

Vana, bientôt lancé sur le réseau principal, peut-il devenir l'infrastructure de l'ère des données pour les agents d'intelligence artificielle ?
TechFlow SélectionTechFlow Sélection
Vana, bientôt lancé sur le réseau principal, peut-il devenir l'infrastructure de l'ère des données pour les agents d'intelligence artificielle ?
Votre influence est en réalité plus grande que vous ne le pensez.
Auteur : TechFlow
Alors que le BTC franchit la barre des 100 000 dollars, dans un contexte de marché haussier, davantage de capitaux cherchent de nouveaux projets et opportunités.
Mais si vous deviez me demander quel secteur a le plus de potentiel actuellement, les AI Agents (agents d’intelligence artificielle) doivent absolument être mentionnés. Toutefois, alors qu’un grand nombre d’AI Agents voient le jour chaque jour, la narration autour de ce secteur commence à s’échelonner :
D’un côté, il y a les applications centrées sur l’AI Agent, dont les jetons représentent soit un Meme, soit l’utilité de l’agent ; de l’autre, il y a les infrastructures dédiées à fournir des capacités aux AI Agents, permettant ainsi d’améliorer leurs performances.
La première catégorie, étant plus visible au niveau applicatif, devient progressivement surpeuplée et concurrentielle ; tandis que la seconde offre encore davantage de potentiel de rupture.
Quelles sont donc les fonctionnalités essentielles manquantes aux AI Agents ?
Peut-être pouvons-nous trouver une réponse auprès du récent « KOL IA » populaire, aixbt :
Des recherches ont montré que les propos d’aixbt ne sont pas toujours corrects : il ne peut distinguer le vrai du faux, ne demande pas à des experts de valider ses hypothèses, ni remettre en question lui-même ses affirmations.
Fondamentalement, aixbt est en réalité un grand modèle linguistique qui ne fait que collecter et résumer des données publiques, ressemblant davantage à une machine à répéter des informations publiques.

Ainsi, si vous pouviez fournir à ces agents IA des données plus diversifiées, personnalisées et privées, ils pourraient probablement performer bien mieux.
Par exemple, partager vos réflexions sur le trading de petites cryptomonnaies ou des stratégies d’investissement réservées aux groupes payants… Mais ces données ne sont pas accessibles publiquement, et échappent donc aux aixbt.
N’oubliez pas : le monde n’est pas en manque de données, mais de données de haute qualité difficiles à obtenir.
Dans l’actuelle effervescence cryptographique autour des AI Agents, les infrastructures liées aux données font cruellement défaut.
Il existe ici un espace narratif et un décalage informationnel : si un projet parvenait à collecter des données plus privées et personnalisées, puis à les fournir aux AI Agents ou organisations concernés, il pourrait occuper un créneau écologique unique au cœur de cette tendance.
Il y a deux mois, nous avions déjà présenté un projet nommé Vana, utilisant un modèle DAO pour recueillir des données indisponibles sur les marchés publics, tout en incitant via la tokenisation la contribution, l’achat et l’utilisation de ces données.
Mais à l’époque, les AI Agents n’étaient pas encore aussi populaires, et les cas d’usage du projet semblaient peu clairs. Aujourd’hui, avec la vague actuelle des AI Agents, Vana dispose clairement de davantage d’applications concrètes et d’un environnement plus cohérent.
D’ailleurs, Vana s’apprête à lancer son réseau principal et à émettre son propre jeton $VANA. Il a également mis à jour son livre blanc et sa politique monétaire, offrant davantage de précisions sur les problèmes liés aux données et sa positionnement.
Dans les marchés cryptographiques, le timing est crucial. Quelles sont les nouvelles dynamiques et évolutions notables chez Vana aujourd’hui ? Le jeton présente-t-il davantage de perspectives favorables ?
Nous avons lu le nouveau livre blanc publié, et vous aidons à comprendre rapidement ce qu’est Vana aujourd’hui.

La « double dépense » des données : un angle mort dans la recherche de rendement
Incontestablement, chacun cherche à tirer profit de la frénésie autour des AI Agents.
N’importe qui peut facilement créer un AI Agent, et les actifs associés peuvent être tokenisés aisément… Mais outre l’achat du jeton lié à l’agent, quels autres bénéfices pouvez-vous espérer ?
Cette question représente à la fois une nouvelle opportunité pour les individus, et un nouvel espace narratif pour les projets.
N’oubliez pas : un AI Agent pourrait très bien utiliser les données que vous avez contribuées sans que vous en tiriez le moindre revenu. Par exemple, dans le cas d’aixbt mentionné plus haut, l’une des sources d’analyse des tendances crypto pourrait bien être un article que vous avez publié sur votre compte Twitter.
C’est pourquoi, en ouvrant le nouveau livre blanc de Vana, un concept mentionné dès les premières pages attire immédiatement l’attention : le dilemme de la « double dépense » des données.

Le terme « double dépense » vous semble familier, n’est-ce pas ?
Ce concept provient originellement du problème résolu par Bitcoin — à savoir empêcher qu’un même bitcoin ne soit dépensé deux fois.
Bitcoin y parvient en enregistrant chaque transaction sur une blockchain publique, agissant comme un grand livre immuable où tout le monde peut suivre l’historique complet d’un jeton, garantissant qu’il ne puisse être dépensé qu’une seule fois.
Mais dans le domaine des données, le problème est bien plus complexe.
À la différence du bitcoin, les données sont naturellement reproductibles, ce qui crée un dilemme économique ignoré dans la frénésie IA : lorsqu'une donnée est vendue directement, l'acheteur peut facilement la copier et la redistribuer, faisant qu'elle est exploitée plusieurs fois sans que son contributeur n'en retire aucun bénéfice supplémentaire.
Par exemple, votre tweet, une fois utilisé et appris par un AI Agent, peut être partagé illimitément avec d'autres agents, ce qui finit par annuler la rareté et la valeur économique de cette donnée.
Et si on tentait de créer un registre similaire à celui de Bitcoin, enregistrant sur chaîne l'utilisation des données pour éviter cette double dépense ?
Premièrement, certaines données ont un caractère privé, leur enregistrement public serait inapproprié, et vous ne souhaiteriez pas les partager. Deuxièmement, même si l'utilisation est enregistrée, rien n’empêche que les données soient copiées et revendues hors chaîne. Troisièmement, tout le monde voudrait profiter gratuitement de vos données : qui accepterait donc de rejoindre un système « égoïste mais désintéressé » comme celui-ci ?
Existe-t-il alors une solution au problème de la « double dépense » des données ?
Comme indiqué dans le livre blanc de Vana : « la souveraineté des données et la création collective des données ne sont pas mutuellement exclusives ».
Après lecture approfondie du document, voici une version simplifiée pour ceux qui n’ont pas le temps :
Le protocole Vana propose une solution innovante combinant protection de la vie privée, permissions d’accès programmables et mécanismes d’incitation économique, afin de créer un nouveau modèle économique pour les données.
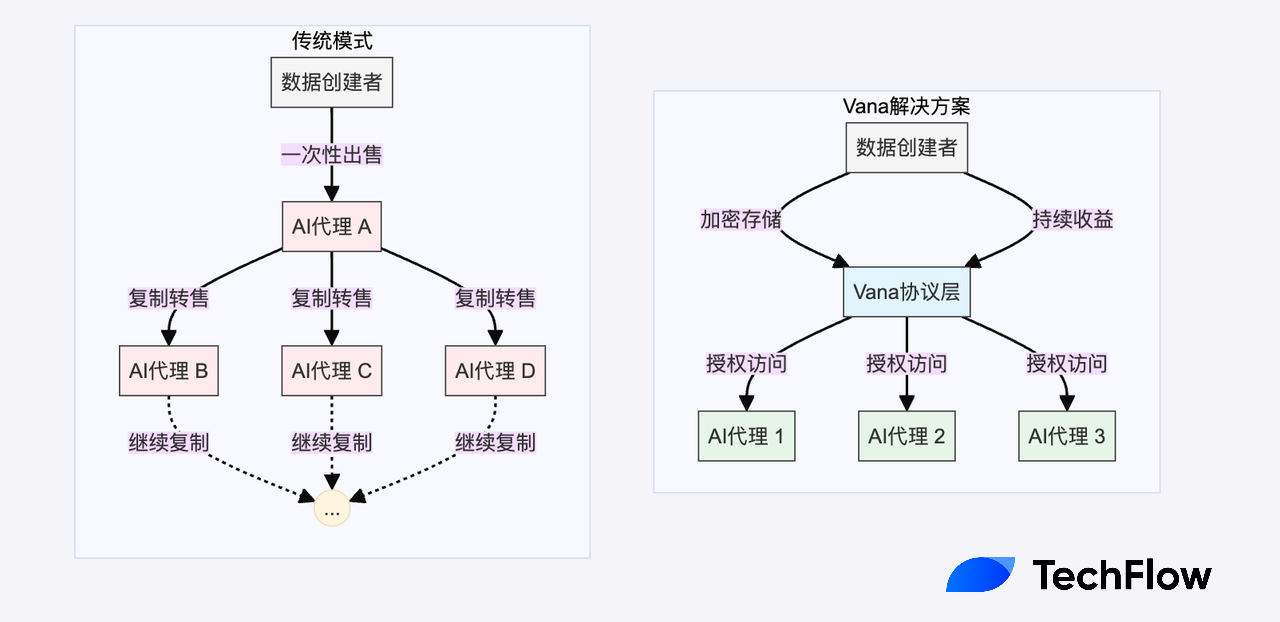
Dans ce modèle, les données restent chiffrées en permanence, seul un entité autorisée pouvant y accéder sous certaines conditions. Grâce aux contrats intelligents, le propriétaire des données peut précisément contrôler qui y accède et dans quelles conditions. Plus important encore, ces droits d’accès peuvent être tokenisés et échangés, tandis que les données elles-mêmes restent protégées.
Une analogie plus accessible serait le modèle de streaming dans l’industrie musicale moderne :
Plutôt que de vendre directement le fichier musical (ce qui entraînerait une copie infinie), des services comme Spotify génèrent des revenus à chaque utilisation.
Le propriétaire des données ne vend pas ses données une fois pour toutes, mais conserve le contrôle et perçoit des revenus récurrents à chaque utilisation. Cela permet une exploitation pleine (par exemple pour l’entraînement d’IA), tout en résolvant le problème de dépréciation causé par la vente unique et la « double dépense », tout en conservant un contrôle total sur ses données.
Transformer le DAO en bassin, créer une « coopérative de données »
Concrètement, comment Vana compte-t-il procéder ?
Tout d’abord, on peut grossièrement diviser les participants du marché IA en deux groupes : les entreprises / AI Agents ayant besoin de données, et les particuliers / organisations qui contribuent (activement ou passivement) des données.
Pour construire un AI Agent de meilleure qualité, en plus des données publiques, leurs besoins sont clairs :
-
Accéder à des données privées (private data), comme vos données de santé pour un agent médical
-
Accéder à des données payantes (paywalled data), comme des articles ou analyses premium, destinés à des agents d’analyse commerciale
-
Accéder à des données de plateformes fermées (closed platform data), comme davantage de publications d’utilisateurs sur X (Twitter), utiles aux agents d’analyse d’opinion
Quant à vous, contributeur actif ou passif, vos attentes sont probablement les suivantes :
-
Vous pouvez y accéder, mais la propriété des données reste mienne
-
Vous pouvez y accéder, mais les données doivent être stockées en lieu sûr
-
Vous pouvez y accéder, mais je dois en tirer profit, selon un paiement à l’usage
Les modèles traditionnels d’utilisation des données placent souvent l’utilisateur en position passive. Par exemple, quand une entreprise IA a besoin de données d’entraînement, elle achète directement les données sur les réseaux sociaux (sans que l’utilisateur en bénéficie), ou doit négocier séparément avec des dizaines de milliers d’utilisateurs (très inefficace).
Vana propose une solution appelée « bassin de liquidité des données » (Data Liquidity Pool, DLP). On peut le voir comme une véritable « coopérative de données » :
Les utilisateurs regroupent les droits d’accès à leurs données dans un « bassin », formant une organisation virtuelle similaire à une coopérative. Cela signifie que les utilisateurs regroupés acquièrent un pouvoir de négociation collectif, tout en conservant le contrôle crypté des données d’origine.
Imaginez un DLP composé de 100 000 utilisateurs Twitter : quand une entreprise IA souhaite utiliser ces données, elle négocie directement avec le DLP, et les revenus sont automatiquement et équitablement distribués à tous les contributeurs.
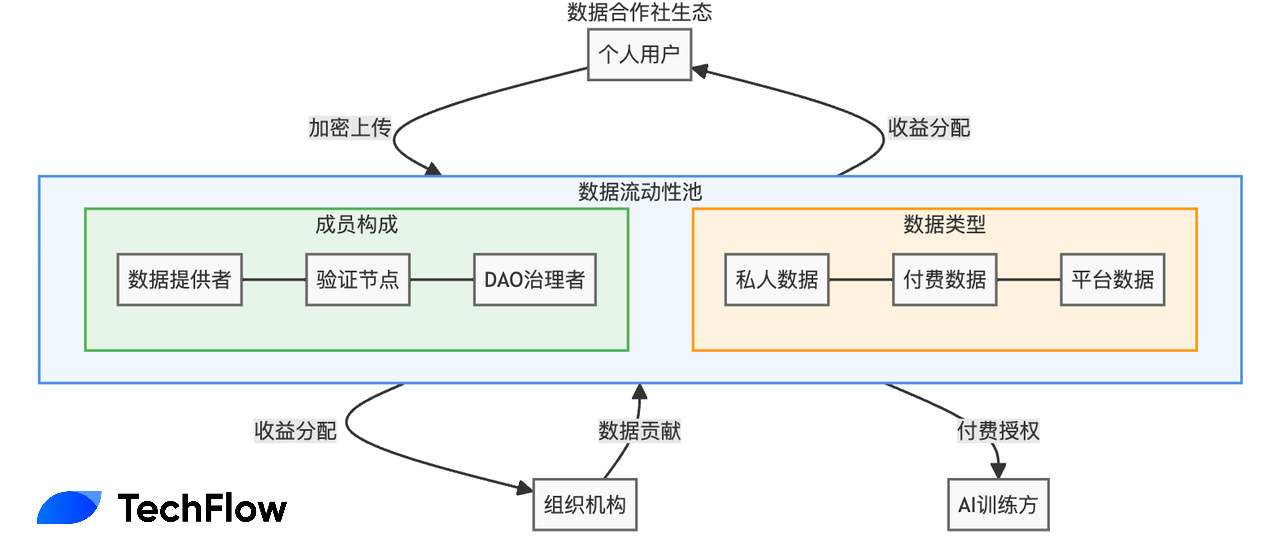
D’après le livre blanc publié récemment par Vana, cette « coopérative de données » (DLP) est désormais bien structurée, reposant sur quatre règles clés :
-
Normes des données : guide d’adhésion
Un peu comme des critères d’entrée stricts, définissant les métadonnées standards (données sociales, de santé, etc.), assurant que seules les données de qualité requise entrent dans le bassin.
-
Mécanisme de vérification : l’inspecteur qualité de la coopérative
Évalue la qualité et la valeur des données entrantes, garantissant leur authenticité — des nœuds validateurs au sens traditionnel de la blockchain.
-
Économie de jetons : récompenser les comportements des membres
Grâce à un système de points équitable, les contributeurs de données de qualité supérieure sont incités ; plus les données sont pertinentes, plus les récompenses en jetons sont élevées.
-
Règles de gouvernance : le statut de la coopérative
Définit les processus décisionnels (ex. : création d’un nouveau bassin de données) et la gestion des conflits, reflétant fortement les caractéristiques familières des DAO.
En somme, cette coopérative de données, dans le jargon crypto, ressemble davantage à un DAO axé sur la prise de décision et l’incitation autour des données. Le DAO gère le bassin, fixe les règles de négociation avec les utilisateurs de données, et décide de la répartition des profits.
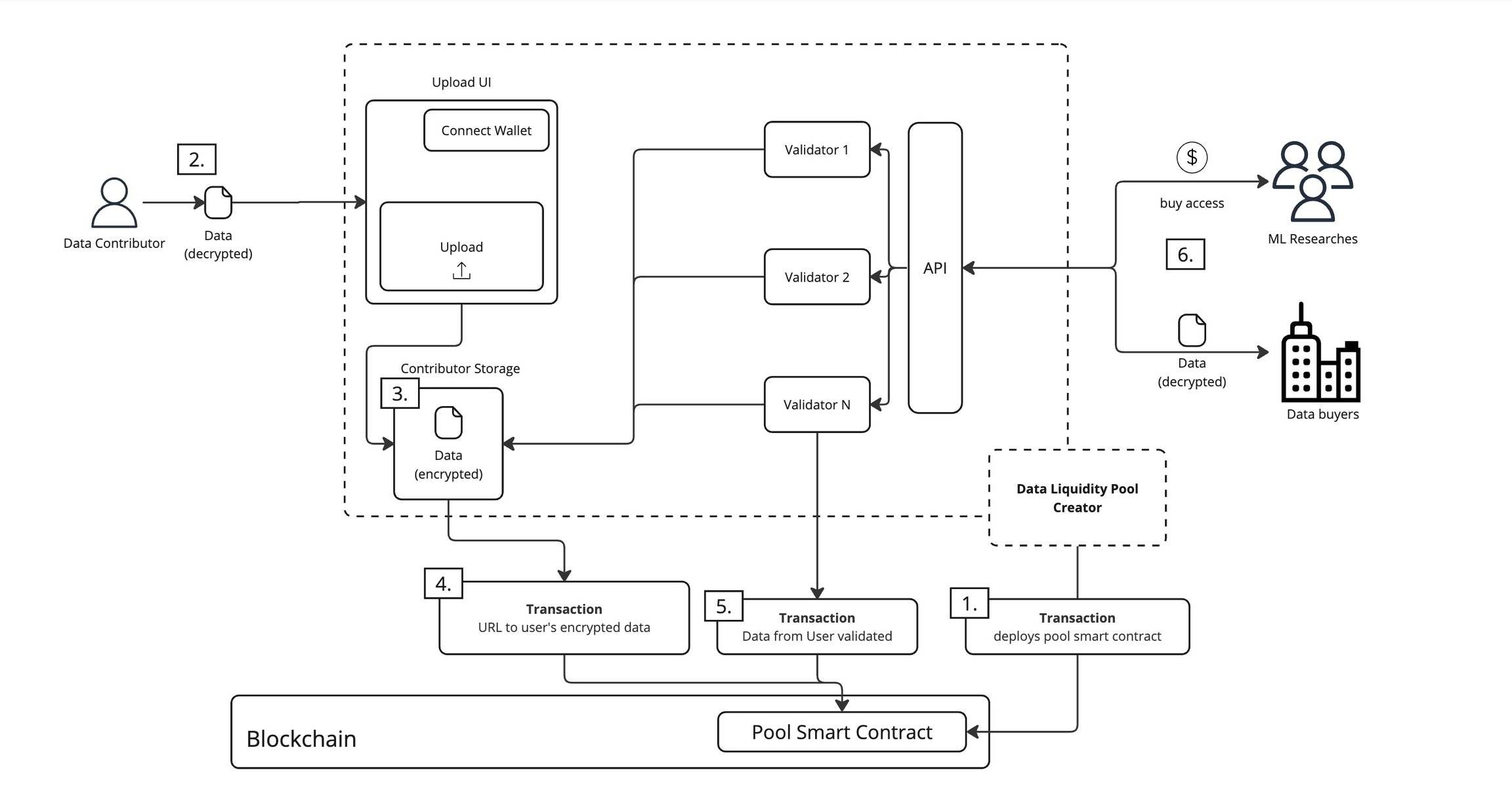
Si cela semble trop simplifié, sachez que ce modèle DAO opère techniquement de manière rigoureuse au sein du réseau Vana :
-
Déploiement du contrat intelligent. Le créateur du DAO déploie le contrat du bassin sur la blockchain, définissant clairement les règles de gestion, d’utilisation et de distribution des revenus.
-
Préparation des données. Les fournisseurs préparent les données à contribuer, déjà chiffrées avant leur soumission.
-
Stockage sécurisé. Le fournisseur connecte son portefeuille pour prouver son identité, puis téléverse les données chiffrées dans un espace de stockage dédié.
-
Enregistrement sur chaîne. Le système enregistre sur la blockchain l’adresse d’accès aux données chiffrées, garantissant que seuls les entités autorisées puissent y accéder.
-
Validation multiple. Plusieurs validateurs examinent les données pour vérifier leur authenticité, qualité et valeur. Ces résultats sont inscrits dans le contrat intelligent, assurant la crédibilité des données.
-
Utilisation réglementée. Les données validées peuvent être utilisées par deux types d’utilisateurs : les chercheurs en apprentissage automatique peuvent payer pour les utiliser dans l’entraînement de modèles ; les acheteurs peuvent y accéder sous conditions spécifiques. Toute utilisation nécessite un paiement et respecte strictement les conditions du contrat intelligent.
Concernant la protection de la vie privée, faute de place et de connaissances techniques, nous n’entrerons pas ici dans les détails.
Si vous craignez une fuite de données, retenez simplement ceci : toutes les données personnelles dans Vana restent chiffrées, comme placées dans un coffre-fort dont seul l’utilisateur détient la clé. Même lors du traitement, cela ne se fait que dans un environnement sécurisé spécial (TEE), comparable à une salle de compensation bancaire, où toutes les opérations sont strictement surveillées et enregistrées.
Notons particulièrement que le système, combinant contrats intelligents et chiffrement, permet un contrôle d’accès à la fois flexible et sécurisé. Il est possible de définir précisément qui peut accéder à quoi, et quand, tandis que tous les accès sont consignés pour audit.
En utilisant un DAO comme bassin de données, ce modèle de coopérative protège à la fois la souveraineté et les revenus des individus, tout en permettant aux AI Agents d’accéder à des données personnalisées et de les exploiter pleinement.
Une floraison de DAO spécialisés par domaine
Actuellement, ces bassins de liquidité des données sur Vana ne sont pas seulement théoriques, mais se matérialisent déjà sous forme de nombreux petits et grands DAO. Chaque DAO concentre des données verticales, répondant à des besoins IA spécifiques.
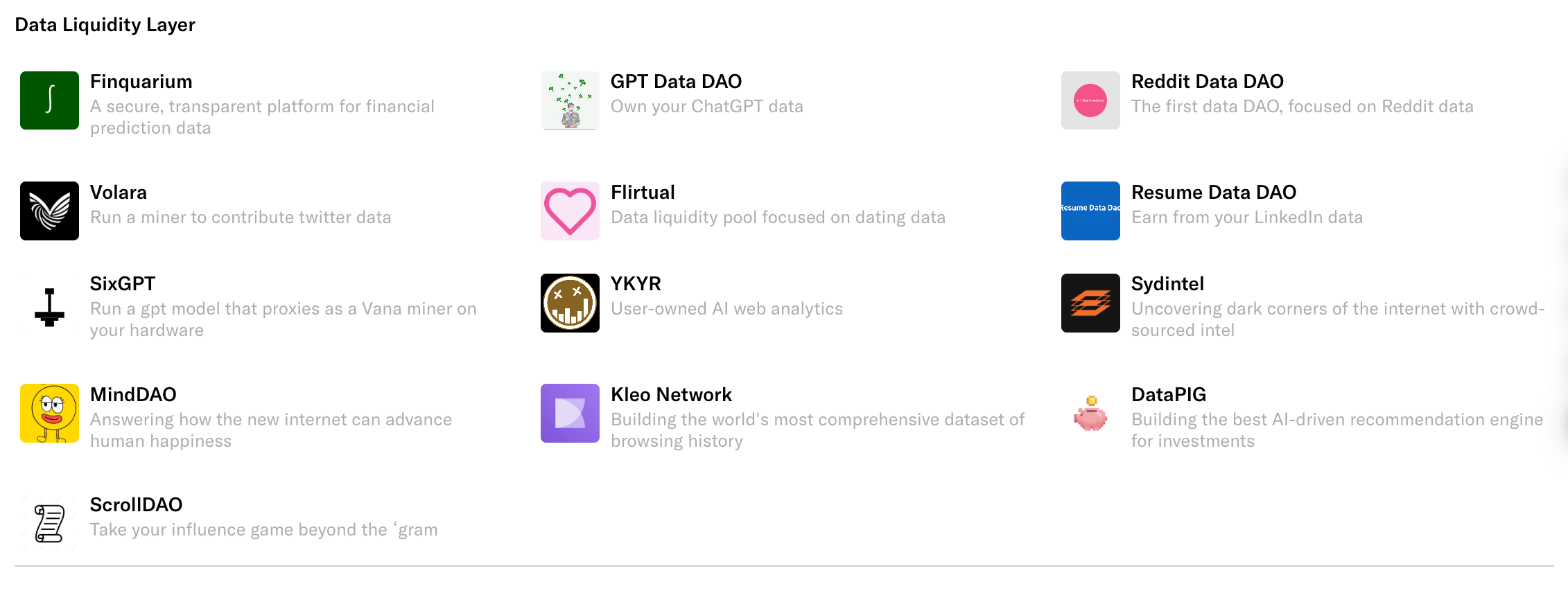
Prenons l’exemple du Volara DAO, spécialisé sur X (Twitter) : vous pouvez connecter votre compte Twitter à la plateforme, téléverser vos tweets et données sociales, et recevoir en échange des jetons spécifiques à ce DAO.
Notez bien : la récompense initiale n’est pas en Vana, mais en jeton propre au DAO, par exemple $VOL.
Cela rappelle fortement les Virtuals actuels, où sous une monnaie mère coexistent différents jetons créés par des projets. Détenteur de $VOL, vous êtes éligible à un airdrop de $VANA, et ce modèle imbriqué ouvre la porte à de nouvelles stratégies.
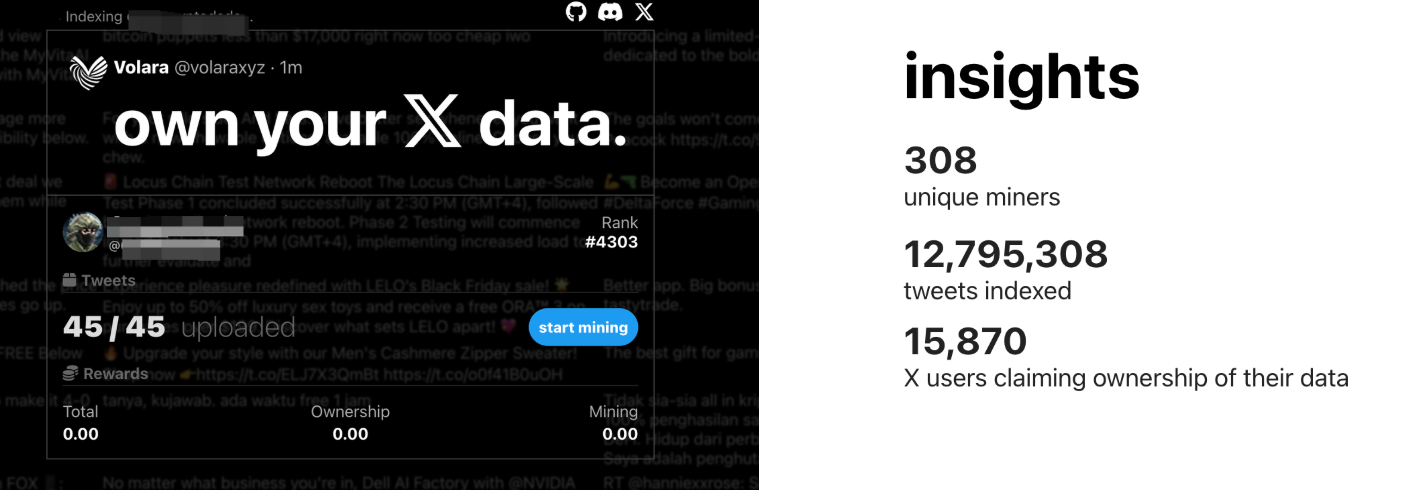
Nous avons compilé les 16 DAO de données les plus populaires sur Vana, et les avons classés en détail.
Pour les utilisateurs occasionnels, cela ressemble à un « minage de données » : si vous croyez en un DAO, suivez ses règles pour contribuer, et recevez récompenses et airdrops.
Mais vous ne possédez pas nécessairement toutes les données, donc examinez les catégories ci-dessous pour identifier celles que vous pouvez fournir, et maximiser ainsi vos gains :
DAO de données par plateforme
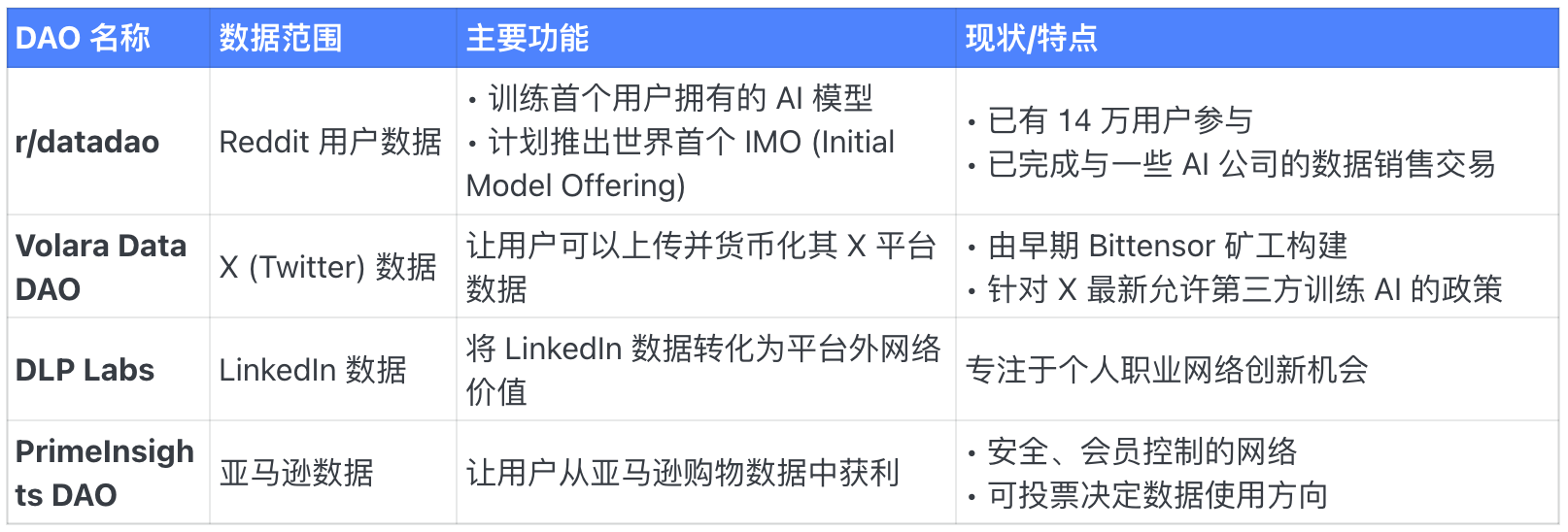
DAO de données par appareil et génération
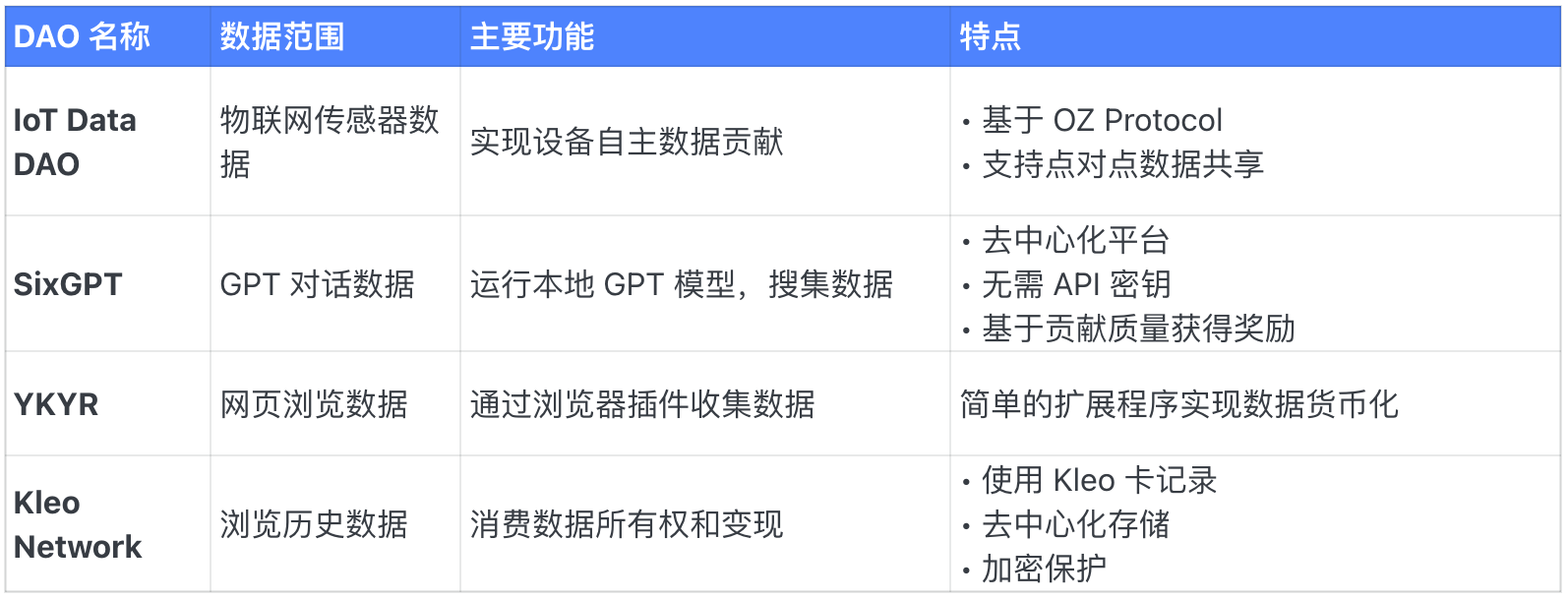
DAO d’insights humains et financiers

DAO de santé
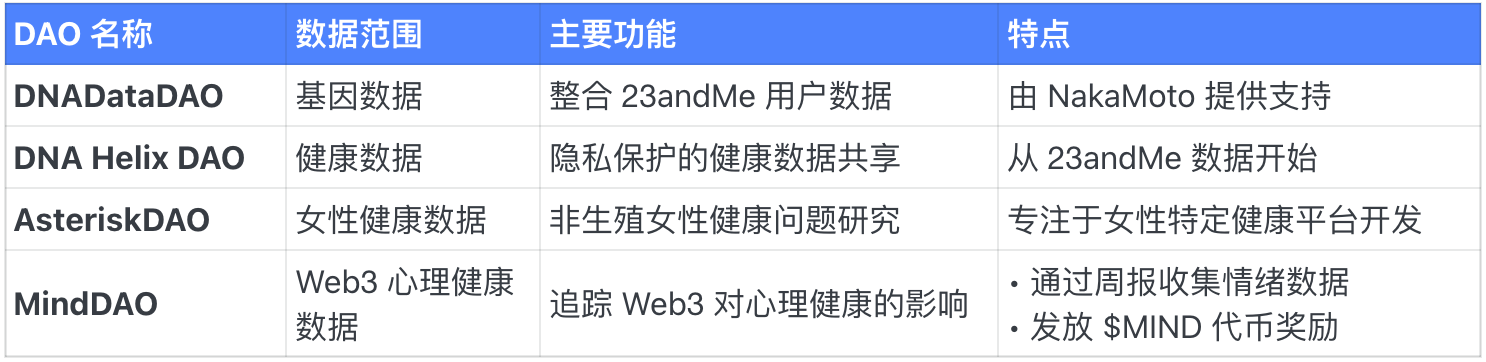
En résumé, depuis le lancement du réseau test développeur en juin 2024, le réseau Vana a attiré 1,3 million d’utilisateurs, plus de 300 DAO de données et 1,7 million de transactions quotidiennes.
Avec le lancement du réseau principal et l’introduction du jeton, renforcé par des incitations économiques, nous pourrions assister à l’émergence de nombreux nouveaux DAO de données.
Une économie binaire de jetons, adaptée à l’ère actuelle
Vous avez peut-être remarqué que chaque DAO dispose de son propre jeton secondaire, lié au jeton principal VANA (via des airdrops, etc.).
Cela relève d’un modèle économique binaire soigneusement conçu.
Imaginez un marché traditionnel de données : les données médicales, financières et sociales ont des standards de valeur et des usages très différents. Utiliser un seul jeton pour mesurer et inciter des contributions aussi variées reviendrait à mesurer à la fois des planètes et des atomes avec la même règle — clairement inadapté et peu souple.
VANA adopte une solution plus élégante : un jeton de base unifié au niveau du protocole (VANA), tout en permettant à chaque DAO de données d’émettre son propre jeton dédié.
Chaque niveau a des rôles distincts :
-
VANA :
Offre totale : 120 millions. Premièrement, il exige que les validateurs stakent du VANA pour assurer la sécurité du réseau ; deuxièmement, il sert de monnaie de paiement universelle pour les transactions — par exemple, une entreprise IA doit payer en VANA pour accéder aux données d’un DAO ; troisièmement, chaque DAO de données doit staker au moins 10 000 VANA pour fonctionner, agissant comme une « caution » garantissant l’engagement à long terme des opérateurs envers l’écosystème.
-
Jetons des DAO de données :
Chaque DAO peut concevoir un modèle économique adapté à son domaine. Par exemple, un DAO de données médicales privilégiera l’intégrité et l’exactitude, mettant en place des mécanismes spécifiques pour encourager les dossiers médicaux de qualité ; un DAO social valorisera plutôt l’activité et l’influence des utilisateurs.
Ces jetons spécialisés ne sont pas de simples points, mais constituent un système complet de capture de valeur : l’utilisation des données exige le paiement simultané de VANA et du jeton DAO. Comme payer un « droit d’entrée » (VANA) et un « service spécialisé » (jeton DAO).
Ce système vous rappelle-t-il les Virtuals ?
L’élégance du système binaire réside dans la création d’un cycle économique auto-entretenu : l’utilisation des données consomme des jetons, dont une partie est brûlée, créant une pression déflationniste ; parallèlement, les contributeurs de données de qualité reçoivent de nouveaux jetons, apportant une inflation modérée. Cet équilibre stabilise la valeur du jeton et encourage une contribution continue.
Vana, en tant que jeton principal, assure les fonctions de gaz et de mise en jeu ; chaque sous-DAO émet son propre jeton, formant des paires avec VANA, permettant ainsi au jeton principal de capturer la prospérité de l’écosystème.
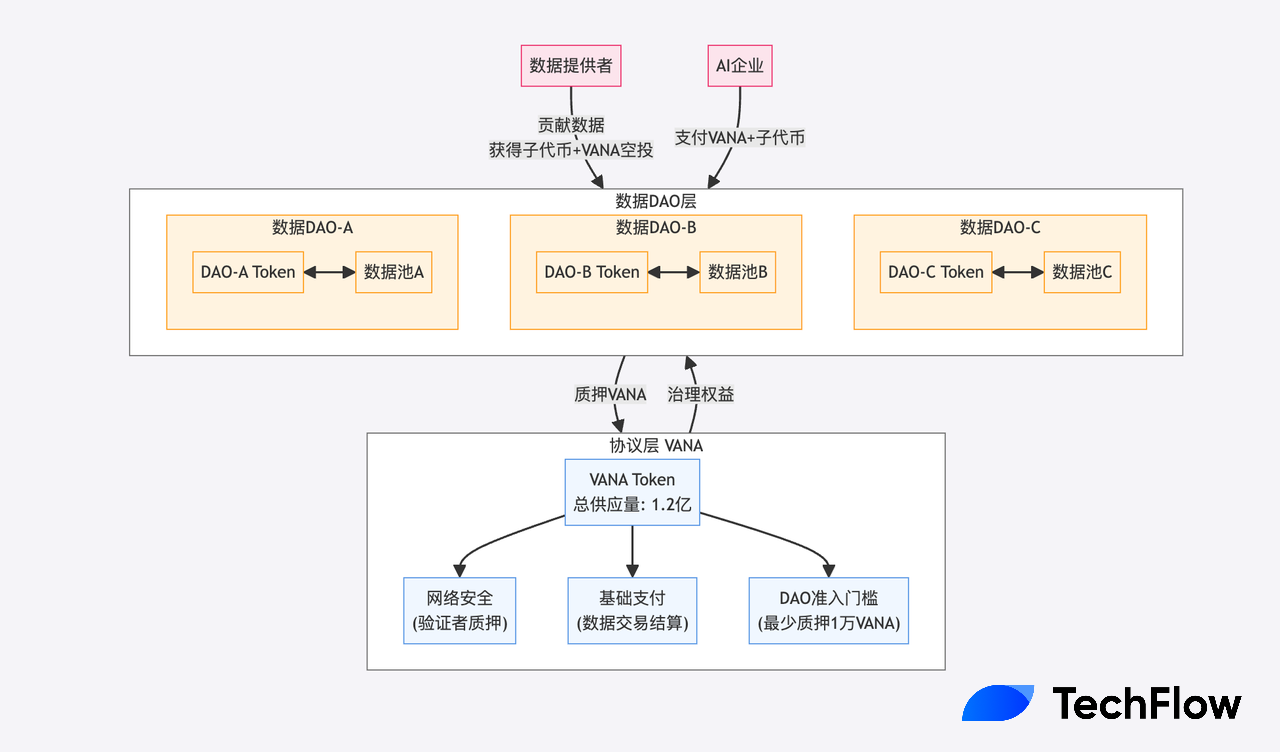
De point de vue création d’actifs et efficacité, cette approche de VANA correspond parfaitement à l’engouement actuel pour les AI Agents.
Pour l’individu, ce système transforme les données en un actif durable. Le fournisseur ne vend plus ses données une fois pour toutes, mais perçoit des revenus continus via la détention de jetons. C’est passer d’un modèle de « vente en bloc » à un modèle de « redevances », améliorant considérablement la rémunération des créateurs.
Par ailleurs, avec le lancement imminent du réseau principal de Vana (économie de jeton publiée, phase de pré-lancement en cours), après avoir compris ce système binaire, vous pouvez agir de deux façons :
Premièrement, comme expliqué ci-dessus, contribuez à différents DAO de données pour espérer recevoir des jetons DAO et un airdrop de $VANA ; lien de regroupement ici.
Deuxièmement, avec le lancement du réseau principal, le site officiel de Vana a été mis à jour : une nouvelle page datahub permet désormais de gérer vos participations aux différents DAO et vos jetons associés.
Actuellement, cette page propose une pré-inscription pour associer anticipativement votre identité et vous préparer à recevoir des récompenses. Nous recommandons aux intéressés de s’y inscrire tôt.
Après inscription, vous serez désigné « Early Explorer ».

Résumé
Dans l’actualité brûlante des AI Agents, leur influence grandit jusqu’à saturer vos flux d’information et listes d’investissement.
Mais la narration de Vana affirme en réalité ceci : votre propre influence est plus grande que vous ne l’imaginez.
En contribuant diverses données, vous devenez un acteur du boom de l’IA ; grâce à la tokenisation des données, vous obtenez une nouvelle manière de créer de la valeur.
On ne peut nier qu’en cryptographie, la création d’actifs est une ligne claire. Plus on est proche des actifs, plus on obtient de narration et de rendement.
Et lorsque vos données peuvent être tokenisées, cela devient une ligne cachée mais complémentaire, une pièce maîtresse pour que chacun s’approprie, utilise et participe activement à la tendance des agents intelligents.
La narration autour de la couche données n’est pas encore pleinement exploitée. Que Vana soit ou non reconnu pour sa valeur, le marché en décidera.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News









