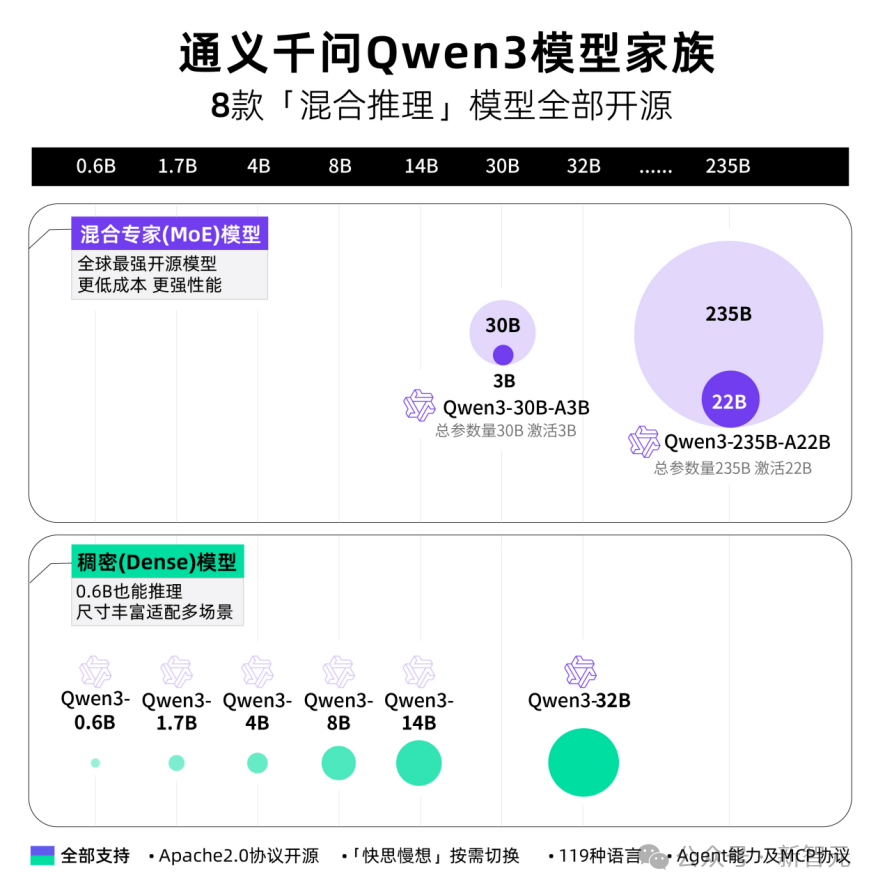
Chaque modèle obtient le SOTA (state-of-the-art) parmi les modèles open source de taille comparable.
Le modèle MoE Qwen3 à 30 milliards de paramètres réalise un levier de performance supérieur à 10x : seulement 3 milliards de paramètres activés suffisent à égaler les performances du modèle précédent Qwen2.5-32B.
Les modèles denses Qwen3 continuent de repousser les limites : avec la moitié des paramètres, ils atteignent des performances équivalentes. Par exemple, le Qwen3-32B surpasse même le Qwen2.5-72B.
En outre, tous les modèles Qwen3 sont hybrides à raisonnement mixte. Via l’API, on peut définir un « budget de pensée » (nombre maximal de tokens alloués au raisonnement profond), permettant un niveau variable de raisonnement selon les besoins en performance et en coût des applications IA.
Par exemple, le modèle 4B est idéal pour les smartphones ; le 8B fonctionne parfaitement sur ordinateur ou voiture embarquée ; le 32B est particulièrement populaire pour les déploiements massifs en entreprise, accessible même aux développeurs individuels.
Nouveau roi des modèles open source, records battus
Qwen3 affiche des progrès majeurs en raisonnement, suivi d'instructions, appel d'outils et capacité multilingue, établissant un nouveau record absolu parmi tous les modèles chinois et mondiaux open source :
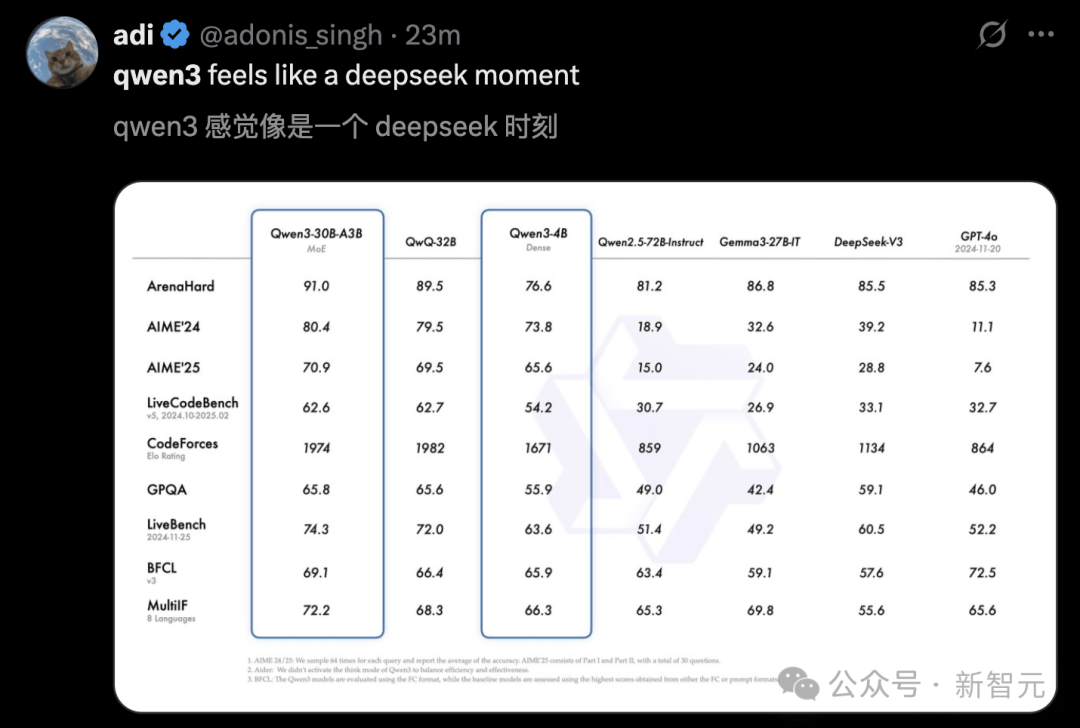
Dans l'évaluation AIME25, équivalent aux Olympiades de mathématiques, Qwen3 obtient 81,5/100, un record inégalé parmi les modèles open source.
Dans le benchmark LiveCodeBench qui évalue les compétences en codage, Qwen3 franchit la barre des 70 points, surpassant même Grok3.
Dans le test ArenaHard mesurant l'alignement avec les préférences humaines, Qwen3 atteint 95,6 points, dépassant OpenAI-o1 et DeepSeek-R1.

Plus précisément, le modèle phare Qwen3-235B-A22B se distingue brillamment face aux meilleurs modèles comme DeepSeek-R1, o1, o3-mini, Grok-3 et Gemini-2.5-Pro, sur tous les benchmarks clés (codage, mathématiques, compétences générales).
De plus, le petit modèle MoE Qwen3-30B-A3B, bien qu’activant seulement un dixième des paramètres du QwQ-32B, offre de meilleures performances.
Même un petit modèle comme Qwen3-4B rivalise avec le Qwen2.5-72B-Instruct.
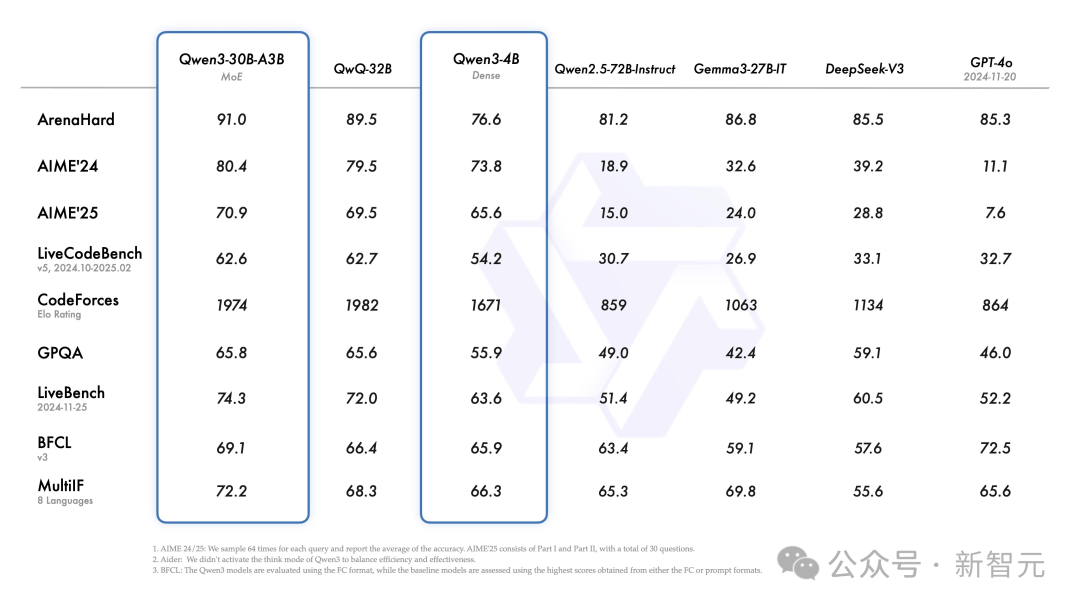
Les modèles affinés, comme Qwen3-30B-A3B, ainsi que leurs versions pré-entraînées (ex. Qwen3-30B-A3B-Base), sont désormais accessibles sur Hugging Face, ModelScope et Kaggle.
Pour le déploiement, Alibaba recommande les frameworks SGLang et vLLM. Pour une utilisation locale, Ollama, LMStudio, MLX, llama.cpp et KTransformers sont fortement conseillés.
Quel que soit l’environnement — recherche, développement ou production — Qwen3 peut facilement s’intégrer à toutes sortes de flux de travail.
Bénéfices pour l’essor des agents IA et des applications de grands modèles
On peut dire que Qwen3 offre un soutien accru à l’explosion imminente des agents IA et des applications basées sur de grands modèles.
Dans l’évaluation BFCL, qui mesure les capacités d’agent, Qwen3 atteint un record de 70,8, surpassant des modèles de pointe comme Gemini2.5-Pro et OpenAI-o1, abaissant ainsi fortement la barrière d’utilisation des outils par les agents.
En outre, Qwen3 prend nativement en charge le protocole MCP et possède de solides capacités d’appel d’outils, combinées au framework Qwen-Agent, qui intègre des modèles et analyseurs d’appel d’outils.
Cela réduit grandement la complexité du codage, permettant des tâches efficaces comme l’automatisation d’opérations sur téléphone ou ordinateur.
Caractéristiques principales
Mode de raisonnement hybride
Les modèles Qwen3 introduisent une approche hybride de résolution de problèmes, supportant deux modes :
1. Mode réflexif : le modèle procède par étapes de raisonnement avant de donner une réponse. Idéal pour les problèmes complexes nécessitant une réflexion approfondie.
2. Mode non réflexif : le modèle fournit rapidement une réponse directe, adapté aux questions simples où la rapidité est cruciale.
Cette flexibilité permet aux utilisateurs de contrôler le processus de raisonnement selon la complexité de la tâche.
Par exemple, les problèmes difficiles peuvent être traités par un raisonnement étendu, tandis que les questions simples sont résolues sans délai.
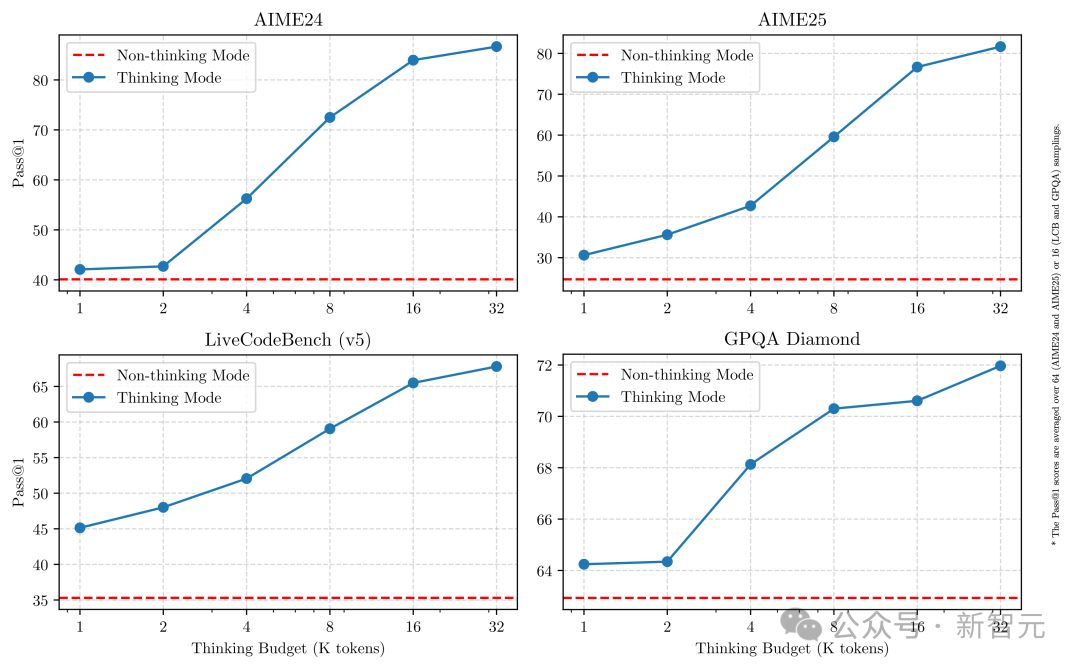
Encore plus important, cette combinaison améliore considérablement la stabilité et l’efficacité du contrôle des ressources de raisonnement.
Comme illustré ci-dessus, Qwen3 montre une amélioration progressive et fluide des performances, directement liée au budget de calcul alloué au raisonnement.
Cette conception permet aux utilisateurs de configurer facilement un budget spécifique par tâche, optimisant ainsi l’équilibre entre efficacité coûts et qualité du raisonnement.
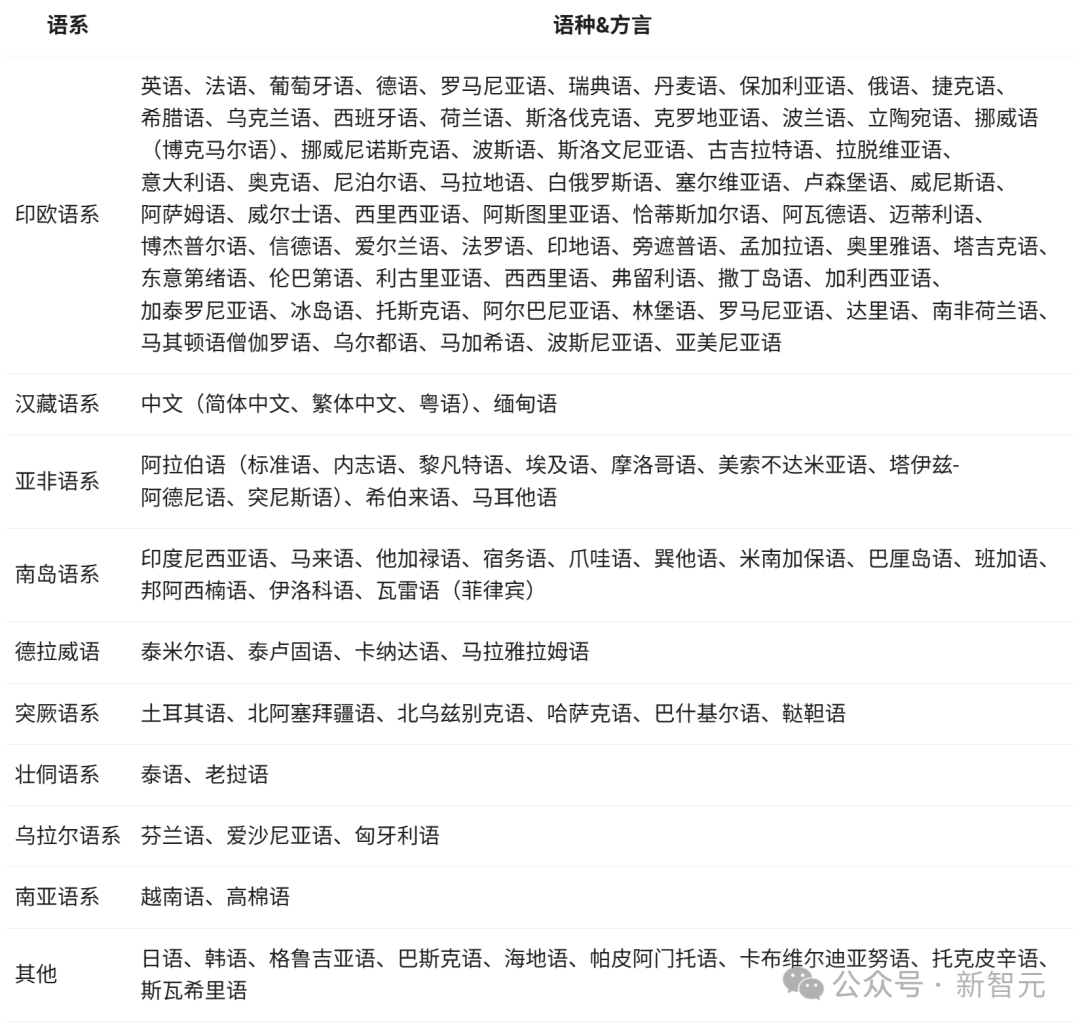
Prise en charge multilingue
Les modèles Qwen3 prennent en charge 119 langues et dialectes.
Cette large capacité multilingue signifie que Qwen3 a un potentiel énorme pour créer des applications internationales populaires à travers le monde.
Capacités d’agent encore renforcées
Alibaba a optimisé les modèles Qwen3 pour améliorer les compétences en codage et en agent, tout en renforçant la prise en charge de MCP.
L'exemple suivant illustre bien comment Qwen3 pense et interagit avec son environnement.
36 billions de tokens, entraînement en plusieurs phases
Comment Qwen3, le modèle le plus puissant de la série Qwen, parvient-il à de telles performances impressionnantes ?
Découvrons ensemble les détails techniques derrière Qwen3.
Pré-entraînement
Comparé à Qwen2.5, le jeu de données de pré-entraînement de Qwen3 est presque doublé, passant de 18 billions à 36 billions de tokens.
Il couvre 119 langues et dialectes, provenant non seulement du web, mais aussi de textes extraits de documents PDF, etc.
Pour assurer la qualité des données, l’équipe a utilisé Qwen2.5-VL pour extraire les textes des documents, puis Qwen2.5 pour améliorer la précision du contenu extrait.
De plus, afin d’améliorer les performances en mathématiques et codage, Qwen3 utilise des données synthétisées générées par Qwen2.5-Math et Qwen2.5-Coder, incluant manuels scolaires, paires question-réponse et extraits de code.
Le pré-entraînement de Qwen3 se déroule en trois phases, visant à renforcer progressivement les capacités du modèle :
Phase 1 (S1) : Construction des compétences linguistiques de base
Entraînement sur plus de 30 billions de tokens avec une longueur contextuelle de 4k. Cette phase pose les bases solides de la compétence linguistique et des connaissances générales du modèle.
Phase 2 (S2) : Optimisation axée sur les connaissances denses
Augmentation de la proportion de données denses en connaissances (STEM, codage, raisonnement), poursuite de l’entraînement sur 5 billions supplémentaires de tokens, améliorant ainsi les performances spécialisées.
Phase 3 (S3) : Extension de la capacité contextuelle
Utilisation de données contextuelles de haute qualité pour étendre la longueur contextuelle du modèle jusqu’à 32k, lui permettant de gérer des entrées complexes et très longues.
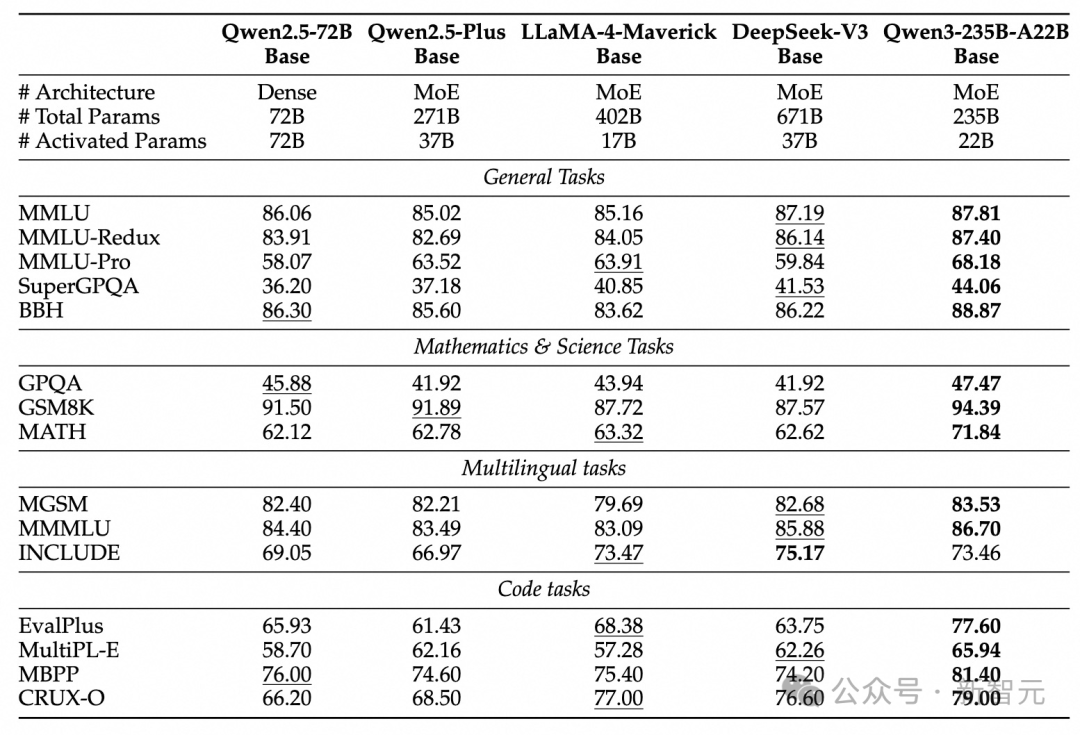
Grâce à l’optimisation de l’architecture, à l’extension des données et à des méthodes d’entraînement plus efficaces, le modèle dense de base Qwen3 affiche des performances remarquables.
Comme indiqué dans le tableau ci-dessous, Qwen3-1.7B/4B/8B/14B/32B-Base égale ou dépasse Qwen2.5-3B/7B/14B/32B/72B-Base, atteignant les performances de modèles plus gros avec moins de paramètres.
Particulièrement dans les domaines STEM, codage et raisonnement, le modèle dense de base Qwen3 surpasse même les grands modèles Qwen2.5.
Encore plus impressionnant : le modèle MoE Qwen3, avec seulement 10 % de ses paramètres activés, atteint des performances similaires à celles du modèle dense de base Qwen2.5.
Cela réduit considérablement les coûts d’entraînement et d’inférence, tout en offrant une grande flexibilité pour le déploiement pratique.
Post-entraînement
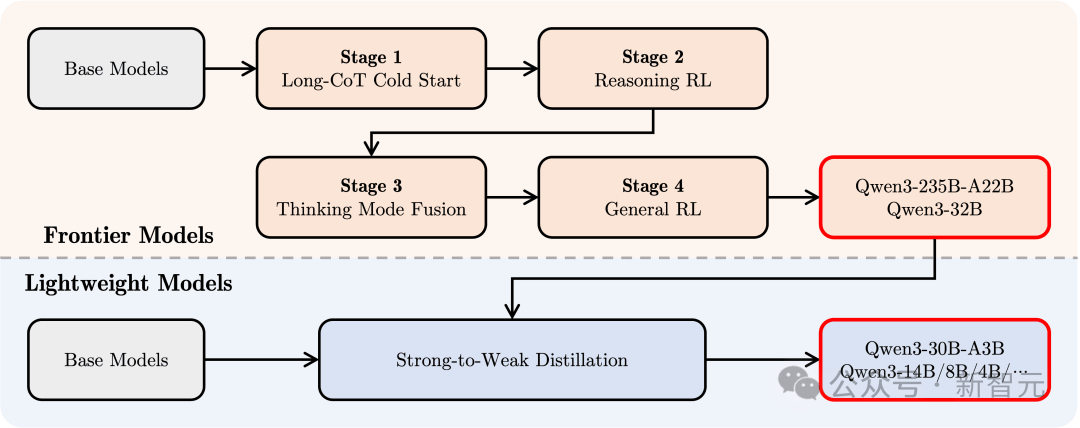
Pour créer un modèle hybride capable à la fois de raisonnement complexe et de réponse rapide, Qwen3 suit un processus de post-entraînement en quatre phases.
1. Démarrage à froid de chaîne de pensée longue
Utilisation de données variées de chaînes de pensée longues, couvrant mathématiques, codage, logique et problèmes STEM, pour enseigner au modèle les bases du raisonnement.
2. Apprentissage par renforcement sur chaîne de pensée longue
Extension des ressources de calcul RL, combinée à un système de récompense basé sur des règles, pour renforcer la capacité du modèle à explorer et exploiter efficacement les chemins de raisonnement.
3. Fusion des modes de pensée
Affinement avec des données de chaîne de pensée longue et des données d’instruction fine-tuning, intégrant la capacité de réponse rapide au sein du modèle réflexif, assurant précision et efficacité sur les tâches complexes.
Ces données sont générées par le modèle amélioré de la phase 2, garantissant une fusion transparente entre raisonnement profond et réponse rapide.
4. Apprentissage par renforcement général
Application de RL sur plus de 20 tâches générales, comme le suivi d’instructions, le respect de formats et les capacités d’agent, pour renforcer la polyvalence et la robustesse du modèle, tout en corrigeant les comportements indésirables.
Retombées positives massives
Moins de 3 heures après sa publication en open source, Qwen3 accumule déjà 17 000 étoiles sur GitHub, embrasant littéralement la communauté open source. Les développeurs téléchargent massivement et commencent des tests à grande vitesse.
Page du projet :
https://github.com/QwenLM/Qwen3
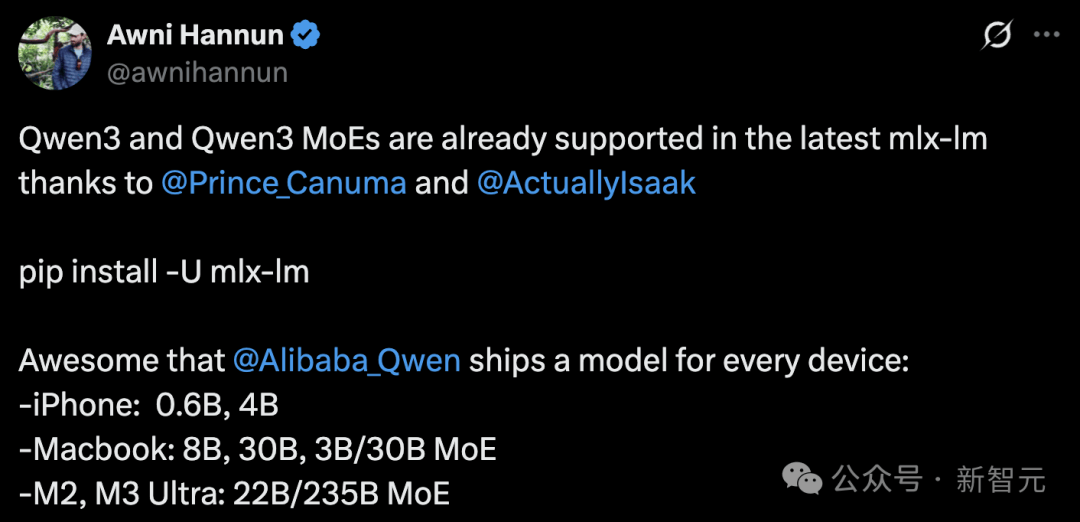
L'ingénieur Apple Awni Hannun annonce que Qwen3 est désormais pris en charge par le framework MLX.
Que ce soit sur iPhone (modèles 0,6B, 4B), MacBook (8B, 30B, MoE 3B/30B) ou appareils grand public M2/M3 Ultra (MoE 22B/235B), Qwen3 peut désormais fonctionner localement.
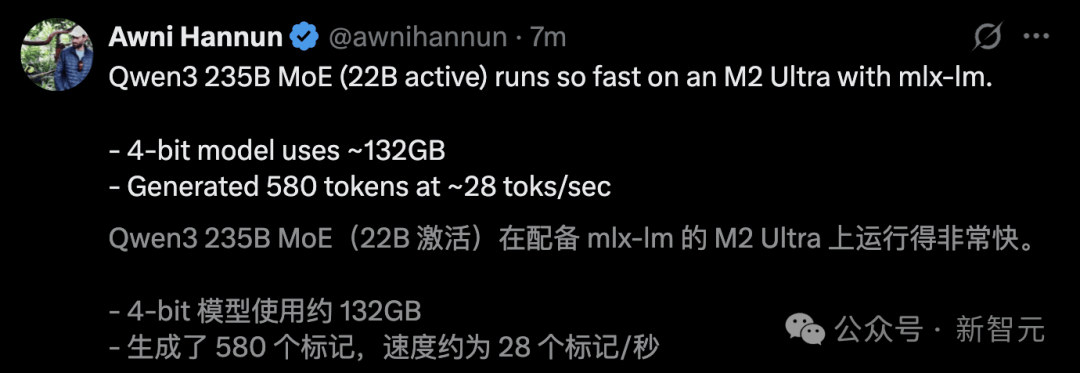
Il a exécuté Qwen3 235B MoE sur un M2 Ultra avec une vitesse de génération atteignant 28 tokens/s.
Des tests utilisateurs montrent que, comparé au modèle Llama de taille similaire, Qwen3 n’est tout simplement pas dans la même catégorie : raisonnement plus profond, contexte plus long maintenu, capacité à résoudre des problèmes plus difficiles.

Quelqu’un a commenté : « Qwen3, c’est un moment DeepSeek. »
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













