
La « surcharge du serveur » de DeepSeek rend tout le monde fou : quel est le problème derrière cela ?
TechFlow SélectionTechFlow Sélection
La « surcharge du serveur » de DeepSeek rend tout le monde fou : quel est le problème derrière cela ?
Bloqué sur la carte.

Image source : Generated by Wujie AI
Users around the world are frustrated by DeepSeek's frequent response of "server busy, please try again later".
Prior to this, DeepSeek was relatively unknown to the general public, but it gained widespread attention after launching its language model V3 on December 26, 2024, which rivals GPT-4o. On January 20, DeepSeek released R1, a language model comparable to OpenAI's o1. The high quality of answers generated through its "deep thinking" mode, along with innovative approaches suggesting a significant reduction in training costs, propelled the company and its application into the mainstream spotlight. Since then, DeepSeek R1 has been continuously experiencing congestion. Its web search function has intermittently failed, and the deep-thinking mode frequently displays "server busy", causing significant inconvenience for many users.
About ten days ago, DeepSeek began experiencing server outages. At noon on January 27, DeepSeek’s official website displayed multiple instances of “deepseek webpage/api unavailable”. That day, DeepSeek became the most downloaded iPhone application during the weekend, surpassing ChatGPT on the US download chart.
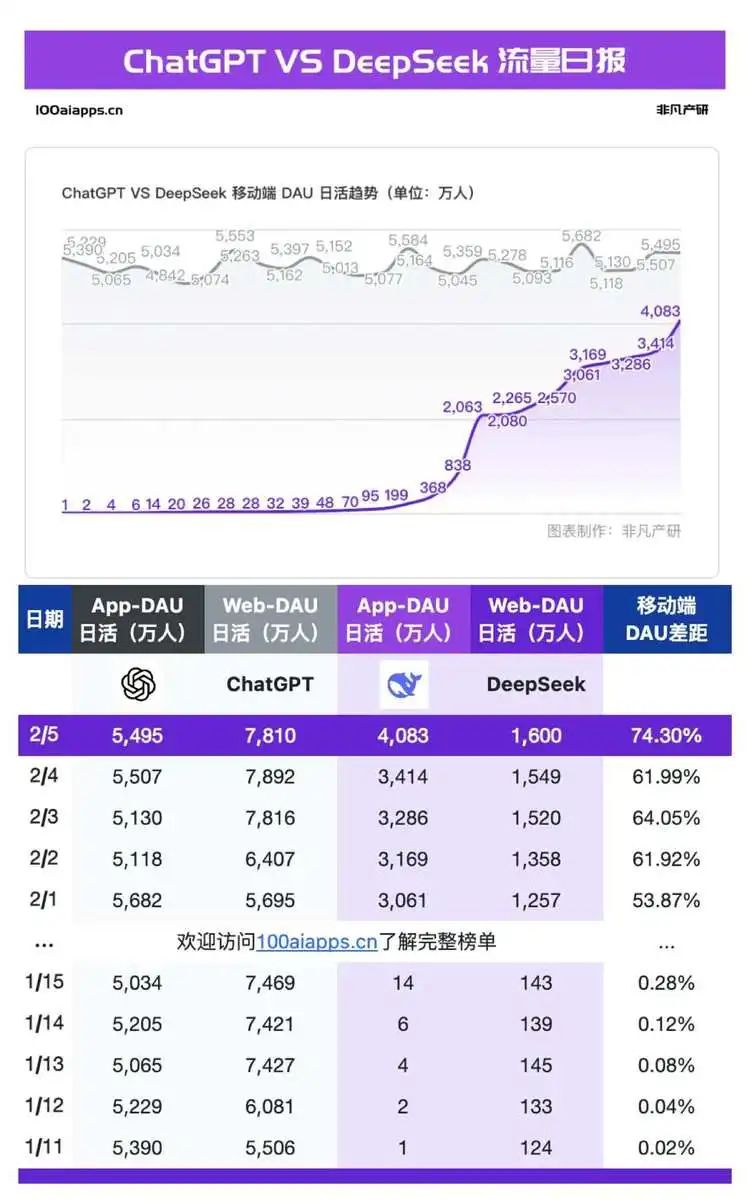
On February 5, just 26 days after launching its mobile app, DeepSeek achieved over 40 million daily active users. For comparison, ChatGPT's mobile version had 54.95 million daily active users, meaning DeepSeek reached 74.3% of ChatGPT's level. Almost as steeply as DeepSeek’s growth curve rose, complaints about server congestion poured in. Users worldwide started encountering frequent crashes after asking just a few questions. Alternative access methods began emerging—such as substitute websites for DeepSeek, services launched by major cloud providers, chipmakers, and infrastructure companies, alongside numerous personal deployment guides. Yet user frustration persisted: although nearly all major global vendors claimed support for deploying DeepSeek, users still complained about unstable service.
What exactly is happening behind the scenes?
1. People accustomed to ChatGPT can't tolerate an inaccessible DeepSeek
The dissatisfaction with "DeepSeek server busy" stems from previous top-tier AI applications like ChatGPT rarely suffering from lag or downtime.
Since OpenAI launched its service, ChatGPT has experienced only a few P0-level (the most severe) outages. Overall, it has remained relatively reliable, striking a balance between innovation and stability, gradually becoming a critical component akin to traditional cloud services.

ChatGPT hasn't suffered many large-scale outages
ChatGPT's inference process is relatively stable, consisting of encoding and decoding steps. During encoding, input text is converted into vectors containing semantic information. In the decoding phase, ChatGPT uses previously generated text as context and leverages the Transformer model to predict the next word or phrase until a complete sentence is formed. The large model itself follows a Decoder architecture, where the decoding stage outputs tokens one by one—the smallest unit used by large models when processing text. Each query to ChatGPT triggers a new inference cycle.
For example, if you ask ChatGPT, "How is your mood today?", it first encodes this sentence, generating attention representations at each layer. Based on these attention representations from prior tokens, it predicts the first output token "I". Then, during decoding, "I" is appended to "How is your mood today?" forming "How is your mood today? I", producing new attention representations. It then predicts the next token: "feel", and continues iteratively until arriving at the final response: "How is your mood today? I feel great."
Kubernetes, the container orchestration tool, acts as ChatGPT's "behind-the-scenes conductor," responsible for scheduling and allocating server resources. When user traffic exceeds Kubernetes control plane capacity, the entire ChatGPT system collapses.
Although ChatGPT has not crashed often, this reliability relies heavily on substantial underlying resources—powerful computing capabilities that people tend to overlook.
Generally, since inference involves smaller data scales, its computational demands are lower than those required for training. Industry experts estimate that during normal large-model inference, GPU memory is primarily consumed by model parameter weights, accounting for more than 80%. In reality, default model sizes within ChatGPT are smaller than DeepSeek-R1’s 671B. Combined with significantly more GPU computing power than DeepSeek, ChatGPT naturally delivers more stable performance compared to DS-R1.
Both DeepSeek-V3 and R1 are 671B models. Model startup equates to the inference process, requiring computing reserves proportional to user volume—for instance, supporting 100 million users requires graphics cards capable of handling that scale. This demand is massive and independent from training compute resources. According to available information, DS clearly lacks sufficient GPU and computing reserves, leading to frequent lags.
This contrast makes users accustomed to ChatGPT's smooth experience uncomfortable, especially given their growing interest in R1.
2. Lag, lag, and more lag
Moreover, a closer look reveals fundamental differences between OpenAI and DeepSeek situations.
The former benefits from Microsoft's backing. As OpenAI's exclusive platform, Microsoft Azure Cloud hosts ChatGPT, DALL-E 2 image generator, and GitHub Copilot coding assistant. This combination has become the classic cloud+AI paradigm, rapidly adopted across the industry. In contrast, despite being a startup, DeepSeek mostly relies on self-built data centers similar to Google, rather than third-party cloud computing providers. After reviewing public information, Silicon Star found no actual cooperation between DeepSeek and any cloud or chip vendor at any level (although cloud vendors announced during Spring Festival that they would run DeepSeek models on their platforms, there has been no meaningful collaboration).
In addition, DeepSeek faces unprecedented user growth, leaving it less time to prepare for sudden surges than ChatGPT had.
DeepSeek’s strong performance results from holistic optimization at hardware and system levels. DeepSeek’s parent company, High-Flyer Quant, invested 200 million yuan back in 2019 to build the Firefly No.1 supercomputing cluster. By 2022, it quietly stockpiled tens of thousands of A100 GPUs. To enable more efficient parallel training, DeepSeek developed its own HAI LLM training framework. Industry analysts believe the Firefly cluster may utilize thousands to tens of thousands of high-performance GPUs (such as NVIDIA A100/H100 or domestic chips), delivering powerful parallel computing capabilities. Currently, the Firefly cluster supports training for models like DeepSeek-R1 and DeepSeek-MoE, which perform close to GPT-4 levels in complex tasks such as math and coding.
The Firefly cluster represents DeepSeek’s exploration of novel architectures and methodologies. It has led outsiders to believe that through such innovations, DS has reduced training costs, enabling them to train R1-level models matching top-tier AI performance using only a fraction of the computational power required by Western counterparts. SemiAnalysis estimates suggest DeepSeek possesses vast computing reserves: a total of 60,000 NVIDIA GPU cards, including 10,000 A100s, 10,000 H100s, 10,000 “compliance-only” H800s, and 30,000 “compliance-only” H20s.
This might imply sufficient GPU availability for R1. However, R1, as an inference model targeting OpenAI’s O3, requires even greater computing deployment during response phases. Whether DS’s savings in training compute outweigh the sharply increased inference compute needs remains unclear.
Notably, while both DeepSeek-V3 and DeepSeek-R1 are large language models, their operational modes differ. DeepSeek-V3 is an instruction-following model similar to ChatGPT, generating responses based on prompts. But DeepSeek-R1 is a reasoning model: when users pose questions, it first performs extensive internal reasoning before generating final answers. The initial tokens produced include detailed chain-of-thought processes; the model explains and breaks down the problem before answering—all reasoning steps are rapidly generated as tokens.
According to Wen Tingcan, Vice President at Yauto Capital, DeepSeek’s massive computing reserve refers specifically to the training phase, where compute resources can be planned and predicted, making shortages unlikely. Inference compute, however, is far more uncertain, depending largely on user scale and usage patterns, thus being more elastic. “Inference compute grows predictably, but with DeepSeek becoming a phenomenon-level product, user numbers and usage have exploded in a short time, causing inference compute demand to surge uncontrollably—hence the lag.”
Gui Zang, an active model product designer and independent developer on Jike, agrees that insufficient GPU capacity is the main cause of DeepSeek’s lag. He believes that as the current highest-downloaded mobile app across 140 global markets, DeepSeek simply cannot sustain operations under current loads—even new GPUs wouldn’t help immediately because “provisioning new GPUs for cloud use takes time.”
“There is a fair market price per hour for running chips like NVIDIA A100 and H100. From a token-output inference cost perspective, DeepSeek is over 90% cheaper than OpenAI’s equivalent o1 model—a figure consistent with general calculations. Therefore, the MOE model architecture itself isn’t the core issue. Rather, the number of GPUs DS owns determines the maximum number of tokens they can produce per minute. Even if more GPUs are allocated to inference services instead of pre-training research, the upper limit remains fixed,” said Chen Yunfei, developer of the AI-native app Xiaomao Buguangdeng, echoing similar views.
Some industry insiders told Silicon Star that the root of DeepSeek’s lag lies in poorly executed private cloud infrastructure.
Another contributing factor to R1’s lag is cyberattacks. On January 30, media learned from cybersecurity firm Qi An Xin that attacks on DeepSeek’s online services suddenly intensified, with attack commands increasing over a hundredfold compared to January 28. Qi An Xin Xlab Lab observed at least two botnets participating in the assault.
However, there appears to be an obvious solution to R1’s own service lag: third-party provisioning. This was precisely the most vibrant scene we witnessed during the Spring Festival—vendors rushing to deploy services to meet global demand for DeepSeek.
On January 31, NVIDIA announced that DeepSeek-R1 is now available via NVIDIA NIM, following a near $600 billion drop in NVIDIA’s market value caused by DeepSeek-related impacts. On the same day, AWS users could deploy DeepSeek’s latest R1 foundation model on Amazon Bedrock and Amazon SageMaker AI. Subsequently, rising AI apps like Perplexity and Cursor also integrated DeepSeek en masse. Microsoft beat Amazon and NVIDIA, deploying DeepSeek-R1 first on Azure and GitHub.
Starting February 1 (Lunar New Year’s Day), Huawei Cloud, Alibaba Cloud, Volcano Engine under ByteDance, and Tencent Cloud joined in, generally offering full-series, all-size DeepSeek model deployment services. Then came AI chipmakers such as Biren Technology, Hanhai Semiconductor, Ascend, and MXCHIP, claiming compatibility with either the original DeepSeek version or distilled smaller versions. On the software side, companies like Yonyou and Kingdee integrated DeepSeek models into certain products to enhance functionality. Finally, device makers including Lenovo, Huawei, and Honor began integrating DeepSeek into select devices as on-device personal assistants and smart automotive cockpits.
To date, DeepSeek has attracted a vast network of partners—domestic and international cloud providers, telecom operators, securities firms, and national platforms like the National Supercomputing Internet Platform—thanks to its intrinsic value. Since DeepSeek-R1 is fully open-source, all service providers benefit from adopting the model. While this dramatically boosted DeepSeek’s visibility, it also exacerbated frequent lag issues. Both service providers and DeepSeek itself are increasingly overwhelmed by surging user traffic, yet neither has identified a key solution to ensure stable usage.
Considering both DeepSeek V3 and R1 boast 671 billion parameters, making them ideal for cloud deployment, cloud providers inherently possess greater computing and inference capabilities. Their launch of DeepSeek deployment services aims to lower enterprise adoption barriers. By deploying DeepSeek models and offering DS model APIs externally, they were expected to deliver better user experiences than DS’s own API.
In practice, however, the inherent runtime issues of the DeepSeek-R1 model remain unresolved across all service providers. Although outsiders assume vendors aren’t lacking GPUs, developers’ feedback shows instability frequencies matching those of R1 itself—mainly because the number of GPUs allocated for R1 inference remains limited.

“R1 maintains high popularity, and service providers must balance multiple integrated models. GPUs available for R1 are very limited. Once a provider launches R1 at relatively low prices, it gets overwhelmed instantly,” explained Gui Zang, model product designer and independent developer, to Silicon Star.
Model deployment optimization spans many aspects—from post-training stages to actual hardware deployment, involving multi-layered work. Yet for DeepSeek’s lag issue, the cause may be simpler: an overly large model combined with inadequate optimization preparation before launch.
Before launching a popular large model, teams face technical, engineering, and business challenges: consistency between training data and production environment data, data latency affecting real-time inference, inefficient online inference with excessive resource consumption, insufficient model generalization, and engineering issues like service stability and API integration.
Most trending large models place heavy emphasis on inference optimization prior to launch due to computation time and memory concerns. Long inference latency leads to poor user experience and failure to meet latency requirements—manifesting as lag. Excessive model parameters consume too much GPU memory, sometimes exceeding single-GPU capacity, also resulting in lag.
Wen Tingcan explained to Silicon Star that the challenges service providers face with R1 stem from DS’s unique model structure: an extremely large model combined with MOE (Mixture of Experts) architecture, an efficient computing method. “(Providers) need time to optimize, but market热度 has a time window—so they launch first and optimize later, rather than fully optimizing before going live.”
For R1 to operate stably, the key now lies in inference-side resource allocation and optimization capability. What DeepSeek needs is to find ways to reduce inference costs and decrease per-session token output volume.
Meanwhile, ongoing lag suggests DS’s actual computing reserves may not be as vast as SemiAnalysis claims. High-Flyer Fund also needs GPUs, and DeepSeek’s training team consumes them too—leaving few GPUs available for end users. Given current development trends, DeepSeek likely won’t prioritize spending on rented services to improve free user experience anytime soon. Instead, they’ll probably wait until their initial C-end business model becomes clear before considering service leasing—an implication that lag will persist for quite some time.
“They likely need two moves: 1) Introduce a paid mechanism to limit free-user model usage; 2) Partner with cloud service providers to leverage external GPU resources,” said developer Chen Yunfei. His proposed temporary fix enjoys broad consensus in the industry.
But currently, DeepSeek doesn’t seem particularly concerned about its "server busy" issue. As a company pursuing AGI, DeepSeek appears reluctant to focus too much on this sudden flood of user traffic. For the foreseeable future, users may just have to get used to seeing the "server busy" screen.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News















